
블록체인 성능 테스트 및 최적화 - 1부
첫 번째 레벨 제목
개요
이 기사의 목적은 특정 예제(cosmos-sdk SimApp)를 통해 전체 성능 프로젝트 프로세스를 소개하는 것입니다. 특정 내용은 사용된 블록체인 성능 테스트를 소개합니다.
1. 기본 개념
2. 공통 도구
첫 번째 레벨 제목
기본 사상
블록체인 성능 테스트는 방법론적으로 기존 성능 테스트와 다르지 않습니다. 성능 테스트에는 많은 혼란스러운 개념이 있습니다. 여기에 몇 가지 정의를 내리기 위해 이 기사에서 설명하는 개념을 나열합니다.
보조 제목
성능 테스트의 정의
성능 테스트는 시스템 또는 서비스 성능 지표에 대한 모니터링 전략을 수립하고 특정 시나리오에서 테스트를 수행하고 성능 병목 현상을 분석 및 판단하고 최적화하고 최종적으로 성능 결과를 얻어 시스템 또는 서비스 성능 지표가 미리 정해진 값을 충족하는지 평가하는 것입니다. 여기서는 cosmos-sdk의 simapp 블록체인과 연동하여 설명합니다.
1. 일반적으로 기술 지표와 비즈니스 지표의 두 가지 유형의 지표를 나타내는 지표를 명확히 할 필요가 있습니다. 기술적 지표는 일반적으로 TPS, 응답시간, 자원활용도인데, 블록체인에 해당하는 것으로 일반적으로 초당 몇 건의 트랜잭션을 처리할 수 있는지를 가리킨다. 이러한 트랜잭션에 대한 응답 시간 또는 통계는 무엇입니까? 이 경우 시스템에서 사용하는 리소스의 상태는 무엇입니까? 충족될 것으로 예상되는 비즈니스 지표는 프로덕션 환경의 통계에서 나와야 합니다.cosmos-sdk의 프로덕션 응용 프로그램 cosmos-hub를 예로 들면 현재 블록 생성 시간은 약 6초이며 각 블록의 트랜잭션 수는 대부분 10 미만입니다. 예상되는 비즈니스 지표를 TPS로 100으로 설정하는 것이 더 합리적입니다. (이렇게 낮은 TPS는 실제로 코스모스 허브의 목표와 관련이 있습니다. 주요 초점이 체인 상호 운용성에 있기 때문입니다.)
2. 테스트 모델: 실제 장면을 추상화하여 비즈니스 모델이 어떻게 생겼는지 설명합니다. 코스모스 허브를 예로 들면 전 세계에 분산된 블록체인 노드는 약 500개의 검증인 노드와 약 200개의 활성 검증인 노드가 있을 때 트랜잭션을 처리합니다. 실제 상황은 테스트할 때 규모에 맞게 추상화할 수 있습니다.
3. 테스트 계획: 테스트 환경, 테스트 데이터, 테스트 모델, 성능 지표 등을 포함합니다. 블록체인 시스템을 비교하는 테스트는 테스트 구조를 결정하고 사용자 1000명과 각 사용자의 잔액 1000 Stake 등의 콘텐츠를 준비하는 것입니다.
4. 모니터링 필요: 모니터링 대상에는 프레스, 블록체인 노드 및 로드 밸런싱 서버와 같은 기타 항목이 포함됩니다. 클라우드 네이티브 시대의 모니터링은 일반적으로 Kubernetes+Prometheus+Grafana입니다.
5. 필수 테스트 조건 : 하드웨어 환경, 테스트 실행 전략 등 예: 4 C 8 G, 처음 60초 동안 초당 10개의 스레드를 추가합니다.
7. 결과 보고서 작성: 보고서의 내용은 물론 실제 지표 데이터입니다.
보조 제목
성능 시나리오 분류
1. 기본 성능 시나리오: 인터페이스의 단일 트랜잭션/용량(트래픽 볼륨)을 만들고 혼합 용량을 준비합니다.
