
Who Takes a Cut of Your AI Monthly Fee? A Breakdown of the $20 Compute Supply Chain
- Core Thesis: AI application subscription fees (e.g., Claude Pro at $20/month) differ from traditional SaaS because their marginal inference cost is not zero. Investors need to reassess the value of AI application revenue, focusing on whether gross margins can sustainably improve alongside usage expansion, rather than simply applying a high-margin SaaS valuation logic.
- Key Elements:
- There is a structural contradiction between fixed AI subscription fees and variable inference costs. Every user query, code generation, etc., consumes resources like GPU power and electricity. The higher the usage, the heavier the cost chain, directly challenging the high-margin assumptions of traditional SaaS.
- A widely circulated cost breakdown chart for the $20 subscription shows fees flowing to model companies, cloud compute, GPU depreciation, electricity, and the supply chain. The core insight is that it reveals the "usage-weighted gross margin" is the key to valuing AI companies, not merely user willingness to pay.
- In the short term, growth in AI usage more reliably flows to the infrastructure layer (e.g., Nvidia, TSMC, HBM manufacturers, power companies). Their revenue is driven by rigid compute demand, making performance verification more direct and faster.
- The efficiency-focused viewpoint argues that technological advancements such as model optimization, small model routing, caching, and custom chips will continue to reduce unit inference costs, creating the potential for improved AI application gross margins.
- The core disagreement is whether the decline in inference costs can outpace the growth in average user usage and task complexity. If the latter is faster, the weighted gross margins of AI application companies will still face pressure.
- Valuation judgments for unlisted model companies (e.g., OpenAI, Anthropic) must focus on their user composition (ratio of light to heavy users), enterprise plan pricing, cloud cost structure, and the actual transmission effect of declining unit inference costs, rather than total subscriber count.
TL;DR
- A cost breakdown chart for the $20 monthly Claude subscription, tracing the fee from the AI company to cloud computing, GPUs, electricity, and the supply chain.
- AI subscriptions carry ongoing inference costs, preventing a direct application of the high-margin assumptions typical of traditional SaaS.
- Related stocks/entities: OpenAI, Anthropic, Microsoft, Amazon, Google, NVIDIA (NVDA), TSMC, SK Hynix, Samsung, Micron, data centers, and the power supply chain.
A chart estimating how the approximately $20 monthly fee for Claude Pro in the US is distributed among the model company, cloud computing, GPU depreciation, electricity, and the supply chain is prompting investors to reassess how to value AI application revenue.

This chart isn't official revenue share data from Anthropic, AWS, or NVIDIA, nor should it be treated as any company's actual ledger. Its value lies in raising a more fundamental question: how much of a user's AI subscription fee can solidify into software-like gross profit, as in traditional SaaS?
The valuation logic for traditional SaaS is clear: once the software is built, the marginal cost of adding another account is usually low, with gross margins for mature pure-software companies often exceeding 70% or even 80%. Investors are willing to pay high multiples because profit margins tend to improve as revenue scales.
The problem for AI applications is that every user query, code generation, file analysis, or agent invocation consumes GPU time, electricity, memory bandwidth, and cloud resources. While the surface is a fixed monthly fee, underlying it is a cost chain that varies with usage. Light users might bring high margins, but heavy users running continuous tasks within their quota or plan can see costs rise rapidly.
Ultimately, the $20 breakdown chart isn't challenging which company gets how many dollars; it's questioning whether "AI application revenue naturally equals SaaS revenue." AI companies need to prove not only that users are willing to pay, but also that usage-weighted gross margins can sustainably improve to justify high multiples.
An Inference Cost Chain Underlies the Subscription Fee
The key difference between AI subscriptions and regular software subscriptions is that the marginal cost of "one use" is no longer near zero.
In traditional SaaS, adding an account for a team incurs costs for servers, customer support, and bandwidth, but these don't typically rise linearly with each click. The truly significant costs are upfront R&D, sales, and customer acquisition. As the product scales, a considerable portion of new revenue can be retained.
Large language model products are different. When a user inputs a question and the model generates an answer, this process is called inference, the actual computation invoked by the user. Tokens are the basic unit for measuring text read and written by the model. The more questions asked, the longer the context, and the more complex the generated content, the more tokens and computing power are consumed.
This creates a conflict between fixed subscriptions and variable costs. The Claude Pro monthly price in the US is roughly $20, subject to regional variations, taxes, and Anthropic's adjustments. Users see a fixed price, but the model company faces vastly different usage behaviors. Some users only write emails and search for information, while others handle long documents, run code tasks, or invoke more complex automation processes.
