
Web3 Collaborative Intelligence: Knowledge Tree, Knowledge Forest and Community Contribution
Original Author: Eric Zhang
Original Author: Eric Zhang
Special thanks to Zeo, DAOctor, Zhengyu, Christina for their contributions, reviews and feedback.
Building knowledge structure databases and better visualizing knowledge are important tasks to advance computer science, artificial intelligence, and the Web. Before the emergence of the world of cryptocurrencies and decentralized applications, old Web 3.0 research mainly focused on building knowledge bases and knowledge graphs, and representation/reasoning based on these structures (Semantic Web).
There are two general approaches to building a knowledge base. One approach is to take data from the web as well as other data sources, organize them into the desired knowledge database (mainly huge collections of "triples" or "graphs"), and then perform "higher order logic" or machine learning techniques for reasoning about structures and other intelligent tasks). Another approach is to rely on human intelligence to collaboratively build databases (for example, Wikipedia, ConceptNet, or the Citizen Science project, which we discuss in more detail later).
This article will first review some relevant innovations of the past few decades, and then discuss how we can move forward to build a high-level knowledge database with collective intelligence and sustainable incentive mechanism.
Knowledge Base, Knowledge Graph and Wikipedia
For a long time, people have been interested in creating knowledge graphs for two main reasons:
The dots that connect all information and knowledge created by humans,
And perform reasoning and machine learning techniques on the knowledge graph to produce better artificial intelligence, and use this system to improve the user experience of Web2 products.
Right now, knowledge graphs that are clearly useful are mostly created as foundational tools for large corporations in Web2. For example, Facebook Knowledge Graph helps in better social network search and Google Knowledge Graph helps in presenting relevant information. Since everything is closed source, we don't know how the knowledge graph is built, but from the UI point of view, these knowledge graphs will definitely help improve the user experience.
The efforts of the Wikipedia community are amazing. It was one of the first attempts to demonstrate the power of the internet community. On the other hand, open databases can be used as Internet public goods. An example is DBpedia, a database that provides an API for applications that want to take advantage of the Wikipedia knowledge base. Another example is ConceptNet, a freely available semantic network that helps AI and NLP programs acquire common semantics.
However, there are some fundamental limits to how much these Internet NGOs can do. Wikipedia relies on donations every year, it operates within a 501(c)3 organization, it is difficult to put more advanced incentives on it and build cooler infrastructure based on knowledge networks. The same goes for DBpedia and ConceptNet etc. As non-profit organizations, it is difficult for these public welfare organizations to deeply build a community that continuously builds infrastructure and eventually forms an ecosystem. I built a Wikipedia graph visualization and search tool in college using DBpedia's API. However, it was much more difficult to join a vibrant community back then. Now in the crypto community, the situation is very different, developers with good ideas can participate in more activities, form teams and be supported by a multi-chain ecosystem.
However, I would not recommend building another Wikipedia (aka DAO-ify Wikipedia, or "Web3 Wikipedia"), because despite the limitations of the current nonprofit model, Wikipedia sites are well curated in content and structure And organizations, people have benefited from its results to a large extent. In general, Wikipedia is good at storing descriptions of knowledge, and through the Web1 and Web2 infrastructure, we've made knowledge searchable. What Wikipedia and the existing web infrastructure are not good at is presenting knowledge for "human understanding" - structured knowledge in the human brain. In order to present this information, human curation and human collaboration are at the core, which is not well supported in Web1/Web2 infrastructure, but will be possible through Web3 infrastructure and coordination mechanisms
**It is worth noting that people strive to build massive structural databases to enhance machine understanding of knowledge. Companies like Cyc, for example, have been trying for decades to build a commonsense knowledge base to help machines mimic the human brain. These companies eventually turned themselves into business software companies, because powerful AI clearly required more than a knowledge base of nodes and relationships. Compared with building a structured knowledge base for machines, human understanding of knowledge and human management are important here-building a knowledge base of human understanding to help more people understand.
On the other hand, it's worth thinking about how to add higher-level semantics to the current Web of Knowledge, the structured knowledge we describe in this paper.
