
ZONFF Research: Web3 データについて話すとき、私たちは何を話しているのでしょうか?
原作者: ルイス・リャオZonff Partners
Web3 データについて話すとき、私たちは何を話しているのでしょうか?これを理解するには、まず Web2 でデータがどのように見えるかを理解する必要があります。この記事では、データの生成、収集、保存、管理、使用のライフサイクル全体について説明します。その前に、まずデータがどのように定義されるかを明確にします。
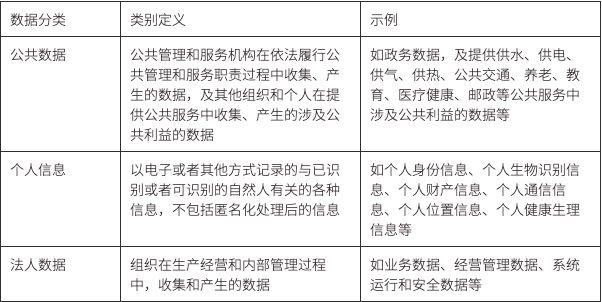
中国国家情報セキュリティ標準化技術委員会が発行した「ネットワーク セキュリティ標準実践ガイドライン - データの分類と格付けガイドライン」(コメント草案 - v1.0 - 202109) では、データは個人情報、公開データ、法的データに分類されています。人物データ。
その具体的な定義と例は次のとおりです。
最初のレベルのタイトル
1.1 データの生成、収集、保存
公的データ、個人データ、法人データは主に、私たちが日常生活でコンピュータ アプリケーションを使用するときに生成されますが、その中でも個人データと法人データは一般ユーザーと密接な関係があります。
画像の説明
画像クレジット: Zonff Partners
画像クレジット: Zonff Partners
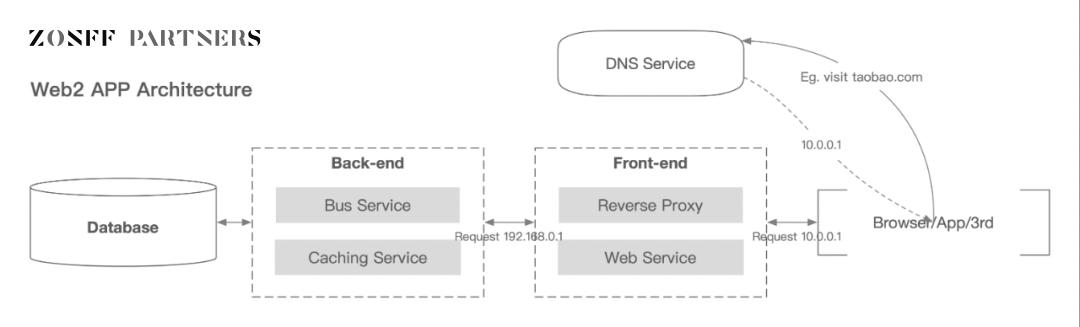
最下位データベースには、バックエンドから送信され、ユーザーとフロントエンドの間の対話によって生成されたデータが保存されます。大まかに言えば、これはユーザーデータです。
モバイル アプリケーションに関する限り、データは次のカテゴリに大まかに分類できます。
ユーザー情報、ユーザーがアプリケーション サービスを使用して記録したユーザー関連情報 (ユーザーの ID 情報、デバイス、ネットワーク、地理的位置、さらにはモバイル デバイスにインストールされているアプリケーションのリストなど) がサーバーによって収集されます。データテーブルと埋め込みポイント。
コンテンツ データ、アプリケーション サービスを使用してユーザーによって生成されたデータ。これには、ユーザーがアプリケーション上でインタラクティブにアクティブに書き込む非個人情報コンテンツ データが含まれます。これはアプリケーション サービスの一部であり、通常はサーバー側のデータ テーブルによって直接収集されます。
行動データとは、アプリケーション使用中のユーザーのインタラクションによって生成されるデータで、閲覧時間、クリック率、浸透率、スライド状況など、アプリケーション使用中のユーザーの行動習慣が含まれ、通常は収集されます。埋もれたポイント。
ログデータ、アプリケーションのクラッシュログなどを含む、ユーザーによるアプリケーションの使用中にアプリケーション自体によって生成されるデータ。
コード データ、非ユーザー インタラクション データには、フロントエンド コードとバックエンド コードが含まれます。これらのデータは、ユーザー データと同様、どこかの集中サーバーに保存されます。
