
การวิเคราะห์เชิงลึกของแทร็กล้านล้านถัดไป: การผสมผสานระหว่างการพิสูจน์ความรู้เป็นศูนย์แ
1. ประวัติความเป็นมาและโอกาสทางการตลาดของคอมพิวเตอร์แบบกระจาย
ชื่อเรื่องรอง
1.1 ประวัติการพัฒนา
ในตอนเริ่มต้น คอมพิวเตอร์แต่ละเครื่องสามารถทำงานประมวลผลได้เพียงงานเดียว เมื่อเกิด CPU แบบมัลติคอร์และมัลติเธรด คอมพิวเตอร์เครื่องเดียวสามารถทำงานประมวลผลหลายอย่างได้
เนื่องจากธุรกิจของเว็บไซต์ขนาดใหญ่เพิ่มขึ้น จึงเป็นเรื่องยากที่จะขยายความจุของรุ่นเซิร์ฟเวอร์เดียว ซึ่งจะทำให้ต้นทุนฮาร์ดแวร์เพิ่มขึ้น สถาปัตยกรรมเชิงบริการปรากฏขึ้นซึ่งประกอบด้วยเซิร์ฟเวอร์หลายเครื่อง ประกอบด้วยผู้ลงทะเบียนบริการ ผู้ให้บริการ และผู้ใช้บริการ
อย่างไรก็ตาม ด้วยการเพิ่มขึ้นของธุรกิจและเซิร์ฟเวอร์ ความสามารถในการบำรุงรักษาและความสามารถในการปรับขนาดของบริการแบบจุดต่อจุดจะยากขึ้นภายใต้โมเดล SOA คล้ายกับหลักการของไมโครคอมพิวเตอร์ โหมดบัส ปรากฏขึ้นเพื่อประสานงานหน่วยบริการต่างๆ Service Bus เชื่อมต่อระบบทั้งหมดเข้าด้วยกันผ่านสถาปัตยกรรมแบบฮับ ส่วนประกอบนี้เรียกว่า ESB (Enterprise Service Bus) ในฐานะตัวกลางทำหน้าที่แปลและประสานงานข้อตกลงการบริการในรูปแบบหรือมาตรฐานต่างๆ
จากนั้นการสื่อสารโมเดล REST ที่ใช้โปรแกรมมิงอินเทอร์เฟซโปรแกรมประยุกต์ (API) มีความโดดเด่นในด้านความเรียบง่ายและความสามารถในการจัดองค์ประกอบที่สูงขึ้น แต่ละบริการส่งออกอินเทอร์เฟซในรูปแบบของ REST เมื่อไคลเอ็นต์ส่งคำขอผ่าน RESTful API ไคลเอนต์จะส่งผ่านการแสดงสถานะทรัพยากรไปยังผู้ร้องขอหรือจุดสิ้นสุด ข้อมูลหรือการนำเสนอนี้ส่งผ่าน HTTP ในรูปแบบใดรูปแบบหนึ่งต่อไปนี้: JSON (Javascript Object Notation), HTML, XLT, Python, PHP หรือข้อความล้วน JSON เป็นภาษาโปรแกรมที่ใช้บ่อยที่สุด และแม้ว่าชื่อจะหมายถึง "JavaScript Object Notation" ในภาษาอังกฤษ แต่ก็ใช้ได้กับภาษาต่างๆ และสามารถอ่านได้ทั้งมนุษย์และเครื่องจักร
เครื่องเสมือน เทคโนโลยีคอนเทนเนอร์ และเอกสาร 3 ฉบับจาก Google:GFS: The Google File System
ปี 2546MapReduce: Simplified Data Processing on Large Clusters
ปี 2547Bigtable: A Distributed Storage System for Structured Data
ปี 2549
ระบบไฟล์แบบกระจาย การประมวลผลแบบกระจาย และฐานข้อมูลแบบกระจาย ซึ่งเปิดม่านของระบบแบบกระจาย Hadoop ทำซ้ำเอกสาร Google, Spark ที่รวดเร็วและง่ายต่อการใช้งาน และ Flink สำหรับการประมวลผลแบบเรียลไทม์
ห่วงโซ่สาธารณะของสัญญาอัจฉริยะที่แสดงโดย Ethereum สามารถเข้าใจได้โดยนามธรรมว่าเป็นเฟรมเวิร์กการประมวลผลแบบกระจายอำนาจ แต่ EVM เป็นเครื่องเสมือนที่มีชุดคำสั่งจำกัด ซึ่งไม่สามารถทำการประมวลผลทั่วไปที่ Web2 ต้องการได้ และทรัพยากรในห่วงโซ่ก็มีราคาแพงมากเช่นกัน ถึงกระนั้นก็ตาม Ethereum ยังได้ทำลายคอขวดของเฟรมเวิร์กการประมวลผลแบบจุดต่อจุด การสื่อสารแบบจุดต่อจุด ความสอดคล้องกันทั่วทั้งเครือข่ายของผลการคำนวณ และความสอดคล้องของข้อมูล
ชื่อเรื่องรอง
1.2 โอกาสทางการตลาด
เริ่มต้นจากความต้องการทางธุรกิจ เหตุใดเครือข่ายคอมพิวเตอร์แบบกระจายอำนาจจึงมีความสำคัญ ขนาดตลาดโดยรวมใหญ่แค่ไหน? ตอนนี้อยู่ในขั้นตอนใด และมีพื้นที่เท่าใดในอนาคต โอกาสใดที่สมควรได้รับความสนใจ? วิธีการทำเงิน?
ข้อความ
1.2.1 เหตุใดการคำนวณแบบกระจายศูนย์จึงมีความสำคัญ
ในวิสัยทัศน์ดั้งเดิมของ Ethereum มันจะกลายเป็นคอมพิวเตอร์ของโลก หลังจากการระเบิดของ ICO ในปี 2560 ทุกคนพบว่าการออกสินทรัพย์ยังคงเป็นจุดสนใจหลัก แต่ในปี 2020 ฤดูร้อนของ Defi ก็ปรากฏขึ้น และ Dapps จำนวนมากก็เริ่มปรากฏขึ้น ด้วยการระเบิดของข้อมูลในห่วงโซ่ EVM ไร้อำนาจมากขึ้นเมื่อเผชิญกับสถานการณ์ทางธุรกิจที่ซับซ้อนมากขึ้น จำเป็นต้องมีรูปแบบของการขยายแบบ off-chain เพื่อใช้งานฟังก์ชั่นที่ EVM ไม่สามารถรับรู้ได้ บทบาทเช่น oracles เป็นการกระจายอำนาจของคอมพิวเตอร์ในระดับหนึ่ง
เมื่อการพัฒนา Dapp ผ่านไปแล้ว จำเป็นต้องทำให้กระบวนการจาก 0 ถึง 1 เสร็จสมบูรณ์เท่านั้น ตอนนี้ต้องการสิ่งอำนวยความสะดวกพื้นฐานที่ทรงพลังมากขึ้นเพื่อรองรับสถานการณ์ทางธุรกิจที่ซับซ้อนยิ่งขึ้น Web3 ทั้งหมดได้ผ่านจากขั้นตอนของการพัฒนาแอปพลิเคชันของเล่นแล้ว และจำเป็นต้องเผชิญกับตรรกะและสถานการณ์ทางธุรกิจที่ซับซ้อนมากขึ้นในอนาคต
ข้อความ
1.2.2 ขนาดตลาดโดยรวมใหญ่แค่ไหน?
