
AI trung chuyển mô hình lớn không chỉ cần điểm chuẩn, mà còn cần kiểm toán: Khung đánh giá GatewayBench ra mắt, trang web chính thức Check4U.ai đồng thời mở cửa
- Quan điểm cốt lõi: Thị trường API trung chuyển mô hình lớn AI (Shadow API) tồn tại các tiêu cực như thay thế mô hình, tính phí ngầm và giá thấp giả tạo, ảnh hưởng đến khả năng tái tạo kết quả nghiên cứu và sự ổn định kinh doanh của doanh nghiệp. Khung kiểm toán GatewayBench, thông qua đánh giá ba chiều về độ tin cậy, tính kinh tế và hiệu suất, nhằm mục đích vạch trần hộp đen, thúc đẩy sự minh bạch của thị trường.
- Các yếu tố chính:
- Kiểm toán của Trung tâm An ninh Thông tin CISPA Helmholtz phát hiện rằng ít nhất 187 bài báo hội nghị hàng đầu trên toàn thế giới sử dụng API trung chuyển, trong đó 62% có nguy cơ không tái tạo được kết quả nghiên cứu do mô hình cơ bản bị thay thế, lượng tử hóa hoặc giảm cấp.
- Tiêu cực một: Mô hình bị "pha loãng" động. Khi tải cao, cổng trung chuyển có thể âm thầm thay thế mô hình gốc bằng phiên bản lượng tử hóa, phiên bản chưng cất hoặc mô hình nguồn mở chi phí thấp, dẫn đến chất lượng đầu ra không ổn định.
- Tiêu cực hai: Tính phí ngầm và rủi ro riêng tư. Bao gồm khai báo gian dối mức tiêu thụ "thinking tokens" của mô hình suy luận, không thực hiện giảm giá bộ nhớ đệm, và chia sẻ pool bộ nhớ đệm giữa các tài khoản dẫn đến việc cách ly dữ liệu doanh nghiệp bị vô hiệu hóa.
- Tiêu cực ba: "Giá thấp nhất toàn mạng" giả tạo. Đơn giá hỗn hợp che giấu chi phí thực tế, hóa đơn cho các kịch bản đầu vào cao (như RAG) có thể cao hơn nhiều so với dự kiến, và các ma sát ngầm như tính phí cho các yêu cầu thất bại, ngưỡng nạp tiền làm tăng chi tiêu thực tế.
- Khung kiểm toán GatewayBench: Hệ thống trọng số là 40% độ tin cậy + 40% tính kinh tế + 20% hiệu suất, kiểm toán cốt lõi bao gồm thuật toán RUT phát hiện tính xác thực của mô hình, PALACE ước tính phạm vi token hợp lý, chỉ số SLO đánh giá khả năng phân phối ổn định.
- Chiều kinh tế giới thiệu khái niệm "True Cost per 1M Tokens", phân tích giá đầu vào/đầu ra/bộ nhớ đệm, so sánh với giá chính thức, xác định các chi phí ngầm như tính phí yêu cầu thất bại, hoàn trả chiết khấu bộ nhớ đệm.
- Nền tảng Check4U.ai đã ra mắt bảng xếp hạng đánh giá mở, nhằm mục đích thông qua một khuôn khổ thống nhất, mã nguồn mở, cho phép các nhà cung cấp dịch vụ chất lượng giao hàng trung thực được thị trường công nhận, thúc đẩy ngành công nghiệp chuyển đổi sang hướng có thể xác minh, có thể chịu trách nhiệm.
Is the GPT-5 or Claude that companies spend huge sums on every month actually the official original model?
To navigate the complex geographical restrictions, corporate compliance processes, and payment barriers of AI large models, a growing number of R&D teams are opting for a shortcut: the third-party AI relay market (Shadow API). This alternative appears highly attractive, allowing developers to access mainstream models like GPT and Claude at a lower barrier, with a user experience close to the official API, while also filling the gaps that official channels cannot cover.
However, this seemingly convenient "door" hides a deep, unfathomable black box.
