
จากทำความรู้จัก Skill ไปสู่การเข้าใจวิธีสร้าง Crypto Research Skill
- มุมมองหลัก: บทความวิเคราะห์เจาะลึกเทคโนโลยี Agent Skill ที่ Anthropic เปิดตัว อธิบายกระบวนการพัฒนาจากฟีเจอร์เฉพาะของ Claude ไปสู่รูปแบบการออกแบบพื้นฐานทั่วไปในสาขา AI Agent และเน้นวิเคราะห์ความแตกต่างโดยพื้นฐานระหว่างมันกับโปรโตคอล MCP รวมถึงคุณค่าของการประยุกต์ใช้ร่วมกันในสถานการณ์การวิจัยการลงทุนด้านคริปโต
- องค์ประกอบสำคัญ:
- Agent Skill เปิดตัวโดย Anthropic และเปิดเป็นมาตรฐานในปลายปี 2025 มีเป้าหมายเพื่อทำให้ความสามารถของ AI เป็นโมดูลาร์ โดยใช้รูปแบบ "เอกสารคำอธิบาย" เพื่อเพิ่มความเสถียรและประสิทธิภาพในการดำเนินงาน ลดความซ้ำซ้อนในการปรับแต่ง Prompt
- กลไกการทำงานหลักคือ "การเปิดเผยแบบค่อยเป็นค่อยไป" โหลดตามความต้องการเป็นสามชั้น (เมตาดาต้า คำสั่ง ทรัพยากร) ประหยัด Token สูงสุดและรักษาประสิทธิภาพ โดย Reference ใช้สำหรับการอ่านความรู้ภายนอกที่ถูกกระตุ้นตามเงื่อนไข และ Script ใช้สำหรับการรันโค้ดภายนอก
- Agent Skill และ MCP มีความแตกต่างโดยพื้นฐาน: MCP เป็น "ท่อข้อมูล" ที่เป็นมาตรฐาน รับผิดชอบการเชื่อมต่อแหล่งข้อมูลภายนอก ในขณะที่ Skill เป็น "แนวทางปฏิบัติ (SOP)" รับผิดชอบกำหนดวิธีที่โมเดลประมวลผลข้อมูล
- ในการปฏิบัติจริงของการวิจัยการลงทุนด้านคริปโต ทั้งสองสามารถร่วมมือกันอย่างแข็งแกร่ง ก่อให้เกิดรูปแบบ "MCP จัดหาน้ำ, Skill กลั่นเหล้า" เช่น ใช้ MCP รับข้อมูลบนเชนและข่าวสาร จากนั้นใช้ Skill จัดลำดับเวิร์กโฟลว์เพื่อสร้างรายงาน Due Diligence หรือค้นพบสัญญาณการซื้อขายโดยอัตโนมัติ
- การผสมผสานนี้สามารถสร้างเวิร์กโฟลว์มืออาชีพที่มีระบบอัตโนมัติสูง เช่น การตรวจสอบ Due Diligence สกุลเงินใหม่อย่างรวดเร็ว (ตรวจสอบข้ามจากทวิตเตอร์, เซนติเมนต์, การวิเคราะห์ AI) และการค้นพบสัญญาณการซื้อขายที่ขับเคลื่อนโดยเหตุการณ์แบบเรียลไทม์ (ผ่านการฟัง WebSocket สตรีมข่าวและเปิดการแจ้งเตือน)
ผู้เขียนต้นฉบับ: @BlazingKevin_ , นักวิจัย Blockbooster
1. พื้นหลังและการวิวัฒนาการของ Agent Skill