この分類では、ユーザー情報は個人情報データに属し、ログおよびコードデータは法人データに属します。このうち、コンテンツ データと行動データは議論に値しますが、Web2 時代では、これらはさらに集中管理されたエンティティによって独自のビジネス データ、つまり法人データに分割されます。
画像の説明
画像の説明
画像クレジット: Preethi Kasireddy
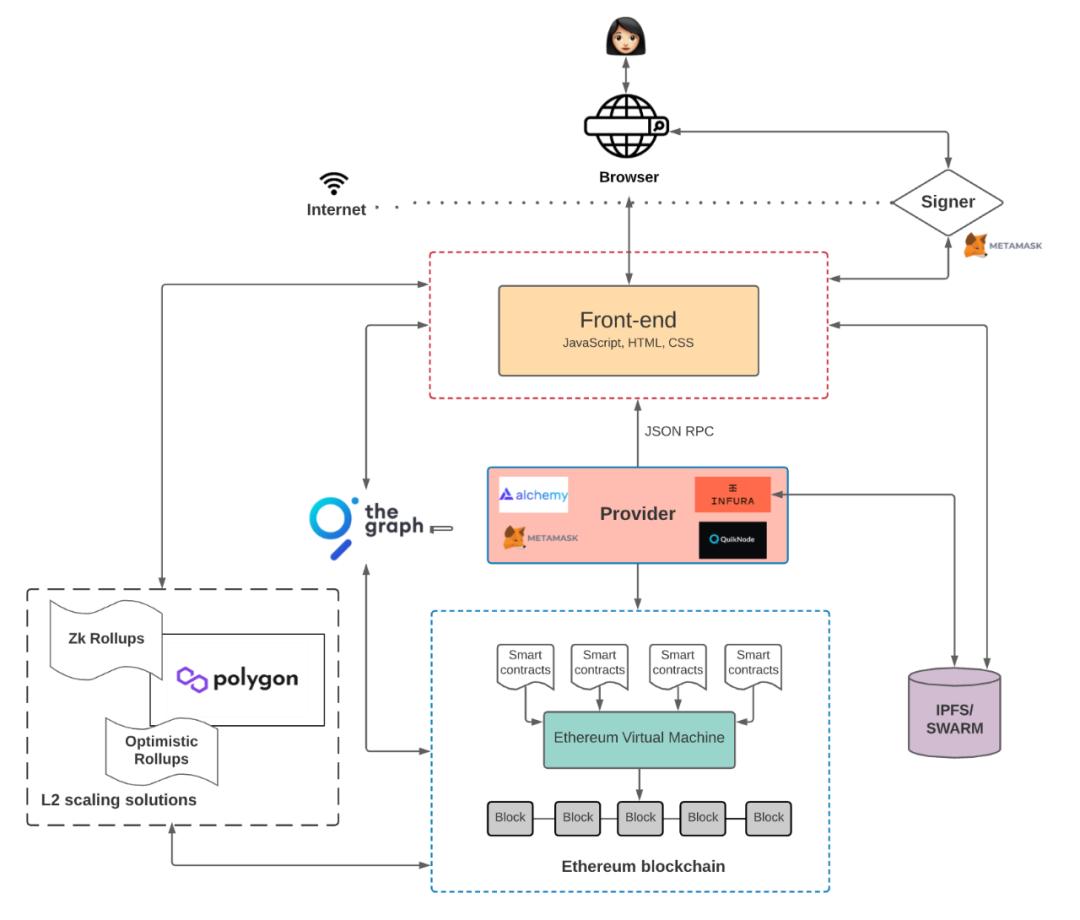
Web2 アプリケーションと比較すると、ユーザー端末とフロントエンドはほとんど変わりませんが、違いはバックエンドとデータベースにあります。ユーザーは(集中サーバーではなく)フロントエンドを通じてノードプロバイダーと対話し、(サーバー上のバックエンド環境ではなく)イーサリアムなどのブロックチェーン上に配置されたコントラクトコードにアクセスして対話します。このプロセスでは、上記の種類のデータも生成されます。技術アーキテクチャの違いにより、Web3 で生成されたデータは集中サーバーに保存されません。生成されたデータの保存方法には類似点と相違点がある可能性があります。さまざまな方法で。
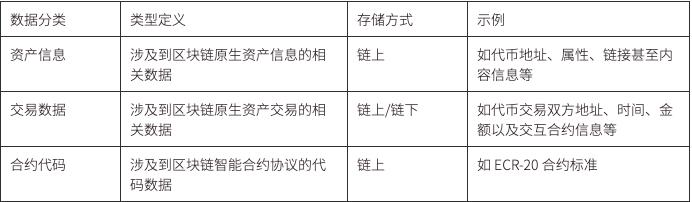
その中で、スマートコントラクトの相互作用によって生成されるすべてのデータはブロックチェーン上に公開され、誰でもアクセスできるため、資産情報、取引データ、契約コードを含むパブリックプロダクトとなります。理論的には、ブロックチェーンのブロックスペースが十分に大きい限り、あらゆるデータをブロックチェーンに保存でき、一部のプロジェクトではブロックチェーンをデータを保存するデータベースとして使用しようとさえしています。
現段階では、上記 3 種類のデータを除き、フロントエンド コード、ユーザー情報、コンテンツ データ、動作データ、ログ データなど、Web3 アプリケーションによって生成されるデータのほとんどは依然として集中サーバーに保存されています。これは、現時点では関連するストレージインフラが完全ではなく、プロジェクト当事者が技術的な問題によって制限されているか、アクセス速度の確保などの理由から集中ソリューションを採用しているためです。インフラストラクチャの継続的な開発に伴い、IFPS、Stroj、Filecoin、Ceramic など、ますます強力なストレージ インフラストラクチャが登場し、ますます多くのアプリケーションが分散ストレージ上に展開され始めています。エンドウェブサイトをIPFS上に構築し、ENSを通じてアクセスすることで、分散型ウェブサイトフロントエンドを構築し、Arweaveを使用してNFTプロジェクトに対応する写真などのファイルデータを永続的に保存します。
一般に、Web3 アプリケーションを構築する場合、開発者には通常、アプリケーション データを保存するための 3 つのオプションがあります。
それをブロックチェーンに保存します。このオプションは非常に高価ですが、アプリケーションを可能な限りシンプルにし、データは完全にオープンになります。利点は、アプリケーションの主権を最も直接的に保護できることです。
スマート コントラクト ロジックはブロックチェーンに保存し、その他は従来のバックエンドに保存します。このアプローチではユーザーの主権が犠牲になり、集中化の危険が生じます。これは、ほとんどの Web3 アプリケーションが現在使用している方法です。
