
IOSG Ventures:GPU供應危機,新創AI企業破局之路
原文作者:Mohit Pandit, IOSG Ventures

摘要
GPU 短缺是現實,供需緊張,但未充分利用的GPU 數量可以滿足當今供應稀缺的需求。
需要一個激勵層來促進雲端運算的參與,然後最終協調用於推理或訓練的運算任務。 DePIN 車型正好適合此用途。
因為供應方的激勵,因為計算成本較低,需求方發現這很吸引人。
並非一切都是美好的,選擇Web3雲時必須做出某些權衡:例如延遲。相對於傳統的GPU 雲,面臨的權衡還包括保險、服務等級協定(Service Level Agreements) 等。
DePIN 模型有潛力解決GPU 可用性問題,但分散化模型不會讓情況變得更好。對於需求呈指數級增長的情況,碎片化供應和沒有供應一樣。
考慮到新市場參與者的數量,市場聚合是不可避免的。
引言
我們正處於機器學習和人工智能的新時代邊緣。雖然AI 已經以各種形式存在一段時間(AI 是被告知執行人類可以做的事情的電腦設備,如洗衣機),但我們現在見證了複雜認知模型的出現,這些模型能夠執行需要智慧人類行為的任務。顯著的例子包括OpenAI 的GPT-4 和DALL-E 2 ,以及Google的Gemini。
在快速成長的人工智能(AI)領域,我們必須認識到發展的雙重面向:模型訓練和推理。推理包括AI 模型的功能和輸出,而訓練包括建立智慧模型所需的複雜過程(包括機器學習演算法、資料集和計算能力)。
以GPT-4 為例,最終使用者關心的只是推理:基於文字輸入從模型取得輸出。然而,這種推理的品質取決於模型訓練。為了訓練有效的AI 模型,開發者需要獲得全面的基礎資料集和龐大的運算能力。這些資源主要集中在包括OpenAI、Google、微軟和AWS 在內的產業巨頭。
公式很簡單:更好的模型訓練>> 導致AI 模型的推理能力增強>> 從而吸引更多用戶>> 帶來更多收入,用於進一步訓練的資源也隨之增加。
這些主要玩家能夠存取大型基礎資料集,更關鍵的是控制大量運算能力,為新興開發者創造了進入障礙。因此,新進入者經常難以以經濟可行的規模和成本獲得足夠的數據或利用必要的計算能力。考慮到這種情況,我們看到互聯網在民主化資源取得方面具有很大價值,主要是與大規模獲取運算資源以及降低成本有關。
GPU 供應問題
NVIDIA 的CEO Jensen Huang 在2019 年CES 上說「摩爾定律已經結束」。現今的GPU 極度未充分利用。即使在深度學習/訓練週期中,GPU 也沒有被充分利用。
以下是不同工作負載的典型GPU 使用率數字:
空閒(剛啟動進入Windows 操作系統): 0-2%
一般生產任務(寫作、簡單瀏覽): 0-15%
影片播放: 15 - 35%
PC 遊戲: 25 - 95%
圖形設計/照片編輯主動工作負載(Photoshop、Illustrator): 15 - 55%
