
Khi suy luận trở thành nguồn lực khan hiếm, giá trị sẽ được ai nắm giữ
- Quan điểm cốt lõi: Nút thắt về sức mạnh tính toán của ngành AI đã chuyển từ giai đoạn huấn luyện sang giai đoạn suy luận, và thị trường đang định giá lại điều này. Giá trị sẽ không còn chỉ thuộc về các công ty sở hữu nhiều GPU nhất, mà sẽ lắng đọng ở các tầng trung gian có khả năng tổng hợp, định tuyến và tối ưu hóa sức mạnh tính toán suy luận phân mảnh, như các nền tảng phi tài sản nặng (asset-light) Hyperbolic.
- Các yếu tố then chốt:
- **Suy luận trở thành nút thắt mới**: Thị trường nhận ra suy luận là chi phí định kỳ (mở rộng theo mức độ sử dụng), chứ không phải là chi phí vốn một lần của quá trình huấn luyện. J.P. Morgan ước tính quy mô thị trường suy luận lớn gấp 10-50 lần so với huấn luyện, bằng chứng là Anthropic đã tiếp quản trung tâm dữ liệu để chuyên dụng cho suy luận.
- **Sự xác nhận chuyển hướng của các ông lớn trong ngành**: Nvidia đã tái cấu trúc báo cáo tài chính xoay quanh việc "phục vụ token", chia suy luận thành hai mặt trận: điện toán đám mây và điện toán biên, đồng thời ra mắt chip có hiệu suất suy luận được cải thiện vượt bậc. Đợt IPO của Cerebras đã nhận được lượng đăng ký mua vượt mức gấp 20 lần nhờ kiến trúc chip tập trung vào tăng tốc suy luận.
- **Câu trả lời cho "Vấn đề 600 tỷ đô la"**: Khoảng cách lợi nhuận đầu tư AI mà Sequoia đưa ra sẽ được lấp đầy bởi nhu cầu suy luận ngày càng tăng, chứ không phải bởi nhu cầu huấn luyện. Nhu cầu thường xuyên (常态化) của suy luận sẽ hấp thụ lượng đầu tư quá mức vào GPU trước đó.
- **Định vị giá trị của Hyperbolic**: Là công ty duy nhất hoạt động trên cả ba lớp: cho thuê GPU, triển khai và API mô hình, Hyperbolic kiếm lợi nhuận bằng cách tổng hợp tài nguyên điện toán đa đám mây và cung cấp dữ liệu định giá theo thời gian thực. Mô hình phi tài sản nặng (asset-light) của nó cho phép thu về chênh lệch giá tốt hơn khi tình trạng dư thừa sức mạnh tính toán xảy ra.
- **Biên lợi nhuận mỏng của tầng ứng dụng và giá trị của tầng trung gian**: Các ứng dụng suy luận như Venice bị chi phối bởi chi phí sức mạnh tính toán đầu vào, dẫn đến lợi nhuận rất thấp. Mô hình kinh tế của chúng cho thấy chi phí tính toán cơ bản (底层) là chi phí chính, điều này củng cố giá trị của tầng tổng hợp (aggregation layer) – nơi kiểm soát việc định tuyến và định giá sức mạnh tính toán, như Hyperbolic.
Original Author: Frank Fu
Original Source: IOSG Ventures
The gap David Cahn identified in 2023 was never filled on the training side. It was filled on the inference side, and the market has only begun pricing this in over the past few weeks. As Nvidia restructures its financial reporting around "serving tokens" and Cerebras' IPO receives a 20x oversubscription, the bottleneck debate is over. The real question has shifted: when inference becomes a scarce resource, where will value accrue in the compute stack?
Follow the GPU: From a $200 Billion Problem to a $600 Billion Problem
In 2023, Sequoia's David Cahn posed the question hanging over the entire AI buildout: the "$200 billion problem." For every dollar spent on a GPU, roughly another dollar is spent powering it in a data center. Therefore, annual GPU CapEx meant these chips ultimately had to generate around $200 billion in revenue to recoup the investment. Even with generous assumptions for AI revenue, he still found a gap of over $125 billion between "investment" and "actual end-customer spend." The concern was straightforward: GPUs were being overbuilt ahead of real demand.