スマート コントラクトのロジックをブロックチェーン上に保存し、IPFS、Arweave、Ceramic などの他のストアに保存し、スマート コントラクトを通じてデータを管理および更新します。この方法は高価で (Ceramic は現在無料)、当面は時間がかかりますが、この方法はアプリケーションの主権を保護できます。
最初のレベルのタイトル
1.2 トレンド: 分散ストレージ - データとアプリケーションの主権
Web3 アプリケーションを構築する 3 つの方法について言えば、主権というキーワードがあります。 Web3の特徴を語る上で避けては通れないこの用語ですが、一般的にはデータ主権とアプリケーション主権が含まれます。それでは主権は重要なのでしょうか?これは別のトピックですが、この記事では説明しません。興味がある場合は、「Web3 データ市場の展望」や「Web3 - Let the"right to data"起きている"。ここではWeb3主権の確立に必要な道筋をデータの観点から切り込み、インフラ整備の方向性と焦点を導き出したい。
デジタル資産主権とユーザーデータ主権を含むデータ主権に関しては、記事「垂直流動性: 価値の相互接続方法」で、トークンがユーザーのデジタル資産主権 (アイデンティティ、関係、財産権) を定義できると述べられています。改ざんが困難な広範なコンセンサス。最も基本的なレベルでは、トークンがどのアドレスに属するかなど、これらの権利の定義はブロックチェーン自体によって完了できます。しかし、より複雑なデジタル商品の権利の所有権となると、多くの問題が発生します。代表的なものは、NFTに対応する写真(または記事など)の保管です。この問題については、「NFT:A」で議論されています。デジタル所有権の革命」について議論します。 「ほとんどのNFTの現状は、対応するデジタル製品がどこかの集中サーバーに保存されていることです。サーバーがクラッシュするかハッキングされると、ユーザーが持つのはチェーン上のハッシュの文字列だけです。ハッシュの背後にある本当の「アイテム」は」いつでも盗まれたり交換されたりして無価値になる可能性があります。
さらに、ユーザー データ主権は、Web2 と Web3 の間の最も明白な境界線の 1 つであり、Web3 の革新と進歩の旗印となります。この点において、Ceramic は、誰もが所有するが独占的ではない、構成可能な Web スケールのデータ エコシステムであるデータ ユニバースを構想しています。ユーザー データは、あるアプリケーションから別のアプリケーションへとユーザーを追っていき、ユーザーは自分自身のデジタル ユニバースを制御する中心として機能します。現時点では、これを実現できるアプリケーションはほとんどありませんが、サイバーコネクトは、分散型ソーシャル グラフ プロトコルを作成し、アプリケーション間でのユーザーの社会的関係データの相互運用性を実現するという優れた試みを行っています。しかし、現時点では、このアプリケーションはユーザーのデータ主権を保証しておらず、構築のために Ceramic への移行が始まっていますが、すべてはまだ途中です。
