
Web3 コラボレーション インテリジェンス: ナレッジ ツリー、ナレッジ フォレスト、およびコミュニティへの貢献
原作者: エリック・チャン
原作者: エリック・チャン
貢献、レビュー、フィードバックをくださった Zeo、DAOctor、Zhengyu、Christina に心より感謝いたします。
知識構造データベースを構築し、知識をより適切に視覚化することは、コンピューター サイエンス、人工知能、Web を進歩させるための重要なタスクです。暗号通貨と分散型アプリケーションの世界が出現する前、古い Web 3.0 の研究は主に知識ベースと知識グラフの構築、およびこれらの構造に基づく表現/推論に焦点を当てていました (セマンティック Web)。
ナレッジ ベースを構築するには、2 つの一般的なアプローチがあります。 1 つのアプローチは、Web やその他のデータ ソースからデータを取得し、それらを目的の知識データベース (主に「トリプル」または「グラフ」の巨大なコレクション) に編成してから、「高次ロジック」または機械学習技術を実行することです。構造やその他の知的なタスクについての推論)。もう 1 つのアプローチは、人間の知性を利用してデータベースを共同で構築することです (たとえば、Wikipedia、ConceptNet、または後で詳しく説明する Citizen Science プロジェクトなど)。
この記事では、まず過去数十年間の関連するイノベーションをいくつかレビューし、次に集合知と持続可能なインセンティブメカニズムを備えた高レベルの知識データベースの構築にどのように前進できるかについて説明します。
ナレッジベース、ナレッジグラフ、ウィキペディア
長い間、人々は次の 2 つの主な理由からナレッジ グラフの作成に興味を持ってきました。
人間が生み出したあらゆる情報や知識を繋ぐ点、
また、ナレッジ グラフ上で推論と機械学習の手法を実行して、より優れた人工知能を生成し、このシステムを使用して Web2 製品のユーザー エクスペリエンスを向上させます。
