
ความท้าทายหลักของการใช้เหตุผล AI แบบกระจายอำนาจ: เราจะพิสูจน์ให้ทั้งเครือข่ายทราบได้อย่างไรว่าคุณไม่ได้ "โกง"
- 核心观点:去中心化LLM需验证节点模型真实性。
- 关键要素:
- GPU非确定性导致输出比较困难。
- 经济机制惩罚作弊,声誉归零。
- 三种验证方案防范模型替换攻击。
- 市场影响:提升去中心化AI网络可信度。
- 时效性标注:中期影响。
บทความต้นฉบับโดย Anastasia Matveeva ผู้ร่วมก่อตั้ง Gonka Protocol
ใน บทความก่อนหน้า เราได้สำรวจความตึงเครียดพื้นฐานระหว่างความปลอดภัยและประสิทธิภาพในการวิเคราะห์แบบกระจายศูนย์โดยใช้หลักสูตรนิติศาสตรมหาบัณฑิต (LLM) วันนี้เราจะทำตามคำมั่นสัญญาและเจาะลึกคำถามสำคัญ: ในเครือข่ายเปิด เราจะตรวจสอบได้อย่างไรว่าโหนดกำลังทำงานตามแบบจำลองที่อ้างไว้จริง ๆ
01. ทำไมการยืนยันจึงยาก?
เพื่อทำความเข้าใจกลไกการตรวจสอบความถูกต้อง ลองมาทบทวนกระบวนการภายในของ Transformer เมื่อทำการอนุมาน ขณะประมวลผลโทเค็นอินพุต เลเยอร์สุดท้ายของโมเดลจะสร้างลอจิท ซึ่งเป็นคะแนนดิบที่ไม่ได้ปรับมาตรฐานสำหรับแต่ละโทเค็นในคำศัพท์ จากนั้นลอจิทเหล่านี้จะถูกแปลงเป็นค่าความน่าจะเป็นโดยใช้ฟังก์ชัน softmax ซึ่งสร้างการแจกแจงความน่าจะเป็นสำหรับโทเค็นถัดไปที่เป็นไปได้ทั้งหมด ในแต่ละขั้นตอนการสร้าง จะมีการสุ่มตัวอย่างโทเค็นจากการแจกแจงนี้เพื่อสร้างลำดับต่อไป
ก่อนที่จะเจาะลึกถึงเวกเตอร์โจมตีที่มีศักยภาพและการนำการตรวจสอบไปใช้อย่างเฉพาะเจาะจง เราก็ต้องเข้าใจก่อนว่าเหตุใดการตรวจสอบจึงทำได้ยาก
ต้นตอของปัญหาอยู่ที่ความไม่กำหนดตายตัวของ GPU แม้แต่รุ่นและอินพุตเดียวกันก็อาจให้ผลลัพธ์ที่แตกต่างกันเล็กน้อยบนฮาร์ดแวร์ที่แตกต่างกัน หรือแม้แต่บนอุปกรณ์เดียวกัน เนื่องจากปัญหาต่างๆ เช่น ความแม่นยำของจุดลอยตัว
