算力集中時代終結:AI訓練正從“機房”走向“網絡”
- 核心观点:低通信算法实现分布式AI训练。
- 关键要素:
- DiLoCo算法减少通信量500倍。
- 联邦优化解耦本地与全局计算。
- 成功预训练数十亿参数模型。
- 市场影响:降低AI训练门槛,促进行业民主化。
- 时效性标注:长期影响
原文作者:Egor Shulgin, Gonka協議
AI技術的快速發展已將其訓練過程推向了任何單一物理位置的極限,這迫使研究人員面對一個根本性挑戰:如何協調分佈在不同大洲(而非同一機房走廊內)的數千個處理器?答案在於更有效率的演算法——那些透過減少通訊來運作的演算法。這一轉變,由聯邦優化領域的突破所驅動,並最終結晶於DiLoCo等框架,使得組織能夠透過標準互聯網連接訓練擁有數十億參數的模型,為大規模協作式AI開發開啟了新的可能。
1. 起點:資料中心內的分散式訓練
現代AI訓練本質上是分散式的。業界普遍觀察到,擴大資料、參數和運算規模能顯著提升模型效能,這使得在單一機器上訓練基礎模型(參數達數十億)成為不可能。業界的預設解決方案是「集中式分散式」模式:在單一地點建造容納數千個GPU的專用資料中心,並透過超高速網路(如英偉達的NVLink或InfiniBand)互連。這些專用互聯技術的速度比標準網路高出幾個數量級,使得所有GPU能夠作為一個cohesive 的整體系統運作。
在此環境下,最常見的訓練策略是資料並行,即將資料集拆分到多個GPU上。 (也存在其他方法,例如管線並行或張量並行,它們將模型本身拆分到多個GPU上,這對於訓練最大的模型是必需的,儘管實現起來更複雜。)以下展示了使用小批量隨機梯度下降(SGD)的一個訓練步驟是如何工作的(同樣的原理也適用於Adam優化器):
- 複製與散佈:將模型副本載入到每個GPU上。將訓練資料分割成小批量。
- 平行計算:每個GPU獨立處理一個不同的小批量,並計算**梯度**-也就是調整模型參數的方向。
- 同步與聚合:所有GPU暫停工作,共享它們的梯度,並將其平均,以產生單一的、統一的更新量。
- 更新:將這個平均後的更新量套用到每個GPU的模型副本上,確保所有副本保持完全一致。
- 重複:移至下一個小批量,重新開始。
本質上,這是一個並行計算與強制同步不斷循環的過程。在每一步訓練之後都會發生的持續通信,只有在資料中心內部昂貴、高速的連線下才可行。這種對頻繁同步的依賴,是集中式分散式訓練的典型特徵。它在離開資料中心這個「溫室」之前,運作得非常完美。
2. 撞上南牆:巨大的通訊瓶頸
為了訓練最大的模型,組織現在必須以驚人的規模建造基礎設施,通常需要在不同城市或大洲建立多個資料中心。這種地理上的分隔造成了一個巨大的障礙。那種在資料中心內部運作良好的、逐步同步的演算法方法,當被拉伸到全球範圍時,就失效了。
問題在於網路速度。在資料中心內部,InfiniBand的資料傳輸速度可達400 Gb/s或更高。而連接遙遠資料中心的廣域網路(WAN),其速度通常接近1 Gbps。這是幾個數量級的效能差距,其根源在於距離和成本的基本限制。小批量SGD所假設的近乎瞬時的通信,與這一現實格格不入。
這種差異造成了嚴重的瓶頸。當模型參數必須在每一步之後都進行同步時,強大的GPU大部分時間都處於閒置狀態,等待資料緩慢地爬過低速網路。結果是:AI社群無法利用全球分佈的大量運算資源——從企業伺服器到消費級硬體——因為現有演算法需要高速、集中式的網路。這代表著一個巨大且尚未開發的算力寶庫。
3. 演算法轉變:聯邦最佳化
