
IOSG: การวิเคราะห์หลายมิติของข้อพิพาทฝ่ายระหว่าง zkVM และ zkEVM
ผู้เขียน: ไบรอัน IOSG Ventures
ในปี 2022 ที่ผ่านมา ประเด็นหลักของการอภิปรายเกี่ยวกับการเปิดตัวดูเหมือนจะอยู่ที่ ZkEVM แต่อย่าลืมว่า ZkVM ก็เป็นวิธีการขยายอีกวิธีหนึ่งเช่นกัน แม้ว่า ZkEVM จะไม่ใช่จุดสนใจของบทความนี้ แต่ก็คุ้มค่าที่จะระลึกถึงความแตกต่างระหว่าง ZkVM และ ZkEVM ในหลายมิติ:
ความเข้ากันได้: แม้ว่าจะเป็นส่วนขยายทั้งหมดแต่โฟกัสก็ต่างกัน จุดเน้นของ ZkEVM คือการบรรลุความเข้ากันได้โดยตรงกับ EVM ที่มีอยู่ ในขณะที่การวางตำแหน่งของ ZkVM คือการบรรลุการขยายตัวที่สมบูรณ์ นั่นคือ เพื่อเพิ่มประสิทธิภาพตรรกะและประสิทธิภาพของ dapps ความเข้ากันได้ไม่ใช่หลัก เมื่อตั้งค่าเลเยอร์ล่างสุดแล้ว ความเข้ากันได้ของ EVM ก็สามารถทำได้เช่นกัน
ประสิทธิภาพการทำงาน: ทั้งคู่มีคอขวดด้านประสิทธิภาพที่สามารถคาดเดาได้ คอขวดหลักของ ZkEVM คือความเข้ากันได้กับ EVM ซึ่งไม่เหมาะสำหรับการสรุปค่าใช้จ่ายเพิ่มเติมที่เกิดขึ้นในระบบป้องกัน ZK คอขวดของ ZkVM คือข้อจำกัดของเอาต์พุตสุดท้ายนั้นซับซ้อนกว่าเนื่องจากการแนะนำชุดคำสั่ง ISA
ประสบการณ์ของนักพัฒนา: Type II ZkEVM (เช่น Scroll, Taiko) มุ่งเน้นไปที่ความเข้ากันได้กับ EVM Bytecode กล่าวอีกนัยหนึ่ง รหัส EVM ที่ระดับ Bytecode ขึ้นไปสามารถสร้างการพิสูจน์ความรู้ที่เป็นศูนย์ที่สอดคล้องกันผ่าน ZkEVM สำหรับ ZkVM มีสองทิศทาง แนวทางหนึ่งคือสร้าง DSL ของตัวเอง (เช่น Cairo) และอีกทางหนึ่งคือเข้ากันได้กับภาษาสำหรับผู้ใหญ่ที่มีอยู่ เช่น C++/Rust (เช่น Risc 0) ในอนาคต เราคาดหวังว่านักพัฒนา Ethereum ที่มีความมั่นคงดั้งเดิมจะสามารถโยกย้ายไปยัง ZkEVM ได้โดยไม่มีค่าใช้จ่าย และแอปพลิเคชันที่ใหม่กว่าและมีประสิทธิภาพมากขึ้นจะทำงานบน ZkVM

หลายคนน่าจะยังจำภาพนี้ได้ CairoVM ไม่มีส่วนเกี่ยวข้องกับ ZkEVM เหตุผลสำคัญสำหรับการต่อสู้แบบกลุ่มของ ZkEVM คือความแตกต่างในแนวคิดการออกแบบ