現在、明らかに有用なナレッジ グラフは、大企業向けの基本ツールとして Web2 で作成されていることがほとんどです。たとえば、Facebook Knowledge Graph はソーシャル ネットワーク検索の向上に役立ち、Google Knowledge Graph は関連情報の表示に役立ちます。すべてがクローズドソースであるため、ナレッジ グラフがどのように構築されているかはわかりませんが、UI の観点から、これらのナレッジ グラフは間違いなくユーザー エクスペリエンスの向上に役立ちます。
ウィキペディア コミュニティの努力は素晴らしいです。これは、インターネット コミュニティの力を実証する最初の試みの 1 つでした。一方、オープンデータベースはインターネット公共財として利用できます。例としては、Wikipedia ナレッジ ベースを利用するアプリケーションに API を提供するデータベースである DBpedia があります。もう 1 つの例は、AI および NLP プログラムが共通のセマンティクスを取得するのに役立つ、無料で利用できるセマンティック ネットワークである ConceptNet です。
しかし、これらのインターネット NGO ができることには根本的な限界がいくつかあります。ウィキペディアは毎年寄付に依存しており、501(c)3 組織内で運営されているため、より高度なインセンティブを設定したり、知識ネットワークに基づいたより優れたインフラストラクチャを構築したりすることは困難です。 DBpedia や ConceptNet などについても同様です。非営利団体であるこれらの公共福祉団体は、インフラを継続的に構築し、最終的にはエコシステムを形成するコミュニティを深く構築することが困難です。私は大学で DBpedia の API を使用して Wikipedia グラフ視覚化および検索ツールを構築しました。しかし、当時は活気に満ちたコミュニティに参加することははるかに困難でした。現在、暗号通貨コミュニティでは状況が大きく異なり、優れたアイデアを持つ開発者はより多くの活動に参加し、チームを結成し、マルチチェーンのエコシステムによってサポートされることができます。