In March 2026, an audit released by the CISPA Helmholtz Center for Information Security in Germany revealed a chilling truth: at least 187 top-tier academic papers worldwide have used AI model relay APIs (Shadow API) for research (62% of which have been accepted by top-tier academic conferences like CVPR and ICLR). However, because these relay gateways secretly replaced, quantized, or downgraded the underlying model, a significant number of research results face the risk of being irreproducible.
And this "disaster" in academia is a potential "time bomb" waiting to explode in enterprise production environments.
Today's large models are no longer just test products in labs; these core infrastructures are deeply integrated into customer service centers, code generation pipelines, Agent workflows, and risk control business chains. Faced with systems supporting critical operations, relay service providers typically market their offerings to enterprises with selling points like "original models," "low prices," "high speed," and "cache support."
But the problem is that traditional evaluation tools simply cannot detect the tricks inside the black box. Existing benchmarking software mainly focuses on the speed and price outside the interface. These tools assume a premise that the data returned by the gateway is all real and trustworthy. Conventional evaluations cannot answer the following core business security questions:
● During traffic spikes, is the high-priced model you purchased being secretly "swapped out" or "downgraded"?
● Behind the so-called high speed and low price, are there inflated Tokens quietly added to the bill, or charges forcibly deducted for failed requests?
● Are the cache discounts promised by the gateway actually refunded to the enterprise? Is cross-account private data strictly isolated?
AI relay APIs have indeed solved the access barrier issue for large models, but they have also created a new crisis of trust. Without understanding these invisible backend paths, making procurement decisions based solely on surface-level unit prices and speeds is like running blindly in the dark. Breaking the black-box era and making honest delivery a market advantage again is the top priority that the current AI supply chain urgently needs to address.
Unveiling the Black Box: The "Three Unspoken Rules" of the AI Large Model Relay Market
Why can't existing conventional benchmarking software detect these problems? Because traditional evaluation tools only operate outside the interface, simply comparing response speeds and listed prices. Behind the highly opaque gateway backend, vendors exploit this information asymmetry, transforming complex technical measures into covert arbitrage tools.
A deep dive into the current AI large model relay market reveals three highly covert "unspoken rules" that are eroding enterprise business quality and budgets:
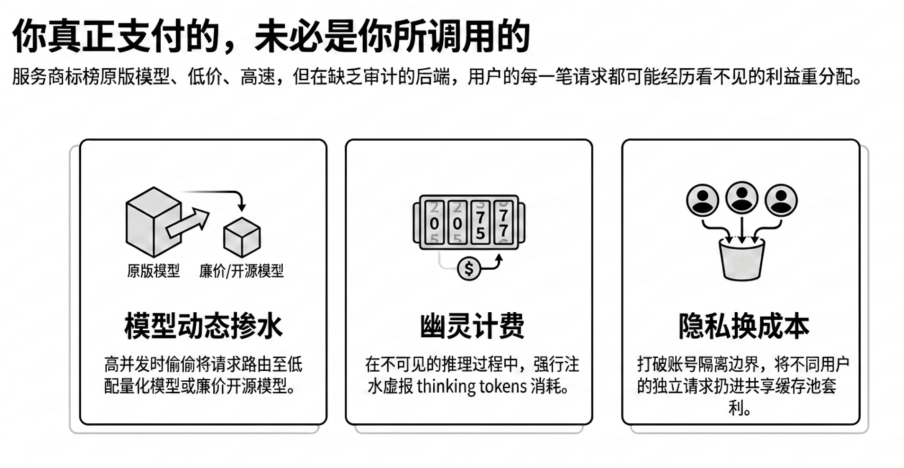
Unspoken Rule 1: Dynamic Model Watering Down
In the gray relay market, the hardest arbitrage tactic to detect is dynamic model swapping.
Many service providers will faithfully call the official original model when facing conventional evaluation tools or low system traffic. However, once they encounter high-concurrency business peaks or blind spots beyond monitoring coverage, these gateways will secretly switch the backend to lower-cost quantized models, weaker distilled versions, or even extremely low-cost open-source models with the same name.