如果頻繁通訊是問題所在,那麼解決方案就是減少通訊。這項簡單的見解奠定了演算法轉變的基礎,它藉鑒了聯邦學習的技術——該領域最初專注於在終端設備(如手機)上的去中心化資料上訓練模型,同時保護隱私。其核心演算法聯邦平均(FedAvg)表明,透過允許每個設備在本地執行多次訓練步驟後再發送更新,可以將所需的通訊輪數減少幾個數量級。
研究人員意識到,在同步間隔之間做更多獨立工作這一原則,是解決地理分散式設定中效能瓶頸的完美方案。這導致了聯邦優化(FedOpt)框架的出現,它採用雙優化器方法,將本地計算與全局通訊解耦。
此框架使用兩種不同的優化器運作:
- 內部優化器(如標準SGD)在每個機器上運行,在其本地資料切片上執行多次獨立的訓練步驟。每個模型副本都自行取得顯著進展。
- 外部優化器處理不頻繁的全域同步。在經過多次本地步驟後,每個工作節點計算其模型參數的總變化量。這些變化被聚合起來,外部最佳化器利用這個平均後的更新量來調整下一週期的全域模型。
這種雙重優化器架構從根本上改變了訓練的動態過程。它不再是所有節點之間頻繁的、逐步的通信,而變成了一系列延長的、獨立的計算期,之後跟隨一個單一的聚合更新。這場源自於隱私研究的演算法轉變,為實現低速網路上的訓練提供了至關重要的突破。問題是:它能用於大規模語言模式嗎?
以下為聯邦最佳化框架示意圖:本地訓練與週期性全域同步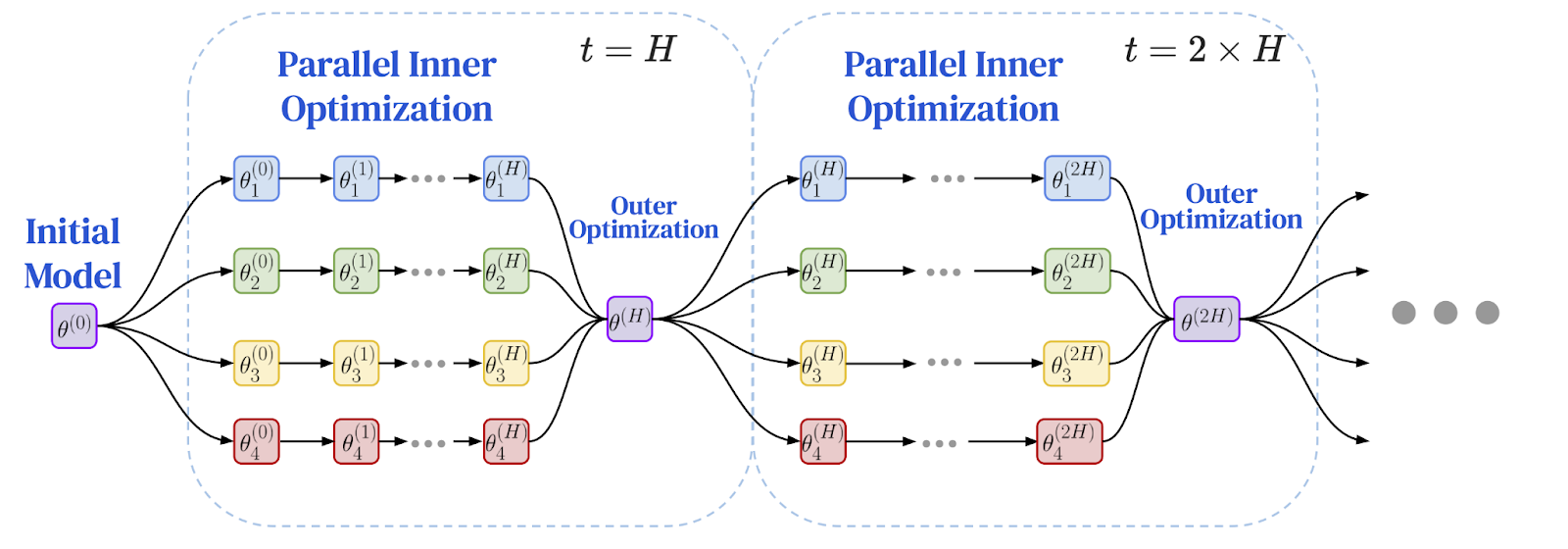
圖片來源:Charles, Z., et al. (2025). "Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo." arXiv:2503.09799
4. 突破性進展:DiLoCo證明其大規模可行性
答案以DiLoCo(分散式低通訊)演算法的形式出現,它證明了聯邦最佳化對於大語言模型的實際可行性。 DiLoCo提供了一套具體的、經過精心調優的方案,用於在低速網路上訓練現代Transformer模型:
- 內部優化器: AdamW,這是用於大語言模型的尖端優化器,在每個工作節點上運行多次本地訓練步驟。
- 外部優化器: Nesterov動量,一種強大且易於理解的演算法,處理不頻繁的全域更新。
最初的實驗表明,DiLoCo能夠匹配完全同步的資料中心訓練的效能,同時將節點間的通訊量減少高達500倍。這是透過網路訓練巨型模型可行的實作證明。
這項突破迅速獲得了關注。開源實作OpenDiLoCo複現了原始結果,並利用Hivemind函式庫將該演算法整合到一個真正的點對點框架中,使得該技術更容易使用。這一勢頭最終促成了PrimeIntellect 、 Nous Research和FlowerLabs等組織成功進行的大規模預訓練,它們展示了使用低通訊演算法透過網路成功預訓練了數十億參數模型。這些開創性的努力將DiLoCo式訓練從一個有前途的研究論文,轉變為在中心化提供者之外建立基礎模型的已驗證方法。
5. 前沿探索:先進技術與未來研究
DiLoCo的成功激發了新一輪的研究熱潮,專注於進一步提升效率和規模。使此方法成熟的關鍵一步是DiLoCo縮放定律的發展,該定律確立了DiLoCo的性能能夠隨著模型規模的增長而可預測且穩健地縮放。這些縮放定律預測,隨著模型變得更大,一個經過良好調優的DiLoCo可以在固定的計算預算下,效能超越傳統的資料並行訓練,同時使用的頻寬少幾個數量級。
