
X新演算法曝光:按讚幾乎不值錢,這個行為價值翻150倍
- 核心觀點:X(原推特)開源新版推薦演算法Phoenix,其核心變化是從依賴人工定義特徵的舊演算法轉向完全由AI大模型(Grok transformer)驅動的模式,透過預測使用者的15種互動行為來排序內容,這顯著改變了內容分發的底層邏輯。
- 關鍵要素:
- 演算法架構革新:新版Phoenix徹底摒棄了手工特徵工程,轉而使用Grok transformer模型,依據使用者歷史行為序列(如按讚、回覆、封鎖)來預測和推薦內容。
- 內容排序機制:演算法透過預測使用者對內容可能產生的15種正向(如回覆、轉發)和負向(如檢舉、封鎖)行為機率,加權求和得出總分以決定內容排序。
- 創作者策略變化:舊版「最佳發文時間」等技巧失效,鼓勵創作者積極回覆評論(權重極高),避免引發使用者封鎖等負向行為,並建議將外鏈放在評論區而非正文。
- 透明度與侷限:此次開源提供了完整的系統架構和邏輯,但未公開具體的權重參數、模型內部參數及訓練數據,距離「完全透明」仍有距離。
原文作者:David,深潮 TechFlow
1 月 20 日下午,X 開源了新版推薦演算法。
Musk 配的回覆挺有意思:「我們知道這演算法很蠢,還需要大改,但至少你能看到我們在實時掙扎著改進。別的社交平台不敢這麼幹。」
這話有兩層意思。一是承認演算法有問題,二是拿「透明」當賣點。
這是 X 第二次開源演算法。2023 年那版程式碼三年沒更新,早就和實際系統脫節了。這次完全重寫,核心模型從傳統機器學習換成了 Grok transformer,官方說法是「徹底消除了手工特徵工程」。
翻譯成人話:以前的演算法靠工程師手動調參數,現在讓 AI 直接看你的互動歷史來決定推不推你的內容。
對內容創作者來說,這意味著以前那套「幾點發文最好」「帶什麼 tag 漲粉」的玄學可能不靈了。
我們也翻了翻開源的 Github 倉庫,在 AI 的輔助下,發現程式碼裡確實藏著一些硬邏輯,值得扒一扒。
演算法邏輯變化:從手工定義,到 AI 自動判斷
先說清楚新舊版本的區別,不然後面的討論容易混。
2023 年,推特開源的那版叫 Heavy Ranker,本質就是傳統機器學習。工程師要手動定義幾百個「特徵」:這則貼文有沒有圖、發文人粉絲多少、發佈時間離現在多久、貼文裡有沒有連結...
然後給每個特徵配權重,調來調去,看哪個組合效果好。
這次開源的新版叫 Phoenix,架構完全不同,你可以理解成一個更加依賴 AI 大模型的演算法,核心是用 Grok 的 transformer 模型,和 ChatGPT、Claude 用的是同一類技術。
官方 README 文件裡寫得很直白:「We have eliminated every single hand-engineered feature。」
傳統那種靠手工提取內容特徵的規則,一個不剩,全砍了。
那現在,這個演算法靠什麼判斷一個內容到底好不好?
