
從認識Skill,到了解如何建構Crypto Research Skill
- 核心觀點:文章深入剖析了Anthropic推出的Agent Skill技術,闡述了其從Claude專屬功能演變為AI Agent領域通用底層設計模式的過程,並重點解析了其與MCP協議的本質區別及在加密投研場景下的協同應用價值。
- 關鍵要素:
- Agent Skill於2025年底由Anthropic推出並開放為標準,旨在將AI能力模組化,通過「說明文件」形式提升任務執行的穩定性和效率,降低Prompt調優冗餘。
- 其核心運行機制為「漸進式揭露」,分三層(元數據、指令、資源)按需載入,極致節省Token並保持高效,其中Reference用於條件觸發讀取外部知識,Script用於執行外部程式碼。
- Agent Skill與MCP存在本質區別:MCP是標準化的「資料管道」,負責連接外部資料來源;而Skill是「行為準則(SOP)」,負責規範模型如何處理資料。
- 在加密投研實戰中,二者可強強聯合,形成「MCP供水,Skill釀酒」的模式,例如利用MCP取得鏈上資料與新聞,再透過Skill編排工作流自動生成盡職調查報告或發現交易訊號。
- 這種組合能建構高度自動化的專業工作流,如新幣種快速盡調(交叉驗證推特、輿情、AI分析)和即時事件驅動的交易訊號發現(透過WebSocket監聽新聞流並觸發警報)。
原文作者: @BlazingKevin_ ,Blockbooster研究員
1. Agent Skill 的誕生背景與演進
2025 年的 AI Agent 賽道正處於從「技術概念」向「工程落地」跨越的關鍵分水嶺。在這個進程中,Anthropic 關於能力封裝的探索,意外地促成了一次行業級的範式轉移。
2025 年 10 月 16 日,Anthropic 正式推出了 Agent Skill。起初,官方對這一特性的定位表現得極為克制——它僅僅被視作提升 Claude 在特定垂直任務(如複雜程式碼邏輯、特定資料分析)表現的輔助模組。
然而,市場和開發者的回饋遠超預期。大家很快發現,這套將「能力模組化」的設計在實際工程中展現出了極高的解耦性和靈活性。它不僅降低了 Prompt 調優的冗餘度,還極大地提升了 Agent 執行特定任務的穩定性。這種體驗,迅速在開發者社群引發了連鎖反應。短時間內,包括 VS Code、Codex、Cursor 在內的頭部生產力工具與整合開發環境(IDE)紛紛跟進,陸續完成了對 Agent Skill 架構的底層支援。
面對生態的自發擴張,Anthropic 捕捉到了這一機制的底層通用價值。2025 年 12 月 18 日,Anthropic 做出了一個具有行業里程碑意義的決定:正式將 Agent Skill 發布為開放標準。
緊接著,在 2026 年 1 月 29 日,官方正式發布了 Skill 的詳盡使用手冊,從協議層面徹底打通了跨平台、跨產品複用的技術壁壘。 這一系列動作標誌著 Agent Skill 已經徹底褪去了「Claude 專屬附屬品」的標籤,正式演變為整個 AI Agent 領域中一種通用的底層設計模式。
至此,一個懸念呼之欲出:這個讓大廠與核心開發者紛紛擁抱的 Agent Skill,究竟在底層工程上解決了什麼核心痛點?它與當前大熱的 MCP 之間,又有著怎樣的本質區別與協同關係?