ในปี 2025 สายงาน AI Agent กำลังอยู่ที่จุดเปลี่ยนสำคัญจากการ "แนวคิดทางเทคนิค" สู่ "การนำไปปฏิบัติจริง" ในกระบวนการนี้ การสำรวจของ Anthropic เกี่ยวกับการห่อหุ้มความสามารถ ได้นำไปสู่การเปลี่ยนแปลงกระบวนทัศน์ระดับอุตสาหกรรมอย่างไม่คาดคิด
วันที่ 16 ตุลาคม 2025 Anthropic ได้เปิดตัว Agent Skill อย่างเป็นทางการ ในตอนแรก การกำหนดตำแหน่งคุณลักษณะนี้ของทางการดูเหมือนจะระมัดระวังมาก — มันถูกมองว่าเป็นเพียงโมดูลเสริมเพื่อปรับปรุงประสิทธิภาพของ Claude ในงานเฉพาะทางแนวตั้ง (เช่น ตรรกะโค้ดที่ซับซ้อน การวิเคราะห์ข้อมูลเฉพาะบางอย่าง)
อย่างไรก็ตาม การตอบรับจากตลาดและนักพัฒนานั้นเกินความคาดหมาย ทุกคนค้นพบอย่างรวดเร็วว่า การออกแบบ "โมดูลาร์ของความสามารถ" นี้แสดงให้เห็นถึงความสามารถในการแยกส่วนและความยืดหยุ่นสูงในการปฏิบัติงานจริง มันไม่เพียงลดความซ้ำซ้อนในการปรับแต่ง Prompt เท่านั้น แต่ยังเพิ่มความเสถียรของ Agent ในการทำงานเฉพาะทางได้อย่างมาก ประสบการณ์นี้ทำให้เกิดปฏิกิริยาลูกโซ่ในชุมชนนักพัฒนาอย่างรวดเร็ว ในช่วงเวลาสั้น ๆ เครื่องมือผลิตภาพชั้นนำและสภาพแวดล้อมการพัฒนาแบบรวม (IDE) รวมถึง VS Code, Codex, Cursor ได้ติดตามและให้การสนับสนุนพื้นฐานสำหรับสถาปัตยกรรม Agent Skill ตามลำดับ
เมื่อเผชิญกับการขยายตัวตามธรรมชาติของระบบนิเวศ Anthropic ได้จับคุณค่าพื้นฐานสากลของกลไกนี้ วันที่ 18 ธันวาคม 2025 Anthropic ได้ตัดสินใจที่เป็นหมุดหมายสำคัญของอุตสาหกรรม: เปิดตัว Agent Skill เป็นมาตรฐานเปิดอย่างเป็นทางการ
ต่อมาในวันที่ 29 มกราคม 2026 ทางการได้เผยแพร่คู่มือการใช้งาน Skill อย่างละเอียด ซึ่งได้ทำลายอุปสรรคทางเทคนิคของการนำกลับมาใช้ข้ามแพลตฟอร์มและข้ามผลิตภัณฑ์ในระดับโปรโตคอลอย่างสมบูรณ์ ชุดการดำเนินการเหล่านี้บ่งชี้ว่า Agent Skill ได้หลุดออกจากป้าย "ของเสริมเฉพาะสำหรับ Claude" อย่างสมบูรณ์ และวิวัฒนาการเป็นรูปแบบการออกแบบพื้นฐานสากล ในวงการ AI Agent ทั้งหมด
ณ จุดนี้ คำถามหนึ่งปรากฏขึ้น: Agent Skill ที่ทำให้บริษัทใหญ่และนักพัฒนาหลักต่างหันมารับใช้ กำลังแก้ไขจุดบกพร่องหลักอะไรในระดับวิศวกรรมพื้นฐาน? และมันมีความแตกต่างและความสัมพันธ์เชิงร่วมที่สำคัญอย่างไรกับ MCP ที่กำลังได้รับความนิยมในปัจจุบัน?