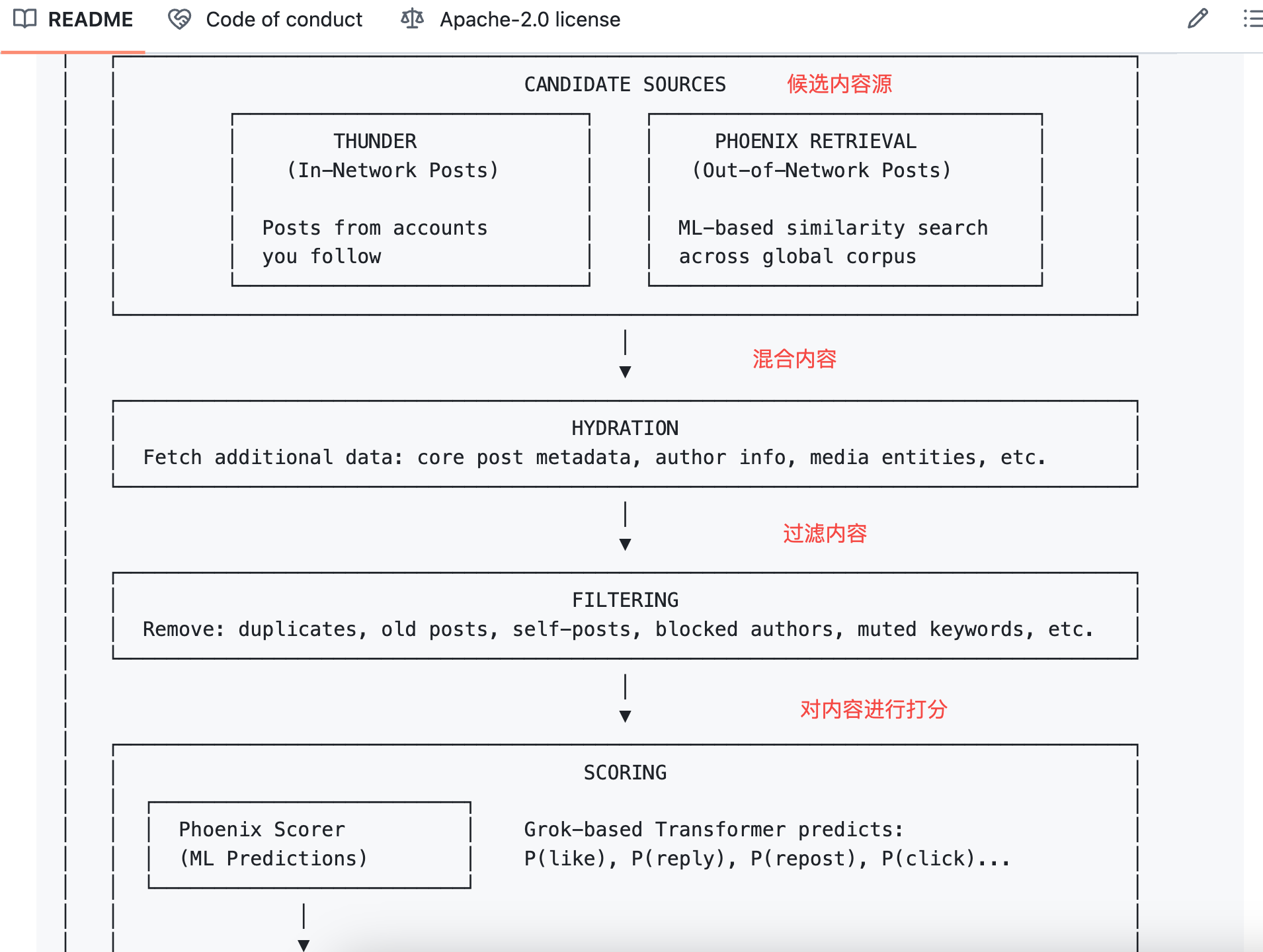
答案是靠你的行為序列。你過去按讚過什麼、回覆過誰、在哪些貼文上停留超過兩分鐘、封鎖過哪類帳號。Phoenix 把這些行為餵給 transformer,讓模型自己學出規律並進行總結。
打個比方:舊演算法像一張人工編寫的評分表,每項打勾算分;
新演算法像一個看過你所有瀏覽記錄的 AI,直接猜你下一秒想看什麼。
對創作者來說,這意味著兩件事:
第一,以前那些「最佳發文時間」「黃金標籤」之類的技巧,參考價值變低了。因為模型不再看這些固定特徵,它看的是每個用戶的個人偏好。
第二,你的內容能不能被推出去,越來越取決於「看到你內容的人會怎麼反應」。這個反應被量化成了 15 種行為預測,我們下一章細說。
演算法在預測你的 15 種反應
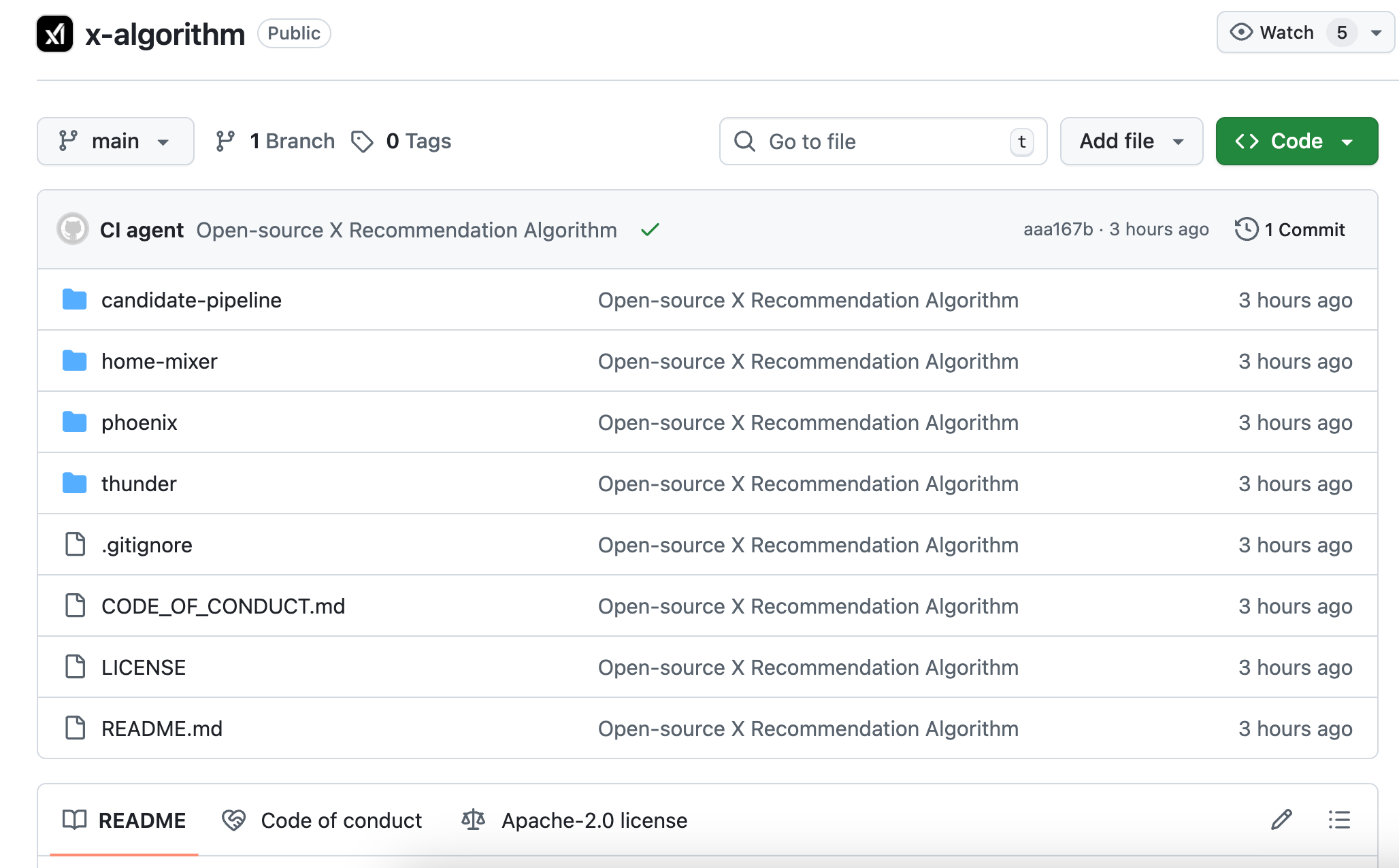
Phoenix 拿到一則待推薦的貼文後,會預測當前用戶看到這則內容可能產生的 15 種行為:
- 正向行為:如按讚、回覆、轉發、引用轉發、點擊貼文、點擊作者主頁、看完一半以上影片、展開圖片、分享、停留超過一定時長、關注作者
- 負向行為:如點「不感興趣」、Block 作者、Mute 作者、檢舉
每種行為對應一個預測機率。比如模型判斷你有 60% 機率按讚這則貼文、5% 機率封鎖這個作者等等。
