
IOSG:多維度分析zkVM與zkEVM的派系之爭
原文作者:Bryan, IOSG Ventures
原文作者:Bryan, IOSG Ventures
過去的2022 年關於rollup 主要的討論焦點似乎都集中在ZkEVM,但是別忘記ZkVM 也是另一種擴容手段。雖然ZkEVM 並不是本文的重點,但是值得回味一下ZkVM 與ZkEVM 之間幾個維度的不同之處:
兼容性:雖然都是擴容,但是側重點並不同,ZkEVM 的側重點在於直接實現與現有EVM 的兼容,而ZkVM 的定位在於實現完全的擴容,也就是將dapp 的邏輯以及性能提升到最優,兼容性並不是首要的。底層搭好了,EVM 兼容也可以實現。
性能:兩者都有比較可以預見的性能方面的瓶頸,ZkEVM 主要瓶頸在於兼容EVM 這樣一個並不適合封裝在ZK 證明系統時產生的多餘成本。 ZkVM 的瓶頸在於因為引入了指令集ISA,導致最終輸出的約束更複雜。

開發者體驗:Type II ZkEVM ( 如Scroll, Taiko) 主打的是對於EVM Bytecode 的兼容,換句話說就是Bytecode 級別及其以上的EVM 代碼都可以通過ZkEVM 產生對應的零知識證明。對於ZkVM 來說,有兩個方向,一個方向是做自己的DSL( 如Cairo), 另一個則是目標兼容現有的比較成熟的語言如C++/Rust(如Risc 0)。未來我們預計原生的solidity 以太坊開發者會可以無成本遷移至ZkEVM,而更新更強大的應用則會跑在ZkVM 上。
很多人應該還記得這張圖,CairoVM 事不關己遊離於ZkEVM 派系鬥爭的本質原因是設計思想的不同
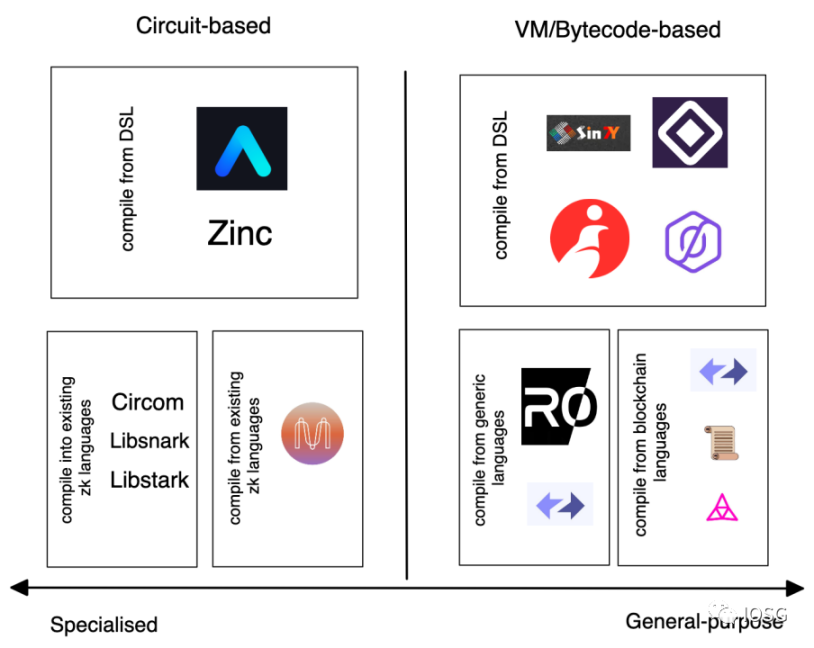
在討論ZkVM 之前,我們首先思考的是如何在區塊鏈中實現ZK 證明系統。大致上,有兩種方法實現電路- 基於電路的系統(circuit based) 以及基於虛擬機的系統(vm-based)。
圖片描述
圖片描述

圖片描述
圖片來源: Bryan, IOSG Ventures
優缺點:
從開發者(developer) 的角度來看,在基於電路的系統中開發通常需要對每個約束條件的成本有深入的了解。然而,對於編寫虛擬機程序來說,電路是靜態的,開發者需要更關心的是指令(instructions)。
從驗證者(verifier) 的角度來看,假設使用相同的純SNARK 作為後端,基於電路的系統和虛擬機在電路的通用性方面有很大的不同。電路系統對每個程序產生不同的電路,而虛擬機對不同程序產生相同的電路。這意味著,在一個rollup 中,電路系統需要在L1 上部署多個驗證合約(verifier contract)。
一級標題
圖片描述
一級標題
二級標題
二級標題
1. ISA 指令集
1. ISA 指令集
規定了電路產生器的工作方式。它的主要責任是將指令(instructions) 正確地映射到約束條件(constraint) 中,這些約束條件隨後被送入證明系統(proving system)。 zk 系統使用的都是RISC( 精簡指令集)。有兩種ISA 的選擇:

二級標題
二級標題
二級標題
2. 編譯器(Compiler)
籠統地來說,編譯器會逐步將編程語言翻譯成機器代碼。在ZK 的環境下,它指的是使用C、C++、Rust 等高級語言編譯成約束系統(R 1 CS、QAP、AIR 等.)的低級代碼表示。有兩種方法,
設計一個基於現有zk 電路表示(existing circuit representations) 的編譯器-- 比如說在ZK 中,電路表現形式從Bellman 這樣的可以直接調用的庫(library) 和Circom 這樣的低級語言開始。為了聚合不同的表現形式,Zokrates 這樣的編譯器(身也是一個DSL)旨在提供一個抽象層,可以編譯成任意的更低級表現形式。
