
AI đang tạo ra "người nghèo thông tin" mới?
- Quan điểm cốt lõi: AI khiến câu trả lời trở nên rẻ và dễ kiếm, nhưng thứ thực sự khan hiếm đã trở thành "khả năng phán đoán câu trả lời". Người nghèo thông tin mới không phải là người bị loại trừ khỏi AI, mà là người có câu trả lời nhưng thiếu khả năng phán đoán, không thể biến nó thành cơ hội, dẫn đến một bất bình đẳng mới dựa trên giáo dục, kinh nghiệm và quyền hạn.
- Các yếu tố then chốt:
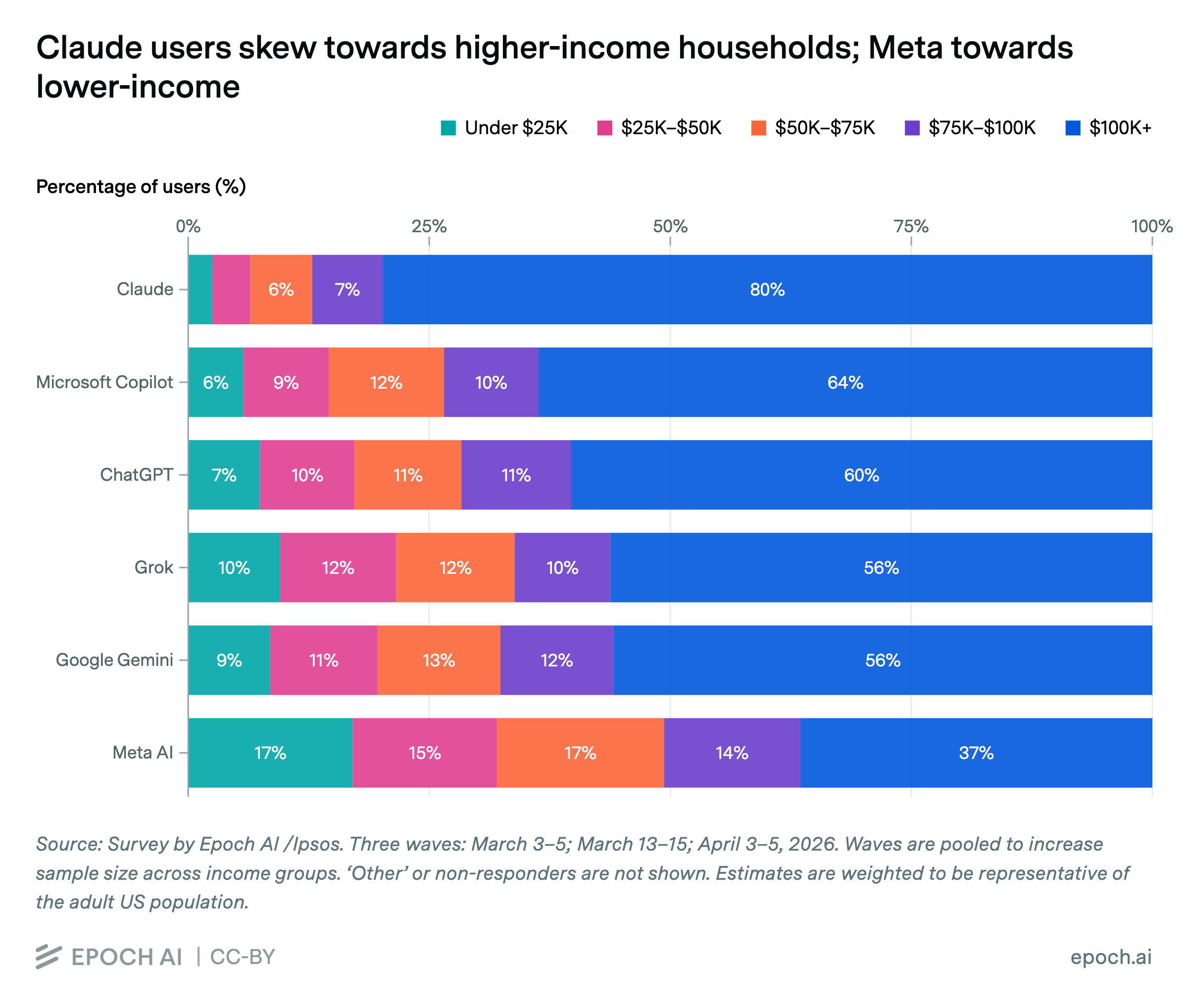
- Phân luồng đầu vào: Khảo sát của Epoch AI cho thấy khoảng 80% người dùng Claude đến từ các gia đình có thu nhập trên 100.000 USD/năm, trong khi 32% người dùng Meta AI đến từ các gia đình có thu nhập dưới 50.000 USD/năm, phản ánh các rào cản về đầu vào và giá cả của các công cụ khác nhau đang sàng lọc người dùng.