จะประเมินขนาดของตลาดได้อย่างไร? ประเมินจากขนาดของธุรกิจคอมพิวเตอร์แบบกระจายในฟิลด์ Web2? คูณด้วยอัตราการเจาะตลาดของ web3? คุณรวมการประเมินมูลค่าของโครงการจัดหาเงินที่เกี่ยวข้องในตลาดปัจจุบันหรือไม่?
เราไม่สามารถถ่ายโอนขนาดตลาดการประมวลผลแบบกระจายจาก Web2 ไปยัง Web3 ได้ด้วยเหตุผลต่อไปนี้: 1. การประมวลผลแบบกระจายในฟิลด์ Web2 ตอบสนองความต้องการส่วนใหญ่ และการประมวลผลแบบกระจายอำนาจในฟิลด์ Web3 นั้นมีความแตกต่างเพื่อตอบสนองความต้องการของตลาด หากมีการคัดลอก จะเป็นการขัดต่อสภาพแวดล้อมเบื้องหลังวัตถุประสงค์ของตลาด 2. สำหรับการประมวลผลแบบกระจายอำนาจในฟิลด์ Web3 ขอบเขตธุรกิจของตลาดที่จะเติบโตในอนาคตจะเป็นทั่วโลก ดังนั้นเราต้องเข้มงวดมากขึ้นในการประมาณขนาดของตลาด
งบประมาณสเกลโดยรวมของแทร็กที่เป็นไปได้ในฟิลด์ Web3 คำนวณตามประเด็นต่อไปนี้:
รูปแบบรายได้มาจากการออกแบบรูปแบบเศรษฐกิจของโทเค็น ตัวอย่างเช่น รูปแบบรายได้ของโทเค็นที่เป็นที่นิยมในปัจจุบันคือการใช้โทเค็นเป็นวิธีการชำระค่าธรรมเนียมระหว่างการทำธุรกรรม ดังนั้นรายได้ค่าธรรมเนียมสามารถสะท้อนความเจริญรุ่งเรืองของระบบนิเวศและกิจกรรมของการทำธุรกรรมทางอ้อม ในที่สุดก็ใช้เป็นมาตรฐานในการตัดสินมูลค่า แน่นอนว่ายังมีโทเค็นรูปแบบอื่นๆ ที่เติบโตเต็มที่ เช่น สำหรับการขุดจำนอง หรือคู่ธุรกรรม หรือสินทรัพย์ยึดของอัลกอริทึม Stablecoins ดังนั้น รูปแบบการประเมินมูลค่าของโครงการ Web3 จึงแตกต่างจากตลาดหุ้นแบบดั้งเดิมและเหมือนกับสกุลเงินของประเทศมากกว่า สถานการณ์ที่สามารถใช้โทเค็นได้จะแตกต่างกันไป ดังนั้นสำหรับการวิเคราะห์เฉพาะโครงการเฉพาะ เราสามารถลองสำรวจว่าควรออกแบบโมเดลโทเค็นอย่างไรในสถานการณ์จำลองการคำนวณแบบกระจายอำนาจของ Web3 ก่อนอื่น เราคิดว่าเราจะออกแบบให้ Decentralized Computing Framework เราจะพบกับความท้าทายแบบใด? ก) เนื่องจากเครือข่ายที่กระจายอำนาจอย่างสมบูรณ์เพื่อดำเนินการงานคอมพิวเตอร์ให้เสร็จสมบูรณ์ในสภาพแวดล้อมที่ไม่น่าไว้วางใจดังกล่าวจึงจำเป็นต้องกระตุ้นผู้ให้บริการทรัพยากรเพื่อให้แน่ใจว่าอัตราออนไลน์และคุณภาพบริการ ในแง่ของกลไกของเกม จำเป็นต้องตรวจสอบให้แน่ใจว่ากลไกการจูงใจนั้นสมเหตุสมผล และวิธีป้องกันผู้โจมตีจากการโจมตีแบบฉ้อฉล การโจมตีแบบ sybil และวิธีการโจมตีอื่นๆ ดังนั้น โทเค็นจึงจำเป็นสำหรับวิธีการจำนำเพื่อเข้าร่วมในเครือข่ายฉันทามติของ POS และรับประกันความสอดคล้องฉันทามติของโหนดทั้งหมดก่อน จำนวนงานที่พวกเขามีส่วนร่วมจำเป็นต้องใช้กลไกแรงจูงใจบางอย่าง สิ่งจูงใจ Token ต้องมีการเติบโตเป็นวงจรในเชิงบวกสำหรับการเติบโตของธุรกิจและการปรับปรุงประสิทธิภาพเครือข่าย ข) เมื่อเทียบกับเลเยอร์ 1 อื่นๆ เครือข่ายเองก็จะสร้างธุรกรรมจำนวนมากเช่นกัน เมื่อเผชิญกับธุรกรรมฝุ่นจำนวนมาก ธุรกรรมแต่ละรายการจะจ่ายค่าธรรมเนียมการจัดการ ซึ่งเป็นรูปแบบโทเค็นที่ได้รับการตรวจสอบโดย ตลาด. ค) หากมีการใช้โทเค็นเพื่อวัตถุประสงค์ในทางปฏิบัติเท่านั้น จะเป็นการยากที่จะขยายมูลค่าตลาดต่อไป หากใช้เป็นสินทรัพย์หลักของพอร์ตสินทรัพย์ จะมีการรวมสินทรัพย์ซ้อนกันหลายชั้น ซึ่งจะขยายผลกระทบของการเงินอย่างมาก การประเมินมูลค่าโดยรวม = อัตราจำนำ * อัตราการใช้ก๊าซ * (ส่วนกลับของการหมุนเวียน) * ราคาเดียว
ข้อความ
1.2.3 ตอนนี้อยู่ในขั้นตอนใด และมีพื้นที่เท่าใดในอนาคต
ตั้งแต่ปี 2017 ถึงปัจจุบัน หลายทีมพยายามพัฒนาไปสู่ทิศทางของ Decentralized Computing แต่ล้มเหลวทั้งหมด สาเหตุของความล้มเหลวจะอธิบายในรายละเอียดในภายหลัง เดิมทีเส้นทางการสำรวจเป็นโครงการที่คล้ายกับโครงการสำรวจเอเลี่ยน และต่อมาได้พัฒนาเพื่อเลียนแบบโมเดลการประมวลผลแบบคลาวด์แบบดั้งเดิม จากนั้นจึงเป็นการสำรวจโมเดลดั้งเดิมของ Web3
สถานะปัจจุบันของเส้นทางทั้งหมดคือความก้าวหน้าที่ได้รับการยืนยันจาก 0 ถึง 1 ในระดับการศึกษา และโครงการขนาดใหญ่บางโครงการมีความก้าวหน้าอย่างมากในการปฏิบัติงานด้านวิศวกรรม ตัวอย่างเช่น การใช้งาน zkRollup และ zkEVM ในปัจจุบันอยู่ในขั้นตอนของการเปิดตัวผลิตภัณฑ์
ยังมีช่องว่างอีกมากในอนาคตด้วยเหตุผลดังต่อไปนี้: 1. จำเป็นต้องปรับปรุงประสิทธิภาพของการคำนวณการตรวจสอบ 2. จำเป็นต้องเสริมชุดคำสั่งให้มากขึ้น 3. การเพิ่มประสิทธิภาพของสถานการณ์ทางธุรกิจที่แตกต่างกันอย่างแท้จริง 4. สถานการณ์ทางธุรกิจที่ไม่สามารถรับรู้ได้ด้วยสัญญาอัจฉริยะในอดีตสามารถรับรู้ได้ผ่านการประมวลผลแบบกระจายอำนาจ
แน่นอนว่านี่เป็นเพียงสถานการณ์ของแอปพลิเคชันที่เสนอ และ Web2 มีสถานการณ์ทางธุรกิจมากมายที่ต้องใช้พลังการประมวลผล
1.2.4 โอกาสใดที่ควรได้รับความสนใจ วิธีการทำเงิน?