為了徹底釐清這些問題,並最終將其落腳於加密行業投研的實際建構中,本文將層層遞進地展開以下探討:
- 概念解析:Agent Skill 的本質及其基礎架構建構。
- 基礎工作流:揭示其底層運轉邏輯與執行流。
- 進階機制:深入剖析 Reference與 Script兩大高階用法。
- 實戰案例:解析 Agent Skill 與 MCP 的本質差異,並演示在 Crypto 投研場景下的組合應用。
2. 什麼是 Agent Skill 及其基礎建構
到底什麼是 Agent Skill?用最通俗的話來講,它其實就是一份大模型可以隨時翻閱的「專屬說明文件」。
在日常使用 AI 時,我們經常會遇到一個痛點:每次開啟新對話,都要把長長的要求重新貼上一次。而 Agent Skill 就是為了解決這個麻煩而生的。

舉個實際的例子:假設你想做一個「智慧客服」 Agent,你可以在 Skill 裡明確寫下規矩:「遇到用戶投訴,第一步必須先安撫情緒,並且絕對不能隨意做出賠償承諾。」 再比如,你經常需要做「會議總結」,你可以直接在 Skill 裡定好模版:「每次輸出會議總結時,必須嚴格按照『參會人員』、『核心議題』、『最終決定』這三個板塊來排版。」
有了這份「說明文件」,你就不需要每次對話都去重複那一長串的指令了。大模型在接到任務時,會自動去翻閱對應的 Skill,立刻就知道該用什麼標準來幹活。
當然,「說明文件」只是一個為了方便大家理解的簡化比喻。實際上,Agent Skill 能做的事情遠比單純的格式規範要強大得多,它的那些「殺手級」高階功能我們會在後面的章節詳細拆解。但在起步階段,你完全可以把它當成一份高效的任務說明書。
接下來,我們就用「會議總結」這個大家最熟悉的場景,來看看究竟該怎麼動手創建一個 Agent Skill。整個過程並不需要複雜的程式設計知識。
根據目前主流工具(如 Claude Code)的設定,我們需要在電腦的用戶目錄下找到(或新建)一個叫 .claude/skill 的資料夾,這裡就是存放所有 Skill 的「大本營」。
第一步,在這個目錄裡創建一個新資料夾。這個資料夾的名字,就是你這個 Agent Skill 的名字。 第二步,在剛剛建好的資料夾裡,創建一個名為 skill.md 的文字檔案。
