
A16z:生成式AI面臨的機遇與挑戰
原文來源:阿法兔研究筆記
原文來源:阿法兔研究筆記
原文來源:阿法兔研究筆記
原文來源:阿法兔研究筆記原文翻譯:阿法兔A16Z最近又發了一篇有意思的文章,談到他們認為的
生成式AI 價值捕獲(請注意:這些大部分都是A16Z的Portofolio,請大家本著客觀理性的態度閱讀,本文不構成任何投資建議或者對項目的推薦)
一級標題
什麼是生成式AI?
一級標題
一級標題
一級標題
第一部分:觀察和預測
人工智能應用正在迅速擴大規模,而留存並沒有那麼容易,並不是所有人都可以建立起來商業規模。
生成式AI 技術的早期階段已浮現:
比如說,數以百計的新興AI 創業公司正沖向市場,開始開發基礎模型,構建AI 原生應用程序、基礎設施與工具。
當然,確實會有很多熱門技術趨勢,會出現過度炒作的情況。但生成式人工智能的蓬勃發展,已經能看到很多公司產生了實實在在的營收。例如,像Stable Diffusion 和ChatGPT 這樣的模型創造了用戶增長的歷史記錄,有的應用在推出後不到一年,就達到了1 億美元的年營收,並且人工智能模型在部分任務中的表現要比人類的水平高幾個數量級。
我們發現,技術範式轉型正在發生。但是,
需要研究的關鍵問題在於:整個市場中,哪些地方會產生價值?過去一年裡,我們和幾十位生成式AI 創業公司的創始人和大公司AI 領域的專家。我們觀察到目前為止,基礎設施供應商很可能是這個市場上最大的贏家,因為基礎設施可以獲得經過整個生成式AI 堆棧最多的流水和營收。
儘管主攻應用開發的公司收入增長非常快,但這部分公司往往在用戶留存、產品差異化和毛利率方面存在弱勢。
而大多數模型供應商目前還沒有掌握大規模的商業化能力。
但迄今為止,除了現有公司傳統意義上的業務護城河,很難在(生成式人工智能的)堆棧上找到結構上可防禦性。
二級標題
二級標題
二級標題
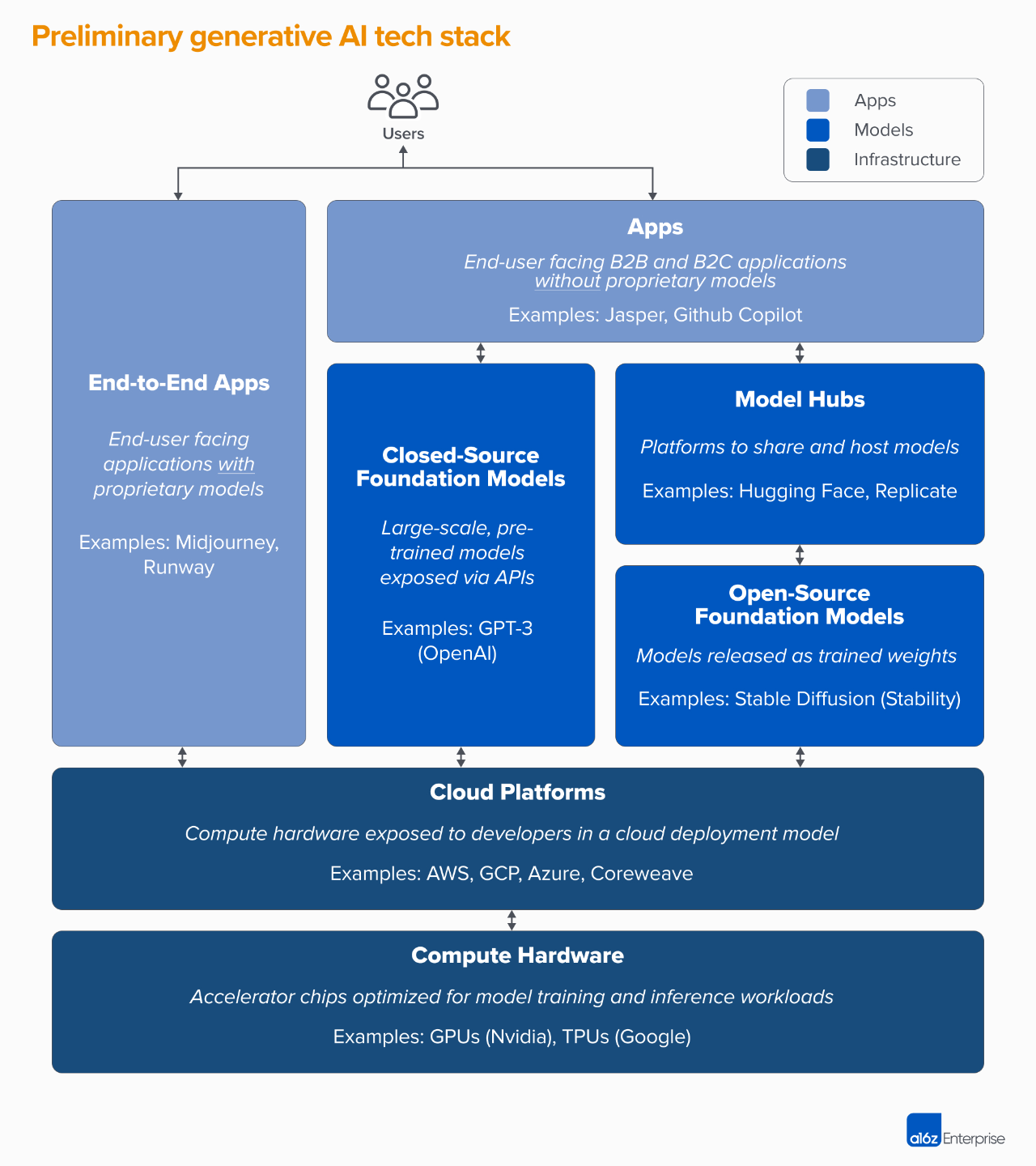
技術棧:基礎設施、人工智能模型和應用程序
想要了解生成式人工智能賽道和市場是如何形成的,首先需要定義目前整個行業的堆棧:"整個生成式人工智能的堆棧可分為三層:"1.將生成式AI 模型,與面向用戶的產品應用集成,這種通常是運行自己的模型管道(
端到端應用
),或者依賴第三方API