ก่อนที่จะพูดถึง ZkVM สิ่งแรกที่เรานึกถึงคือการนำระบบพิสูจน์ ZK ไปใช้ในบล็อกเชนอย่างไร ในวงกว้าง มีสองวิธีในการปรับใช้วงจร - ระบบที่ใช้วงจร (อิงตามวงจร) และระบบที่ใช้เครื่องเสมือน (อิงตาม vm)
ประการแรก หน้าที่ของระบบที่ใช้วงจรคือการแปลงโปรแกรมโดยตรงเป็นข้อจำกัดและส่งไปยังระบบพิสูจน์ ระบบที่ใช้เครื่องเสมือนดำเนินการโปรแกรมผ่านชุดคำสั่ง (ISA) และในกระบวนการสร้าง การติดตามการดำเนินการ จากนั้นวิถีการดำเนินการนี้จะถูกแมปเข้ากับข้อจำกัด ซึ่งจากนั้นจะถูกป้อนเข้าสู่ระบบพิสูจน์
สำหรับระบบที่ใช้วงจร การคำนวณของโปรแกรมจะถูกจำกัดโดยแต่ละเครื่องที่รันโปรแกรม สำหรับระบบที่ใช้เครื่องเสมือน ISA จะฝังอยู่ในเครื่องสร้างวงจรและสร้างข้อจำกัดของโปรแกรม ขณะเดียวกัน เครื่องกำเนิดวงจรก็มีข้อจำกัด เช่น ชุดคำสั่ง รอบการทำงาน และหน่วยความจำ เครื่องเสมือนมีลักษณะทั่วไป กล่าวคือ เครื่องใดๆ สามารถเรียกใช้โปรแกรมได้ตราบเท่าที่เงื่อนไขการทำงานของโปรแกรมอยู่ในข้อจำกัดที่กล่าวถึงข้างต้น
คำอธิบายภาพ

เครดิตรูปภาพ: Bryan, IOSG Ventures
ข้อดีและข้อเสีย:
จากมุมมองของนักพัฒนา การพัฒนาในระบบที่ใช้วงจรมักต้องการความเข้าใจอย่างลึกซึ้งเกี่ยวกับต้นทุนของแต่ละข้อจำกัด อย่างไรก็ตาม สำหรับการเขียนโปรแกรมเครื่องเสมือน วงจรเป็นแบบคงที่ และนักพัฒนาจำเป็นต้องใส่ใจมากขึ้นเกี่ยวกับคำแนะนำ
จากมุมมองของผู้ตรวจสอบ ระบบที่ใช้วงจรและเครื่องเสมือนมีความแตกต่างกันอย่างมากในลักษณะทั่วไปของวงจร โดยสมมติว่าใช้ SNARK บริสุทธิ์เหมือนกันเป็นแบ็กเอนด์ ระบบวงจรสร้างวงจรที่แตกต่างกันสำหรับแต่ละโปรแกรม ในขณะที่เครื่องเสมือนสร้างวงจรเดียวกันสำหรับโปรแกรมต่างๆ ซึ่งหมายความว่าในการยกเลิก ระบบวงจรจำเป็นต้องปรับใช้สัญญาผู้ตรวจสอบหลายรายการใน L1
จากมุมมองของแอปพลิเคชัน เครื่องเสมือนทำให้ตรรกะของแอปพลิเคชันซับซ้อนขึ้นโดยการฝังรูปแบบหน่วยความจำ (หน่วยความจำ) ลงในการออกแบบ และจุดประสงค์ของการใช้ระบบวงจรคือเพื่อปรับปรุงประสิทธิภาพของโปรแกรม
