
Phân tích chuyên sâu về lý luận AI phi tập trung: Cách cân bằng giữa bảo mật và hiệu suất
- 核心观点:去中心化AI推理可打破算力垄断。
- 关键要素:
- 利用闲置GPU算力降低AI成本。
- 区块链记录确保推理可验证。
- 声誉机制平衡安全与性能。
- 市场影响:挑战中心化云服务商定价权。
- 时效性标注:中期影响。
Tác giả gốc: Anastasia Matveeva - Đồng sáng lập Gonka Protocol
Mục lục
- "Phân quyền" thực sự
- Blockchain và Bằng chứng lý luận
- Nó thực sự hoạt động như thế nào
- Sự đánh đổi giữa bảo mật và hiệu suất
- Tối ưu hóa không gian
Khi bắt đầu xây dựng Gonka , chúng tôi đã có một tầm nhìn: Sẽ ra sao nếu ai cũng có thể chạy suy luận AI và được trả tiền cho việc đó? Sẽ ra sao nếu chúng ta có thể khai thác toàn bộ sức mạnh tính toán chưa sử dụng đó thay vì phụ thuộc vào các nhà cung cấp tập trung đắt đỏ?
Bối cảnh AI hiện tại đang bị chi phối bởi một số ít nhà cung cấp đám mây lớn: AWS, Azure và Google Cloud kiểm soát phần lớn cơ sở hạ tầng AI trên thế giới. Sự tập trung hóa này tạo ra những vấn đề nghiêm trọng mà nhiều người trong chúng ta đã từng trải nghiệm trực tiếp. Việc một số ít công ty kiểm soát cơ sở hạ tầng AI đồng nghĩa với việc họ có thể tùy ý đặt giá, kiểm duyệt các ứng dụng không mong muốn và tạo ra một điểm lỗi duy nhất. Khi API của OpenAI gặp sự cố, hàng nghìn ứng dụng cũng bị sập theo. Khi AWS gặp sự cố, một nửa internet ngừng hoạt động.
Ngay cả những công nghệ tiên tiến "hiệu quả" cũng không hề rẻ. Anthropic trước đây đã tuyên bố rằng việc đào tạo Claude Sonnet 3.5 tốn "hàng chục triệu đô la", và mặc dù Claude Sonnet 4 hiện đã có sẵn rộng rãi, Anthropic vẫn chưa công bố chi phí đào tạo. Giám đốc điều hành của công ty, Dario Amodei, trước đây đã dự đoán chi phí đào tạo cho các mô hình tiên tiến sẽ lên tới gần 1 tỷ đô la, và làn sóng mô hình tiếp theo sẽ lên tới hàng tỷ đô la. Việc chạy suy luận trên các mô hình này cũng tốn kém không kém. Đối với một ứng dụng hoạt động ở mức độ vừa phải, một lần chạy suy luận LLM có thể tốn từ hàng trăm đến hàng nghìn đô la mỗi ngày.
Trong khi đó, thế giới đang có một lượng lớn sức mạnh tính toán đang nằm im (hoặc bị sử dụng một cách vô nghĩa). Hãy nghĩ đến những thợ đào Bitcoin đang đốt điện để giải các câu đố băm vô giá trị, hay các trung tâm dữ liệu đang hoạt động dưới công suất. Sẽ thế nào nếu sức mạnh tính toán này có thể được sử dụng cho một mục đích thực sự có giá trị, chẳng hạn như suy luận AI?
Một phương pháp phi tập trung có thể tập trung sức mạnh tính toán, giảm thiểu rào cản về vốn và hạn chế tình trạng tắc nghẽn từ một nhà cung cấp duy nhất. Thay vì phụ thuộc vào một vài công ty lớn, chúng ta có thể tạo ra một mạng lưới nơi bất kỳ ai có GPU đều có thể tham gia và được trả tiền để chạy suy luận AI.
Chúng tôi biết rằng việc xây dựng một giải pháp phi tập trung khả thi sẽ vô cùng phức tạp. Từ cơ chế đồng thuận đến giao thức đào tạo cho đến phân bổ tài nguyên, có vô số yếu tố cần được phối hợp. Hôm nay, tôi chỉ muốn tập trung vào một khía cạnh: chạy suy luận trên một LLM cụ thể . Vậy thì việc này khó đến mức nào?