為了處理1000億參數以上規模的模型,研究人員透過像DiLoCoX這樣的技術擴展了DiLoCo的設計,它將雙優化器方法與管線並行結合。 DiLoCoX使得在標準的1 Gbps網路上預訓練一個1070億參數模型成為可能。進一步的改進包括串流DiLoCo (它重疊通訊和計算以隱藏網路延遲)和非同步方法(防止單一慢速節點成為整個系統的瓶頸)。
創新也發生在演算法核心層面。對像Muon這樣的新型內部優化器的研究催生了MuLoCo ,這是一個變體,允許將模型更新壓縮到2比特且性能損失可忽略不計,從而實現了數據傳輸量減少8倍。或許最雄心勃勃的研究方向是網路上的模型並行,將模型本身拆分到不同的機器上。該領域的早期研究,例如SWARM並行,開發了將模型層分佈到由低速網路連接的異質且不可靠設備上的容錯方法。基於這些概念,像Pluralis Research這樣的團隊已經證明了訓練數十億參數模型的可能性,其中不同的層託管在完全處於不同地理位置的GPU上,這為在僅由標準互聯網連接的分佈式消費級硬體上訓練模型打開了大門。
6. 信任挑戰:開放網路中的治理
隨著訓練從受控的資料中心轉向開放、無需許可的網絡,一個根本性問題浮現了:信任。在一個沒有中央權威的真正去中心化系統中,參與者如何驗證他們從其他人那裡收到的更新是合法的?如何防止惡意參與者毒化模型,或懶惰的參與者為他們從未完成的工作索取獎勵?這個治理問題是最後的障礙。
一道防線是拜占庭容錯——一個來自分散式運算的概念,旨在設計即使部分參與者故障或主動惡意行為也能正常運作的系統。在集中式系統中,伺服器可以套用穩健的聚合規則來丟棄惡意更新。這在點對點環境中更難實現,因為那裡沒有中央聚合器。取而代之的是,每個誠實節點必須評估來自其鄰居的更新,並決定信任哪些、丟棄哪些。
另一種方法涉及密碼學技術,以驗證取代信任。一個早期的想法是學習證明(Proof-of-Learning),提議參與者記錄訓練檢查點以證明他們投入了必要的計算。其他技術如零知識證明(ZKPs)允許工作節點證明他們正確執行了所需的訓練步驟,而無需透露底層數據,儘管其當前的計算開銷對於驗證當今大規模基礎模型的訓練仍是一個挑戰。
前瞻:一個新AI範式的黎明
從高牆聳立的資料中心到開放的互聯網,這段旅程標誌著人工智慧創建方式發生了深刻轉變。我們始於集中式訓練的物理極限,當時進步取決於對昂貴的、同地協作硬體的獲取。這導致了通訊瓶頸,一堵使得在分散式網路上訓練巨型模型不切實際的牆。然而,這堵牆並非被更快的線纜打破,而是被更有效率的演算法所攻克。
這場植根於聯邦優化並由DiLoCo具體化的演算法轉變,證明了減少通訊頻率是關鍵。這項突破正被各種技術迅速推進:建立縮放定律、重疊通訊、探索新型優化器,甚至在網路上並行化模型本身。由多元化的研究者和公司生態系統成功預訓練數十億參數模型,正是這種新典範力量的證明。
隨著信任挑戰透過魯棒防禦和密碼學驗證得到解決,道路正在變得清晰。去中心化訓練正在從一個工程解決方案,演變為一個更開放、協作和可訪問的AI未來的基礎支柱。它預示著一個世界,在那裡,建立強大模型的能力不再局限於少數科技巨頭,而是分佈在全球,釋放所有人的集體運算力量和智慧。
參考文獻
McMahan, HB, et al. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data . International Conference on Artificial Intelligence and Statistics (AISTATS).