Citizen Science and Volunteer Computing
Another branch of exploration I want to mention is citizen science and volunteer computing. In the early 2010s, the scientific community had many exciting projects harnessing the wisdom of crowds to accelerate the progress of research and scientific discovery. There are generally two types of such efforts. The first is called voluntary computing, which distributes computing tasks to a group of individual computing devices (eg LHC@Home, SETI@Home). The second type is called citizen science, which creates repetitive tasks (not a pejorative term here!) that everyone can perform. The project collects data (and sometimes analysis results) from numerous contributors and feeds them into a number of research projects to create meaningful results (e.g. projects listed in Citizen Cyberlab, SciStarter, or the Machine Learning Community, tagged Images to enrich training data can be crowdsourced). Think of these efforts as "DAOs" without inventing the word, the coordination aspect of decentralized communities is nothing new!
Many projects have been successful, but again, unfortunately, the sustainability of these projects has been limited. SETI@Home is no longer in operation, and many citizen science projects that could have lasted longer did not. Incentives and ecosystems are two important aspects of any collaborative effort. Without an ecosystem, innovation is limited. Without sustainable incentives, there will be no vibrant community and no ecosystem will ever emerge.
Structure of Complex Concepts and Knowledge
Now let's consider what high-level concepts and knowledge look like. Intuitively, when we "understand" a concept, we actually understand the concept in considerable detail. We can think of the process of "understanding" in two ways:
1. Understanding through tree structure
The deeper the tree is broken down, the more primitive the concept. At some point, there will be some very direct resource on the web that can be directly referenced (e.g. a Wikipedia page or some article/video).
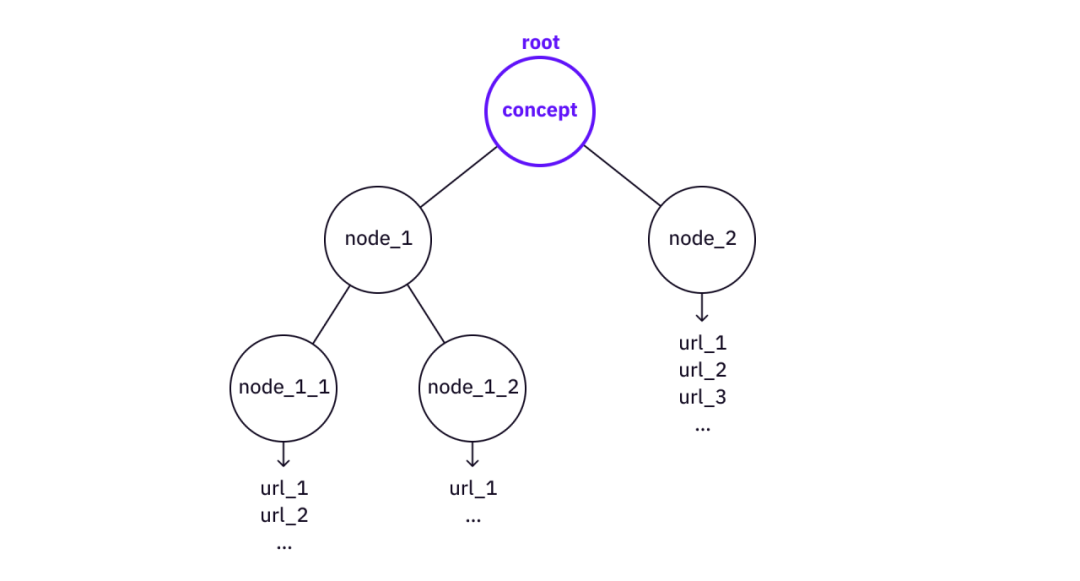
image description
"Broken down" concepts into a tree structure
We can find some similar ideas from old AI. K-line theory shows that our memories and knowledge are stored in tree structures (P-nodes and K-nodes). While there is a lack of actual evidence that such structures actually exist in our brains, the model has the power to explain how human memory and the human brain work, and tree structures are indeed the most compact form of storing structural knowledge.
