
去中心化AI推理的核心挑戰:如何向全網證明你沒有「作弊」?
- 核心观点:去中心化LLM需验证节点模型真实性。
- 关键要素:
- GPU非确定性导致输出比较困难。
- 经济机制惩罚作弊,声誉归零。
- 三种验证方案防范模型替换攻击。
- 市场影响:提升去中心化AI网络可信度。
- 时效性标注:中期影响。
原文作者:Anastasia Matveeva, Gonka協定共同創辦人
在上一篇文章中,我們探討了LLM去中心化推理中安全與表現的根本矛盾。今天,我們將兌現承諾,深入探討一個核心問題:在一個開放網路中,你如何真正驗證某個節點確實運行了它聲稱的那個精確模型,而沒有偷梁換柱?
01. 為什麼驗證如此困難
要理解驗證機制,不妨回顧Transformer在執行推理時的內部過程。當輸入令牌被處理時,模型的最後一層會產出logits-即詞彙表中每個令牌原始的、未歸一化的分數。這些logits隨後透過softmax函數轉換為機率,從而在所有可能的下一個代幣上形成一個機率分佈。在每一個生成步驟中,都從此分佈中抽樣一個令牌,以繼續產生序列。
在深入探討潛在的攻擊向量和具體的驗證實施方案之前,我們首先需要先理解驗證本身為何困難。
問題的根源在於GPU的非確定性。即使是相同的模型和輸入,在不同的硬體、甚至同一裝置上,由於浮點數精度等問題,也可能產生略微不同的輸出。
GPU的非確定性使得直接比較輸出令牌序列變得沒有意義。因此,我們需要檢視Transformer的內部運算過程。一個自然的選擇是比較輸出層,即模型詞彙表上的機率分佈是否接近。為了確保我們是在比較同一序列的機率分佈,我們的驗證程序要求驗證者必須完全復現執行器所產生的完全相同令牌序列,然後逐一產生步驟地比較這些機率分佈。這個過程將會產出一個驗證存證,用來證明模型的真實性。
然而,機率性也帶來了微妙平衡:我們既要懲罰持續作弊者,又要避免誤傷那些只是運氣不好、產生小機率輸出的誠實節點。閾值設得太嚴,誤殺好人;設得太鬆,放過壞人。