ただし、別の Wikipedia (別名 DAO 化 Wikipedia、または「Web3 Wikipedia」) を構築することはお勧めしません。現在の非営利モデルの制限にもかかわらず、Wikipedia サイトはコンテンツと構造がよく厳選されており、組織や人々はその恩恵を受けているからです。かなりの程度の結果が得られます。一般に、Wikipedia は知識の説明を保存することに優れており、Web1 および Web2 インフラストラクチャを通じて知識を検索可能にしました。ウィキペディアと既存の Web インフラストラクチャが苦手とするのは、「人間の理解」のための知識、つまり人間の心の中に構造化された知識を提示することです。この情報を提示するには、人間によるキュレーションと人間によるコラボレーションが中核となり、これは Web1/Web2 インフラストラクチャでは十分にサポートされていませんが、Web3 インフラストラクチャと調整メカニズムを通じて可能になります。
**人々は機械による知識の理解を強化するために大規模な構造データベースを構築しようと努めていることは注目に値します。たとえば、Cyc のような企業は、機械が人間の脳を模倣できるようにするための常識的な知識ベースの構築に数十年にわたって取り組んできました。強力な AI には明らかにノードと関係の知識ベース以上のものが必要だったため、これらの企業は最終的にビジネス ソフトウェア企業に転向しました。機械のための構造化された知識ベースの構築と比較して、ここでは人間による知識の理解と人間による管理が重要です。より多くの人々の理解を助けるために、人間の理解による知識ベースを構築します。
一方で、現在の知識の Web (本稿で説明する構造化された知識) に高レベルのセマンティクスを追加する方法を考える価値があります。
シチズン サイエンスとボランティア コンピューティング
私が言及したい探究のもう 1 つの分野は、市民科学とボランティア コンピューティングです。 2010 年代初頭、科学コミュニティでは、研究と科学的発見の進歩を加速するために群衆の知恵を活用する多くの刺激的なプロジェクトがありました。このような取り組みには、一般に 2 つのタイプがあります。 1 つ目はボランタリー コンピューティングと呼ばれるもので、コンピューティング タスクを個々のコンピューティング デバイスのグループ (LHC@Home、SETI@Home など) に分散します。 