2. ความพยายามในการคำนวณแบบกระจายศูนย์
ชื่อเรื่องรอง
2.1 รูปแบบบริการคลาวด์
ปัจจุบัน Ethereum มีปัญหาดังต่อไปนี้:
ปริมาณงานโดยรวมอยู่ในระดับต่ำ มันใช้พลังงานในการคำนวณมาก แต่ปริมาณงานนั้นเทียบเท่ากับสมาร์ทโฟนเท่านั้น
การตรวจสอบอยู่ในระดับต่ำ ปัญหานี้เรียกว่า Verifier's Dilemma โหนดที่ได้รับสิทธิ์ในการบรรจุจะได้รับรางวัล และโหนดอื่นจำเป็นต้องตรวจสอบ แต่ไม่ได้รับรางวัล และความกระตือรือร้นในการตรวจสอบต่ำ เมื่อเวลาผ่านไป การคำนวณอาจไม่ได้รับการยืนยัน ทำให้เกิดความเสี่ยงต่อความปลอดภัยของข้อมูลในห่วงโซ่
ปริมาณการคำนวณมีจำกัด (gasLimit) และต้นทุนการคำนวณสูง
บางทีมกำลังพยายามนำรูปแบบการประมวลผลแบบคลาวด์มาใช้อย่างกว้างขวางโดย Web2 ผู้ใช้จ่ายค่าธรรมเนียมจำนวนหนึ่ง และค่าธรรมเนียมจะคำนวณตามเวลาการใช้งานของทรัพยากรคอมพิวเตอร์ เหตุผลพื้นฐานในการนำแบบจำลองดังกล่าวมาใช้คือ เป็นไปไม่ได้ที่จะตรวจสอบว่างานการคำนวณดำเนินการอย่างถูกต้องหรือไม่ โดยผ่านพารามิเตอร์เวลาที่ตรวจจับได้หรือพารามิเตอร์ที่ควบคุมได้อื่นๆ เท่านั้น
ผลสุดท้ายแตกต่างจากความตั้งใจเดิมอย่างสิ้นเชิง
ชื่อเรื่องรอง
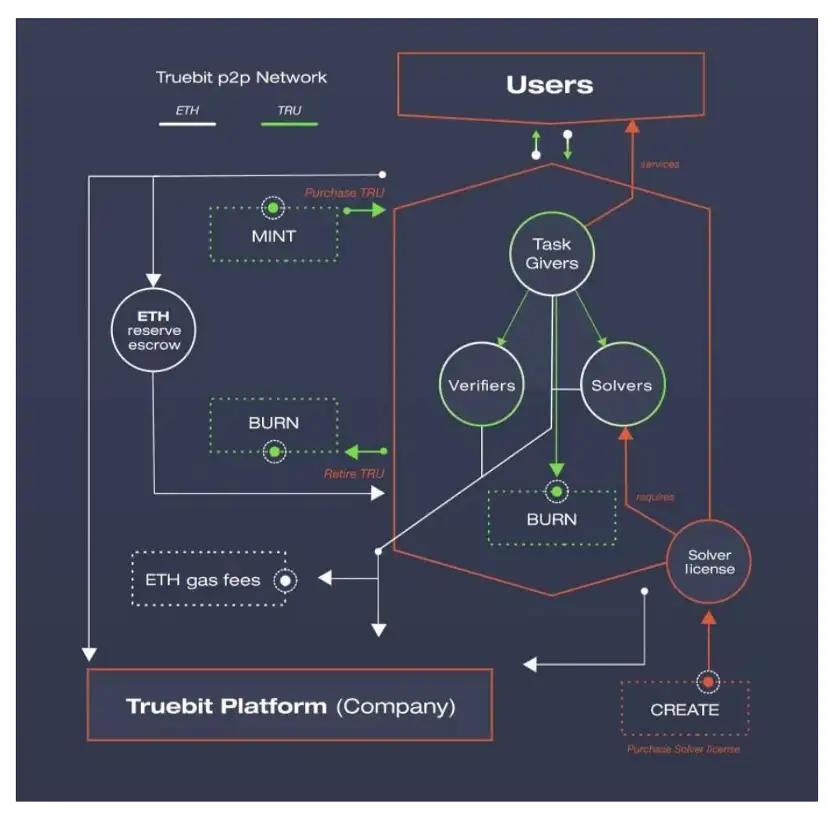
2.2 โหมดชาเลนเจอร์
https://www.aicoin.com/article/256862.html
ในทางกลับกัน TrueBit ใช้ระบบเกมเพื่อให้ได้โซลูชันที่เหมาะสมที่สุดทั่วโลก เพื่อให้แน่ใจว่างานการคำนวณแบบกระจายจะดำเนินการอย่างถูกต้อง
ประเด็นหลักของเฟรมเวิร์กการประมวลผลที่รวดเร็วของเรา:
บทบาท: นักแก้ปัญหา ผู้ท้าชิง และผู้พิพากษา
นักแก้ปัญหาจำเป็นต้องจำนำเงินก่อนจึงจะสามารถรับงานคอมพิวเตอร์ได้
ในฐานะนักล่าเงินรางวัล ผู้ท้าชิงจำเป็นต้องตรวจสอบซ้ำๆ ว่าผลการคำนวณของผู้แก้ปัญหานั้นสอดคล้องกับท้องถิ่นของตนหรือไม่
ผู้ท้าชิงจะแยกงานการคำนวณล่าสุดที่สอดคล้องกับสถานะการคำนวณของทั้งสอง หากมีจุด Divergence ให้ส่งค่าแฮชของ Merkle Tree ของจุด Divergence
ในตอนท้ายกรรมการจะตัดสินว่าการท้าทายนั้นสำเร็จหรือไม่
ผู้ท้าชิงสามารถส่งงานล่าช้าได้ ตราบใดที่พวกเขาทำงานส่งสำเร็จ ส่งผลให้ขาดความตรงต่อเวลา
ชื่อเรื่องรอง
2.3 ใช้หลักฐานที่ไม่มีความรู้เพื่อตรวจสอบการคำนวณ
ดังนั้นวิธีการบรรลุผลจึงไม่เพียงรับประกันว่ากระบวนการคำนวณสามารถตรวจสอบได้ แต่ยังรับประกันความตรงเวลาของการตรวจสอบอีกด้วย