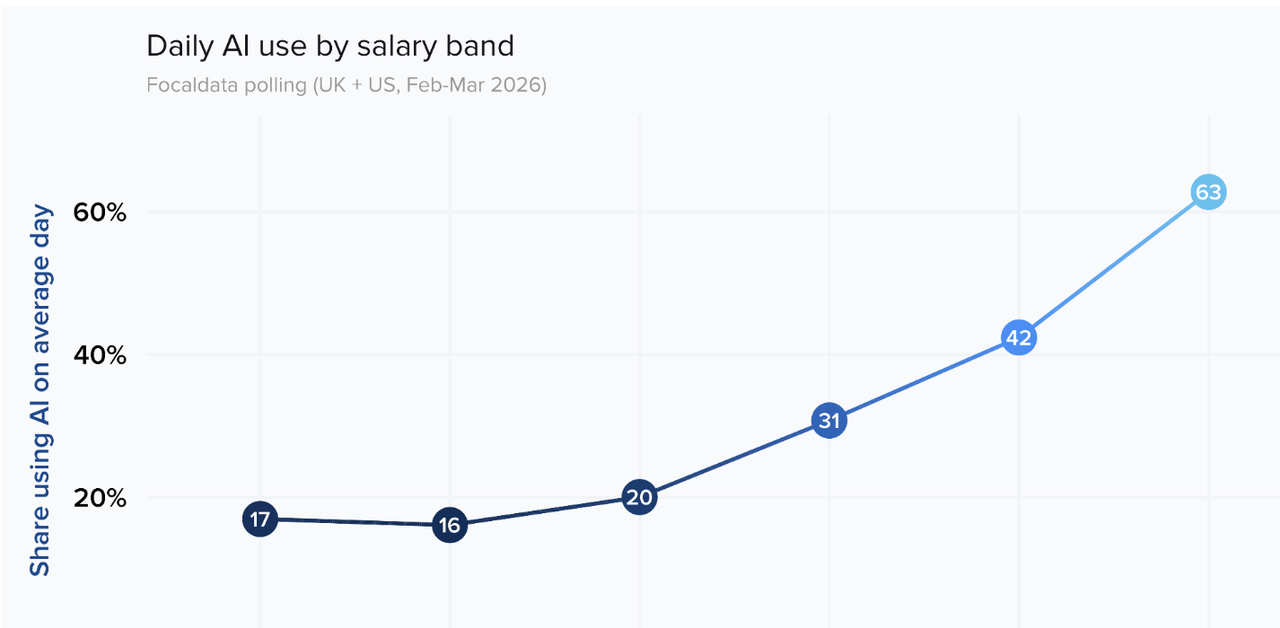
- Khoảng cách sử dụng nơi làm việc: Khảo sát lao động Anh-Mỹ (năm 2026) chỉ ra rằng 63% người lao động ở nhóm lương cao nhất sử dụng AI hàng ngày, trong khi nhóm thấp nhất chỉ là 16%-17%. Yếu tố thực sự thúc đẩy việc sử dụng không phải là mức lương, mà là độ tuổi, thâm niên và đào tạo.
- Thiếu đào tạo: Tính đến đầu năm 2026, chỉ 14% nhân viên được đào tạo AI chính thức, 2/3 chưa từng được đào tạo bất kỳ hình thức nào. Đào tạo AI về bản chất là sự phân bổ quyền hạn, quyết định ai có thể bước vào quỹ đạo tăng trưởng năng suất.
- Khả năng phán đoán là tối thượng: Những người sử dụng AI nhiều nhất là nhân viên có thâm niên 2-10 năm, chứ không phải là người trẻ nhất. Giá trị của AI phụ thuộc rất nhiều vào kinh nghiệm và khả năng phán đoán sẵn có của người dùng; người thiếu khả năng phán đoán dễ dàng chấp nhận toàn bộ đầu ra, thậm chí cản trở sự phát triển của chính họ.
