
AI モデルは大きいほど良いのではありませんか?モデルの「ダウンサイジング」技術ソリューションの包括的な分析
ChatGPTをきっかけに大規模モデルが世界的に盛り上がり、インターネット企業も「百モデル戦争」に陥り「巻き込まれる」ことも:各社がリリースする大規模モデルはますます巨大化し、パラメータ規模も増大そのほとんどすべてが数百億、数千億、場合によっては兆を超える規模です。
しかし、この現状は持続可能な開発アプローチではないと主張する人もいます。 OpenAIの創設者サム・アルトマン氏は、GPT-4の開発コストは1億ドルを超えたと述べ、Analytics India Magazineが発行したレポートによると、OpenAIは人工知能サービスChatGPTの実行に1日あたり約70万ドルを費やすことになるという。同時に、LLM は電力消費に関する懸念も引き起こしており、Google の報告によると、トレーニング用の PaLM は約 2 か月で約 3.4 キロワット時を消費しました。これは、米国の一般家庭約 300 軒の年間エネルギー消費量に相当します。
したがって、モデルのサイズは増大し続けるため、HuggingFace のチーフ エバンジェリストである Julien Simon 氏は、「小さいほど良い」と述べています。実際、パラメータのスケールが一定のレベルに達すると、パラメータを追加してもモデルの効果が大幅に改善されないことがよくありますが、実用性と経済性の観点から、モデルの「スリム化」は避けられない選択です。スケールによる限界利益や、リソース消費による莫大なコストは、多くの場合、価値がありません。また、大規模なモデルは規模が大きいため、エッジデバイスにデプロイできず、クラウドでしかユーザーにサービスを提供できないなど、アプリケーションに多くの問題が発生しますが、多くの場合、モデルをデプロイする必要があります。エッジノード上でユーザーにパーソナライズされたサービスを提供します。
AI モデルが改善され続ける場合、開発者はより少ないリソースでより高いパフォーマンスを達成する方法の問題を解決する必要があります。学術界でも産業界でも、大規模モデル圧縮は常に注目を集めている分野であり、現在多くのテクノロジーがそれを行っています。この記事では、モデル圧縮方法を直感的に理解できるように、量子化、枝刈り、パラメータ共有、知識蒸留という 4 つの一般的なモデル圧縮方法を簡単に紹介します。
1. モデルスリム化の理論的根拠:パラメータスケールの「限界減少」
モデルを「バケツ」、データを「リンゴ」、データに含まれる情報を「リンゴジュース」に例えると、大規模なモデルをトレーニングするプロセスは、リンゴジュースに何かを詰めるプロセスとして理解できます。バケツ。リンゴの数が多ければ多いほど、リンゴジュースの量も多くなり、リンゴジュースを入れるためにはより大きなバケツが必要になります。大型モデルの登場は、リンゴジュースを十分に入れることができる、より大きなバケツを作成するようなものです。
リンゴが多すぎ、リンゴジュースが多すぎる場合、「オーバーフロー」が発生します。つまり、モデルのサイズが小さすぎてデータセット内のすべての知識を学習できません。この状況を「アンダーフィッティング」と呼びます。モデルは実際のデータ分布を学習できません。リンゴが少なすぎ、サイダーが少なすぎると、「アンダーフィル」が発生します。モデルのトレーニング時間を長くして「強制的に絞ったジュース」でバケツが満たされると、ジュース中の不純物が増加し、モデルのパフォーマンスの低下につながります。したがって、モデルのサイズとデータのサイズを一致させることが非常に重要です。