จากมุมมองของความซับซ้อนของระบบ (complexity) เครื่องเสมือนจะรวมเอาความซับซ้อนที่มากกว่าไว้ในระบบ เช่น โมเดลหน่วยความจำ การสื่อสารระหว่างโฮสต์ (host) และไคลเอนต์ (guest) เป็นต้น เมื่อเทียบกับระบบวงจรที่ง่ายกว่า
คำอธิบายภาพ
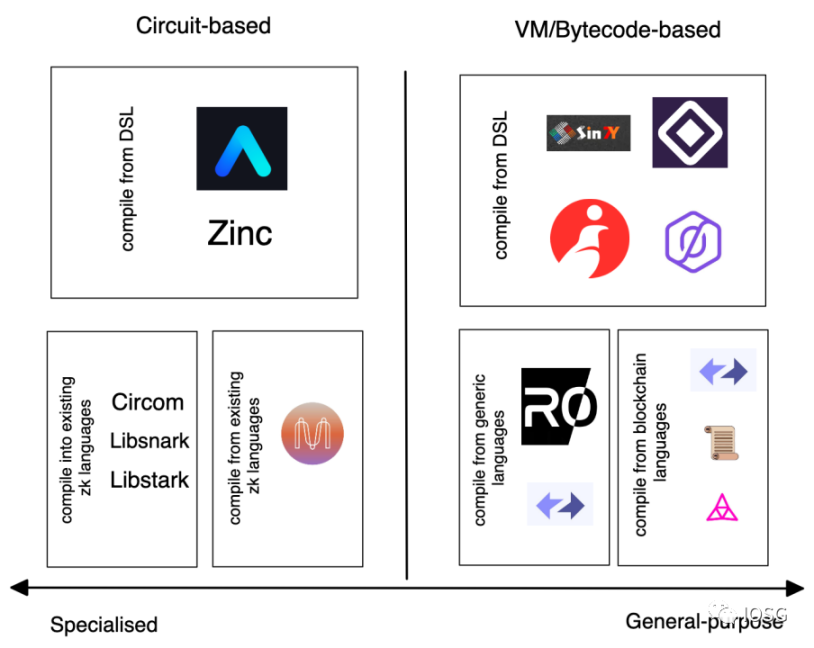
ชื่อระดับแรก
หลักการออกแบบเครื่องเสมือน
ชื่อเรื่องรอง
1. ชุดคำสั่งไอเอสเอ
ระบุวิธีการทำงานของวงจรกำเนิด ความรับผิดชอบหลักคือการแมปคำสั่งเข้ากับข้อจำกัดอย่างถูกต้อง ซึ่งจากนั้นป้อนเข้าระบบพิสูจน์ ระบบ zk ใช้ RISC (ชุดคำสั่งย่อ) มีสองตัวเลือก ISA:
อย่างแรกคือการสร้าง ISA แบบกำหนดเอง (custom ISA) ซึ่งเห็นได้จากการออกแบบของไคโร โดยทั่วไปแล้ว ตรรกะข้อจำกัดมีสี่ประเภทดังนี้

จุดเน้นการออกแบบพื้นฐานของ ISA แบบกำหนดเองคือเพื่อให้แน่ใจว่ามีข้อจำกัดน้อยที่สุดเท่าที่จะเป็นไปได้ เพื่อให้ทั้งการดำเนินการโปรแกรมและการตรวจสอบทำงานได้อย่างรวดเร็ว
ชื่อเรื่องรอง
2. คอมไพเลอร์
พูดกว้าง ๆ คอมไพเลอร์ค่อย ๆ แปลภาษาโปรแกรมเป็นรหัสเครื่อง ในบริบทของ ZK หมายถึงการแสดงโค้ดระดับต่ำที่รวบรวมไว้ในระบบข้อจำกัด (R 1 CS, QAP, AIR ฯลฯ) โดยใช้ภาษาระดับสูง เช่น C, C++, Rust เป็นต้น มีสองวิธีคือ
ออกแบบคอมไพเลอร์ตามการแสดงวงจร zk ที่มีอยู่ เช่น ใน ZK การแสดงวงจรเริ่มต้นจากไลบรารีที่เรียกได้โดยตรง เช่น Bellman และภาษาระดับต่ำ เช่น Circom ในการรวมการแทนค่าที่แตกต่างกัน คอมไพเลอร์อย่าง Zokrates (ตัวมันเองคือ DSL) มีเป้าหมายที่จะจัดเตรียมเลเยอร์นามธรรมที่สามารถรวบรวมเป็นการแทนค่าระดับล่างโดยพลการ
สร้างบนโครงสร้างพื้นฐานคอมไพเลอร์ (ที่มีอยู่) ตรรกะพื้นฐานคือการใช้ตัวแทนระดับกลางสำหรับส่วนหน้าและส่วนหลังหลายส่วน
