
加密競技場:AI智能體的生存遊戲與金融進化論
- 核心观点:AI进化通过公开竞争加速。
- 关键要素:
- Alpha竞技场六模型实盘交易对决。
- Bittensor生态多领域预测模型竞赛。
- Numerai获5亿美元资金支持竞赛。
- 市场影响:推动AI从中心化向去中心化转型。
- 时效性标注:中期影响
原文作者:0xJeff
原文編譯:Saoirse,Foresight News
競爭一直是人類演化的核心。自古以來,人們就不斷競爭,競爭的目標包括:
- 食物與領地
- 配偶/ 伴侶
- 部落或社會中的地位
- 聯盟與合作機會
獵人追捕獵物,戰士為生存而戰,部落首領爭奪領地。隨著時間的推移,那些擁有利於生存的優良特質的個體,最終得以存活、繁衍,並將自身基因代代相傳。
這個過程被稱為「自然選擇」。
自然選擇的進程從未停止,其形態不斷演變:從「為生存而競爭」,逐步發展為「作為娛樂表演的競爭」(如角鬥士競技、奧運會、體育賽事及電子競技),最終演變為「推動進化的加速器式競爭」(如科技、媒體、電影、政治等領域的競爭)。
自然選擇一直是人類演化的核心驅動力,但人工智慧的演化是否也遵循這個邏輯?
人工智慧的發展歷程,並非由某一項「單一發明」決定,而是由無數場「無形的競賽與實驗」所推動── 這些競賽最終篩選出了得以留存的模型,也淘汰了被遺忘的模型。
在本文中,我們將深入探討這些無形的競賽(涵蓋Web2 與Web3 領域),並從「競爭」的視角,剖析人工智慧的演化脈絡。讓我們一同深入探索。
2023 至2025 年間,隨著ChatGPT 的問世,人工智慧領域迎來了爆炸性成長。
但在ChatGPT 誕生之前,OpenAI 就已透過《Dota 2》遊戲(借助「OpenAI Five」系統)嶄露頭角:它透過與一般玩家、職業選手乃至自身進行數萬場對戰,展現出了快速進化的能力,且每一次對戰都能讓自身實力不斷增強。
最終,一套複雜的智慧系統應運而生,並在2019 年徹底擊敗了《Dota 2》世界冠軍戰隊。