A year later, the gap hasn't narrowed; it's widened. In Cahn's 2024 follow-up, as hyperscaler CapEx ballooned, he redefined it as the "$600 billion problem." The bearish logic converges into a familiar shape: overbuilding leads to oversupply, and oversupply burns capital.
Both articles were essentially asking the same thing: Who fills this gap? The answer never appeared on the "training" side of the ledger. It appeared on the inference side, and the market has only started pricing this in over the past few weeks.
Cerebras IPO and the Inference Squeeze
Cerebras went public on Thursday. The IPO was 20x oversubscribed, pricing at nearly double the final mark-up from Wednesday. The demand wasn't driven by bets on the "next Nvidia killer," but something simpler: the market is beginning to realize that in AI, the real bottleneck is inference, not training.
Cerebras' core competency is a chip architecture that makes inference extremely fast. Not training, but inference. This is what excites Wall Street. The inference market is recurring; it expands with usage. Every time Claude answers a question, every time an agent executes a task, it consumes compute. Training happens once; inference never stops.
J.P. Morgan estimates the inference market size to be 10 to 50 times that of training. When machines start executing tasks issued by other machines – an agentic expansion – inference demand no longer scales with user numbers, but with compute itself.
Nvidia Redraws the Map: Inference Takes the Spotlight
If Cerebras was the market's awakening, Nvidia's latest quarterly earnings were confirmation from the top of the chain. On the latest earnings call, Jensen Huang made the unspoken explicit: AI demand is growing parabolically. The reason is simple: agentic AI has arrived. Mainstream AI has transitioned from one-shot inference to logical reasoning, and now to the agent stage, where it calls tools and orchestrates tasks autonomously. Huang stated, "Tokens are now profitable." In the AI era, compute is revenue and profit.
This reshapes the entire industry. Training is a one-time cost to build a model; inference is the recurring cost of running it. The bottleneck today is inference, not training.
Nvidia wrote this judgment into its own financial reporting structure. It now reports by two platforms instead of one: Data Center and Edge Computing. Data Center (~$75 billion for the quarter, +92% YoY) is further broken down into Hyperscale (~$38 billion, +12% QoQ) and ACIE (AI Cloud, Industrial & Enterprise, ~$37 billion, +31% QoQ). The entirely new line is Edge Computing: $6.4 billion, +29% YoY, covering the endpoints where agentic AI and physical AI actually run, like PCs, workstations, AI-RAN base stations, robots, and cars.
Edge currently accounts for less than 8% of total revenue, but Nvidia has elevated it to a "second platform" alongside Data Center. The signal is clear: inference is splitting into two fronts – cloud inference within data centers, and endpoint inference at the edge. AI needs to see, move, and act in the physical world. The roadmap follows the same logic: Vera Rubin, shipping from Q3, offers up to 35x the inference throughput of Blackwell; Huang also gave a new $200 billion TAM for the Vera CPU designed for agentic workloads. Every frontier model company is expected to fully transition to it on day one.
When the world's most valuable company restructures its financial disclosures around "serving tokens," the bottleneck debate is settled. The rest of this article discusses who captures value when inference (not training) becomes the scarce resource.
First, a scope clarification. Among these two fronts, this article discusses cloud inference – rented data center GPUs that provide external API token services. Endpoint inference runs on local chips within the device itself (Nvidia's Jetson, RTX, Drive, AI-RAN), completely bypassing the underlying GPU rental and aggregation stack. Consider this a tailwind amplifying the entire inference economy and corroborating the bottleneck thesis, rather than the market Hyperbolic and Venice operate in, which are entirely on the cloud front.
The Squeeze Has Arrived
Anthropic is the canary in the coal mine. Usage far exceeds pre-provisioned capacity, with complaints about Claude being "lobotomized" flooding the internet – including rate-limited replies, slower reasoning, and compressed context windows. The solution is brute-force compute: in May 2026, Anthropic took over the entire Colossus 1 data center from SpaceX, with 220k+ Nvidia GPUs and 300+ megawatts, dedicating it entirely to inference, not training.