การไม่กำหนดลำดับของ GPU ทำให้การเปรียบเทียบลำดับโทเค็นเอาต์พุตโดยตรงไม่มีความหมาย ดังนั้นเราจึงจำเป็นต้องตรวจสอบกระบวนการคำนวณภายในของ Transformer ทางเลือกที่เหมาะสมคือการเปรียบเทียบการแจกแจงความน่าจะเป็นในเลเยอร์เอาต์พุต ซึ่งก็คือคำศัพท์ของแบบจำลอง เพื่อให้แน่ใจว่าเรากำลังเปรียบเทียบการแจกแจงความน่าจะเป็นของลำดับเดียวกัน ขั้นตอนการตรวจสอบของเรากำหนดให้ผู้ตรวจสอบทำซ้ำลำดับโทเค็นที่เหมือนกันทุกประการซึ่งสร้างโดยผู้ดำเนินการ แล้วจึงเปรียบเทียบการแจกแจงความน่าจะเป็นเหล่านี้ทีละขั้นตอน กระบวนการนี้จะสร้างใบรับรองการตรวจสอบที่พิสูจน์ความถูกต้องของแบบจำลอง
อย่างไรก็ตาม พฤติกรรมความน่าจะเป็นยังทำให้เกิดความสมดุลที่ละเอียดอ่อน: เราจำเป็นต้องลงโทษผู้โกงที่คอยโกงอยู่ตลอดเวลา ขณะเดียวกันก็หลีกเลี่ยงการสร้างความเสียหายให้กับโหนดที่ซื่อสัตย์โดยไม่ได้ตั้งใจ ซึ่งมักจะโชคร้ายและให้ผลลัพธ์ที่มีความน่าจะเป็นต่ำ การกำหนดเกณฑ์ที่สูงเกินไปอาจทำให้ผู้เล่นที่ดีตายโดยไม่ได้ตั้งใจ ในขณะที่การกำหนดเกณฑ์ที่ต่ำเกินไปอาจทำให้ผู้เล่นที่แย่หลุดพ้นจากความรับผิดชอบได้
02. เศรษฐศาสตร์ของการโกง: ประโยชน์และความเสี่ยง
ประโยชน์ที่อาจได้รับ: สิ่งล่อใจมหาศาล
การโจมตีที่ตรงที่สุดคือ "การแทนที่โมเดล" สมมติว่าการปรับใช้เครือข่ายต้องใช้พลังประมวลผลจำนวนมากสำหรับโมเดล Qwen3-32B โหนดที่มีเหตุผลอาจคิดว่า "จะเกิดอะไรขึ้นถ้าฉันแอบรันโมเดล Qwen2.5-3B ซึ่งเล็กกว่ามาก และเก็บส่วนต่างของพลังประมวลผลที่ประหยัดได้เอาไว้"
การใช้แบบจำลองพารามิเตอร์ 3 พันล้านตัวเพื่อปลอมแปลงเป็นแบบจำลองพารามิเตอร์ 32 พันล้านตัว อาจช่วยลดต้นทุนด้านพลังการประมวลผลลงได้มหาศาล หากคุณสามารถหลอกระบบตรวจสอบได้ ก็เหมือนกับการได้รับค่าตอบแทนสำหรับพลังการประมวลผลคุณภาพสูง ในขณะที่ให้ผลลัพธ์ด้วยพลังการประมวลผลราคาถูก