アプリケーション主権に関しては、主権アプリケーションを「上部構造」と呼ぶ人もいます。これは、止められない、無料、価値がある、スケーラブル、パーミッションレス、正の外部性、信頼できる中立性などの特性を備えており、これらが揃ってデジタル世界を提供します。公共財は「公共財」のインフラストラクチャを構築します。メタバース」(信じられるなら)。現在、いわゆる Web3 アプリケーションのほとんどは高度なアプリケーション主権を持たず、真の公共製品ではなく、権力によって容易に認可され、変更される可能性がありますが、トルネード キャッシュ事件はこの問題を直接的に示しています。主な理由の 1 つは、これらのアプリケーション プロトコル層のコントラクト コードはブロックチェーン上で公開されているにもかかわらず、フロントエンドやドメイン名などのコンポーネントは依然としてサードパーティの集中管理されたエンティティによって制御されているということです。
データ主権とアプリケーション主権を実現するには、Web3 アプリケーションの構築方法が非常に重要です。基本的な出発点はストレージです。データはどこに存在し、どのように保存すればユーザー主権を確保できるでしょうか。一般に、ユーザーのデータ型に応じて、さまざまな解決策があります。
ユーザーの資産情報とトランザクション データは公開台帳データである必要があり、チェーン上で検証可能性を確保することが最も重要ですが、Aztec のようなアプリケーションにとってユーザーのオンチェーン トランザクションのプライバシーを保護することは非常に価値があります。
ユーザーのユーザー情報、コンテンツデータ、行動データは個人情報に該当し、ユーザーの管理を確実にすることが非常に重要であり、ユーザーの同意を得た上で、これらのデータを選択的に公開し、正の外部性を発見することができます。
法人データとしては、ログデータやコードデータは許容されており、民営化する必要があるが、「スーパービルディング」などのWeb3インフラストラクチャアプリケーションに関しては、公共インフラとしての性格を持ち、アプリケーションコードの保管も行うべきである。オープンであり、プラットフォーム レベルを超えた検閲防止機能を備えていること。
現在、ほとんどの Web3 アプリケーションが「スマート コントラクト ロジックをブロックチェーンに保存し、その他のロジックを従来のバックエンドに保存する」ことを採用している理由は、元の集中型インフラストラクチャ ソリューションに代わる十分な分散型インフラストラクチャが現在存在しないためです。
まず第一に、IPFS、Filecoin、Arweave などの分散ストレージはすべて静的ストレージであるため、コンピューティング機能や状態管理機能が不足しており、より高度なデータベースのような機能 (可変性、バージョン管理、アクセス制御など) を実装できません。 Ceramic はこれらの問題をある程度解決するダイナミック ストレージですが、現在の Ceramic のアクセス速度は依然として比較的遅く、開発キットは完璧ではなく、その分散化の度合いは常に一定ではありません。と批判した。