ตัวอย่างเช่น ในการใช้งาน zkEVM จะต้องส่ง zkProof ที่ตรวจสอบได้สำหรับแต่ละบล็อกเวลา zkProof นี้มี bytecode ที่สร้างขึ้นโดยรหัสธุรกิจการคำนวณลอจิก จากนั้นจึงดำเนินการ bytecode เพื่อสร้างรหัสวงจร ด้วยวิธีนี้ ทำให้ทราบว่าตรรกะทางธุรกิจการคำนวณดำเนินการอย่างถูกต้อง และรับประกันความทันเวลาของการตรวจสอบผ่านเวลาที่สั้นและแน่นอน
ภายใต้สมมติฐานที่ว่ามีฮาร์ดแวร์การเร่งความเร็วแบบ Zero-knowledge proof ที่มีประสิทธิภาพสูงเพียงพอ และอัลกอริทึมการพิสูจน์แบบ zero-knowledge ที่ปรับให้เหมาะสมเพียงพอ สถานการณ์การคำนวณเพื่อวัตถุประสงค์ทั่วไปสามารถพัฒนาได้อย่างเต็มที่ บริการคอมพิวเตอร์จำนวนมากในสถานการณ์ Web2 สามารถทำซ้ำได้โดยเครื่องเสมือนสำหรับวัตถุประสงค์ทั่วไปที่ไม่มีความรู้ ทิศทางธุรกิจที่ทำกำไรได้ดังที่ได้กล่าวมาแล้ว
3. การผสมผสานระหว่างการพิสูจน์ความรู้เป็นศูนย์และการคำนวณแบบกระจาย
ชื่อเรื่องรอง
3.1 ระดับวิชาการ
ลองย้อนกลับไปดูพัฒนาการทางประวัติศาสตร์และวิวัฒนาการของอัลกอริทึมการพิสูจน์ด้วยความรู้เป็นศูนย์:
GMR 85 เป็นอัลกอริธึมแรกสุดที่ได้มาจากเอกสารที่ตีพิมพ์โดย Goldwasser, Micali และ Rackoff: The Knowledge Complexity of Interactive Proof Systems (ie GMR 85) ซึ่งเสนอในปี 1985 และเผยแพร่ในปี 1989 เอกสารนี้ส่วนใหญ่อธิบายถึงจำนวนความรู้ที่ต้องแลกเปลี่ยนหลังจากการโต้ตอบรอบ K ในระบบโต้ตอบเพื่อพิสูจน์ว่าข้อความนั้นถูกต้อง
Yao's Garbled Circuit (GC) [89]. โปรโตคอลการคำนวณที่ปลอดภัยสองฝ่ายที่ใช้การถ่ายโอนซึ่งรู้จักกันดีซึ่งสามารถประเมินฟังก์ชันใดก็ได้ แนวคิดหลักของวงจรที่ทำให้งงงวยคือการแยกวงจรการคำนวณ (เราสามารถดำเนินการทางคณิตศาสตร์ด้วยวงจร AND, วงจร OR และวงจร NOT) เข้าสู่ขั้นตอนการสร้างและขั้นตอนการประเมิน แต่ละฝ่ายมีหน้าที่รับผิดชอบในขั้นตอนที่เข้ารหัสวงจร ดังนั้นทั้งสองฝ่ายจึงไม่สามารถรับข้อมูลจากอีกฝ่ายได้ แต่ก็ยังสามารถรับผลลัพธ์ตามวงจรได้ วงจรที่ทำให้งงงวยประกอบด้วยโปรโตคอลการถ่ายโอนที่หลงลืมและรหัสลับ ความซับซ้อนของวงจรเพิ่มขึ้นอย่างน้อยเป็นเชิงเส้นกับเนื้อหาอินพุต หลังจากที่มีการเผยแพร่วงจรการทำให้งงงวย Goldreich-Micali-Wigderson (GMW) [91] ได้ขยายวงจรการทำให้งงงวยไปยังหลายฝ่ายเพื่อต่อต้านศัตรูที่ประสงค์ร้าย