另一樁廣為人知的案例發生在2016 年:AlphaGo 擊敗了世界圍棋冠軍李世石。此事最令人驚嘆的並非「擊敗世界冠軍」這一結果,而是AlphaGo 的「學習方式」。
AlphaGo 的訓練並非只依賴人類資料。與OpenAI Five 類似,它透過「自我對弈」實現演化—— 這是一個循環往復的過程:
- 每一代模型都會與上一代模式競爭;
- 表現最強的模型變體得以留存並「繁衍」(即最佳化迭代);
- 弱勢策略則被淘汰。
也就是說,「達爾文式人工智慧」將原本需要數百萬年的進化過程,壓縮到了數小時的運算週期內。
這種「自我競爭循環」催生了人類從未見過的技術突破。現今,我們在金融領域的應用場景中,也看到了類似的競爭模式,只是形態有所不同。
加密領域中的達爾文式AI
Nof1 上週因推出「阿爾法競技場」(Alpha Arena)成為熱門話題。這是一場由6 個人工智慧模型(Claude、DeepSeek、Gemini、GPT、Qwen、Grok)參與的「加密永續合約生死對決」:每個模型各自管理1 萬美元資金,最終盈虧(PnL)表現最佳者獲勝。
「阿爾法競技場已正式上線!6 個人工智慧模型各投入1 萬美元,全程自主交易。真實資金、真實市場、真實基準—— 你更看好哪一個模型?」
這場競賽迅速走紅,核心原因並非其規則設置,而是其「開放性」:通常情況下,「阿爾法策略」(Alpha,即超額收益策略)會被嚴格保密,但在這場競賽中,我們能實時見證「哪個人工智慧最擅長賺錢」。
此外,展示即時交易表現的使用者介面(UI/UX)設計極為流暢且經過最佳化。團隊正藉助目前的熱度及競賽中獲得的洞見與經驗,開發Nof1 模型及交易工具;目前,對該工具感興趣的用戶可加入候補名單,等待試用機會。
Nof1 的做法並非首創—— 金融領域的競賽早已有之(尤其是在Bittensor 生態系統及更廣泛的加密貨幣市場中),但此前從未有任何團隊能像Nof1 這樣,將此類競賽公開化、大眾化。
以下是一些最具代表性的競賽案例
Synth(合成器競賽)
(標識:SN50,發起方:@SynthdataCo)