2. (혼합) 용량 성능 시나리오: 혼합 용량 테스트는 실제 온라인 장면이 서로 다른 서비스로 구성되기 때문에 서로 다른 동시성 비율에 따라 이러한 서비스에 의해 시작되는 기울기 압력 테스트는 혼합 용량 테스트 시나리오입니다.
4. 비정상적인 성능 시나리오: 강력한 압력 하에서 이상을 시뮬레이션합니다.
보조 제목
중요한 성과 지표
1. RT, Response Time
2. HPS, Hits Per Second
3. TPS, Transactions Per Second,다음과 같은 성능 테스트에 대한 많은 지표가 있습니다.
4. QPS, Queries Per Second
5. PV, Page View
6. Throughput
7. IOPS, Input/Output Operations Per Second
여기서 트랜잭션은 일반적으로 전통적인 애플리케이션에서는 "트랜잭션", 블록체인 분야에서는 "트랜잭션"이라고 합니다.
더 중요한 지표는 리소스 사용률, 처리량 및 응답 시간입니다. 서비스 공급자는 앞의 두 가지에 더 관심을 갖고 사용자는 후자를 업데이트합니다. 이러한 지표의 일반적인 상황은 성능 테스트 방법론(http://hosteddocs.ittoolbox.com/questnolg 22106 java.pdf)의 클래식 다이어그램을 참조하여 설명되며 실제 상황은 다를 수 있습니다. 그림에는 3개의 라인, 3개의 영역, 3개의 상태가 정의되어 있으며, 이 그림은 좀 더 살펴볼 가치가 있으며 지표 간의 관계를 대략적으로 이해할 수 있습니다.
1. 3선: 활용도, 처리량, 응답 시간
보조 제목
다른
다른
1. 일반적으로 성능 테스트는 언제 수행해야 합니까?
a. 프로젝트가 시작되기 전에 시스템의 운반 능력을 추정합니다.
b. 프로젝트 개편 후 효과 평가
2. 성능 보고서를 받으면 프로젝트를 종료하므로 성능 검증에 불과합니다. 포괄적인 성능 테스트를 수행하고 동시에 시스템을 최적의 상태로 조정하는 것은 완전한 성능 프로젝트입니다. 성능 튜닝은 시간이 오래 걸리고 개발 참여가 필요할 수 있어 비용이 많이 듭니다.
블록체인 성능 테스트Why blockchain performance is hard to measure보조 제목
지연
지연
이 지연 기간의 시작과 끝은 어떻게 정의됩니까?
1. 시작점은 사용자가 제출을 클릭하는 것입니까 아니면 트랜잭션이 mempool에 도착하는 것입니까?
2. 끝점은 트랜잭션이 첫 번째 블록으로 확인되는 것입니까? 아니면 6번째 블록으로 확인되는 건가요(POW 블록체인은 그렇게 생각합니다)? 아니면 최종 사용자가 인터페이스에서 응답을 받을 때입니까?
3. 일부 블록체인 시스템은 처리를 시작하기 전에 특정 지연 및 특정 양의 트랜잭션을 기다립니다. 이런 식으로 가장 운이 좋은 트랜잭션이 마지막에 참여하고 처리 지연이 가장 짧습니다.
5. 일부 블록체인 시스템의 트랜잭션 처리는 우선 순위가 있으며 수수료가 높은 트랜잭션은 빠르게 확인되는 반면 수수료가 낮은 트랜잭션은 상대적으로 느립니다. 수수료 차이는 트랜잭션 지연 및 TPS 통계에 영향을 미칩니다.
보조 제목
처리량
또 다른 현실적 문제는 사용자가 블록체인의 TPS에 별로 신경을 쓰지 않고 어떻게 하면 수수료를 적게 사용하고 최대한 빨리 거래를 완료할 수 있는지에만 관심이 있다는 것입니다. 이러한 관점에서 TPS는 시스템 서비스 공급자에게만 의미가 있습니다.