基於(現有的)編譯器基礎設施(compiler infrastructure) 來構建。基本邏輯是利用一個針對多個前端和後端的中間表現形式(intermediate representation)。
Risc 0 的編譯器是基於multi-level intermediate representation(MLIR),可以生成多個IR(類似於LLVM)。不同的IR 給開發者帶來了靈活性,因為不同的IR 有各自的設計重點,例如其中有一些的優化是專門針對硬件,所以開發者可以根據自己的意願進行選擇。類似的想法在使用GCC 的vnTinyRAM 和TinyRAM 中也可以看到。 ZkSync 也是另一個利用編譯器基礎設施的例子。
此外,你還可以看到一些針對zk 的編譯器基礎設施,如CirC,它也藉用了LLVM 的一些設計理念。
除了上述兩個最關鍵的設計步驟外,還有一些其他的考慮因素:
1.系統的安全性(security) 和驗證的成本(verifier cost) 之間的權衡
系統使用的比特數越高(即安全性越高),意味著驗證的成本越高。安全性反映在密鑰生成器(比如在SNARK 中代表橢圓曲線)。
2.與前端和後端的兼容性(compatibility)
兼容性取決於為電路的中間表示(intermediate representation) 的有效性。 IR 需要在正確性(程序的輸出是否與輸入相匹配+ 輸出是否符合證明系統)和靈活性(支持多種前端和後端)之間取得了平衡。如果IR 最初是為解決像R 1 CS 這樣的低度(low-degree) 約束系統而設計的,那麼與其他更高級別(high-degree) 的約束系統如AIR 的兼容就很難。
3.為提高效率需要手工製作(hand-crafted) 電路
使用通用模型(general purpose) 的缺點是,對於一些不需要復雜指令的簡單操作,其效率較低。
簡述一下先前的一些理論,
Pinocchio 協議之前: 實現了可驗證的計算,但驗證時間非常慢
Pinocchio 協議: 在可驗證性和驗證成功率方面提供了理論上的可行性(即驗證的時間比執行程序的時間短),是基於電路的系統
TinyRAM 協議: 相對於Pinocchio 協議,TinyRAM 更像一個虛擬機,引入了ISA,因此擺脫了一些限制,如內存訪問(RAM)、控制流(conttrol flow) 等
vnTinyRAM 協議: 使得密鑰生成(key generation) 並不取決每個程序,提供了額外的通用性。擴展電路產生器,即能夠處理更大的程序。
上述模型都以SNARK 作為其後端證明系統,但是特別是在處理虛擬機時,STARK 和Plonk 似乎是一個更合適的後端,從根本上說是由於其約束系統更適合於實現cpu 一樣的邏輯。
接下來,本文會介紹三個基於STARK 的虛擬機- Risc 0, MidenVM, CairoVM。簡而言之,除了都以STARK 作為證明系統外,它們各自有一些不同:
Risc 0 利用Risc-V 來實現指令集的簡潔性。 R 0 在MLIR 進行編譯,這是LLVM-IR 的一個變種,旨在支持多種現有的通用編程語言,如Rust、C++。 Risc-V 還有一些額外的好處,比如對於硬件較為友好。
Miden 的目標是與以太坊虛擬機(EVM)兼容,本質上是EVM 的rollup。 Miden 現在有自己的編程語言,但也致力於在未來支持Move。
Cairo VM 是由Starkware 開發的。這三個系統所使用的STARK 證明系統是由Eli Ben-Sasson 發明的,目前Starkware 的總裁。
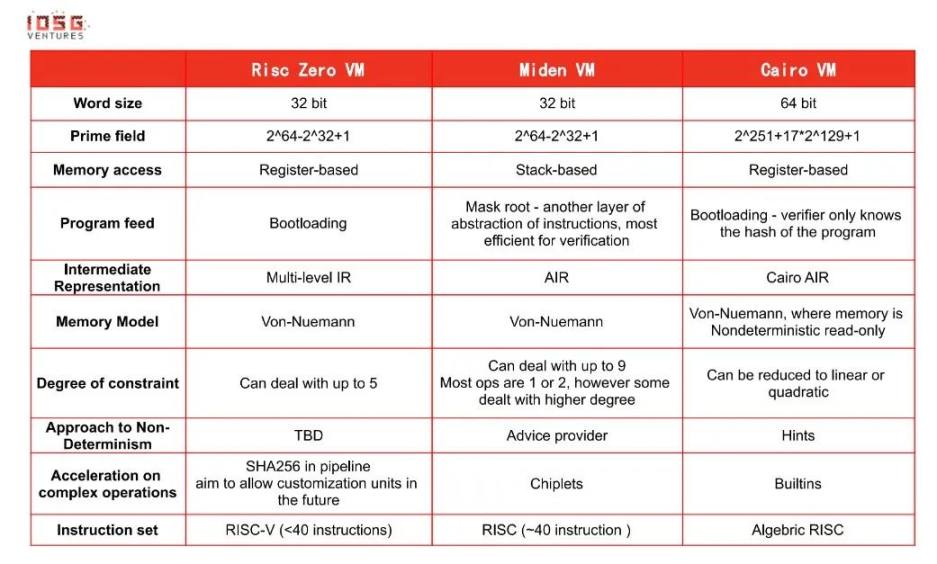
讓我們更深入地了解它們的區別:
* 如何讀懂上面的表格?一些註解...