ผู้โจมตีที่ซับซ้อนกว่าอาจใช้เทคนิคการควอนไทซ์ โดยอ้างว่าทำงานที่ความแม่นยำระดับ FP8 แต่แท้จริงแล้วกลับใช้ควอนไทซ์ระดับ INT4 ความแตกต่างของประสิทธิภาพอาจไม่มากเท่า แต่การประหยัดต้นทุนก็ยังคงมีนัยสำคัญ และผลลัพธ์ที่ได้อาจใกล้เคียงกันมากพอที่จะผ่านการตรวจสอบแบบง่ายๆ
ในระดับที่ซับซ้อนยิ่งขึ้น ยังมีการโจมตีแบบเติมข้อมูลล่วงหน้าด้วย การโจมตีนี้ช่วยให้ผู้โจมตีสามารถสร้างหลักฐานสำหรับผลลัพธ์ของแบบจำลองราคาถูกได้ ราวกับว่าผลลัพธ์นั้นถูกสร้างขึ้นจากแบบจำลองเต็มรูปแบบตามที่เครือข่ายคาดหวัง โดยวิธีการทำงานมีดังนี้:
ตัวอย่างเช่น มีการบรรลุฉันทามติบนเชนในการปรับใช้ Qwen3-235B ด้วยชุดพารามิเตอร์ที่เฉพาะเจาะจง
1. ผู้ดำเนินการใช้ Qwen2.5-3B เพื่อสร้างลำดับ: `[Hello, world, how, are, you]`
2. ผู้ดำเนินการคำนวณการพิสูจน์ Qwen3-235B สำหรับโทเค็นเดียวกันนี้โดยผ่านการส่งต่อครั้งเดียว: `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]`
3. ผู้ดำเนินการยื่นความน่าจะเป็นของ Qwen3-235B เป็นหลักฐาน โดยอ้างว่าเหตุผลนั้นมาจาก Qwen3-235B
ในกรณีนี้ ความน่าจะเป็นมาจากแบบจำลองที่ถูกต้อง ทำให้ดูถูกต้อง แต่กระบวนการสร้างลำดับจริงนั้นมีค่าใช้จ่ายถูกกว่ามาก เนื่องจากแบบจำลองเต็มสามารถให้ผลลัพธ์ได้เท่ากับแบบจำลองขนาดเล็กในทางทฤษฎี ผลลัพธ์จึงอาจดูถูกต้องสมบูรณ์เมื่อพิจารณาจากการตรวจสอบ
การสูญเสียที่อาจเกิดขึ้น: มีราคาแพงมากขึ้น