每一個 Agent Skill 都必須有這麼一個 skill.md 檔案。它的作用就是告訴 AI:我是誰,我能幹什麼,以及你該怎麼按我的要求工作。打開這個檔案,你會發現它清晰地分成了上下兩部分:

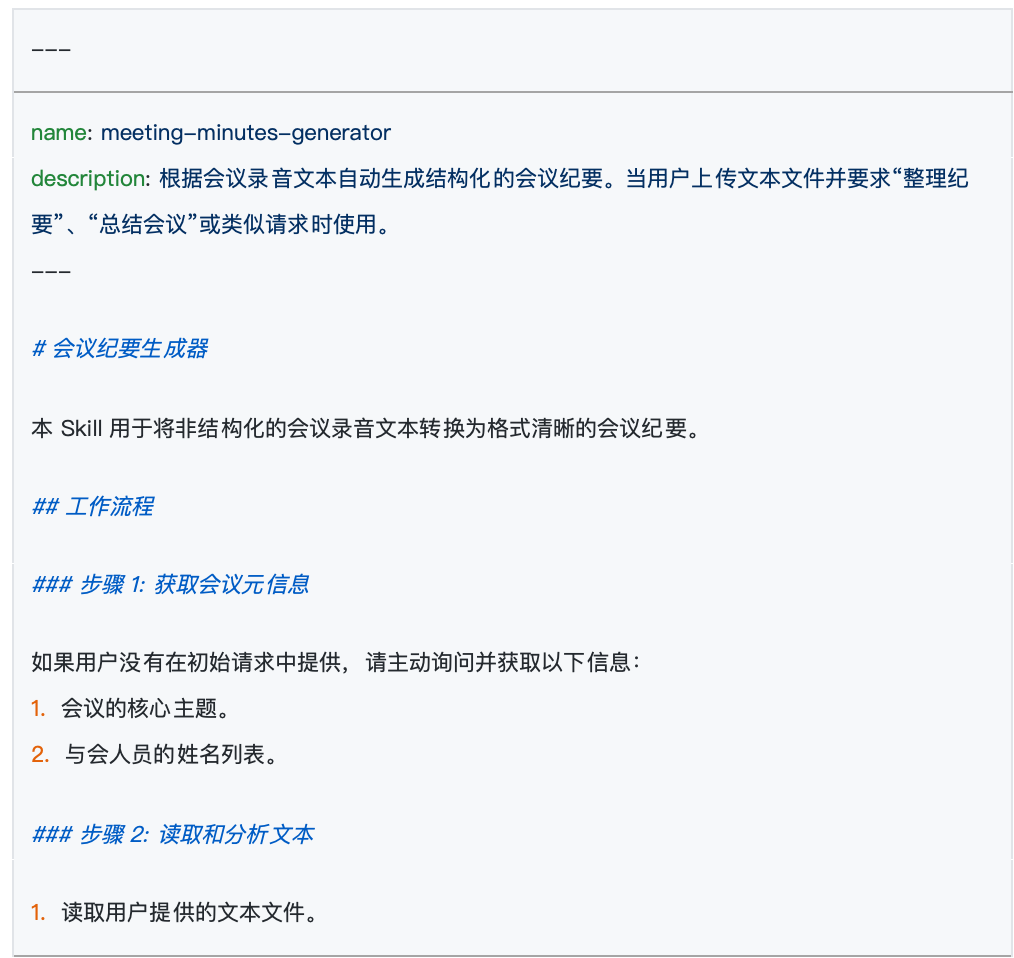
在檔案的最開頭,通常是被兩段短橫線 --- 包起來的區域。這裡面只寫兩個核心屬性:name 和 description。
name:就是這個 Skill 的名字,必須和外面的資料夾名字一模一樣。description:這是極其重要的一環。它負責向大模型解釋這個 Skill 的具體用途。AI 在後台會持續掃描所有 Skill 的描述,以此來判斷當前用戶的提問到底該用哪一個 Skill 來解答。 因此,寫一段精準、全面的描述,是確保你的 Skill 能被 AI 準確喚醒的大前提。
短橫線下方剩下的部分,就是寫給 AI 看的具體規則了。官方把這部分叫做「指令」。 這就是你發揮的地方,你要在這裡詳細描述模型需要遵循的邏輯。比如在會議總結的例子裡,你就可以在這裡用大白話規定:「必須提煉出參會人員名單、討論的議題以及最終落實的決定」。

把這幾步做完,一個簡單但非常實用的 Agent Skill 就誕生了。
不過,一個真正好用的 Skill,往往始於周密的前期設計。在鍵盤上敲下第一行字之前,先清晰地定義目標、範圍和成功標準,會讓你的建構過程事半功倍。
建構 Skill 的第一步,其實不是去想「我能讓 AI 搞出什麼花樣」,而是要反問自己:「我到底需要解決日常工作中的什麼重複性問題?」 建議一開始先具體定義出 2 到 3 個這個 Skill 應該覆蓋的明確場景。

其次,是定義成功的標準。你怎麼知道自己寫出的 Skill 好不好用?在動手前,給它設定幾個能衡量的標準。比如定量的標準可以是「處理速度是否變快了」,定性的標準可以是「它提取的會議決定是不是每次都足夠精準沒有遺漏」。
3. Agent Skill 的基礎運行工作流
在了解了 Agent Skill 的基本面貌後,我們不禁要問:在實際運行中,這套「說明文件」究竟是如何發揮作用的?
