ブロックチェーンは、複数の当事者が共同して総勘定元帳の記録プロセスを完了するテクノロジーです。複数の参加コンピューティング当事者がデバイスをネットワークに接続して、ビットコイン、イーサリアム、ポルカドットなどのオープンなブロックチェーン ネットワークを形成します。すべてのコンピューティング参加者は、使用するリソースを共有します。開発者とユーザーによって。このような運用ルールでは、運用ステップごとに「データの流れ」が流れます。基盤となるノードの通信からブロックのパッケージ化、コピー、確認を経て、アプリケーション層でのトランザクション転送まで。ネットワーク上の送金トランザクションから各ノードの残高、口座データ、オンチェーン上のデータまで。そのため、データ処理におけるブロックチェーンのパラダイムは、従来のデータベースでのデータ処理に比べて最大の利点となります。ここで、インターネットの長いサイクルの中で、データは企業によってその中核的価値として認識されるようになったと同時に、データ処理と管理に関する多くの課題を早急に解決する必要があると言わざるを得ません。プロジェクトは開発中です ブロックチェーン テクノロジーを使用し、他のテクノロジーと組み合わせてブロックチェーン ベースのデータ ソリューションを形成してみます。例えば、ブロックチェーンのデータ構造には複数の構造設計や様々な計算形式が追加されます。1. ブロックチェーンデータ構造に基づいた基本と高度
ブロックチェーンネットワークのデータフロープロセスは次のようになります. ノードがトランザクション (データ) を発見し、トランザクションをパッケージ化してブロックを形成し、パッケージングノードがブロードキャストを開始し、コンセンサスに参加しているノードがコピーを開始しますブロックを削除して保存します (または、コンセンサス ノードが保存後、他の完全なノードがレプリケーションを開始することを確認します)。このようにして、ブロックチェーン上のデータは信頼できるものになります (オープンかつ透明であり、改ざんできません)。データはブロックに保存されますが、ブロック サイズには制限があるため、ブロックにはビットコイン送金トランザクション、イーサリアム送金、コントラクト コール メッセージなどの小さなバイト情報が詰め込まれることがよくあります。これらの取引情報は、商品のトレーサビリティや流通情報などに置き換えることができます。また、広告のクリック数や生活保護寄付金の使途、銀行の共同口座情報など、公開可能なあらゆる情報に置き換えることも可能です。ただし、他の情報のバイト数が大きいため、トランザクション データなどの小バイトの情報をブロックに格納する方が適しています。複数の関係者によるブロックチェーンの確認後、これらの公開データは信頼できるものとなり、読み取って使用することができます。2.ChainlinkのOracleネットワークデータ構造
Chainlink の価格処理モデル
チェーン上で処理された後、信頼できる価格データが形成され、DeFi アプリケーションによって検出および使用され、データの使用回数に応じて、LINK トークンが報酬としてネットワークに支払われ、インセンティブ収入が得られます。このモデルでは、Chainlink ネットワークの外部から入力されたデータがチェーン上で集約および処理され、最終的に需要者に流れて価値が実現されます。このプロセスには、価格フィードごとの Oracle 価格の更新など、多くの重要な部分があります。各価格フィードは、各地に散在する価格を取得し、最終的に集約して処理する必要があり、価格フィードごとに散在するオラクルマシンの数が異なります。たとえば、ETH/USD 価格フィードには 21 のオラクル フィードがあります。いつでも最も正確なデータを更新するには、データがスムーズに更新される前に、価格フィードを処理するスマート コントラクトが 21 台のオラクル マシンのうち少なくとも 14 台のオラクル マシンを受信して価格データを提供する必要があります。上記の操作のデータが正しくて信頼できるかどうかは非常に重要です。そうでないと、DeFi アプリケーションの価格を攻撃するためにオラクルをハイジャックする事件が発生します。したがって、例外を処理するには、価格の平均値を取得する、価格の乖離が大きい場合は価格の更新を再開する、価格の集計時刻を指定するなどの特定のルールが必要です。3. ハードウェア取得に基づくデータ フロー
Chainlink のモデルは広く使用されていますが、上記の最も基本的な構造を注意深く精査すると、データはチェーン処理を通じて信頼できるものになるものの、「チェーン上のデータ」のプロセスと以前は制御できないなど、いくつかの欠点が明らかにわかります。チェーンに行きます。さらに大きな問題は、Chainlink が単純なデータ、つまりバイト数が少なく宣伝性の強いデータを扱っていることです。したがって、このようなデータ モデルはいくつかのプロセス変換を行い、最終的に次のようなデータ プロセスを作成できます。ターミナル (データ生成元) の暗号化 - データ ストレージ - チェーン上のデータ ハッシュの保存 - チェーン上のデータ フローこのようなプロセスは、ハードウェア、分散ストレージ、ブロックチェーン ネットワークの組み合わせに基づくデータ フローとして説明できます。現在、モノのインターネット ネットワークの統合アプリケーションとして知られています。今日の例は、インターネットの Jasmy です。日本発のシングスネットワーク。このネットワークは、トヨタおよび旅行サービスプロバイダーのウィッツとの協力を完了し、プラットフォームのモデルを通じてスマートカーの端末データを処理し、個人情報コンプライアンスの回避に基づいてデータの価値をマイニングします。そのデータ処理パラダイムを詳しく分析してみましょう。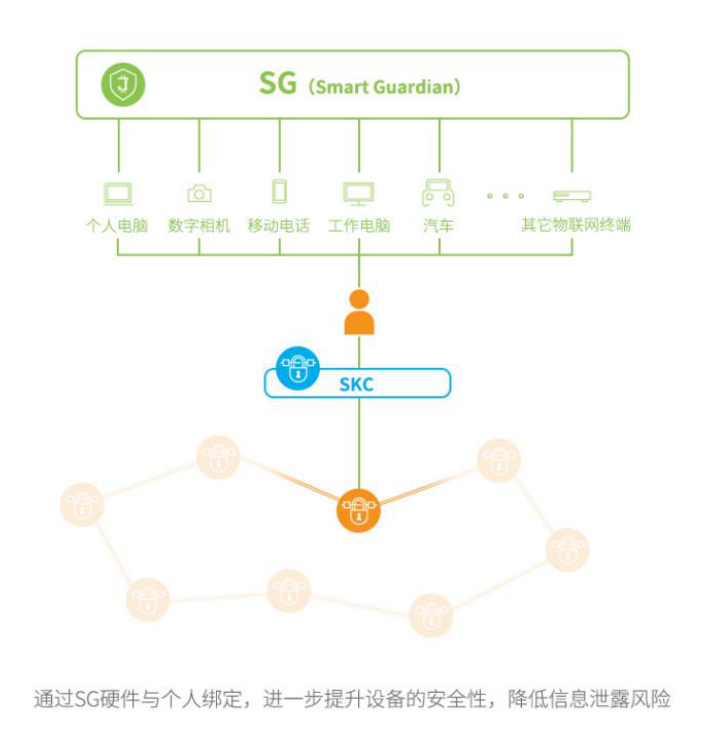 Jasmyによるハードウェア端末の管理例
Jasmyによるハードウェア端末の管理例
この部分では、多数の端末デバイスを管理する必要があるため、IoT デバイスを接続して主にデバイス管理を担う IoT プラットフォームを形成する必要があります。次のステップは、データ カテゴリが複雑でデバイス側で暗号化されているため、データを呼び出し可能にするために、データをオープン ネットワーク環境にアップロードし、いつでもデータを確認およびダウンロードできるようにする必要があります。ただし、その所有権と使用権には管理が必要です。したがって、大量のデータを処理するには分散ストレージが使用されますが、最も便利な例は IPFS に基づくデータ ストレージ構造です。4. IoT技術統合のデータ処理パラダイム
このプロセスと Oracle の実装の違いは、IoT 端末を使用してエッジ側の暗号化を完了し、エンドベースの暗号化を使用して後続の転送を完了することです。1. IoTプラットフォームは端末IoTデバイスの管理を担当し、JasmyのSKCサービスとSGサービスを使用して端末データの暗号化と管理を実現します。2. 端末のデータは、Jasmy の個人データ キャビネットに分散保管され、SKC および SG テクノロジーにより、このプロセス中に個人 ID またはデバイス ID に基づいてデータを特定できます。3. 分散ストレージのファイル ハッシュがチェーンにアップロードされ、チェーン上の ID がファイル ハッシュにバインドされます。4. ブロックチェーンネットワークに基づいて開発されたデータトランザクションアプリケーションは、データ価値の移転、つまりデータの所有権とデータ使用権の交換を実行できます。5. データユーザーは、分散ストレージの個人データキャビネット内のデータを呼び出すことができます。このプロセスには、日本のハードウェアメーカーであるソニーのハードウェア分野での暗号化技術と、モノのインターネット分野でのサプライチェーン能力を備えたジャスミーのいくつかの特徴が活かされており、他の一般的なブロックチェーン起業家ではモノのインターネットの利点を実現できません。 . 簡単に達成できます。例えば、SKCのコア技術であるFeliCaは、日本で長年使われている非接触チップ暗号化技術であり、ソニー製品の安全性を保証しています。これはまさに、Jasmy 構造に追加された新しい計算方法です。さらに、Jasmy はハードウェア メーカーと協力して、ネットワークに参加するための端末セキュリティとコンピューティング機能を備えたデバイスを発売することができます (たとえば、Jasmy Secure PC を立ち上げました)。Jasmy によって形成されたデータ価値実現モデル
5. 信頼できるデータコンピューティングに基づくデータフロー
Jasmy の設計モデルから、ブロックチェーンの単純なモデルは、いくつかの技術的恩恵の後、優れた結果を達成できることがわかります。データにとって最も必要なのは、所有権の帰属とデータ所有権に基づく信頼できるデータの流れ、つまりデータの可用性と不可視性の実現であり、データ所有者の権利と利益を確保するための一連の要件です。このパラダイムは、分散ストレージ、データ所有権の定義、および信頼できる実行に分割できるトラステッド コンピューティング モデルに基づくデータ フローとして定義できます。この部分を説明するために PlatON を使用します。PlatONの階層ロジックと機能配置
上の図では、レイヤー 2 のコンピューティング ネットワークには、データ ストレージのキャリア ノードである State が格納されており、この構造では、アカウント モデルとデータ ストレージが統合されたアプリケーションであることがわかります。PlatON の技術文書によると、状態アクセスでは、PlatON は引き続きイーサリアムのアカウント モデルを使用してデータを保存しますが、データ量が多いため、状態データはパトリシア ツリー (イーサリアムのストレージ構造) には保存されません。これは、履歴状態を保存しない別の SNAPDB (データベース) に個別に保存されます。PlatONのデータストレージモデル