The circulating breakdown chart attempts to visualize this: of the $20, a portion stays with the model company, another goes to cloud and computing providers. Computing costs include electricity, operations, and GPU depreciation. GPU procurement then flows up to NVIDIA, TSMC, HBM (High Bandwidth Memory) suppliers, optical modules, ODM manufacturers, and power-related companies.
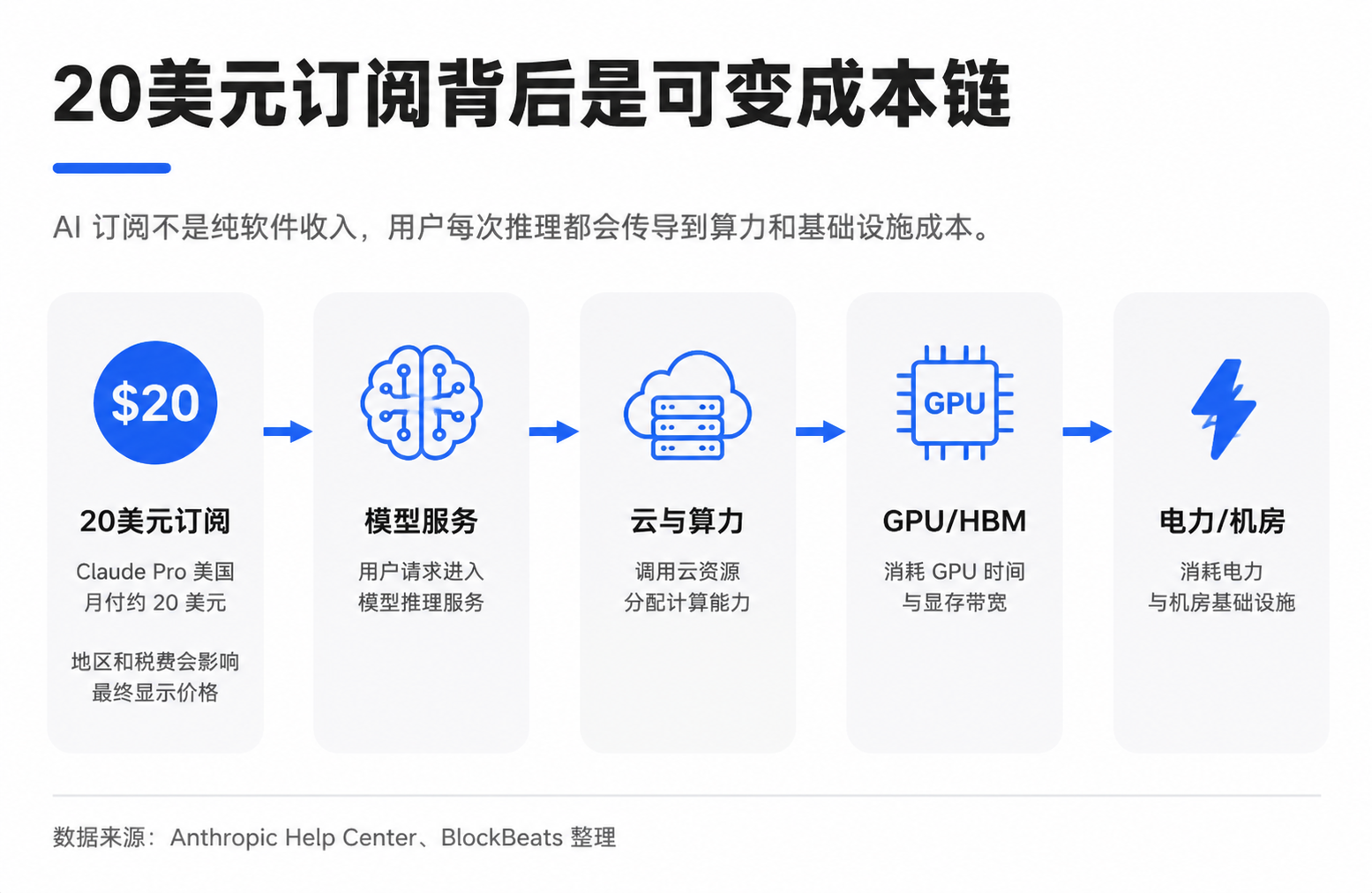
"GPU depreciation" here means the expensive GPUs aren't expensed all at once, but are gradually allocated to AI services based on useful life, usage intensity, or accounting methods. The actual allocation is affected by plan limits, the ratio of light to heavy users, internal cloud provider pricing, reserved instance discounts, GPU utilization rates, and depreciation periods. Average cost also differs from marginal cost.