Word size(字長) - 由於這些虛擬機所基於的約束系統是AIR,其功能與CPU 架構類似。所以選擇CPU 字長(32/64 位)比較合適。
Memory access(內存讀取)- Risc 0 使用寄存器(register) 的原因主要是Risc-V 指令集是基於寄存器的。 Miden 主要使用堆棧(stack) 來存儲數據,因為AIR 的功能與堆棧類似。 CairoVM 沒有使用通用寄存器(general-purpose register),因為Cairo 模型中的內存訪問(main memory) 成本較低。
Program feed(程序執行)- 不同方法是有取捨的。例如,對於mast root 方法來說,它需要在處理指令時進行解碼,因此在執行步驟較多的程序中下證明者的成本較高
Bootloading 方法試圖在保持隱私的同時在證明者成本和驗證者的成本之間取得平衡。
Non-determinism(非確定性)- 非確定性是NP-complete 問題的一個重要屬性。利用非確定性有助於快速驗證過去的執行。反過來說,它增加了更多的約束條件,因此在驗證方面會有一些妥協。
Acceleration on complex operations(複雜運算的加速)- 有些計算在CPU 上運行很慢。例如,位操作,如XOR 和AND,哈希程序(hash program),如ECDSA,還有範圍檢查(range-check)......大多是區塊鏈/ 加密技術的原生但不是CPU 原生的運算(除了位操作)。直接通過DSL 來實現這些運算會很容易導致證明的周期(cycle) 耗盡。
Permutation/multiset ( 排列/ 多列組合) - 在大多數zkVM 中大量使用,有兩個目的--1.通過減少存儲完整的執行軌跡(execution trace) 來降低驗證者的成本2.證明驗證者知道完整的執行軌跡
文章最後筆者想談談Risc 0 目前的發展以及其讓我興奮的原因。
R 0 目前的發展:
a.自研的「Zirgen」的編譯器基礎設施正在開發中。將Zirgen 與一些現有的zk 專用編譯器的性能進行比較會很有趣。
b.一些很有意思的的創新,如field extension,可以實現更堅實的安全參數以及在更大的整數上進行操作。
c.見證了在ZK 硬件和ZK 軟件公司之間的整合中看到的挑戰,Risc 0 使用了一個硬件抽象層,以便在硬件方面進行更好的開發。
d.Still a work-in-progress! 還在開發中!
支持手工製作的電路(hand-crafted circuits),支持多種哈希算法。目前,專用的SHA 256 電路已實現,然而還不能滿足所有的需求。筆者相信具體選擇優化哪類電路取決於Risc 0 所提供的用例(use case)。 SHA 256 是一個非常好的起點。另一方面,ZKVM 的定位給人以靈活性,例如,只要他們不想,就不必去管Keccak :)
遞歸(recursion):這是一個很大的話題,筆者傾向於不在該報告進行深入研究。需要知道的是,隨著Risc 0 傾向於支持更複雜的用例/ 程序,更迫切地需要遞歸。為了進一步支持遞歸,他們目前正在研究一個硬件端的GPU 加速方案。
WHAT EXCITES ME:
處理非確定性(non-determinism):這是ZKVM 必須處理的一個屬性,而傳統的虛擬機是沒有這個問題的。非確定性可以幫助虛擬機執行得更快。 MLIR 相對更擅長處理傳統虛擬機方面的問題,而Risc 0 如何將非確定性嵌入到ZKVM 系統設計中值得期待。
a.簡單且可驗證!
在分佈式系統中,PoW 需要高水平的冗餘,因為人們不信任他人,因此需要重複執行相同的計算來達成共識。而通過利用零知識證明,狀態的實現應該和同意1+ 1 = 2 一樣容易。
b.更多更實際的用例:
除了最直接的擴容外,更多有意思的用例將變得可行,比如零知識機器學習、數據分析等。相比於Cairo 這樣的特定的ZK 語言,Rust/C++ 的功能更普適且更強大,更多web2 的用例跑在Risc 0 VM 上。
c.更具包容性/ 成熟的開發者社區:


