
IOSG Ventures: GPU 供給危機、新興 AI 企業が打開する方法
原作者: Mohit Pandit、IOSG Ventures

まとめ
GPU 不足は現実であり、需要と供給は逼迫していますが、十分に活用されていない GPU の数が今日の逼迫した供給ニーズを満たすことができます。
クラウド コンピューティングへの参加を促進し、最終的に推論やトレーニングのためのコンピューティング タスクを調整するには、インセンティブ レイヤーが必要です。 DePIN モデルはこの目的に最適です。
供給側のインセンティブにより、計算コストが低くなり、需要側はこれを魅力的に感じます。
すべてがバラ色というわけではありません。Web3 クラウドを選択する際には、「遅延」など、特定のトレードオフを考慮する必要があります。従来の GPU クラウドと比較して、直面するトレードオフには、保険、サービス レベル アグリーメント (サービス レベル アグリーメント) なども含まれます。
DePIN モデルには GPU の可用性の問題を解決できる可能性がありますが、断片化されたモデルでは状況は改善されません。需要が指数関数的に増加している状況では、供給が断片化すると供給がないのと同じになります。
新たな市場参加者の数を考慮すると、市場の集中は避けられません。
導入
私たちは機械学習と人工知能の新時代を迎えようとしています。 AI はこれまでさまざまな形で存在してきましたが (AI は洗濯機など、人間が実行できることを実行するように指示されたコンピュータ装置です)、私たちは現在、インテリジェントな作業を必要とするタスクを実行できる高度な認知モデルの出現を目の当たりにしています。人間の行動 タスク。注目すべき例には、OpenAI の GPT-4 および DALL-E 2、Google の Gemini などがあります。
急速に成長している人工知能 (AI) の分野では、モデルのトレーニングと推論という開発の 2 つの側面を認識する必要があります。推論には AI モデルの機能と出力が含まれますが、トレーニングにはインテリジェントなモデルの構築に必要な複雑なプロセス (機械学習アルゴリズム、データセット、計算能力など) が含まれます。
GPT-4 の場合、エンド ユーザーが気にするのは推論、つまりテキスト入力に基づいてモデルから出力を取得することだけです。ただし、この推論の品質はモデルのトレーニングに依存します。効果的な AI モデルをトレーニングするには、開発者は包括的な基礎データ セットと大規模なコンピューティング能力にアクセスする必要があります。これらのリソースは主に、OpenAI、Google、Microsoft、AWS などの業界大手の手に集中しています。
方程式は単純です。モデルのトレーニングが改善されると、AI モデルの推論能力が向上します。>> それにより、より多くのユーザーが集まります。>> 収益が増加し、その結果、さらなるトレーニングのためのリソースが増加します。
これらの大手企業は、基盤となる大規模なデータセットにアクセスし、重要なことに大量のコンピューティング能力を制御しているため、新興開発者にとって参入障壁が生じています。その結果、新規参入者は、経済的に実現可能な規模とコストで十分なデータを取得したり、必要なコンピューティング能力を活用したりするのに苦労することがよくあります。このシナリオを念頭に置くと、ネットワークには、主に大規模なコンピューティング リソースへのアクセスとコスト削減に関連する、リソースへのアクセスの民主化において大きな価値があることがわかります。
GPUの供給の問題
NVIDIA CEO のジェンスン・ファン氏は CES 2019 で「ムーアの法則は終わった」と述べました。今日の GPU は非常に十分に活用されていません。ディープラーニング/トレーニングサイクル中であっても、GPU は十分に活用されていません。
さまざまなワークロードの一般的な GPU 使用率の数値を次に示します。
アイドル状態 (Windows オペレーティング システムを起動したばかり): 0 ~ 2%
一般的な生産性タスク (執筆、軽いブラウジング): 0 ~ 15%
ビデオ再生: 15 - 35%
PC ゲーム: 25 ~ 95%
グラフィック デザイン/写真編集のアクティブなワークロード (Photoshop、Illustrator): 15 ~ 55%
ビデオ編集 (アクティブ): 15 - 55%
ビデオ編集 (レンダリング): 33 ~ 100%
3D レンダリング (CUDA/OptiX): 33 ~ 100% (GPU-Z を使用すると、Win タスク マネージャーによって誤って報告されることがよくあります)
GPU を搭載したほとんどの消費者向けデバイスは、最初の 3 つのカテゴリに分類されます。
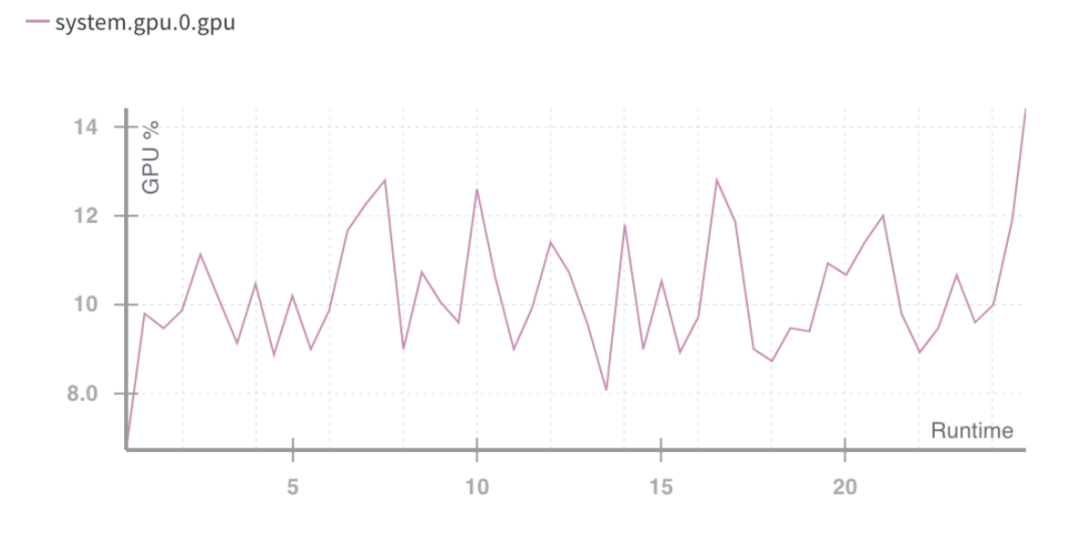
GPU ランタイム使用率 %。出典: 重みとバイアス
上記の状況は、コンピューティング リソースの使用率が低いという問題を示しています。
消費者向け GPU の容量をより有効に活用する必要がありますが、GPU 使用率が急増した場合でも、それは最適とは言えません。これにより、将来的に行うべき 2 つのことが明確になります。
リソース (GPU) の集約
トレーニングタスクの並列化
使用できるハードウェアの種類に関しては、現在 4 種類が提供されています。
· データセンター GPU (例: Nvidia A 100s)
· コンシューマー向け GPU (例: Nvidia RTX 3060)
· カスタム ASIC (Coreweave IPU など)
· コンシューマ向け SoC (例: Apple M 2)
ASIC に加えて (特定の目的のために構築されているため)、他のハードウェアを組み合わせて最も効率的に利用できます。これらのチップの多くが消費者やデータセンターの手に渡っているため、統合されたサプライサイド DePIN モデルが進むべき道となる可能性があります。
GPU の生産量はピラミッド型になっており、一般消費者向け GPU が最も生産量が多いのに対し、NVIDIA A 100 や H 100 などのプレミアム GPU の生産量は最も少ない (ただし、パフォーマンスは高い)。これらの高度なチップの製造コストは消費者向け GPU の 15 倍ですが、場合によっては 15 倍のパフォーマンスを発揮できないこともあります。
現在、クラウド コンピューティング市場全体の価値は約 4,830 億ドルに達しており、今後数年間で約 27% の年間複利成長率で成長すると予想されています。 2023 年までに ML コンピューティングの需要は約 130 億時間になると見込まれており、これは現在の標準レートで 2023 年の ML コンピューティングへの支出額が約 560 億ドルに相当します。この市場全体も急速に成長しており、3 か月ごとに 2 倍に成長しています。
GPUの要件
コンピューティングのニーズは主に AI 開発者 (研究者やエンジニア) から生じます。彼らの主なニーズは、価格 (低コストのコンピューティング)、規模 (大量の GPU コンピューティング)、ユーザー エクスペリエンス (アクセスと使いやすさ) です。過去 2 年間、AI ベースのアプリケーションと ML モデルの開発の需要の増加により、GPU の需要が非常に高まりました。 ML モデルの開発と実行には以下が必要です。
大量の計算 (複数の GPU またはデータセンターへのアクセスによる)
各タスクを並列実行するために多数の GPU にデプロイして、モデルのトレーニング、微調整、推論を実行する機能
コンピューティング関連のハードウェア支出は、2021 年の 170 億ドルから 2025 年には 2,850 億ドル (CAGR 約 102%) に増加すると予想されており、ARK は、コンピューティング関連のハードウェア支出が 2030 年までに 1 兆 7000 億ドルに達すると予想しています (年平均成長率 43%)。
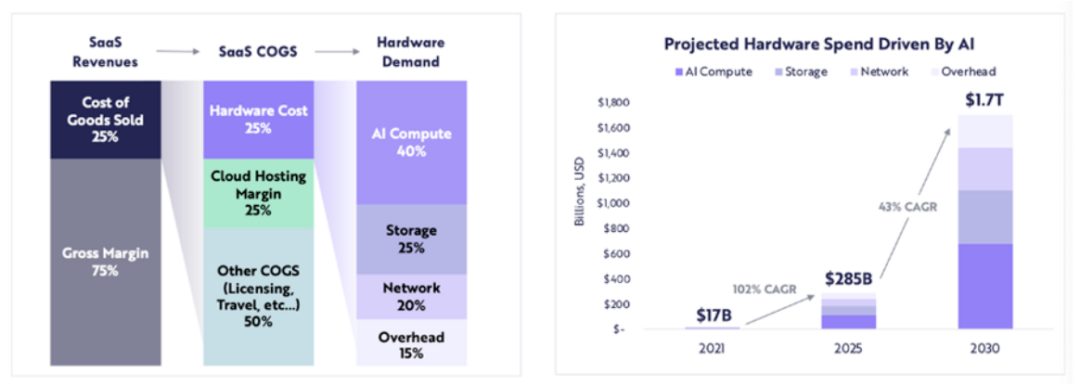
ARK Research
多数の LLM がイノベーション段階にあり、競争によりより多くのパラメーターと再トレーニングに対する計算需要が高まっているため、今後数年間は高品質の計算に対する需要が継続すると予想されます。
新しい GPU の供給が逼迫する中、ブロックチェーンはどこに関係するのでしょうか?
リソースが不十分な場合、DePIN モデルが助けを提供します。
供給側を開始して大規模な供給を作成する
タスクを調整して完了する
タスクが正しく完了していることを確認する
仕事を遂行したプロバイダーに適切な報酬を与える
あらゆる種類の GPU (コンシューマ、エンタープライズ、ハイパフォーマンスなど) を集約すると、使用率に問題が発生する可能性があります。計算タスクが分割されている場合、A 100 チップは単純な計算を実行することは想定されていません。 GPU ネットワークは、市場開拓戦略に基づいて、ネットワークにどのタイプの GPU を含めるべきかを決定する必要があります。
コンピューティング リソース自体が (場合によってはグローバルに) 分散されている場合、どの種類のコンピューティング フレームワークを使用するかについてユーザーまたはプロトコル自体が選択する必要があります。 io.net のようなプロバイダーを使用すると、ユーザーは 3 つのコンピューティング フレームワーク (Ray、Mega-Ray) から選択するか、Kubernetes クラスターをデプロイしてコンテナー内でコンピューティング タスクを実行できます。 Apache Spark などの分散コンピューティング フレームワークは他にもありますが、Ray が最もよく使用されます。選択した GPU が計算タスクを完了すると、出力が再構築されてトレーニングされたモデルが得られます。
適切に設計されたトークン モデルは、GPU プロバイダーのコンピューティング コストを補助することになり、多くの開発者 (需要側) はそのようなスキームがより魅力的であると感じるでしょう。分散コンピューティング システムには本質的に遅延が存在します。計算による分解と出力の再構成があります。したがって、開発者はモデルのトレーニングの費用対効果と必要な時間の間でトレードオフを行う必要があります。
分散コンピューティング システムには独自のチェーンが必要ですか?