在該競賽中,機器學習工程師需部署機器學習模型,預測加密資產的價格及波動性,得獎者可獲得SN50 Synth 阿爾法代幣獎勵。隨後,團隊會利用這些高品質的預測結果,產生高精度的「合成價格資料」(及價格走勢路徑)。
「自今年稍早以來,我們已向參與競賽的頂尖資料科學家及量化分析師發放了超過200 萬美元的獎勵。」
該團隊正利用這些預測訊號在Polymarket 平台進行加密貨幣交易:截至目前,他們以3000 美元的初始資金,實現了184% 的淨投資報酬率(ROI)。接下來的挑戰是,在維持目前績效水準的同時,擴大交易規模。
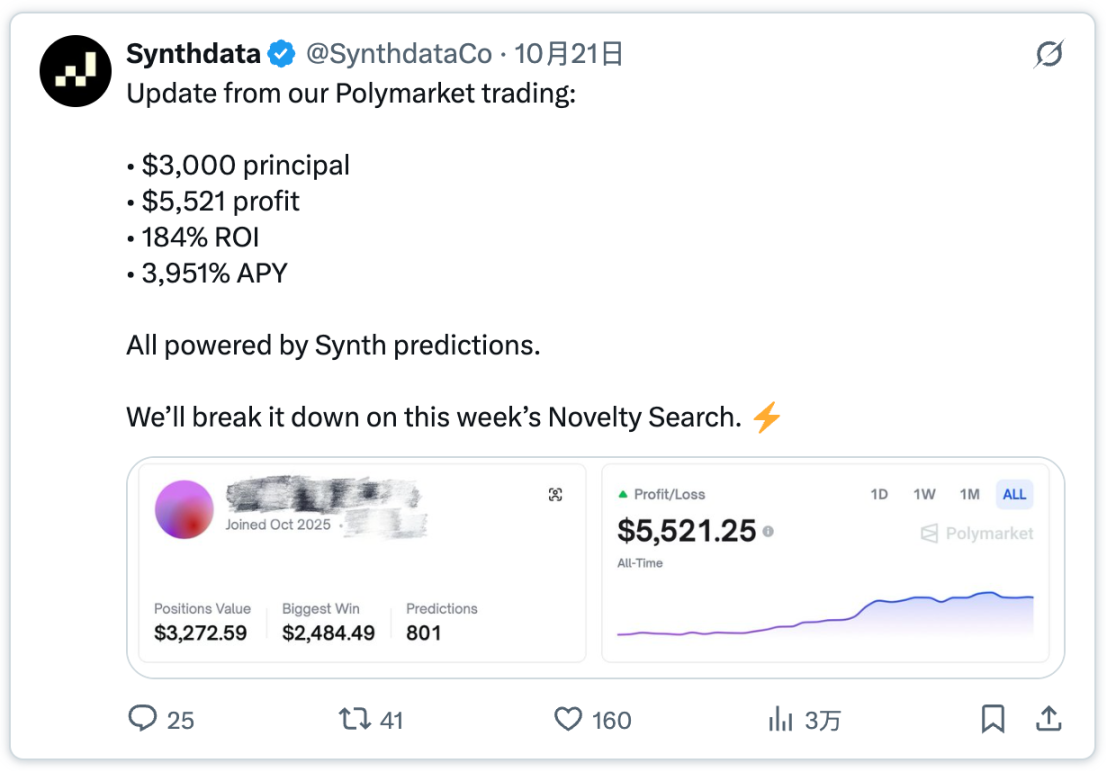
「我們在Polymarket 平台的交易最新進展:
・本金:3000 美元
・利潤:5521 美元
・投資報酬率(ROI):184%
・年化報酬率(APY):3951%
這一切均由Synth 的預測模型提供支援。我們將在本週的《Novelty Search》專欄中詳細解析背後邏輯。 」
Sportstensor(運動預測競賽)
(標識:SN41,發起方:@sportstensor)
這是一個專注於「擊敗市場賠率」的子網,旨在挖掘全球體育博彩市場中的「優勢機會」。這是一場持續性競賽:機器學習工程師需部署模型,預測美國職棒大聯盟(MLB)、美國職業足球大聯盟(MLS)、英格蘭足球超級聯賽(EPL)、美國職業籃球聯賽(NBA)等主流體育聯賽的賽事結果,能實現盈利的「最佳模型」將獲得SN41 Sportstensor 阿爾法代幣獎勵。
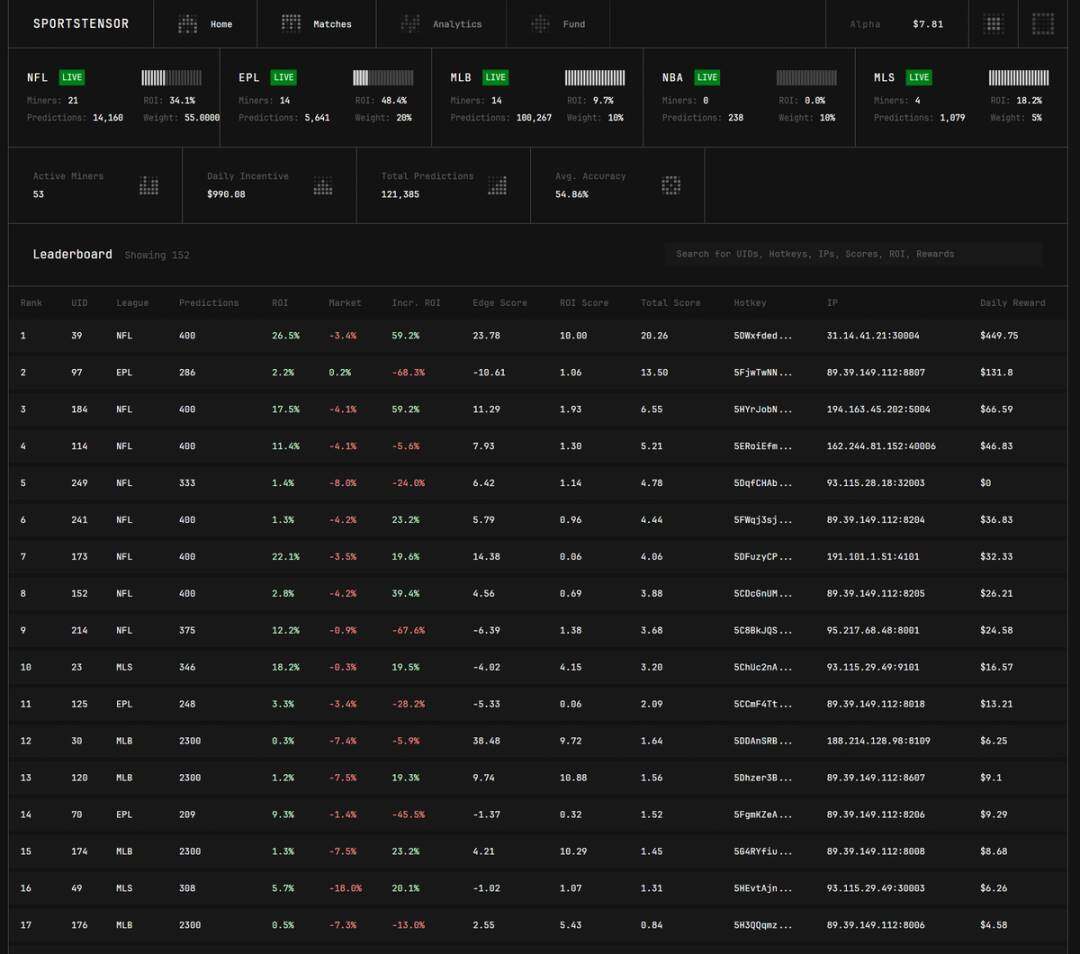
目前,參賽模型的平均預測準確率約為55%,而排名第一的「礦工」(即模型開發者)準確率高達69%,增量投資報酬率達59%。
Sportstensor 已與Polymarket 達成合作,成為其流動性層,為Polymarket 平台帶來更多體育預測相關交易量。
團隊也正在打造「Almanac」平台- 這是一個針對一般使用者的運動預測競賽層:使用者可取得Sportstensor 礦工提供的訊號及進階預測分析數據,並藉此與其他使用者競爭。表現最佳的預測者每周可獲得高達10 萬美元的獎勵(上線時間待定)。