IPFS、Filecoin、Arweaveなどの分散ストレージの主な機能は、改ざんされにくい特性によりNFTなどのデジタルデータを一定期間保証するため、写真や文書、静的コードなどの非構造化データを静的に保存することです。主権、チェーン上のハッシュ コードとチェーン上の分散ストレージ アドレス間の接続が確立されると、異常な方法で外部の力による影響を受けることは困難になります。その上に構築されたフロントエンド コードもアプリケーション主権の整合性を促進しますが、現段階のストレージ テクノロジは単なるストレージであるため、コンピューティング能力の不足により、その機能サポートは集中型サーバー ソリューションに大きく遅れをとっています。
画像の説明
画像の説明
日時: 2022 年 8 月 23 日
最初のレベルのタイトル
2.1 データ管理
分散ストレージ上に Web3 アプリケーションを構築すると、外部の力による干渉を受ける可能性が低くなり、独占と権力が打破されます。しかし、ストレージだけでは十分ではなく、個人データの台頭を実現するには、アプリケーションとユーザーのデータの主権を確保するために、ストレージ環境におけるレンダリング コンピューティング、データ処理、権限設定、プライバシー保護などのテクノロジーのサポートも必要です。デジタル世界における主権。特に権限制御とプライバシー保護の問題は、高レベルの主権技術ソリューションで実装される必要があります。 Web2 アプリケーションのこれらのレベルのデータは、さまざまなセキュリティ保護レベルに従って特定の集中サーバーに保存され、そのセキュリティはネットワーク セキュリティによって保証され、その主権はプラットフォーム (エンタープライズ プラットフォーム、政府プラットフォームなど) によって保証されます。このデータ管理モードでは、ユーザーはスーパー管理者の支配下にあり、ユーザーはデータ自体に対する権限を持ちません。また、データセキュリティもスーパー管理者に一元的に管理されており、例えば、先日ある地域で起きた公安情報漏洩事件では、スーパー管理者が秘密鍵を漏洩させ、数百人の個人情報が流出しました。何百万人もの人々が漏洩する。
Web3 のデータ管理には、次の 2 つの特性が必要です。
データ主権の保護。これはプラットフォーム レベル、さらには世界レベルを超え、世界レベルの合意を通じてデジタル世界におけるユーザーの共通の権利を保護する必要があります。従来の世界では、この点での保護はプラットフォーム レベルで行われており、ルールは非合意から生まれます。プラットフォーム レベルの企業はすべてのルールとシステムを管理でき、いつでも変更できるため、ルールに違反する可能性があります。いつでもユーザーの個人主権。
データプライバシーの保証。ユーザー データのプライバシーは、データベース ネットワーク セキュリティではなく、暗号化によって数学的に保証されます。ユーザー制御の選択的暗号化は、ユーザー データ主権の基本的な権利の 1 つです。
Web3 データの管理方法は、データの保存方法によって異なります。
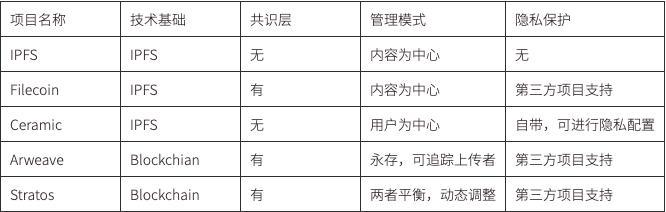