2 番目のタイプはシチズン サイエンスと呼ばれるもので、誰もが実行できる反復的なタスク (ここでは軽蔑的な用語ではありません!) を作成します。このプロジェクトは、多数の寄稿者からデータ (および場合によっては分析結果) を収集し、それらを多数の研究プロジェクトにフィードして、有意義な結果を生み出します (たとえば、Citizen Cyberlab、SciStarter、または Machine Learning Community にリストされているプロジェクトで、トレーニング データを強化するためのタグ付けされた画像を使用できます)クラウドソーシング)。言葉を発明することなく、これらの取り組みを「DAO」と考えてください。分散型コミュニティの調整の側面は新しいものではありません。
多くのプロジェクトが成功しましたが、やはり残念ながら、これらのプロジェクトの持続可能性は限られています。 SETI@Home はもう運営されておらず、もっと長く継続できたはずの多くの市民科学プロジェクトも運営されていません。インセンティブとエコシステムは、あらゆる共同作業における 2 つの重要な側面です。エコシステムがなければ、イノベーションは制限されます。持続可能なインセンティブがなければ、活気のあるコミュニティは存在せず、エコシステムも出現しません。
複雑な概念と知識の構造
次に、上位レベルの概念と知識がどのようなものかを考えてみましょう。直観的には、私たちが概念を「理解」するとき、実際にはその概念をかなり詳細に理解していることになります。 「理解」のプロセスは次の 2 つの方法で考えることができます。
1. ツリー構造で理解する
ツリーを深く分解するほど、概念はより原始的になります。ある時点で、直接参照できる非常に直接的なリソースが Web 上に存在することになります (例: Wikipedia ページや記事/ビデオなど)。
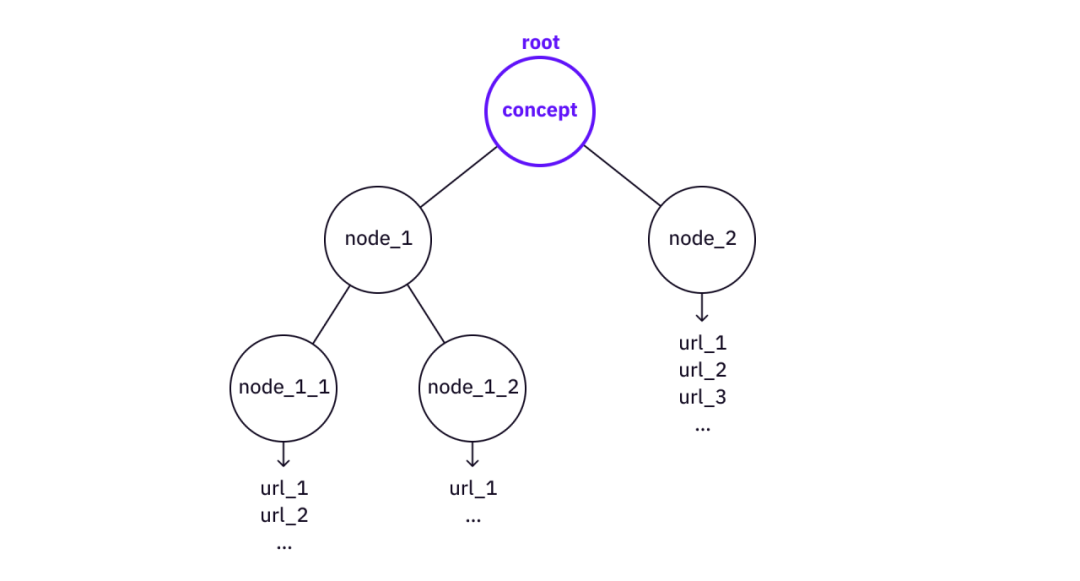
画像の説明
コンセプトをツリー構造に「分解」
古いAIからも同様のアイデアがいくつか見つかります。 K ライン理論は、私たちの記憶と知識がツリー構造 (P ノードと K ノード) に保存されていることを示しています。このような構造が実際に私たちの脳に存在するという実際の証拠は不足していますが、このモデルには人間の記憶と人間の脳がどのように機能するかを説明する力があり、ツリー構造は確かに構造知識を保存する最もコンパクトな形式です。