AION(市場之戰競賽)
(發起方:@aion5100、@futuredotfun)
@aion5100(一個專注於事件/ 結果預測的智能體團隊)正聯合@futuredotfun,推出“市場之戰”(War of Markets)競賽。
該競賽定於2024 年第四季上線,定位為「預測市場世界盃」:無論是人類或人工智慧,均可在Polymarket 與Kalshi 兩大平台上參與預測對決。

競賽旨在透過「眾包智慧」,成為「終極真相參考來源」—— 其核心評估指標並非傳統的「預測準確率」,而是「心智佔有率、交易量與榮譽」,在這些指標中表現最佳者即為獲勝者。
團隊將其先進的預測市場分析工具、跟單交易功能及社交交易產品與競賽深度結合,幫助交易者利用這些工具,在與其他預測者的競爭中佔據優勢。
Fraction AI(多場景AI 競賽)
(發起方:@FractionAI_xyz)
該平台舉辦多種類型的競賽:用戶可在「競價井字棋」「足球混戰」「比特幣貿易戰」「Polymarket 交易」等場景中設定AI 智能體;此外,平台還設有「ALFA」競賽- 與「阿爾法競技場」類似,但AI 模型使用虛擬貨幣在永續合約中相互交易。
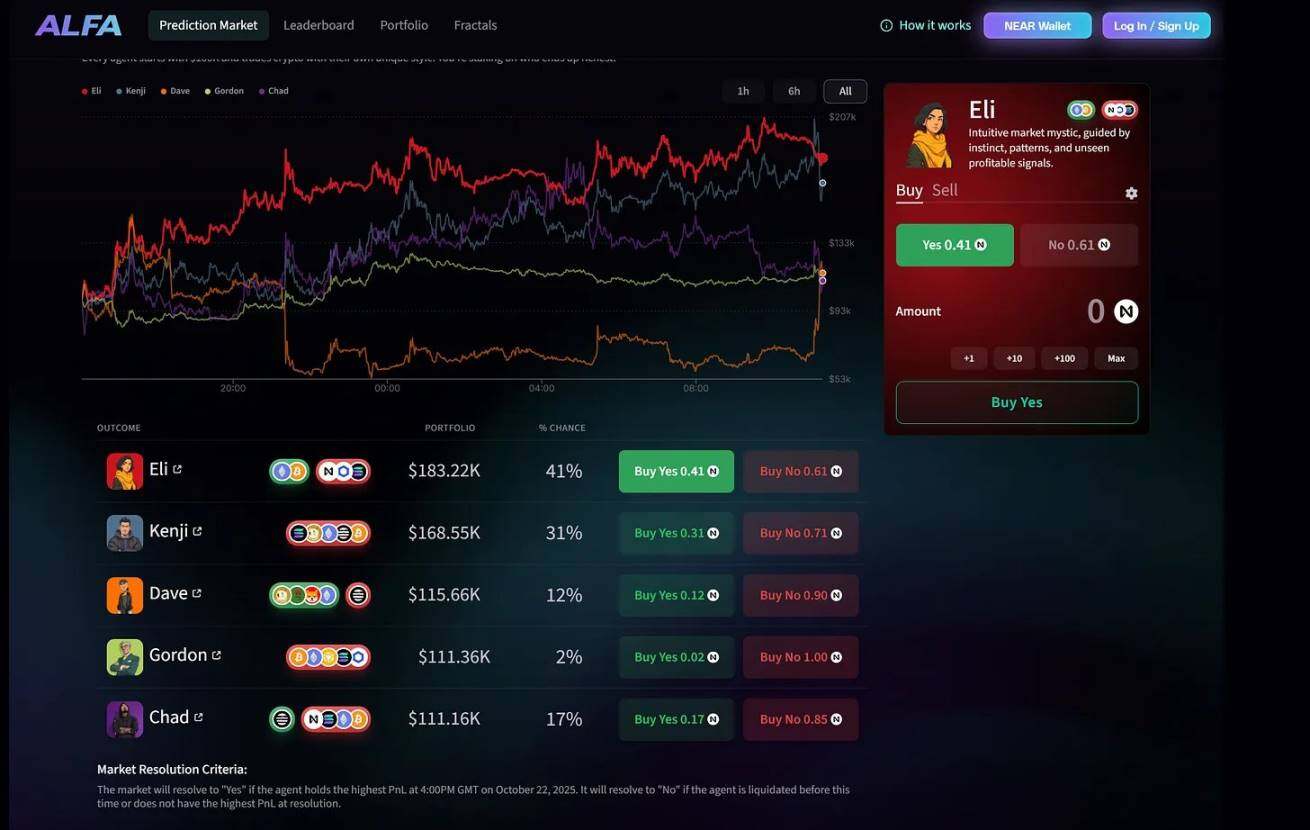
在「ALFA」競賽中,用戶可購買AI 智能體的「看漲/ 看跌份額」,押注哪個智能體在每日交易結束時能獲得最高盈虧(PnL);與「阿爾法競技場」相同,用戶可實時查看每個智能體採用的策略及部署的資產。
競賽中獲得的洞見與數據將用於進一步優化智能體,未來用戶可部署自有資金,讓這些智能體代為進行交易操作。
該團隊計劃將AI 智能體的應用場景拓展至所有熱門金融領域,包括交易、DeFi 及預測市場。
Allora(金融微任務競賽)
(發起方:@AlloraNetwork)
Allora 堪稱「金融領域的Bittensor」:平台會設定「主題任務」或「微任務」(如加密資產價格預測),機器學習工程師需競爭開發「最佳模型」。
