
Jensen Huang's GTC Keynote Full Text: The Age of Inference Arrives, Lobster is the New Operating System
- Core Viewpoint: At GTC 2026, NVIDIA elaborated on its transformation from a chip company to an "AI infrastructure and factory company." Based on the business logic of "Token Factory Economics," it provided a robust demand forecast of at least $1 trillion by 2027.
- Key Elements:
- Performance Guidance: Jensen Huang stated that NVIDIA's demand expectation through 2027 is at least $1 trillion, and he believes actual demand will be even higher. This expectation once drove the stock price up over 4.3%.
- Token Factory Economics: Future data centers are "factories" producing AI Tokens. Under fixed power constraints, the system with the highest Token throughput per watt has the lowest production cost, directly determining revenue.
- Technological Breakthrough: The new-generation AI computing system, Vera Rubin, through end-to-end co-design, increased Token generation speed by 350 times within two years, far exceeding Moore's Law's 1.5x improvement.
- Ecosystem and Software Revolution: The open-source project OpenClaw is seen as the "operating system" for the Agent era. Jensen Huang asserts that all SaaS companies will transform into AaaS (Agent-as-a-Service) companies.
- Market Structure: 60% of NVIDIA's business comes from the top five cloud service providers, while 40% is widely distributed across sovereign clouds, enterprises, industrial, robotics, and edge computing, demonstrating broad industry coverage.
Original Author: Bao Yilong
Original Source: Wall Street News

On March 16, 2026, the NVIDIA GTC 2026 conference officially opened, with NVIDIA founder and CEO Jensen Huang delivering the keynote speech.
At this conference, regarded as the "annual pilgrimage for the AI industry," Jensen Huang elaborated on NVIDIA's transformation from a "chip company" to an "AI infrastructure and factory company." Addressing the market's most pressing concerns about the sustainability of performance and growth potential, Huang detailed the underlying business logic driving future growth—"Token Factory Economics."
Extremely Optimistic Performance Guidance: "At Least $1 Trillion in Demand by 2027"
Over the past two years, global AI computing demand has exploded exponentially. As large models evolved from "perception" and "generation" to "reasoning" and "action (task execution)," the consumption of computing power has surged dramatically. Regarding the market's high focus on the ceiling for orders and revenue, Huang gave an exceptionally strong forecast.
Huang stated bluntly in his speech:
At this time last year, I said we saw $500 billion in high-confidence demand, covering Blackwell and Rubin through 2026. Now, right here, right now, I see at least $1 trillion in demand by 2027.

Huang's trillion-dollar expectation once pushed NVIDIA's stock price up over 4.3%.
Not only that, he further elaborated on this number:
Is this reasonable? That's what I'm going to talk about next. In fact, we will even be supply-constrained. I am certain the actual computing demand will be much higher than this.
Huang pointed out that NVIDIA's systems have proven themselves to be the world's "lowest-cost infrastructure." Because NVIDIA can run AI models from almost every domain, this versatility ensures that the $1 trillion invested by customers can be fully utilized and maintain a long lifecycle.
Currently, 60% of NVIDIA's business comes from the top five hyperscale cloud service providers, while the remaining 40% is widely distributed across sovereign clouds, enterprises, industrial, robotics, and edge computing sectors.
Token Factory Economics: Performance per Watt Determines Commercial Lifeline
To explain the rationale behind this $1 trillion demand, Huang presented a new business mindset to global CEOs. He stated that future data centers are no longer warehouses for storing files but "factories" producing Tokens (the basic unit generated by AI).

Huang emphasized:
Every data center, every factory, by definition, is power-constrained. A 1GW (gigawatt) factory will never become 2GW; that's the law of physics and atoms. Under a fixed power budget, whoever has the highest token throughput per watt has the lowest production cost.