如果你最近體驗過像 Manus AI 這樣的產品,你大概率經歷過這樣的場景:當你拋出一個特定問題時,AI 並沒有立刻開始「長篇大論」或產生幻覺,而是敏銳地意識到「這件事歸某個特定的 Agent Skill 管」。於是,它會在介面上彈出一個提示,詢問你是否允許調用該 Skill。
當你點擊「同意」後,AI 便像換了一個人一樣,嚴格按照預設的規矩完美輸出結果。
這個看似簡單的「申請-同意-執行」的互動背後,其實隱藏著一套極為精巧的底層運行工作流。為了徹底講清楚這套機制,我們需要先明確整個流程中參與互動的「三個核心角色」:
- 用戶:發起任務請求的人。
- 客戶端工具(如 Claude Code 等):負責調度和統籌的「中間人」。
- 大語言模型:負責理解意圖和生成最終結果的「大腦」。
當我們向系統輸入一段需求(例如:「幫我總結一下今天早上的專案例會」)時,這三個角色之間會發生如下的四步精密協作:
第一步:輕量級掃描(傳遞元資料)
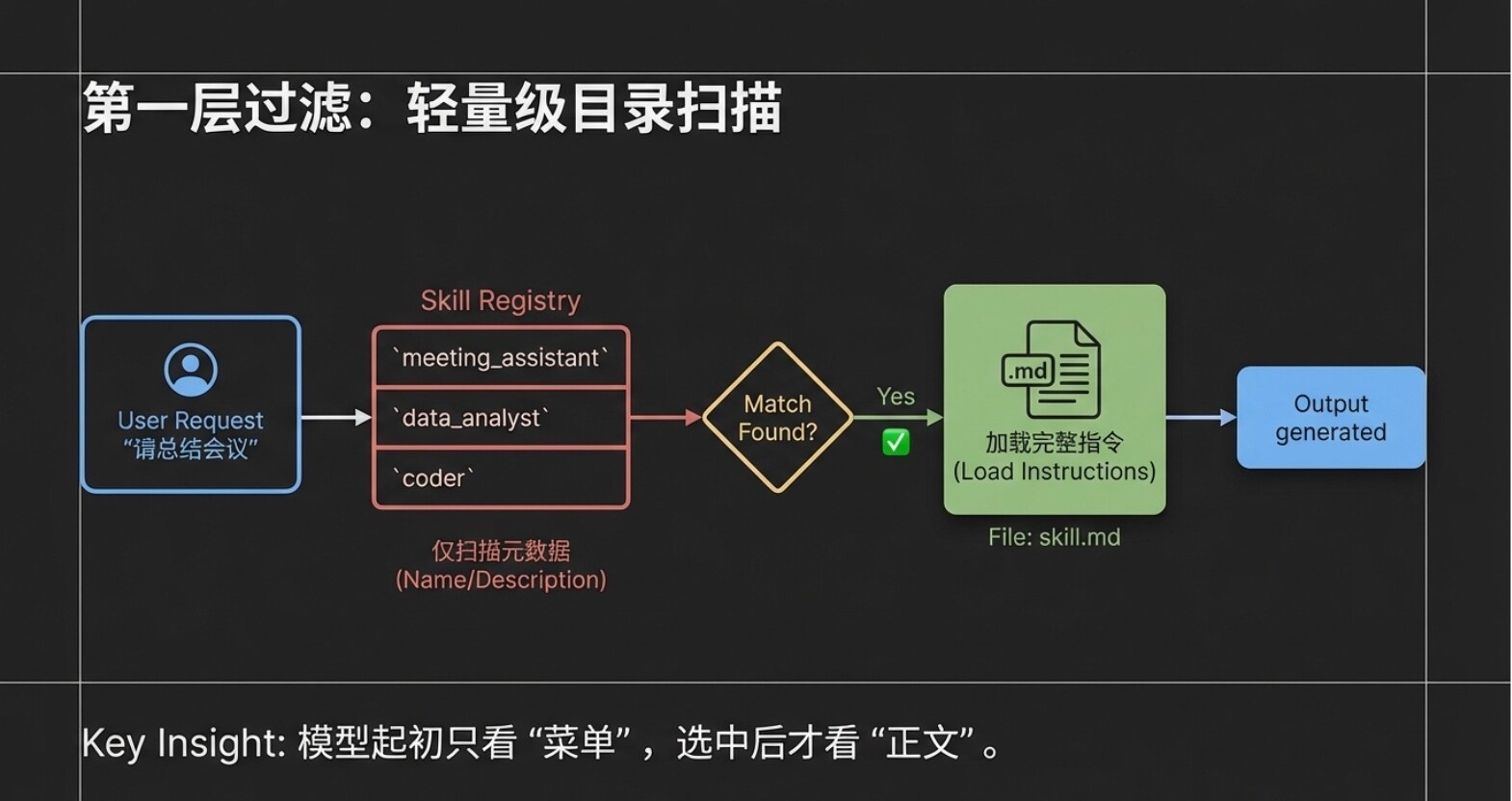
用戶輸入請求後,客戶端工具(Claude Code)不會一股腦地把所有說明文件都扔給大模型。相反,它只會把用戶的請求,連同當前系統中所有 Agent Skill 的「名稱」和「描述」(也就是我們上一章提到的 Metadata 元資料層),打包發送給大模型。 你可以想像一下,哪怕你安裝了十幾個甚至幾十個 Skill,此時大模型拿到的也僅僅是一份「輕量級的目錄」。這種設計極大地節省了模型的注意力,避免了資訊的相互干擾。
第二步:精準的意圖匹配 大模型在收到用戶請求和這份「Skill 目錄」後,會進行快速的語意分析。它發現用戶的訴求是「總結會議」,而目錄中恰好有一個名叫「會議總結助手」的 Skill,其描述完美契合該任務。 此時,大模型會把這個匹配結果告訴客戶端工具:「我發現這個任務可以用『會議總結助手』來解決。」
第三步:按需載入完整指令 得到大模型的反饋後,客戶端工具(Claude Code)才會真正進入「會議總結助手」的專屬資料夾,去讀取那個完整的 skill.md 正文。 請注意,這是一個極其關鍵的設計:只有在此時,完整的指令內容才會被讀取,而且系統只讀取這一個被選中的 Skill。 其他未被命中的 Skill 依然安靜地躺在目錄裡,不會佔用任何資源。
