
DAOrayaki:Web3生態系統中的AI應用前景
自從ChatGPT 和GPT-4 推出後,有很多關於人工智能如何革新一切,包括Web 3 的內容。多個行業的開發者報告稱,通過利用ChatGPT 作為共同駕駛員來自動化任務,如生成樣板代碼、進行單元測試、創建文檔、調試和檢測漏洞等,可以顯著提高生產效率,範圍從50% 到500 % 不等。雖然本文將探討人工智能如何實現新的有趣的Web 3 用例,但其主要關注點是Web 3 和人工智能之間的互利關係。很少有技術有能力顯著影響人工智能的發展方向,而Web 3 是其中之一。

Web3 如何促進人工智能?
儘管其具有巨大的潛力,但當前的人工智能模型面臨著一些挑戰,如數據隱私、專有模型的執行公正性以及創造和傳播可信的虛假內容的能力等。一些現有的Web 3 技術在應對這些挑戰方面具有獨特的優勢。
01 為機器學習(ML)訓練創建專有數據集
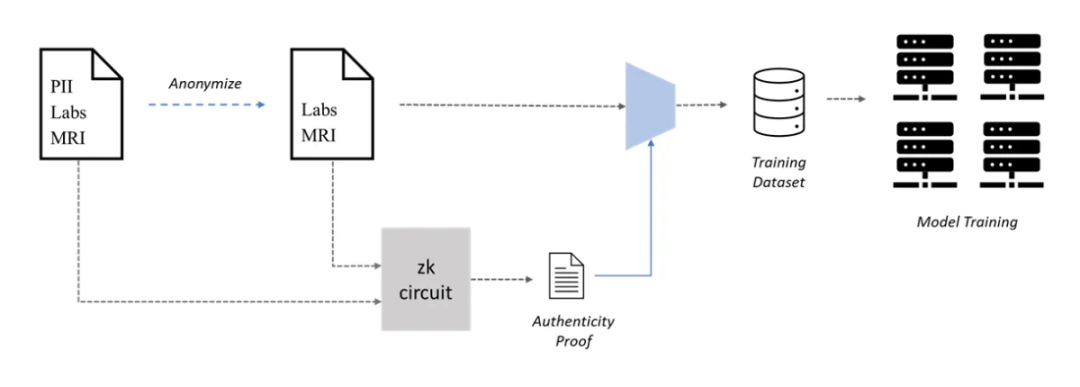
Web 3 可以幫助AI 的一個領域是通過協作創建專有數據集進行機器學習(ML)訓練,即使用PoPW 網絡進行數據集創建。大規模數據集對於準確的ML 模型至關重要,但在需要使用私有數據(如使用ML 進行醫學診斷)的用例中,其創建可能成為瓶頸。由於患者數據隱私的關注,醫療記錄的訪問是訓練這些模型的必要條件,但患者可能因隱私問題而不願意分享他們的醫療記錄。為了解決這個問題,患者可以通過可驗證的方式對其醫療記錄進行匿名化,以保護他們的隱私同時仍然可以用於ML 訓練。
但是,匿名化的醫療記錄的真實性是一個問題,因為虛假數據會嚴重影響模型的性能。為解決這個問題,可以使用零知識證明(ZKPs)來驗證匿名化的醫療記錄的真實性。患者可以生成ZKPs,以證明匿名記錄確實是原始記錄的副本,即使在刪除個人身份信息(PII)後也是如此。這樣,患者可以將匿名記錄與ZKPs 一起提供給感興趣的各方,並甚至獲得他們的貢獻的獎勵,而不會犧牲他們的隱私。
02 運行私有數據推理
當前LLM 的一個主要弱點是處理私有數據。例如,當用戶與chatGPT 互動時,OpenAI 會收集用戶的私人數據,並將其用於模型的訓練,這會導致敏感信息的洩露。這是三星公司的情況。零知識(zk)技術可以幫助解決ML 模型在私有數據上執行推理時出現的一些問題。在這裡,我們考慮兩種情況:開源模型和專有模型。
對於開源模型,用戶可以在其私有數據上本地下載模型並運行。例如,Worldcoin 計劃升級World ID。在此用例中,Worldcoin 需要處理用戶的私人生物識別數據,即用戶的虹膜掃描,以創建名為IrisCode 的每個用戶的唯一標識符。在這種情況下,用戶可以在其設備上保持其生物識別數據的私密性,下載用於IrisCode 生成的ML 模型,本地運行推理,並創建證明表明其IrisCode 已成功創建。生成的證明保證了推理的真實性,同時保持了數據的隱私。像Modulus Labs 開發的ML 模型的高效zk 證明機制對於這種用例至關重要。
另一種情況是當用於推理的ML 模型是專有的。這項任務有點困難,因為本地推理不是一種選擇。但是,ZKP 有兩種可能的方式可以幫助。第一種方法是使用ZKP 將用戶數據進行匿名處理,如前面數據集創建案例中所討論的,然後將匿名化的數據發送到ML 模型。另一種方法是在將預處理輸出發送到ML 模型之前,在私人數據上使用本地預處理步驟。在這種情況下,預處理步驟隱藏了用戶的私人數據,以便無法重構。用戶生成一個ZKP,表明預處理步驟的正確執行,然後專有模型的其餘部分可以在模型所有者的服務器上遠程執行。這裡的示例用例可能包括可以分析潛在診斷的患者的醫療記錄的AI 醫生,以及評估客戶私人財務信息的金融風險評估算法。