แม้ว่าการโกงระบบอาจสร้างผลกำไรมหาศาล แต่ความเสียหายที่อาจเกิดขึ้นก็มีความสำคัญไม่แพ้กัน ความท้าทายที่แท้จริงของผู้โกงไม่ใช่การผ่านการตรวจสอบเพียงครั้งเดียว แต่คือการหลบเลี่ยงการตรวจจับอย่างเป็นระบบเป็นระยะเวลานาน เพื่อให้ "ส่วนลด" ที่พวกเขาได้รับจากการคำนวณสูงกว่าโทษที่เครือข่ายสามารถกำหนดได้
ในเครือข่าย Gonka เราได้ออกแบบกลไกการปราบปรามเศรษฐกิจที่ซับซ้อน:
- ทุกคนคือผู้ตรวจสอบ: แต่ละโหนดจะตรวจสอบส่วนหนึ่งของการใช้เหตุผลเครือข่ายตามน้ำหนักของมัน
- ระบบชื่อเสียง: ค่าชื่อเสียงของโหนดใหม่คือ 0 และการตรวจสอบการอนุมานทั้งหมดจะได้รับการยืนยัน การมีส่วนร่วมอย่างซื่อสัตย์อย่างต่อเนื่องจะทำให้ชื่อเสียงเพิ่มขึ้น และความถี่ในการตรวจสอบจะลดลงเหลือ 1%
- กลไกการลงโทษ: หากคุณถูกจับได้ว่าโกง ชื่อเสียงของคุณจะถูกรีเซ็ตเป็นศูนย์ และจะต้องใช้เวลาประมาณ 30 วันในการสร้างขึ้นมาใหม่
- การชำระบัญชียุค: ภายในยุคประมาณ 24 ชั่วโมง หากคุณถูกจับได้ว่าโกงเป็นจำนวนครั้งที่มีนัยสำคัญทางสถิติ รางวัลทั้งหมดสำหรับยุคทั้งหมดจะถูกยึด
ซึ่งหมายความว่าผู้โกงที่พยายามประหยัดพลังการประมวลผล 50% อาจสูญเสียกำไรไป 100% ความเสี่ยง "ขาดทุนมากกว่ากำไร" นี้ทำให้การโกงไม่ทำกำไรทางเศรษฐกิจ ปัญหาที่เรามุ่งแก้ไขด้วยกลไกการตรวจสอบของเราไม่ใช่การจับข้อสรุปที่น่าสงสัยทั้งหมด แต่คือการขีดเส้นแบ่งเพื่อให้แน่ใจว่าเราสามารถจับผู้โกงได้อย่างสม่ำเสมอด้วยความน่าจะเป็นที่สูงเพียงพอ โดยไม่ทำลายชื่อเสียงของผู้เข้าร่วมที่ซื่อสัตย์
03. จับคนโกงอย่างไร? 3 ระบบตรวจสอบ
แล้วเราจะรับมือกับการโจมตีเหล่านี้ได้อย่างไร? ปัญหาสามารถแบ่งได้เป็นสองส่วน: 1) การตรวจสอบการกระจายในบทพิสูจน์นั้นใกล้เคียงกับการกระจายที่สร้างโดยแบบจำลองที่อ้างสิทธิ์ และ 2) การยืนยันว่าข้อความเอาต์พุตถูกสร้างขึ้นตามบทพิสูจน์ที่ส่งมาจริง