詳細を取得したい場合は、知識ツリーを分解します。一方、知識のツリーがある場合は、このツリーを使用してより大きなツリー (つまり、知識と理解のより高度な抽象化) を構築できます。
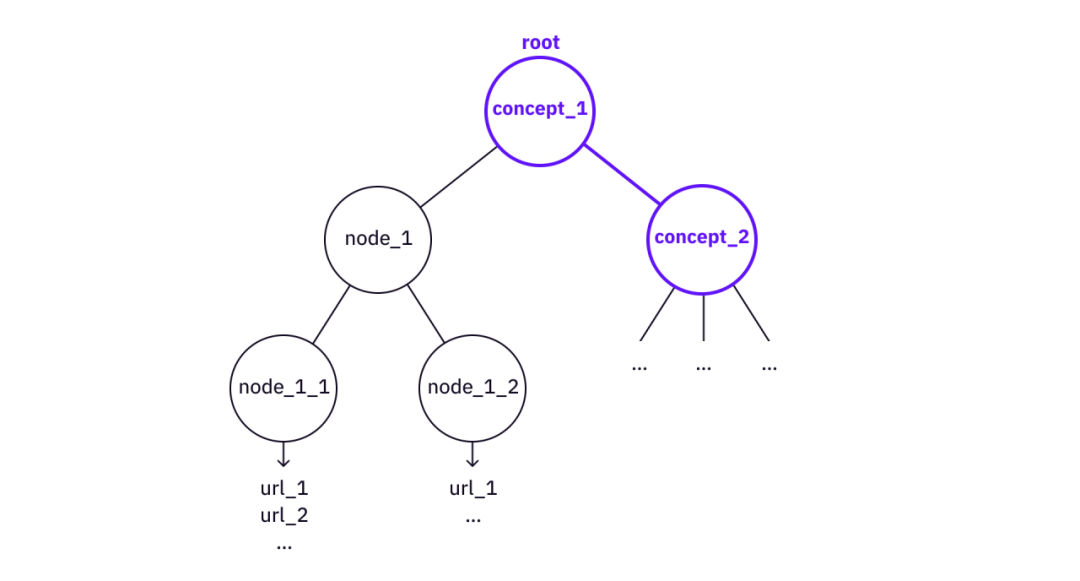
画像の説明
コンセプト_2「建物」の使い方 コンセプト_1
「構築」の場合、「マークル ツリー」ツリーをノードとして使用して、「バークル ツリー」や「マークル複数証明」など、より複雑な知識ツリーを構築できます。
ここで重要なのはツリーの構造であることに注意してください。ナレッジ ツリーは、根の概念から葉に至るまで、既存の Web リソースへの必要なすべての参照を指します。ここではノード間の関係は重要ではありません (ナレッジ グラフ システムの「トリプル」思考とは異なります)。
2.「関連知識」による理解
また、より多くの「コンテキスト」を追加することで、知識の理解が深まります。ヴァイゲンシュタインの有名な言葉にあるように、「しかし、『5』という言葉は何を意味するのでしょうか?ここにはそのような質問はなく、『5』という言葉がどのように使われるかだけが問題です。」その背後にある考え方は、何かの意味は実際にはそれに関連する他の概念に依存し、それらが一緒になって何かの意味を決定するというものです。より多くのコンテキスト(つまり、知識自体の関連知識)を追加することで、知識をより「深く」理解することができます。
一般に、人々はグラフよりもツリーを理解するのが簡単です。ナレッジ マップを構築する代わりに、「関連するナレッジ」をより実用的な方法、つまりルート ノードによって接続されたナレッジ ツリーのセット、つまり本質的にナレッジ フォレストを形成すると考える方がよいでしょう。
ナレッジフォレストは、多数のナレッジツリーのデータベースとして構築できます(並列植栽)。データベースに対して実行できる基本的な操作は 2 つあります。
知識ツリーの特徴は、特定のベクトル空間内のベクトルとして構築できます。次に、ベクトルを使用して、概念的に関連しているが (1) によって直接リンクされていない知識ツリーを関連付けることができます。
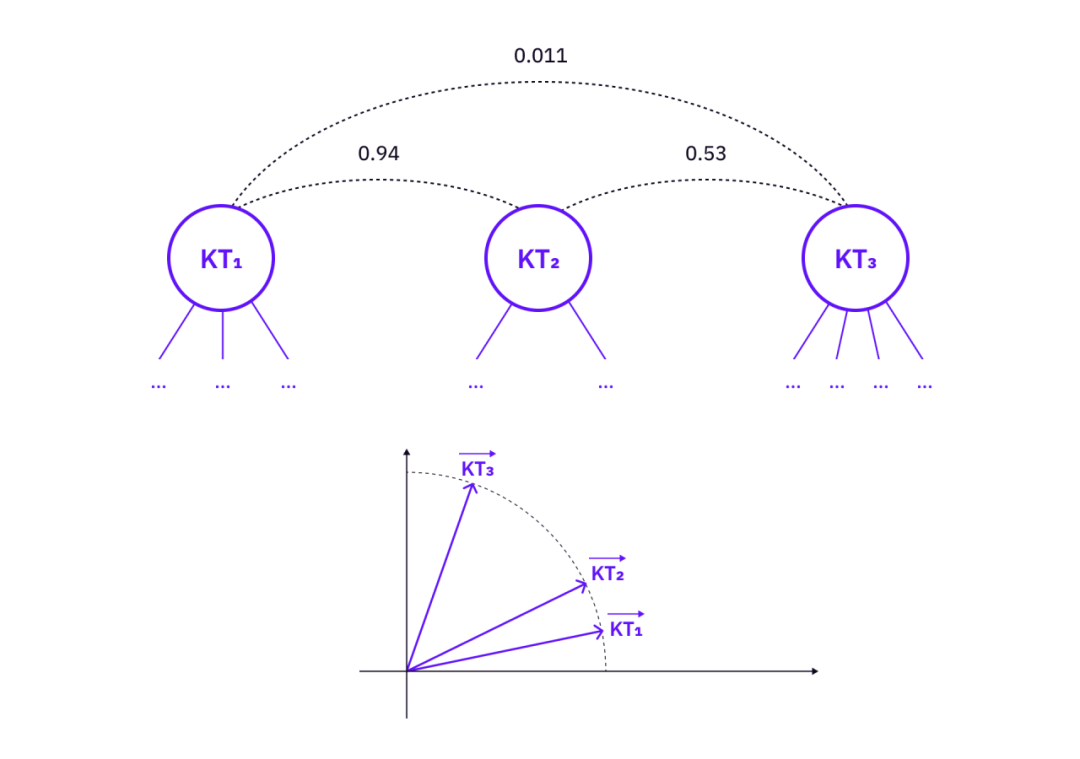
画像の説明
知識ツリー間の関係の測定
理解の深さについて
一般に、同じ概念に対する理解のレベルは人によって異なります。一部の人にとって、マークル ツリーの概念は単純であり、これ以上分解する必要はありません (彼らの脳はこの概念を何らかの常識にカプセル化しています)。一方で、「マークル ツリー」の概念を理解するのに十分な情報を持っていない人もいます。 」とさらに詳しく分析する必要があるかもしれません。
したがって、知識ツリーは相互に排他的である必要はありません。これは、異なるツリー間で重複があってもよいことを意味します。基本的な概念を説明するツリーと、高度な概念のために構築されたツリーが存在する場合があります。
オーバーラップにより、ツリー間に冗長性が生じる可能性があります。冗長性を減らすために、次の操作を導入できます。
マージ - 両方のツリーのノードの下にサブツリーがすでに存在する可能性があり、一部の重要なノード、リーフ、および参照がベース ツリーでまだカバーされていない場合は、上位レベルのツリーからより基本的なツリーに情報をマージする価値がある可能性があります。
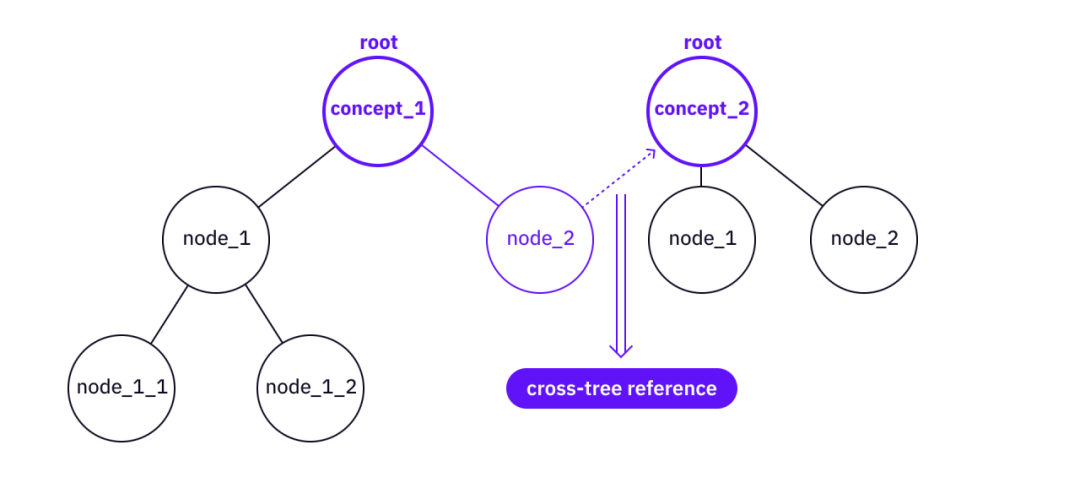
クロスツリー参照リンク
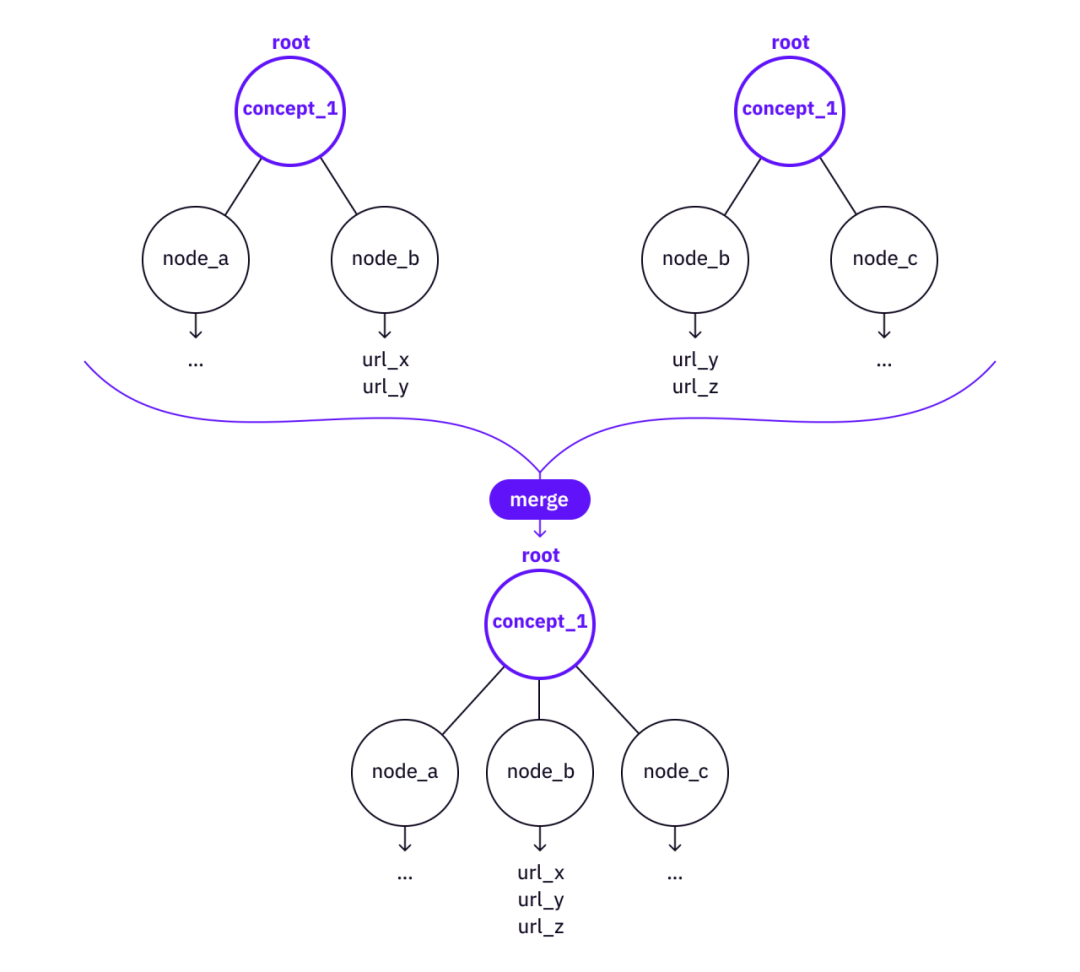
画像の説明
2 つのツリーを 1 つにマージする
ナレッジツリーとメタオペレーション
単一のナレッジ ツリーは、ルート、子ノードのセット、および葉のセットで構成され、ツリー構造に編成されます。次に、ツリーを作成および調整するための一連の基本操作を定義できます。
ルート(ツリー)を作成する
子ノードを追加する
ノードに葉を追加する
参照リンクをリーフに追加
次に、実際のユーザーがツリーを「植え」て貢献するための一連の高レベルのアクションを定義できます。
サブツリーの追加 - 完全なノードとリーフを持つナレッジ ツリーに必要な子ノードを導入します。
同じコンセプトの 2 つのツリーをマージする
知識の森
知識の木をたくさん植えれば、知識の森が出来上がります!
知識の森とは、一緒に植えられた知識の木の大きなグループです。知識の森に関する興味深い事実は、木の間に絡み合いが存在する可能性があるということです。理論的には、異なるノードとリーフ間の接続は任意にすることができます (たとえば、あるツリーのリーフと別のツリーのルート間のリンク)。実際、点線のリンクを追加すると、ナレッジ フォレストは「一種の」ナレッジ グラフになります。ただし、重要なのは個人の知識ツリーです。
たとえば、破線は MACI ツリーと zk-Snark ツリー間のリンクを示します。
ナレッジ ツリーの葉は、Web 上の既存の記事、ビデオ、リソースに接続します。したがって、これらの葉の上の層は構造情報または理解層です。
ナレッジフォレストでできることは完全にオープンです。おそらく、私たちが考慮すべき最も重要なことは、最初から協力的な知識ベースのエコシステムを構築することです。ナレッジ フォレストを使用して多くのことを実行したい場合があります。ここでは 3 つの例を示します。
ナレッジツリーとナレッジフォレストの視覚化
点線のリンクからナレッジ フォレストを参照する
ナレッジ ツリー クラスターを見つける
非営利団体は物事を実現できますが、DAO は物事をより良くすることができます。ここでの考え方は、一連のツリー操作を一連の刺激にマッピングすることです。メタオペレーションが標準化されるほど、DAO のメンバーを調整するためのスケーラビリティが向上します。
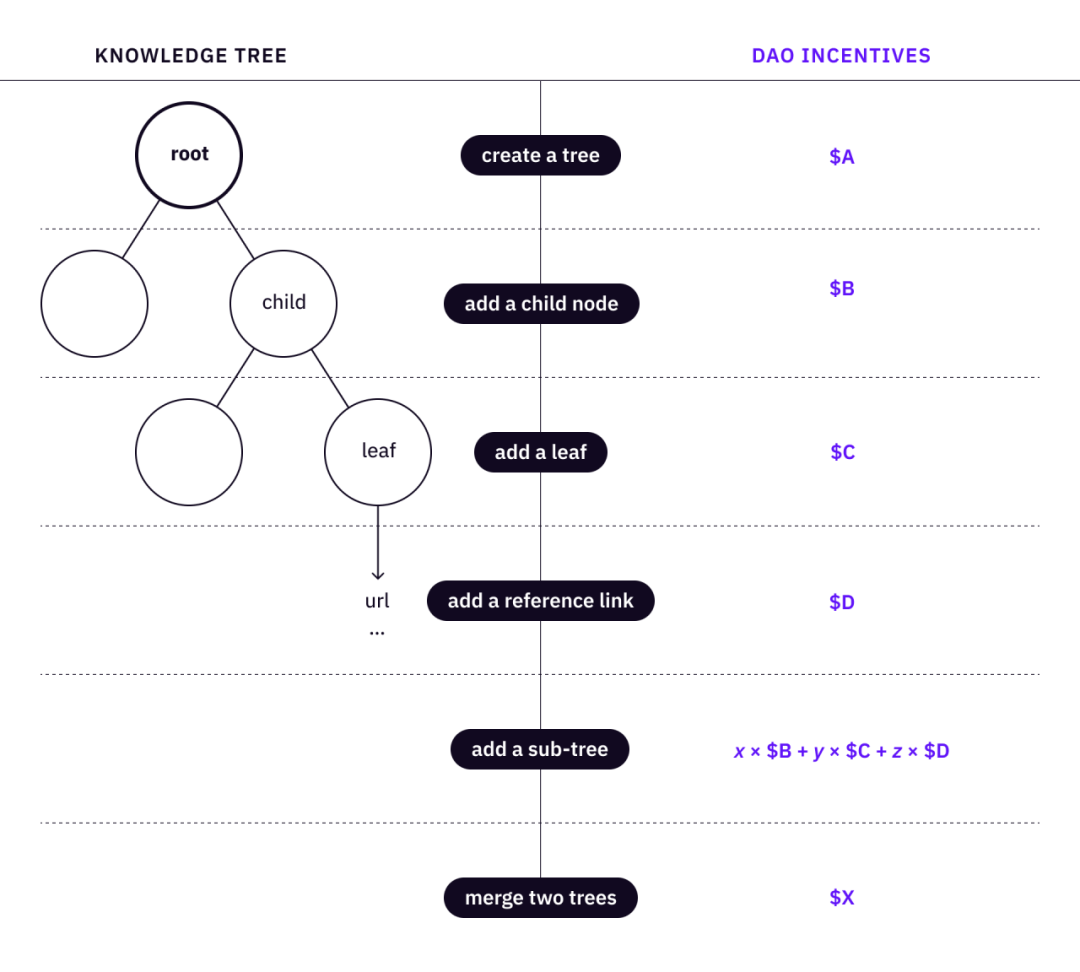
画像の説明<->ナレッジツリーの操作
DAOの貢献
ナレッジ ツリーの場合、DAO 貢献者はルートを作成し (「ツリーを作成/植える」に相当)、ナレッジ パスを追加し (「ツリーを植える」)、リーフへの参照リンクを追加できます。インセンティブ メカニズムは、ナレッジ ツリーを計画し成長させるために検証可能なアクションをとったコミュニティの貢献者に報酬を与える一連のルールを作成します。
また、計画と品質管理には審査委員会(または審査グループ)が重要です。 DAO の調整とインセンティブは広範囲に実験されており (DAOrayaki DAO など)、ここでも同様の構造を実装できます。
ナレッジフォレストとナレッジグラフ
新しい概念を学び、知識を得ることで、樹木を理解しやすくなります。特定のトピックについて、ツリーにはループがないため、人間はツリー内の知識構造を理解するのが簡単です。また、ツリーの深さが特定のレベルに制限されている場合、人間の脳はより簡単に理解できます。処理して記憶する。
さらに、ナレッジ グラフ表現は、知識ノード間のあいまいな接続またはあいまいな接続を表現するのに制限があります (常識的な知識表現と同じ問題)。
ナレッジ ツリーとナレッジ フォレストの実際の実装に取り組んでいる BUIDLers チームには、データ構造、製品設計、貢献とインセンティブの詳細、UI など、多くの詳細が含まれています。それにも関わらず、知識の森を構築するのであれば、一般的にはそれを公共財として組織し、世界中の誰もが利用できるようにすべきだと私は感じています。しかし、Dora コミュニティが何を思いつくか見てみましょう!
結論は
そのアイデアは、既存の Web インフラストラクチャ (Wikipedia など) の上に新しい種類のナレッジ ベースを構築し、それを誰でも利用できるようにすることで、(次のようなナレッジ グラフ上の Web ルーティングなどを介して) 抽象的な知識を理解する複雑さを最小限に抑えることです。 Wikipedia または Wikipedia は O(nlog(n)) ほど複雑になる場合がありますが、n 個のノードを持つツリーの深さは log(n) だけなので、ナビゲーションが簡単になります。 DAO の貢献者と調整し、高度な暗号ネイティブ インセンティブを利用して組織の持続可能性を確保します。この記事のアイデアは完全ではなく、議論と改善の余地がたくさんあり、チームがそれを実現したい場合にはエンジニアリング上および製品上で考慮すべき問題がたくさんあります。
参考文献
参考文献
セマンティック Web: https://en.wikipedia.org/wiki/Semantic_Web
トリプル: https://conceptnet.io/
ConceptNet:https://conceptnet.io/
DBpedia:https://www.dbpedia.org/
高次ロジック: https://en.wikipedia.org/wiki/Cyc
https://github.com/zhangjiannan/Graphpedia
Wikipedia のグラフ視覚化および検索ツール:
Cyc:https://en.wikipedia.org/wiki/Cyc
マルチチェーンエコシステム: https://hackerlink.io/grant/dora-factory/top
LHC@Home:https://lhcathome.cern.ch/lhcathome/
SETI@Home:https://setiathome.berkeley.edu/
Citizen Cyberlab:https://www.citizencyberlab.org/projects/
SciStarter:https://scistarter.org/
ボランティア コンピューティング: https://en.wikipedia.org/wiki/Volunteer_computing
ナレッジグラフ構築ツール1:https://obsidian.md/