โปรโตคอล sigma เป็นที่รู้จักกันว่า (พิเศษ) การพิสูจน์ความรู้เป็นศูนย์สำหรับผู้ตรวจสอบที่ซื่อสัตย์ นั่นคือถือว่าผู้ตรวจสอบมีความซื่อสัตย์ ตัวอย่างนี้คล้ายกับโปรโตคอลการตรวจสอบความถูกต้องของ Schnorr ยกเว้นว่าโปรโตคอลหลังมักจะไม่โต้ตอบ
Pinocchio (PGHR 13) ในปี 2013: Pinocchio: Nearly Practical Verifiable Computation ซึ่งบีบอัดเวลาการพิสูจน์และการตรวจสอบให้อยู่ในขอบเขตที่ใช้ได้ ยังเป็นโปรโตคอลพื้นฐานที่ Zcash ใช้
Groth 16 ในปี 2016: เกี่ยวกับขนาดของอาร์กิวเมนต์ที่ไม่มีการโต้ตอบตามการจับคู่ ซึ่งช่วยลดขนาดของการพิสูจน์และปรับปรุงประสิทธิภาพการตรวจสอบ ปัจจุบันเป็นอัลกอริทึมพื้นฐานของ ZK ที่ใช้กันอย่างแพร่หลายมากที่สุด
Bulletproofs (BBBPWM 17) Bulletproofs: Short Proofs for Confidential Transactions and More ในปี 2560 ได้เสนออัลกอริทึม Bulletproof ซึ่งเป็นการพิสูจน์ความรู้แบบ Zero-Knowledge ที่สั้นมากซึ่งไม่ต้องการการตั้งค่าที่เชื่อถือได้ และจะนำไปใช้กับ Monero ในอีก 6 เดือนต่อมา ซึ่ง เป็นการรวมทฤษฎีสู่แอปพลิเคชันที่รวดเร็วมาก
ในปี 2018 zk-STARKs (BBHR 18) ที่ปรับขนาดได้ โปร่งใส และความสมบูรณ์ของการคำนวณที่ปลอดภัยหลังควอนตัมได้เสนอโปรโตคอลอัลกอริทึม ZK-STARK ที่ไม่ต้องการการตั้งค่าที่เชื่อถือได้ จากสิ่งนี้ StarkWare ซึ่งเป็นโครงการ ZK ที่สำคัญที่สุดจึงถือกำเนิดขึ้น
Bulletproofs มีลักษณะดังนี้:
1) NIZK สั้น ๆ โดยไม่มีการตั้งค่าที่เชื่อถือได้
2) สร้างความมุ่งมั่นของ Pedersen
3) สนับสนุนการรวมหลักฐาน
4) เวลาพิสูจน์คือ: O ( N ⋅ log ( N ) ) O(N\cdot \log(N))O(N⋅log(N)) ประมาณ 30 วินาที
5) เวลาในการตรวจสอบคือ: O ( N ) O(N)O(N) ประมาณ 1 วินาที
6) ขนาดหลักฐานคือ: O ( log ( N ) ) O(\log(N))O(log(N)), ประมาณ 1.3 KB
7) สมมติฐานด้านความปลอดภัยขึ้นอยู่กับ: บันทึกที่ไม่ต่อเนื่อง
สถานการณ์ที่ใช้บังคับของ Bulletproofs คือ:
2 )inner product proofs
1) การพิสูจน์ช่วง (ประมาณ 600 ไบต์เท่านั้น)
4 )aggregated and distributed (with many private inputs) proofs
3) การตรวจสอบตัวกลางในโปรโตคอล MPC
คุณสมบัติที่สำคัญของ Halo 2 คือ:
1) รวมแผนการสะสมอย่างมีประสิทธิภาพกับการคำนวณทางคณิตศาสตร์ของ PLONKish โดยไม่ต้องตั้งค่าที่เชื่อถือได้
2) ตามโครงการความมุ่งมั่นของ IPA
3) นิเวศวิทยาของนักพัฒนาที่เจริญรุ่งเรือง\log N)O(N∗logN)。
4) เวลาพิสูจน์คือ: O ( N ∗ log N ) O(N*
5) เวลาตรวจสอบคือ: O ( 1 ) > O ( 1) > O ( 1) > Groth 16.\log N)O(logN)。
6) ขนาดหลักฐานคือ: O ( log N ) O(
7) สมมติฐานด้านความปลอดภัยขึ้นอยู่กับ: บันทึกที่ไม่ต่อเนื่อง
สถานการณ์ที่เหมาะสมสำหรับ Halo 2 รวมถึง:
1) การคำนวณใด ๆ ที่ตรวจสอบได้
2) องค์ประกอบการพิสูจน์แบบเรียกซ้ำ
3) การแฮชที่ปรับให้เหมาะกับวงจรโดยอิงจากฟังก์ชัน Sinsemilla ที่อิงกับการค้นหา
สถานการณ์ที่ Halo 2 ไม่เหมาะคือ:
1) เว้นแต่คุณจะแทนที่ Halo 2 ด้วยเวอร์ชัน KZG การตรวจสอบบน Ethereum จะมีราคาแพง
คุณสมบัติหลักของ Plonky 2 คือ:
1) รวม FRI กับ PLONK โดยไม่มีการตั้งค่าที่เชื่อถือได้
2) ปรับให้เหมาะสมสำหรับโปรเซสเซอร์ที่มี SIMD และใช้ฟิลด์ Goldilocks ขนาด 64 ไบต์\log N)O(logN)。
3) เวลาพิสูจน์คือ: O ( log N ) O(\log N)O(logN)。
4) เวลาตรวจสอบคือ: O ( log N ) O(\log N)O(N∗logN)。
5) ขนาดหลักฐานคือ: O ( N ∗ log N ) O(N*
6) สมมติฐานด้านความปลอดภัยขึ้นอยู่กับ: ฟังก์ชันแฮชที่ป้องกันการชนกัน
สถานการณ์ที่ Plonky 2 เหมาะสำหรับคือ:
1) การคำนวณที่ตรวจสอบได้โดยพลการ
2) องค์ประกอบการพิสูจน์แบบเรียกซ้ำ
3) ใช้เกตแบบกำหนดเองเพื่อเพิ่มประสิทธิภาพวงจร
สถานการณ์ที่ Plonky 2 ไม่เหมาะคือ:
ในปัจจุบัน Halo 2 ได้กลายเป็นอัลกอริทึมกระแสหลักที่ zkvm นำมาใช้ รองรับการพิสูจน์ซ้ำ และรองรับการตรวจสอบความถูกต้องของการคำนวณทุกประเภท เป็นการวางรากฐานสำหรับสถานการณ์การคำนวณทั่วไปของเครื่องเสมือนประเภท Zero-Knowledge Proof
ชื่อเรื่องรอง
3.2 ระดับปฏิบัติทางวิศวกรรม
ขณะนี้การพิสูจน์ความรู้ที่ไม่มีความรู้มีความก้าวหน้าอย่างก้าวกระโดดในระดับวิชาการ ความคืบหน้าในปัจจุบันเป็นอย่างไรเมื่อพูดถึงการพัฒนาจริง
เราสังเกตจากหลายระดับ:
ภาษาโปรแกรม: ปัจจุบันมีภาษาโปรแกรมเฉพาะที่ช่วยให้นักพัฒนาไม่จำเป็นต้องมีความเข้าใจอย่างลึกซึ้งเกี่ยวกับวิธีการออกแบบรหัสวงจร ซึ่งจะทำให้เกณฑ์การพัฒนาลดลง แน่นอนว่ายังมีการสนับสนุนสำหรับการแปล Solidity เป็นรหัสวงจร ความเป็นมิตรกับนักพัฒนานั้นดีขึ้นเรื่อยๆ
เครื่องเสมือน: ปัจจุบันมีการใช้งาน zkvm มากมาย ภาษาแรกคือภาษาโปรแกรมที่ออกแบบเองซึ่งรวบรวมเป็นรหัสวงจรผ่านคอมไพเลอร์ของตัวเอง และสุดท้าย zkproof ถูกสร้างขึ้น ประการที่สองคือการรองรับภาษาการเขียนโปรแกรมแบบ solidity ซึ่งรวบรวมเป็น bytecode เป้าหมายโดย LLVM และสุดท้ายแปลเป็นรหัสวงจรและ zkproof ประการที่สามคือความเข้ากันได้ที่เทียบเท่ากับ EVM อย่างแท้จริง ซึ่งสุดท้ายจะแปลการดำเนินการ bytecode เป็นรหัสวงจรและ zkproof นี่เป็นจุดจบของ zkvm หรือไม่ ไม่ ไม่ว่าจะเป็นสถานการณ์การประมวลผลเพื่อวัตถุประสงค์ทั่วไปที่ขยายออกไปนอกเหนือไปจากการเขียนโปรแกรมสัญญาอัจฉริยะ หรือความสมบูรณ์และการปรับให้เหมาะสมของ zkvm สำหรับชุดคำสั่งพื้นฐานในโครงร่างต่างๆ ก็ยังคงอยู่ในขั้น 1 ถึง N หนทางข้างหน้ายังอีกยาวไกล และงานด้านวิศวกรรมจำนวนมากจำเป็นต้องได้รับการปรับปรุงและนำไปใช้จริง แต่ละบริษัทประสบความสำเร็จตั้งแต่ระดับวิชาการไปจนถึงความรู้ด้านวิศวกรรม ผู้ซึ่งในที่สุดก็สามารถเป็นราชาและฆ่าล้างถนนนองเลือดได้ ไม่เพียงแต่ต้องมีความคืบหน้าอย่างมากในการปรับปรุงประสิทธิภาพเท่านั้น แต่ยังต้องดึงดูดนักพัฒนาจำนวนมากให้เข้าสู่ระบบนิเวศด้วย เวลาเป็นองค์ประกอบที่สำคัญมาก การผลักดันสู่ตลาดก่อน การดึงดูดเงินทุนเพื่อสะสม และแอปพลิเคชันที่เกิดขึ้นเองตามธรรมชาติในระบบนิเวศล้วนเป็นองค์ประกอบแห่งความสำเร็จ
เครื่องมือและสิ่งอำนวยความสะดวกสนับสนุนอุปกรณ์ต่อพ่วง: การสนับสนุนปลั๊กอินตัวแก้ไข ปลั๊กอินการทดสอบหน่วย เครื่องมือดีบักดีบัก ฯลฯ เพื่อช่วยให้นักพัฒนาสามารถพัฒนาแอปพลิเคชันที่ไม่มีความรู้ที่พิสูจน์ได้อย่างมีประสิทธิภาพมากขึ้น
โครงสร้างพื้นฐานสำหรับการเร่งการพิสูจน์ด้วยความรู้เป็นศูนย์: เนื่องจาก FFT และ MSM ใช้เวลาประมวลผลมากในอัลกอริทึมการพิสูจน์ด้วยความรู้เป็นศูนย์ทั้งหมด จึงสามารถดำเนินการแบบขนานบนอุปกรณ์ประมวลผลแบบขนาน เช่น GPU/FPGA เพื่อให้ได้ผลของเวลาบีบอัด ค่าใช้จ่าย
การเกิดขึ้นของโครงการดาว: zkSync, Starkware และโครงการคุณภาพสูงอื่น ๆ ได้ประกาศเวลาการเปิดตัวผลิตภัณฑ์อย่างเป็นทางการ มันแสดงให้เห็นว่าการรวมกันของการพิสูจน์ความรู้เป็นศูนย์และการคำนวณแบบกระจายศูนย์ไม่ได้อยู่ในระดับทฤษฎีอีกต่อไป แต่ค่อยๆ เติบโตในการปฏิบัติงานด้านวิศวกรรม
4. ปัญหาคอขวดที่พบและวิธีการแก้ไข
ชื่อเรื่องรอง
4.1 ประสิทธิภาพการสร้าง zkProof ต่ำ
เราได้กล่าวไว้ก่อนหน้านี้เกี่ยวกับกำลังการผลิตของตลาด การพัฒนาอุตสาหกรรมในปัจจุบัน และความก้าวหน้าทางเทคโนโลยีที่เกิดขึ้นจริง แต่ไม่มีความท้าทายใช่หรือไม่
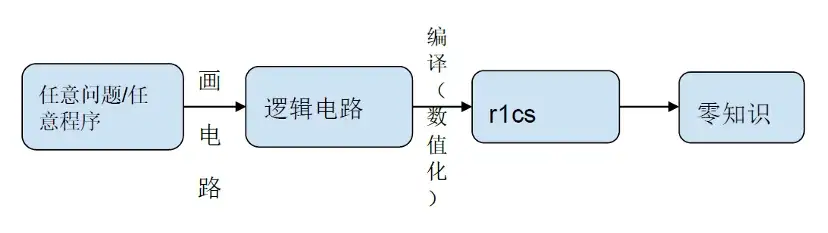
เราแยกชิ้นส่วนกระบวนการสร้าง zkProof ทั้งหมด:
ในขั้นตอนการคอมไพล์วงจรลอจิกและการกำหนดตัวเลข r 1 cs 80% ของการคำนวณอยู่ในบริการคอมพิวเตอร์ เช่น NTT และ MSM นอกจากนี้ อัลกอริทึมแฮชยังดำเนินการในระดับต่างๆ ของวงจรลอจิก เมื่อจำนวนระดับเพิ่มขึ้น เวลาโอเวอร์เฮดของอัลกอริทึมแฮชจะเพิ่มขึ้นเป็นเส้นตรง แน่นอน ตอนนี้อุตสาหกรรมเสนออัลกอริทึม GKR ที่ลดเวลาโอเวอร์เฮดลง 200 เท่า
อย่างไรก็ตาม ค่าใช้จ่ายในการประมวลผลของ NTT และ MSM ยังคงสูงอยู่ หากคุณต้องการลดเวลารอคอยสำหรับผู้ใช้และปรับปรุงประสบการณ์ผู้ใช้ คุณต้องเร่งความเร็วที่ระดับของการใช้งานทางคณิตศาสตร์ การปรับสถาปัตยกรรมซอฟต์แวร์ให้เหมาะสม GPU/FPGA/ASIC เป็นต้น
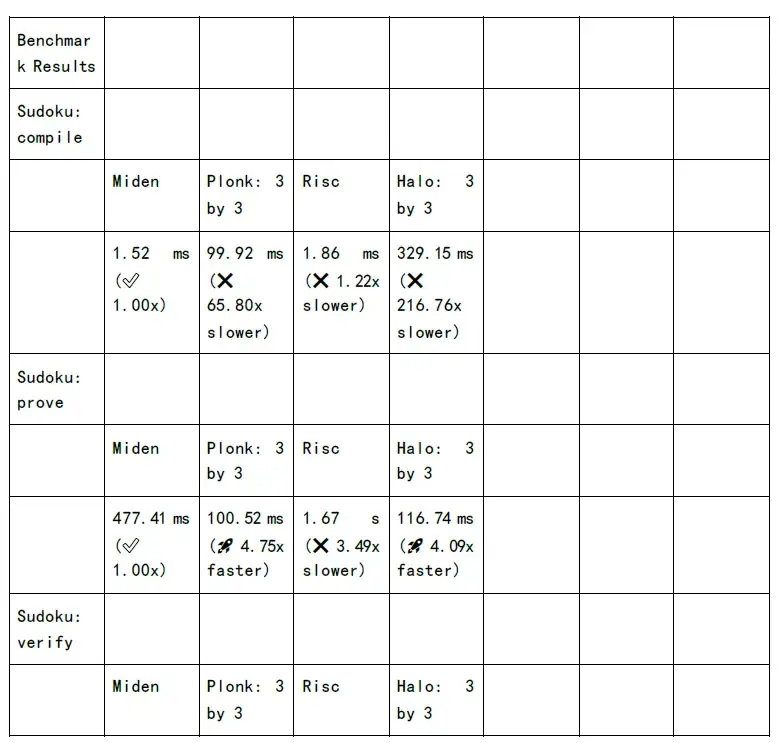
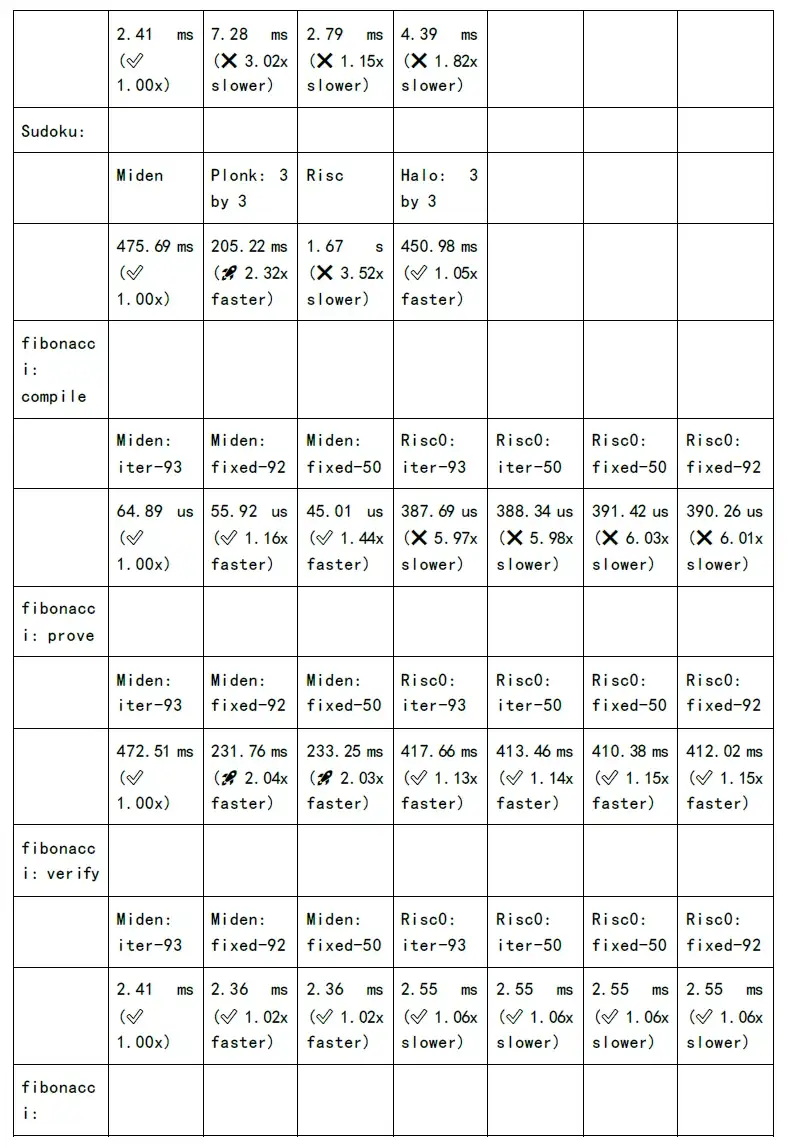
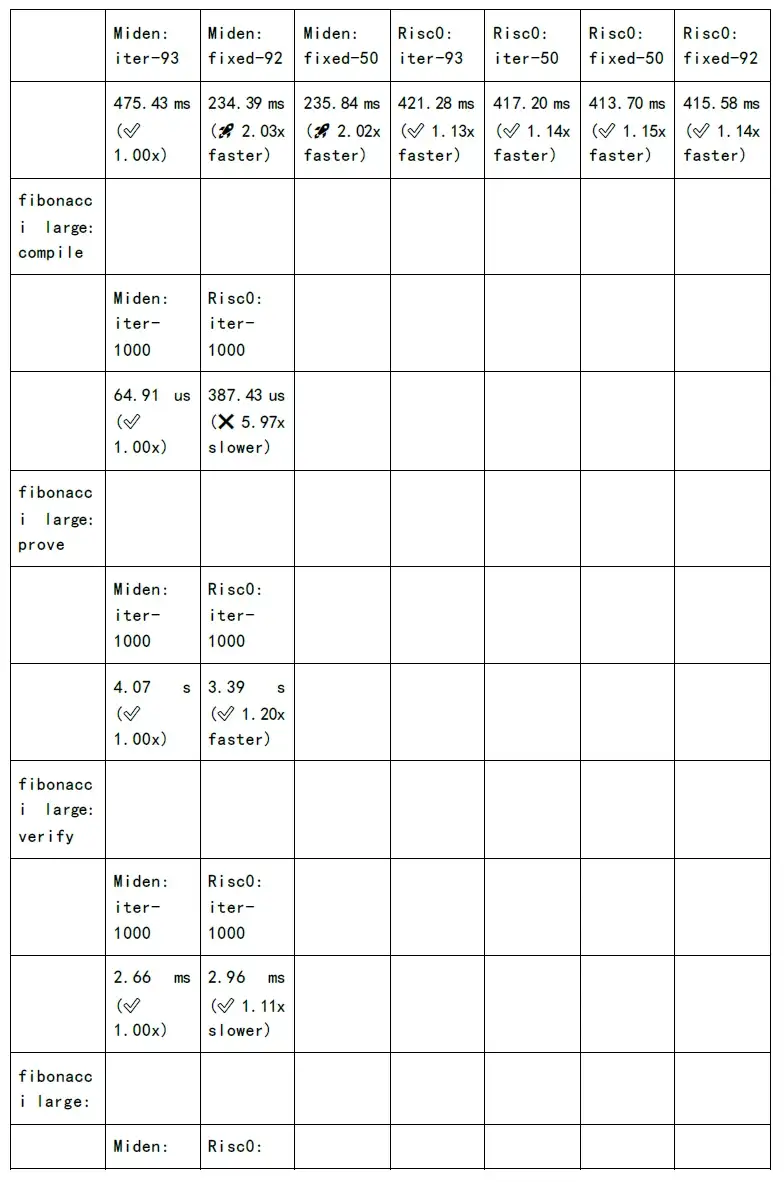
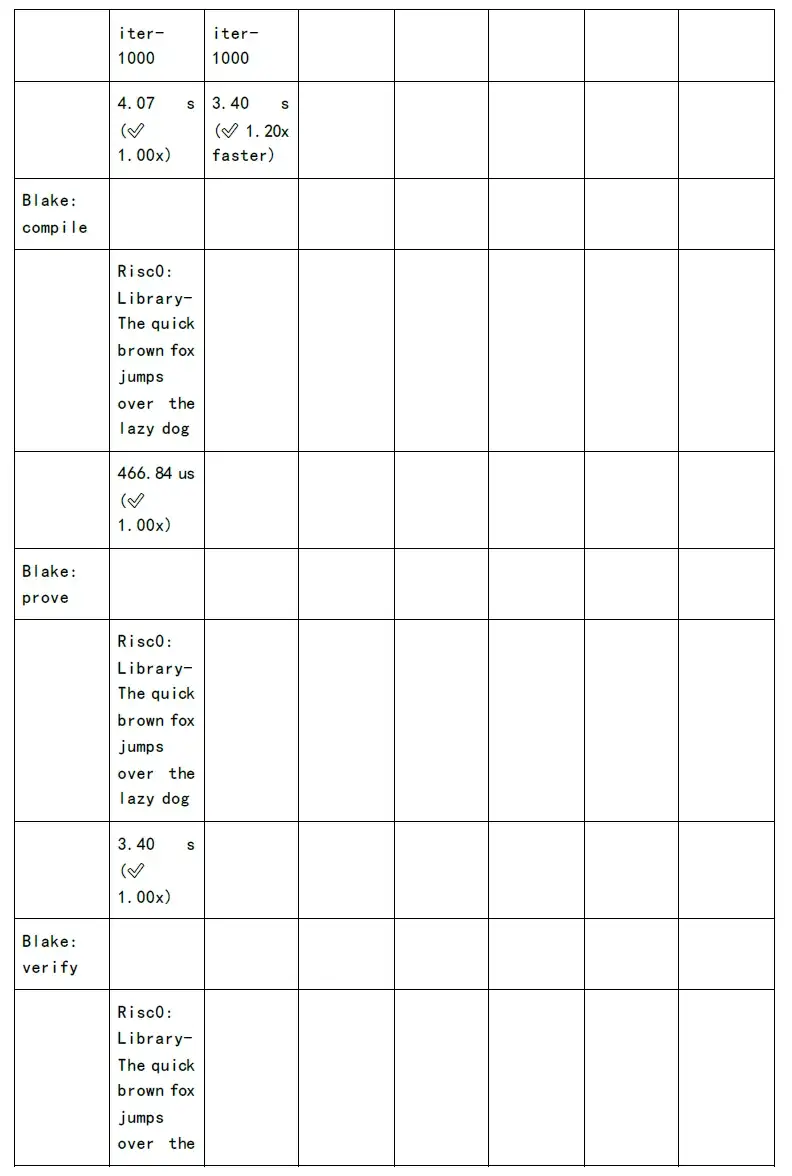
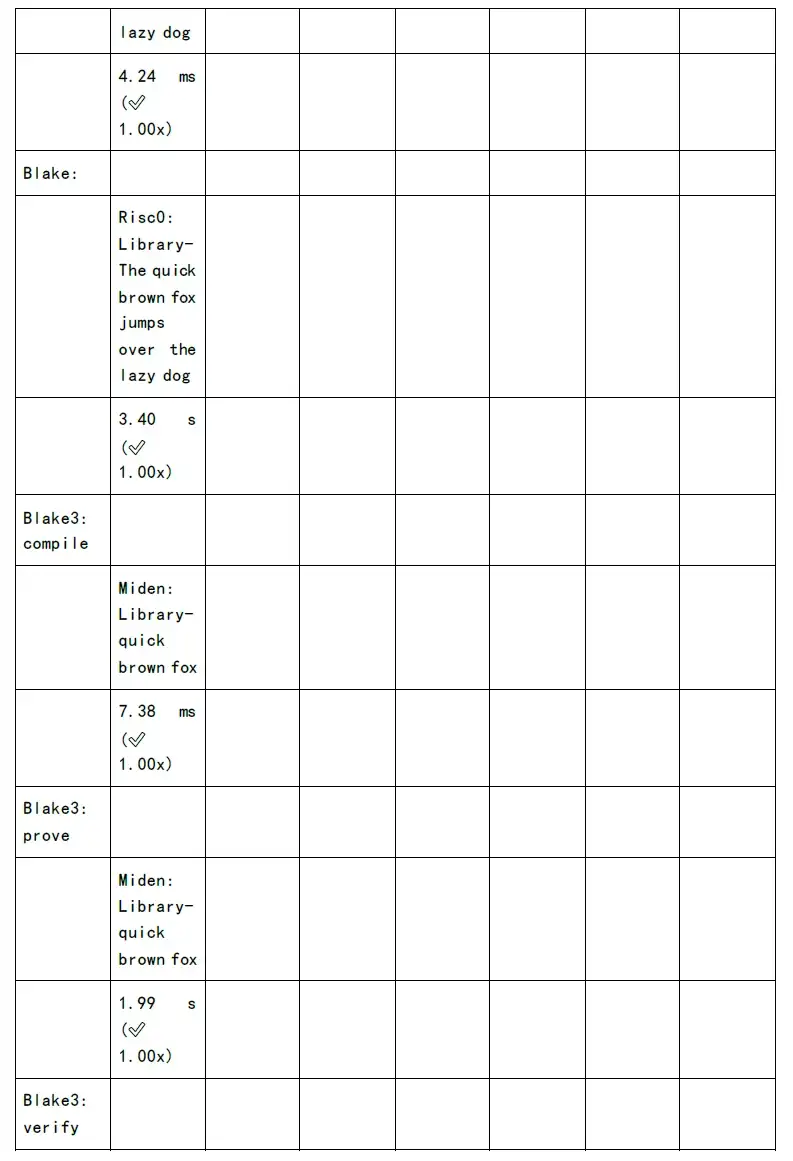
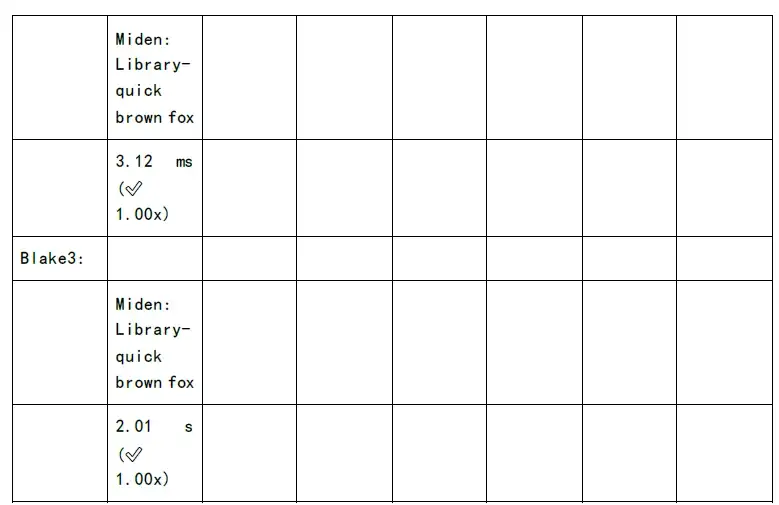
รูปต่อไปนี้แสดงการทดสอบเวลาในการสร้างการพิสูจน์และเวลาการตรวจสอบของแต่ละอัลกอริทึมตระกูล zkSnark:
ตอนนี้เรามองเห็นหลุมพรางและความท้าทายแล้ว นั่นก็หมายความว่ามีโอกาสมากมาย:
บริการกราฟิกการ์ดแบบเร่งความเร็ว Saas ใช้กราฟิกการ์ดสำหรับการเร่งความเร็ว ซึ่งมีต้นทุนต่ำกว่าการออกแบบ ASIC และวงจรการพัฒนายังสั้นกว่าอีกด้วย อย่างไรก็ตาม นวัตกรรมซอฟต์แวร์จะถูกกำจัดไปในที่สุดโดยการเร่งฮาร์ดแวร์ในระยะยาว
ชื่อเรื่องรอง
4.2 ใช้ทรัพยากรฮาร์ดแวร์จำนวนมาก
ในอนาคต หากคุณต้องการทำให้แอปพลิเคชัน zkSnark เป็นที่นิยมในวงกว้าง จำเป็นต้องเพิ่มประสิทธิภาพในระดับต่างๆ
ชื่อเรื่องรอง
4.3 ต้นทุนการใช้ก๊าซ
ดังนั้น โครงการ zkp จำนวนมากเสนอว่าเลเยอร์ที่มีประสิทธิภาพของข้อมูลและ zkProof ที่ส่งมาโดยใช้การบีบอัดหลักฐานแบบเรียกซ้ำล้วนแต่ช่วยลดต้นทุนก๊าซ
ชื่อเรื่องรอง
ในปัจจุบัน แพลตฟอร์ม zkvm ส่วนใหญ่จะมุ่งเน้นที่การเขียนโปรแกรมแบบ smart contract หากจำเป็นต้องใช้สถานการณ์การคำนวณทั่วไปมากขึ้น ตัวอย่างเช่น เลเยอร์ด้านล่างของเครื่องเสมือน zkvm รองรับคำสั่ง libc คำสั่งที่รองรับการทำงานของเมทริกซ์ และคำสั่งการคำนวณที่ซับซ้อนมากขึ้น
ชื่อระดับแรก
5. สรุป