เพื่อชี้แจงปัญหาเหล่านี้ให้กระจ่าง และสุดท้ายนำไปประยุกต์ใช้ในการสร้างการวิจัยและการลงทุนในอุตสาหกรรมคริปโตจริง บทความนี้จะสำรวจประเด็นต่อไปนี้อย่างเป็นขั้นเป็นตอน:
- การวิเคราะห์แนวคิด: สาระสำคัญของ Agent Skill และการสร้างโครงสร้างพื้นฐาน
- เวิร์กโฟลว์พื้นฐาน: เผยให้เห็นตรรกะการทำงานและการไหลของการดำเนินการพื้นฐาน
- กลไกขั้นสูง: วิเคราะห์การใช้ขั้นสูงสองแบบคือ Reference และ Script อย่างลึกซึ้ง
- กรณีศึกษาจริง: วิเคราะห์ความแตกต่างพื้นฐานระหว่าง Agent Skill กับ MCP และสาธิตการประยุกต์ใช้ร่วมกันในสถานการณ์วิจัยและการลงทุน Crypto
2. Agent Skill คืออะไรและการสร้างพื้นฐาน
Agent Skill คืออะไรกันแน่? พูดง่าย ๆ มันคือ"เอกสารคำอธิบายเฉพาะ" ที่โมเดลภาษาขนาดใหญ่สามารถเปิดอ่านได้ตลอดเวลา
ในการใช้ AI ในชีวิตประจำวัน เรามักประสบปัญหาหนึ่ง: ทุกครั้งที่เริ่มการสนทนาใหม่ เราต้องวางข้อกำหนดยาว ๆ ซ้ำอีกครั้ง และ Agent Skill ถูกสร้างขึ้นมาเพื่อแก้ไขปัญหานี้

ยกตัวอย่างจริง: สมมติว่าคุณต้องการสร้าง Agent "ผู้ช่วยบริการลูกค้าอัจฉริยะ" คุณสามารถเขียนกฎใน Skill ได้อย่างชัดเจนว่า: "เมื่อพบลูกค้าร้องเรียน ขั้นแรกต้องปลอบโยนอารมณ์ และห้ามสัญญาชดเชยโดยพลการ" อีกตัวอย่างหนึ่ง คุณมักต้องการทำ "สรุปการประชุม" คุณสามารถกำหนดเทมเพลตใน Skill โดยตรงว่า: "ทุกครั้งที่ส่งออกสรุปการประชุม ต้องจัดรูปแบบตามสามส่วนนี้อย่างเคร่งครัด: 'ผู้เข้าร่วมประชุม', 'ประเด็นหลัก', 'การตัดสินใจสุดท้าย'"
เมื่อมี "เอกสารคำอธิบาย" นี้ คุณไม่จำเป็นต้องวางคำสั่งยาว ๆ ซ้ำทุกครั้งในการสนทนา เมื่อโมเดลภาษาขนาดใหญ่ได้รับงาน มันจะเปิดอ่าน Skill ที่เกี่ยวข้องโดยอัตโนมัติ และรู้ทันทีว่าต้องใช้มาตรฐานอะไรในการทำงาน