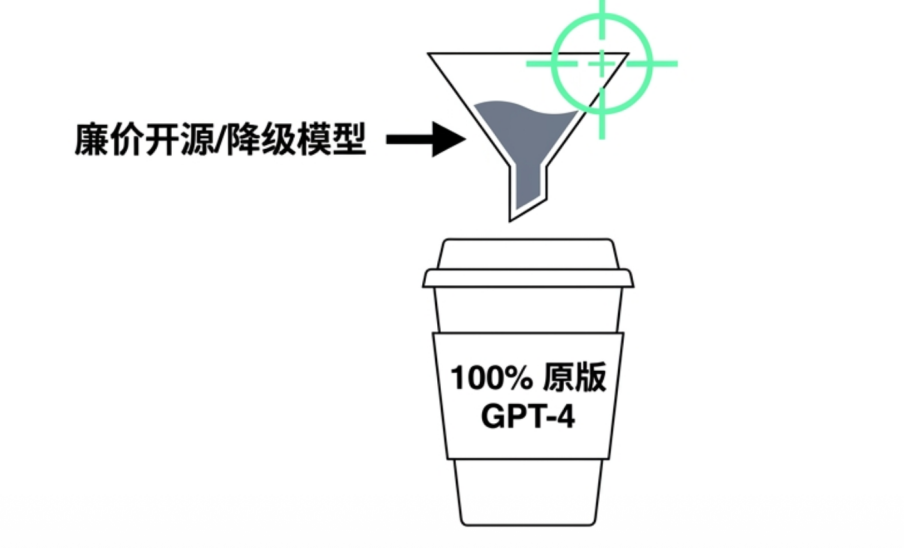
While the interface may still appear to output text on the surface, the underlying probability distribution has been tampered with. The actual quality of the output enterprises receive no longer matches the metrics originally promised by the vendor. This model-swapping behavior exposes the accuracy of customer service responses and the quality of code generation to the risk of uncontrollable degradation at any time.
Unspoken Rule 2: The Invisible Bill (Hidden Billing and Privacy Exposure)
With the popularization of reasoning models, a new and harder-to-verify cost item has appeared in large model bills: thinking tokens. Since this part of the reasoning process is invisible by default, it's difficult for buyers to verify whether the reasoning consumption claimed by the platform is real, creating room for unscrupulous gateways to inflate costs.
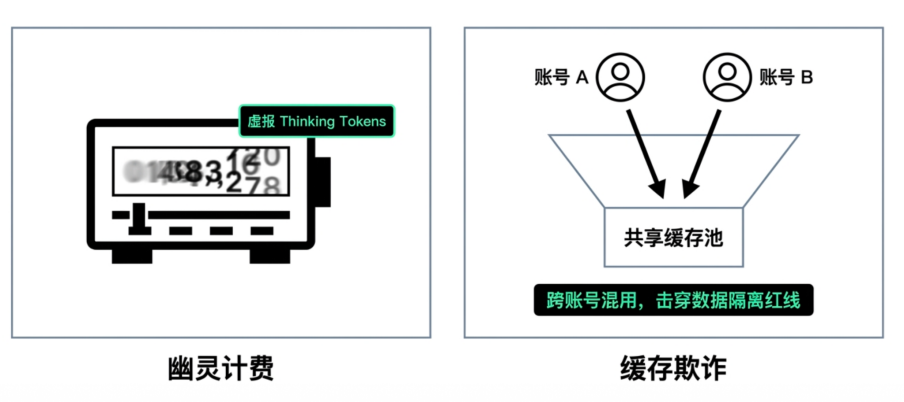
Even more frightening than inflated bills is uncontrolled cache fraud. Some service providers display a cache hit indicator on the bill but fail to pass on the actual discounts to the enterprise. Cache optimization becomes a mere numbers game on paper. Worse still, to forcibly increase cache hit rates and reduce their own costs, some gateways may forcibly push prompts from different enterprises into a single shared cache pool. This directly undermines the data isolation boundaries of multi-tenant systems, exposing core enterprise business data and commercial secrets to the risk of cross-account mixing.