上の例は鮮明ですが、誤解を招きやすいのです。1 リットルのバケツには 1 リットルのリンゴジュースが入り、2 リットルのバケツには 2 リットルのリンゴジュースが入ります(①など)。しかし実際には、パラメータが収容できる情報はパラメータのスケールに応じて直線的に増加するのではなく、「限界逓減」の増加傾向にあります(②③など)。
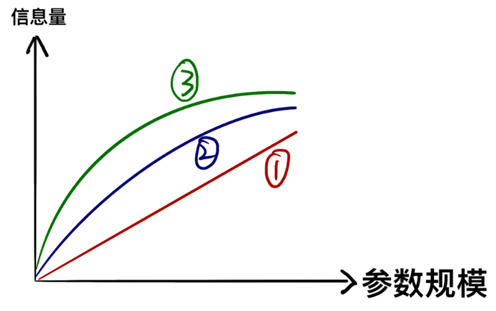
つまり、大型モデルが示す並外れた能力は、多くの「詳細な知識」を習得しているためであり、「詳細な知識」に費やされるパラメータの数は膨大である。データ内のほとんどの知識を学習した後、さらに詳細な知識を学習し続ける場合は、さらにパラメーターを追加する必要があります。ある程度の精度を犠牲にしたり、一部の詳細情報を無視したり、詳細情報を識別するパラメータを削除したりすることをいとわない場合、パラメータのスケールを大幅に削減できます。これが、学術界や学術界におけるモデルスリム化の理論的基礎と中心的なアイデアです。業界の
2. 定量化 - 体重を減らすための最も「シンプルで大雑把な」方法
コンピュータでは、数値の精度が高くなるほど、必要な記憶容量が大きくなります。モデルのパラメータ精度が非常に高い場合 (小数点以下の桁数が多いことが直感的に理解されます)、量子化の中心的な考え方であるモデル圧縮を達成するために精度を直接下げることができます。一般的なモデルのパラメータは 3 2 ビットですが、モデルの精度を 8 ビットに下げることに同意すると、記憶容量を 75% 削減できます。
この方法の理論的基礎は、量子化派のコンセンサスです。最適化中に小さな勾配の変化を捕捉する必要があるため、トレーニング中には複雑で高精度のモデルが必要ですが、推論中には必要ないため、量子化でできることは、推論能力を過度に低下させることなく、モデルが占めるスペースを縮小します。
3. 枝刈り - 「外科的」パラメータの削除方法
大規模モデルは規模が大きく構造が複雑で、内部にはあまり使われないパラメータや構造が多数混在しています。無駄な部分をできるだけ正確に特定して削除できれば、機能を維持したままモデルのサイズを縮小することができます。
ほとんどのニューラル ネットワークでは、ネットワーク層 (畳み込み層または全結合層) の重み値のヒストグラム統計を実行することで、トレーニング後の重み値の分布がほぼ正規分布、または複数の正規分布の混合であることがわかります。 、0 に近いほど相対的に重みが多くなります。これは「重みの疎性」という現象です。
重み値の絶対値は重要性の尺度とみなすことができ、重み値が大きいほどモデル出力への寄与が大きく、逆も同様で重要ではなく、削除後のモデル精度への影響は大きくなります。比較的小さい。
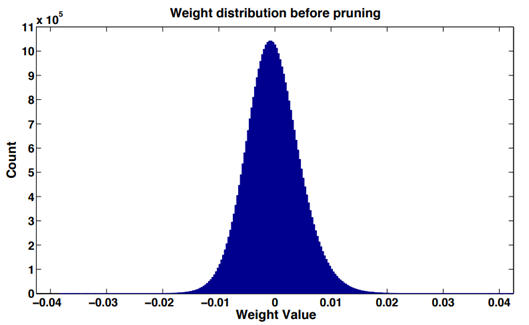
同時に、深いネットワークには、活性化しにくいニューロンが多数存在します。論文「ネットワーク トリミング: 効率的なディープ アーキテクチャに向けたデータ駆動型ニューロン プルーニング アプローチ」では、いくつかの簡単な統計を調査し、入力された画像データの種類に関係なく、CNN の多くのニューロンの活性化が非常に低いことがわかりました。著者らは、ゼロニューロンは冗長である可能性が高く、ネットワーク全体の精度に影響を与えることなく削除できると主張しています。この状況を「活性化希薄」と呼びます。
したがって、ニューラル ネットワークの上記の特性に基づいて、さまざまな構造を調整および最適化して、モデルのサイズを削減できます。