IPFS と Filecoin はコンテンツ中心であり、Content ID (CID) を通じて保存されたコンテンツにアクセスします。これに基づいて、サードパーティ アプリケーションがデータ管理用に構築されています。たとえば、ChainSafe Files を通じて、シングル サインオンの問題を解決できます。非対称暗号化により、データを暗号化し、便利に保存できます。コンテンツ中心の管理モデルではユーザー管理が難しくなり、データの所有権を割り当てる方法がより複雑になります。ストレージの提供に加えて、Filecoin の環境に優しいスケーラビリティは他の最下層よりもはるかに高くなります。特に FVM の発売後は、データ ストレージとデータ取得の一部の垂直分野向けに特別なツールが登場する可能性があります。これは、企業が一部のデータをより適切に管理し、データ セキュリティを確保し、多くの新しいアプリケーションを開発するのに役立つ可能性があります。
Ceramic も IPFS に基づいていますが、ユーザー中心で、IDX プロトコル、3ID DID メソッド (CIP-79) に基づいて、Ceramic の認証に使用できる Ceramic ネイティブのアカウント システムを構築し、ユーザーはブロックチェーン ウォレットを使用して制御できます。 3ID DID データ ストリーム上でトランザクションを実行し、独自のデータを管理します。これは、DID をデータに関連付けてデータ モデルに保存することで実現されます。データ モデルはユーザー データの形式 (スキーマ) を定義し、同じデータ モデルを使用するすべてのアプリケーションはデータ形式を共有します。
Arweave は、1 回限りの支払いと永続的なストレージを備えたオンチェーン データの分散ストレージ プロジェクトです。データはオープンかつ透過的にチェーン上に保存され、誰でもアクセスできます。チェーン上に保存されたデータは、Arweave ブロックチェーンを通じて閲覧できます。ブラウザ。このモードでのデータ管理は、管理チェーン上のデータとまったく同じです。アクセス制御や元データの「ホット アップデート」はありません。データが更新されるたびに、インデックス アドレスが変更されます。問題はありません。 IPFS と Filecoin を使用しますが、その利点は、データがどのユーザーに属しているかが非常に明確であり、データ権利の追跡に役立つことです。
最初のレベルのタイトル
2.2 トレンド: 分散型データ市場
副題
Ceramic のデータ モデル マーケットプレイス
Ceramic は、データ ユニバースの中で、データは相互運用可能である必要があり、生産性の向上を大きく促進できるため、オープン データ モデル市場を創設したいと述べています。このようなデータモデル市場は、イーサリアムにおけるETC契約標準と同様のデータモデルに関する緊急合意を通じて実現され、開発者はデータモデルのすべてのデータに準拠したアプリケーションを機能テンプレートとして選択できます。 。現在、そのような市場は取引市場ではありません。
データ モデルに関して、簡単な例として、分散型ソーシャル ネットワークでは、データ モデルを 4 つのパラメーターに単純化できます。
PostList: ユーザー投稿のインデックスを保存します。
投稿: 単一の投稿を保存します
プロファイル: ユーザー情報を保存します
FollowList: ユーザーのフォローリストを保存します
では、Ceramic 上でデータ モデルを作成、共有、再利用して、アプリケーション間でのデータの相互運用性を実現するにはどうすればよいでしょうか?