คอมไพเลอร์ของ Risc 0 ใช้การแทนระดับกลางแบบหลายระดับ (MLIR) ซึ่งสามารถสร้าง IR ได้หลายตัว (คล้ายกับ LLVM) IR ที่แตกต่างกันช่วยให้นักพัฒนามีความยืดหยุ่น เนื่องจาก IR ที่แตกต่างกันมีจุดเน้นในการออกแบบของตนเอง เช่น บาง IR ได้รับการปรับให้เหมาะกับฮาร์ดแวร์โดยเฉพาะ ดังนั้นนักพัฒนาจึงสามารถเลือกได้ตามความต้องการของตนเอง แนวคิดที่คล้ายกันสามารถเห็นได้ใน vnTinyRAM และ TinyRAM โดยใช้ GCC ZkSync เป็นอีกตัวอย่างหนึ่งของการใช้ประโยชน์จากโครงสร้างพื้นฐานของคอมไพเลอร์
นอกจากนี้ คุณยังสามารถดูโครงสร้างพื้นฐานคอมไพเลอร์สำหรับ zk เช่น CirC ซึ่งยืมแนวคิดการออกแบบบางอย่างจาก LLVM
นอกจากสองขั้นตอนการออกแบบที่สำคัญที่สุดข้างต้นแล้ว ยังมีข้อควรพิจารณาอื่นๆ อีกบางประการ:
1. การแลกเปลี่ยนระหว่างความปลอดภัยของระบบ (ความปลอดภัย) และต้นทุนการตรวจสอบ (ต้นทุนการตรวจสอบ)
ยิ่งจำนวนบิตที่ระบบใช้มาก (นั่นคือ ความปลอดภัยยิ่งสูง) ค่าใช้จ่ายในการตรวจสอบก็จะยิ่งสูงขึ้น ความปลอดภัยสะท้อนอยู่ในตัวสร้างคีย์ (เช่นใน SNARK ที่แสดงเส้นโค้งวงรี)
2. ความเข้ากันได้กับส่วนหน้าและส่วนหลัง
ความเข้ากันได้ขึ้นอยู่กับความพร้อมของตัวแทนระดับกลางสำหรับวงจร IR จำเป็นต้องสร้างสมดุลระหว่างความถูกต้อง (เอาต์พุตของโปรแกรมตรงกับอินพุตหรือไม่ + เอาต์พุตตรงกับระบบพิสูจน์หรือไม่) และความยืดหยุ่น (รองรับส่วนหน้าและส่วนหลังหลายส่วน) หากเดิมที IR ได้รับการออกแบบมาเพื่อแก้ปัญหาระบบที่มีข้อจำกัดระดับต่ำ เช่น R 1 CS ความเข้ากันได้กับระบบที่มีข้อจำกัดระดับสูงกว่าอื่นๆ เช่น AIR นั้นเป็นเรื่องยาก
3. เพื่อปรับปรุงประสิทธิภาพ จำเป็นต้องใช้วงจรที่สร้างขึ้นด้วยมือ
ข้อเสียของการใช้แบบจำลองสำหรับวัตถุประสงค์ทั่วไปคือมีประสิทธิภาพน้อยกว่าสำหรับการดำเนินการง่ายๆ บางอย่างที่ไม่ต้องการคำแนะนำที่ซับซ้อน
อธิบายทฤษฎีก่อนหน้านี้บางส่วนโดยสังเขป
ก่อนโปรโตคอล Pinocchio: การคำนวณที่ตรวจสอบได้สำเร็จ แต่เวลาการตรวจสอบช้ามาก