(阿法兔研究筆記註釋:這裡我們說的模型管道,指的就是就是一個模型的輸出作為下一個模型的輸入)
2.為人工智能產品提供動力的模型,以專有API 或開源檢查點的形式提供(這反過來需要一個託管解決方案)
(註釋:這塊說的是,要么把整個模型的構建方式以及預訓練的模型(又叫檢查點)開放出來,要么需要把整個模型的構建方式以及預訓練的模保密,只開放一個接口API ,如果是前者的話,你就要自己去跑訓練/微調/推理,所以需要知道它能什麼樣的環境、什麼樣的硬件基礎上跑,所以需要有人提供一個託管平台處理模型運行環境的事情)
3.為生成性人工智能模型運行訓練和推理工作負載的基礎設施供應商(即云平台和硬件製造商)
需要注意的是,這塊我們講的並不是整個市場的生態圖,而是一個分析市場的框架,本文在每個類別中都列出了一些知名廠商的例子,不過沒有囊括列出目前所有最厲害的AIGC應用,也沒有深入討論MLops 或LLMops 工具,因為這塊還沒有達到完全成熟的標準化,有機會我們會繼續討論。
第一波的生成式人工智能應用開始形成規模化,但在留存和差異化方面卻不容易
在之前的技術週期中,傳統意義上的觀點會認為,想要建立大型的、獨立的公司,就必須擁有終端客戶,這裡的終端客戶包括個人消費者和B 2B買家。
因為這種傳統意義上的觀點,大家很容易也認為:生成式人工智能中最大的機會也在於能夠做面向終端用戶的應用的公司。
但是到目前為止,其實情況並不一定會這樣。
生成式人工智能應用的增長非常驚人,這種增長主要是由非常新穎和應用案例所驅動的,比如說圖像生成、文案寫作和代碼編寫,這三個產品類別的年收入已經超過了1 億美元。
但是,光增長還不足以構建持久的軟件公司,關鍵在於,這種增長必須是有利潤,也就是說,用戶和客戶一旦註冊就可以產生利潤(高毛利),並且這種利潤還需要能夠長期可持續(高留存率)。如果公司之間不存在強大的技術差異化,B 2B和B 2C應用程序只要通過網絡效應,和數據優勢,再或者構建愈發複雜的工作流程,從而獲得成功。
但是,在生成式人工智能領域,上述假設未必成立。在我們調研的做生成式人工智能APP 的創業公司中,毛利率的變化範圍很廣,少數公司能達到90% ,多數公司毛利率低至50-60% ,這塊主要由模型成本影響。儘管我們可以看到目前渠道頂端(Top-of-funnel )的增長,