Phân quyền thực sự là gì?
Khi nói về suy luận AI phi tập trung , chúng tôi muốn nói đến một điều gì đó rất cụ thể. Nó không chỉ là việc chạy các mô hình AI trên nhiều máy chủ, mà là xây dựng một hệ thống nơi bất kỳ ai cũng có thể tham gia, đóng góp sức mạnh tính toán và được khen thưởng cho những nỗ lực làm việc trung thực.
Yêu cầu quan trọng là hệ thống phải không cần sự tin cậy . Điều này có nghĩa là bạn không cần phải tin tưởng bất kỳ cá nhân hay công ty nào để vận hành hệ thống một cách chính xác. Nếu bạn cho phép người lạ trên internet chạy mô hình AI của mình, bạn cần có sự đảm bảo bằng mật mã rằng họ thực sự đang làm những gì họ tuyên bố (ít nhất là với xác suất đủ cao).
Yêu cầu không cần tin cậy này có một số hàm ý thú vị. Thứ nhất, nó có nghĩa là hệ thống cần phải có khả năng xác minh : bạn cần chứng minh được rằng cùng một mô hình và cùng các tham số đã được sử dụng để tạo ra một đầu ra nhất định. Điều này đặc biệt quan trọng đối với các hợp đồng thông minh cần xác minh rằng các phản hồi AI mà chúng nhận được là hợp lệ.
Nhưng có một thách thức: bạn càng thêm nhiều xác minh, toàn bộ hệ thống càng chậm, vì năng lượng mạng bị tiêu tốn cho việc xác minh. Nếu bạn hoàn toàn tin tưởng tất cả mọi người, không cần phải suy luận xác minh, và hiệu suất gần như tương đương với các nhà cung cấp tập trung. Nhưng nếu bạn không tin tưởng ai và luôn xác minh mọi thứ, hệ thống sẽ trở nên cực kỳ chậm và kém cạnh tranh với các giải pháp tập trung.
Đây là mâu thuẫn cốt lõi mà chúng tôi đang nỗ lực giải quyết: tìm ra sự cân bằng phù hợp giữa bảo mật và hiệu suất .
Blockchain và Bằng chứng lý luận
Vậy làm thế nào để xác minh rằng ai đó đã chạy đúng mô hình và tham số? Blockchain trở thành một lựa chọn hiển nhiên — mặc dù có những thách thức riêng, nhưng nó vẫn là cách đáng tin cậy nhất mà chúng ta biết để tạo ra một bản ghi sự kiện bất biến.
Ý tưởng cơ bản khá đơn giản. Khi ai đó chạy suy luận, họ cần cung cấp bằng chứng chứng minh họ đã sử dụng đúng mô hình. Bằng chứng này được ghi lại trên blockchain, tạo ra một bản ghi vĩnh viễn, chống giả mạo mà bất kỳ ai cũng có thể xác minh.
Vấn đề là blockchain rất chậm. Thực sự rất chậm. Nếu chúng tôi cố gắng ghi lại mọi bước suy luận trên chuỗi, khối lượng dữ liệu khổng lồ sẽ nhanh chóng làm quá tải mạng. Chính hạn chế này đã chi phối nhiều quyết định của chúng tôi khi thiết kế Mạng Gonka.
Khi thiết kế mạng và suy nghĩ về điện toán phân tán, có nhiều chiến lược để lựa chọn. Bạn có thể phân mảnh một mô hình trên nhiều nút, hay giữ toàn bộ mô hình trên một nút duy nhất? Những hạn chế chính đến từ băng thông mạng và tốc độ blockchain. Để giải pháp của chúng tôi khả thi, chúng tôi đã chọn lắp một mô hình đầy đủ trên một nút duy nhất, mặc dù điều này có thể thay đổi trong tương lai. Điều này đặt ra yêu cầu tối thiểu để tham gia mạng, vì mỗi nút cần đủ sức mạnh tính toán và bộ nhớ để chạy toàn bộ mô hình. Tuy nhiên, một mô hình vẫn có thể được phân mảnh trên nhiều GPU thuộc cùng một nút, mang lại cho chúng tôi sự linh hoạt trong các ràng buộc của một nút duy nhất. Chúng tôi sử dụng vLLM, cho phép tùy chỉnh các tham số song song tensor và pipeline để đạt hiệu suất tối ưu.