โปรโตคอล Pinocchio: ให้ความเป็นไปได้ทางทฤษฎีในแง่ของการตรวจสอบและอัตราความสำเร็จในการตรวจสอบ (นั่นคือ เวลาการตรวจสอบสั้นกว่าเวลาดำเนินการของโปรแกรม) และเป็นระบบที่ใช้วงจร
โปรโตคอล TinyRAM: เมื่อเปรียบเทียบกับโปรโตคอล Pinocchio แล้ว TinyRAM เป็นเหมือนเครื่องเสมือนมากกว่า โดยเปิดตัว ISA ดังนั้นจึงกำจัดข้อจำกัดบางอย่าง เช่น การเข้าถึงหน่วยความจำ (RAM) โฟลว์การควบคุม (โฟลว์การควบคุม) เป็นต้น
โปรโตคอล vnTinyRAM: ทำให้การสร้างคีย์เป็นอิสระจากแต่ละโปรแกรม ทำให้มีความสามารถรอบด้านเพิ่มเติม เครื่องกำเนิดวงจรขยาย เช่น สามารถจัดการโปรแกรมขนาดใหญ่ได้
โมเดลด้านบนทั้งหมดใช้ SNARK เป็นระบบป้องกันแบ็กเอนด์ แต่โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับเครื่องเสมือน STARK และ Plonk ดูเหมือนจะเป็นแบ็กเอนด์ที่เหมาะสมกว่า โดยพื้นฐานแล้วเนื่องจากระบบข้อจำกัดของพวกมันนั้นเหมาะสมกว่าสำหรับการนำลอจิกแบบซีพียูมาใช้
ต่อไป บทความนี้จะแนะนำเครื่องเสมือนที่ใช้ STARK สามเครื่อง ได้แก่ Risc 0, MidenVM, CairoVM กล่าวโดยย่อ นอกเหนือจากการใช้ STARK เป็นระบบพิสูจน์แล้ว ทั้งคู่ยังมีข้อแตกต่างบางประการ:
Risc 0 ใช้ประโยชน์จาก Risc-V เพื่อความเรียบง่ายของชุดคำสั่ง R 0 คอมไพล์ใน MLIR ซึ่งเป็นตัวแปรของ LLVM-IR ที่ออกแบบมาเพื่อรองรับภาษาการเขียนโปรแกรมสำหรับวัตถุประสงค์ทั่วไปที่มีอยู่หลายภาษา เช่น Rust, C++ Risc-V ยังมีประโยชน์เพิ่มเติมบางอย่าง เช่น เป็นมิตรกับฮาร์ดแวร์มากกว่า
Miden ตั้งเป้าหมายให้เข้ากันได้กับ Ethereum Virtual Machine (EVM) โดยพื้นฐานแล้วเป็นการรวบรวม EVM ขณะนี้ Miden มีภาษาโปรแกรมของตัวเองแล้ว แต่กำลังทำงานเพื่อสนับสนุน Move ในอนาคตด้วย
Cairo VM พัฒนาโดย Starkware ระบบพิสูจน์ STARK ที่ใช้โดยทั้งสามระบบนี้คิดค้นโดย Eli Ben-Sasson ซึ่งปัจจุบันเป็นประธานของ Starkware
มาดูความแตกต่างกันให้ลึกซึ้งยิ่งขึ้น:
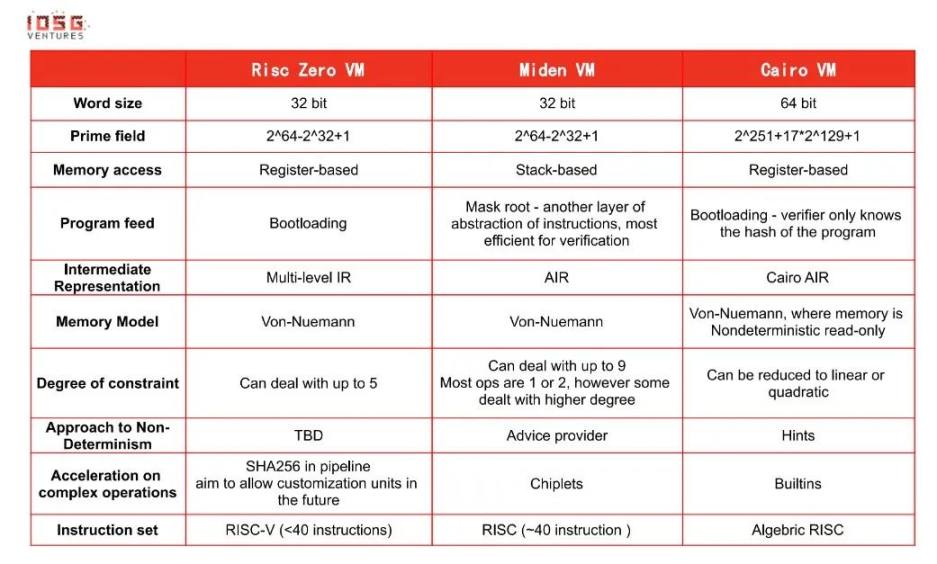
* วิธีการอ่านแบบฟอร์มข้างต้น? บันทึกบางอย่าง...
