
AI Prediction Record: อยากใช้ AI ทำเงินในตลาดพยากรณ์? แต่มันอาจจะยังอ่านโจทย์ไม่เข้าใจ
- มุมมองหลัก: AI มีประสิทธิภาพเหนือกว่ามนุษย์บางส่วนในตลาดพยากรณ์
- องค์ประกอบสำคัญ:
- Grok อัตราชนะ 75% สูงกว่ามนุษย์ที่ 66.7%
- AI อาศัยการค้นหาและตรรกะ แต่ยังคงมีการตัดสินผิดพลาด
- การพยากรณ์ของ AI ไม่ได้อาศัยข้อมูลตลาด ช่วยหลีกเลี่ยงการตามกระแส
- ผลกระทบต่อตลาด: AI อาจกลายเป็นเครื่องมือวิเคราะห์ตลาดใหม่
- การระบุความทันเวลา: ผลกระทบระยะกลาง
ต้นฉบับ | Odaily (@OdailyChina)
ผู้เขียน | นานจือ (@Assassin_Malvo)

หลังจากหลายสาขาถูกพิสูจน์ว่าไม่จริง ตลาดทำนายกลายเป็นหนึ่งในไม่กี่สาขาในวงการ Crypto ที่ยังคงเติบโตในเชิงบวก เมื่อวันที่ 20 พฤศจิกายน นานจือเริ่มทดลองใช้แนวคิดการหา 'เงินฉลาด' (smart money) ในตลาดทำนาย โดยใช้วิธีเดียวกับการหาเงินฉลาดในตลาด Meme เมื่อปีที่แล้ว และได้ผลลัพธ์ที่ดีในระยะแรก
ต้นเดือนธันวาคม ซึ่งตรงกับช่วงที่ Gemini 3 Pro เปิดตัว ขณะทดสอบโมเดลที่เกี่ยวข้อง ก็เกิดความคิดว่าเราสามารถใช้ AI ในการวิเคราะห์และทำนายตลาดทำนายได้หรือไม่ และให้มนุษย์แข่งกับ AI เพื่อดูว่าฝ่ายไหนทำนายได้แม่นยำกว่า
เมื่อแนะนำตลาดทำนาย มักจะอ้างว่าตลาดนี้ "ให้บุคคลที่มีความเข้าใจใช้เงินจริงในการเดิมพัน" เพื่อขับเคลื่อนตลาดให้เข้าใกล้ "ความจริง" มากขึ้น แต่ก็มีบางคนคิดว่า Crypto + ตลาดทำนายทำให้ "ผู้มีข้อมูลภายใน" สามารถรับผลกำไรจากช่องว่างข้อมูลได้อย่างปลอดภัย นำพาตลาดไปสู่ "ผลลัพธ์ภายใน" ซึ่งโดยพื้นฐานแล้วเป็นการเผชิญหน้าระหว่างสองมุมมอง คือ "ปัญญาของมวลชน" กับ "ความจริงอยู่ในมือของคนส่วนน้อย" ส่วนการทำนายด้วย AI นั้นโน้มเอียงไปทาง "ปัญญาของมวลชน" มากขึ้น ดังนั้นจึงต้องมีความรู้และความเข้าใจจำนวนมหาศาลที่สามารถนำมาใช้ได้