If we want to retrieve details, we decompose a knowledge tree. On the other hand, if we have a tree of knowledge, we can use this tree to build larger trees (aka higher abstractions of knowledge and understanding).
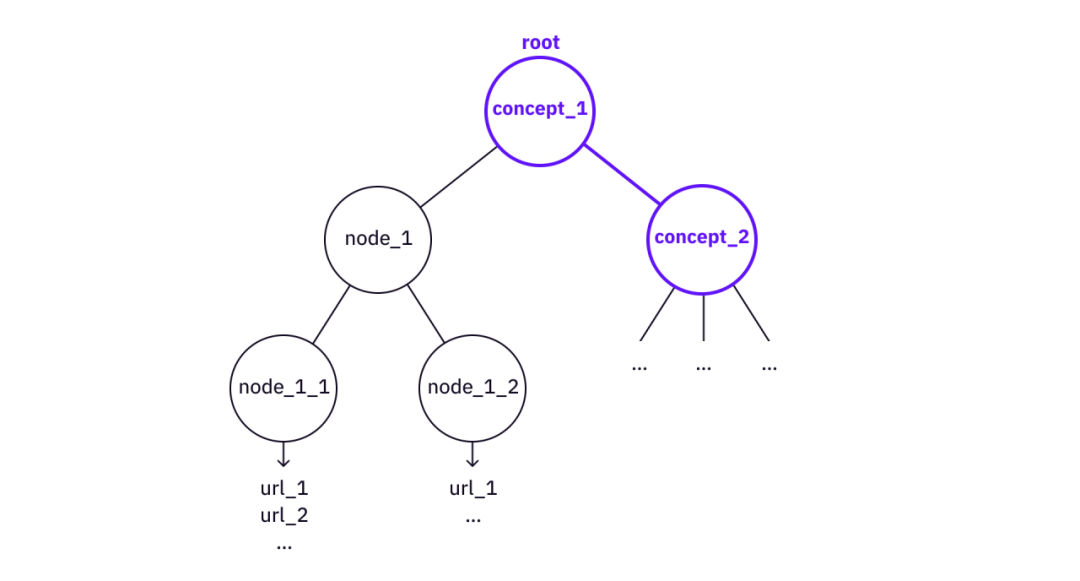
image description
Using Concept_2 "Building" Concept_1
In the case of "construction", a "Merkle tree" tree can be used as nodes to build more complex knowledge trees, such as "Verkle trees" or "Merkle multiple proofs".
It is worth noting that the key point here is the structure of the tree. The knowledge tree points to all necessary references to existing web resources from the root concept to the leaves. The relationship between nodes is not important here (unlike the "triple" thinking in knowledge graph systems).
2. Understanding through “relevant knowledge”
We also gain a deeper understanding of knowledge by adding more "context". As Weigenstain famously said, "But what does the word 'five' mean? There is no such question here, only how the word 'five' is used". The idea behind it is that the meaning of something actually depends on other concepts related to it, which together determine the meaning of something. By adding more context (that is, relevant knowledge of the knowledge itself), we can understand knowledge more "deeper".
In general, it's easier for people to understand trees than graphs. Instead of building a knowledge map, it is better to think of "related knowledge" as a more practical way-a set of knowledge trees connected by root nodes, which essentially forms a knowledge forest.
A knowledge forest can be constructed as a database of many knowledge trees (parallel planting). There are two basic operations we can perform on the database.
The features of a knowledge tree can be constructed as vectors in a certain vector space. Vectors can then be used to associate knowledge trees that are conceptually related but not directly linked by (1).