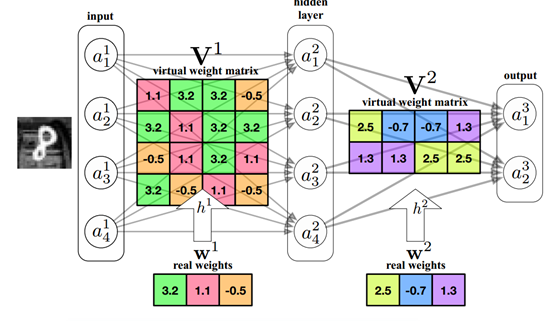
4. パラメータの共有 - 複雑なモデルに代わる小さな代替案を見つける
ニューラル ネットワークは実際のデータ分布を当てはめたものであり、本質的には関数です。同じパフォーマンスでパラメータ サイズが小さく、同じ入力で同様の出力が得られる関数を見つけることができれば、パラメータ サイズは自然に小さくなります。
技術分野では、通常、次元削減に PCA アルゴリズムを使用して、低次元での高次元配列のマッピングを見つけます。モデルパラメータ行列の低次元マッピングが見つかれば、パフォーマンスを確保しながらパラメータの数を減らすことができます。
現在、パラメータ共有には、重みの K-means クラスタリング、ハッシュ法によるランダム分類、同じグループの重みの処理など、さまざまな方法があります。
5. 知識の蒸留 - 生徒が教師に取って代わる
大きなモデルには多くの知識が含まれているため、大きなモデルに小さなモデルを「教えて」、小さなモデルが大きなモデルの能力を持つようにすることはできますか?これが知識の蒸留の核となる考え方です。
すでにある大規模なモデルは Teacher モデルと呼ばれます。この時点で、Teacher モデルを使用して Student モデルを監督し、Teacher モデルの知識を学習できます。
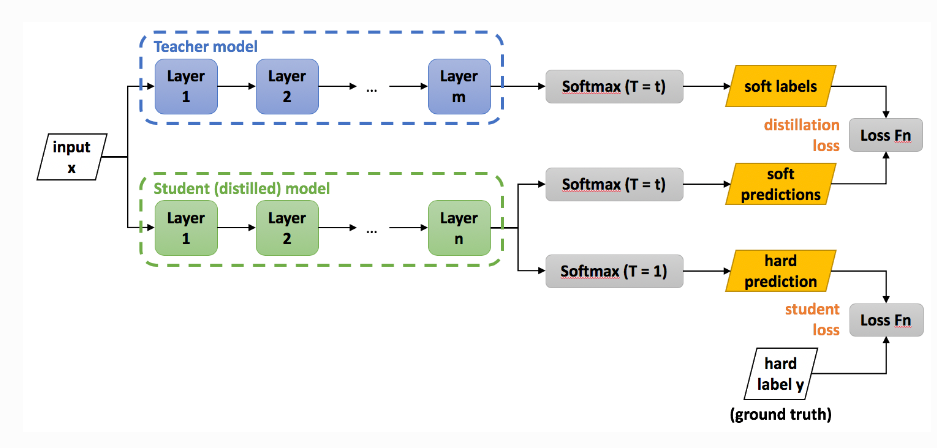
最初の 3 つの方法は元のモデルのパラメーターや構造を多かれ少なかれ変更していますが、知識の蒸留はより小さなモデルを再トレーニングするのと同等であるため、他の方法よりも元のモデルの機能をよりよく保存できますが、精度は一部のみです。失った。
結論
モデル圧縮に対する統一的なアプローチはありません。さまざまなモデルに対して、スケールと精度のバランスを図るために、通常、複数の圧縮方法が試行されます。現在、私たちが使っている大規模なモデルはすべてクラウド上に展開されており、呼び出す権利だけで所有権はありませんが、結局のところ、そのような大規模なモデルをローカルに保存することはできません。叶わない夢。しかし、歴史を振り返ってみると、コンピューターが誕生したばかりの 1940 年代、人々はこれほど巨大で電力を必要とする「巨大機械」を目にしていましたが、それが数十年後の今日、誰もが使うコンピューターになるとは誰も予想していなかったでしょう。 。同様に、モデル圧縮技術の発展、モデル構造の最適化、ハードウェア性能の飛躍により、将来的には大きなモデルはもはや「大きな」ものではなく、誰もが利用できるプライベートなツールになると予想されます。自分の。
参考文献:
https://blog.csdn.net/shentanyue/article/details/83539359
https://zhuanlan.zhihu.com/p/102038521
https://arxiv.org/abs/1607.03250
https://arxiv.org/abs/1806.09228
https://arxiv.org/abs/1504.04788
著作権に関する声明: 転載する必要がある場合は、アシスタント WeChat を追加して連絡してください。許可なく原稿を転載または洗浄した場合、当社は法的責任を追及する権利を留保します。
免責事項: 市場にはリスクがあり、投資には注意が必要です。読者は、この記事の意見、観点、結論を検討する際に、現地の法律や規制を厳格に遵守するよう求められ、上記の内容は投資アドバイスを構成するものではありません。