Ceramic は、Ceramic 用の再利用可能なアプリケーション データ モデルのオープン ソースのコミュニティ構築リポジトリである DataModels Registry を提供します。ここで開発者は、共有データ モデルに基づいて構築された顧客運用アプリケーションの基礎である既存のデータ モデルをオープンに登録、発見、再利用できます。現在は Github ストレージをベースとしていますが、将来的には Ceramic 上で配布される予定です。
レジストリに追加されたすべてのデータ モデルは、@datamodels npm パッケージの下で自動的に公開されます。開発者は @datamodels/model-name を使用して 1 つ以上のデータ モデルをインストールし、DID DataStore や Self.ID などの IDX クライアントを使用して実行時にデータを保存または取得できるようになります。
副題
オーシャンのデータ取引市場
画像の説明
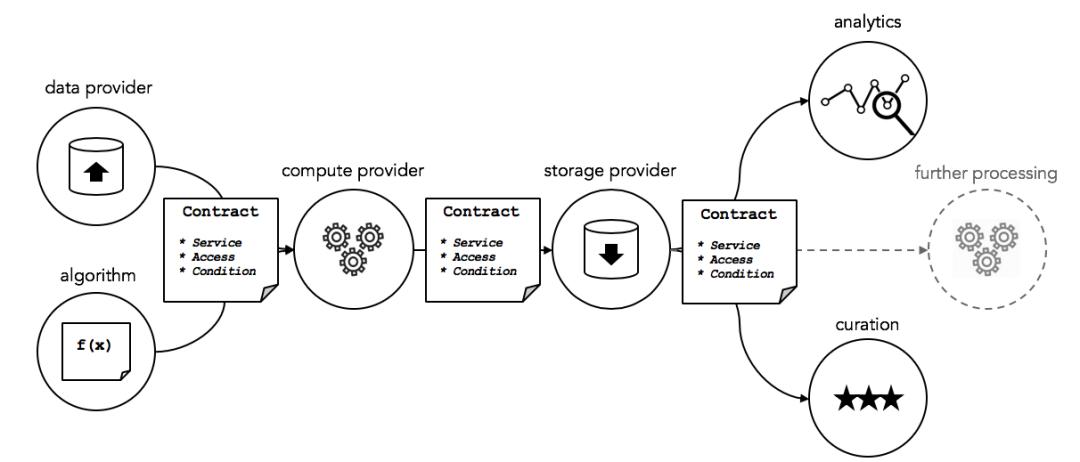
画像クレジット: オーシャンプロトコル
画像の説明
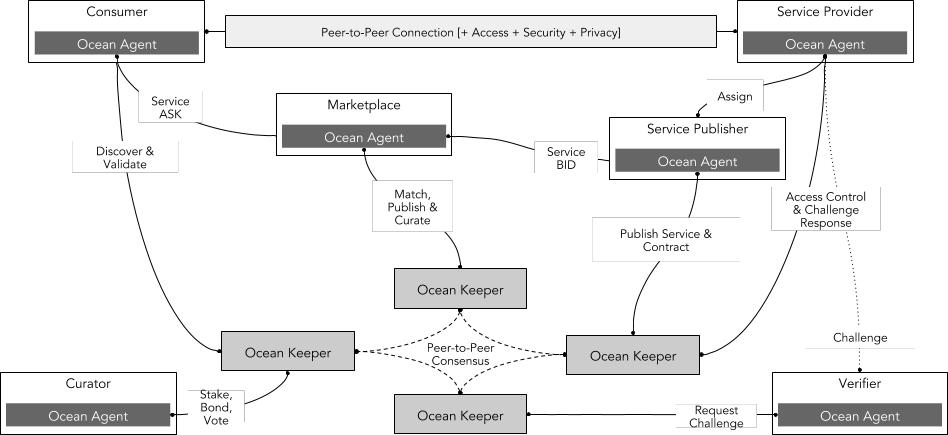
出典: オーシャンプロトコル
最初のレベルのタイトル
3.1 データ使用量とスタック
上記の内容の理解に基づいて、以下の図に示すような Web3 データ スタックを提案します。
最下層は、分散ストレージ、オンチェーンおよびオフチェーンのデータなどのデータ ソースが保存される場所です。
2 つ目は、データベース、データ テーブル、インデックス ミドルウェア、データ マーケットなどを含む、これらのデータの管理アプリケーションです。
画像の説明

画像クレジット: Zonff Partners
画像クレジット: Zonff Partners
現在、業界の Web3 上で使用されるデータのほとんどはオンチェーン データであり、データ分析ツールやインデックス作成ツールが次々に登場し、オンチェーン データの巨大な宝の山は完全に活用されています。上図における分析アプリケーションの分類 そのほとんどはチェーン上のデータマイニングであり、オフチェーンデータが関与するのはほんの一部です。一般に、データ使用リンクは ETLA (抽出、変換、ロード、分析) プロセスであり、各ノードには代表的なプロジェクトがあります。 Extract(抽出)プロジェクトの代表はThe Graph、利用可能なデータテーブルへのTransform(変換)とLoad(ロード)リンクのプロジェクト代表はDuneとLuabsae、Anaization(分析)プロジェクトの代表はNansenとNFTGOです。 。
分散型ストレージに関しては、ETLA の全プロセスをサポートするプロジェクトはほとんどなく、抽出プロジェクトがいくつかあるだけですが、ここには大きなチャンスと課題があります。 Graph コミュニティと Ceramic コミュニティ自体が Ceramic 上のデータの抽出に取り組んでおり、Orbis の創設者も Ceramic 上のデータを閲覧するための Cerscan を作成しようとしました。 Arweave はすでに、The Graph を通じてサブグラフを使用して Arweave に保存されたデータを読み取って管理することができます。これを実行している関連するサードパーティ プロジェクトも Filecoin 上にあります。しかし、現時点では TLA プロセスを気にする人は誰もいません。最大の理由は、異なる分散ストレージに保存されているデータが非常に異質であり、これらのデータの価値を採掘するための統一モデルを持つことが難しいためです。有望な Ceramic がこの措置を講じたのは、そのデータ モデルの存在により Ceramic 上のデータの不均一性が指数関数的に減少し、データの可用性が向上したためです。