This capacity unlocked a chain of limit changes, each a signal. On May 6, Anthropic doubled Claude Code's five-hour limit, removed peak-hour rate limits, and significantly raised Opus' API rate limits. On May 13, it further increased Claude Code's weekly limit by 50% (until July 13). Then, starting June 15, it did the opposite of "generous": it cut agentic and programmatic usage (Agent SDK, headless mode `claude -p`, CI pipelines) from the flat subscription into a separate metered credit pool ($20 to $200 per month, charged at API rates). This last step encapsulates the entire argument in one action: agents consume inference far faster than a flat subscription was ever designed to bear, so it must be priced as the "recurring cost" it truly is.
Training is a one-time capital expenditure. Inference is a recurring operational cost, compounding with every new user and every new agent.
The Stack: Six Layers, One Bottleneck
Every AI application sits on a supply chain starting from a TSMC fab and ending at an API endpoint:

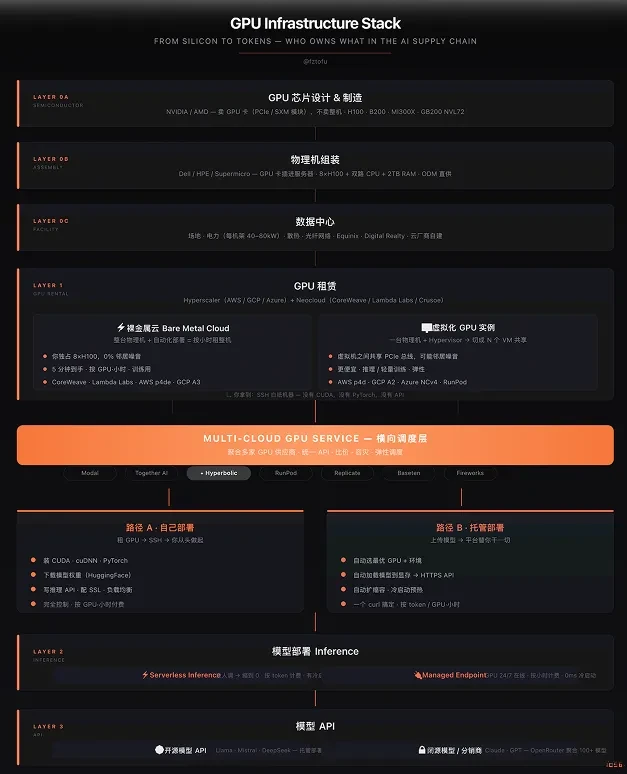
Most companies own only one layer. Nvidia owns silicon, CoreWeave owns bare metal, Together AI owns inference optimization, and OpenRouter owns model API routing.
Except for one.
Hyperbolic: The Only Company Spanning Three Layers
Hyperbolic launched its on-demand GPU marketplace in June 2025. In its first few months, it surpassed 200k+ developers, with adoption covering frontier AI labs, search, and large consumer platforms.
What's interesting is its architecture.
Hyperbolic doesn't own a single GPU itself. Every card comes from neoclouds and data centers, including CoreWeave, Lambda Labs, Nebius, and smaller operators with idle capacity. This sounds like a weakness, but it's actually a moat.
By sitting between GPU supply and consumption, Hyperbolic sees real-time data others don't. It knows who is buying which GPU at what price and when. It sees oversupply before it becomes public, and demand surges before they hit the market.
Today, the moat itself is this multi-cloud aggregation. Hyperbolic stitches together fragmented capacity from dozens of independent clouds and data centers into a standardized, unified pool. This allows developers to rent the cheapest available GPU anywhere without negotiating with each operator or managing a dozen accounts. The more clouds it integrates, the deeper the liquidity, the richer the pricing data. Looking ahead, the team is exploring how to use this data to model GPU price curves and eventually deploy its own capital to smooth supply and demand, acting as a market maker for physical compute; but this goal is still early stage. What compounds in the present is the aggregation layer.
This is the flywheel:
- Integrate more clouds → More aggregated supply
- More supply → Deeper market and real-time pricing data
- Better data → Smarter routing today, pricing models in the long run
- Better liquidity and prices → More developers → More clouds wanting to integrate
No other company is attempting this. Hyperbolic is the only one simultaneously spanning the GPU rental layer, the deployment layer, and the model API layer.