แน่นอน "เอกสารคำอธิบาย" เป็นเพียงการเปรียบเทียบที่เรียบง่ายเพื่อให้เข้าใจง่าย ที่จริงแล้ว Agent Skill สามารถทำได้มากกว่าการกำหนดรูปแบบเพียงอย่างเดียว ฟังก์ชันขั้นสูง "สุดยอด" ของมันจะถูกแยกวิเคราะห์โดยละเอียดในบทต่อ ๆ ไป แต่ในขั้นเริ่มต้น คุณสามารถมองว่ามันเป็นคู่มือคำอธิบายงานที่มีประสิทธิภาพได้
ต่อไป เราจะใช้สถานการณ์ "สรุปการประชุม" ที่ทุกคนคุ้นเคย เพื่อดูวิธีการสร้าง Agent Skill อย่างเป็นรูปธรรม กระบวนการทั้งหมดไม่จำเป็นต้องมีความรู้การเขียนโปรแกรมที่ซับซ้อน
ตามการตั้งค่าของเครื่องมือหลักในปัจจุบัน (เช่น Claude Code) เราต้องค้นหา (หรือสร้างใหม่) โฟลเดอร์ชื่อ .claude/skill ในไดเรกทอรีผู้ใช้ของคอมพิวเตอร์ ซึ่งเป็น "ฐานที่ตั้ง" สำหรับเก็บ Skill ทั้งหมด
ขั้นตอนแรก สร้างโฟลเดอร์ใหม่ในไดเรกทอรีนี้ ชื่อโฟลเดอร์นี้คือชื่อของ Agent Skill นี้ ขั้นตอนที่สอง ในโฟลเดอร์ที่เพิ่งสร้าง สร้างไฟล์ข้อความชื่อ skill.md
ทุก Agent Skill ต้องมีไฟล์ skill.md นี้ หน้าที่ของมันคือบอก AI: ฉันคือใคร ฉันทำอะไรได้บ้าง และคุณควรทำงานตามข้อกำหนดของฉันอย่างไร เมื่อเปิดไฟล์นี้ คุณจะพบว่ามันแบ่งออกเป็นสองส่วนอย่างชัดเจน:

ที่ส่วนต้นของไฟล์ มักจะเป็นพื้นที่ที่ล้อมรอบด้วยขีดกลางสั้นสองขีด --- ภายในเขียนเฉพาะสองคุณสมบัติหลัก: name และ description
name: คือชื่อของ Skill นี้ ต้องตรงกับชื่อโฟลเดอร์ด้านนอกทุกประการdescription: นี่เป็นส่วนที่สำคัญอย่างยิ่ง มีหน้าที่อธิบายการใช้เฉพาะของ Skill นี้ให้โมเดลภาษาขนาดใหญ่ฟัง AI จะสแกนคำอธิบายของ Skill ทั้งหมดอย่างต่อเนื่องในแบ็กเอนด์ เพื่อตัดสินว่าคำถามของผู้ใช้ในปัจจุบันควรใช้ Skill ใดในการตอบ ดังนั้น การเขียนคำอธิบายที่แม่นยำและครอบคลุม เป็นเงื่อนไขเบื้องต้นที่สำคัญเพื่อให้แน่ใจว่า Skill ของคุณจะถูกเรียกใช้โดย AI ได้อย่างถูกต้อง