目前市面上的很多應用程序也確實缺乏差異性,因為這些應用主要依賴於相似的底層人工智能模型,並沒有發現明顯能夠具備獨家網絡效應、其他競爭對手很難復制的的殺手級應用和數據/工作流程。
二級標題
二級標題
在垂直整合("在垂直整合(")方面
模型+應用
)方面
如果人工智能模型作為一種消費型服務,應用開發者可以用小團隊模式快速迭代,並隨著技術的進步,逐步更換模型供應商。但還有開發者不同意,他們認為,產品就是模型,從頭開始訓練是創造可防禦性的唯一途徑,這裡指的是不斷地對專有產品數據進行再訓練(re-training)。但這就需要更高的資本,並且需要穩定的產品團隊為代價的。
會和Gartner 公司發布的炒作週期(hyper cycle) 一致?
一級標題
一級標題
一級標題
第二部分:關於生成式人工智能的規模化商業落地
我們第一部分說了目前生成式AI 的堆棧以及面臨的部分問題。第二部分繼續講:
關於生成式人工智能的規模化商業落地
以及到底Winner Takes All 價值捕獲最大的,在哪部分?
還有上面其他問題?
目前行業的問題在哪?
儘管模型的發明,導致生成式人工智能技術廣為人知,但目前還未達到大規模的商業落地的程度
倘若沒有谷歌、OpenAI 和Stability 等公司在研究方面的付出,以及這些公司將研究工程化,我們今天就無法見證如此成功的生成式人工智能技術。無論是我們看到的全新模型架構,還是擴展訓練管道,主要得益於當前大型語言模型(LLMs)和圖像模型的強大能力。然而,如果我們去看這些公司的收入,和這麼大的使用量和市場的熱度比,收入並不是很高。在圖像生成這塊,Stable Diffusion 的社區出現爆炸性增長。但Stability 公司的主要檢查點是開放的,這也是Stability 業務的核心宗旨。
在自然語言模型方面,OpenAI 以GPT-3/3.5 和ChatGPT 而聞名。
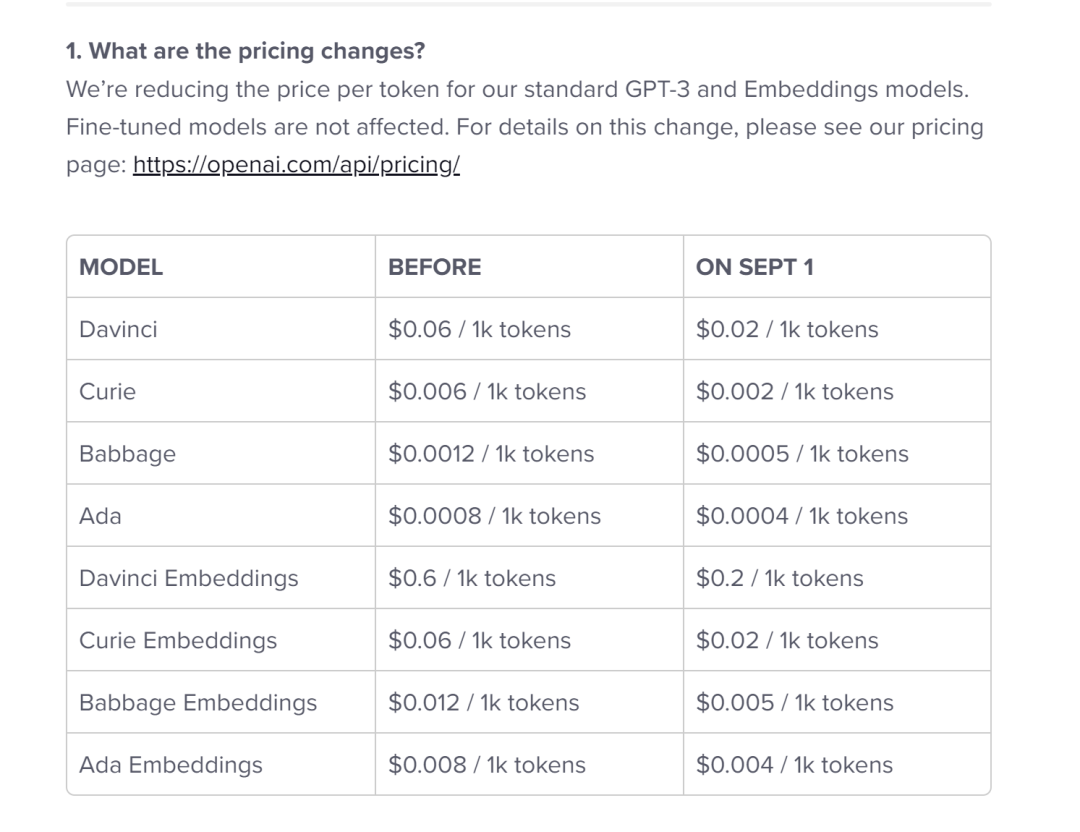
但到目前為止,基於OpenAI 構建的殺手級應用還是較少,而且價格已經下降過一次。 (見下圖)(想想為什麼降價?)
當然,目前這些可能只是暫時現象。 Stability 是新型創業公司,沒有把重點放在商業化上。 OpenAI 有可能擁有海量業務,隨著更多的殺手級應用的構建,OpenAI 可以賺取所有自然語言行業類別收入的很大一部分,