- Giới hạn của hiệu ứng bình quyền: Thí nghiệm cho thấy AI có tác dụng nâng cao hơn đối với người có kỹ năng thấp, nhưng dữ liệu thực tế lại cho thấy việc áp dụng, bối cảnh và khả năng phán đoán vốn đã bất bình đẳng. Công nghệ có thể thu hẹp khoảng cách trong phòng thí nghiệm, nhưng lại có thể mở rộng khoảng cách trong thực tế.
- Bất bình đẳng cấu trúc: AI sở hữu các đặc tính kỹ thuật của sự bình quyền, nhưng lại vận hành trong một cấu trúc xã hội bất bình đẳng. Tác động của nó bao trùm mọi công việc phụ thuộc vào phán đoán và ngôn ngữ, tốc độ phân hóa có thể nhanh hơn và sâu hơn, lợi ích sẽ không đến cùng một lúc.
Điều tàn khốc nhất của AI không phải là nó không cho người nghèo câu trả lời.
Ngược lại, nó cho mọi người câu trả lời.
Nó cung cấp cho sinh viên khung bài luận, cho nhân viên mẫu email, cho doanh nhân kế hoạch kinh doanh, và cho người thường những lời giải thích pháp lý, lời khuyên đầu tư, và định hướng nghề nghiệp. Lần đầu tiên, câu trả lời trở nên rẻ mạt, dồi dào và trông có vẻ đúng đắn đến vậy.
Nhưng vấn đề nằm ở chỗ: Khi câu trả lời ai cũng có thể có được, thứ thực sự khan hiếm không còn là câu trả lời nữa, mà là khả năng đánh giá câu trả lời đó.
Người nghèo thông tin mới, không phải là những người bị ngăn cản bởi AI, mà là những người đã có câu trả lời, nhưng không có khả năng đánh giá câu trả lời và cũng không có điều kiện để biến câu trả lời đó thành cơ hội thực sự.

I. Sự chênh lệch thông tin trong kỷ nguyên AI
Người nghèo thông tin trong kỷ nguyên Internet là những người bị loại trừ khỏi mạng lưới. Giải pháp có vẻ rõ ràng: Kết nối internet, phổ cập thiết bị, nâng cao tỷ lệ biết chữ. Thời kỳ công cụ tìm kiếm phức tạp hơn một chút, bạn cần học cách tinh chỉnh từ khóa, sàng lọc nguồn, đánh giá độ tin cậy, và tốt nhất là biết một chút tiếng Anh. Nhưng rào cản là hữu hình và có thể định lượng được.
Sự chênh lệch thông tin trong kỷ nguyên AI có cấu trúc hoàn toàn khác.
Các mô hình ngôn ngữ lớn không phải là công cụ tìm kiếm, chúng trực tiếp tạo ra kết luận cho bạn. Bạn không cần phải "tìm" câu trả lời nữa - câu trả lời sẽ được tổ chức thành các đoạn văn mạch lạc, các bước rõ ràng, giọng điệu tự tin, và được đưa đến trước mắt bạn một cách chủ động. Bề ngoài, rào cản dường như đã giảm đi đáng kể. Nhưng ẩn sâu bên trong là một cấu trúc lạnh lùng: Khi câu trả lời trở nên rẻ mạt, sai lầm cũng trở nên rẻ mạt tương tự; và khả năng phân biệt "liệu câu trả lời này có đáng tin cậy hay không" lại trở nên khan hiếm và có giá trị hơn bao giờ hết.
Mọi cuộc lan tỏa của công nghệ phổ quát trong lịch sử đều tuân theo cùng một logic: Công nghệ mới thưởng cho những người đã sở hữu vốn bổ trợ. In ấn mang lại lợi ích cho người biết chữ trước; máy tính mang lại lợi ích cho người biết sử dụng phần mềm văn phòng, biết lập trình trước; Internet mang lại lợi ích cho người giỏi tiếng Anh, thành thạo kỹ năng tra cứu trước. Vốn bổ trợ cho AI bao gồm nền tảng giáo dục, kiến thức chuyên môn, tư duy phản biện, sự ủy quyền của tổ chức, khả năng chi trả, và thứ khó định lượng nhất - khả năng phán đoán.
Công nghệ mới hiếm khi thưởng cho những người cần nó nhất trước tiên. Nó thường thưởng cho những người có thể tận dụng nó tốt nhất trước tiên.
II. Điều đầu tiên bị phân hóa, là con đường đến với AI
Vết nứt đầu tiên của sự bất bình đẳng đã được tạo ra trước khi bạn mở ứng dụng.