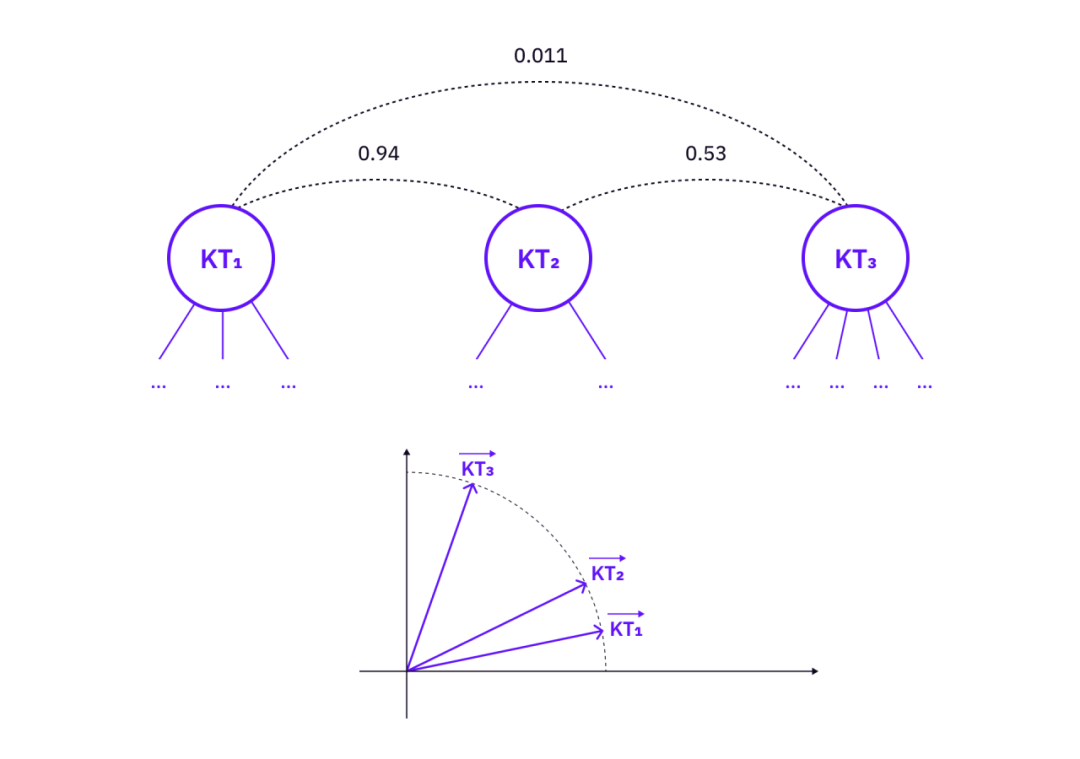
image description
Measuring Relationships Between Knowledge Trees
about the depth of understanding
In general, people have different levels of understanding of the same concept. For some people, the concept of a Merkle tree is simple and does not need to be broken down further (their brain has encapsulated this concept into some common sense), while others do not have enough information to understand the concept of a "Merkle tree" and may need A further breakdown.
Therefore, knowledge trees do not have to be mutually exclusive, which means that there may be overlap between different trees. There may be trees explaining basic concepts, and trees built for advanced concepts.
Overlap can create redundancy between trees. To reduce redundancy, we can introduce the following operations:
Merge - There may already be subtrees under the nodes of both trees, and if some valuable nodes, leaves, and references are not already covered by the base tree, it may be worth merging information from the higher level tree to the more base tree.