第四步:嚴格執行與輸出響應 最後,客戶端工具會將「用戶的原始請求」和「會議總結助手完整的 skill.md 內容」一起發送給大模型。 這一次,大模型不再是做選擇題,而是進入了執行模式。它會嚴格遵循 skill.md 裡定下的規矩(比如:必須提取參會人員、核心議題、最終決定),生成高度結構化的響應,並交由客戶端工具展示給用戶。
4. 核心機制一:按需載入與 Reference
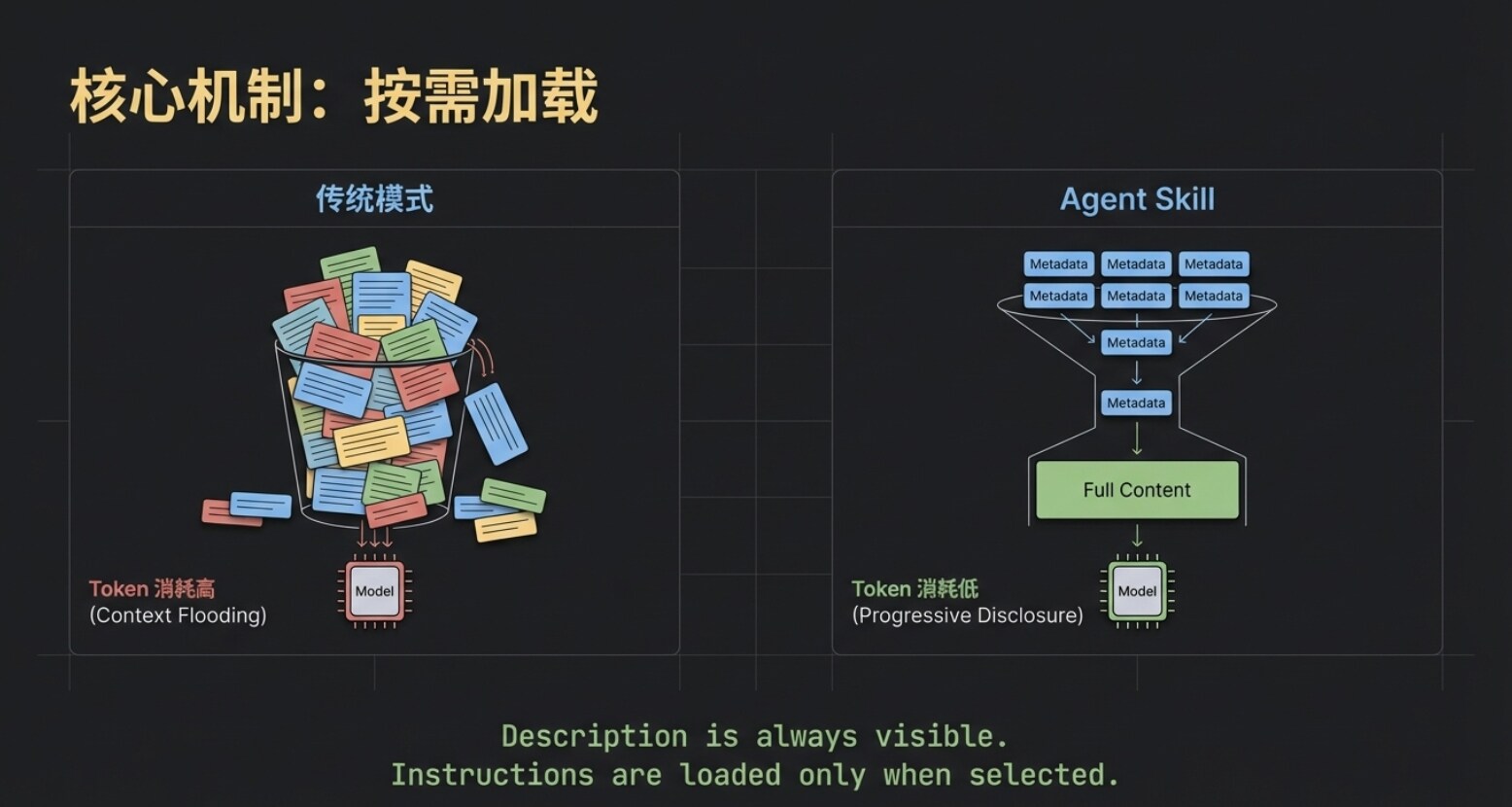
上一章的工作流,引出了 Agent Skill 的第一個核心底層機制——按需載入。
雖然所有 Skill 的名稱和描述始終對大模型可見,但具體的指令內容,只有在該 Skill 被精準命中後,才會被真正拉取到模型的上下文中。
這就極大地節省了寶貴的 Token 資源。試想一下,哪怕你同時部署了「爆款文案」、「會議總結」、「鏈上資料分析」等十幾個大體量的 Skill,模型最初也只需做一次極低消耗的「目錄檢索」。只有在選中目標後,系統才會把那份對應的 skill.md 餵給模型。這種「按需載入」,就是 Agent Skill 保持輕量和高效的第一層密碼。
然而,對於追求極致效率的進階用戶來說,僅僅做到第一層按需載入還不夠。
隨著業務的深入,我們往往希望 Skill 變得更加聰明。以「會議總結助手」為例,我們希望它不僅能簡單複述議題,還能提供增量的洞察價值:當會議決定要花錢時,它能直接在總結裡標註是否符合集團的財務合規;當涉及到外部合作時,它能自動提示潛在的法務風險。這樣一來,團隊在看總結時,一眼就能掃到關鍵的合規預警,免去了二次查閱規章制度的繁瑣。
但這在工程上帶來了一個致命矛盾:Skill 要想具備這種能力,前提是必須把冗長的《財務規定》和《法律條文》全都塞進 skill.md 檔案裡。這會導致核心指令檔案變得無比臃腫。哪怕今天開的只是一場純技術的早會,模型也被迫要載入數萬字的財務和法律「廢話」,這不僅造成了 Token 的嚴重浪費,還極易引發模型的「注意力渙散」。