02. 作弊的經濟帳:收益與風險
潛在收益:誘惑巨大
最直接的攻擊是「模型替換」。假設網路部署需要大量算力的Qwen3-32B模型,一個理性節點可能會想:“如果我偷偷運行小得多的Qwen2.5-3B模型,把省下的算力差價裝進口袋呢?”
用30億參數模型冒充320億參數模型,算力成本可能降低一個數量級。如果你能欺騙驗證系統,就等於你拿著高級算力的報酬,卻交付廉價算力的結果。
更狡猾的攻擊者可能會使用量化技術,聲稱運行FP8精度,但實際上使用的是INT4量化。性能差異可能不那麼顯著,但成本節約依然可觀,且輸出可能足夠相似,以至於可以通過簡單的驗證。
在更複雜的層面上,也存在預填充攻擊。這種攻擊允許攻擊者為廉價模型的輸出產生證明,彷彿該輸出是由網路所期望的完整模型產生的一樣。其工作原理如下:
例如,鏈上達成共識,部署具有特定參數集的Qwen3-235B。
1. 執行器使用Qwen2.5-3B產生序列:`[Hello, world, how, are, you]`。
2. 執行器透過單次推理前向傳播,為這些完全相同的令牌計算Qwen3-235B的存證:`[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`。
3. 執行器提交Qwen3-235B的機率作為證明,聲稱該推理來自Qwen3-235B。
在這種情況下,機率來自於正確的模型,使得它們看起來是合法的,但實際的序列生成過程成本卻低廉得多。由於完整模型在理論上也有可能產生與較小模型相同的輸出,因此從驗證的角度來看,結果可能看起來完全合法。
潛在損失:代價更高
雖然欺騙系統可能帶來相當可觀的利益,但潛在的損失也同樣巨大。作弊者要解決的真正難題不是透過單次驗證,而是長期、有系統地逃避偵測,使得他們在計算上獲得的「折扣」超過網路可能施加的懲罰。
在Gonka網路中,我們設計了一套精妙的經濟抑制機制:
- 人人都是驗證者:每個節點都按權重驗證部分網路推理