ขนาดคำ - เนื่องจากระบบข้อจำกัดเหล่านี้ใช้เครื่องเสมือนเหล่านี้คือ AIR จึงทำงานคล้ายกับสถาปัตยกรรม CPU ดังนั้นจึงเหมาะสมกว่าที่จะเลือกความยาวคำของ CPU (32/64 บิต)
การเข้าถึงหน่วยความจำ (การอ่านหน่วยความจำ) - เหตุผลที่ Risc 0 ใช้รีจิสเตอร์เป็นส่วนใหญ่เนื่องจากชุดคำสั่ง Risc-V ใช้รีจิสเตอร์ Miden ใช้สแตกในการจัดเก็บข้อมูลเป็นหลัก เนื่องจาก AIR ทำหน้าที่เหมือนกับสแตก CairoVM ไม่ใช้การลงทะเบียนวัตถุประสงค์ทั่วไป เนื่องจากการเข้าถึงหน่วยความจำ (หน่วยความจำหลัก) มีค่าใช้จ่ายต่ำในโมเดลไคโร
ฟีดโปรแกรม (การทำงานของโปรแกรม) - วิธีการต่าง ๆ มีการแลกเปลี่ยน ตัวอย่างเช่น สำหรับวิธีแมสต์รูท จำเป็นต้องถอดรหัสเมื่อประมวลผลคำสั่ง ดังนั้นค่าใช้จ่ายในการพิสูจน์จึงสูงในโปรแกรมที่มีหลายขั้นตอน
วิธีการ bootloading พยายามที่จะรักษาสมดุลระหว่างค่าใช้จ่ายในการพิสูจน์และค่าใช้จ่ายของผู้ตรวจสอบในขณะที่รักษาความเป็นส่วนตัว
ความไม่เป็นตัวกำหนด - ความไม่เป็นตัวกำหนดเป็นคุณสมบัติที่สำคัญของปัญหาที่สมบูรณ์ของ NP การใช้ non-determinism ช่วยตรวจสอบการดำเนินการในอดีตได้อย่างรวดเร็ว ในทางกลับกัน จะเพิ่มข้อจำกัดมากขึ้น ดังนั้นจะมีการประนีประนอมในการตรวจสอบความถูกต้อง
การเร่งความเร็วในการดำเนินการที่ซับซ้อน - การคำนวณบางอย่างทำงานช้ามากบน CPU ตัวอย่างเช่น การทำงานของบิต เช่น XOR และ AND โปรแกรมแฮช เช่น ECDSA และการตรวจสอบช่วง... ส่วนใหญ่มาจาก blockchain/crypto แต่ไม่ใช่การทำงานของ CPU (ยกเว้นการดำเนินการบิต) การใช้การดำเนินการเหล่านี้โดยตรงผ่าน DSL จะทำให้วงจรการพิสูจน์หมดไปอย่างง่ายดาย
Permutation/multiset (การเรียงสับเปลี่ยน / การรวมหลายคอลัมน์) - ใช้มากใน zkVM ส่วนใหญ่ มีวัตถุประสงค์สองประการ - 1. ลดค่าใช้จ่ายของผู้ตรวจสอบโดยลดการจัดเก็บการติดตามการดำเนินการทั้งหมด (การติดตามการดำเนินการ) 2. พิสูจน์ว่าผู้ตรวจสอบทราบ การติดตามการดำเนินการแบบเต็ม
ในตอนท้ายของบทความ ผู้เขียนต้องการพูดคุยเกี่ยวกับการพัฒนาในปัจจุบันของ Risc 0 และสาเหตุที่ทำให้ฉันตื่นเต้น
R 0 การพัฒนาในปัจจุบัน:
ก. โครงสร้างพื้นฐานคอมไพเลอร์ "Zirgen" ที่พัฒนาขึ้นเองอยู่ในระหว่างการพัฒนา มันน่าสนใจที่จะเปรียบเทียบประสิทธิภาพของ Zirgen กับคอมไพเลอร์เฉพาะ zk ที่มีอยู่บางตัว
ข. นวัตกรรมที่น่าสนใจบางอย่าง เช่น การขยายฟิลด์ สามารถบรรลุพารามิเตอร์ความปลอดภัยที่มั่นคงมากขึ้นและดำเนินการกับจำนวนเต็มจำนวนมากขึ้น
ค. เพื่อเป็นสักขีพยานในความท้าทายที่พบในการผสานรวมระหว่าง ZK Hardware และ ZK Software บริษัท Risc 0 ใช้เลเยอร์นามธรรมของฮาร์ดแวร์เพื่อการพัฒนาที่ดีขึ้นในด้านฮาร์ดแวร์
d.ยังอยู่ในระหว่างดำเนินการ!ยังอยู่ระหว่างการพัฒนา!