Reddi, S., et al. (2021). Adaptive Federated Optimization . International Conference on Learning Representations (ICLR).
Jia, H., et al. (2021). Proof-of-Learning: Definitions and Practice . IEEE Symposium on Security and Privacy.
Ryabinin, Max, et al. (2023). Swarm parallelism: Training large models can be surprisingly communication-efficient . International Conference on Machine Learning (ICML).
Douillard, A., et al. (2023). DiLoCo: Distributed Low-Communication Training of Language Models .
Jaghouar, S., Ong, JM, & Hagemann, J. (2024). OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training .
Jaghouar, S., et al. (2024). Decentralized Training of Foundation Models: A Case Study with INTELLECT-1 .
Liu, B., et al. (2024). Asynchronous Local-SGD Training for Language Modeling .
Charles, Z., et al. (2025). Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo .
Douillard, A., et al. (2025). Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch .
Psyche Team. (2025). Democratizing AI: The Psyche Network Architecture . Nous Research Blog.
Qi, J., et al. (2025). DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster .
Sani, L., et al. (2025). Photon: Federated LLM Pre-Training . Proceedings of the Conference on Machine Learning and Systems (MLSys).
Thérien, B., et al. (2025). MuLoCo: Muon is a practical inner optimizer for DiLoCo .
Long, A., et al. (2025). Protocol Models: Scaling Decentralized Training with Communication-Efficient Model Parallelism .