
Firedancer バリデーターが発売され、Solana の大量採用への道が開かれる
この記事は以下から引用しました:《What is Firedancer? A Deep Dive into Solana 2.0 》
原作者:0xIchigo
毎日の翻訳者: 夫のハウ

ご存知のとおり、Solana は現在のパブリック チェーンの高性能を代表するものの 1 つであり、そのより高速なオンチェーン処理速度は多くのプロジェクト関係者によって求められており、Visa などの伝統的な大手企業の支持も集めています。しかし、Solana には常にネットワーク ダウンタイムという隠れた危険が潜んでいます。ネットワーク ダウンタイムの問題をどのように解決すればよいでしょうか? Jump がクライアントを検証するために起動する Firedancer クライアントが答えを与えることができるかもしれません。
この記事では、ブロックチェーン上のバリデーターとバリデーター・クライアントの役割から始めて、Firedancer バリデーター・クライアントが Solana ネットワークをどのようにサポートするかを検討します。
以下はOdailyがまとめたものです。
バリデーターとバリデータークライアントの多様性とは何ですか?
バリデーターは、プルーフ・オブ・ステーク ブロックチェーンに参加するコンピューターです。バリデーターは Solana ネットワークのバックボーンであり、トランザクションの処理とコンセンサス プロセスへの参加を担当します。バリデーターは、一定量の Solana のネイティブ トークンを担保としてロックすることでネットワークを保護します。ステーキング トークンは、バリデーターをネットワークに経済的に接続するセキュリティ デポジットと考えることができます。このつながりにより、バリデーターはその貢献に基づいて報酬を得ることができるため、タスクを正確かつ効率的に実行するよう奨励されます。同時に、バリデーターも悪意のある動作や誤動作に対してペナルティを科せられます。バリデーターの資産は不適切な行為により減額されます。このプロセスは減額と呼ばれます。したがって、バリデーターは、自分の賭け金を増やすために自分の義務を正しく遂行するあらゆるインセンティブを持っています。
バリデーター・クライアントは、バリデーターがタスクを実行するために使用するアプリケーションです。クライアントはバリデーターの基礎であり、暗号的に一意の ID を通じてコンセンサスプロセスに参加します。
複数の異なるクライアントがあると、フォールト トレランスが向上します。たとえば、共有の 33% を超える制御を単一のクライアントが存在しない場合、クラッシュや稼働に影響を与えるバグによってネットワークがダウンすることはありません。同様に、クライアントに無効な状態遷移を引き起こすバグがあり、そのクライアントを使用する共有が 33% 未満の場合、ネットワークはセキュリティ障害から保護されます。これは、ネットワークの大部分が有効な状態に留まり、ブロックチェーンの分割やフォークが防止されるためです。したがって、バリデータ クライアントの多様性によってネットワークの回復力が向上し、1 つのクライアントのエラーや脆弱性がネットワーク全体に深刻な影響を与えることはありません。
クライアントの多様性は、各クライアントが実行するステークの割合と利用可能なクライアントの総数によって測定できます。この記事を書いている時点では、Solana ネットワークには 1979 人のバリデーターがいます。メインネット上のこれらのバリデーターによって使用される 2 つのクライアントは、Solana Labs と Jito Labs によって提供されます。 Solana が 2020 年 3 月にローンチされたとき、Solana Labs が開発した検証クライアントを使用していました。 2022 年 8 月に、Jito Labs は 2 番目のバリデーター クライアントをリリースしました。クライアントは、Jito によって保守およびデプロイされた Solana Labs コードのフォークです。クライアントは、ブロック内の最大抽出可能値 (MEV) の抽出を最適化します。 Solana はメモリ プールなしでチャンクをストリーミングするため、Jito のクライアントは擬似メモリ プールを作成します。 mempool は未確認および保留中のトランザクションのキューであることに注意してください。擬似メモリプールを使用すると、バリデーターはこれらのトランザクションを検索し、それらを最適にバンドルして、Jito のブロック エンジンに送信できます。
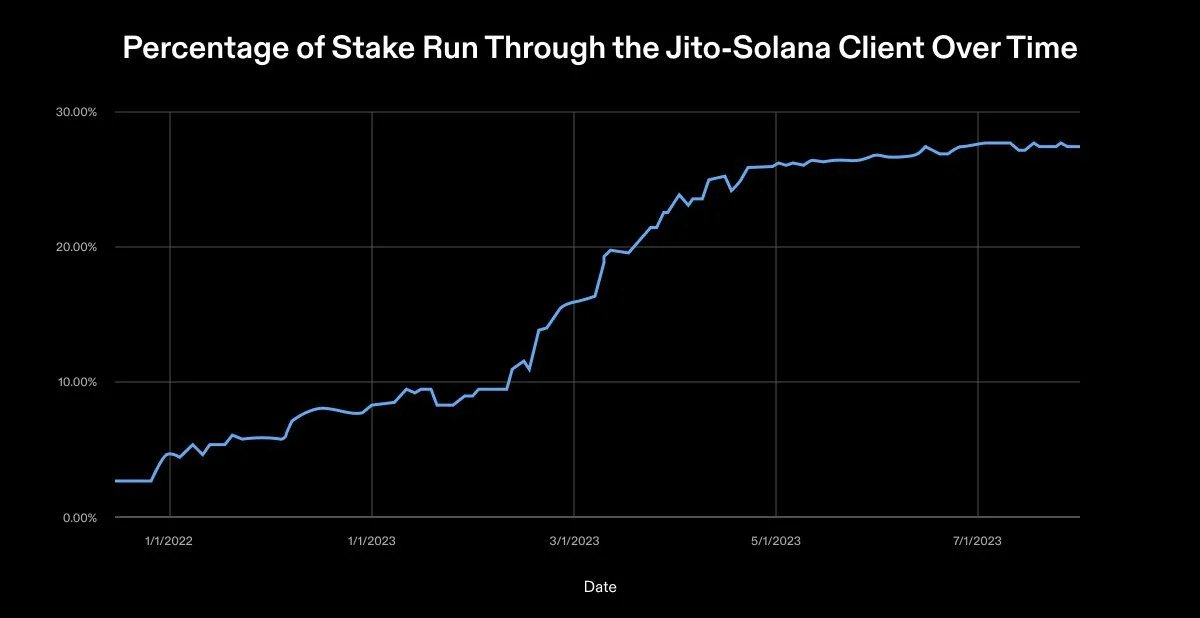
2023年10月現在、Solana Labsの顧客はアクティブステーキングの68.55%を保有し、Jitoは31.45%を保有している。 Jito クライアントを使用するバリデーターの数は、Solana Foundation の以前の健康レポートと比較して 16% 増加しました。 Jito クライアントの使用量の増加は、クライアントの多様化の進化傾向を示しています。
この成長に関するニュースは心強いものですが、完璧ではありません。 Jito のクライアントは Solana Labs クライアントの分岐であることを強調しておく必要があります。これは、Jito が元のバリデータ コードベースと多くのコンポーネントを共有しており、Solana Labs クライアントに影響を与えるバグや脆弱性に対して脆弱になる可能性があることを意味します。理想的な将来では、Solana には少なくとも 4 つの独立したバリデーター クライアントが必要です。さまざまなチームがさまざまなプログラミング言語を使用してこれらのクライアントを構築します。各クライアントが約 25% を保有するため、単一の実装が 33% の株式シェアを超えることはありません。この理想的なセットアップにより、バリデータ スタック全体で単一障害点が排除されます。
2 番目の独立したバリデータ クライアントを開発することは、この将来を実現するために不可欠であり、Jump はそれを実現することに取り組んでいます。
Jump が新しいバリデータ クライアントを構築しているのはなぜですか?
