
Part 3 of the Gonka Algorithm Series: Computational Challenges and Anti-Cheating Mechanisms
- 核心观点:Gonka PoW 2.0将挖矿转化为有用AI计算。
- 关键要素:
- LLaMA模型权重确定性初始化。
- 目标向量球面均匀分布生成。
- 统计学欺诈检测与防作弊验证。
- 市场影响:推动挖矿向实用AI计算转型。
- 时效性标注:长期影响
Introduction: The core mechanism of Gonka PoW 2.0
The core idea of Gonka PoW 2.0 is to transform traditional proof-of-work into a meaningful AI computing task. This article will delve into its two core mechanisms: computational challenge generation and anti-cheating verification. It will demonstrate how this innovative consensus mechanism ensures computational usefulness while establishing a reliable anti-cheating safeguard.
The entire process can be summarized as the following diagram: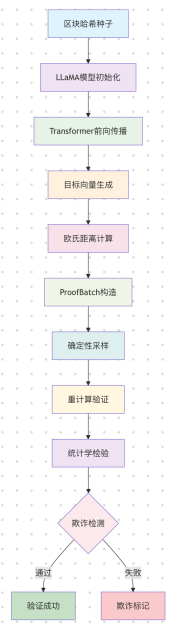
1. Computational Challenge Generation Mechanism
Computational challenges are at the core of Gonka PoW 2.0, transforming traditional proof-of-work into a meaningful AI computing task. Unlike traditional PoW, Gonka's computational challenge is not a simple hash calculation, but a complete deep learning reasoning process, which not only ensures network security but also produces usable computational results.
1.1 Unified management of the seed system
All computations are driven by a unified seed, ensuring that all nodes in the network run the same computational tasks. This design ensures reproducibility and fairness in computations, as every node must execute the same computational tasks to obtain valid results.
Data source : mlnode/packages/pow/src/pow/compute/compute.py#L217-L225

Key elements of seed systems include:
-Block hash : acts as the master seed to ensure the consistency of computing tasks
-Public key : identifies the identity of the computing node
-Block height : ensure time synchronization
-Parameter configuration : control model architecture and computational complexity
1.2 Deterministic Initialization of LLaMA Model Weights
Each computational task starts with a unified LLaMA model architecture, with weights deterministically initialized via block hashing. This design ensures that all nodes use the same model structure and initial weights, guaranteeing consistent computational results.
Data source : mlnode/packages/pow/src/pow/models/llama31.py#L32-L51 

Mathematical principles of weight initialization:
-Normal distribution : N(0, 0.02²) - Small variance ensures gradient stability
- Determinism : The same block hash produces the same weight
-Memory efficiency : support float16 precision to reduce video memory usage
1.3 Target vector generation and distance calculation
The target vectors are uniformly distributed on the high-dimensional unit sphere, which is the key to the fairness of the computational challenge. By generating uniformly distributed target vectors in high-dimensional space, the randomness and fairness of the computational challenge are ensured.
Data source : mlnode/packages/pow/src/pow/random.py#L165-L177
In a 4096-dimensional vocabulary space, spherical geometry has the following properties:
-Unit length :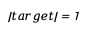
-Angle distribution : The angle between any two random vectors tends to be 90°
- Concentration phenomenon : most of the mass is distributed near the surface of the sphere
Mathematical principle of uniform distribution on the sphere:
In n-dimensional space, a uniform distribution on the unit sphere can be generated as follows:
1. First generate n independent standard normal distribution random variables: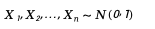
2. Then normalize: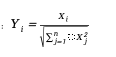
This method ensures that the generated vectors are evenly distributed on the sphere, and the mathematical expression is:
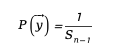
in is the surface area of the n-1 sphere.
is the surface area of the n-1 sphere.
Distance calculation is a key step in verifying the calculation results. The effectiveness of the calculation is measured by calculating the Euclidean distance between the model output and the target vector:
Data source : Based on the processing logic in mlnode/packages/pow/src/pow/compute/compute.py 