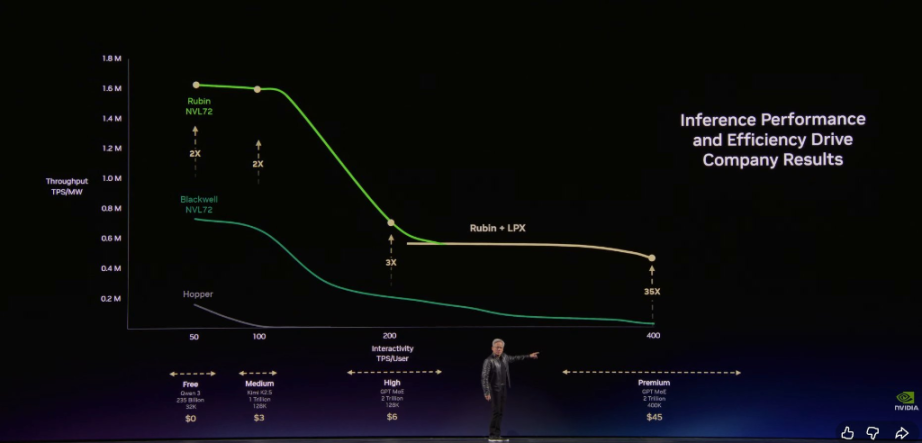
Huang categorized future AI services into five commercial tiers:
- Free Tier (high throughput, low speed)
- Mid Tier (~$3 per million tokens)
- Premium Tier (~$6 per million tokens)
- High-Speed Tier (~$45 per million tokens)
- Ultra-High-Speed Tier (~$150 per million tokens)
He pointed out that as models become larger and contexts longer, AI gets smarter, but the token generation rate decreases. Huang stated:
In this token factory, your throughput and token generation speed will directly translate into your precise revenue next year.
Huang emphasized that NVIDIA's architecture allows customers to achieve extremely high throughput at the free tier while delivering a staggering 35x performance improvement at the highest-value inference tiers.
Vera Rubin Achieves 350x Acceleration in Two Years, Groq Fills Ultra-Fast Inference Gap
Within this physical constraint, NVIDIA introduced its most complex AI computing system ever, Vera Rubin. Huang stated:
In the past, when mentioning Hopper, I would hold up a chip; that was cute. But when mentioning Vera Rubin, people think of the entire system. In this 100% liquid-cooled system that completely eliminates traditional cables, racks that used to take two days to install now take only two hours.
Huang pointed out that through extreme end-to-end software and hardware co-design, Vera Rubin achieved a staggering data leap within the same 1GW data center:
In just two years, we increased the token generation rate from 22 million to 700 million, achieving 350x growth. Moore's Law could only bring about a 1.5x improvement over the same period.
To address bandwidth bottlenecks under ultra-fast inference conditions (e.g., 1000 Tokens/second), NVIDIA presented the final solution integrating the acquired company Groq: asymmetric disaggregated inference. Huang explained:
These two processors are fundamentally different. The Groq chip has 500MB of SRAM, while a single Rubin chip has 288GB of memory.

Huang pointed out that NVIDIA, through its Dynamo software system, assigns the "Pre-fill" stage requiring massive computation and memory to Vera Rubin, and the "Decode" stage extremely sensitive to latency to Groq. Huang also gave advice on enterprise computing power configuration:
If your workload is primarily high throughput, use 100% Vera Rubin; if you have a lot of high-value, programming-level token generation needs, allocate about 25% of your data center scale to Groq.
It was revealed that the Groq LP30 chip, manufactured by Samsung, is already in mass production and is expected to ship in the third quarter, while the first Vera Rubin rack is already running on Microsoft Azure cloud.
Furthermore, regarding optical interconnect technology, Huang showcased the world's first mass-produced Co-Packaged Optics (CPO) switch, Spectrum X, and settled the market debate over the "copper vs. optics" roadmap:
We need more copper cable capacity, more optical chip capacity, more CPO capacity.
Agents End Traditional SaaS, "Annual Salary + Tokens" Becomes Silicon Valley Standard
Beyond hardware barriers, Huang devoted significant time to the revolution in AI software and ecosystems, particularly the explosion of Agents.
He described the open-source project OpenClaw as "the most popular open-source project in human history," claiming it surpassed what Linux achieved in 30 years in just a few weeks. Huang stated bluntly that OpenClaw is essentially the "operating system" for Agent computers.
Huang asserted:
Every SaaS (Software-as-a-Service) company will become an AaaS (Agent-as-a-Service) company. Undoubtedly, to safely deploy such agents capable of accessing sensitive data and executing code, NVIDIA launched the enterprise-grade NeMo Claw reference design, adding a policy engine and privacy router.