チェーン上のデータだけでなく、チェーン上のデータとオフチェーンのデータを連携させようとするプロジェクトも数多くあり、こうしたプロジェクトは「チェーン改革」プロジェクトといえる。
タイプ分類は次のとおりです。
Web2 データ主権付与および取引市場: Itheum、Navigate、Swash、Phyllo など。このタイプのプロジェクトは、主に従来のインターネット データとオンチェーン データを組み合わせて、Web2 と Web3 の間の情報のやり取りを可能にすることを目的としています。一般的な方法は、Web2 データをエクスポートして指定されたデータ プールにインポートするか、従来のインターネット ソーシャルを直接バインドすることです。アカウントなど。
企業データのコンセンサス: Authtrail プロジェクトは、企業の内部データベースと統合し、コンセンサス層に参加して、企業内で改ざん防止と追跡可能なデータを実現します。
オンチェーンとオフチェーンのデータの組み合わせ: 空間と時間。Authtrail と同様に、このプロジェクトはオフチェーン データベースを統合しますが、コンセンサス層はなく、オフチェーンとオンチェーンのデータを共同計算するものです。さらに、プールも同様のことを行っています。
Web3 データの使用パラダイムは明らかに Web2 とは異なります。主にデータが収集される方法、つまり、さまざまな種類のデータの保存、インデックス付け、抽出、統合、利用の方法が異なります。前述の分類に従って、いくつかの簡単な要約を次に示します。
公開データ: 「ネットワーク セキュリティ標準実践ガイド - データの分類と格付けガイドライン」に分類されている公開データおよび一部の法人データが含まれます。パブリック プロダクトとして、価値を得るために公にマイニングできるデータです。アクセスには許可は必要ありませんが、エアドロップの利益を追跡するためにユーザーの所有権を追跡できます。典型的な例としては、オンチェーン データと保存された暗号化されていないアプリケーション データがあります。分散ストレージ上 (ユーザーの投稿、いいね、コメントなど)。その使用に対する最も重要な上流サポートは、The Graph などのインデックス作成アプリケーション、または Tableland などの Web3 ネイティブ データベース アプリケーションです。
プライベート データ: 「ネットワーク セキュリティ標準実践ガイド - データの分類と格付けガイドライン」で分類された個人情報および一部の法人データが含まれます。暗号化ストレージと特定のプライバシー許可設定が必要なデータ タイプとして、そのアクセスは許可されており、公的に取得することはできません。分散ストレージやブロックチェーンに保存される場合は、設定可能なアクセス許可を持つ暗号化ストレージが必要です。または、ZK、MPC、TEE、その他のプライバシー技術保護などの他の手段を通じて。その使用に対する最も重要な上流サポートは、Kwil や Ceramic などのデータベース アプリケーションです。