Vào tháng 4 năm 2026, Viện nghiên cứu AI Epoch AI cùng với công ty thăm dò ý kiến Ipsos đã công bố một cuộc khảo sát bảng câu hỏi với khoảng 5000 người trưởng thành tại Mỹ. Ba vòng câu hỏi xoay quanh một vấn đề tưởng chừng bình thường: Trong tuần qua, bạn đã sử dụng những dịch vụ AI nào? Nhưng câu trả lời mang lại không chỉ đơn giản là sở thích sản phẩm, mà là một bản đồ về sự đan xen giữa thu nhập, điểm truy cập và sự phân phối.
Trong số người dùng hoạt động hàng tuần của Claude, khoảng 80% đến từ các gia đình có thu nhập trên 100.000 đô la Mỹ/năm; trong số người dùng Meta AI, tỷ lệ này chỉ là 37%. Ngược lại, khoảng 32% người dùng Meta AI đến từ các gia đình có thu nhập dưới 50.000 đô la Mỹ/năm, trong khi tỷ lệ này ở người dùng Claude chỉ là 7%.
Những con số này quan trọng, không phải vì chúng chứng minh "người giàu dùng AI cao cấp, người nghèo dùng AI miễn phí". Đó là cách đọc nông cạn nhất. Điều đáng hỏi hơn là: Tại sao những người khác nhau lại gặp những AI khác nhau trong cuộc sống hàng ngày?
Một người dùng AI để kết hợp bữa tối từ đồ ăn thừa trong tủ lạnh, chỉnh sáng nền ảnh, viết lại tin nhắn cho lịch sự hơn. Người kia dùng AI để tổng hợp phỏng vấn khách hàng, so sánh báo giá nhà cung cấp, chọn ra những giả định yếu trong báo cáo. Cả hai đều đang sử dụng một công nghệ. Nhưng một cách sử dụng dừng lại ở sự tiện lợi, cách kia đi vào vòng tuần hoàn của thu nhập, vị trí công việc và quyền thương lượng.
Sự khác biệt không chỉ nằm ở người dùng, mà còn ở điểm truy cập. Lộ trình sử dụng Claude đòi hỏi phải chủ động tìm kiếm, so sánh sản phẩm, hiểu sự khác biệt về năng lực, lựa chọn gói trả phí, và sau đó tích hợp công cụ vào quy trình làm việc - mỗi bước đều là một bộ lọc. Lộ trình của Meta AI gần như ngược lại: Nó được tích hợp sẵn trong nền tảng mạng xã hội, miễn phí, ít ma sát, người dùng thường gặp nó một cách thụ động trong lúc lướt tin, nhắn tin hoặc xem ảnh.
Đây không phải là một thị trường về thị hiếu, mà là một thị trường về sự phân phối. Người dùng tưởng chừng đang chọn công cụ, nhưng giá cả và điểm truy cập của công cụ cũng đang chọn người dùng.
Nguồn: epoch.ai
III. Sau đó bị phân hóa, là bối cảnh sử dụng AI
Ngay cả khi bạn tìm được một công cụ AI tốt, làn sóng phân hóa thứ hai đang chờ bạn tại công ty.
Ở những văn phòng thông thường, sự xuất hiện của AI hiếm khi xuất hiện dưới dạng "thông báo sa thải". Trước tiên, nó đảm nhận việc ghi chú cuộc họp, nháp email, sắp xếp bảng tính, phân loại khách hàng và bản thảo báo cáo sơ bộ. Đối với người quản lý, việc tự động hóa này giải phóng thời gian, để họ đưa ra phán đoán; còn đối với nhân viên mới và nhân viên cấp thấp, việc tự động hóa này lấy đi, chính là cơ hội để họ chứng minh bản thân, rèn luyện khả năng phán đoán và bước vào các công việc cấp cao hơn.
Dữ liệu còn lạnh lùng hơn bối cảnh này: Khảo sát theo dõi AI về lực lượng lao động Anh-Mỹ do Financial Times phối hợp với các viện nghiên cứu thực hiện (tháng 2-3/2026, bao phủ hơn 4000 người được hỏi ở Anh và Mỹ) cho thấy, 63% người lao động ở mức lương cao nhất sử dụng AI trong ngày làm việc thông thường, trong khi tỷ lệ này ở hai nhóm lương thấp nhất chỉ lần lượt là 17% và 16%. Đây không phải là một con dốc thoai thoải, đây là một vách đá.