For ordinary professionals, this transformation is equally imminent. Huang depicted the new future workplace:
In the future, every engineer in our company will need an annual token budget. Their base salary might be several hundred thousand dollars, and I will add about half that amount on top as a token allowance for them to achieve 10x efficiency gains. This is already a new hiring chip in Silicon Valley: how many tokens come with your offer?
At the end of the speech, Huang also "spoiled" the next-generation computing architecture, Feynman, which will for the first time enable co-horizontal scaling of copper wires and CPO. Even more intriguing, NVIDIA is developing the "Vera Rubin Space-1" data center computer deployed in space, completely opening up the imagination for AI computing power to extend beyond Earth.
Full transcript of Jensen Huang's GTC 2026 keynote speech, translated as follows (with AI tool assistance):
Host: Please welcome NVIDIA founder and CEO Jensen Huang to the stage.
Jensen Huang, Founder and CEO:
Welcome to GTC. I want to remind everyone, this is a technology conference. I'm so happy to see so many people lining up early in the morning, and to see all of you here.
At GTC, we will focus on three themes: technology, platforms, and ecosystems. NVIDIA currently has three major platforms: the CUDA-X platform, the system platform, and our newly launched AI factory platform.
Before we begin, I want to thank our warm-up session hosts—Sarah Guo from Conviction, Alfred Lin from Sequoia Capital (NVIDIA's first venture capitalist), and Gavin Baker, NVIDIA's first major institutional investor. These three have deep insights into technology and immense influence across the entire technology ecosystem. Of course, I also want to thank all the distinguished guests I personally invited today. Thank you to this all-star team.
I also want to thank all the companies present today. NVIDIA is a platform company; we have technology, platforms, and a rich ecosystem. The companies here today represent almost all participants in a $100 trillion industry; 450 companies are sponsoring this event, for which I am deeply grateful.
This conference features 1,000 technical sessions, 2,000 speakers, covering every layer of the AI "five-layer cake" architecture—from infrastructure like land, power, and facilities, to chips, platforms, models, and finally the various applications driving the entire industry forward.
CUDA: Two Decades of Technological Accumulation
It all started here. This year marks the 20th anniversary of CUDA.
For twenty years, we have been dedicated to developing this architecture. CUDA is a revolutionary invention—SIMT (Single Instruction, Multiple Threads) technology allows developers to write programs in scalar code and scale them into multi-threaded applications, with programming difficulty far lower than previous SIMD architectures. We recently added Tiles functionality to help developers more easily program Tensor Cores and the various mathematical operation structures that today's AI relies on. Currently, CUDA has thousands of tools, compilers, frameworks, and libraries, with hundreds of thousands of public projects in the open-source community, deeply integrated into every technology ecosystem.
This chart reveals NVIDIA's 100% strategic logic; I've been showing this slide from the beginning. The hardest and most core element is the "installed base" at the bottom of the chart. Over twenty years, we have accumulated hundreds of millions of GPUs and computing systems running CUDA worldwide.
Our GPUs cover all cloud platforms, serving almost every computer manufacturer and industry. CUDA's massive installed base is the fundamental reason this flywheel keeps accelerating. Installed base attracts developers, developers create new algorithms and achieve breakthroughs, breakthroughs spawn entirely new markets, new markets form new ecosystems and attract more companies, further expanding the installed base—this flywheel is continuously accelerating.
Downloads of NVIDIA libraries are growing at an astonishing rate, massive in scale and accelerating. This flywheel enables our computing platform to support a vast number of applications and endless new breakthroughs.
More importantly, it also gives this infrastructure an extremely long useful life. The reason is obvious: the range of applications that can run on NVIDIA CUDA is extremely rich, covering every stage of the AI lifecycle, various data processing platforms, and all kinds of scientific principle solvers. Therefore, once an NVIDIA GPU is installed, its actual utility value is extremely high. This is why the cloud price of our Ampere architecture GPU, released six years ago, is actually rising.
The fundamental reason for all this is: massive installed base, strong flywheel, broad developer ecosystem. When these factors work together, coupled with our continuous software updates, computing costs keep falling. Accelerated computing dramatically improves application performance, and as we maintain and iterate software long-term, users not only get a performance leap initially but also continuously enjoy falling computing costs. We are willing to provide long-term support for every GPU worldwide because they are architecturally fully compatible.