Unspoken Rule 3: The Fake "Lowest Price on the Market" (Carefully Designed Financial Trap)
When procuring large model APIs, the "lowest price on the market" often catches attention first. However, in actual business operations, the nominal unit price does not equal the real cost. Especially in the relay gateway market, input, output, cache hits, and cache writes are often bundled into a composite price. While this seems convenient for comparison, it can easily become distorted once subjected to real business loads.
This distortion arises from the fact that enterprises don't have a fixed input-output ratio when calling large models. RAG, long document analysis, and complex Agent workflows are typically high-input, low-output; code generation and content creation might be low-input, high-output. If the platform only shows a blended unit price, it's difficult for buyers to determine where the costs originate. A platform with a seemingly low blended price might optimize its offer by lowering the output unit price while simultaneously raising prices for inputs, cache writes, or other less noticeable items. Ultimately, the actual bill for certain high-input scenarios could be much higher than expected.
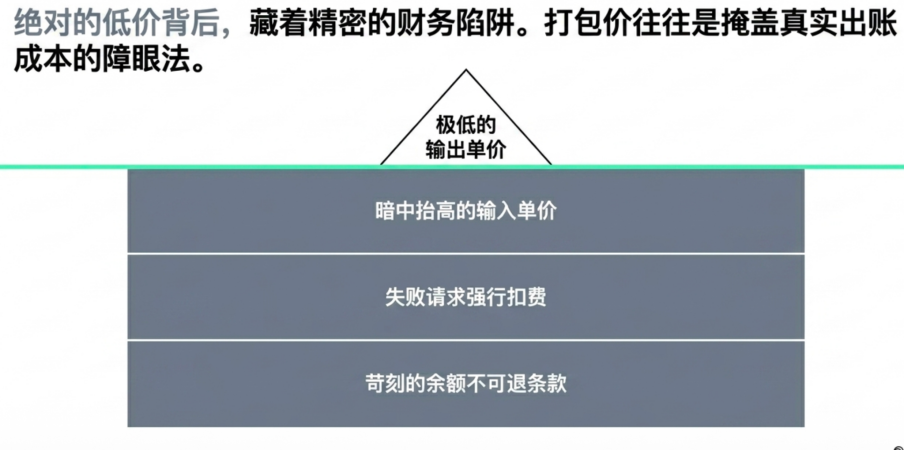
Furthermore, hidden costs are often buried in various inconspicuous terms. For instance, during system disconnections, timeouts, or 5xx errors, charges may still be forcibly applied for failed requests. Low unit prices are often tied to high deposit minimums, non-refundable balance clauses, and opaque foreign exchange and payment channel fees. When all these financial frictions are combined, the actual cost debited from the enterprise's ledger per million Tokens can be several times higher than the nominal price advertised on the webpage.
GatewayBench: A Professional Audit Framework for Large Model Gateways
Faced with the highly opaque gateway backend, traditional speed testing and benchmarking tools have clear limitations. These metrics can compare response speed, model coverage, and nominal price, but struggle to answer more critical questions: Does the model actually called by the gateway match the promise? Is the bill transparent? Are the cache and data isolation trustworthy?
Against this backdrop, the GatewayBench audit and evaluation framework has officially launched, opening its evaluation portal via the website Check4U.ai. As an open-source audit framework for large model gateways, GatewayBench looks beyond just speed and surface prices. It deconstructs gateway evaluation into three dimensions: Trustworthiness, Cost-Effectiveness, and Performance, employing a weighting system of 40% Trustworthiness + 40% Cost-Effectiveness + 20% Performance.