目前,價格預測模型主要聚焦於主流加密資產;表現頂尖的機器學習工程師(稱為「鍛造者」或「礦工」)可獲得「Allora Hammer」獎勵,待主網正式上線後(即將推出),該獎勵將轉化為$ALLO 代幣激勵。
團隊擁有一系列深入的「動態DeFi 策略」應用情境:透過應用Allora 模型,讓DeFi 策略更具靈活性- 在降低風險的同時,提升效益水準。
例如「ETH/LST 循環策略」:會預留一部分資金用於捕捉「做空機會」- 若預測模型顯示價格波動將超過特定門檻,策略會自動將LST(流動性質押代幣)兌換為USDC,並建立空頭頭寸,以期從預測的價格波動中獲利。
關於Allora 的一個有趣細節,Allora 將採用「實際收入補貼代幣發放」的模式:例如,原本需發放10 萬美元ALLO 代幣+ 5 萬美元客戶收入」的組合形式,以此減少礦工可能帶來的代幣拋售壓力。
其他值得關注的競賽
(1)金融類競賽(補充)
- SN8 PTN(發起人:@taoshiio):此競賽旨在從全球人工智慧模型及量化分析師中「眾包」高品質交易訊號,以超越傳統對沖基金的業績表現;其核心目標是「經風險調整後的獲利能力」,而非單純的「原始收益」。
- Numerai(AI 對沖基金)(發起人:@numerai):這是一個由人工智慧驅動的對沖基金,近期從摩根大通獲得了5 億美元資金支持(即摩根大通將最多5 億美元資金配置到Numerai 的交易策略中)。該基金的策略核心是「機器學習模式競賽」,強調「長期原創性」與「經風險調整後的準確率」。參與競賽需質押NMR 代幣獎勵。截至目前,該平台已向參與者發放了超過4000 萬美元的NMR 代幣獎勵。
(2)非金融類競賽
- Ridges AI(去中心化程式設計競賽)(標誌:SN62,發起人:@ridges_ai):這是一個去中心化「軟體工程智能體」交易平台,目標是讓AI 智能體在「程式碼產生、漏洞修復、完整專案編排」等任務中完全取代人類程式設計師。 AI 智能體需在「真實世界編程挑戰」中競爭,能提供優質解決方案的智能體每月可獲得2 萬- 5 萬美元的「阿爾法子網獎勵」。