したがって、PlatON のストレージはアカウント データ ストレージ (statedb) とスナップショット ストレージ (snapshotdb) に分割され、明らかに、1 つはチェーンの Layer1 に、もう 1 つは Layer2 に配置されます。ただし、レイヤー 2 では、データ コンピューティングの特性を最大限に発揮するために、非対話型のチェーン証明を実現する検証可能コンピューティング (VC) アルゴリズムなど、信頼できるコンピューティング デバイスとテクノロジによって追加の処理が実行されます。コンピューティング拡張スキーム、秘密分散 (SS) および準同型暗号化 (HE) と組み合わせた秘密マルチパーティ計算 (MPC) など、プライバシー コンピューティング プロトコルを実現します。さらに、信頼性の高いスマート コントラクトの計算を実行する MPC 仮想マシンがあり、これがネットワーク全体でのスマート コントラクトの運用の基礎となります。これらのLayer2層の実装により、最終的にデータフローやデータ適用を実現する際に、元データの漏洩を防ぎ、協調計算や結果検証を行うことが可能となります。特定のアプリケーション シナリオの要件を実装できるようにするには、レイヤー 2 に接続されたコンピューティング デバイスが専用のコンピューティング機能を備えている必要があることに注意してください。それにはスーパーコンピューティング能力と信頼できる機能が必要です。したがって、PlatON により、FPGA/ASIC などで開発された高性能コンピューティング デバイスがネットワークにアクセスして、このプロセスのニーズを満たすことができるようになります。6. 3 つのデータ処理パラダイムのアプリケーション分析
上記の3つのパラダイムがブロックチェーンベースのデータ処理手法の主流ですが、これら3つのパラダイムの応用はどうなるのでしょうか?Chainlinkの一部のノードが提供する価格フィードの表示
ただし、Oracle は単純な高頻度データのパラダイムであり、このモデルはシンプルで適用しやすいですが、インターネット社会のレガシーな問題を解決するのは苦手です。たとえば、データプライバシーの問題では、Oracle はパブリックデータでは信頼性が高くなりますが、独自のデータ部分はまったく得意ではありません。モノのインターネットに基づくデータ フローは、明らかに日常生活および商用データ処理のパラダイムです。たとえば、Jasmy のアプリケーションは、すでにインターネット アプリ データ、企業オフィス データ、および特定のハードウェア エコシステムのデータを対象としています。これは、ユーザーエンドからプラットフォームおよびビジネスのエコロジカルフローまで設計されたパラダイムです。これは、現在最も広く使用されているパラダイム構造でもあります。最後のトラステッド コンピューティングは、主にデータ資産の商用化を目的としたパラダイムです。解決が最も難しい部分は、商用化されたデータの連携シナリオにおいて、データが利用可能であるか不可視であるか、そして膨大な量のデータの信頼性があるかどうかです。テクノロジーが必要なだけでなく、信頼できるテクノロジー、コンピューティング能力、ストレージも同様に重視する必要があります。したがって、これら 3 つのパラダイムにはそれぞれ長所と短所があり、仮想通貨分野の DeFi には Oracle パラダイムが最適です。 Jasmy を例に挙げると、アプリケーションの境界が最も広く、単純な財務データ以外のアプリケーション分野にも切り込むことができます。このテクノロジーは比較的完成していますが、データのより詳細な定義と仕様がまだ必要です。それは第 3 のパラダイム トレンドに向かって発展する可能性があります。7.最後に書く
データの問題は深刻ですが、その解決策はイノベーターの実践で十分に準備されており、ブロックチェーンプロジェクトの実装プロセスが加速されれば、上記の3つのパラダイムはより多くのビジネス価値を生み出すでしょう。例えば、Jasmyはエンタープライズデータの機密設計と端末データ管理を実現することで、エッジデータの利用可能価値を高め、エンタープライズデータの利用率を高めることができます。 PlatON は、データの可用性と不可視性を実現し、AI プライバシー コンピューティングの分野に適用して、機械学習のプロセスでのデータ アプリケーションを支援します。このプロセスは、AI + 医療、AI + 旅行などの多くの業界で画期的です。 、AI+インターネットアプリケーションなど数年前、私たちは AI テクノロジーの出現を嘆いて「未来が来た」と言っていましたが、データの問題が解決された今では、本当に自信を持って「未来が来た」と言えると著者は考えています。これは、データが所有者のものとなる新しい未来であり、インターネット上のデータカオス時代では表現できない新しい未来です。 