기본 도구
보조 제목
압력 도구Jmeter일반용 압력 도구
4. …
또는 다음과 같은 특정 애플리케이션별 테스트 도구:
Jmeter를 사용하는 것은 사용 시나리오에 더 가깝고 더 일반적이어야 합니다. 일반적으로 블록체인 노드와 상호 작용하는 방법이 있습니다(일반적인 명령줄 상호 작용은 궁극적으로 다음 인터페이스 중 하나를 호출하는 것입니다).
1. gRPC 프로토콜
Jmeter에서 지원하는 Sampler는 HTTP를 지원하며 gRPC 프로토콜을 지원하려면 플러그인의 도움이 필요합니다.jmeter-grpc-request
보조 제목
모니터링 도구Prometheus일반 모니터링 도구https://prometheus.io/assets/architecture.png이 도구는 많은 콘텐츠를 모니터링할 수 있으며 그 생태는 그림(
). 공식 테스트 환경은 일반적으로 하드웨어 구성이 높기 때문에 블록체인 응용 프로그램 테스트 실습에서 docker-compose는 일반적으로 공식 테스트 환경을 시뮬레이션하기 위해 여러 블록체인 노드를 배포하는 데 사용됩니다.자체 구축된 컴퓨터실이 아닌 경우 사용 클라우드 서비스 제조업체의 기계는 비싸므로 비용을 절감할 수 있습니다.cadvisor。
docker-compose에서는 메모리, CPU 컴퓨팅 파워 등 컨테이너가 사용하는 리소스를 제한하고 CPU 코어를 바인딩할 수도 있습니다.stress-ng그림
첫 번째 레벨 제목
성능 튜닝
일반적으로 성능 병목 현상의 일반적인 메타 원인(일반적으로 하드웨어 수준에서 이유 뒤에 있는 이유라고 함)은 네트워크, CPU 및 디스크 IO입니다. 디스크 IO 병목 현상을 일으키는 작업에는 빈번한 로그 쓰기, 불필요한 로그 인쇄 및 네트워크를 통한 디스크 액세스가 포함됩니다. 이러한 리소스는 시스템 호출을 통해 완료되며, 시스템 호출을 추적하기 위해 strace를 사용하여 실행된 시스템 호출과 이러한 호출에 소요된 시간을 확인할 수 있습니다.
발생할 수 있는 또 다른 문제는 시스템 불안정성으로, 이는 CPU 사용량/TPS 불안정성으로 나타날 수 있습니다.
CPU 사용량이 불안정한 경우(추세는 안정적이지만 변동이 심함) CPU 명령 실행의 관점에서 볼 때 CPU가 다양한 시간 동안 유휴 상태에 있음을 의미합니다. 이 경우 유휴 상태인 CPU가 있기 때문이 아니라 유휴 시간이 길거나 짧기 때문입니다. 이유를 관찰하고 찾으려면 프로그램에 해당하는 Linux 시스템 도구 및 프로파일링 도구를 사용해야 합니다.
보조 제목
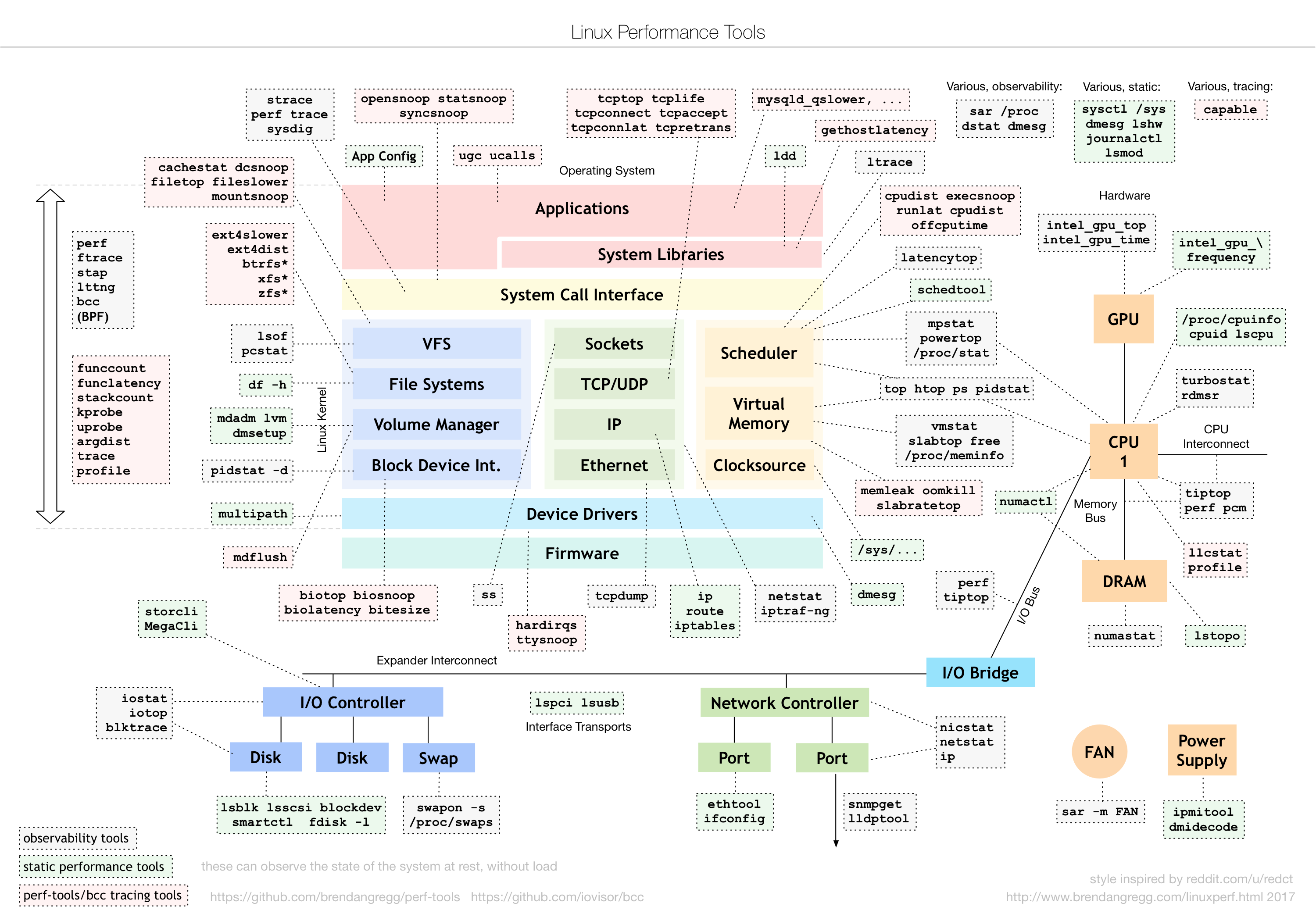
분석 도구https://www.brendangregg.com/Perf/linux_perf_tools_full.png그림
보조 제목
디스크 IO는 일반적으로 시스템 병목 현상을 유발하며 디스크 IO 스택은 상대적으로 길어 분석하기 어렵습니다. IO 스택에 익숙하면 문제를 찾는 데 도움이 됩니다(https://www.thomas-krenn.com/en/wikiEN/images/c/c 2/Linux-storage-stack-diagram_v 6.2.pdf)
그림
이유를 찾은 후 운영 체제 매개 변수 또는 응용 시스템 매개 변수를 조정하여 성능을 최적화하는 것이 더 빠릅니다.코드를 수정해야 하는 경우 시스템 아키텍처 최적화, 포함 및 코딩 작업이 포함되며 튜닝 주기가 매우 길어집니다. .



{kind=link}
{kind=link}