- 聲譽系統:新節點聲譽值為0,所有推理都被驗證。隨著持續誠實參與,聲譽成長,驗證頻率可降至1%
- 懲罰機制:作弊被抓,聲譽歸零,需要約30天重建
- 紀元結算:在約24小時的紀元內,只要被抓到統計顯著次數的作弊,整個紀元的獎勵全部沒收
這意味著,試圖節省50%算力的作弊者,反而可能損失100%的收益。這種「得不償失」的風險,使得作弊在經濟上變得極不划算。我們透過驗證機制要解決的問題,並非捕捉每一個有疑問的推理,而是劃清一條界線,確保我們能夠以足夠高的機率持續抓住詐欺者,同時又不損害誠實參與者的聲譽。
03. 如何抓住作弊者?三種驗證方案
那麼,我們該如何捕捉這些攻擊呢?這個問題可以分為兩部分:1) 驗證證明中的分佈是否接近聲稱模型所產生的分佈;2) 確認輸出文本確實是基於所提交的存證產生的。
方案一:機率分佈比對(核心基礎)
當執行器產生推理輸出(例如`[Hello, world, how, are, you]`)時,他們會記錄一個驗證存證,其中包含最終輸出以及輸出序列中每個位置的前K個機率(例如,對於第一個位置是`[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`,等等,等等。驗證者隨後強制其模型遵循完全相同的令牌序列,並計算每個位置上機率的歸一化距離\( d_i \):
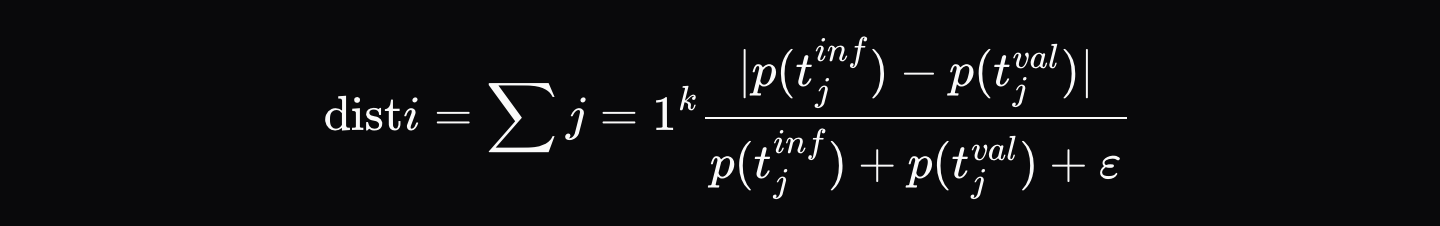
其中\( p_{\text{artifact},ij} \) 是推理存證中該位置第j個最可能令牌的機率,而\( p_{\text{validator},ij} \) 是驗證者分佈中**同一個令牌**的機率。
最終的距離測量是每個令牌距離的平均和:
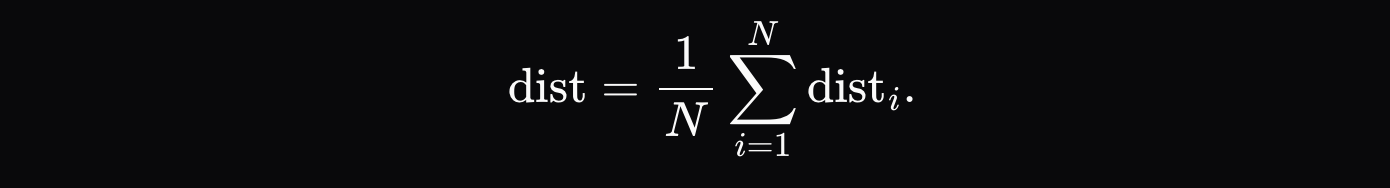
對於捕捉完全不同的模型,甚至是同一模型的不同量化版本,比較前K機率被證明是足夠的。如下方的圖表所示,當我們在Qwen3-32B FP8與INT4量化版本之間進行測試時,我們實現了99%的詐欺偵測率,且零誤報。其他模型的機率分佈差異也足夠大,使得作弊行為能夠在一個紀元內被輕鬆發現,而誠實的參與者則保持安全。