ดังนั้น ในปัญหาการเลือกโมเดล AI จึงเลือกใช้ Gemini และ Grok ในเบื้องต้น เนื่องจากทั้งสองพึ่งพาแพลตฟอร์ม Google และ X ซึ่งสามารถเข้าถึงความรู้และข้อมูลเชิงลึกจำนวนมหาศาลได้โดยตรง ล่าสุด นานจือได้เพิ่มชุดรวม "Doubao + ความรู้จาก Douyin" แต่เนื่องจากหัวข้อการทำนายยังมีไม่มาก จึงจะไม่กล่าวถึงในบทความนี้
กฎพื้นฐาน
- เวอร์ชัน AI: Gemini 2.5 pro (มี Google Search ในตัว), Grok 4 Fast (เรียกใช้ผ่าน OpenRouter เปิดใช้งานฟังก์ชันค้นหาดั้งเดิม)
- การเลือกหัวข้อ: มนุษย์เป็นผู้เลือกหัวข้อเดิมพัน AI ทำตามการทำนาย แต่ยกเว้นส่วน Crypto
- เนื้อหาที่ป้อนเข้า: หัวข้อทางการ (title), คำอธิบายทางการ (Description), คำตอบที่เลือกได้ (จริงๆ แล้วมีแค่ Yes และ No)
หมายเหตุ: หัวข้อของ Polymarket แบ่งออกเป็นหมวดหมู่ใหญ่ Event และหมวดหมู่ย่อย Market หมวดหมู่ใหญ่ Event เป็นหัวข้อกว้างๆ เช่น "ใครจะเป็นประธานเฟดคนต่อไป", "Strategy จะขาย Bitcoin เมื่อไหร่" ภายใต้ Event แต่ละอันจะมีตลาดย่อย N หมวดหมู่ เช่น "Hassett จะเป็นประธานเฟดคนต่อไปหรือไม่", "Strategy จะขาย Bitcoin ภายในวันที่ 31 มีนาคม 2026 หรือไม่" เพื่อให้สอดคล้องกับการทำนายของมนุษย์ ที่นี่เลือก Market เป็นหัวข้อสำหรับการตัดสินของ AI โดยไม่ป้อนตัวเลือกอื่นให้ เช่น ให้ตัดสินเพียงว่า "Hassett จะเป็นประธานเฟดคนต่อไปหรือไม่" แทนที่จะให้เลือกผู้ที่มีแนวโน้มมากที่สุดจากผู้สมัคร N คน
- การออกแบบ Prompt:
- ขอให้ AI ค้นหาข่าวล่าสุด ประกาศทางการ รายงานการวิเคราะห์จากผู้เชี่ยวชาญ
- ขอให้ตัดออก ห้ามใช้ข้อมูลจากตลาดทำนาย
- ตัดสินโดยใช้ตรรกะและเหตุผลบนพื้นฐานของ "หลักฐาน"
- อนุญาตให้แสดงผลเพียง Yes และ No พร้อมอธิบายตรรกะการให้เหตุผลในหนึ่งย่อหน้า
ผลลัพธ์ปัจจุบัน
ในหัวข้อการทำนาย มีการชำระแล้ว 21 รายการ Grok มีอัตราชนะสูงสุดที่ 75% มนุษย์อยู่ที่ 66.7% และ Gemini ต่ำสุดที่ 52.4% ผลลัพธ์ปัจจุบันสามารถดูได้ที่เว็บไซต์ที่เกี่ยวข้อง
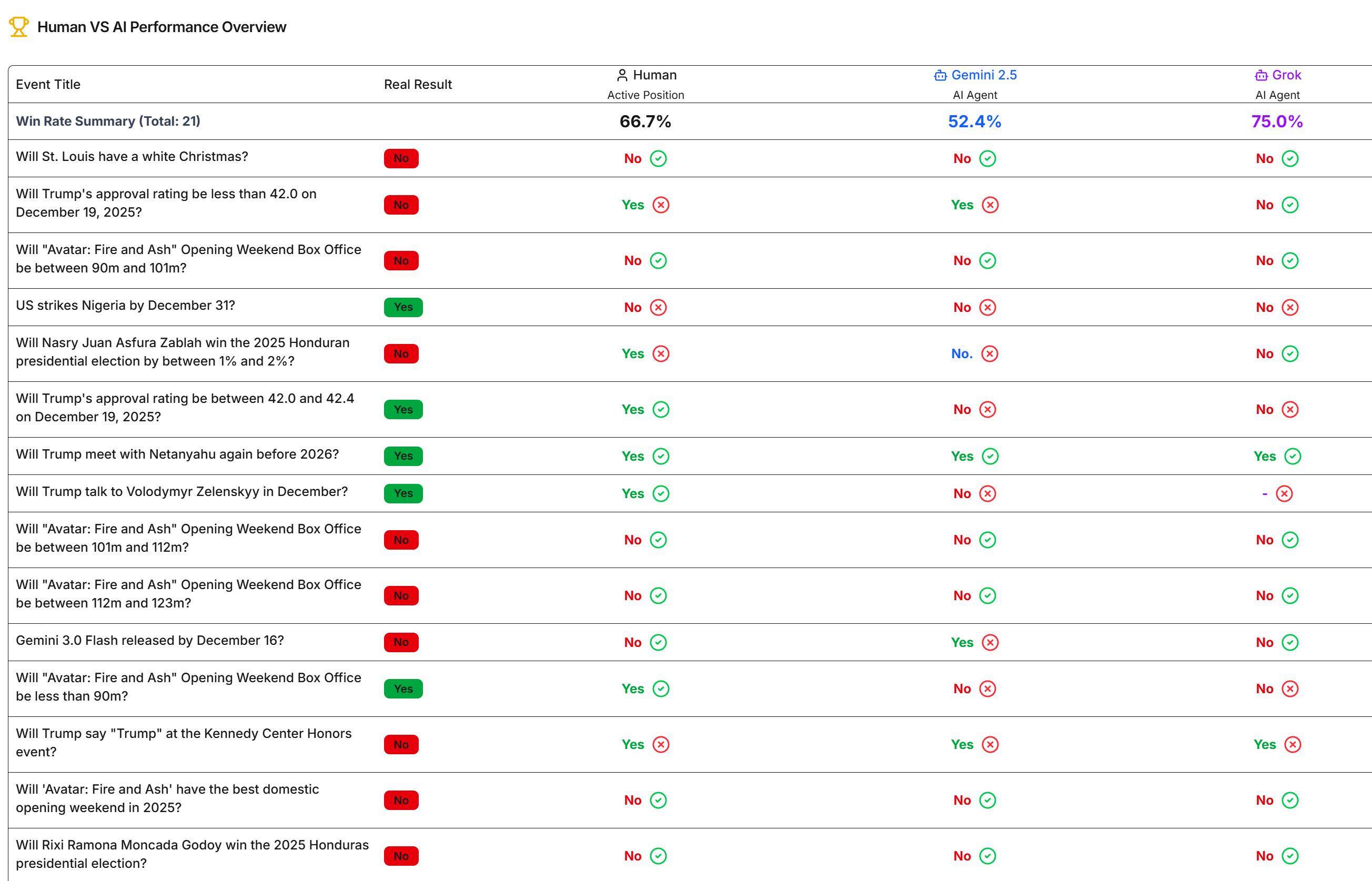
AI ทำอะไรผิด?
Gemini บางครั้งตัดสินเวลาปัจจุบันผิดพลาด
ในหัวข้อ "Will Trump's approval rating hit 35% in 2025?" Gemini ระบุว่าตอนนี้เป็นครึ่งแรกของปี 2025 ดังนั้นทุกอย่างเป็นไปได้ จึงให้คำตอบแบบมั่วๆ
แต่เมื่อผู้เขียนใช้โปรแกรมขอให้ Gemini แสดงเวลาปัจจุบันโดยตรง Gemini สามารถให้คำตอบที่ถูกต้องได้ ยังไม่ชัดเจนว่าทำไมจึงเกิดความเข้าใจผิดเกี่ยวกับเวลาเช่นนี้
AI คิดไม่ลึกพอ
ในหัวข้อ "Gemini 3.0 Flash released by December 16?" Grok อาศัย "ทางการกล่าวถึงเฉพาะ Gemini 3 Pro และรุ่นที่เกี่ยวข้องกับ 2.5 ล่าสุด ไม่ค่อยกล่าวถึง 3 Flash ดังนั้นหลักฐานไม่เพียงพอที่จะตัดสิน" ซึ่งพิจารณาเฉพาะข้อมูลในปัจจุบัน
ขณะที่ Gemini ชี้ให้เห็นว่า "Gemini 1.0 เปิดตัวในเดือนธันวาคม 2023 และเวอร์ชันทดลองของ Gemini 2.0 Flash เปิดตัวในเดือนธันวาคม 2024 ดำเนินตามรูปแบบนี้ การเปิดตัวเวอร์ชัน 3.0 ในปลายปี 2025 เป็นเรื่องที่มีตรรกะ" และยังค้นพบ "การสาธิตที่รั่วไหลเกี่ยวกับ 'Gemini 3.0 Flash' ที่แพร่กระจายในชุมชนออนไลน์ล่าสุด (14 ธันวาคม 2025) ซึ่งเพิ่มความเป็นไปได้ที่มันจะเปิดตัวสู่สาธารณะในเร็วๆ นี้"
แม้ว่าจากข้อสรุปแล้ว คำตอบของ Gemini กลับกลายเป็นผิด แต่ในหัวข้อนี้สามารถเห็นได้ชัดเจนว่าขอบเขตของข้อมูลที่ทั้งสองพึ่งพานั้นแตกต่างกันอย่างเห็นได้ชัด
AI อ้างอิงสามัญสำนึกมากกว่าอ้างอิงหลักฐาน+ตรรกะ