ส่วนที่เหลือใต้ขีดกลาง คือกฎเกณฑ์เฉพาะสำหรับ AI ทางการเรียกส่วนนี้ว่า "คำสั่ง" นี่คือพื้นที่ที่คุณสามารถแสดงออกได้ คุณต้องอธิบายตรรกะที่โมเดลต้องปฏิบัติตามโดยละเอียด ตัวอย่างเช่น ในตัวอย่างสรุปการประชุม คุณสามารถกำหนดที่นี่ด้วยภาษาง่าย ๆ ว่า: "ต้องสรุปรายชื่อผู้เข้าร่วมประชุม หัวข้อที่อภิปราย และการตัดสินใจสุดท้ายที่ดำเนินการ"
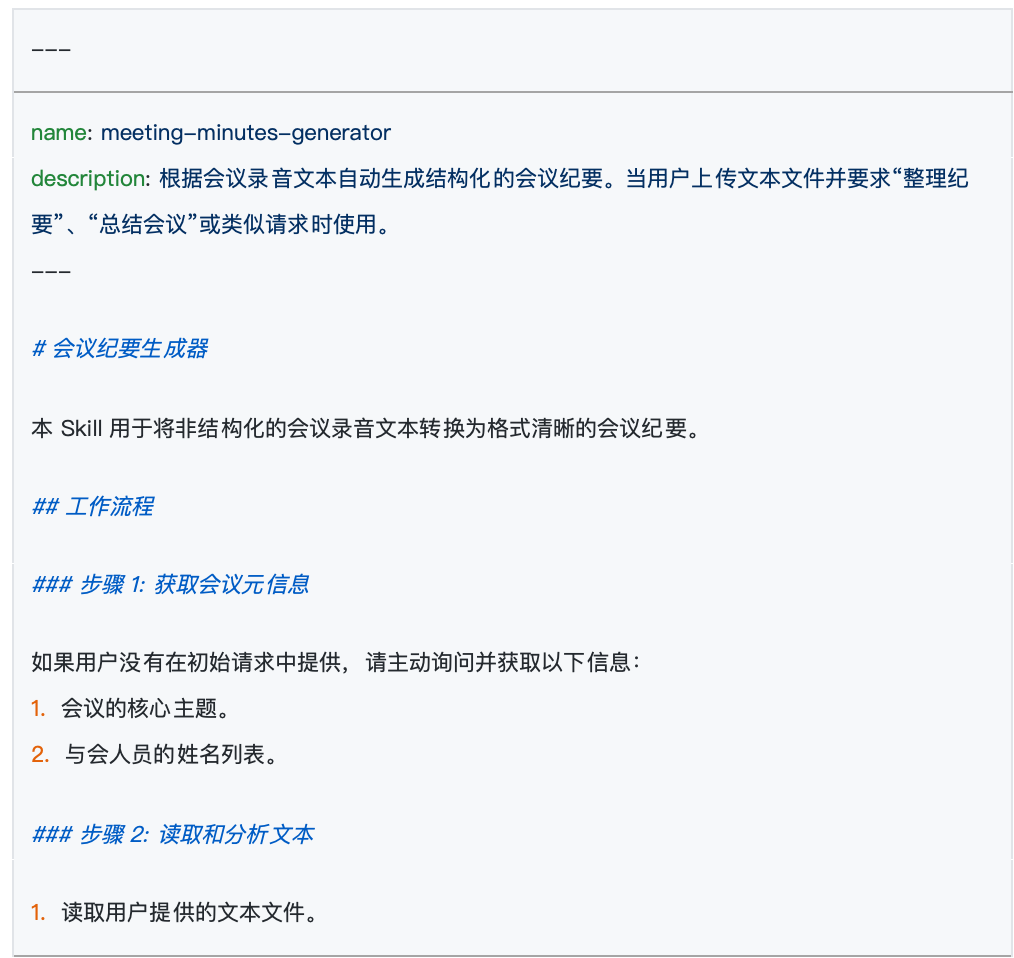

เมื่อทำขั้นตอนเหล่านี้เสร็จ Agent Skill ที่เรียบง่ายแต่ใช้งานได้จริงก็ถือกำเนิดขึ้น
อย่างไรก็ตาม Skill ที่ใช้งานได้ดีจริง ๆ มักเริ่มต้นจากการออกแบบเบื้องต้นที่รอบคอบ ก่อนที่จะพิมพ์ตัวอักษรแรก การกำหนดเป้าหมาย ขอบเขต และมาตรฐานความสำเร็จอย่างชัดเจนล่วงหน้า จะทำให้กระบวนการสร้างของคุณมีประสิทธิภาพมากขึ้น
ขั้นตอนแรกในการสร้าง Skill จริง ๆ แล้วไม่ใช่การคิดว่า "ฉันจะให้ AI ทำอะไรได้บ้าง" แต่เป็นการถามตัวเองว่า: "ฉันต้องการแก้ปัญหาซ้ำซากอะไรในการทำงานประจำวันจริง ๆ?" แนะนำให้กำหนดสถานการณ์ที่ชัดเจน 2 ถึง 3 สถานการณ์ที่ Skill นี้ควรครอบคลุมตั้งแต่แรก

ประการที่สอง คือการกำหนดมาตรฐานความสำเร็จ คุณจะรู้ได้อย่างไรว่า Skill ที่คุณเขียนใช้งานได้ดี? ก่อนเริ่มต้น กำหนดมาตรฐานที่วัดได้หลายประการ เช่น มาตรฐานเชิงปริมาณอาจเป็น "ความเร็วในการประมวลผลเร็วขึ้นหรือไม่" มาตรฐานเชิงคุณภาพอาจเป็น "การตัดสินใจการประชุมที่มันสรุปออกมาทุกครั้งแม่นยำเพียงพอและไม่ขาดตกบกพร่องหรือไม่"
3. เวิร์กโฟลว์การทำงานพื้นฐานของ Agent Skill
หลังจากเข้าใจลักษณะพื้นฐานของ Agent Skill แล้ว เราอาจสงสัยว่า: ในการทำงานจริง "เอกสารคำอธิบาย" ชุดนี้ทำงานอย่างไร?
