
Vitalikの最新長文:AI時代、コードはどうすればより安全になるのか?
- 核心的な見解:Vitalik は、AI がもたらすセキュリティ上の課題に対して、形式検証は万能薬ではないが、AI と組み合わせることで、より信頼性の高いソフトウェアセキュリティの核心を構築できると考えている。特にスマートコントラクトや ZK 証明などの複雑な暗号システムにおいて、これはネットワークセキュリティにおける防御側の優位性を確保するための重要な道筋である。
- 重要な要素:
- 形式検証は、機械が検証可能な数学的証明を用いてコードの正しさを検証する手法だが、ハードルが高い。AI がコードや証明の作成を補助することで、現実的な意味を持ち直す。
- 「証明可能な安全性」は絶対的な安全を意味するわけではなく、仮定の欠落、仕様の誤り、ハードウェアの境界、サイドチャネル攻撃などによって無効化される可能性がある。しかし、従来の手法よりも信頼性の高いセキュリティパラダイムを提供する。
- イーサリアムの将来を支える STARK、ZK-EVM などの複雑なコンポーネントは、その中核となるセキュリティ目標が比較的明確であり、AI 支援による形式検証の適用に最も適している。
- AI は多数の欠陥のあるコードを生み出すだろうが、ソフトウェアは「セキュリティの核心」と「安全でないエッジコンポーネント」に分化し、形式検証によってセキュリティの核心の信頼性を確保できる。
- AI と形式検証は非常に相補的な技術である。AI はコーディング効率を高めるが正確性を低下させる一方、形式検証は正確性を回復し、過去よりも強力になり得る。
Original title: A Shallow Dive into Formal Verification
Original author: Vitalik
Original translation: Peggy, BlockBeats
Editor's note: As AI programming capabilities rapidly advance, software security is facing a new paradox: AI can generate code more efficiently, and it can also discover vulnerabilities more efficiently. This issue is particularly critical for the crypto industry. Once defects appear in smart contracts, ZK proofs, consensus algorithms, and on-chain asset systems, the consequences are often not ordinary software errors, but irreversible loss of funds and erosion of trust.
What Vitalik discusses in this article is precisely another path for code security in the age of AI: formal verification. Simply put, it does not rely on human auditors examining code line by line, but instead formulates the properties that a program should satisfy as mathematical propositions, and then uses machine-checkable proofs to verify whether these properties hold. In the past, formal verification remained a relatively niche field of research and engineering due to its high barriers and cumbersome processes; however, as AI can assist in writing code and proofs, this method is regaining practical significance.
The core judgment of the article is not that "formal verification can solve all security problems." On the contrary, Vitalik repeatedly reminds us that so-called "provable security" does not equal absolute security: proofs may miss key assumptions, the specifications themselves may be written incorrectly, and unverified code, hardware boundaries, and side-channel attacks can also become new sources of risk. Nevertheless, it still offers a more reliable security paradigm: expressing the developer's intent in multiple ways, and then letting the system automatically check whether these expressions are compatible with each other.
This is especially important for Ethereum. Future Ethereum will increasingly rely on complex underlying components, including STARKs, ZK-EVM, quantum-resistant signatures, consensus algorithms, and high-performance EVM implementations. The implementation of these systems is extremely complex, but their core security goals can often be relatively clearly formalized. It is precisely in such scenarios that AI-assisted formal verification can realize its greatest potential: let AI be responsible for writing efficient code and proofs, and let humans be responsible for checking whether the final proven propositions truly correspond to the security goals they intend to achieve.
From a broader perspective, this article is also Vitalik's response to cybersecurity in the age of AI. Faced with stronger AI attackers, the answer is not to abandon open source, abandon smart contracts, or re-rely on a few centralized institutions, but to compress critical systems into smaller, more verifiable, and more trustworthy "security cores." AI will cause a massive increase in rough code, but it may also make truly important code safer than ever before.
The following is the original text:
Special thanks to Yoichi Hirai, Justin Drake, Nadim Kobeissi, and Alex Hicks for providing feedback and review on this article.
Over the past few months, a new programming paradigm has been rapidly emerging within Ethereum's cutting-edge research and development circles, as well as in many other corners of the computing world: developers are writing code directly in very low-level languages, such as EVM bytecode, assembly language, or Lean, and verifying its correctness by writing automatically checkable mathematical proofs in Lean.
When used properly, this approach has the potential to produce both extremely efficient code and significantly more secure software than past development methods. Yoichi Hirai calls it the "ultimate form of software development." This article will attempt to explain the basic logic behind this method: what formal verification of software can do, and where its shortcomings and boundaries lie—both within the context of Ethereum and in the broader field of software development.
What is Formal Verification?
Formal verification refers to writing proofs of mathematical theorems in a way that can be automatically checked by a machine.
To give a relatively simple yet still interesting example, we can look at a basic theorem about the Fibonacci sequence: every third number is even, and the other two are odd.

A simple proof method uses mathematical induction, advancing three numbers at a time.
First, look at the base case. Let F1 = F2 = 1, F3 = 2. By direct observation, this proposition—"When i is a multiple of 3, Fi is even; otherwise, Fi is odd"—holds before x = 3.
Next is the induction step. Assume the proposition holds before 3k+3, meaning we already know the parities of F3k+1, F3k+2, and F3k+3 are odd, odd, and even respectively. Then, we can calculate the parities of the next set of three numbers:
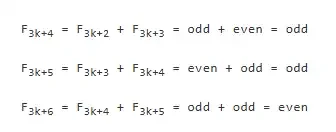
Thus, we have completed the derivation from "the proposition holds before 3k+3" to "confirming the proposition also holds before 3k+6." By repeating this reasoning, we can be confident that this rule holds for all integers.
This argument is convincing to humans. But what if you wanted to prove something a hundred times more complex, and you really wanted to make sure you hadn't made a mistake? Then, you could construct a proof that a computer would also find convincing.
It would roughly look like this:

This is the same reasoning, just expressed in Lean. Lean is a programming language often used for writing and verifying mathematical proofs.
It looks quite different from the "human version" I gave above, for a good reason: what is intuitive to a computer is completely different from what is intuitive to a human. The computer here refers to the old sense of "computer"—a deterministic program composed of if/then statements, not a large language model.
In the proof above, you aren't emphasizing the fact that fib(3k+4) = fib(3k+3) + fib(3k+2); you are emphasizing that fib(3k+3) + fib(3k+2) is odd, and the bewilderingly named `omega` tactic in Lean will automatically combine this with its understanding of the definition of fib(3k+4).
In more complex proofs, you sometimes have to explicitly state at each step exactly which mathematical law allows you to take that step, and these laws sometimes have obscure names like `Prod.mk.inj`. On the other hand, you can also expand huge polynomial expressions in one step and complete the argument with just a single line expression like `omega` or `ring`.
This unintuitiveness and tediousness are significant reasons why machine-verifiable proofs, despite existing for nearly 60 years, have remained in a niche field. But at the same time, many things that were nearly impossible in the past are rapidly becoming feasible due to the rapid progress of AI.
Verifying Computer Programs
At this point, you might think: Okay, so we can have computers verify proofs of mathematical theorems, so we can finally figure out which of those crazy new findings about primes are real and which are just errors hidden in hundreds of pages of PDF papers. Maybe we could even figure out whether Shinichi Mochizuki's proof of the abc conjecture is correct! But besides satisfying curiosity, what practical significance does this have?
There can be many answers. And for me, a very important one is: verifying the correctness of computer programs, especially those involving cryptography or security. After all, a computer program is itself a mathematical object. Therefore, proving that a computer program will behave in a certain way is essentially proving a mathematical theorem.
For example, suppose you want to prove whether an encrypted communication software like Signal is truly secure. You can first write down mathematically what "secure" means in this context. In summary, you need to prove that, under certain cryptographic assumptions, only the person holding the private key can learn any information about the message content. In reality, of course, many security properties are important.
And it turns out a team is indeed trying to figure this out. One of the security theorems they proposed looks roughly like this:

Here is Leanstral's summary of what this theorem means:
The `passive_secrecy_le_ddh` theorem is a tight reduction showing that, under the Random Oracle Model, the passive message secrecy of X3DH is at least as hard to break as the DDH assumption.