Solana のメインネットは過去 4 回ダウンしており、そのたびに数百人のバリデータによる手動修復が必要でした。この障害は、Solana のネットワークの信頼性に対する懸念を浮き彫りにしました。Jump はプロトコル自体は信頼できると考えており、ダウンタイムの原因はコンセンサスに影響を与えるソフトウェア モジュールの問題にあると考えています。したがって、Jump はこれらの問題を解決するための新しいバリデータ クライアントを開発しています。このクライアントの全体的な目標は、Solana ネットワークの安定性と効率を向上させることです。
スタンドアロンのバリデータ クライアントを開発するのは困難な作業です。ただし、Jump が信頼できるグローバル ネットワークを構築したのはこれが初めてではありません。以前は、証券取引 (株式の売買) は市場の専門家によって手作業で行われていました。電子取引プラットフォームの出現により、証券取引はよりオープンになりました。このオープン性により、競争と自動化が高まり、投資家の取引にかかる時間とコストが削減されます。市場の専門家の間で技術競争が始まりました。
トレーダーは生計を立てるために貿易をします。より良い取引体験を実現するには、ソフトウェア、ハードウェア、ネットワーク ソリューションにさらに重点を置く必要があります。これらのシステムには、高いマシン インテリジェンス、低いリアルタイム レイテンシー、高いスループット、高い適応性、高い拡張性、高い信頼性、および高い説明責任が必要です。
画一的なソリューション (つまり、企業が買い切りできるソフトウェア) は競争上の優位性ではありません。 2番目の取引所に正しい注文を送信すると、損失が大きくなります。高頻度取引分野における熾烈な競争により、クラス最高のグローバル取引インフラを構築するための終わりのない開発サイクルが生まれています。
このシナリオはよく知られているかもしれません。取引システムを成功させるための要件は、ブロックチェーンを成功させるための要件と似ています。ブロックチェーンは、優れたパフォーマンス、強力な耐障害性、低遅延を備えたネットワークである必要があります。遅いブロックチェーンは、現代のエンタープライズ アプリケーションのニーズを満たすことができず、イノベーション、スケーラビリティ、現実世界での有用性を妨げるだけの失敗したテクノロジーです。グローバル ネットワークと高性能システムの開発で 20 年以上の経験を持つ Jump は、独立したバリデータ クライアントを作成するのに最適なチームです。 Jump Trading の最高科学責任者である Kevin Bowers は、構築プロセスを最初から最後まで監督しました。
なぜ光の速度は遅すぎるのでしょうか?
Kevin Bowers は、光が遅すぎるという問題について詳しく説明します。光の速度は有限の定数であり、単一のトランジスタが処理できる計算数に自然な制限が与えられます。現在、ビットはトランジスタを通過する電子によってモデル化されています。シャノンの容量定理は、チャネル上で送信できるエラーのないデータの最大量であり、トランジスタを介して送信できるビット数を制限します。基礎物理学と情報理論の制限により、計算速度は、電子が物質中を移動する速度と送信できるデータの量によって制限されます。スーパーコンピューターを限界まで押し上げると、これらの制約が明らかになります。その結果、「コンピュータのデータ処理能力とそれを送信する能力の間には重大な不一致が存在する」。
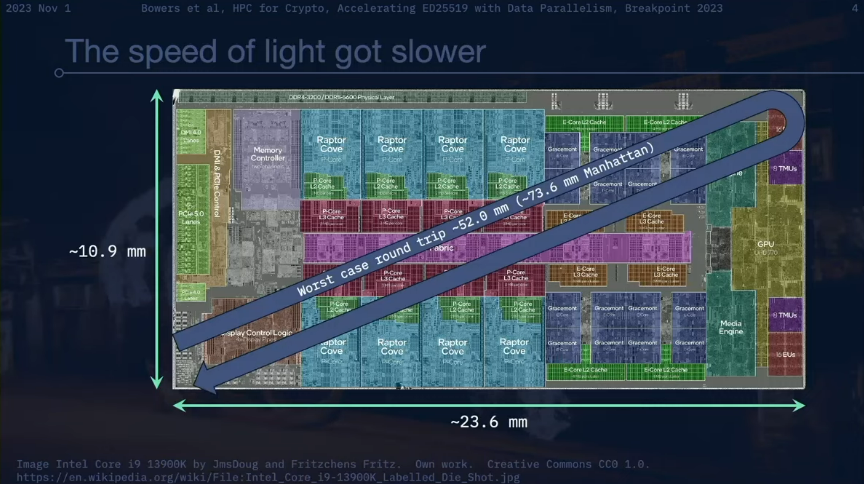
Intel Core i 9 13900 K CPUを例に挙げます。 24 x 86 コアを備え、基本クロック速度は 2.2 GHz、最大ターボ クロック速度は 5.8 GHz です。最悪のシナリオでは、光は CPU 内で合計約 52.0 mm の距離を進む必要があります。 CPU のマンハッタン距離 (つまり、直角の軸に沿って測定された 2 点間の距離) は約 73.6 mm です。 CPU の最大ターボ クロック周波数 5.8 GHz では、光は空気中を約 51.7 mm 移動できます。これは、信号が 1 クロック サイクルで CPU 上のほぼ任意の 2 点間の往復を完了できることを意味します。
しかし、現実ははるかに悪いです。これらの測定では空気中を伝わる光の速度が使用されますが、信号は実際には二酸化ケイ素 (SiO2) を介して送信されます。 5.8 GHz のクロック サイクルで、光は二酸化ケイ素中を約 26.2 ミリメートル進むことができます。シリコン (Si) では、光は 5.8 GHz のクロック サイクルで約 15.0 ミリメートルしか伝わりません。これは、CPU の長辺の半分をわずかに超える長さです。
Firedancer チームは、近年のコンピューティング テクノロジーの進歩は、CPU を高速化するというよりも、より多くのコアを CPU に詰め込むことにあると考えています。より多くのパフォーマンスが必要な場合、より多くのハードウェアを購入することが推奨されます。これは現在、スループットがボトルネックになっている状況で機能します。実際のボトルネックは光の速度です。この自然な制限は意思決定の麻痺につながります。あらゆる種類の最適化と同様、システム内には十分に最適化されていないためにすぐに効果が得られないコンポーネントが数多くあります。最適化されていないパーツは、利用できるコンピューティング リソースが少ないため、時間の経過とともに劣化します。それで、今何をすべきでしょうか?