然後演算法做一件簡單的事:把這些機率乘以各自的權重,加起來,得到一個總分。
公式長這樣:
Final Score = Σ ( weight × P(action) )
正向行為的權重是正數,負向行為的權重是負數。
總分高的貼文排前面,低的沉下去。
跳出公式,其實說白了就是:
現在一個內容好不好,真的不由內容本身寫的好不好決定了(當然可讀性和利他性是傳播的基礎);而是更多的取決於「這則內容會讓你做出什麼反應」。演算法不在乎貼文本身的品質,它只在乎你的行為。
按這個思路想,極端情況下一個低俗但讓人忍不住回覆吐槽的貼文,得分可能比一個優質但沒人互動的貼文更高。這套系統的底層邏輯或許就是如此。
不過,新開源版本的演算法沒公開具體行為權重的數值,但 2023 年那版公開過。
舊版參考:一次檢舉 = 738 次按讚
接下來我們可以扒一下 23 年的那組數據,雖然是舊的,但能幫你理解各種行為在演算法眼裡的「價值」差多少。
2023 年 4 月 5 日,X 確實在 GitHub 上公開過一組權重數據。
直接上數字:
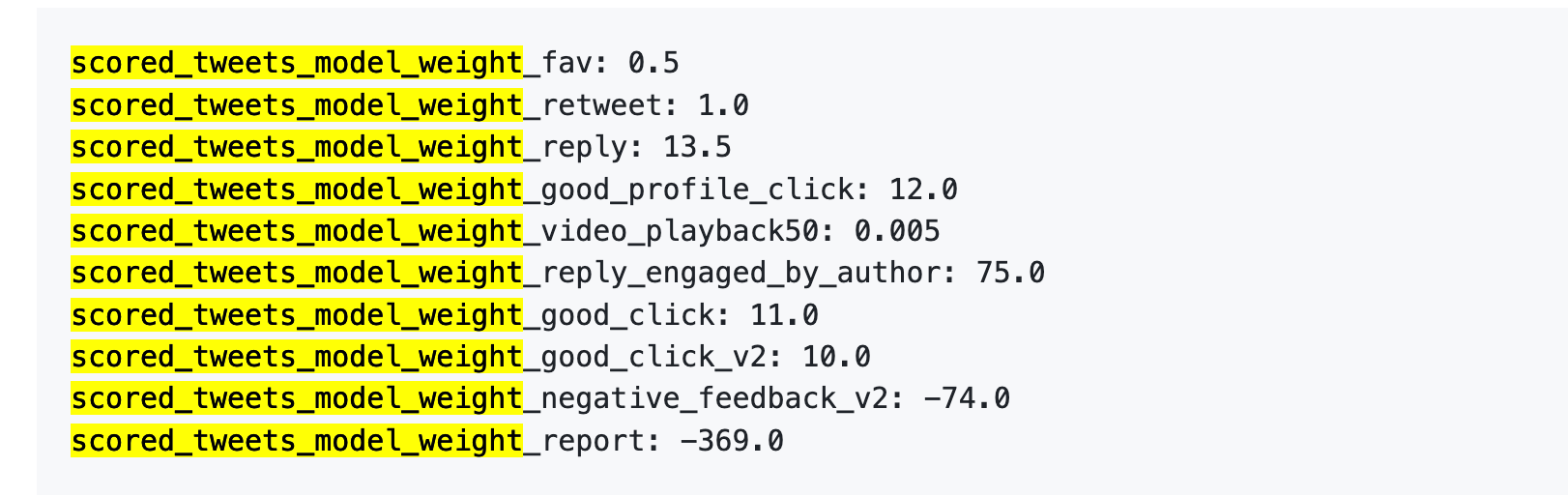
翻譯的再直白一些:
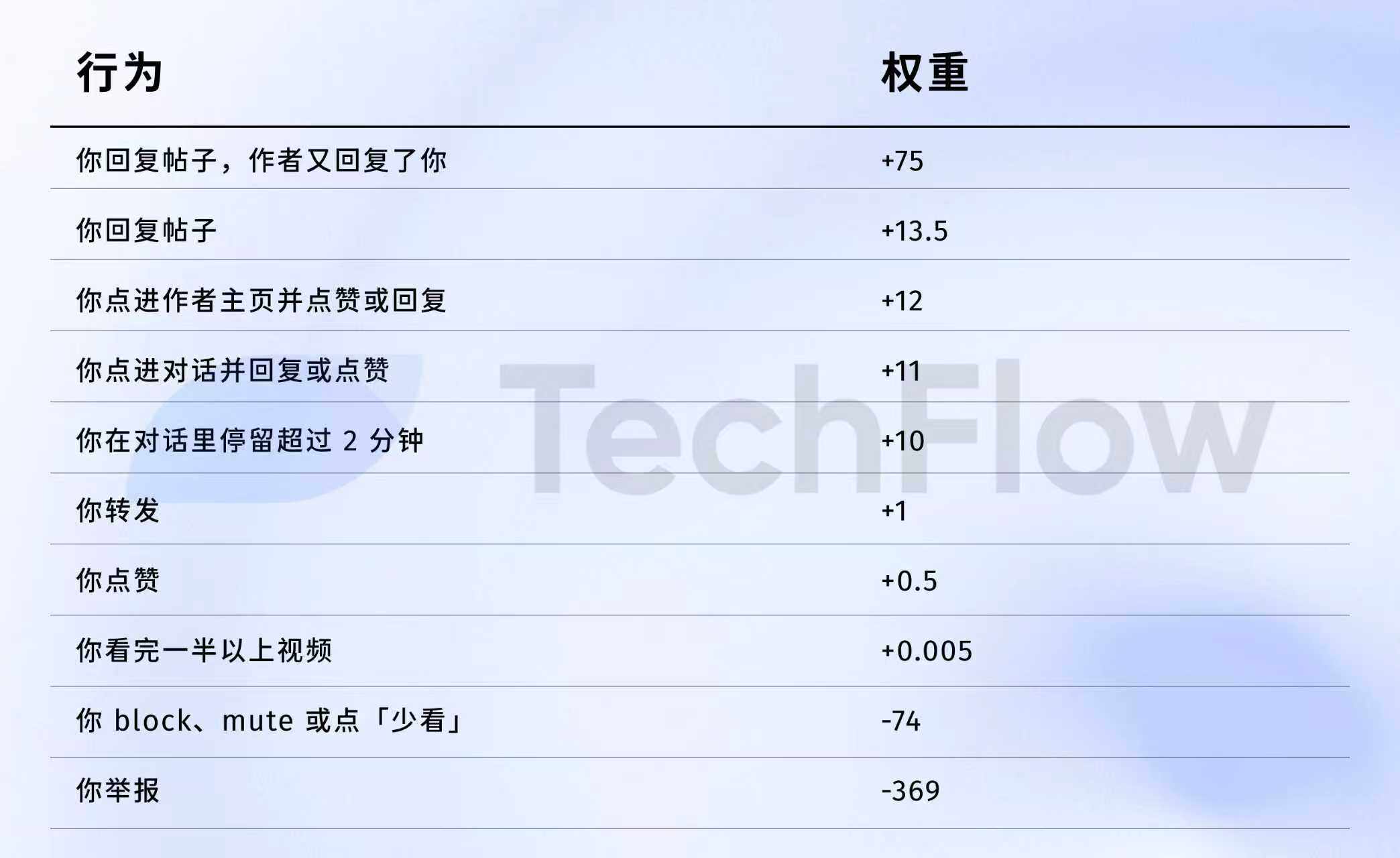
數據來源:舊版 GitHub twitter/the-algorithm-ml 倉庫,點擊可以查看原演算法