那麼,能不能在按需載入的基礎上,再實現一層「按需中的按需」呢?比如,只有當會議內容真真切切聊到了「錢」,系統才把財務規定掏出來給模型看?
答案是肯定的。Agent Skill 體系中的 Reference 機制,正是為此而生。

Reference 的本質,是條件觸發的外部知識庫。我們來看看它是如何優雅地解決上述痛點的:
- 建立外部參考檔案:首先,我們在該 Skill 的目錄下新增一個獨立檔案,也就是術語中的 Reference。我們將它命名為
集團財務手冊.md,裡面詳細列明了各項報銷標準(例如:住宿補貼 500 元/晚,餐飲費人均 300 元/天等)。 - 設定觸發條件:接著,回到核心的
skill.md檔案中,新增一條專門的「財務提醒規則」。我們可以用自然語言明確約定:「僅在會議內容提及錢、預算、採購、費用等字眼時觸發。觸發後,需讀取集團財務手冊.md檔案。請根據該檔案內容,指出會議決定中的金額是否超標,並明確相應的審批人。」
完成設定後,當我們在下次會議中復盤預算分配時,一場精妙的動態協作就開始了:
- 客戶端工具掃描並向你申請使用「會議總結助手」 Skill(完成第一層按需載入)。
- 模型在閱讀會議記錄時,敏銳地捕捉到了「預算」相關的字眼,立刻觸碰了我們在
skill.md中埋下的規則。 - 此時,系統會向你發起第二次請求:「是否允許讀取
集團財務手冊.md?」(完成第二層按需載入:Reference 動態觸發)。 - 授權通過後,模型將會議內容與動態引入的財務標準進行交叉比對,最終輸出一份不僅包含「參會人員、議題、決定」,更掛載了「財務合規預警」的高質量總結。
請務必記住 Reference 的核心特徵:它是嚴格受條件約束的。反過來說,如果今天你們開的是一場探討程式碼邏輯的技術復盤會,全場與錢毫無關係,那麼這份 集團財務手冊.md 就會安靜地躺在硬碟裡,絕不會佔用哪怕一個 Token 的算力資源。
5. Script與漸進式披露機制
講完了解決資訊過載的 Reference 機制,接下來我們進入 Agent Skill 的另一個殺手級能力:程式碼執行(Script)。