In other words, if an attacker can break the passive message secrecy of X3DH, they can also break DDH. Since DDH is generally assumed to be a hard problem, X3DH can also be considered resistant to passive attacks.
The theorem proves that if an attacker can only passively observe Signal's key exchange messages, they cannot distinguish the final session key from a random key with a non-negligible probability advantage.
If combined with a proof showing that AES encryption is correctly implemented, you get a proof that the encryption mechanism of the Signal protocol is secure against passive attackers.
Similar verification projects also exist for proving secure implementations of TLS and other in-browser cryptographic components.
If you can achieve end-to-end formal verification, then you are not just proving that some protocol description is theoretically secure, but that the specific piece of code actually run by the user is secure in practice. From the user's perspective, this dramatically increases the degree of "trustlessness": to fully trust this code, you don't need to check the entire codebase line by line; you just need to check the statements that have been proven to be true.
Of course, there are some very important asterisks here, especially concerning what the keyword "secure" actually means. It's easy to forget to prove the truly important claims; it's easy to encounter situations where the claim to be proven has no simpler description than the code itself; it's also easy to sneak in assumptions during the proof that ultimately don't hold. It's also easy to decide that only a certain part of the system truly needs formal proof, but then get hit by a critical vulnerability in another part, or even at the hardware level. Even Lean's implementation itself could have bugs. But before we delve into these headache-inducing details, let's first further explore the almost utopian prospect that formal verification could bring if done ideally and correctly.
Formal Verification for Security
Bugs in computer code are already worrying.
When you put cryptocurrency into immutable on-chain smart contracts, code bugs become even scarier. Because once the code goes wrong, North Korean hackers can automatically take all your money, and you have almost no recourse.
When all this is wrapped in zero-knowledge proofs, code bugs become even scarier. Because if someone successfully breaks the zero-knowledge proof system, they can withdraw all the funds, and we might have no idea what went wrong—or worse, we might not even know that a problem has occurred.
When we have powerful AI models, code bugs become even scarier. For example, a model like Claude Mythos, after another two years of improvement, might be able to automate the discovery of these vulnerabilities.

Faced with this reality, some people have begun to advocate abandoning the basic concept of smart contracts, even believing that cyberspace cannot be a domain where defenders have a structural advantage over attackers.
Here are some quotes:
To harden a system, the token cost for you to find a vulnerability must be greater than the token cost for an attacker to exploit it.
And also:
Our industry is built around deterministic code. Write code, test, deploy, and know it works—but in my experience, this contract is breaking down. Among top operators in truly AI-native companies, the codebase begins to become something you "trust it works," and the probability associated with that trust can no longer be precisely stated.
Worse, some people think the only solution is to give up open source.
This would be a bleak future for cybersecurity. It would be an exceptionally bleak future for those who care about the decentralization and freedom of the internet. The entire cypherpunk spirit is fundamentally built on the idea that on the internet, defenders have the advantage. Building a digital "castle"—whether manifested as encryption, signatures, or proofs—is easier than destroying it. If we lose this, then internet security can only come from economies of scale, from hunting down potential attackers worldwide, and more broadly, from a binary choice: either dominate everything or face destruction.
I disagree with this assessment. I have a much more optimistic vision for the future of cybersecurity.
I believe the challenge posed by powerful AI vulnerability discovery is indeed serious, but it is a transitional challenge. Once the dust settles and we enter a new equilibrium, we will arrive at a state more favorable to defenders than in the past.
Mozilla agrees with this too. To quote them:
You may need to reprioritize all other tasks and dedicate yourself to this mission in a sustained and focused manner. But there is light at the end of the tunnel. We are very proud to see how the team stepped up to meet this challenge, and others will too. Our work is not done, but we have passed the inflection point and are beginning to see a better future that goes far beyond just "barely keeping up." Defenders finally have a chance to achieve a decisive victory.
......
The number of flaws is finite, and we are entering a world where we can finally find them all.