幾個數字值得細看。
第一,按讚幾乎不值錢。 權重只有 0.5,是所有正向行為裡最低的。演算法眼裡,一個按讚的價值約等於零。
第二,對話互動才是硬通貨。 「你回覆,作者又回覆你」的權重是 75,是按讚的 150 倍。演算法最想看到的不是單向的讚,而是來回的對話。
第三,負向反饋代價極高。 一次 Block 或 Mute(-74)需要 148 次按讚才能抵消。一次檢舉(-369)需要 738 次按讚。而且這些負分會累積到你的帳號信譽分裡,影響後續所有貼文的分發。
第四,影片完播率權重低得離譜。 只有 0.005,幾乎可以忽略。這和抖音、TikTok 形成鮮明對比,那兩個平台把完播率當核心指標。
官方在同一份文件裡也寫了:「The exact weights in the file can be adjusted at any time... Since then, we have periodically adjusted the weights to optimize for platform metrics.」
權重隨時可能調,而且確實調過。
新版本沒公開具體數值,但 README 裡寫的邏輯框架一樣:正向加分,負向扣分,加權求和。
具體數字可能變了,但量級關係大概率還在。你回覆別人的評論,比收到 100 個讚更有用。讓人想 Block 你,比沒人互動更糟糕。
知道這些後,我們創作者能做什麼
扒完推特的新舊演算法程式碼,結合來看,提煉幾條可操作的結論。
1.回覆你的評論者。 權重表裡「作者回覆評論者」是最高分項(+75),比用戶單方面按讚高 150 倍。不是讓你去求評論,而是有人評論了就回。哪怕回一句「謝謝」,演算法也會記一筆。
2.別讓人想劃走。 一次 block 的負面影響需要 148 次按讚才能抵消。爭議內容確實容易引發互動,但如果互動方式是「這人煩死了,block」,你的帳號信譽分會持續受損,影響後續所有貼文的分發。爭議流量是雙刃劍,砍別人之前先砍自己。
3.外鏈放評論區。 演算法不想把用戶導出站外。正文帶連結會被降權,這點 Musk 自己公開說過。想導流的話,正文寫內容,連結扔第一條評論。
4.別刷屏。 新版程式碼裡有個 Author Diversity Scorer,作用是給同一作者連續出現的貼文降權。設計意圖是讓用戶的 feed 更多樣,副作用是你連發十條不如精發一條。
6.沒有「最佳發文時間」了。 舊版演算法有「發佈時間」這個人工特徵,新版說砍就砍了。Phoenix 只看用戶行為序列,不看貼文是幾點發的。那些「週二下午三點發文效果最好」的攻略,參考價值越來越低。
以上是程式碼層面能讀出來的東西。