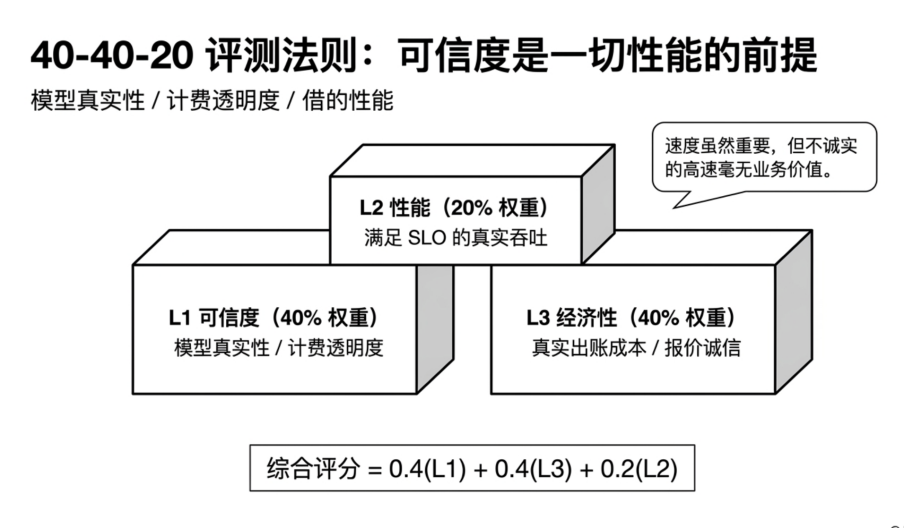
This weighting reflects GatewayBench's fundamental judgment: In the AI large model relay API scenario, trustworthiness and true cost take precedence over speed. A gateway must first prove the authenticity of its models, the transparency of its billing, and the explainability of its costs before it qualifies for performance competition.
Aiming for this goal, GatewayBench provides three core audit capabilities:
L1 Trustworthiness Audit: From Platform Claims to Verifiable Trust
In GatewayBench's scoring system, L1 Trustworthiness accounts for 40% weight. The logic behind this design is: In the AI large model relay API scenario, while speed and price are important, if the model is not authentic and the bill is not transparent, there is no basis for discussing other metrics.
The core risk of third-party large model relay gateways lies in the invisible process behind a successful call. A normal response at the interface level only confirms that the request was processed, but fails to prove that the model origin, billing process, and cache handling all conform to the platform's promises. In the past, these links lacked externally verifiable evidence, making them difficult to subject to systematic audit.
The L1 dimension of GatewayBench is precisely designed to transform these vague suspicions into auditable engineering signals. It does this by breaking down trustworthiness into three questions: Is the model authentic? Is the billing transparent? Is the cache trustworthy? And it uses statistical tests, cryptographic structures, and latency fingerprints to observe, from the outside, what actually happens inside the gateway black box.
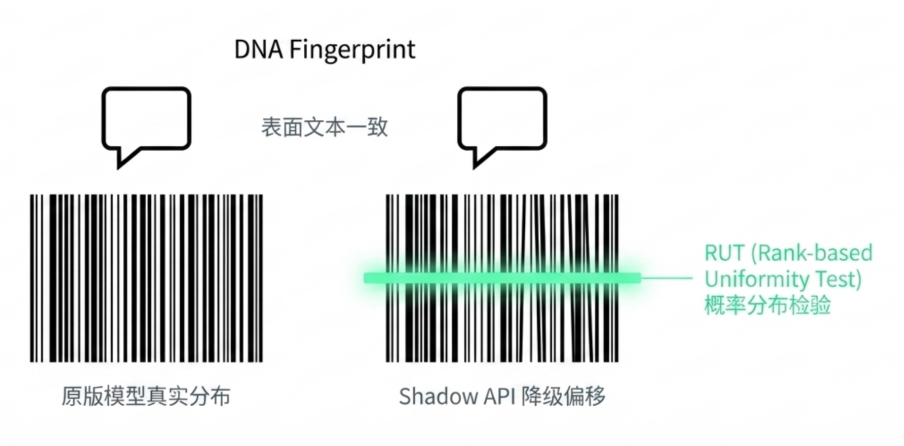
For model authenticity, GatewayBench introduces the RUT (Rank-based Uniformity Test) algorithm, which checks the position of output tokens in the probability ranking of a reference model. Different models may generate similar text, but the token probability distribution is harder to fake. If quantization, downgrading, or substitution occurs in the backend, the distribution shift will leave traces. Simultaneously, GatewayBench can also combine Logprob Tracking, requesting only one output token for a fixed prompt and tracking whether its log probability shows a stable shift over different time periods. This provides a lower-cost signal for continuous monitoring of model updates, fine-tuning, quantization adjustments, or routing changes.