หากคุณเคยใช้ผลิตภัณฑ์เช่น Manus AI ล่าสุด คุณอาจเคยประสบสถานการณ์เช่นนี้: เมื่อคุณโยนคำถามเฉพาะเจาะจงออกไป AI ไม่ได้เริ่ม "อธิบายยาว" หรือเกิดภาพหลอนทันที แต่ตระหนักได้อย่างเฉียบคมว่า "เรื่องนี้อยู่ภายใต้การจัดการของ Agent Skill เฉพาะบางตัว" ดังนั้น มันจะแสดงข้อความแจ้งเตือนบนอินเทอร์เฟซ ถามว่าคุณอนุญาตให้เรียกใช้ Skill นั้นหรือไม่
เมื่อคุณคลิก "ตกลง" AI จะเปลี่ยนไปเหมือนเป็นคนอื่น ส่งออกผลลัพธ์ที่สมบูรณ์แบบตามกฎที่กำหนดไว้ล่วงหน้าอย่างเคร่งครัด
เบื้องหลังการโต้ตอบที่ดูเรียบง่าย "ขอ-ยินยอม-ดำเนินการ" นี้ แท้จริงแล้วซ่อนเวิร์กโฟลว์การทำงานพื้นฐานที่ประณีตอย่างยิ่ง เพื่ออธิบายกลไกนี้ให้กระจ่าง เราต้องกำหนด "สามบทบาทหลัก" ที่มีส่วนร่วมในการโต้ตอบในกระบวนการทั้งหมดก่อน:
- ผู้ใช้: ผู้ที่เริ่มคำของาน
- เครื่องมือไคลเอ็นต์ (เช่น Claude Code เป็นต้น): "คนกลาง" ที่รับผิดชอบการจัดตารางและการประสานงาน
- โมเดลภาษาขนาดใหญ่: "สมอง" ที่รับผิดชอบการทำความเข้าใจความตั้งใจและสร้างผลลัพธ์สุดท้าย
เมื่อเราป้อนความต้องการ (เช่น: "ช่วยสรุปการประชุมโครงการเช้านี้ให้หน่อย") เข้าสู่ระบบ สามบทบาทนี้จะทำงานร่วมกันอย่างประณีตสี่ขั้นตอนดังนี้:
ขั้นตอนที่หนึ่ง: การสแกนแบบเบา (ส่งข้อมูลเมตา)
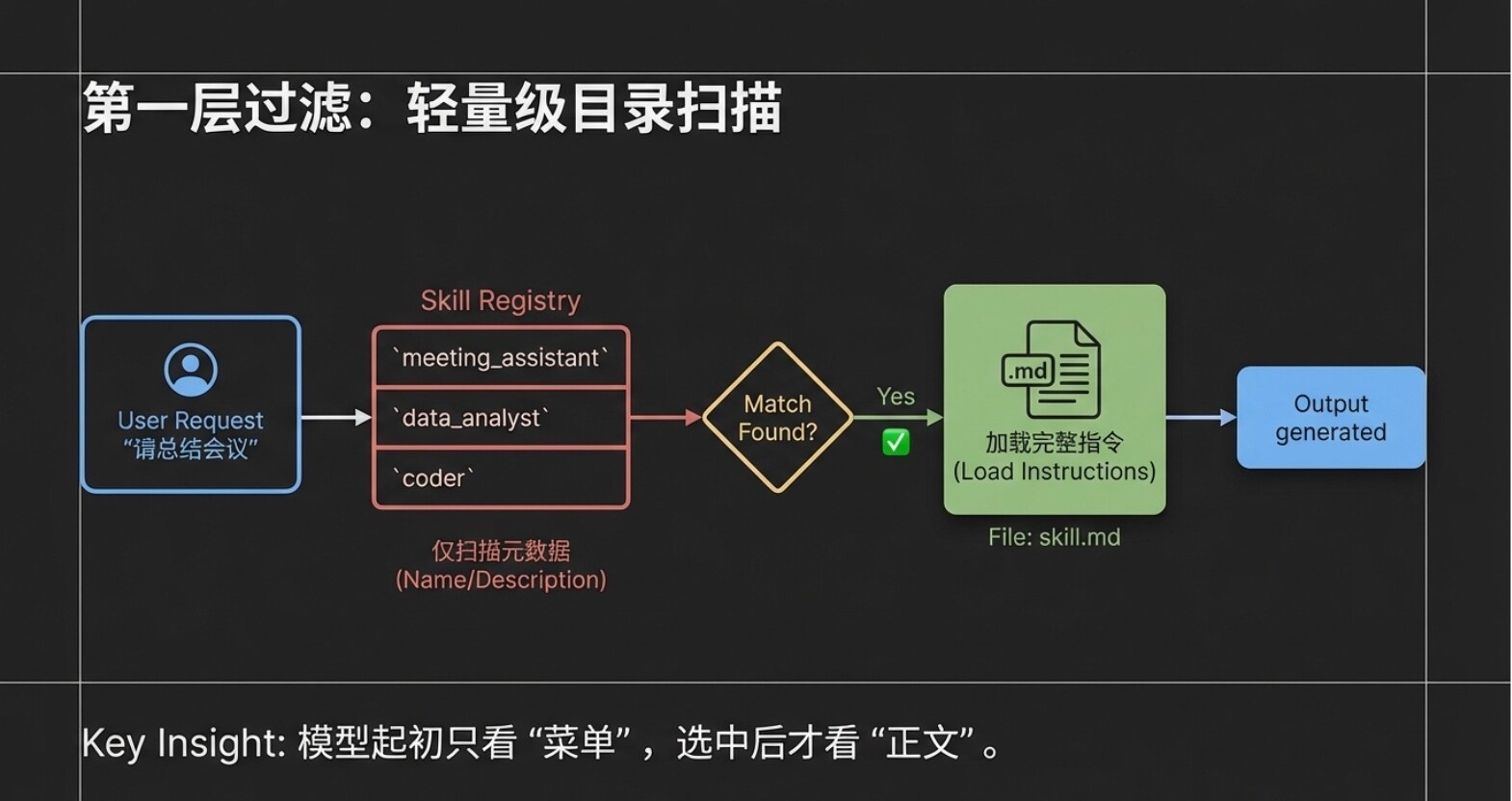