Now, if you Ctrl+F in Mozilla's article for "formal" and "verification," you will find neither word appears. A positive future for cybersecurity does not strictly depend on formal verification, nor on any other single technology.
What does it depend on? Basically, the following diagram:
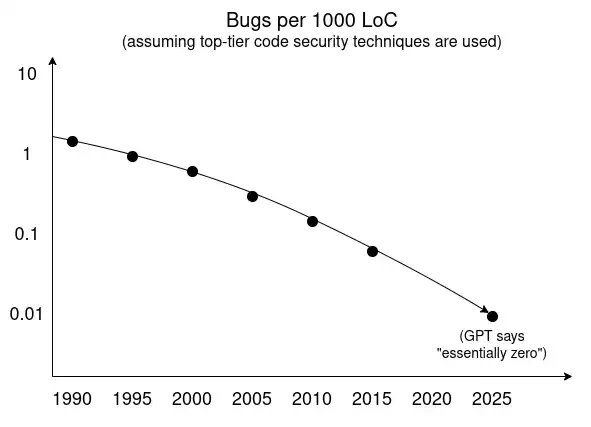
Over the past few decades, many technologies have driven the trend of decreasing bug counts:
Type systems;
Memory-safe languages;
Software architecture improvements, including sandboxing, permission mechanisms, and a more general clear distinction between the "trusted computing base" and "other code";
Better testing methods;
Accumulated knowledge about secure and insecure coding patterns;
An increasing number of pre-written and audited software libraries.
AI-assisted formal verification should not be seen as a completely new paradigm, but rather as a powerful accelerator: it is accelerating a trend and paradigm that has long been moving forward.
Formal verification is not a panacea. But it is particularly suitable in certain scenarios: when the goal is much simpler than the implementation. This is especially evident in some of the most challenging technologies needed for Ethereum's next major iteration, such as quantum-resistant signatures, STARKs, consensus algorithms, and ZK-EVM.
STARK is a very complex piece of software. But the core security property it achieves is easy to understand and easy to formalize: if you see a proof pointing to the hash H of program P, input x, and output y, then either the hash algorithm used by STARK is broken, or P(x) = y. Hence, we have the Arklib project, which aims to create a fully formally verified STARK implementation. Another related project is VCV-io, which provides foundational oracle computation infrastructure for formal verification of various cryptographic protocols, many of which are themselves dependencies of STARK.
More ambitious is evm-asm: a project aiming to build a complete EVM implementation and formally verify it. Here, the security property is less clear. Simply put, its goal is to prove that this implementation is equivalent to another EVM implementation written in Lean; the latter can prioritize intuitiveness and readability as much as possible without considering runtime efficiency.
Of course, theoretically, a scenario could still arise where we have ten EVM implementations, all proven equivalent to each other, but all sharing the same fatal flaw that somehow allows an attacker to drain all ETH from an address they shouldn't control. However, the probability of this happening is much lower compared to a single EVM implementation today having such a flaw alone. Another security property whose importance we truly realized only after painful experience—DoS resistance—is relatively easy to specify clearly.
Two other important directions are:
Byzantine Fault Tolerant consensus. In this direction, formally defining all desired security properties is also not easy. But given that related bugs have been very common, attempting formal verification is still worthwhile. Hence, there is now ongoing work on Lean consensus implementations and their proofs.
Smart contract programming languages. Related examples include formal verification efforts in Vyper and Verity.
In all these cases, one of the huge incremental benefits of formal verification is that these proofs are truly end-to-end. Many of the trickiest bugs are interaction bugs that occur at the boundaries between two separately considered subsystems. It's too difficult for humans to reason about the entire system end-to-end; but automated rule-checking systems can do it.
Formal Verification for Efficiency
Let's look at evm-asm again. It is an EVM implementation.
But it is an EVM implementation written directly in RISC-V assembly language.
Literally, assembly.
Below is the ADD opcode:

The reason for choosing RISC-V is that ZK-EVM provers currently under construction typically work by proving RISC-V and compiling the Ethereum client to RISC-V. Therefore, if you write an EVM implementation directly in RISC-V