特別是如果OpenAI 與微軟的產品組合的整合順利進行,這些模型的高使用量會帶來大規模收入。
但也存在隱患:
比如說,如果模型開源,那麼它就可以由任何人託管,包括那些不承擔大規模模型訓練成本(這塊高達數千或數億美元)的其他公司。
而且目前還不清楚,閉源模型可以無限期地保持其優勢。例如,比如說我們開始看到Anthropic、Cohere 和Character.ai 等公司建立的大模型LLMs 接近OpenAI 的性能水平,在類似的數據集(即互聯網)上訓練,採用類似的模型架構。Stable Diffusion的例子表明,如果開源模型的性能和社區支持達到了一定水平,那麼同一個賽道的其他替代品可能會發現競爭非常困難。;
到目前為止,對模型提供方來說,最明顯的收穫也許是與託管有關的商業化
(註釋:這塊就是指的是上篇提到的要么把整個模型的構建方式以及預訓練的模型(又叫檢查點)開放出來,要么需要把整個模型的構建方式以及預訓練的模保密,只開放一個接口API,如果是前者的話,你就要自己去跑訓練/微調/推理,所以需要知道它能什麼樣的環境、什麼樣的硬件基礎上跑,所以需要有人提供一個託管平台處理模型運行環境的事情)
以及對專有API 的需求(例如來自OpenAI)正在迅速增長。比如,開源模型的託管服務(如Hugging Face 和Replicate)出現,成為輕鬆分享和整合模型的樞紐,甚至在模型生產者和消費者之間,產生了間接的網絡效應。還有有力的假設是,有可能通過微調和與企業客戶的託管協議,來實現公司的盈利。不過,模型供應方還面臨著問題:
商業化。
普遍觀點認為,隨著時間的推移,人工智能模型的性能將趨於一致。在與APP 開發人員交談時,目前這種性能一致的現像還沒有發生,因為在文本和圖像模型中都有排名靠前的選手。這些公司的優勢,不在於獨特模型架構,而是基於很高的高資本要求、專有的產品互動數據和稀缺的AI 人才。但是,這些能夠成為一家公司長久可持續的優勢嗎?脫離模型供應商的風險。
依靠模型供應商是很多APP 公司起步的途徑,它們甚至靠供應商發展業務,但是,一旦達到規模,APP 開發商,就有動力建立和/或託管自己的模型。許多模型供應商的客戶分佈並不均衡,少數應用程序掌握了大部分的收入。如果這些客戶不用供應商的模型,轉向自己內部進行人工智能模型開發,怎麼辦?