หลังจากผู้ใช้ป้อนคำขอ เครื่องมือไคลเอ็นต์ (Claude Code) จะไม่โยนเอกสารคำอธิบายทั้งหมดให้โมเดลภาษาขนาดใหญ่ในทีเดียว ในทางกลับกัน มันจะส่งคำขอของผู้ใช้ พร้อมกับ"ชื่อ" และ "คำอธิบาย" ของ Agent Skill ทั้งหมดในระบบปัจจุบัน (ซึ่งก็คือชั้นข้อมูลเมตา Metadata ที่กล่าวถึงในบทก่อนหน้า) ให้โมเดลภาษาขนาดใหญ่ คุณสามารถจินตนาการได้ว่า แม้คุณจะติดตั้ง Skill มากกว่าสิบหรือหลายสิบตัว โมเดลภาษาขนาดใหญ่ในเวลานี้ได้รับเพียง "สารบัญแบบเบา" การออกแบบนี้ช่วยประหยัดความสนใจของโมเดลได้อย่างมาก และหลีกเลี่ยงการรบกวนข้อมูลซึ่งกันและกัน
ขั้นตอนที่สอง: การจับคู่ความตั้งใจที่แม่นยำ โมเดลภาษาขนาดใหญ่หลังจากได้รับคำขอผู้ใช้และ "สารบัญ Skill" นี้ จะทำการวิเคราะห์ความหมายอย่างรวดเร็ว มันพบว่าความต้องการของผู้ใช้คือ "สรุปการประชุม" และในสารบัญมี Skill ชื่อ "ผู้ช่วยสรุปการประชุม" อยู่พอดี ซึ่งคำอธิบายของมันสอดคล้องกับงานนั้นอย่างสมบูรณ์ ในเวลานี้ โมเดลภาษาขนาดใหญ่จะแจ้งผลการจับคู่นี้ให้เครื่องมือไคลเอ็นต์ทราบ: "ฉันพบว่างานนี้สามารถแก้ไขด้วย 'ผู้ช่วยสรุปการประชุม'"
ขั้นตอนที่สาม: โหลดคำสั่งสมบูรณ์ตามความต้องการ หลังจากได้รับข้อเสนอแนะจากโมเดลภาษาขนาดใหญ่ เครื่องมือไคลเอ็นต์ (Claude Code) จะเข้าสู่โฟลเดอร์เฉพาะของ "ผู้ช่วยสรุปการประชุม" จริง ๆ เพื่ออ่านเนื้อหาสมบูรณ์ของ skill.md โปรดทราบ นี่เป็นการออกแบบที่สำคัญอย่างยิ่ง: เฉพาะในเวลานี้เท่านั้น เนื้อหาคำสั่งสมบูรณ์จะถูกอ่าน และระบบจะอ่านเฉพาะ Skill นี้ที่ถูกเลือกเท่านั้น Skill อื่น ๆ ที่ไม่ถูกเลือกจะยังคงอยู่ในสารบัญอย่างเงียบ ๆ โดยไม่ใช้ทรัพยากรใด ๆ