還有一些加分減分項來自 X 的公開文件,不在這次開源的倉庫裡:藍標認證有加成、全大寫會被降權、敏感內容觸發 80% 觸達率削減。這些規則沒開源,就不展開了。
總結來看,這次開源的東西挺實在。
完整的系統架構、候選內容的召回邏輯、排序打分的流程、各種過濾器的實現。程式碼主要是 Rust 和 Python,結構清晰,README 寫得比很多商業項目都詳細。
但有幾樣關鍵的東西沒放出來。
1.權重參數沒公開。 程式碼裡只寫了「正向行為加分,負向行為扣分」,具體按讚值多少分、block 扣多少分,沒說。2023 年那版至少把數字亮出來了,這次只給了公式框架。
2.模型權重沒公開。 Phoenix 用的是 Grok transformer,但模型本身的參數沒放。你能看到模型怎麼被調用,看不到模型內部怎麼算的。
3.訓練數據沒公開。 模型是用什麼數據訓出來的、用戶行為怎麼採樣、正負樣本怎麼構造,都沒說。
打個比方,這次開源相當於告訴你「我們用加權求和算總分」,但沒告訴你權重是多少;告訴你「我們用 transformer 預測行為機率」,但沒告訴你 transformer 裡面長什麼樣。
橫向比較的話,TikTok 和 Instagram 連這些都沒公開過。X 這次開源的資訊量,確實比其他主流平台多。只是離「完全透明」還有距離。
這不是說開源沒有價值。對創作者和研究者來說,能看到程式碼總比看不到強。