下圖為Qwen3-32B FP8 (誠實) vs INT4量化(詐欺)的成功與失敗驗證次數比較:
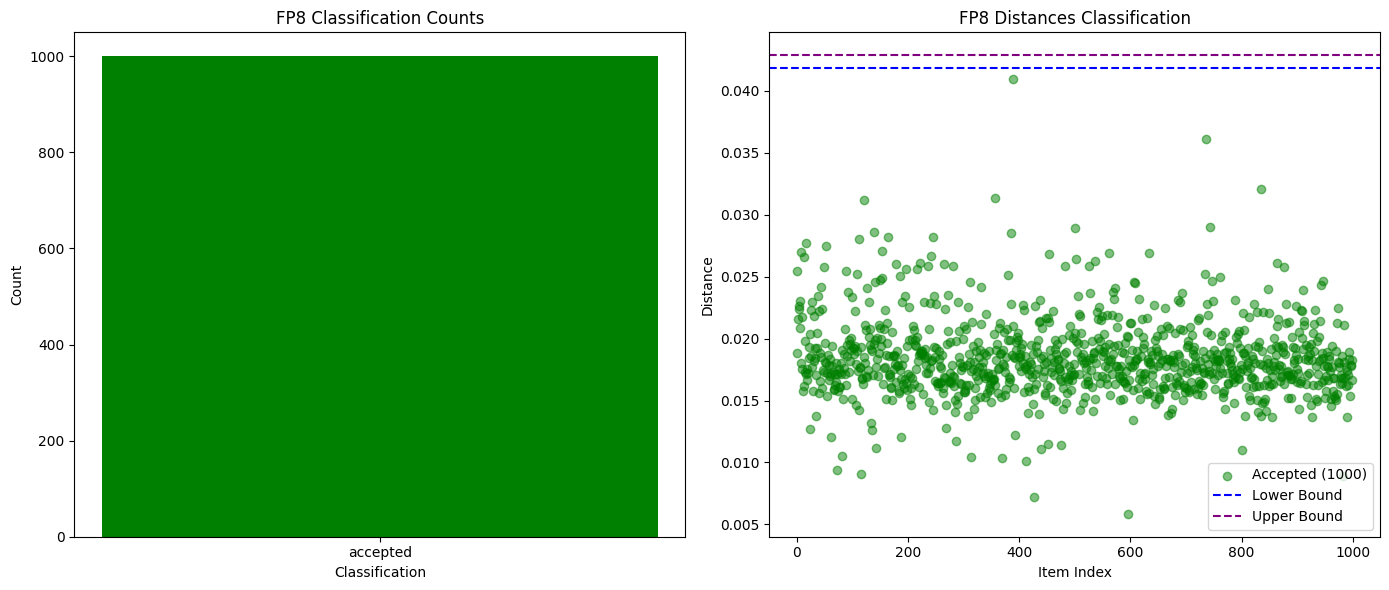
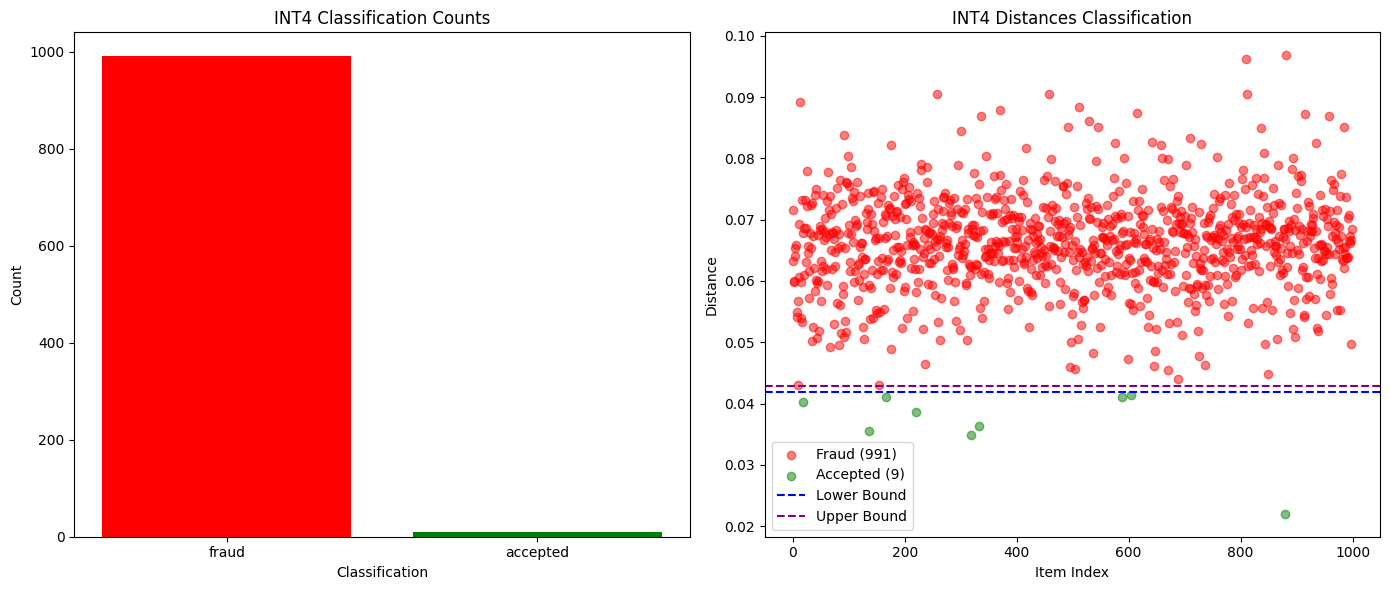
下圖為Qwen3-32B FP8 (誠實) vs INT4量化(詐欺))的機率分佈距離隨序列長度的變化:
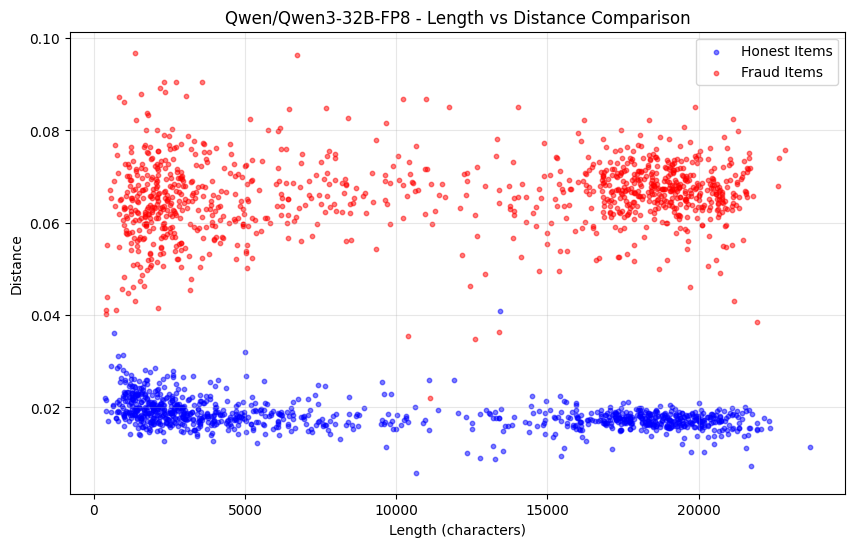
然而,僅靠這種方法的缺點是它無法防範預填充攻擊。如果機率確實與完整模型的分佈相匹配,但序列是透過一個較小的模型產生的,我們還有幾種額外的方法來捕捉這種情況。
方案二:困惑度偵測(防禦預填充攻擊)
除了驗證存證是否來自正確模型,我們還檢查輸出文字是否「可能」來自該存證的機率分佈。
如果序列由不同模型生成,其相對於聲稱模型機率分佈的困惑度會異常高。測試中,區分Qwen2.5-7B與Qwen2.5-3B預填充攻擊,困惑度差異顯著。
捕捉預填充攻擊最直觀的方法是檢查困惑度:除了驗證存證是否由聲稱的模型產生之外,我們還可以檢查輸出文字**是否很可能**是從提交的分佈中產生的:
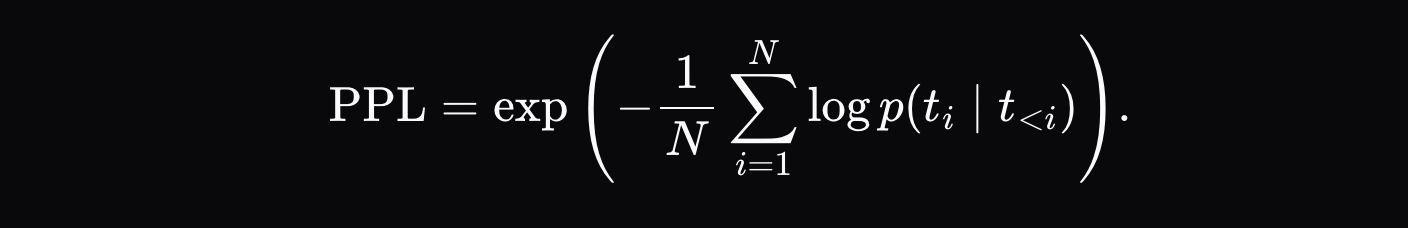
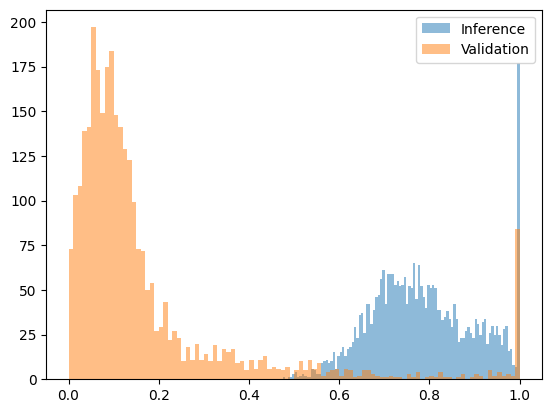
如果困惑度過高,則表示該序列很可能由不同的模型產生。這種方法對於防禦使用顯著不同模型的攻擊效果很好。當我們測試由Qwen2.5-3B產生但聲稱來自Qwen2.5-7B的序列時,困惑度的差異足夠明顯,可以設定清晰的閾值。下圖顯示了一個經過變換的困惑度函數,將其擬合到[0, 1]區間內,其中7B模型的輸出大部分落在0.2以下,而預填充攻擊的輸出(3B模型輸出配7B模型機率)全部落在0.4以上。