For billing transparency, GatewayBench uses PALACE to estimate a reasonable range for thinking tokens, identifying abnormal over-reporting in reasoning models. It also leverages verifiable structures like CoIn to make billing records more traceable and resistant to tampering.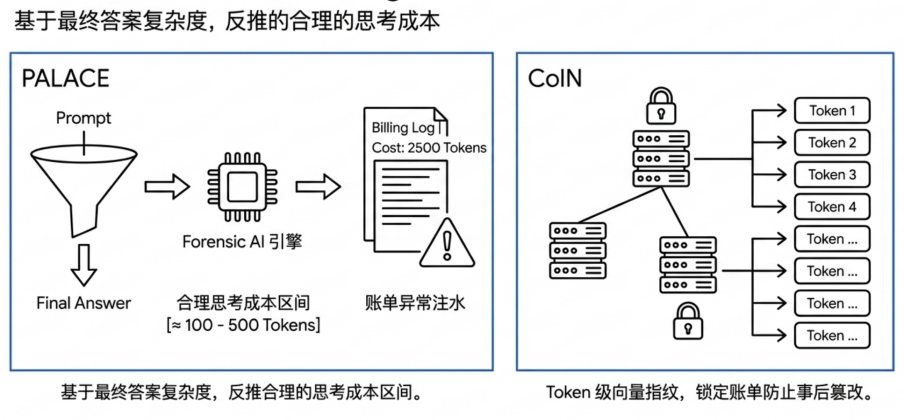
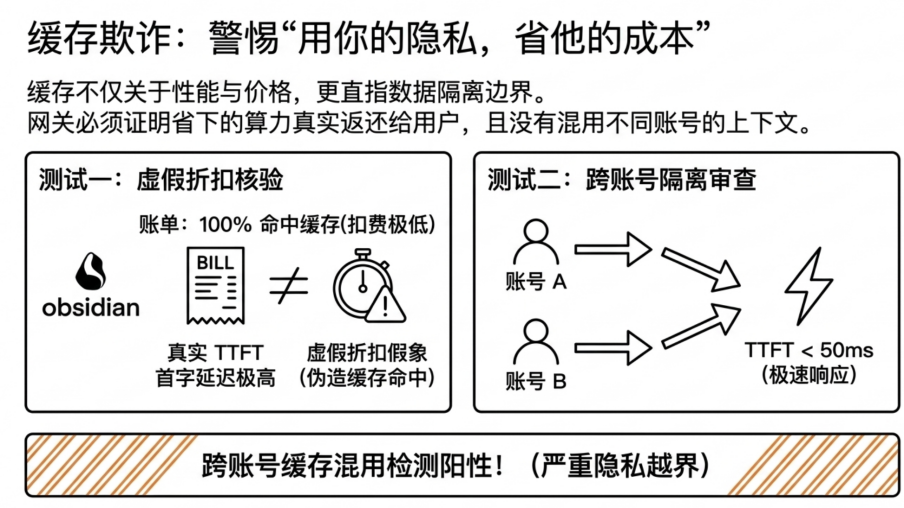
For cache trustworthiness, GatewayBench uses latency fingerprints to determine if a claimed cache hit is genuine, and conducts cross-account isolation tests to identify potential tenant boundary issues. If the bill shows a cache hit but the TTFT hasn't correspondingly decreased, the discount might only exist on paper. If abnormal cache reuse occurs between two independent accounts, it may signal a cache isolation risk.
Through these methods, GatewayBench transforms the black box, previously only understood through intuition and suspicion, into a set of measurable, auditable, and comparable signals, achieving truly "verifiable trust."
L2 Performance: Extreme Load Testing to Probe Stable Delivery Under Severe Stress
Only gateways that pass the L1 Trustworthiness audit are eligible for performance and cost-effectiveness comparison.
In the large model infrastructure ecosystem, performance has always been the metric most emphasized by relay stations and aggregator API providers. Terms like "fastest in the world" and "single concurrency 150 tokens/s" are common. However, in designing its metric system, GatewayBench has maintained a fairly restrained weight for performance: L2 Performance accounts for only 20% of the overall score.