Nó thực sự hoạt động như thế nào
Do đó, chúng tôi đã thống nhất rằng mỗi nút lưu trữ một mô hình hoàn chỉnh và chạy toàn bộ suy luận, loại bỏ nhu cầu phối hợp giữa nhiều máy trong quá trình tính toán thực tế. Blockchain chỉ được sử dụng để lưu trữ hồ sơ. Chúng tôi chỉ ghi lại các giao dịch và hiện vật được sử dụng để xác minh suy luận. Quá trình tính toán thực tế diễn ra ngoài chuỗi.
Chúng tôi muốn hệ thống được phân cấp, không có bất kỳ điểm trung tâm nào chỉ đạo các yêu cầu suy luận đến các nút mạng. Trên thực tế, mỗi bên tham gia triển khai ít nhất hai nút: một nút mạng và một hoặc nhiều nút suy luận (ML). Các nút mạng chịu trách nhiệm giao tiếp (bao gồm một nút chuỗi kết nối với blockchain và một nút API quản lý các yêu cầu của người dùng), trong khi các nút ML của bạn thực hiện suy luận LLM.
Khi một yêu cầu suy luận đến mạng, nó sẽ đến một trong các nút API (hoạt động như một "tác nhân chuyển giao"), nút này sẽ chọn ngẫu nhiên một "trình thực thi" (một nút ML từ một bên tham gia khác). Để tiết kiệm thời gian và song song hóa việc ghi nhật ký blockchain với tính toán LLM thực tế, tác nhân chuyển giao (TA) trước tiên sẽ gửi yêu cầu đầu vào đến trình thực thi và ghi lại đầu vào trên chuỗi trong khi nút ML của trình thực thi đang chạy suy luận. Sau khi tính toán hoàn tất, trình thực thi sẽ gửi đầu ra đến nút API của TA, trong khi nút chuỗi của nó ghi lại hiện vật xác minh trên chuỗi. Nút API của TA truyền đầu ra trở lại máy khách, cũng được ghi lại trên chuỗi. Tất nhiên, những bản ghi này vẫn góp phần vào các hạn chế về băng thông mạng tổng thể.
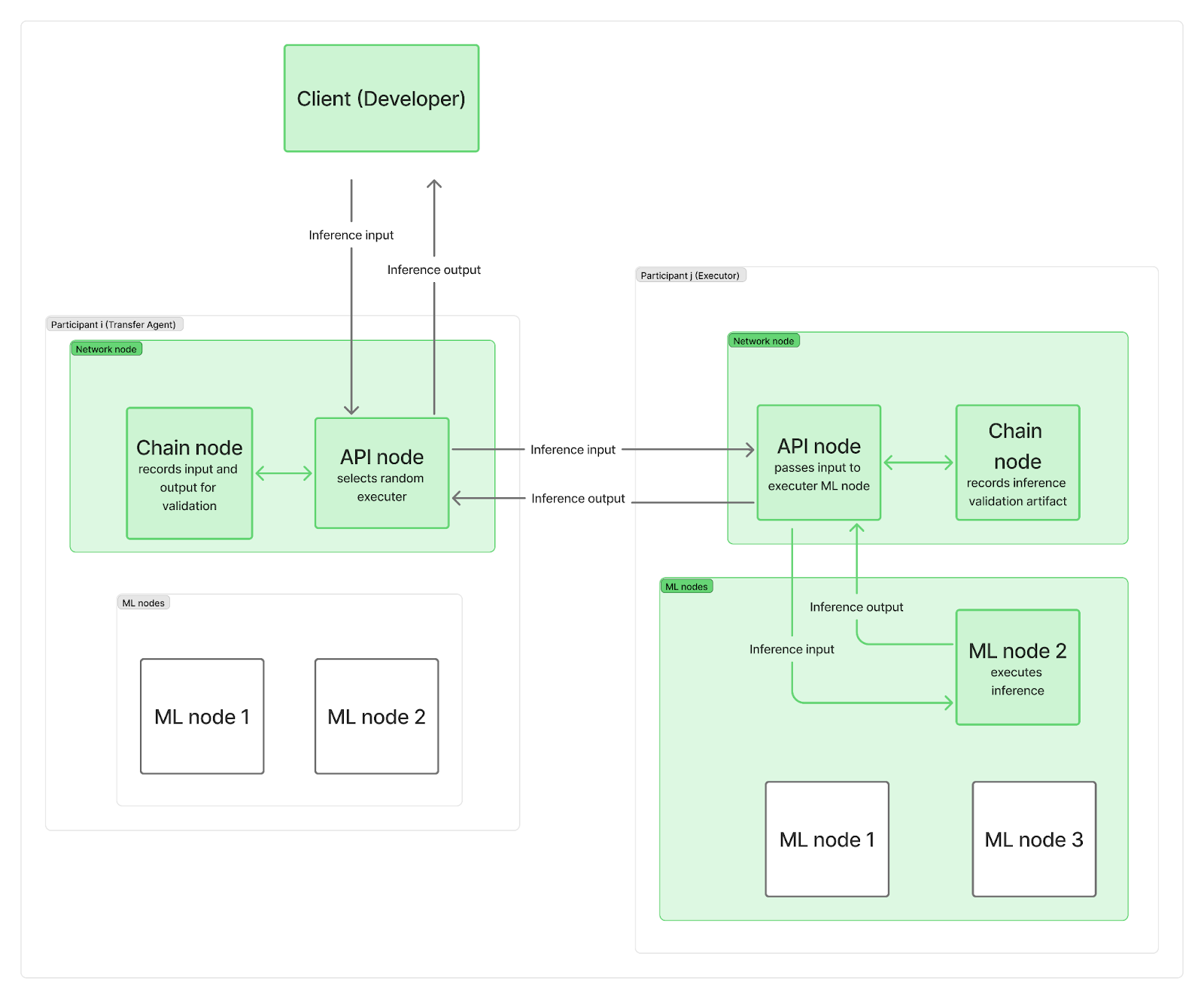