下圖為Qwen2.5-7B (誠實) vs Qwen2.5-3B預填攻擊(詐欺)變換後的困惑度函數:
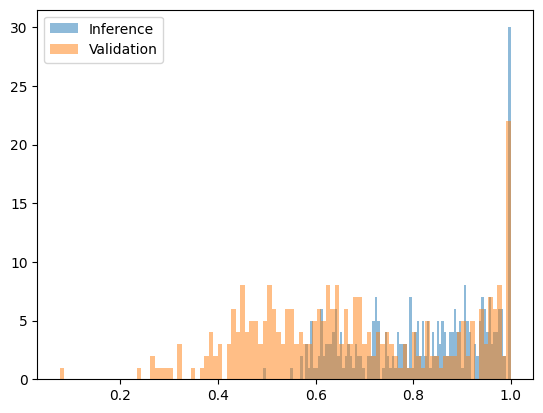
然而,與相似模型以及同一模型的不同量化版本相比,困惑度檢測有其限制。例如,比較Qwen2.5-7B Base的w8a16與w8a8量化版本時,並未顯示出明顯的差異。
下圖為Qwen2.5-7B w8a16 (誠實) vs w8a8量化(欺詐))變換後的困惑度函數:
好在,使用相似模型進行攻擊通常在經濟上是沒有意義的。如果他們運行一個成本是聲稱模型70-90%的模型,再加上對真實模型進行一次評分計算,他們實際花費的計算資源可能比老實實運行真實模型還要多。
需要指出的是,單一由誠實參與者產生的低機率輸出不會顯著降低其聲譽。如果這種低機率輸出對於該參與者來說不是持續出現的,即它只是一個偶然的統計離群值,那麼他們在紀元結束時仍然會獲得全額獎勵。
方案三:RNG種子綁定(確定性方案)
這是最徹底的解決方案:將輸出序列與隨機數產生器種子綁定。
執行器使用源自請求的確定性種子(如`run_seed = SHA256(user_seed || inference_id_from_chain)`)初始化RNG。驗證存證包含此種子和機率分佈。
驗證者使用相同種子驗證:如果序列確實來自聲稱模型的機率分佈,則必定能復現相同輸出。這提供了確定性的「是/否」答案,能徹底杜絕預填充攻擊,且驗證成本遠低於完整推理。
04. 展望:通往去中心化AI的未來
我們分享這些實踐與思考,源自於對去中心化AI未來的堅定信念。隨著AI模型日益滲透社會生活,將模型輸出與特定參數綁定的需求只會越來越強。
Gonka網路選擇的驗證方案在實務上證明可行,其組件也可復用於其他需要驗證AI推理真實性的場景。
去中心化AI不僅是技術的演進,更是生產關係的改變──它試圖在開放環境中,用演算法和經濟機制解決最基本的信任問題。這條路還很長,但我們已邁出堅實的一步。