The key direction investors need to monitor is this: AI application companies can't just report revenue growth; they must also address whether the underlying computing costs grow in tandem. If usage volume expands faster than model efficiency improvements, higher subscription revenue could lead to greater margin pressure. Only with sufficiently rapid efficiency gains can model companies hope to approach the profit structure of software firms.
Infrastructure Captures More Certain Revenue First
Currently, growth in AI usage flows more directly to infrastructure rather than all accumulating in the application layer.
Whether a user interacts with a model via Claude, ChatGPT, Gemini, or an internal enterprise agent, the inference ultimately relies on computing power, electricity, memory, and network infrastructure. While applications may face churn or replacement, underlying resource consumption is more rigid. As long as AI usage continues to rise, cloud CapEx, GPU procurement, HBM demand, and data center power consumption will be pulled along.
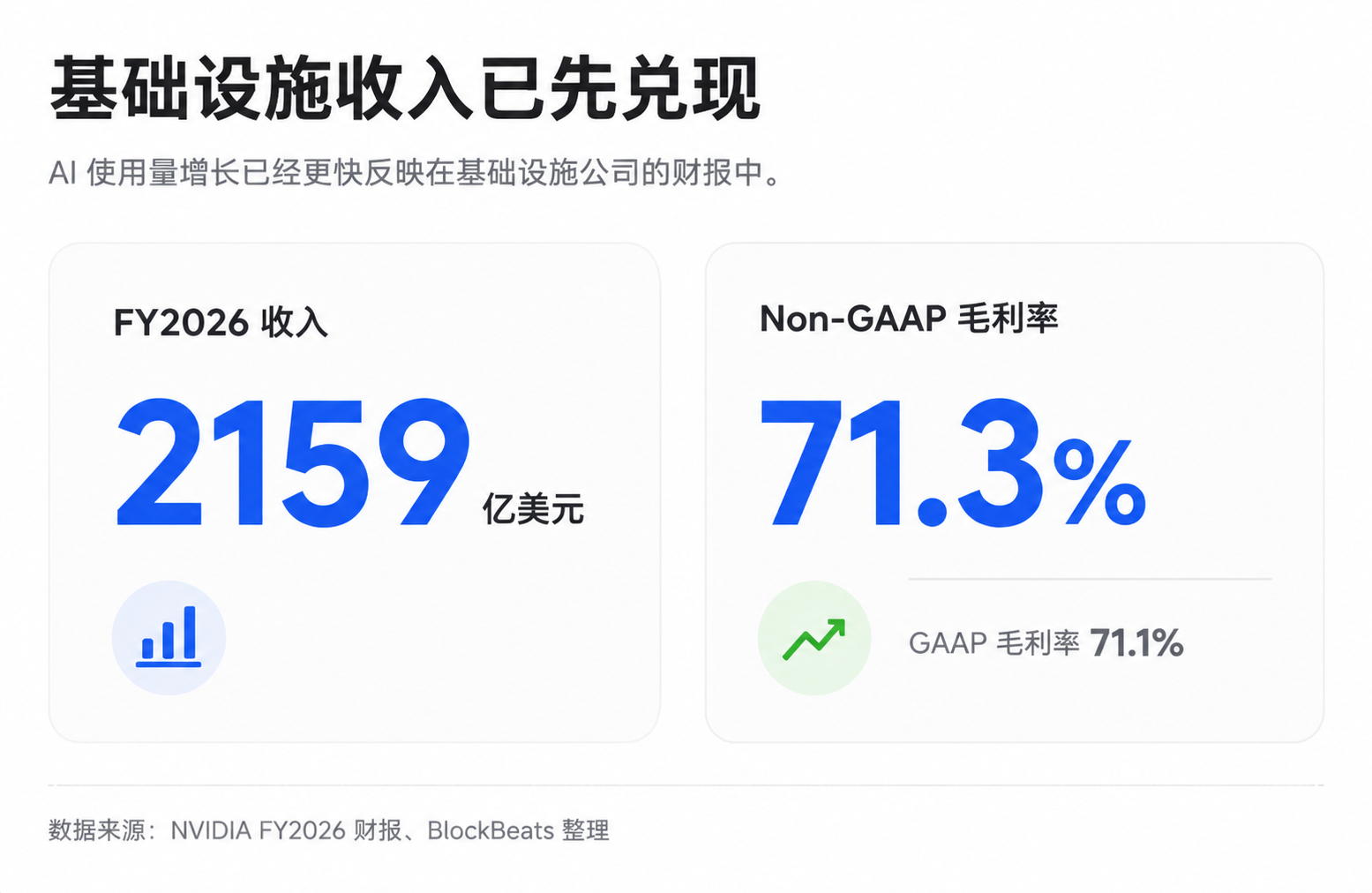
This is why infrastructure stocks like NVIDIA, TSMC, and SK Hynix are being continuously revalued by the market. NVIDIA's overall gross margins have been high recently, with GAAP and non-GAAP gross margins for FY2026 around 71.1% and 71.3%, and subsequent quarterly guidance remaining elevated. It's important to note that individual quarters can be affected by specific expenses, and public financials don't always perfectly isolate the AI data center's true gross margin structure, but the pricing power of scarce infrastructure is already reflected in performance.