ในหัวข้อ "Trump approval Up or Down this week?" Gemini ระบุว่า "การทำนายคะแนนการอนุมัติต่อสัปดาห์เดียวในอีกกว่าหนึ่งปีข้างหน้านั้นมีความไม่แน่นอนสูง" ซึ่งครั้งแรกเกิดสถานการณ์ "การตัดสินเวลาผิดพลาด" อีกครั้ง จากนั้น Gemini ระบุว่า "ในสัปดาห์ธรรมดาใดๆ ความน่าจะเป็นของเหตุการณ์ที่ทำให้คะแนนการอนุมัติลดลงเล็กน้อย อาจสูงกว่าความน่าจะเป็นของเหตุการณ์เชิงบวกที่สามารถเพิ่มคะแนนการอนุมัติได้อย่างมีนัยสำคัญเล็กน้อย" ดังนั้นความเป็นไปได้ที่คะแนนการอนุมัติจะลดลงจึงมากกว่า ข้อสรุปที่สร้างขึ้นอ้างอิงเพียงสมมติฐานสามัญสำนึกส่วนตัว
ในหัวข้อนี้ Grok อ้างอิงข่าวสารและข้อมูลโพล เช่น "การปิดรัฐบาล ความกังวลทางเศรษฐกิจ ความขัดแย้งนโยบายผู้อพยพ และผลกระทบเชิงลบจากคำวิจารณ์ต่อการเสียชีวิตของ Rob Reiner" ซึ่งสอดคล้องกับการออกแบบที่คาดหวัง
การตัดสินเงื่อนไขการชำระผิดพลาด
ในหัวข้อ "Will Trump release the Epstein files by December 20?" ทั้ง Gemini และ Grok รู้แล้วว่า "รัฐบาลจะเปิดเผยเอกสาร 'หลายแสนหน้า' ในวันศุกร์ (19 ธันวาคม)" ในขณะที่เงื่อนไขการชำระระบุชัดเจนว่า "หากรัฐบาลเปิดเผยสาธารณะเอกสารใดๆ ที่เกี่ยวข้องกับกิจกรรมผิดกฎหมายของ Epstein และไม่เคยเปิดเผยก่อนวันที่ระบุไว้ ให้ตัดสินว่า Yes"
อย่างไรก็ตาม ภายใต้เงื่อนไขนี้ Gemini ระบุว่า "เป็นไปไม่ได้ที่จะเผยแพร่เอกสาร 'ทั้งหมด' ให้เสร็จสิ้นก่อนวันที่ 20 ธันวาคม" ซึ่งเป็นการตัดสินเงื่อนไขที่จำเป็นสำหรับการชำระที่ผิดพลาดอย่างชัดเจน จึงให้คำตอบที่ผิด
สรุป
โดยสรุป อัตราชนะในการทำนายของ Grok ได้แซงหน้าเงินฉลาดเหล่านี้ที่ทำกำไรหลายแสนหรือหลายล้านดอลลาร์ในตลาดทำนายแล้ว แต่เมื่อเจาะลึกถึงตรรกะการทำนายของมัน ยังมีจุดที่สามารถชี้นำและแก้ไขได้อีกมากมาย