Phát hiện quan trọng hơn nằm ở các yếu tố thúc đẩy. Phân tích hồi quy của cuộc khảo sát nghề nghiệp này cho thấy, ảnh hưởng của mức lương đến tỷ lệ sử dụng AI gần như biến mất sau khi kiểm soát các biến số khác - bốn yếu tố thực sự có tác dụng là: tuổi tác, thâm niên, ngành nghề và đào tạo. Trong đó, đào tạo có tác động lớn nhất: Một công ty cung cấp đào tạo AI chính thức, tỷ lệ sử dụng AI hàng ngày của nhân viên cao hơn 37 điểm phần trăm so với các công ty tương tự không có đào tạo. Ngay cả chỉ với hướng dẫn không chính thức, cũng có sự cải thiện 24 điểm phần trăm.
Tuy nhiên, thực tế là: Tính đến đầu năm 2026, chỉ có 14% nhân viên cho biết họ đã từng được chủ lao động cung cấp đào tạo AI chính thức, và 2/3 hoàn toàn không nhận được bất kỳ hình thức đào tạo nào.
Đào tạo AI không phải là vấn đề kỹ thuật, mà là vấn đề phân phối. Ai được chọn để đào tạo, người đó được phép bước vào quỹ đạo tăng trưởng năng suất; ai không, công cụ chỉ là một biểu tượng trên màn hình không được ủy quyền để mở.
AI ở khía cạnh tiêu dùng là một ứng dụng, ở khía cạnh nghề nghiệp là một quyền hạn. Và quyền hạn, chưa bao giờ được phân phối đồng đều.
Nguồn: Focaldata
IV. Cuối cùng bị phân hóa, là khả năng đánh giá AI
Đây là làn sóng phân hóa kín đáo nhất, và cũng là căn bản nhất.
Hãy tưởng tượng một sinh viên mới tốt nghiệp vừa vào làm tại một công ty tư vấn. Anh ta dùng AI để tạo bản thảo đầu tiên của một báo cáo phân tích ngành, cấu trúc hoàn chỉnh, dữ liệu đầy đủ, giọng điệu tự tin. Người quản lý của anh ta - một người đã làm trong ngành này mười năm - liếc qua và chỉ ra rằng nguồn gốc dữ liệu của hai trích dẫn có khiếm khuyết về phương pháp luận, và kết luận thứ ba có vấn đề về suy luận nhân quả. Người quản lý không phải vì chăm chỉ hơn, mà vì anh ta có lớp nền tảng đó - biết chỗ nào dễ sai, biết sự trôi chảy nào là thực sự trôi chảy, sự trôi chảy nào là máy móc đang lấp đầy chỗ trống.
Đây chính là ý nghĩa thực sự của phát hiện phản trực giác trong dữ liệu khảo sát nghề nghiệp: Người sử dụng AI nhiều nhất trong công việc, không phải là nhân viên trẻ nhất, mà là những người đã làm công việc hiện tại từ 2 đến 10 năm. Mối quan hệ giữa tỷ lệ sử dụng AI và thâm niên vẫn đáng kể sau khi kiểm soát độ tuổi. Điều này không phải vì người trẻ không muốn dùng, mà vì giá trị của AI phụ thuộc rất nhiều vào khả năng phán đoán sẵn có của người dùng.
Kinh nghiệm là vốn bổ trợ quan trọng nhất của AI, và kinh nghiệm không thể được đăng ký theo dõi.
AI làm giảm chi phí của việc "nghe có vẻ hiểu", nhưng không giảm tương đương chi phí của việc "thực sự hiểu". Thậm chí còn có một hậu quả nguy hiểm hơn: Người dùng càng thiếu nền tảng, càng dễ chấp nhận toàn bộ đầu ra của AI; và càng chấp nhận toàn bộ, khả năng phán đoán càng khó phát triển. Khi người đại diện phán đoán thay bạn, bạn đang tiêu thụ trí thông minh, chứ không phải đang tích lũy nó.
Người đoạt giải Nobel Kinh tế, Giáo sư MIT Daron Acemoglu đã thẳng thắn về điều này: Sử dụng công cụ AI đòi hỏi một trình độ giáo dục, tư duy trừu tượng, khả năng định lượng và sự quen thuộc với công nghệ nhất định. "AI sẽ làm gia tăng bất bình đẳng, điều đó gần như ch