ハイパフォーマンス コンピューティングでは、すべてが最終的に最適化される必要があります。その結果、地球規模の物理学と情報理論の限界で動作する、量的取引と量的研究を指向した生産システムが生まれました。これには、これらの物理的制約を満たすカスタム ネットワーク スイッチング テクノロジを作成するロックフリー アルゴリズムが含まれます。 Jump はテクノロジー企業であると同時に商社でもあります。 SF と現実の最先端において、現在ジャンプが直面している問題と、ファイアダンサーを開発しているソラナの間には驚くべき類似点があります。
ファイヤーダンサーとは何ですか?
Firedancer は、Firedancer チームによって C 言語で開発された新しいスタンドアロン検証クライアントです。 Firedancer は、モジュール式アーキテクチャ、最小限の依存関係、および広範なテスト プロセスを使用して、信頼性を念頭に置いて設計されています。これは、Solana Labs クライアントの 3 つの機能コンポーネント (ネットワーク、ランタイム、コンセンサス) の大幅な書き換えを提案しています。各レベルは最大のパフォーマンスが得られるように最適化されているため、クライアントの実行能力は検証ハードウェアによってのみ制限され、現在直面しているソフトウェアの非効率性によって引き起こされるパフォーマンスの制限によって制限されることはありません。 Firedancer を使用すると、Solana は帯域幅とハードウェアに基づいて拡張できるようになります。
Firedancer の目標は次のとおりです。
Solana プロトコルを文書化して標準化します (最終的には、Rust バリデーター コードではなくドキュメントを参照して Solana バリデーターを作成できるようになります)。
バリデータクライアントの多様性を高めます。
エコシステムのパフォーマンスを向上させます。
ファイヤーダンサーの仕組み
モジュラーアーキテクチャ
Firedancer は、独自のモジュラー アーキテクチャを通じて、現在の Solana バリデータ クライアントとは異なります。単一プロセスとして実行される Solana Labs の Rust 検証クライアントとは異なり、Firedancer は「タイル」と呼ばれる多数の独立した Linux C プロセスで構成されています。タイルはプロセスとメモリです。このタイル アーキテクチャは、Firedancer の運用哲学と堅牢性と効率性を向上させるアプローチの基礎です。
プロセスは、実行中のプログラムのインスタンスです。これは最新のオペレーティング システムの基本コンポーネントであり、一連の命令の実行を表します。各プロセスには独自のメモリ空間とリソースがあり、オペレーティング システムは他のプロセスの影響を受けることなく、これらのリソースを独立して割り当てて管理します。プロセスは、大きな工場の独立した作業員のようなもので、独自のツールとワークスペースを使用して特定のタスクを処理します。
Firedancer では、各タイルは特定の役割を持つ独立したプロセスです。たとえば、QUIC タイルは、受信 QUIC トラフィックを処理し、カプセル化されたトランザクションを検証タイルに転送する役割を果たします。検証タイルは署名検証を担当し、他のタイルにも同様のタスクがあります。これらのタイルは独立して同時に実行され、システム全体の機能を構成します。独立した Linux プロセスは、小規模で独立したフォールト ドメインを形成できます。これは、1 つのタイルの問題が、バリデーター全体を直ちに危険にさらすことなく、システム全体に最小限の影響、つまり小さな「影響範囲」を与えるだけであることを意味します。
Firedancer アーキテクチャの主な利点は、ダウンタイムなしで各タイルを数秒で交換およびアップグレードできることです。これは、Solana Labs の Rust 検証クライアントをアップグレードする前に完全にシャットダウンする必要があるという要件とは対照的です。この違いは、Rust には ABI (Application Binary Interface) の安定性がないことが原因であり、純粋な Rust 環境ではオンザフライ アップグレードが妨げられます。 C プロセスのアプローチでは、C ランタイム モデルのバイナリの安定性を利用して、アップグレード関連のダウンタイムを大幅に削減できます。これは、個々のタイルが異なるワークスペースでバリデーターの状態を管理するためです。これらの共有メモリ オブジェクトは、バリデーターの電源がオンになって実行されている限り存続します。再起動またはアップグレード中に、各タイルは中断したところからシームレスに再開できます。
全体として、Firedancer は NUMA 対応のタイルベースのアーキテクチャに基づいて構築されています。このアーキテクチャでは、各タイルが 1 つの CPU コアを使用します。タイル間の高性能メッセージングを特徴とし、メモリの局所性、リソース レイアウト、コンポーネントの遅延を最適化します。
ネットワーク処理
Firedancer のネットワーク処理は、ギガビット/秒の速度にアップグレードされる Solana ネットワークの激しい要求に対処できるように設計されています。このプロセスは、インバウンドアクティビティとアウトバウンドアクティビティに分かれています。
インバウンド活動では主にユーザーからのトランザクションの受け取りが行われます。バリデーターによるパケットの処理が遅れると、コンセンサス メッセージが失われる可能性があるため、Firedancer のパフォーマンスは非常に重要です。 Solana ノードは現在約 0.2 Gbps で動作していますが、Jump ノードは約 40 GBps の最大帯域幅ピークを記録しています。この帯域幅の急増は、堅牢でスケーラブルな受信処理ソリューションの必要性を浮き彫りにしています。
アウトバウンドアクティビティには、ブロックのパッキング、ブロックの作成、シャードの送信が含まれます。これらの手順は、Solana ネットワークを安全かつ効率的に運用するために重要です。これらのタスクのパフォーマンスは、スループットだけでなく、ネットワーク全体の信頼性にも影響します。