資本會很重要嗎?
生成式人工智能的願景太大了,以至於許多模型供應商已經開始將公共利益納入其使命。這一點也沒有妨礙他們的融資。但需要討論的是,模型供應商是否真有意願去獲取價值,以及他們是否應該得到這些。
得基礎設施得天下。
生成式人工智能中的所有,都會使用雲託管的GPU(或TPU)服務。無論是模型供應方還是研究實驗室,運行訓練工作負載,還是託管公司運行推理/微調,FLOPS 是生成式人工智能的關鍵。
(阿法兔研究筆記註釋:FLOPS 是floating point operations per second 的縮寫,意思是每秒浮點運算次數,理解為計算速度。是一個衡量硬件性能的指標。通常我們去評價一個模型時,首先要看它的精確度,當精確度不行的時候,你和別人說我的模型預測的多麼多麼的快,部署的時候佔的內存多麼多麼的小,都是白搭。但當你模型達到一定的精確度之後,就需要更進一步的評價指標來評價模型:
這裡包括:
1 )前向傳播時所需的計算力,它反應了對硬件如GPU 性能要求的高低;
2 )參數個數,它反應所佔內存大小。為什麼要加上這兩個指標呢?因為這事關你模型算法的落地。比如你要在手機和汽車上部署深度學習模型,對模型大小和計算力就有嚴格要求。模型參數想必大家都知道是什麼怎麼算了,而前向傳播時所需的計算力可能還會帶有一點點疑問。所以這裡總計一下前向傳播時所需的計算力。它正是由FLOPs 體現。參考資料:知乎阿柴本柴:https://zhuanlan.zhihu.com/p/137719986 )
因此,生成式人工智能領域的很多資金,最終都流向了基礎設施公司。粗略估計的話,平均而言,應用程序公司在推理和每個客戶的微調上花費了大約20-40% 的收入。而這筆收入通常是直接支付給雲供應商的計算實例或第三方模型供應商,供應商反過來又將大約一半的收入用於雲基礎設施。
因此,我們可以推測:今天生成式人工智能總收入的10-20% 是給了雲供應商。除此之外,訓練自己的模型的初創公司,也已經融資數十億美元的風險資本,而其中大部分(在早期輪次中高達80-90% )通常也是花雲供應商身上。許多科技公司每年在模型培訓上花費數億美元,它們要么與外部雲供應商合作,要么直接與硬件製造商合作。
對於一個AIGC 新生市場來說,其中大部分是花在三大雲上:
亞馬遜雲科技(AWS)、谷歌云(GCP)和微軟Azure,這些雲供應商每年總共花費超過1000 億美元的資本支出,以確保擁有最全面、最可靠和最具成本競爭力的平台。
特別是在生成式人工智能這塊,這幾家云廠商可以優先獲得稀缺的硬件(如Nvidia A 100 和H 100 GPU)(阿法兔註釋:A 100 就長下面那樣

也可以讀這篇文章:
突發| 關於美國停止英偉達對華銷售部分產品的解讀20220901
於是乎,競爭出現,比如像甲骨文這樣的挑戰者,再或者如Coreweave 和Lambda Labs 這樣的創業公司,已經通過專門針對大型模型開發商的解決方案迅速發展,在成本、可用性和個性化的支持方面進行競爭,這些公司還公開了更細化的資源抽象(即容器),而大型雲由於GPU 虛擬化的限制,只提供虛擬機實例。
【阿法兔研究筆記註釋:舉個例子,我們想在互聯網上購物、發消息、使用網上銀行,都是在和基於雲的服務器進行交互。也就是說,當我們在用客戶端(移動手機、電腦、Ipad )進行各種操作時,都需要向服務器發出請求,每個操作都需要對應的服務器要處理每個請求,之後返迴響應。
成千上萬個用戶成同時進行的大量的請求和相應,需要很強的計算能力(想想我們在雙十一購物的時候,無數用戶同時瘋狂下單,購物車會突然很卡),這時候,計算能力就很重要了。前面我們說過,虛擬機屬於計算能力的一部分,在我們使用雲服務商的雲計算解決方案時,可以根據企業目前的能力和需求,選擇使用虛擬機。
啥是虛擬機呢?