รองรับวงจรที่สร้างขึ้นด้วยมือและอัลกอริทึมแฮชหลายตัว ปัจจุบัน มีการใช้วงจร SHA 256 เฉพาะ แต่ไม่ตรงตามข้อกำหนดทั้งหมด ผู้เขียนเชื่อว่าการเลือกวงจรที่จะปรับให้เหมาะสมนั้นขึ้นอยู่กับกรณีการใช้งานที่ Risc 0 ให้มา SHA 256 เป็นจุดเริ่มต้นที่ดีมาก ในทางกลับกัน ZKVM อยู่ในตำแหน่งที่ให้ความยืดหยุ่นแก่ผู้คน เช่น ไม่ต้องกังวลกับ Keccak หากพวกเขาไม่ต้องการ :)
การเรียกซ้ำ: นี่เป็นหัวข้อใหญ่ และฉันมักจะไม่เจาะลึกในรายงานนี้ โปรดทราบว่าเนื่องจาก Risc 0 มีแนวโน้มที่จะรองรับกรณีการใช้งาน/โปรแกรมที่ซับซ้อนมากขึ้น ความจำเป็นในการเรียกซ้ำจึงเร่งด่วนมากขึ้น เพื่อรองรับการเรียกซ้ำเพิ่มเติม พวกเขากำลังทำงานกับโซลูชันการเร่งความเร็ว GPU ฝั่งฮาร์ดแวร์
การจัดการกับความไม่แน่นอน: นี่คือคุณสมบัติที่ ZKVM ต้องจัดการ ในขณะที่เครื่องเสมือนแบบดั้งเดิมไม่มีปัญหานี้ ความไม่แน่นอนสามารถช่วยให้เครื่องเสมือนทำงานได้เร็วขึ้น MLIR ค่อนข้างดีกว่าในการจัดการกับปัญหาเครื่องเสมือนแบบดั้งเดิม และการที่ Risc 0 ฝังความไม่แน่นอนลงในการออกแบบระบบ ZKVM ก็คุ้มค่าที่จะตั้งตารอ
WHAT EXCITES ME:
ก. ง่ายและตรวจสอบได้!
ในระบบแบบกระจาย PoW ต้องการความซ้ำซ้อนในระดับสูงเนื่องจากผู้คนไม่ไว้วางใจผู้อื่น ดังนั้นการคำนวณเดียวกันจึงจำเป็นต้องดำเนินการซ้ำๆ เพื่อให้ได้ฉันทามติ และด้วยการใช้การพิสูจน์ความรู้เป็นศูนย์ การตระหนักรู้สถานะควรจะง่ายเหมือนการตกลงว่า 1+1=2
ข กรณีการใช้งานจริงเพิ่มเติม:
นอกเหนือจากการขยายโดยตรงที่สุดแล้ว กรณีการใช้งานที่น่าสนใจมากขึ้นจะเป็นไปได้ เช่น การเรียนรู้ของเครื่องที่ไม่มีความรู้ การวิเคราะห์ข้อมูล เป็นต้น เมื่อเปรียบเทียบกับภาษา ZK ที่เฉพาะเจาะจง เช่น ไคโร แล้ว Rust/C++ นั้นมีความหลากหลายและมีประสิทธิภาพมากกว่า และกรณีการใช้งาน web2 ที่ทำงานบน Risc 0 VM นั้นมีจำนวนมากกว่า
c. ชุมชนนักพัฒนาที่ครอบคลุมมากขึ้น/เติบโตเต็มที่:
นักพัฒนาที่สนใจใน STARK และ blockchain ไม่จำเป็นต้องเรียนรู้ DSL ใหม่ เพียงแค่ใช้ Rust/C++