Firedancer は、トランザクションを処理するためのポイントツーポイント インターフェイスを使用して、Solana の過去の問題を解決することを目指しています。これまでの Solana ポイントツーポイント インターフェイスの重大な欠点は、受信トランザクションを処理する際の輻輳制御が欠如していることでした。この欠陥により、2021 年 9 月 14 日 (17 時間) と 2022 年 4 月 30 日 (7 時間) に障害が発生しました。
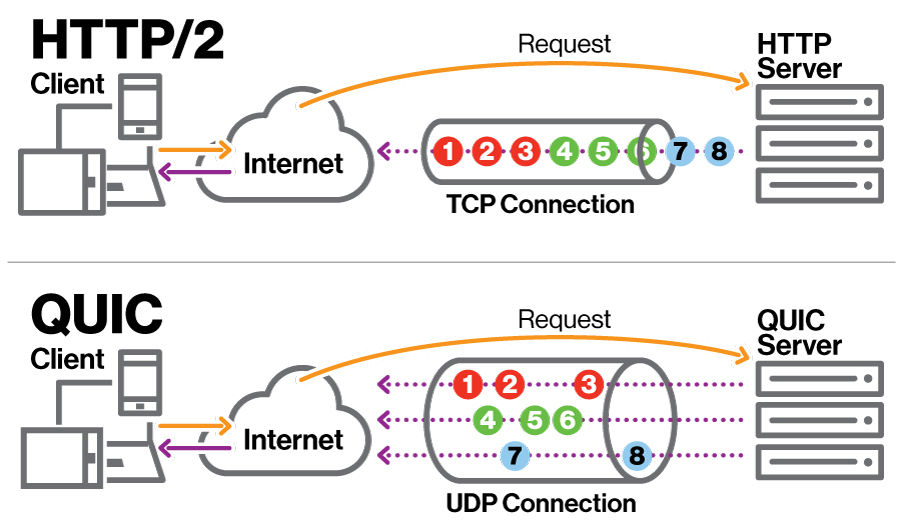
これに応じて、Solana は、高いトランザクション負荷を適切に処理するために、ネットワークをいくつかアップグレードしました。 Firedancer もこれに倣い、交通管制方式として QUIC を採用しました。QUIC は、HTTP/3 の基礎となる多重化トランスポート ネットワーク プロトコルです。DDoS 攻撃からの防御とネットワーク トラフィックの管理において重要な役割を果たします。ただし、場合によってはコストがメリットを上回る場合があることに注意することが重要です。 QUIC は、DDoS 攻撃を軽減するために専用のデータセンター ハードウェアと組み合わせて使用され、トランザクション フラッディング攻撃の誘因を排除します。
QUIC の 151 ページの仕様は、開発にかなりの複雑さをもたらします。ライセンス、パフォーマンス、信頼性のニーズを満たす既存の C ライブラリが見つからなかったので、Firedancer チームは独自の実装を構築しました。 Firedancer の QUIC 実装 (fd_quic という愛称) は、最適化されたデータ構造とアルゴリズムを導入して、メモリ割り当てを最小限に抑え、メモリの枯渇を防ぎます。
Firedancer のカスタム ネットワーク スタックは、その処理能力の中心です。このスタックは、Receive Side Scaling (RSS) を活用するためにゼロから設計されました。 RSS は、ネットワーク トラフィックをさまざまな CPU コアに分散してネットワーク処理の並列性を高める、ハードウェア アクセラレーション形式のネットワーク負荷分散です。各 CPU コアは、追加のオーバーヘッドをほとんど発生させずに、受信トラフィックの一部を処理します。このアプローチは、複雑なスケジューラ、ロック、アトミック操作を排除することで、従来のソフトウェアベースの負荷分散よりも優れたパフォーマンスを発揮します。
Firedancer は、高性能タイル アプリケーションを構成するための新しいメッセージング フレームワークを導入します。これらのタイルは、高性能パケット処理用に最適化されたアドレス ファミリである AF_XDP を利用することで、ソケット ベースのカーネル ネットワークの制限を回避できます。 AF_XDP を使用して、Firedancer がネットワーク インターフェイス バッファからデータを直接読み取ることができるようにします。
このタイル システムは、Firedancer スタック内に次のようなさまざまなハイ パフォーマンス コンピューティングの概念を実装します。
NUMA Aware - NUMA (Non-Uniform Memory Access) は、プロセッサが他のプロセッサに関連付けられたメモリにアクセスするよりも速く独自のメモリにアクセスするコンピュータ メモリ設計です。 Firedancer の場合、NUMA 対応であるということは、クライアントがマルチプロセッサ構成でメモリを効率的に処理できることを意味します。これは、利用可能なハードウェア リソースの使用率を最適化するため、大量のトランザクションを処理する場合に重要です。
キャッシュの局所性 - キャッシュの局所性とは、プロセッサー近くのキャッシュに既に格納されているデータを利用することを指します。これは通常、時間的局所性 (つまり、最も最近アクセスされたデータ) の変形です。 Firedancer では、キャッシュの局所性に重点を置いており、レイテンシーを最小限に抑え、速度を最大限に高めながらネットワーク データを処理するように設計されています。
ロックフリーの同時実行 - ロックフリーの同時実行とは、同時操作を管理するためにロック メカニズム (ミューテックスなど) を必要としないアルゴリズムを設計することを指します。 Firedancer では、ロックフリーの同時実行により、ロックによる遅延なく複数のネットワーク操作を並行して実行できます。ロックフリーの同時実行性により、Firedancer の大量のトランザクションを同時に処理する能力が強化されます。
大きなページ サイズ - メモリ管理で大きなページ サイズを使用すると、データ セットの処理が容易になり、ページ テーブルの検索と潜在的なメモリの断片化が減少します。 Firedancer にとって、これはメモリ処理効率の向上を意味します。これは、大量のネットワーク データを処理する場合に非常に役立ちます。
ビルドシステム
Firedancer のビルド システムは、信頼性と一貫性を確保するための一連の指針に従っています。外部依存関係を最小限に抑えることに重点を置き、ビルド プロセスに関与するすべてのツールを依存関係として扱います。これには、すべての依存関係 (コンパイラーを含む) を正確なバージョンに固定することが含まれます。このシステムの重要な点は、ビルド ステップ中の環境分離です。環境分離により、ビルド プロセスがシステム環境の影響を受けないため、移植性が向上します。
ファイアダンサーが速い理由
高度なデータ並列処理
Firedancer は、ED 25519 署名検証などの暗号化タスクにおいて、最新のプロセッサー内で利用可能な高度なデータ並列処理を活用します。最新の CPU には、複数のデータ要素を同時に処理するための単一命令複数データ (SIMD) 命令と、CPU サイクルごとに複数の命令の実行を最適化する機能があります。多くの場合、データ要素の配列またはベクトルに対して 1 つの命令を並列処理する方が、面積、時間、電力の点でより効率的です。ここで、並列データ処理の改善は、純粋な処理速度の改善と比較して、スループットの改善に影響を与える可能性があります。