就是計算機系統的仿真器,可以在一個完全隔離的系統中,提供我們真實計算機的功能。系統虛擬機可以提供一個可以運行完整操作系統的完整系統平台,例如我們用的Windows 系統。 MAC OS 系統等。程序虛擬機就是,可以在仿真器裡單獨運行計算機程序。也就是說,如果購買了雲服務商提供的虛擬機,就像從雲服務商那裡買了一塊地,之後就可以在虛擬機上面安裝各種軟件和運行各種任務,就像我們在自己買來的土地上自由改造,蓋房子一樣。
什麼是容器?容器,我們通常會理解為,飯碗、器皿等可以裝東西的工具。 IT 裡常說的容器技術又是什麼?其實, 這個詞語來自於Linux Container 翻譯,在英文裡,Container 這個單詞有集裝箱、容器的含義(在技術的比喻上,容器主要的含義是偏集裝箱的)。但是由於容器在中文中讀起來更順口,我們就使用中文的容器作為常用詞語。如果想要形象的理解Linux Container 技術,讀到這裡的你,腦海中可以想像出海邊貨運碼頭的集裝箱。
貨運碼頭裡的集裝箱是運載貨物用的,它是一種按規格標準化的鋼製箱子。集裝箱的特點是,都是方形的,並且格式劃一,可以層層疊放。這樣一來,貨物在集裝箱內可以放入巨型貨運輪船,需要運送貨物的生產廠商就可以更加快捷方便地運送貨物,集裝箱的出現,為生產商提供更高效的運輸服務。根據這種方便運輸服務,為了在中文環境能夠容易地使用,計算機世界裡引用了容器這一形象的概念。 】
我們認為,迄今為止生成式AI 的最大贏家,是負責運行絕大部分人工智能工作負載的英偉達Nvidia。
英偉達在2023 財年第三季度的數據中心GPU 收入為38 億美元,其中有很大一部分用於生成式AI 的使用案例。
(GPU:圖形處理器(英語:graphics processing unit,縮寫:GPU),又稱顯示核心、視覺處理器、顯示芯片,是一種專門在個人電腦、工作站、遊戲機和一些移動設備(如平板電腦、智能手機等)上做圖像和圖形相關運算工作的微處理器)
英偉達通過幾十年以來對GPU 生態的投資,和學術界的長期深入應用,圍繞這一業務建立了強大的護城河。最近的分析發現,Nvidia 的GPU 在研究論文中被引用的次數是頂級AI 芯片初創公司的90 倍。
當然,也存在其他硬件的選擇確實存在,包括谷歌TPU;AMD Instinct GPU;AWS Inferentia 和Trainium 芯片;以及Cerebras、Sambanova 和Graphcore 等初創公司。
英特爾公司以自家高端Habana 芯片和Ponte Vecchio GPU 進入市場。但到目前為止,英特爾新芯片中很少有佔據重要市場份額的。其他兩個值得關注的例外是谷歌和台積電,前者的TPU 已經在穩定擴散社區和一些大型GCP 交易中獲得牽引力,後者被認為製造這裡列出的所有芯片,包括Nvidia GPU(英特爾使用自己的工廠和台積電混合製造芯片)。
我們發現:基礎設施是存在有利可圖的、持久的、似乎可以防禦的堆棧層
但是,基礎設施公司需要回答的問題包括:
無狀態工作負載這個怎麼辦?