The reason is simple. Speed is certainly important; it determines a system's basic usability and can weed out services with frequent lag or uncontrollable long tails. But speed should not outweigh trustworthiness and cost-effectiveness. Even if a gateway runs very fast, it cannot be a trustworthy enterprise-grade infrastructure if it engages in model swapping, bill padding, or cache opacity.
Therefore, in the L2 Performance dimension, GatewayBench does not chase single-point peak speeds. Instead, it breaks performance down into questions closer to the production environment: Latency determines how long users wait; Goodput measures the effective capacity delivered within latency redlines; Long context tests observe how the system degrades under heavy loads.
The premise behind this design is: Performance is a threshold, but it is not the endpoint. What enterprises are truly buying is stable, on-time, and predictable delivery capability under the premise of trustworthiness.
In commercial-grade applications, the peak speed of an idle system is of extremely limited reference value. GatewayBench rejects simply competing on throughput (Tokens/s) and instead introduces SLO (Service Level Objective) as the business red line. Enterprises can stipulate, for example, that P95 TTFA must be less than 1.5 seconds, P95 E2E must be less than 8 seconds, and streaming output must not show significant jitter. Goodput is built on this red line: Only the throughput delivered while meeting the SLO is considered effective capacity (Goodput).
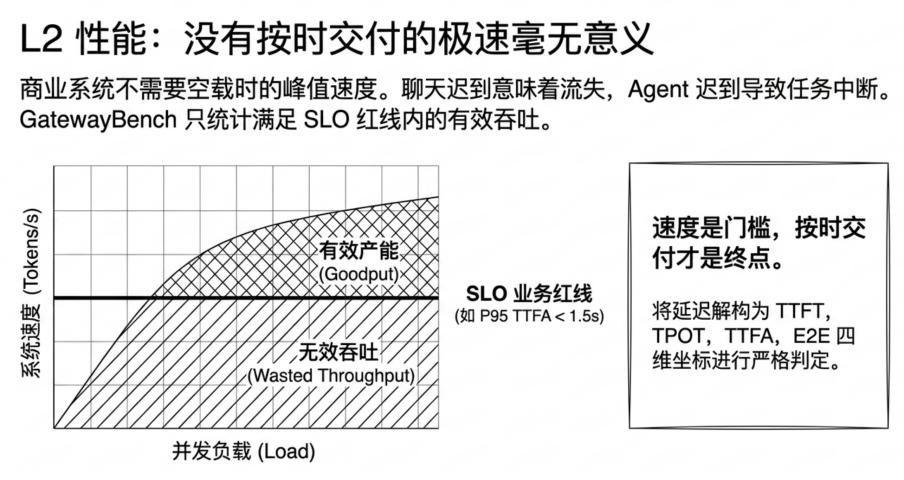
To test the true scheduling capability of relay gateways, GatewayBench will throw out stress tests with ultra-long contexts at the 100k level. These tests aim to observe whether the system maintains stable, graceful degradation under heavy load or experiences long-tail instability or even hidden downgrades. What enterprises are paying for is precisely this stable delivery capability that can still "turn in the paper on time" under extreme business pressure.
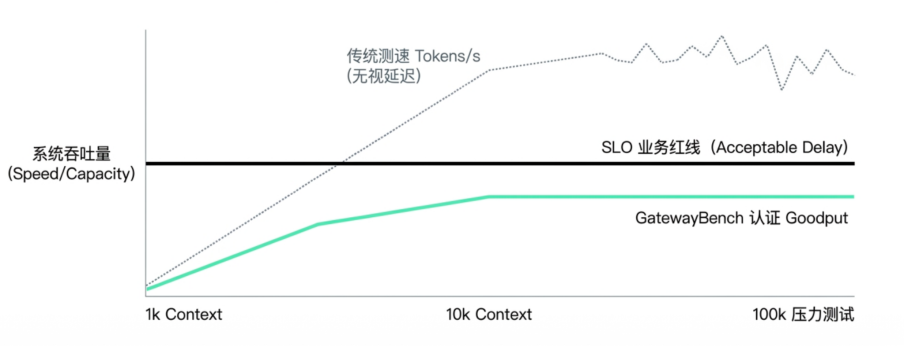
L3 Cost-Effectiveness: Penetrating the Bill Fog to Reveal the 'True Cost per 1M Tokens'
Price is the most sensitive variable for enterprises when procuring large model relay APIs, and it is also the most easily repackaged. Listed unit prices on web pages may look clear, but once in production, costs are influenced by input-output ratios, cache rules, failed requests, deposit terms, exchange rates, and payment channel fees.
