
AI大模型並非越大越好?全面解析模型“瘦身”技術方案
ChatGPT 帶動了全球大模型熱潮,互聯網公司陷入“百模大戰”,甚至出現了“內捲”:各家公司發布的大模型一個比一個大,參數規模成了宣傳噱頭,幾乎都在百億、千億甚至萬億以上。
然而,也有人提出這種現狀並非可持續的發展方式。 OpenAI 創始人Sam Altman 稱GPT-4 的開發成本突破了一億美元,Analytics India Magazine 發布的報告顯示, OpenAI 每天將花費約70 萬美元來運行其人工智能服務ChatGPT。同時,LLM 也會引起人們對電力消耗的擔憂,谷歌報告稱,培訓PaLM 在大約兩個月內耗費了大約3.4 千瓦時,相當於大約300 個美國家庭每年的能源消耗量。
因此,隨著模型規模的不斷增大,HuggingFace 首席佈道師Julien Simon 卻說“Smaller is better”。事實上,在參數規模達到一定程度後,再增加參數往往對模型效果的提升並不明顯,從實用性和經濟性來考慮,模型“瘦身”是一項必然的選擇,因為相對於龐大的參數規模所帶來的遞減邊際效益,巨大的資源消耗成本往往不值得。而且,大模型因規模太大將在應用上產生諸多問題,比如無法部署在邊緣設備上,只能以雲的形式向用戶提供服務,然而很多時候,我們需要將模型部署在邊緣節點,以提供用戶個性化服務。
如果要繼續改進AI 模型,開發者將需要解決如何以更少的資源實現更高性能的問題。無論是在學術界還是在工業界,大模型壓縮一直是一個熱門領域,目前也有很多技術在做。本文簡單介紹四種常見的模型壓縮手段:量化、剪枝、參數共享和知識蒸餾,幫助大家對模型壓縮方法有一個直觀的了解。
1、模型瘦身的理論基礎:參數規模“邊際遞減”
如果我們把模型比作一個“水桶”,把數據比作“蘋果”,把數據中含有的信息比作“蘋果汁”,那麼訓練大模型的過程,就可以理解為用水桶裝蘋果汁的過程。蘋果越多,蘋果汁就越多,我們也需要更大的水桶來盛放蘋果汁。大模型的出現就猶如我們造出了更大的水桶,從而有更大的能力裝足夠的蘋果汁。
如果蘋果太多,蘋果汁太多,就會導致“溢出”,也就是模型規模太小,無法學習到數據集中所有的知識,我們稱這種情況為“欠擬合”,即模型無法學習到真實的數據分佈;如果蘋果太少,蘋果汁太少,就會導致“裝不滿”。如果通過增加模型訓練時長來“強行榨汁”裝滿水桶,就會導致果汁中雜質增多,從而出現模型性能下降,我們稱這種情況為“過擬合”,即模型過分學習數據導致的通用性下降。因此,模型規模與數據規模的匹配是非常重要的。
以上例子雖然形象,但容易產生一種誤解:一升水桶能裝一升蘋果汁,兩升水桶就能裝兩升(如①)。但實際上,參數所能容納的信息並不隨參數規模線性增加,而是趨於一種“邊際遞減”的增長(如②③)。
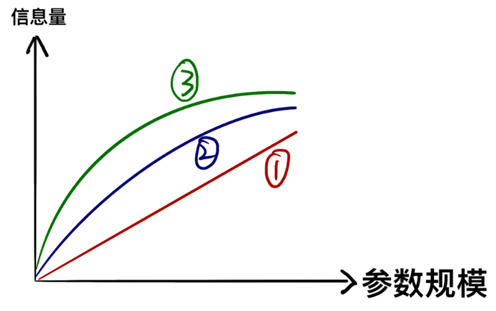
換句話說,大模型所表現出的超凡能力,是因為學到了很多“細節性知識”,而且花在“細節性知識”上的參數數量龐大。當我們已經學到數據中大部分知識的時候,再繼續學習更多的細節知識,就需要增設更多的參數。如果我們肯犧牲一些精度,忽略掉部分細節性信息,或者將識別細節性信息的參數進行裁剪,就可以將參數規模降低很多,而這正是學術界和工業界模型瘦身的理論基礎和核心思路。
2、量化——最“簡單粗暴”的瘦身方法
在計算機中,數值的精度越高,需要的存儲空間就越大。如果模型的參數精度非常高(直觀理解就是小數點後位數很多),那麼我們可以直接降低精度,從而實現模型壓縮,這就是量化的核心思路。一般模型的參數為3 2b it,如果我們同意將模型的精度降為8 bit,就能減少75% 的存儲空間。
這種方法的理論基礎,是在量化派中存在的一個共識:複雜的、高精度的模型在訓練時是必要的,因為我們需要在優化時捕捉微小的梯度變化,然而在推理時並沒有必要,因此量化可以做到只降低模型占用空間而不過於降低推理能力。