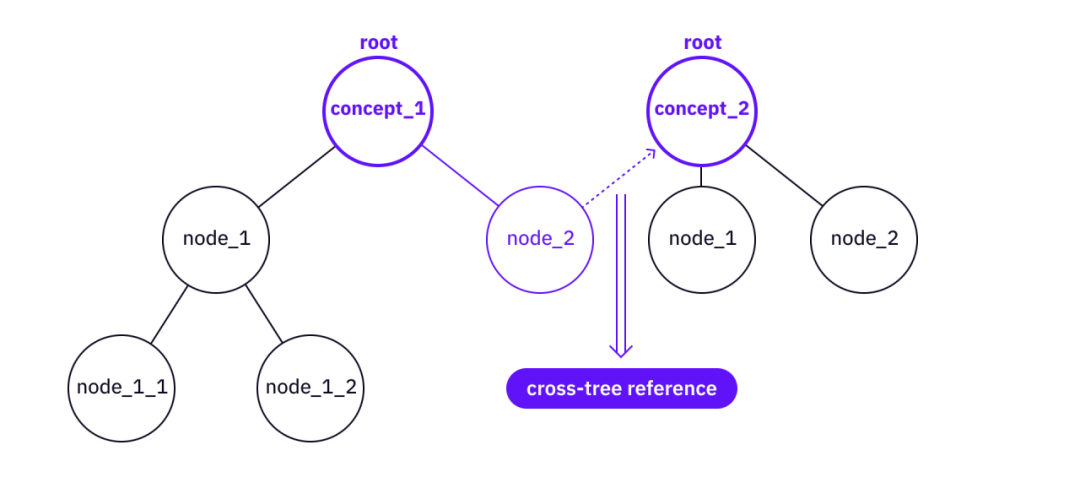
Cross-Tree Reference Links
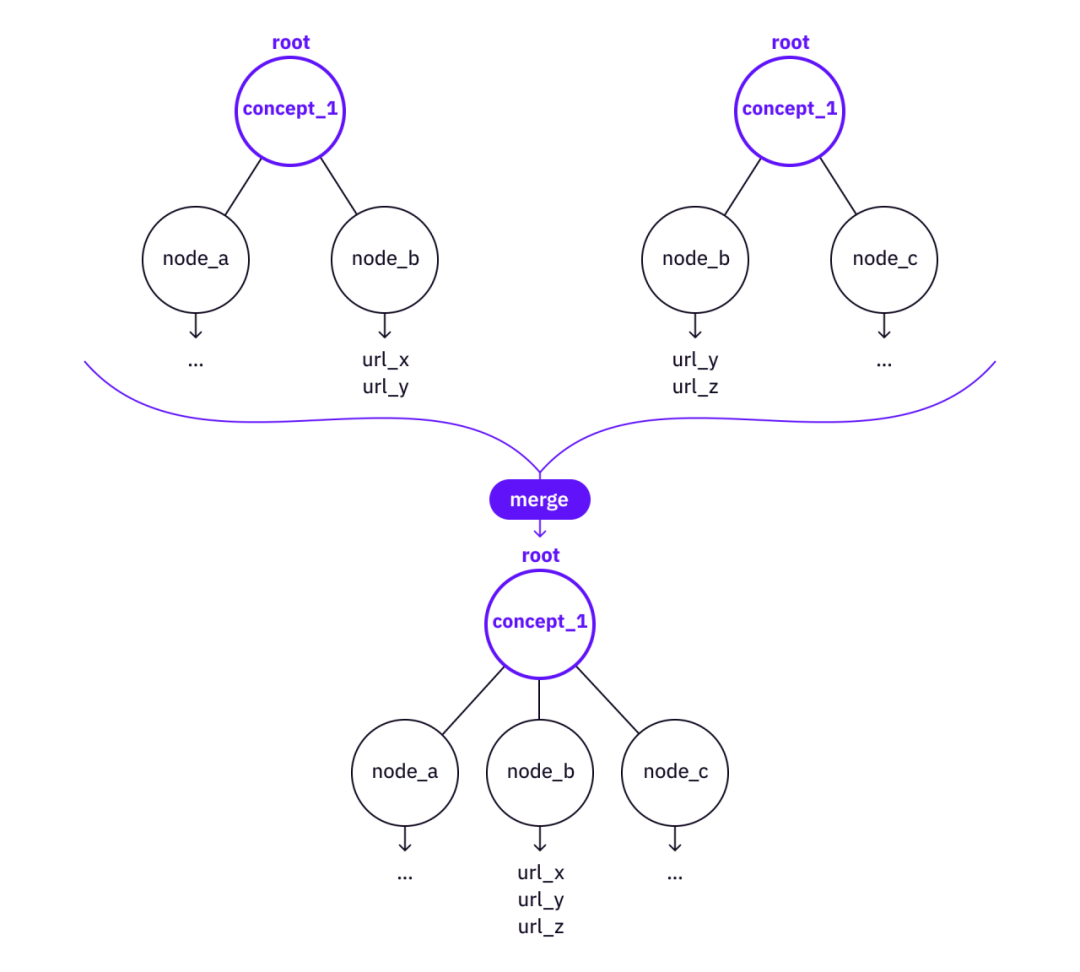
image description
Merge two trees into one
Knowledge Trees and Meta-Operations
A single knowledge tree consists of a root, a set of child nodes, and a set of leaves, organized into a tree structure. We can then define a set of basic operations to create and refine a tree.
create root (tree)
add child node
Add leaves to nodes
Add reference link to leaf
We can then define a series of high-level actions for actual users to "plant" and contribute to a tree.