ขั้นตอนที่สี่: ดำเนินการอย่างเคร่งครัดและส่งออกการตอบสนอง สุดท้าย เครื่องมือไคลเอ็นต์จะส่ง "คำขอต้นฉบับของผู้ใช้" และ "เนื้อหา skill.md สมบูรณ์ของผู้ช่วยสรุปการประชุม" ให้โมเดลภาษาขนาดใหญ่พร้อมกัน ครั้งนี้ โมเดลภาษาขนาดใหญ่ไม่ได้ทำแบบเลือกคำตอบอีกต่อไป แต่เข้าสู่โหมดการดำเนินการ มันจะปฏิบัติตามกฎที่กำหนดใน skill.md อย่างเคร่งครัด (เช่น: ต้องดึงผู้เข้าร่วมประชุม ประเด็นหลัก การตัดสินใจสุดท้าย) สร้างการตอบสนองที่มีโครงสร้างสูง และให้เครื่องมือไคลเอ็นต์แสดงผลให้ผู้ใช้เห็น
4. กลไกหลักที่หนึ่ง: การโหลดตามความต้องการและ Reference
เวิร์กโฟลว์ในบทก่อนหน้า นำไปสู่กลไกพื้นฐานหลักแรกของ Agent Skill — การโหลดตามความต้องการ
แม้ว่าชื่อและคำอธิบายของ Skill ทั้งหมดจะมองเห็นได้โดยโมเดลภาษาขนาดใหญ่ตลอดเวลา แต่เนื้อหาคำสั่งเฉพาะ จะถูกดึงเข้าสู่บริบทของโมเดลจริง ๆ เฉพาะเมื่อ Skill นั้นถูกเลือกอย่างแม่นยำเท่านั้น
สิ่งนี้ช่วยประหยัดทรัพยากร Token อันมีค่าได้อย่างมาก ลองจินตนาการดู แม้คุณจะติดตั้ง Skill ขนาดใหญ่หลายสิบตัวพร้อมกัน เช่น "เนื้อหาไวรัล", "สรุปการประชุม", "การวิเคราะห์ข้อมูลบนเชน" โมเดลในตอนแรกก็เพียงแค่ทำ "การค้นหาสารบัญ" ที่ใช้ทรัพยากรต่ำมาก เฉพาะเมื่อเลือกเป้าหมายแล้ว ระบบจึงจะป้อน skill.md ที่สอดคล้องกันให้โมเดล "การโหล