ネットワークは次の 2 つの方法で動作します。
タスク(または計算サイクル)または時間ごとに充電
時間単位で課金される
最初のアプローチでは、Gensyn が試みているものと同様のプルーフ・オブ・ワーク・チェーンを構築できます。そこでは、さまざまな GPU が「作業」を共有し、それに対して報酬を受け取ります。よりトラストレスなモデルの場合、ソルバーによって生成された証明に基づいてシステムの完全性を維持することで報酬を得る検証者と内部告発者の概念があります。
もう 1 つの作業証明システムは Exabits です。これは、タスク分割の代わりに、GPU ネットワーク全体を単一のスーパーコンピューターとして扱います。このモデルは大規模な LLM により適しているようです。
Akash Network は GPU サポートを追加し、このスペースに GPU を集約し始めました。ステータス (GPU プロバイダーによって行われた作業を表示) に関するコンセンサスを達成するための基盤となる L1、マーケットプレイス層、およびユーザー アプリケーションのデプロイとスケーリングを管理するための Kubernetes や Docker Swarm などのコンテナ オーケストレーション システムがあります。
システムがトラストレスである場合、プルーフ・オブ・ワーク・チェーン・モデルが最も効果的です。これにより、プロトコルの調整と整合性が確保されます。
一方、io.net のようなシステムは、それ自体がチェーンとして構造化されていません。彼らは、GPU の可用性という中核的な問題を解決し、時間単位 (1 時間あたり) ごとに顧客に料金を請求することを選択しました。基本的に GPU を「リース」し、特定のリース期間中は必要に応じて使用するため、検証可能レイヤーは必要ありません。プロトコル自体にはタスクの分割はありませんが、Ray、Mega-Ray、Kubernetes などのオープンソース フレームワークを使用して開発者によって行われます。
Web2 および Web3 GPU クラウド
Web2 には、GPU クラウドまたはサービス スペースとしての GPU に多くのプレーヤーがいます。この分野の主要なプレーヤーには、AWS、CoreWeave、PaperSpace、Jarvis Labs、Lambda Labs、Google Cloud、Microsoft Azure、OVH Cloud などがあります。
これは、顧客がコンピューティングが必要なときに 1 つの GPU (または複数の GPU) を時間単位 (通常は 1 時間) でレンタルする従来のクラウド ビジネス モデルです。さまざまなユースケースに応じて、さまざまなソリューションが多数あります。
Web2 GPU クラウドと Web3 GPU クラウドの主な違いは、次のパラメータです。
1. クラウドのセットアップ費用
トークンのインセンティブにより、GPU クラウドのセットアップコストが大幅に削減されます。 OpenAIはコンピューティングチップの生産資金として1兆ドルを調達している。トークンによるインセンティブがなければ、市場リーダーを倒すには少なくとも 1 兆ドルかかると思われます。
2. 計算時間
非 Web3 GPU クラウドは、レンタルされた GPU クラスターが地理的エリア内に配置されているため高速になります。一方、Web3 モデルはより広範囲に分散されたシステムを備えている可能性があり、非効率的な問題の分割、負荷分散、そして最も重要な帯域幅によって遅延が発生する可能性があります。 。
3. コストの計算
トークンのインセンティブにより、Web3 コンピューティングのコストは既存の Web2 モデルよりも大幅に低くなります。
計算コストの比較:
これらの数値は、これらの GPU で利用できるクラスターの供給量と使用率が増えるにつれて変わる可能性があります。 Gensyn は、A 100 (およびその同等品) を 1 時間あたりわずか 0.55 ドルで提供すると主張しており、Exabits も同様のコスト削減構造を約束しています。
4. コンプライアンス
パーミッションレス システムではコンプライアンスを遵守するのは簡単ではありません。ただし、io.net、Gensyn などの Web3 システムは、自らをパーミッションレス システムとはみなしません。 GPU オンボーディング、データ読み込み、データ共有、結果共有の段階で GDPR や HIPAA などのコンプライアンス問題を処理しました。
生態系
Gensyn、io.net、Exabits、Akash
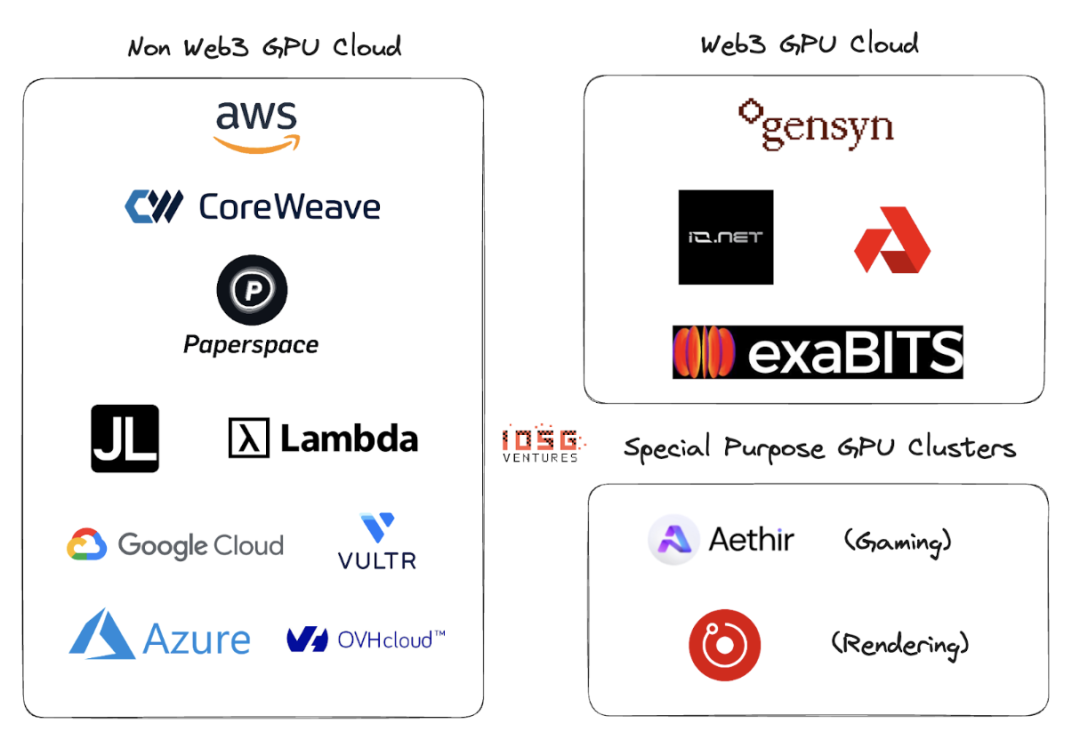
危険
1. 需要リスク
LLM のトップ プレイヤーは今後も GPU を蓄積し続けるか、最高 2.8 エクサフロップ/秒のパフォーマンスを持つ NVIDIA の Selene スーパーコンピューターのような GPU クラスターを使用することになると思います。 GPU をプールするために消費者やロングテール クラウド プロバイダーに依存することはありません。現在、トップの AI 組織はコストよりも品質で競争しています。
重くない ML モデルの場合、既存の GPU を最適化しながらサービスを提供できる、ブロックチェーンベースのトークンインセンティブ付き GPU クラスターなど、より安価なコンピューティング リソースを求めることになります (上記は仮定です。これらの組織は、使用するモデルを使用する代わりに、独自のモデルをトレーニングすることを好みます) LLM)
2. 供給リスク
ASIC 研究や Tensor Processing Unit (TPU) などの発明に巨額の資本が注ぎ込まれているため、この GPU 供給の問題は自然に解決する可能性があります。これらの ASIC が優れたパフォーマンスとコストのトレードオフを提供できれば、大規模な AI 組織が保管していた既存の GPU が市場に戻ってくる可能性があります。
ブロックチェーンベースの GPU クラスターは長期的な問題を解決しますか?ブロックチェーンは GPU 以外のあらゆるチップをサポートできますが、需要側の行動がこの分野のプロジェクトの方向性を完全に決定します。
結論は
小規模な GPU クラスターを含む断片化されたネットワークでは問題は解決されません。 「ロングテール」GPU クラスターの余地はありません。 GPU プロバイダー (小売業者または小規模なクラウド プレーヤー) は、ネットワークに対するインセンティブが優れているため、大規模なネットワークに引き寄せられるでしょう。これは、優れたトークン モデルと、複数のコンピューティング タイプをサポートする供給側の能力によって決まります。
GPU クラスターは、CDN と同様の集約の運命をたどる可能性があります。大手企業が AWS などの既存のリーダーと競合する場合、ネットワーク遅延とノードの地理的近接性を削減するためにリソースの共有を開始する可能性があります。
需要側が大きくなる場合 (より多くのモデルをトレーニングする必要があり、より多くのパラメーターの数をトレーニングする必要がある場合)、Web3 プレーヤーは供給側のビジネス開発に非常に積極的になる必要があります。同じ顧客ベースから競合するクラスターが多すぎる場合、需要 (TFLOPS で測定) が急激に増加する一方で、供給が断片化され (概念全体が無効になります)、需要が増大します。
Io.net は、アグリゲーター モデルから始めて、多くの競合他社よりも際立っています。彼らは、レンダー ネットワークとファイルコイン マイナーからの GPU を集約して容量を提供するとともに、独自のプラットフォームで供給をブートストラップしています。これは、DePIN GPU クラスターにとって勝利の方向となる可能性があります。