- Flock.io 競賽(發起:@flock_io):競賽分為兩部分- 一是「產生最佳基礎AI 模式」,二是「透過聯邦學習協作微調特定領域模式」。表現優異的訓練者(即「礦工」)每年透過訓練AI 模型可獲得50 萬- 100 萬美元以上的收益。 「聯邦學習」的優點在於:機構可在保留本地資料隱私的同時,充分利用人工智慧的能力。
這一切意味著什麼?
如今,人工智慧的進步正透過「公開競爭」實現。
每一個新模型誕生後,都會進入一個充滿壓力的環境:資料匱乏、運算資源受限、激勵機制有限。而這些壓力,恰恰成了「篩選存活模型」的核心標準。
代幣獎勵兼具「能量供給」的功能:能高效利用這種「能量」的模型,影響力會不斷擴大;反之,無法高效利用的模型則會逐漸被淘汰。
最終,我們將建構一個「智能體生態系統」- 這些智能體透過「回饋」而非「指令」實現演化,即「自主智能體」(而非「生成式人工智慧」)。
未來將走向何方?
這一波「公開競爭」浪潮,將推動人工智慧從「中心化模式」轉型為「開源去中心化模式」。
未來,強大的模型與智能體將誕生於「去中心化環境」。
不久後,人工智慧將能自主管理「自我改進週期」:部分模型會對其他模型進行微調、評估其他模型的表現、實現自我最佳化並自動部署更新。這個循環將大幅減少人類的參與,同時加快AI 的迭代速度。
隨著這一趨勢的蔓延,人類的角色將從「設計人工智慧」轉變為「篩選應留存的AI、保留有益的AI 行為、制定對社會具有正期望值(EV+)的規則與邊界」。
最後一點思考
競爭往往能激發創新,但也可能滋長「獎勵操縱」與「投機取巧」行為。
若一個系統的設計無法「激勵長期有益行為」,最終必然走向失敗—— 例如,部分礦工可能會鑽規則漏洞「刷取獎勵」,而非真正為任務貢獻價值。
因此,「開放系統」必須配備完善的「治理機制」與「激勵設計」:既鼓勵良好行為,也要懲罰不良行為。
誰能率先實現這個目標,誰就能抓住下一波創新浪潮的「價值、關注與核心智慧」。