影片編輯(主動): 15 - 55%
影片編輯(渲染): 33 - 100%
3D渲染(CUDA / OptiX): 33 - 100% (常被Win 工作管理員錯誤回報- 使用GPU-Z)
大多數有GPU 的消費性設備屬於前三類。
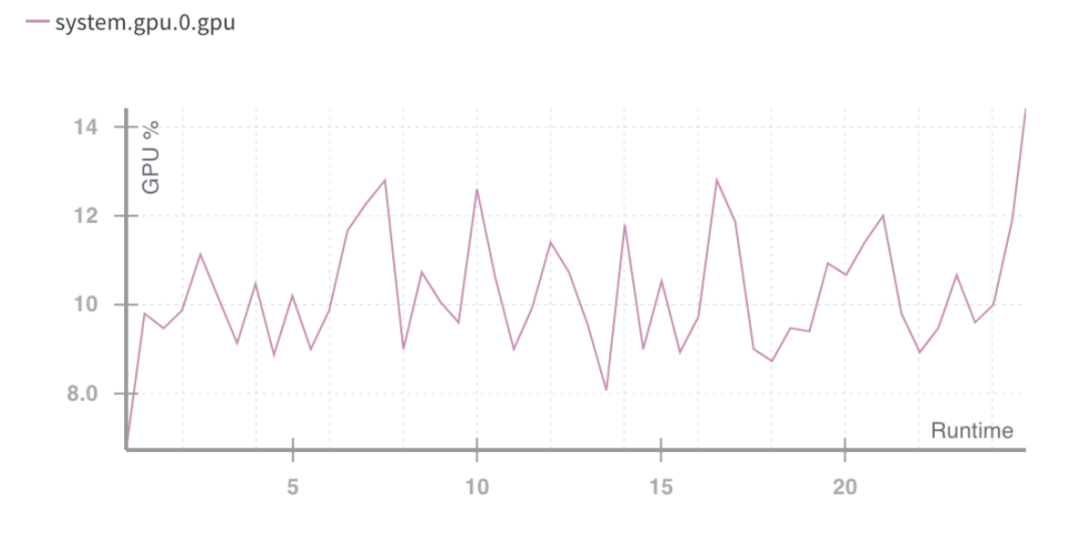
GPU 運轉時利用率%。 Source: Weights and Biases
上述情況指向一個問題:運算資源利用不良。
需要更好地利用消費者GPU 的容量,即使在GPU 使用率出現高峰時,也是次優的。這明確了未來要進行的兩件事:
資源(GPU)聚合
訓練任務的平行化
可以使用的硬件類型方面,現在有4 種類型用於供應:
· 資料中心GPU(例如,Nvidia A 100 s)
· 消費者GPU(例如,Nvidia RTX 3060)
· 客製化ASIC(例如,Coreweave IPU)
· 消費者SoCs(例如,蘋果M 2)
除了ASIC(因為它們是為特定目的而構建的),其他硬件可以被匯集以最有效地利用。隨著許多這樣的晶片掌握在消費者和資料中心手中,聚合供應方的DePIN 模型可能是可行的道路。
GPU 生產是一個量體金字塔;消費級GPU 產量最高,而像NVIDIA A 100 s 和H 100 s 這樣的高階GPU 產量最低(但效能較高)。生產這些高階晶片的成本是消費者GPU 的15 倍,但有時並不提供15 倍的效能。
整個雲端運算市場今天價值約4,830 億美元,預計未來幾年將以約27% 的複合年增長率成長。到2023 年,將有大約130 億小時的ML 運算需求,以目前標準費率,這相當於2023 年ML 計算的約560 億美元支出。這整個市場也在快速成長,每3 個月成長2 倍。
GPU 需求
計算需求主要來自AI 開發者(研究人員和工程師)。他們的主要需求是:價格(低成本運算)、規模(大量GPU 運算)和用戶體驗(易於存取和使用)。在過去兩年中,由於對基於AI 的應用程式的需求增加以及ML 模型的發展,GPU 需求量巨大。開發和運行ML 模型需要:
大量運算(來自存取多個GPU 或資料中心)
能夠執行模型訓練、微調( fine tuning) 以及推理,每個任務都部署在大量GPU 上並行執行
計算相關硬體支出預計將從2021 年的170 億美元成長到2025 年的2,850 億美元(約102% 的複合年增長率),ARK 預計到2030 年計算相關硬件支出將達到1.7 兆美元(43 %的複合年增長率)。
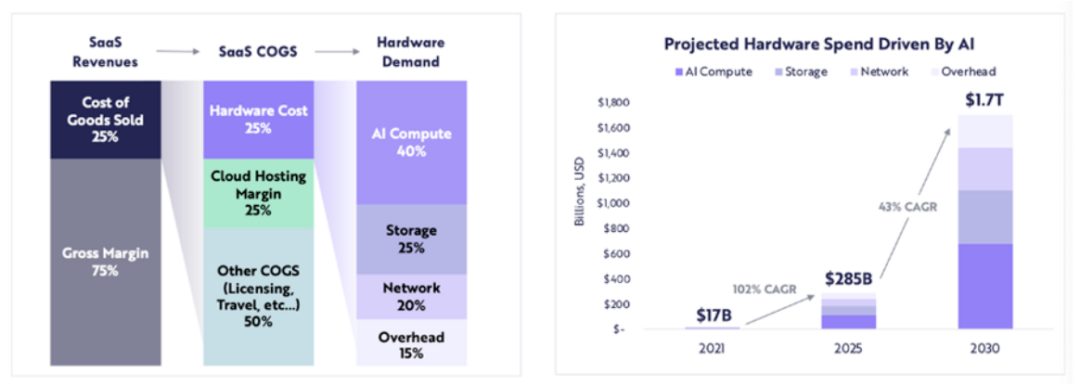
ARK Research
隨著大量LLM 處於創新階段,競爭驅動對更多參數的計算需求,以及重新訓練,我們可以預期在未來幾年內對高品質運算的持續需求。
隨著新的GPU 供應緊縮,區塊鏈在哪裡發揮作用?
當使用資源不足的時候,DePIN 模型就會提供出其幫助:
啟動供應方,創建大量供應
協調和完成任務
確保任務正確完成
為完成工作的提供者正確獎勵
聚合任何類型的GPU(消費者、企業、高效能等)可能會在利用方面出現問題。當計算任務被分割時,A 100 晶片不應該執行簡單的計算。 GPU 網絡需要決定他們認為應該包含在網絡中的GPU 類型,根據他們的市場進入策略。
當計算資源本身分散(有時是全球性的)時,需要由使用者或協定本身做出選擇,決定將使用哪種類型的計算框架。提供者像io.net 允許使用者從3 個運算框架中選擇:Ray、Mega-Ray 或部署Kubernetes 群集在容器中執行運算任務。還有更多分散式運算框架,如Apache Spark,但Ray 是最常使用的。一旦所選GPU 完成了運算任務,將重構輸出以給出訓練有素的模型。
一個設計良好的代幣模型將為GPU 提供者補貼運算成本,許多開發者(需求方)會發現這樣的方案更具吸引力。分散式計算系統本質上具有延遲。存在計算分解和輸出重構。所以開發者需要在訓練模型的成本效益和所需時間之間做出權衡。
分散式運算系統需要有自己的鏈嗎?
網絡有兩種運作方式:
按任務(或計算週期)收費或按時間收費
按時間單位收費
第一種方法,可以建立一個類似於Gensyn 所嘗試的工作證明鏈,其中不同GPU 分擔「工作」並因此獲得獎勵。為了更無信任的模型,他們有驗證者和告密者的概念,他們因保持系統的完整性而獲得獎勵,這是基於解算者生成的證明。
另一個工作證明系統是Exabits,它不是任務分割,而是將其整個GPU 網絡視為單一超級電腦。這種模型似乎更適合大型LLM。
Akash Network 增加了GPU 支持,並開始聚合GPU 進入這一領域。他們有一個底層L1來就狀態(顯示GPU 提供者完成的工作)達成共識,一個市場層,以及容器編排系統,如Kubernetes 或Docker Swarm 來管理用戶應用程式的部署和擴展。
一個系統如果要是無信任,工作證明鏈模型將最有效。這確保了協議的協調和完整性。
另一方面,像io.net 這樣的系統並沒有將自己建構成一個鏈。他們選擇解決GPU 可用性的核心問題,並按時間單位(每小時)向客戶收費。他們不需要可驗證性層,因為他們本質上是「租用」GPU,在特定租賃期內隨意使用。協定本身沒有任務分割,而是由開發者使用像Ray、Mega-Ray 或Kubernetes 這樣的開源框架來完成。
Web2與Web3 GPU 雲
Web2在GPU 雲或GPU 即服務領域有許多參與者。這一領域的主要玩家包括AWS、CoreWeave、PaperSpace、Jarvis Labs、Lambda Labs、Google雲端、微軟Azure 和OVH 雲端。
這是一個傳統的雲端商業模型,客戶需要在計算時可以按時間單位(通常是一小時)租用GPU(或多個GPU)。有許多不同的解決方案適用於不同的用例。
Web2和Web3 GPU 雲之間的主要差異在於以下幾個參數:
1. 雲端設定成本
由於代幣激勵,建立GPU 雲的成本顯著降低。 OpenAI 正在籌集1 兆美元用於計算晶片的生產。看來在沒有代幣誘因的情況下,打敗市場領導者需要至少1 兆美元。
2. 計算時間
非Web3 GPU 雲將會更快,因為已租用的GPU 叢集位於地理區域內,而Web3模型可能有一個更廣泛分佈的系統,延遲可能來自於低效的問題分割、負載平衡,最重要的是頻寬。
3. 計算成本
由於代幣激勵,Web3計算的成本將顯著低於現有的Web2模型。
計算成本對比:
當有更多供應和利用叢集提供這些GPU 時,這些數字可能會發生變化。 Gensyn 聲稱以低至每小時0.55 美元的價格提供A 100 s(及其等價物),Exabits 承諾類似的成本節省結構。
4. 合規性
在無授權系統中,合規性並不容易。然而,像io.net、Gensyn 等Web3系統並不會將自己定位為無許可系統。在GPU 上線、資料載入、資料共享和結果共享階段處理了GDPR 和HIPAA 等合規性問題。
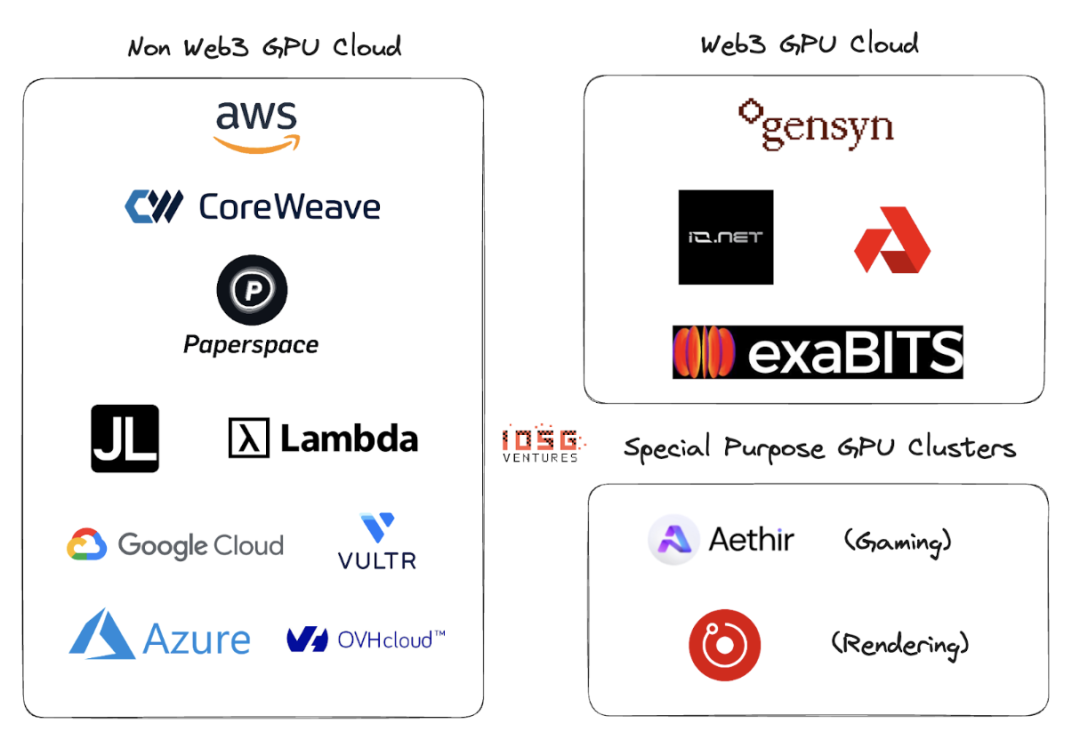
生態系統
Gensyn、io.net、Exabits、Akash
風險
1. 需求風險
我認為頂級LLM 玩家要么會繼續累積GPU,要么會使用像NVIDIA 的Selene 超級電腦這樣的GPU 集群,後者的峰值性能為2.8 exaFLOP/s。他們不會依賴消費者或長尾雲供應商匯集GPU。目前,頂級AI 組織在品質上的競爭大於成本。
對於非重型ML 模型,他們將尋求更便宜的運算資源,像基於區塊鏈的代幣激勵GPU 叢集可以在優化現有GPU 的同時提供服務(以上是假設:那些組織更喜歡訓練自己的模型,而不是使用LLM)
2. 供應風險
隨著大量資本投入ASIC 研究,以及像張量處理單元(TPU)這樣的發明,這個GPU 供應問題可能會自行消失。如果這些ASIC 可以提供良好的效能:成本權衡,那麼大型AI 組織囤積的現有GPU 可能會重新回歸市場。
基於區塊鏈的GPU 叢集是否解決了一個長期問題?雖然區塊鏈可以支援GPU 以外的任何晶片,但需求方的所作所為將完全決定這一領域內項目的發展方向。
結論
擁有小型GPU 叢集的碎片化網路不會解決問題。沒有「長尾」GPU 群集的位置。 GPU 供應商(零售或較小的雲端玩家)將傾向於更大的網絡,因為網路的激勵更好。會是良好代幣模型的功能,也是供應方支援多種計算類型的能力。
GPU 叢集可能會像CDN 一樣看到類似的聚合命運。如果大型玩家要與AWS 等現有領導者競爭,他們可能會開始共享資源,以減少網路延遲和節點的地理接近性。
如果需求方成長得更大(需要訓練的模型更多,需要訓練的參數數量也更多),Web3玩家必須在供應方業務發展方面非常積極。如果有太多的集群從相同的客戶群中競爭,將會出現碎片化的供應(這使整個概念無效),而需求(以TFLOPs 計)呈指數級增長。
Io.net 已經從眾多競爭者中脫穎而出,以聚合器模型起步。他們已經聚合了Render Network 和Filecoin 礦工的GPU,提供容量,同時也在自己的平台上引導供應。這可能是DePIN GPU 叢集的贏家方向。