Add subtree - introduces necessary child nodes for a knowledge tree with full nodes and leaves
Merge two trees of the same concept
knowledge forest
Plant a large number of trees of knowledge, and we have a forest of knowledge!
A forest of knowledge is a large group of trees of knowledge planted together. An interesting fact about forests of knowledge is that there can be entanglement between trees. In theory, the connections between different nodes and leaves can be arbitrary (e.g. a link between a leaf of one tree and the root of another tree). In fact, if we add dotted links, the Knowledge Forest "sort of" becomes a Knowledge Graph. However, it is the personal knowledge tree that matters.
For example, dashed lines indicate links between MACI trees and zk-Snark trees.
The leaves of the knowledge tree connect to existing articles/videos/resources on the web. Therefore, the layers above these leaves are structural information or understanding layers.
What we can do with Knowledge Forest is completely open. Probably the most important thing we should consider is an ecosystem of collaborative knowledge bases from the start. We may want to do many things with the knowledge forest, here are three examples:
Visualizing Knowledge Tree and Knowledge Forest
Browse the Knowledge Forest via dotted links
Find knowledge tree clusters
Nonprofits can make things happen, but DAOs can make things better. The idea here is to map a set of tree operations to a set of stimuli. The more standardized the meta-operations are, the more scalable the DAO is for coordinating its members.
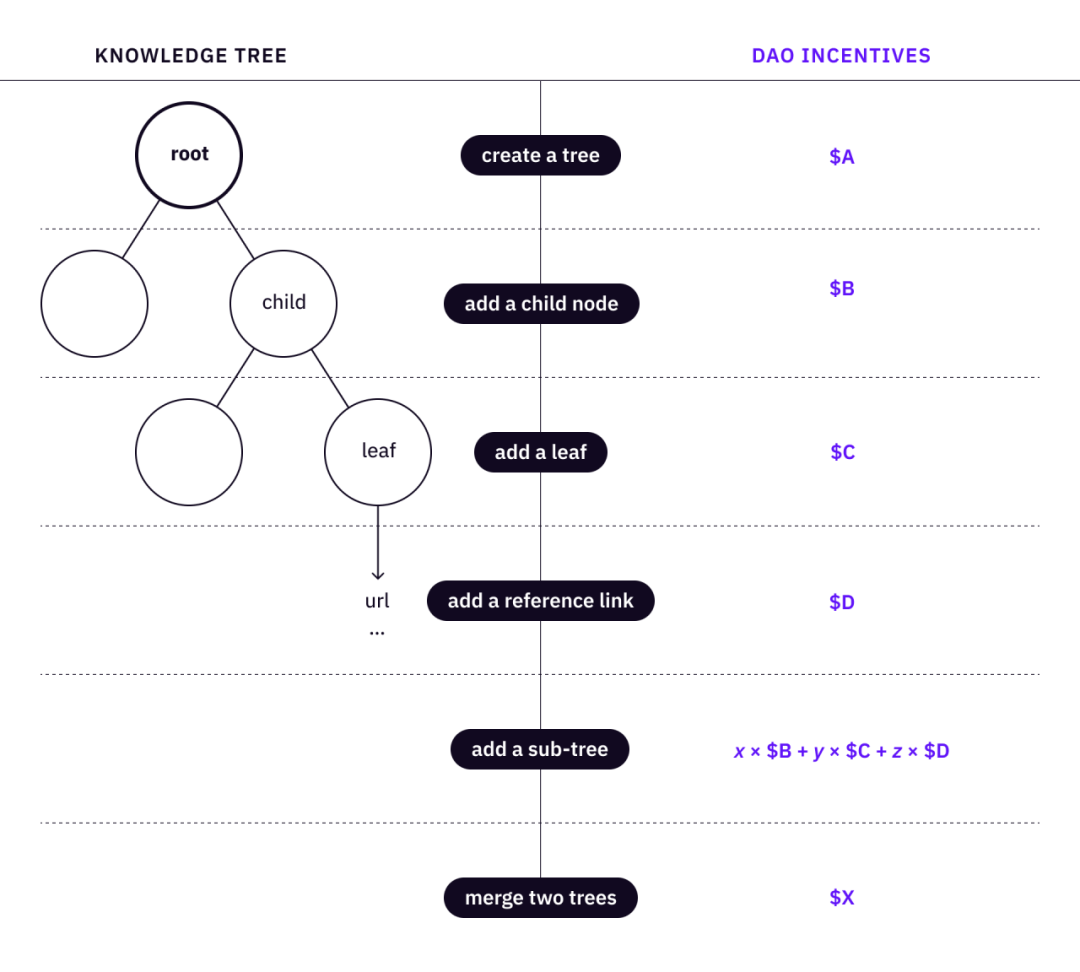
image description<->knowledge tree operation
DAO Contribution
In the case of a knowledge tree, a DAO contributor can create a root (equivalent to "create/plant a tree"), add a knowledge path ("plant a tree"), and add reference links to the leaves. The incentive mechanism creates a set of rules to reward community contributors who take verifiable actions to plan and grow the knowledge tree.
Also, review committees (or review groups) are important for planning and quality control. Coordination and incentives for DAOs have been extensively experimented with (e.g., DAOrayaki DAO), and a similar structure could be implemented here.
Knowledge Forest and Knowledge Graph