HBM is the most typical link in this chain. It's not ordinary memory but a crucial component supporting high-throughput computation in AI accelerators. As model size, context length, and concurrent inference demand increase, AI chips' reliance on high-bandwidth memory intensifies. Supply chain estimates show HBM's share in the cost of next-gen AI chips is rising, which is a key reason SK Hynix, Samsung, and Micron are being repriced in this AI cycle.
Electricity and data centers have also transitioned from background costs to core investment themes. The energy consumption of a single simple text query might not be dramatic, but complex agents, long contexts, code generation, and multi-turn tasks amplify computation. For cloud providers and data center operators, the key isn't the power draw of one query, but the cluster utilization rate, electricity prices, cooling capacity, server room space, and grid connectivity, which become both costs and bottlenecks when massive numbers of inference requests occur continuously.
The advantage of the infrastructure side is faster performance verification. Cloud providers' AI CapEx has already been deployed; NVIDIA's revenue and margins are reflected in earnings; HBM manufacturers' orders and prices feed into their profit statements relatively quickly. The model application layer, however, trades more on future expectations: subscription conversion, enterprise penetration, API revenue, and profit release following a declining cost curve.
Efficiency Improvement Remains the Core Bullish Argument
Software investors and AI bulls do have a counterargument. The efficiency camp's core view is that today's high inference costs are a temporary early-stage phenomenon. Model optimization, caching, smaller models, custom chips, and higher cluster utilization will persistently lower unit costs. If costs fall fast enough, AI applications can still return to a high-margin software logic.
This counterargument has a factual basis. Unit prices for some mainstream models have dropped significantly while maintaining or improving capability. OpenAI has stated that the per-token cost of GPT-4o mini is 99% lower than the earlier text-davinci-003. The pace varies by company; Anthropic has recently focused more on same-price upgrades and model tiering. Still, the industry direction is to deliver stronger capabilities at lower cost.

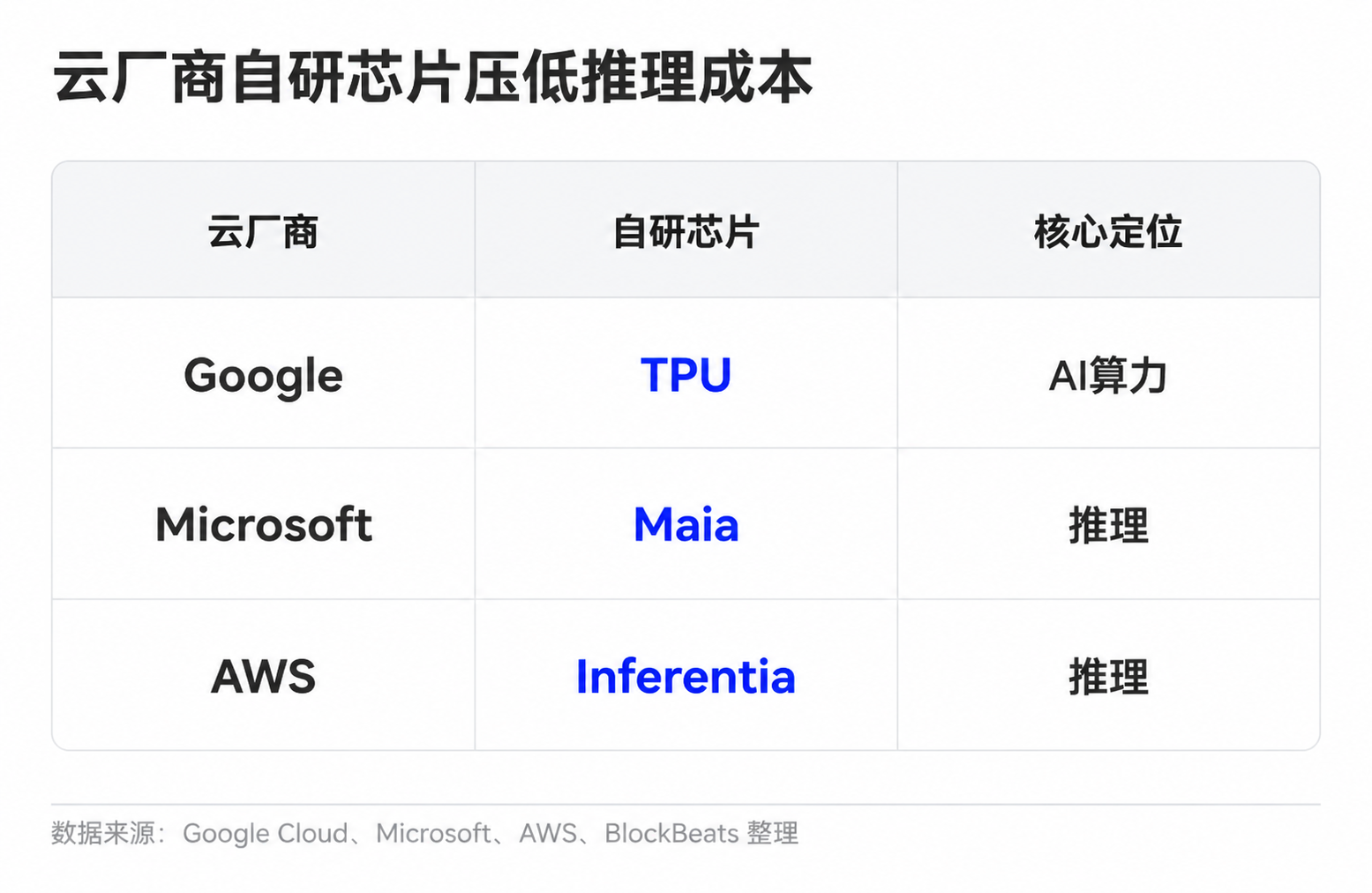
Model companies have several ways to improve unit economics. Simple tasks can be routed to smaller models, common requests can leverage caching, while long-context and complex tasks are handled by more powerful models. Cloud providers are reducing unit compute costs through custom chips and cluster scheduling. Google has TPUs, Microsoft introduced Maia for inference, and Amazon is advancing Trainium and Inferentia.
Looking solely at technological progress, there is room for improvement in AI application profit margins. Cheaper inference, better model routing, and stronger compression can allow the same $20 subscription to support more usage. Light users, high-priced enterprise plans, tiered API pricing, and stricter usage caps can also help improve overall unit economics.
The challenge is that cost reduction isn't the only variable. AI applications are moving from simple chat to heavier workloads. Previously, users might only engage in Q&A and text rewriting. Now, growing demand comes from code agents, long document processing, video and multimodal generation, and enterprise automation workflows. These use cases offer higher value but also consume significantly more resources. The more useful the model, the more likely users are to delegate complex, long-duration tasks to it.
The debate thus becomes more specific: can the rate of inference cost decline outpace the growth in usage volume and task complexity? If unit costs fall quickly but average user consumption grows even faster, the model company's weighted gross margins will still be pressured. Conversely, if model routing, caching, custom chips, and pricing tiers are sufficiently effective, AI subscriptions may gradually shed their current cost-heavy characteristics.
Subscriber Count ≠ Gross Margin
The $20 breakdown chart shouldn't be taken as the final picture. It's more of a valuation reminder for the current phase: when the market lacks sufficiently transparent gross margin data from model companies, investors should discount the assumption that "AI applications are naturally equivalent to SaaS."
For private model companies like OpenAI and Anthropic, external investors have limited access to complete financials. Clues will come from fundraising materials, partner disclosures, cloud cost structures, enterprise plan pricing, API revenue share, and usage limitations. The truly valuable data points aren't just the number of paid users, but the ratio of light to heavy users, whether enterprise clients are willing to pay higher prices for intensive use, whether cloud settlement costs are declining, and whether unit inference cost reductions are translating into company gross margins.
Verification for publicly traded companies will appear faster in their earnings reports. NVIDIA's overall margins and data center revenue growth, TSMC's advanced process and packaging demand, HBM manufacturers' pricing and profit margins, and cloud providers' CapEx intensity will continue to reflect whether AI usage volume is still transmitting to the infrastructure side. If these metrics remain strong while the application layer shows little evidence of margin improvement, the market will likely continue awarding a valuation premium to infrastructure.
Ultimately, for model companies to reclaim a higher valuation anchor, they need to prove not just that users are willing to pay $20, but that these subscription fees can retain sufficient gross profit after heavy usage. The next pricing debate likely won't revolve around the headline ARR number, but whether inference costs, plan limitations, and enterprise pricing can all work out positively together.