Steps for distance calculation:
1. Permutation application : rearrange the output dimensions according to the permutation seed
2. Vector normalization : Ensure that all output vectors lie on the unit sphere
3. Distance calculation : Calculate the Euclidean distance to the target vector
4. Batch encapsulation : encapsulate the results into ProofBatch data structure
2. Anti-cheating verification mechanism
To ensure the fairness and security of computational challenges, the system has designed a sophisticated anti-cheating verification system. This mechanism verifies the authenticity of computations through deterministic sampling and statistical testing, preventing malicious nodes from obtaining improper benefits through cheating.
2.1 ProofBatch Data Structure
The calculation results are encapsulated into the ProofBatch data structure, which is the core carrier of the verification process. ProofBatch contains the identity information of the computing node, timestamp, and calculation results, providing the necessary data foundation for subsequent verification.
Data source : mlnode/packages/pow/src/pow/data.py#L8-L25 

Characteristics of the ProofBatch data structure:
-Identity : public_key uniquely identifies the computing node
- Blockchain binding : block_hash and block_height ensure time synchronization
-Calculation results : nonces and dist record all attempts and their distance values
- Sub-batch support : support extracting successful calculations that meet the threshold
2.2 Deterministic Sampling Mechanism
To improve verification efficiency, the system uses a deterministic sampling mechanism, verifying only some of the calculation results rather than all of them. This design not only ensures the effectiveness of verification, but also greatly reduces verification costs.
Gonka's verification sampling rate is uniformly managed through on-chain parameters to ensure consistency across the entire network:
Data source : inference-chain/proto/inference/inference/params.proto#L75-L78

Data source : inference-chain/x/inference/types/params.go#L129-L133

Based on the seed system, the sampling process is completely deterministic, ensuring the fairness of verification. By using the SHA-256 hash function and the validator's public key, block hash, block height and other information to generate the seed, all validators are guaranteed to use the same sampling strategy:
Data source : decentralized-api/mlnodeclient/poc.go#L175-L201 

Advantages of deterministic sampling:
- Fairness : All validators use the same sampling strategy
- Efficiency : Only verify part of the data to reduce verification costs
- Security : It is difficult to predict the sampled data to prevent cheating
2.3 Statistical Fraud Detection
The system uses a binomial distribution test to detect fraud, using statistical methods to determine the honesty of computing nodes. This method sets an expected error rate based on hardware precision and computational complexity, and uses statistical tests to detect anomalies.
Data source : mlnode/packages/pow/src/pow/data.py#L7
The expected error rate is set taking into account the following factors:
-Floating point precision : Differences in floating point precision between different hardware
-Parallel computing : Numerical accumulation errors caused by GPU parallelization
- Randomness : small differences in model weight initialization
-System differences : computing behavior differences between different operating systems and drivers
Data source : mlnode/packages/pow/src/pow/data.py#L174-L204




Summary: Building a secure and reliable AI computing network
Gonka PoW 2.0 successfully combines the security requirements of blockchain with the practical value of AI computing through a carefully designed computational challenge and anti-cheating verification mechanism. The computational challenge ensures the meaningfulness of the work, while the anti-cheating mechanism guarantees the fairness and security of the network.
This design not only verifies the technical feasibility of "meaningful mining", but also establishes a new standard for distributed AI computing: computing must be both secure and useful, verifiable and efficient.
By combining statistics, cryptography, and distributed system design, Gonka PoW 2.0 successfully established a reliable anti-cheating mechanism while ensuring computational usefulness, providing a solid security foundation for the technical route of "meaningful mining."
Note: This article is based on the actual code implementation and design documentation of the Gonka project. All technical analysis and configuration parameters are from the official code repository of the project.
About Gonka.ai
Gonka is a decentralized network designed to provide efficient AI computing power. Its design goal is to maximize the use of global GPU computing power to complete meaningful AI workloads. By eliminating centralized gatekeepers, Gonka provides developers and researchers with permissionless access to computing resources while rewarding all participants with its native GNK token.
Gonka was incubated by US AI developer Product Science Inc. Founded by the Libermans siblings, Web 2 industry veterans and former core product directors at Snap Inc., the company successfully raised $18 million in 2023 from investors including OpenAI investor Coatue Management, Solana investor Slow Ventures, K5, Insight, and Benchmark Partners. Early contributors to the project include well-known leaders in the Web 2-Web 3 space, such as 6 Blocks, Hard Yaka, Gcore, and Bitfury.
Official Website | Github | X | Discord | Whitepaper | Economic Model | User Manual