Như bạn có thể thấy, việc ghi lại blockchain không làm chậm quá trình bắt đầu tính toán suy luận cũng như thời gian trả về kết quả cuối cùng cho máy khách. Việc xác minh xem suy luận có được hoàn thành một cách trung thực hay không diễn ra sau đó, song song với các suy luận khác. Nếu người thực thi bị phát hiện gian lận, họ sẽ mất toàn bộ phần thưởng của kỷ nguyên, và máy khách sẽ được thông báo và được hoàn tiền.
Câu hỏi cuối cùng là: Hiện vật bao gồm những gì và chúng ta xác minh lý luận của mình thường xuyên như thế nào?
Sự đánh đổi giữa bảo mật và hiệu suất
Thách thức cơ bản là tính bảo mật và hiệu suất không tương thích với nhau.
Nếu bạn muốn bảo mật tối đa, bạn cần xác minh mọi thứ. Nhưng điều đó rất chậm và tốn kém. Nếu bạn muốn hiệu suất tối đa, bạn cần tin tưởng tất cả mọi người. Nhưng điều đó rất rủi ro và khiến bạn phải đối mặt với đủ loại tấn công.
Sau một số lần thử nghiệm, sai sót và điều chỉnh tham số, chúng tôi đã tìm ra một phương pháp cân bằng được hai yếu tố này. Chúng tôi phải tinh chỉnh cẩn thận lượng xác minh, thời điểm xác minh và cách thức để quy trình xác minh hiệu quả nhất có thể. Quá nhiều xác minh sẽ khiến hệ thống trở nên vô dụng; quá ít xác minh sẽ khiến hệ thống trở nên không an toàn.
Việc duy trì tính gọn nhẹ của hệ thống là rất quan trọng. Chúng tôi duy trì điều này bằng cách lưu trữ k xác suất tiếp theo của mã thông báo hàng đầu . Chúng tôi sử dụng chúng để đo lường khả năng một đầu ra nhất định thực sự được tạo ra bởi mô hình và các tham số được yêu cầu, đồng thời để phát hiện bất kỳ nỗ lực can thiệp nào, chẳng hạn như sử dụng một mô hình nhỏ hơn hoặc lượng tử hóa, với độ tin cậy đủ cao. Chúng tôi sẽ mô tả chi tiết hơn về việc triển khai quy trình xác minh suy luận trong một bài đăng khác.