Venice as a Mirror
Venice is the clearest representation of the inference economy at the application layer, and a useful contrast to Hyperbolic's position. It's a privacy-first inference application: an OpenAI-compatible API plus consumer-facing subscriptions (Free / Pro / Pro+ / Max), routing requests to ~75 models, roughly two-thirds of which are open-source or self-hosted (Llama, Mistral, Qwen, DeepSeek), with the rest being anonymous pass-through to closed-source frontier models. The key point is that Venice doesn't own meaningful compute itself. It rents from undisclosed GPU partners and confidential computing providers (NEAR AI Cloud, Phala), and pays frontier labs for pass-through. So its true cost of revenue is inference compute, not SaaS hosting.
What Venice truly sells is privacy. "Privacy-ization" here doesn't mean turning public compute into private property; it's wrapping commoditized inference with guarantees: no data retention, no training on data, anonymized requests, with some load running in TEEs where even the operator can't see plaintext. The underlying compute is a commodity; the markup comes from this privacy wrapper. And this guarantee is layered, not uniform: for open-source models running on self-controlled or TEE GPUs, it achieves near end-to-end confidential computing. But for anonymous pass-through to closed-source models like Claude or GPT, privacy is just identity stripping – the frontier lab still processes the raw prompt. So the strongest privacy covers only the open-source portion; the frontier model part is "anonymous" rather than "truly confidential." Venice's gross margin = subscription price − inference costs paid downstream. The premium it can charge over raw API prices is almost entirely supported by this privacy premium, which is also why it's low-margin and constrained by frontier pass-through pricing.
The token design packages this inference demand. Venice runs on two tokens: VVV (staking and platform access) and DIEM, an inference credit, with each DIEM roughly equivalent to $1 worth of compute per day. Paid subscriptions trigger a programmatic buyback-and-burn of VVV (approx. $2 / $5 / $10 for Pro / Pro+ / Max respectively), with emissions decreasing on a fixed schedule: 6M → 5M → 4M VVV monthly, dropping to 3M on July 1. The buybacks are real but discretionary and still small: ~$103k burned each in April and May, slowly climbing to ~$110k in June, well below the ~$200k per month mark.
Fundamentals are healthier than the headline suggests. The publicly circulated "$70 million ARR" figure is almost certainly the result of mistaking subscription renewals for net new customer acquisition; a defensible observable range is closer to $6 million to $15 million ARR. Below this, traction is real: ~136k token holders, ~9.9 million monthly website visits (~330k daily), with new Pro subscriptions hovering around ~1,400 per day. This is a real business, but a low-margin one, with its economics constrained by the compute it purchases.
This is precisely why Hyperbolic sits one layer above. If Venice is a gas station, Hyperbolic is the refinery. Venice buys compute from the same constrained supply everyone depends on; Hyperbolic aggregates and standardizes that fragmented supply, then sells it to Venice and all players like it. As inference demand grows, value doesn't just accrue to applications consuming compute, but critically, to the layer that aggregates and routes compute, and captures the cost of revenue these applications pay.
Why This Matters Now
Nvidia restructured its finances around "serving tokens." Cerebras' IPO proves the market understands inference is the bottleneck. Anthropic's scramble for capacity proves it's a real problem. Agentic and physical AI will amplify demand by orders of magnitude, across both cloud and edge fronts.
And it also closes the loop on the "$600 billion problem" from another side. Cahn's bearish logic – overbuilding leading to oversupply – will likely be validated. But oversupply is precisely the best market for an asset-light aggregator. When GPU prices decline and supply fragments across dozens of clouds, the player who holds no hardware and routes every workload to the cheapest available card profits from the spread, while operators holding depreciating GPUs take the losses. Hyperbolic is long on oversupply, not shorting it.
The company that ultimately wins won't be the one with the most GPUs. It will be the one that can tell you which GPUs are where, at what price, and route every workload to the place that can run it at the lowest cost.
Hyperbolic is building exactly that. It doesn't own GPUs itself. It's pure software, spanning three layers deep, but building the ultimate aggregation layer for inference compute.