The reason we are willing to do this is because the installed base is so massive—every time we release a new optimization, it benefits millions of users. This dynamic combination allows the NVIDIA architecture to continuously expand its reach, accelerate its own growth, while constantly lowering computing costs, ultimately stimulating new growth. CUDA is at the heart of all this.
From GeForce to CUDA: A Twenty-Five-Year Evolution
And our journey with CUDA actually began twenty-five years ago.
GeForce—I believe many of you grew up with GeForce. GeForce is NVIDIA's most successful market development project. We started cultivating future customers when you couldn't afford the products—your parents became NVIDIA's earliest users on your behalf, buying our products year after year, until one day you grew into excellent computer scientists, becoming true customers and developers.
This is the foundation laid by GeForce twenty-five years ago. Twenty-five years ago, we invented the programmable shader—an obvious yet profound invention that made accelerators programmable, the world's first programmable accelerator, the pixel shader. Five years later, we created CUDA—one of the most important investments we ever made. The company had limited financial resources at the time, but we bet the vast majority of our profits on it, committed to extending CUDA from GeForce to every computer. We were so determined because we deeply believed in its potential. Despite initial hardships, the company held onto this belief for 13 generations, a full twenty years, and now CUDA is everywhere.
It was the pixel shader that drove the GeForce revolution. And about eight years ago, we launched RTX—a complete architectural overhaul for the modern computer graphics era. GeForce brought CUDA to the world, and precisely because of that, allowed scholars like Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton, Andrew Ng to discover that GPUs could be a powerful tool for accelerating deep learning, igniting the AI big bang a decade ago.
A decade ago, we decided to merge programmable shading with two new concepts: one was hardware ray tracing, which was technically very challenging; the other was a forward-looking idea—about a decade ago, we foresaw that AI would completely transform computer graphics. Just as GeForce brought AI to the world, AI will now reshape the entire implementation of computer graphics.
Today, I want to show you the future. This is our next-generation graphics technology, we call it Neural Rendering—the deep integration of 3D graphics and AI. This is DLSS 5, watch.
Neural Rendering: The Fusion of Structured Data and Generative AI
Isn't this breathtaking? Computer graphics have come to life.
What did we do? We combined controllable 3D graphics (the true foundation of the virtual world) with its structured data, then infused it with generative AI and probabilistic computing. One is completely deterministic, the other probabilistic yet highly realistic—we merged these two concepts, achieving precise control through structured data while performing real-time generation.
Ultimately, the content is both stunningly beautiful and completely controllable.
The concept of fusing structured information with generative AI will be replicated across industry after industry. Structured data is the foundation of trustworthy AI.
Accelerated Platforms for Structured and Unstructured Data
Now I want to show you a technology architecture diagram.
Structured data—familiar ones like SQL, Spark, Pandas, Velox, and important platforms like Snowflake, Databricks, Amazon EMR, Azure Fabric, Google BigQuery, all process Data Frames. These Data Frames are like giant spreadsheets, carrying all the information of the business world, the Ground Truth of enterprise computing.
In the AI era, we need AI to use this structured data and accelerate it to the extreme. In the past, accelerating structured data processing was to make enterprises run more efficiently. In the future, AI will use these data structures at speeds far exceeding humans, and AI agents will heavily call upon structured databases.
For unstructured data, vector databases, PDFs, videos, audio, etc., constitute the vast majority of the world's data forms—about 90% of data generated annually is unstructured. In the past, this data was almost completely unusable: we read it, stored it in file systems, and that was it. We couldn't query it, nor easily retrieve it, because unstructured data lacks simple indexing; you must understand its meaning and context. Now, AI can do this—with multimodal perception and understanding technology, AI can read PDF documents, understand their meaning, and embed them into larger, queryable structures.
NVIDIA has created two foundational libraries for this:
- cuDF: for accelerated processing of Data Frames, structured data
- cuVS: for vector storage, semantic data, and unstructured AI data processing
These two platforms will become one of the most important foundational platforms in the future.
Today, we announced partnerships with several companies. IBM—the inventor of SQL—will use cuDF to accelerate its WatsonX Data platform. Dell jointly built the Dell AI Data Platform with us, integrating cuDF and cuVS, achieving significant performance improvements in real projects with NTT Data. For Google Cloud, we now not only accelerate Vertex AI but also BigQuery, and in collaboration