Đồng thời, làm thế nào chúng tôi quyết định suy luận nào cần xác minh và suy luận nào không? Chúng tôi đã chọn phương pháp dựa trên uy tín. Khi một người tham gia mới tham gia mạng lưới, uy tín của họ là 0 và 100% suy luận của họ phải được xác minh bởi ít nhất một người tham gia . Nếu phát hiện ra vấn đề, cơ chế đồng thuận cuối cùng sẽ quyết định liệu suy luận của bạn có được chấp thuận hay không, hay uy tín của bạn sẽ bị hạ thấp và bạn có thể bị loại khỏi mạng lưới. Khi uy tín của bạn tăng lên, số lượng suy luận cần xác minh sẽ giảm xuống và cuối cùng, 1% suy luận có thể được chọn ngẫu nhiên để xác minh. Phương pháp tiếp cận năng động này cho phép chúng tôi giữ tỷ lệ xác minh chung ở mức thấp đồng thời phát hiện hiệu quả những người tham gia cố gắng gian lận.
Vào cuối mỗi kỷ nguyên, người tham gia sẽ được thưởng theo tỷ lệ tương ứng với trọng số của họ trong mạng lưới. Các nhiệm vụ cũng được tính trọng số, vì vậy phần thưởng dự kiến sẽ tỷ lệ thuận với cả trọng số và khối lượng công việc đã hoàn thành. Điều này có nghĩa là chúng tôi không cần phải bắt và trừng phạt những kẻ gian lận ngay lập tức; chỉ cần bắt chúng trong kỷ nguyên là đủ trước khi phân phối phần thưởng.
Các động lực kinh tế thúc đẩy sự đánh đổi này cũng như các thông số kỹ thuật. Bằng cách khiến việc gian lận trở nên tốn kém và sự tham gia trung thực trở nên có lợi, chúng ta có thể tạo ra một hệ thống mà sự lựa chọn hợp lý là sự tham gia trung thực.
Tối ưu hóa không gian
Sau nhiều tháng xây dựng và thử nghiệm, chúng tôi đã xây dựng một hệ thống kết hợp lợi thế lưu trữ hồ sơ và bảo mật của blockchain, đồng thời tiếp cận hiệu suất suy luận một lần của các nhà cung cấp tập trung. Sự căng thẳng cơ bản giữa bảo mật và hiệu suất là có thật, và không có giải pháp hoàn hảo nào, chỉ có những sự đánh đổi khác nhau.
Chúng tôi tin rằng khi mạng lưới mở rộng, nó sẽ có cơ hội thực sự để cạnh tranh với các nhà cung cấp tập trung trong khi vẫn duy trì quyền kiểm soát cộng đồng phi tập trung hoàn toàn. Cũng có nhiều tiềm năng để tối ưu hóa khi mạng lưới phát triển. Nếu bạn quan tâm đến việc tìm hiểu về quy trình này, vui lòng truy cập GitHub và tài liệu của chúng tôi, tham gia thảo luận trên Discord và tự mình tham gia vào mạng lưới.
Giới thiệu về Gonka.ai
Gonka là một mạng lưới phi tập trung được thiết kế để cung cấp sức mạnh tính toán AI hiệu quả. Mục tiêu thiết kế của nó là tối đa hóa việc sử dụng sức mạnh tính toán GPU toàn cầu để hoàn thành khối lượng công việc AI có ý nghĩa. Bằng cách loại bỏ các cổng kiểm soát tập trung, Gonka cung cấp cho các nhà phát triển và nhà nghiên cứu quyền truy cập không cần cấp phép vào tài nguyên điện toán, đồng thời thưởng cho tất cả người tham gia bằng token GNK gốc.
Gonka được ươm mầm bởi công ty phát triển AI Product Science Inc. của Mỹ. Được thành lập bởi anh em nhà Libermans, những người kỳ cựu trong ngành Web 2 và cựu giám đốc sản phẩm cốt lõi tại Snap Inc., công ty đã huy động thành công 18 triệu đô la vào năm 2023 từ các nhà đầu tư, bao gồm Coatue Management, nhà đầu tư của OpenAI, Slow Ventures, nhà đầu tư của Solana, K5, Insight và Benchmark Partners. Những người đóng góp ban đầu cho dự án bao gồm các công ty hàng đầu trong lĩnh vực Web 2-Web 3, chẳng hạn như 6 Blocks, Hard Yaka, Gcore và Bitfury.
Trang web chính thức | Github | X | Discord | Sách trắng | Mô hình kinh tế | Hướng dẫn sử dụng