Therefore, GatewayBench assigns a 40% weight to L3 Cost-Effectiveness, making it a core dimension alongside L1 Trustworthiness. What matters here is not the nominal unit price on a price list, but the True Cost per 1M Tokens—the cost an enterprise ultimately pays under real business loads.
In terms of listed pricing, GatewayBench breaks down the input price, output price, cache hit price, and cache write price, preventing a single blended price from masking the cost structure. Input-output ratios vary significantly across different business scenarios. RAG, long document analysis, and Agent workflows are typically high-input, low-output; code generation and content creation may incur higher output costs. Looking only at a composite price easily leads to misjudging actual expenditure.
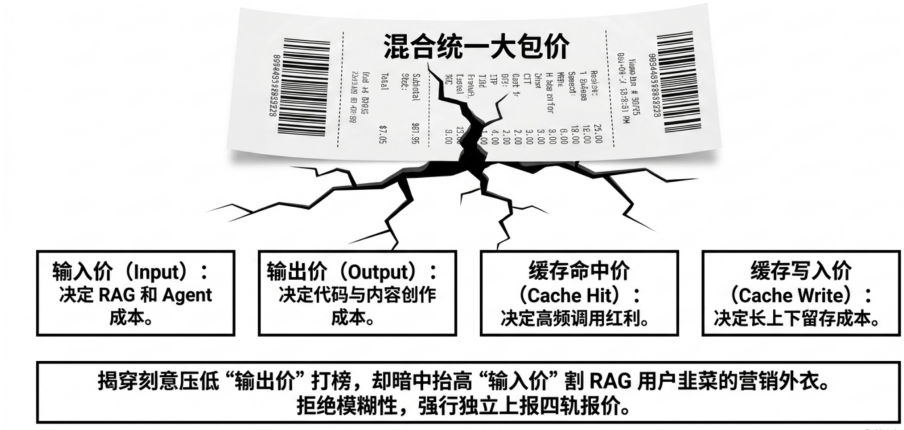
Relative to official pricing, GatewayBench introduces a "platform price / official price" ratio and combines it with an assessment of the gateway's role to determine if the markup is reasonable. Aggregator routing, multi-channel failover, and unified billing can justify some service premium; simple forwarding proxies should be closer to the official price. A low price does not necessarily represent an advantage, and a high price must correspond to genuine engineering value.
The GatewayBench framework also delves deep into the hidden frictions behind the bills: Are failed requests forcibly charged? Are claimed cache discounts actually refunded? Do fund accounts have restrictive consumption limits? By deconstructing these layers, GatewayBench ultimately reveals the true debited cost for the enterprise, stripped of all marketing packaging.
Join GatewayBench: Let Honest Delivery Be Rewarded by the Market
The API relay market will not disappear due to controversy. As long as model access continues to face regional, payment, risk control, and compliance differences, third-party gateways will continue to serve genuine demand. Since this is an unavoidable reality, GatewayBench aims to make these relay stations more transparent, trustworthy, and sustainable.
The biggest contradiction in the current API relay market is that information asymmetry is amplifying the "bad money drives out good" effect. Some service providers can gain short-term traffic through model swapping, billing packaging, cache arbitrage, or low-price marketing. Meanwhile, vendors that insist on original model passthrough, transparent billing, and stable service, because they cannot break free from real cost constraints, find it harder to be seen in the noisy market.
This is not a structure the infrastructure market can rely on long-term. Any mature supply chain requires a market-based trust mechanism grounded in metrics: Good service should be seen, stable performance should be recorded, and honest delivery should attract more traffic, more trust, and higher-quality procurement budgets. Conversely, service providers that profit long-term from information asymmetry should bear higher trust costs.
Based on