03 內容的真實性和對抗深度偽造技術
與專注於生成圖片、音頻和視頻的生成式人工智能模型相比,chatGPT 可能已經搶佔了風頭。然而,這些模型目前已經能夠生成逼真的深度偽造作品。最近由AI 生成的Drake 歌曲就是這些模型所能實現的例子。由於人類被編程成相信所見所聞,這些深度偽造作品代表了一個重大威脅。有許多初創公司正在嘗試使用Web 2 技術來解決這個問題。然而,Web 3 技術,如數字簽名,更適合解決這個問題。
在Web 3 中,用戶的交互,即交易,由用戶的私鑰進行簽名以證明其有效性。同樣,無論是文本、圖片、音頻還是視頻,內容也可以由創建者的私鑰進行簽名以證明其真實性。任何人都可以根據創建者的公共地址對簽名進行驗證,該地址在創建者的網站或社交媒體賬戶上提供。 Web 3 網絡已經構建了所有需要的基礎設施來實現此用例。 Fred Wilson 討論瞭如何將內容與公共加密密鑰關聯起來,以有效打擊錯誤信息。許多聲譽良好的風險投資公司已經將其現有的社交媒體資料,如Twitter,或去中心化的社交媒體平台,如Lens Protocol 和Mirror,與一個加密的公共地址相鏈接,這為數字簽名作為內容認證方法的可信度提供了支持。
儘管這個概念很簡單,但仍然需要大量的工作來改進這個認證過程的用戶體驗。例如,需要自動化創建內容的數字簽名,以提供無縫的流程給創建者使用。另一個挑戰是如何生成已簽名數據的子集,例如音頻或視頻片段,而無需重新簽名。許多現有的Web 3 技術獨具優勢,可以解決這些問題。
04 專有模型的信任最小化
另一個Web 3 可以為人工智能提供幫助的領域是,在專有機器學習模型作為服務提供時,最小化對服務提供者的信任。用戶可能需要驗證他們所支付的服務是否真正得到了提供,或獲得機器學習模型公平執行的保證,即所有用戶都使用同一模型。零知識證明可用於提供此類保證。在此架構中,機器學習模型的創建者生成一個表示該模型的零知識電路。需要時,該電路用於為用戶推斷生成零知識證明。零知識證明可以發送給用戶進行驗證,也可以發佈到處理用戶驗證任務的公共鏈上。如果機器學習模型是私有的,則獨立的第三方可以驗證所使用的zk 電路是否代表了該模型。機器學習模型的信任最小化方面在模型的執行結果具有高風險時特別有用。例如:
醫療診斷的機器學習模型
在這種用例中,患者提交其醫療數據以供機器學習模型進行潛在的診斷。患者需要確保目標機器學習模型已正確地應用於其數據。推斷過程生成證明機器學習模型正確執行的零知識證明。
貸款的信用價值評估
零知識證明可以確保銀行和金融機構在評估信用價值時考慮申請人提交的所有財務信息。此外,零知識證明可以證明公平性,即證明所有用戶都使用同一模型。
保險索賠處理
目前的保險理賠處理是手動和主觀的。機器學習模型可以更公正地評估有關保險單和索賠詳細信息的索賠。結合零知識證明,這些索賠處理的機器學習模型可以被證明已考慮所有政策和索賠細節,並且所有同一保險單下的索賠都使用同一模型進行處理。
05 解決模型創建的中心化問題
創建和訓練LLM 是一個耗時且昂貴的過程,需要特定的領域專業知識、專用計算基礎設施以及數百萬美元的計算成本。這些特徵可能會導致強大的中央實體(例如OpenAI),這些實體可以通過限制對其模型的訪問來對其用戶行使重大影響力。
考慮到這些集中化風險,人們正在就Web 3 如何促進LLM 不同方面的去中心化展開重要的討論。一些Web 3 的支持者提出採用去中心化計算作為與中央化玩家競爭的方法。其基本觀點是,去中心化計算可以成為一種更便宜的選擇。然而,我們認為這可能不是與中央化玩家競爭的最佳角度。去中心化計算的缺點在於,由於不同異構計算設備之間的通信開銷,它在ML 訓練中可能會慢10-100 倍。
作為替代方案,Web 3 項目可以專注於以PoPW 的方式創建獨特且有競爭力的ML 模型。這些PoPW 網絡還可以收集數據以構建獨特的數據集來訓練這些模型。一些正在朝這個方向發展的項目包括Together 和Bittensor。
06 AI 代理的支付和執行渠道
過去幾週,利用LLMs 來推理完成某個目標所需任務並執行這些任務以實現目標的AI 代理正在崛起。 AI 代理的浪潮始於BabyAGI 的想法,並迅速擴散到高級版本,包括AutoGPT。這裡的一個重要預測是,AI 代理將變得更加專業化,以在某些任務上表現出色。如果存在專門的AI 代理市場,那麼AI 代理可以搜索、僱傭和支付其他AI 代理來執行特定任務,從而實現主項目的完成。在此過程中,Web 3 網絡為AI 代理提供了理想的環境。對於支付,AI 代理可以配備加密貨幣錢包,用於接收付款和支付其他AI 代理。此外,AI 代理可以插入加密網絡以無需獲得許可地委託資源。例如,如果一個AI 代理需要存儲數據,那麼AI 代理可以創建一個Filecoin錢包,並支付IPFS上的分散式存儲費用。 AI 代理還可以從分散式計算網絡如Akash委託計算資源來執行某些任務,甚至擴展其自身的執行。
07 保護免受AI 侵犯隱私
鑑於訓練性能良好的ML 模型需要大量數據,可以安全地假定任何公共數據都會被用於ML 模型,以預測個人行為。此外,銀行和金融機構可以建立自己的ML 模型,這些模型是根據用戶的財務信息進行訓練的,並能夠預測用戶的未來財務行為。這可能是對隱私的重大侵犯。這種威脅的唯一緩解是默認的金融交易隱私。這種隱私可以通過使用zCash 或Aztec 支付等私人支付區塊鍊和Penumbra 和Aleo 等私人DeFi協議來實現。
AI 賦能的Web3應用案例
01 鏈上游戲
為非程序員玩家生成機器人
像Dark Forest 這樣的鏈上游戲創造了一種獨特的範例,玩家可以通過開發和部署執行所需遊戲任務的機器人來獲得優勢。這種範式轉變可能會排除不能編寫代碼的玩家。然而,LLM 可以改變這一點。 LLM 可以被微調來理解鏈上游戲邏輯,並允許玩家創建反映玩家策略的機器人,而不需要玩家編寫任何代碼。像Primodium 和AI Arena 這樣的項目正在致力於為他們的遊戲吸引人工智能和人類玩家。
機器人戰鬥、賭博和投注
鏈上游戲的另一個可能性是完全自治的AI 玩家。在這種情況下,玩家是一個AI 代理,例如AutoGPT,它使用LLM 作為後端,並可以訪問外部資源,例如互聯網訪問和潛在的初始加密貨幣資金。這些AI 玩家可以像機器人戰爭一樣進行賭博。這可以開闢一種關於這些賭注結果的投機和賭博市場。
為鏈上游戲創建逼真的NPC 環境
目前的遊戲很少關注非玩家角色(NPC)。 NPC 的行動有限,對遊戲進程的影響很小。鑑於人工智能和Web3的協同作用,可以創建更具吸引力的由AI 控制的NPC,這些NPC 可以打破可預測性,使遊戲更有趣。這裡潛在的挑戰是如何在最小化與這些活動相關的吞吐量(TPS)的同時引入有意義的NPC 動態。過度的NPC 活動所需的TPS 要求可能會導致網絡擁塞,對實際玩家產生不良用戶體驗。
02 去中心化社交媒體
目前去中心化社交(DeSo)平檯面臨的一個挑戰是,它們與現有的中心化平台相比並沒有提供獨特的用戶體驗。接受與AI 的無縫集成可以提供缺乏Web2替代品的獨特體驗。例如,AI 管理的帳戶可以通過共享相關內容、在帖子上發表評論和參與討論來幫助吸引新用戶加入網絡。 AI 帳戶還可以用於新聞聚合,總結與用戶興趣相匹配的最新趨勢。 [ 18 ]
03 去中心化協議的安全和經濟設計測試
基於LLM 的AI 代理可以定義目標、創建代碼並執行代碼的趨勢為測試去中心化網絡的安全性和經濟健全性創造了機會。在這種情況下,AI 代理被指示利用協議的安全性或經濟平衡。 AI 代理可以首先審查協議文件和智能合約,識別弱點。然後,AI 代理可以獨立競爭執行機制來攻擊協議,以最大化自己的收益。這種方法模擬了協議在啟動後所經歷的實際環境。根據這些測試結果,協議的設計者可以審查協議設計並修補弱點。迄今為止,只有專業公司(例如Gauntlet)具備為去中心化協議提供此類服務所需的技術技能集。然而,我們預計,經過Solidity、DeFi 機制和先前的開發機制訓練的LLM 可以提供類似的功能。
04 用於數據索引和指標提取的LLM
儘管區塊鏈數據是公開的,但索引該數據並提取有用的見解一直是一個持續的挑戰。該領域的某些參與者(如CoinMetrics)專門從事索引數據和構建複雜指標以銷售,而其他人(如Dune)專注於索引原始交易的主要組件,並通過社區貢獻眾包指標提取部分。最近的LLM 進展表明,數據索引和指標提取可能會受到破壞。 Dune 已經認識到了這個威脅,並宣布了一個LLM 路線圖,其中包括SQL 查詢解釋和基於NLP 的查詢的潛力。然而,我們預測LLM 的影響將比這更深入。這裡的一種可能性是基於LLM 的索引,其中LLM 模型直接與區塊鏈節點交互,為特定的指標索引數據。像Dune Ninja 這樣的初創公司已經在探索創新的LLM 應用於數據索引。
05 引入新生態的開發者
不同的區塊鏈競爭吸引開發者來建立該生態系統中的應用程序。 Web 3 開發者活動是某個生態系統成功的重要指標。開發者面臨的主要難點是在開始學習和構建新生態系統時得到支持。生態系統已經投資數百萬美元,以專門的開發者關係團隊的形式支持探索生態系統的開發者。在這方面,新興的LLMs 已經展示出驚人的成果,可以解釋複雜的代碼、捕獲錯誤,甚至創建文檔。經過調整的LLMs 可以補充人類經驗,顯著擴大開發人員關係團隊的生產力。例如,LLMs 可用於創建文檔、教程、回答常見問題,甚至支持hackathon 的開發人員使用模板代碼或創建單元測試。
06 改進DeFi 協議
通過將人工智能集成到DeFi 協議的邏輯中,許多DeFi 協議的性能可以顯著提高。迄今為止,集成AI 到DeFi 的主要瓶頸是實現鏈上AI 的成本過高。 AI 模型可以在鏈下實現,但以前沒有辦法驗證模型執行。然而,通過Modulus 和ChainML 等項目,鏈下執行的驗證正在變得可能。這些項目允許在鏈下執行ML 模型,同時限制鏈上成本。在Modulus 的情況下,鏈上費用被限制為驗證模型的ZKP。在ChainML 的情況下,鏈上成本是支付給分散的AI 執行網絡的Oracle 費用。
一些可以從AI 集成中受益的DeFi 用例。
AMM 流動性供應,即更新Uniswap V3流動性的範圍。
使用鏈上和鏈下數據保護債務頭寸的清算保護。
結論
結論
結論
我們認為Web3和AI 在文化和技術上是兼容的。與Web2傾向於排斥機器人不同,Web3由於其無需權限的可編程性而允許AI 蓬勃發展。更廣泛地說,如果您將區塊鏈視為一個網絡,那麼我們預計AI 將主導網絡的邊緣。這適用於各種消費者應用,從社交媒體到遊戲。到目前為止,Web 3 網絡的邊緣在很大程度上是人類。人類啟動和簽署交易或實施具有固定策略的機器人。隨著時間的推移,我們將看到越來越多的AI 代理在網絡邊緣處。 AI 代理將通過智能合約與人類和彼此進行交互。這些交互將使新穎的消費者體驗成為可能。