Trees are easier to understand when we learn new concepts and gain knowledge. For any particular topic, it is easy for humans to understand the knowledge structure in a tree because there are no loops in the tree, and if the depth of the tree is limited to a certain level, it is much easier for the human brain to process and memorize.
Furthermore, knowledge graph representations are limited in representing ambiguous or ambiguous connections between knowledge nodes (same issue as commonsense knowledge representation).
A team of BUIDLers working on the actual implementation of Knowledge Trees and Knowledge Forests has many details - data structures, product design, contribution and incentive details, UI, etc. Nevertheless, if a knowledge forest is to be built, I feel that in general it should be organized as a public good and made available to everyone in the world. But let's see what the Dora community comes up with!
in conclusion
The idea is to build a new kind of knowledge base on top of the existing web infrastructure (such as Wikipedia, etc.) and make it available to everyone, thereby minimizing the complexity of understanding abstract knowledge (via like Web Routing on knowledge graphs like Wikipedia or Wikipedia can be as complicated as O(nlog(n)), but a tree with n nodes is only log(n) deep, which makes navigation easier). Coordinate with contributors in the DAO and use advanced crypto-native incentives to ensure organizational sustainability. The ideas in this article are not complete, there is a lot of room for discussion and improvement, and there are a lot of engineering and product issues to consider if a team wants to make it a reality.
references
references
Semantic Web: https://en.wikipedia.org/wiki/Semantic_Web
Triple: https://conceptnet.io/
ConceptNet:https://conceptnet.io/
DBpedia:https://www.dbpedia.org/
Higher-order logic: https://en.wikipedia.org/wiki/Cyc
https://github.com/zhangjiannan/Graphpedia
Wikipedia graph visualization and search tools:
Cyc:https://en.wikipedia.org/wiki/Cyc
Multi-chain ecosystem: https://hackerlink.io/grant/dora-factory/top
LHC@Home:https://lhcathome.cern.ch/lhcathome/
SETI@Home:https://setiathome.berkeley.edu/
Citizen Cyberlab:https://www.citizencyberlab.org/projects/
SciStarter:https://scistarter.org/
Volunteer Computing: https://en.wikipedia.org/wiki/Volunteer_computing
Knowledge graph construction tool 1: https://obsidian.md/