這個意思就是說,無論你在哪裡租用Nvidia GPU 都是一樣的。大多數人工智能工作負載是無狀態的,即模型推理不需要附加數據庫或存儲(註釋:它不需要外部的存儲或者數據庫,除了模型權重本身)。這意味著人工智能工作負載可能比傳統的應用工作負載更容易在雲端遷移。在這種情況下,雲供應商如何創造粘性,防止客戶跑到更便宜的選擇?
芯片要是不稀缺了,咋辦?
雲提供商和Nvidia 的定價,因為GPU 稀缺供應而可以賣得很貴。有供應商告訴我們,A 100 的上市價格自推出以來,已經持續上升,而這對計算硬件來說是非常不尋常的。那麼,當這種供應限制最終通過增加生產和/或採用新的硬件平台而消除時,對雲供應商有啥影響?
新晉雲能否突破重圍?
我們認為垂直雲將以更專業的產品從三巨頭手中奪取市場份額。到目前為止,在人工智能領域,新來的雲選手,已經通過適度的技術差異化和Nvidia 的支持,獲得了動力。比如說,現有的雲供應商既是他們的最大客戶,也是新興的競爭對手。那麼,對這些新興雲公司來說,長期的問題是,能否克服三大巨頭的規模優勢?
那麼,價值到底在哪部分會累積最多?我們怎麼投,可以捕獲最大的價值?目前還沒有清晰的答案,但是,根據目前掌握的生成式AI 早期數據,結合對早期AI 和機器學習創業公司的經驗,做出以下判斷:
在今天的生成式AI 中,幾乎不存在任何意義上的系統性護城河。我們看到目前的應用程序,產品差異化不大,這種跡象非常明顯。原因在於,這些應用使用的是類似的人工智能模型。所以,目前模型面臨的,是無法判斷它們在更長週期內的差異化到底在哪,它們是在類似的數據集和架構上訓練的;而云供應商同樣,大家的技術基本趨同,因為運行相同的GPU;甚至硬件公司,也會在相同的工廠生產芯片。
當然,
仍有標準護城河——規模護城河存在,比如說同樣的創業公司,我比你更能融資,我的融資能力更強;或者供應鏈方面的護城河,我有GPU,你沒有;或者是生態系統護城河,比如說我軟件的用戶比你多,且開始的早,我有時間和用戶規模壁壘;再或者算法護城河,比如說我的算法就是比你更強大。銷售領域的護城河,我就是比你會賣貨,我是渠道上的佼佼者;再或者就是數據這塊的護城河,比如我收集的數據比你多。
但是,這些護城河都無法在長期上具備優勢,且不可持久。而且,目前要判斷強大的、直接的網絡效應到底會在這些堆棧的那一層佔據優勢,目前還為時過早。
根據現有的數據,目前還無法判斷在生成式人工智能領域,是否會出現長期的、贏家通吃的機會。
聽起來有些奇怪,但對我們來說,這是好消息。
正是因為整個市場的潛在規模難以把握,它和軟件和所有人的嘗試均息息相關。我們預計會有很多參與這個市場的選手,大家會在生成式AI 堆棧的各個層面進行良心競爭。我們期望,橫向和縱向都能跑出來成功的公司。
但是,這是由終端市場和用戶決定的。例如,如果終端產品的主要差異化在於人工智能技術本身,那麼垂直化(即把麵向用戶的應用程序與本土模型緊密結合這塊)領域很可能會勝出。