Firedancer がデータ並列処理を使用する領域の 1 つは、計算による署名検証の最適化です。このアプローチにより、配列またはベクトル内のデータ要素を同時に処理して、スループットを最大化し、待ち時間を最小限に抑えることができます。 ED 25519 実装の中核はガロア体の演算です。この形式の算術演算は、暗号アルゴリズムとバイナリ計算に適しています。ガロア体では、加算、減算、乗算、除算などの演算が、コンピュータ システムのバイナリの性質に基づいて定義されます。 2^3 で定義されたガロア体の例を次に示します。
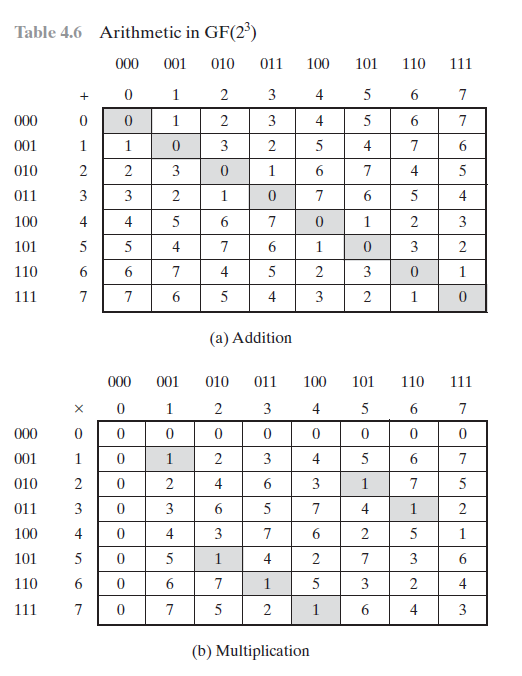
唯一の問題は、ED 25519 が 2^(255-19) で定義されるガロア体を使用していることです。ドメイン要素は 0 から 2^(255-19) までの数値と考えることができます。基本的な操作は次のとおりです。

加算、減算、乗算は、ほぼ uint 256 _t 数学 (つまり、最大値が 2^(256-1) である符号なし整数を使用した計算) です。除算の計算は困難です。一般的な CPU と GPU は、uint 256 _t 数学はおろか、サポートしていません。信じられないほど難しい除算は言うまでもなく、ほとんど uint 256 _t math です。この数学を実装してパフォーマンスを向上させることが重要な問題であり、これはこの数学をどれだけうまくシミュレートできるかにかかっています。

Firedancer の実装は、数値をより柔軟に処理することで算術演算を分解します。通常の長い除算と乗算の原理を適用して、ある列から次の列に数値を運ぶと、列を並列処理できます。この計算をシミュレートする最も速い方法は、uint 256 _t を 9 ビットの「キャリー」を含む 6 つの 43 ビット数値として表すことです。これにより、キャリー ビットに十分なスペースを確保しながら、既存の 64 ビット操作を CPU 上で実行できるようになります。この数値の配置により、頻繁なキャリー伝播の必要性が減り、Firedancer が大きな数値をより効率的に処理できるようになります。
この実装では、算術計算を並列化された列の合計に再編成することにより、データの並列性を利用します。列を並列処理すると、順次ボトルネックになる可能性のあるタスクが並列化可能なタスクに変わるため、全体の計算を高速化できます。 Firedancer は、AVX 512 およびその IFMA 拡張機能 (AVX 512-IFMA) などのベクトル化された命令セットも使用します。これらの命令セットにより、前述のガロア体の演算処理が可能になり、速度と効率が向上します。
Firedancer の AVX 512 アクセラレーションの実装は非常に高速です。単一の 2.3 GHz Icelake サーバー コアでは、コアあたりのクロック パフォーマンスは 2022 Breakpoint デモの 2 倍以上です。この実装は、100% のベクトル チャネル使用率と大規模なデータ並列処理を特徴としています。これは、光速レイテンシのおかげで、たとえカスタム ハードウェアを使用していても、一度に 1 つのことを実行するよりも、独立した並列タスクを同時に実行する方がはるかに簡単であるという、Firedancer チームによるもう 1 つの素晴らしいデモンストレーションです。
FPGAとの高速ネットワーク通信を可能にする
CPU は、コアごとに 1 秒あたり約 30,000 件の署名検証を処理できます。これらはエネルギー効率の高いオプションですが、大規模な運用には欠点があります。この制限は、逐次処理アプローチに起因しています。 GPU は、この処理能力を 1 コアあたり 1 秒あたり約 100 万回の検証にまで高めます。ただし、ユニットあたり約 300 W を消費し、バッチ処理により固有の遅延が発生します。
FPGA がより良い選択肢になります。これらは GPU のスループットに匹敵しますが、消費電力は大幅に少なく、FPGA あたり約 50 W です。レイテンシーも GPU の 10 ミリ秒のレイテンシーよりも低くなります。 FPGA は、約 200 マイクロ秒の遅延で、より応答性の高いリアルタイム処理ソリューションを提供します。 GPU のバッチ処理とは異なり、Firedancer の FPGA はストリーミング形式で各トランザクションを個別に処理します。 Firedancer が FPGA を使用した結果、消費電力は 400 W 未満で、8 つの FPGA で 1 秒あたり 800 万の署名を処理できます。
チームは、Breakpoint 2022 で Firedancer の ED 25519 署名検証プロセスをデモンストレーションしました。このプロセスには、純粋な RTL パイプラインでの SHA-512 計算や、カスタム ECC-CPU プロセッサ パイプラインでのさまざまなチェックと計算など、複数の段階が含まれます。基本的に、Firedancer チームはカスタム プロセッサ用のコンパイラとアセンブラを作成し、RFC (コメント要求) から Python コードを取得し、オペレータ オーバーロード オブジェクトを使用してマシン コードを生成し、そのマシン コードを ECC -On に置きました。 CPU。

特に、Firedancer は AWS アクセラレータのフォームファクタ スタイルを採用して、堅牢性とネットワーク接続性のバランスをとっています。このオプションは、クラウド プロバイダー間で制限されることが多い機能である直接ネットワーク接続に関連する課題を解決します。この選択により、Firedancer はその高度な機能をクラウド インフラストラクチャの制約内でシームレスに統合できるようになります。
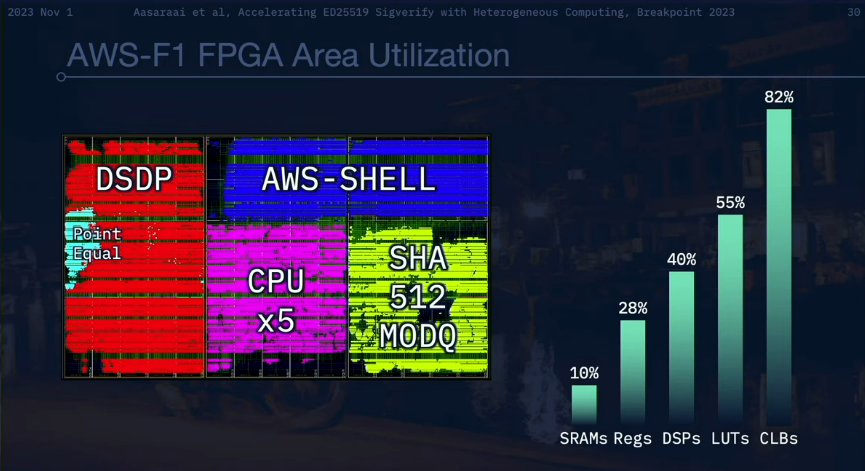
さまざまな操作には、概念的なデータ空間だけではなく、実際の物理空間が必要であることを認識する必要があります。 Firedancer は、物理コンポーネントの位置を戦略的に配置して、コンポーネントをコンパクトにして再利用できるようにすることで機能します。この構成により、Firedancer は FPGA の効率を最大化することができ、8 年前のマシンで 7 年前の FPGA を使用して 1 秒あたり 800 万トランザクションを達成しました。
ネットワーク通信における根本的な課題は、新しいトランザクションを世界中にブロードキャストすることです
インターネットのポイントツーポイントの性質、帯域幅の制限、遅延の問題により、ネットワークを使用した直接ブロードキャストなどの従来の方法の実現可能性が制限されています。リングまたはツリー構造でデータを分散すると、これらの問題は部分的に解決されますが、送信中にパケットが失われる可能性があります。
リードソロモン符号化は、これらの問題に対する推奨される解決策です。これは、失われたパケットを回復するためにデータ送信の冗長性 (つまり、パリティ情報) を導入します。基本的な概念は、2 つの点で直線を定義でき、この直線上の任意の 2 点で元のデータ点を再構築できるということです。データ ポイントに基づいて多項式を構築し、この関数のさまざまなポイントを別々のパケットに分散することにより、受信機が少なくとも 2 つのパケットを受信する限り、元のデータを再構築できます。
直線上の点 (y = mx + b) に従来の公式を使用すると計算に時間がかかるため、多項式を作成します。 Firedancer は、ラグランジュ多項式 (多項式構築に特化した方法) を使用して処理を高速化します。これにより、リードソロモン符号化に必要な多項式の作成が簡素化されます。また、プロセスを高次多項式のより効率的な行列とベクトルの乗算に変換します。このマトリックスは高度に構造化されており、パターンの最初の行が完全に決定するような再帰的なパターンが含まれています。この構造は、乗算計算をより高速に実行する方法があることを意味します。 Firedancer は O(n log n) メソッドを使用します。これは、乗算にこの行列を使用する方法に関する 2016 年の記事で説明されています。これは、現在知られているリードソロモン エンコードの理論上の最速の方法です。その結果、従来の方法と比較して非常に効率的にパリティ情報を計算できる方法が得られます。
コアあたり 120 Gbps 以上の RS エンコーディング速度。
RS デコード速度はコアあたり最大 50 Gbps。
これらのメトリクスは、現在の最大 8 Gbps/コア RS エンコーディング (rust-rse) と比較されます。
この最適化されたリードソロモン符号化方式を使用することで、Firedancer は従来の方式より 14 倍速くパリティ情報を計算できます。これにより、データのエンコードとデコードのプロセスが高速かつ信頼性が高く、世界中で高スループットと低遅延を維持するために重要になります。
ファイアダンサーはどうやって安全を保っているのでしょうか?
チャンス
現在、すべてのバリデーターは、元のバリデーター クライアントに基づくソフトウェアを使用しています。 Firedancer が Solana Labs の顧客と異なる場合、Firedancer は Solana の顧客とサプライチェーンの多様性を改善する可能性があります。これには、同様の依存関係の使用や、Rust を使用したクライアントの開発が含まれます。
Solana Labs と Jito バリデータ クライアントは別のプロセスとして実行されます。モノリシック アプリケーションが実稼働環境で実行されると、そのアプリケーションにセキュリティを追加するのは困難になります。これらのクライアントを実行しているバリデーターは、純粋な Rust にセキュリティを即時にアップグレードするためにシャットダウンする必要があります。 Firedancer チームは、最初からセキュリティ アーキテクチャを組み込んだ新しいクライアントを開発することができました。
Firedancer には、過去の経験から学ぶという利点もあります。 Solana Labs は、スタートアップ環境でバリデータ クライアントを開発しました。このペースの速い環境は、ラボが迅速に市場に投入するために迅速に行動する必要があることを意味します。これは、彼らの将来の発展の見通しを懸念させます。 Firedancer チームは、Labs が何をしてきたか、また他のチェーンのチームが何をしてきたかを見て、バリデータ クライアントを最初から開発できたらどう違うだろうかと尋ねることができます。
チャレンジ
Solana Labs のクライアントとは異なりますが、Firedancer はその動作を厳密に再現する必要があります。これを行わないと、整合性エラーが発生し、セキュリティ リスクになる可能性があります。この問題は、共有の一部を両方のクライアントで実行するよう奨励し、Firedancer の合計シェアを長期間にわたって合計シェアの 33% 未満に保つことで軽減できます。いずれにせよ、Firedancer チームは、実装の難しさや安全性に関係なく、プロトコルのすべての機能セットを実装する必要があります。すべてが Firedancer と一致している必要があります。したがって、チームは単独でコードを開発することはできず、Labs クライアントの機能と照らし合わせてコードをレビューする必要があります。これは、仕様とドキュメントの欠如によってさらに悪化します。つまり、Firedancer はプロトコルに非効率な構造を導入しなければなりません。
Firedancer チームは、新しいクライアントを C で開発していることも認識する必要がありました。 C 言語は、Rust などの言語のようにメモリの安全性をネイティブに保証しません。 Firedancer コードベースの主な目的は、メモリの安全性の脆弱性の発生と影響を軽減することです。 Firedancer はペースの速いプロジェクトであるため、この目標には特別な注意が必要です。 Firedancer は、そのようなバグを発生させずに開発速度を維持する方法を見つけなければなりません。オペレーティング システムのサンドボックス化は、タイルをオペレーティング システムから分離する方法です。タイルは、リソースにアクセスし、その作業に必要なシステム コールを実行することのみが許可されます。 Tile には明確に定義された目的があり、Firedancer チームは主にクライアント側のコードを開発するため、Tile の権限は最小特権の原則に基づいて剥奪されます。
多層防御設計を実装する
すべてのソフトウェアには、ある時点でセキュリティ上の脆弱性が存在します。ソフトウェアにはバグがあるという前提から、Firedancer は 1 つの脆弱性による潜在的な影響を制限することを選択します。このアプローチは多層防御と呼ばれます。多層防御は、さまざまなセキュリティ対策を使用して資産を保護する戦略です。攻撃者がシステムの一部を侵害した場合、その脅威がシステム全体に影響を与えることを防ぐための追加の対策が存在します。
Firedancer は、脆弱性と悪用の段階の間のリスクを軽減するように設計されています。たとえば、メモリの安全性の脆弱性は、攻撃者にとって悪用するのが困難です。これは、この種の攻撃を防ぐことは十分に研究されている問題だからです。 C では、メモリの安全性に関する集中的な研究により、チームが Firedancer で使用した一連の強化技術とコンパイラ機能が生まれました。たとえ攻撃者が業界のベストプラクティスを回避できたとしても、脆弱性を悪用してシステムを侵害することは困難です。これは、タイルの分離とオペレーティング システムのサンドボックスの存在によるものです。
タイルの分離は、Firedancer の並列アーキテクチャの結果です。各タイルは独自の Linux プロセスで実行されるため、明確な単一の目的があります。たとえば、QUIC タイルは、受信 QUIC トラフィックを処理し、カプセル化されたトランザクションを検証タイルに転送する役割を果たします。検証タイルは署名検証を担当します。 QUIC タイルと検証タイル間の通信は、共有メモリ インターフェイスを通じて行われます (つまり、Linux プロセスは相互にデータを受け渡すことができます)。 2 つのタイル間の共有メモリ インターフェイスは、分離境界として機能します。 QUIC タイルに悪意のある QUIC パケットの処理時に攻撃者が任意のコードを実行できるバグが含まれている場合でも、他のタイルには影響しません。単一のプロセスでは、これは直ちに侵害につながる可能性があります。攻撃者がこの脆弱性を悪用して複数のバリデータをターゲットにした場合、ネットワーク全体に損害を与える可能性があります。攻撃者が QUIC タイルのパフォーマンスを低下させる可能性はありますが、Firedancer の設計により、これは QUIC タイルに限定されます。
オペレーティング システムのサンドボックス化は、タイルをオペレーティング システムから分離する方法です。タイルは、リソースにアクセスし、その作業に必要なシステム コールを実行することのみが許可されます。 Tile には明確に定義された目的があり、そのコードのほぼすべてが Firedancer チームによって開発されているため、Tile の権限は最小特権の原則に基づいて最小限に制限されています。タイルは独自の Linux 名前空間に配置され、システムの限定的なビューを提供します。この狭いビューにより、Tile はほとんどのファイル システム、ネットワーク、および同じシステム上で実行されているその他のプロセスにアクセスできなくなります。名前空間は、セキュリティ第一の境界を提供します。ただし、攻撃者が特権を昇格させるカーネルの脆弱性を持っている場合、この分離はバイパスされる可能性があります。システム コール インターフェイスは、タイルから到達可能なカーネル内の最後の攻撃ベクトルです。これを防ぐために、Firedancer は seccomp-BPF を使用して、システム コールがカーネルによって処理される前にフィルタリングします。クライアントは、タイルを選択したシステム コールのセットに制限できます。場合によっては、システム コールのパラメータをフィルタリングすることができます。 Firedancer は読み取りおよび書き込みシステム コールが特定のファイル記述子に対してのみ動作することを保証するため、これは重要です。
組み込みのセキュリティ プランを採用する
Firedancer の開発中、あらゆる段階で包括的な安全手順を組み込むことに注意が払われました。クライアントのセキュリティ プログラムは、開発チームとセキュリティ チーム間の継続的なコラボレーションの成果であり、安全なブロックチェーン テクノロジーの新しい標準を設定します。
このプロセスは、セルフサービスのファズ テスト インフラストラクチャから始まります。ファズ テストは、脆弱性を示すクラッシュやエラー状態を自動的に検出する技術です。ファズ テストは、P2P インターフェイス (パーサー) や SBPF 仮想マシンなど、信頼できないユーザー入力を受け入れるすべてのコンポーネントをストレス テストすることによって実行されます。 OSS-Fuzz は、コード変更中に継続的なファズ カバレッジを維持します。セキュリティ チームは、継続的なカバレッジに基づくファズ テストのために、専用の ClusterFuzzer インスタンスもセットアップしました。開発者とセキュリティ エンジニアは、ファズ テスト (つまり、セキュリティ クリティカルなコンポーネントの特別なバージョンに対する単体テスト) 用のツールも提供します。開発者は、自動的に受信されてテストされる新しいファズ テストを提供することもできます。目標は、次の段階に進む前に、すべての部品を完全にファジング テストすることです。
内部コードのレビューは、ツールが見逃す可能性のある脆弱性を発見するのに役立ちます。現段階では、リスクが高く影響の大きいコンポーネントに重点が置かれています。この段階は、セキュリティ プログラムの他の部分にフィードバックを提供するフィードバック メカニズムです。チームは、これらのレビューで学んだすべての教訓を適用して、ファズ テストの範囲を改善し、特定の脆弱性クラスに対する新しい静的分析チェックを導入し、さらには複雑な攻撃ベクトルを排除するために大規模なコード リファクタリングを実装します。外部のセキュリティ レビューは、発売前と発売後の両方で、業界をリードする専門家とアクティブなバグ報奨金プログラムによって補完されます。
Firedancer は、さまざまなテスト ネットワークで広範なストレス テストも受けています。これらのテスト ネットワークは、ノードの重複、ネットワーク リンクの障害、パケット フラッディング、コンセンサス違反などのさまざまな攻撃や障害にさらされます。これらのネットワークが耐える負荷は、メインネットでの現実的な負荷をはるかに超えています。
そこで疑問が生じます: Firedancer の現在の状況は何ですか?
ファイヤーダンサーの現在はどうなっているのか、フランケンダンサーとは何なのか?
Firedancer チームは、バリデータ クライアントをモジュール化するために Firedancer を徐々に開発しています。これは、文書化と標準化の目標と一致しています。このアプローチにより、Firedancer は Solana の最新の開発状況を常に最新の状態に保つことができます。これがフランケンダンサーの誕生につながりました。 Frankendancer は、Firedancer チームが開発したコンポーネントを既存のバリデーター クライアント インフラストラクチャに統合するハイブリッド クライアント モデルです。この開発プロセスにより、段階的な改善と新機能のテストが可能になります。
フランケンダンサーは、交通の真ん中にスポーツカーを置くようなものです。より多くのコンポーネントが開発され、ボトルネックが解消されるにつれて、パフォーマンスは向上し続けます。このモジュール式開発プロセスにより、カスタマイズ可能で柔軟なバリデーター環境が容易になります。ここで、開発者はニーズに応じてバリデータークライアントの特定のコンポーネントを変更または置き換えることができます。
実際に動作するもの
Frankendancer は、Solana バリデーターのすべてのネットワーク機能を実装します。
インバウンド: QUIC、TPU、Sigverify、Dedup
アウトバウンド: ブロック パッキング、シュレッドの作成/署名/送信 (タービン)
Frankendancer は、Solana Labs の Rust ランタイムおよびコンセンサス コードに加えて、Firedancer の高性能 C ネットワーキング コードを使用します。
Frankendancer のアーキテクチャ設計は、ハイエンド ハードウェアの最適化に重点を置いています。標準の Linux オペレーティング システムを実行するローエンドのクラウド ホストをサポートしていますが、Firedancer チームはコア数の多いサーバー向けに Frankendancer を最適化しています。長期的な目標は、クラウド内の既存のハードウェア リソースを活用して効率とパフォーマンスを向上させることです。クライアントは、複数の同時接続、ハードウェア アクセラレーション、負荷分散のためのランダム化されたトラフィック ステアリング (ネットワーク トラフィックの均一な分散を保証)、およびコンポーネント間の追加のセキュリティを提供する複数のプロセス境界をサポートします。
技術効率はフランケンダンサーの基礎です。システムは、クリティカル パスでのメモリ割り当てとアトミック操作を回避し、すべての割り当ては初期化時に NUMA で最適化されます。この設計により、最大限の効率とパフォーマンスが保証されます。さらに、システム コンポーネントを非同期かつリモートで検査できる機能と、タイルの柔軟な管理 (非同期開始、停止、再起動) により、システムに堅牢性と適応性の層が追加されます。
フランケンダンサーはどうなるのでしょうか?
Frankendancer の各タイルは、ネットワークの受信側で 1 秒あたり 1,000,000 トランザクション (TPS) を処理できます。各タイルは 1 つの CPU コアを使用するため、パフォーマンスは使用されるコアの数に比例して増加します。 Frankendancer は、4 つのコアのみを使用し、各コアの 25 Gbps ネットワーク インターフェイス カード (NIC) を最大限に活用することでこの偉業を達成します。
ネットワークのアウトバウンド操作に関しては、Frankendancer はタービンの最適化により大幅な改善を達成しました。現在の標準ノード ハードウェアは、タイルあたり 6 Gbps の速度を達成します。これには、シャーディング (つまり、データのブロックが分割されてバリデーター ネットワークに送信される方法) における大幅な速度の向上が含まれます。現在の標準的な Solana ノードと比較して、Frankendancer はマークル ツリーを使用しない場合に約 22% のシャーディング速度向上を示し、マークル ツリーを使用するとほぼ 2 倍になります。これは、現在のバリデーター ブロックの伝播とトランザクション受信のパフォーマンスに比べて大幅に向上しています。
Firedancer のネットワーク パフォーマンスは、ハードウェアの限界に達し、今日の標準的なバリデータ ハードウェアと比較して最大のパフォーマンスを達成していることを示しています。これは重要なテクノロジーのマイルストーンであり、極端なワークロードを効果的かつ効率的に処理できるクライアントの能力を示しています。
Frankendancer がテストネットで起動されました
Frankendancer は現在、テスト ネットワーク上でブロックをステーキング、投票、生成しています。 Solana Labs や Jito、その他約 2900 のバリデーターと互換性があります。この現実世界の展開は、コモディティ ハードウェアにおける Firedancer のパワーを実証しています。現在、AMD EPYC 7513 CPU を搭載した Equinix Metal m 3.large.x 86 サーバーにデプロイされています。他の多くのバリデーターも同じタイプのサーバーを使用しています。手頃な価格のソリューションを提供しており、オンデマンド料金は 1 時間あたり 3.10 ドルから 4.65 ドルの範囲で、場所によって異なります。
メインネットの立ち上げに向けた Firedancer の進歩により、ノード ハードウェアにいくつかの可能性が開かれます。
現在のバリデーター ハードウェアにより、ノードごとのパフォーマンス能力が向上します。
Firedancer の効率性により、バリデーターは同等のパフォーマンス レベルを維持しながら、より手頃な価格の低スペックのハードウェアを使用できるようになります。
Firedancer は、ハードウェアと帯域幅の進歩を活用するように設計されています。
これらの開発は、Wiredancer (Firedancer チームによるハードウェア アクセラレーションの実験) や Rust ベースのモジュラー ランタイム/SVM などの他の取り組みと合わせて、Firedancer を先進的なソリューションにしています。
Firedancer の進歩は、並列実行として知られる Firedancer と並行してバリデーターに Solana Labs クライアントを実行させるかどうかについての議論も引き起こしました。このアプローチでは、両方のクライアントの長所を活用し、どちらかのクライアントがネットワーク全体に及ぼす潜在的な影響を軽減することで、ネットワーク アクティビティを最大化します。さらに、これにより、Jito のようなプロジェクトが Firedancer のフォークを検討するかどうかについての憶測が生まれました。これにより、MEV 抽出とトランザクション処理の効率がさらに最適化される可能性があります。時間だけが教えてくれます。
結論は
開発者は、操作を物理的なスペースではなくデータ スペースを占有するものと考えることがよくあります。光の速度が自然な制限であるため、この仮定によりシステムは遅くなり、ハードウェアを適切に最適化できなくなります。非常に敵対的で競争の激しい環境では、Solana にハードウェアを追加するだけでパフォーマンスが向上することを期待することはできません。最適化する必要があります。 Firedancer は、バリデータ クライアントの構造と操作に革命をもたらします。 Firedancer チームは、信頼性が高く、高度にモジュール化されたパフォーマンスの高い検証クライアントを構築することで、Solana の大量導入に備えています。
あなたが若手開発者であっても、通常の Solana ユーザーであっても、Firedancer とその意味を理解することが重要です。この技術的偉業により、市場で最速かつ最高のパフォーマンスを誇るブロックチェーンがさらに優れたものになります。 Solana は、高スループット、低遅延のグローバル ステート マシンとして設計されています。 Firedancer は、これらの目標を達成するための大きな一歩です。