3、剪枝——“外科手術式”的參數剔除法
大模型規模龐大,結構複雜,內部參雜著大量作用微小甚至無用的參數和結構。如果我們能盡可能精確鎖定無用之處,將其剔除,那麼也能夠在保證功能的同時降低模型的規模。
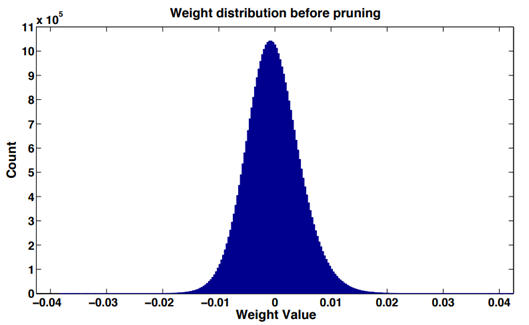
在大多數神經網絡中,通過對網絡層(卷積層或者全連接層)權重數值進行直方圖統計,可以發現,訓練後的權重數值分佈近似正態分佈或多正態分佈的混合,接近於0的權重相對較多,這就是“權重稀疏”現象。
權重數值的絕對值大小可以看作重要性的一種度量,權重數值越大對模型輸出貢獻也越大,反之則不重要,刪去後對模型精度的影響也比較小。
同時,在深度網絡中,存在著大量難以激活的神經元。論文《Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures》經過了一些簡單的統計,發現無論輸入什麼樣圖像數據,CNN 中的許多神經元都具有非常低的激活。作者認為,零神經元很可能是冗餘的,可以在不影響網絡整體精度的情況下將其移除。我們稱這種情況為“激活稀疏”。
因此,針對神經網絡上述特點,我們可以針對不同的結構進行裁剪優化,從而減小模型的規模。
4、參數共享——尋找複雜模型的小型替代
神經網絡是對現實數據分佈的擬合,本質是一個函數。如果我們能找到相同性能但參數規模更小的函數,使得相同的輸入能夠有接近的輸出,那麼自然也就減小了參數規模。
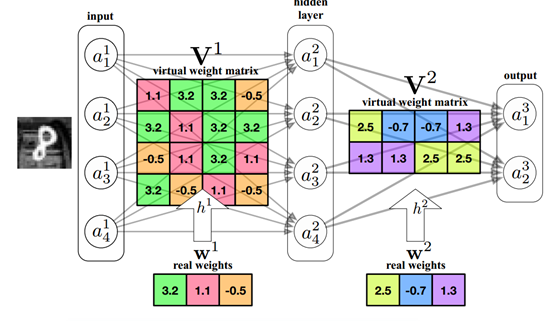
在技術領域,我們通常用PCA 算法進行降維,尋找高維數組在低維的映射。如果我們尋找到模型參數矩陣的低維映射,則可實現保證性能的同時降低參數量。
目前已經有多種參數共享的方法,比如對權重進行K-means 聚類,以及採用哈希方法隨機分類,然後對同一組的權值進行處理等。
5、知識蒸餾——學生代替老師
既然大模型蘊含著大量的知識,我們能否讓大模型“教會”一個小模型,使得小模型擁有大模型的本領?這便是知識蒸餾的核心思路。
已經擁有的大模型,我們稱之為Teacher 模型。此時我們可以用Teacher 模型對Student 模型做監督學習,從而學到Teacher 模型的知識。
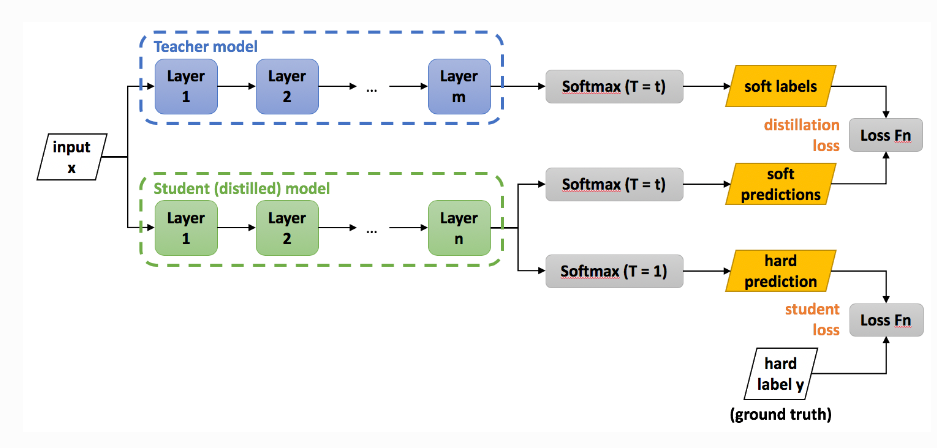
前三種方法或多或少都改變了原有模型的參數或結構,而知識蒸餾則相當於重新訓練了一個規模較小的模型,因此相比其他方法來講更能保全原有模型的功能,只是損失了部分精度。
結語
模型壓縮不存在統一的方法。針對不同的模型,一般會嘗試多種壓縮手段,從而做到規模與精度的平衡。如今,我們使用的大模型都部署在雲端,我們只有調用權而不具有所有權,畢竟本地無法存儲如此規模的模型,“人人都有大模型”似乎是一個遙不可及的夢。然而我們回顧歷史,在上個世紀40 年代計算機剛剛誕生的時候,人們看到如此龐大和耗電的“機器巨獸”,沒人會猜到它在數十年後的今天居然會成為人人都有的日常工具。同樣,隨著模型壓縮技術的進展、模型結構的優化以及硬件性能的飛躍,我們也期待在未來,大模型不再“大”,而是成為人人都能擁有的私人工具。
參考文獻:
https://blog.csdn.net/shentanyue/article/details/83539359
https://zhuanlan.zhihu.com/p/102038521
https://arxiv.org/abs/1607.03250
https://arxiv.org/abs/1806.09228
https://arxiv.org/abs/1504.04788
版權聲明:如需轉載歡迎加小助理微信溝通,未經允許轉載、洗稿、我方將保留追究法律責任的權利。
免責聲明:市場有風險,投資需謹慎。請讀者在考慮本文中的任何意見、觀點或結論時嚴格遵守所在地法律法規,以上內容不構成任何投資建議。