ตัวเลือกที่ 1: การเปรียบเทียบการแจกแจงความน่าจะเป็น (พื้นฐานหลัก)
เมื่อผู้ดำเนินการสร้างเอาต์พุตอนุมาน (เช่น `[Hello, world, how, are, you]`) พวกเขาจะบันทึกใบรับรองการตรวจสอบที่มีเอาต์พุตสุดท้ายและความน่าจะเป็น K สูงสุดสำหรับแต่ละตำแหน่งในลำดับเอาต์พุต (เช่น `[{Hello: 0.9, Hi: 0.05, Hey: 0.05}, ...]` สำหรับตำแหน่งแรก เป็นต้น) จากนั้นผู้ตรวจสอบจะบังคับให้โมเดลปฏิบัติตามลำดับโทเค็นเดียวกันทุกประการและคำนวณระยะทางที่ปรับมาตรฐาน \( d_i \) ระหว่างความน่าจะเป็นที่ตำแหน่งแต่ละตำแหน่ง:
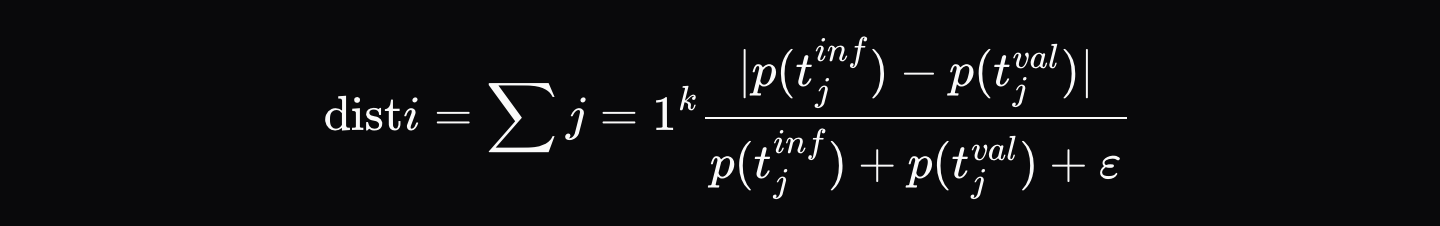
โดยที่ \( p_{\text{artifact},ij} \) คือความน่าจะเป็นของโทเค็นที่น่าจะเป็นไปได้มากที่สุดเป็นอันดับ j ในตำแหน่งนั้นในที่เก็บข้อมูลอนุมาน และ \( p_{\text{validator},ij} \) คือความน่าจะเป็นของโทเค็นเดียวกันในการแจกแจงตัวตรวจสอบ
เมตริกระยะทางสุดท้ายคือผลรวมเฉลี่ยของระยะทางของแต่ละโทเค็น:
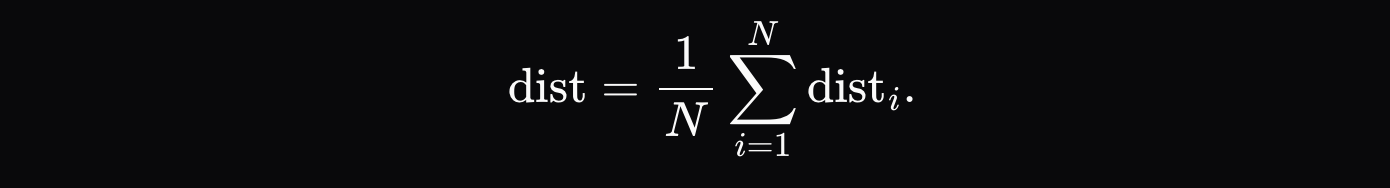
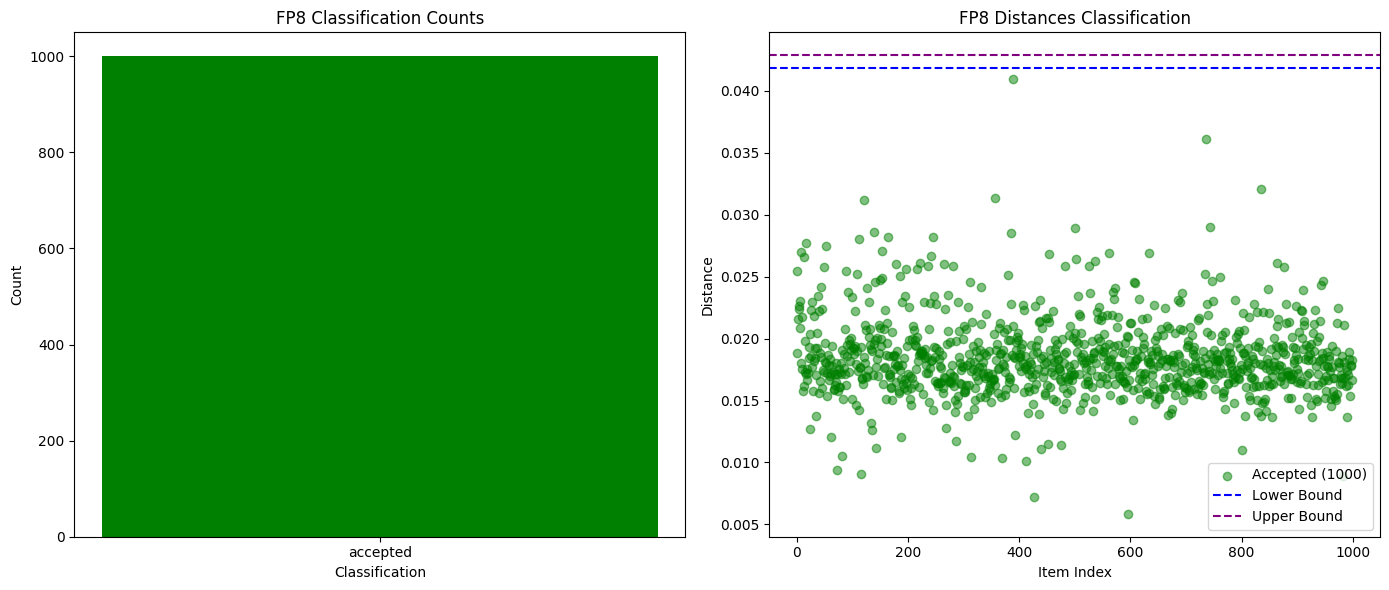
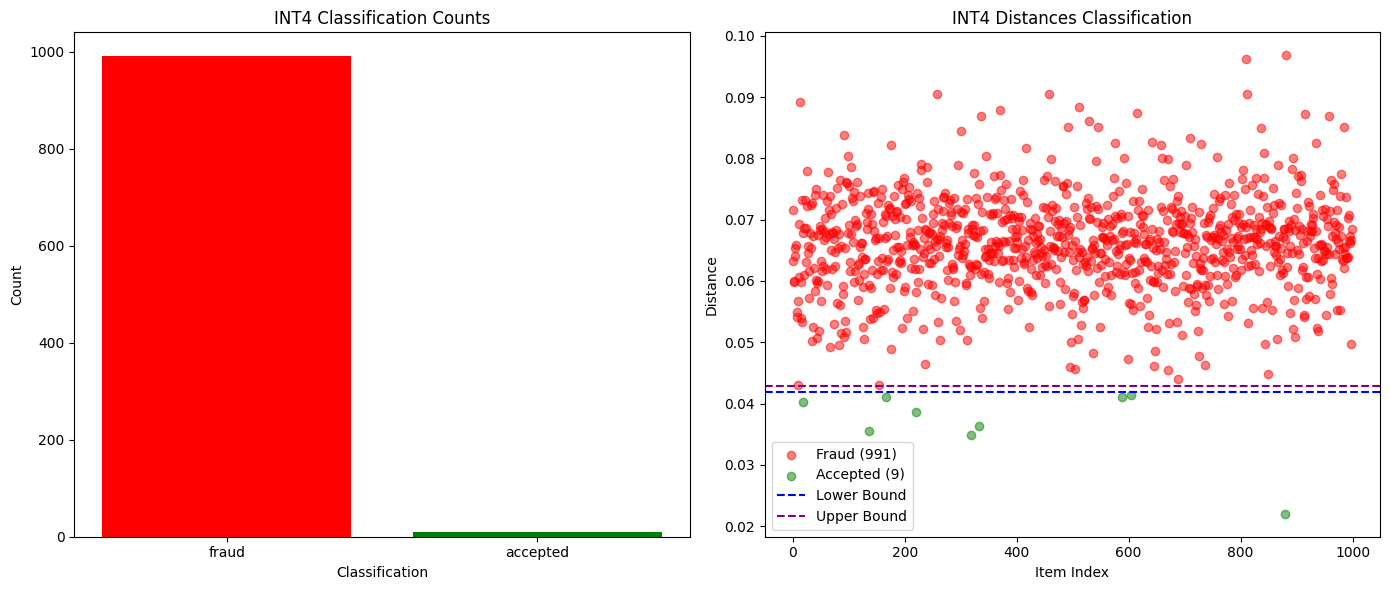
การเปรียบเทียบความน่าจะเป็น K สูงสุดนั้นเพียงพอที่จะตรวจจับแบบจำลองที่แตกต่างกันโดยสิ้นเชิง หรือแม้แต่เวอร์ชันการวัดปริมาณที่แตกต่างกันของแบบจำลองเดียวกัน ดังที่แสดงในแผนภูมิด้านล่าง เมื่อทดสอบระหว่างเวอร์ชันการวัดปริมาณ Qwen3-32B FP8 และ INT4 เราได้อัตราการตรวจจับการฉ้อโกง 99% โดยไม่มีผลบวกปลอมเลย นอกจากนี้ การแจกแจงความน่าจะเป็นของแบบจำลองอื่นๆ ก็แตกต่างกันมากพอที่จะทำให้สามารถตรวจจับการโกงได้อย่างง่ายดายภายในยุคเดียว ในขณะที่ผู้เข้าร่วมที่ซื่อสัตย์ยังคงปลอดภัย
รูปต่อไปนี้เปรียบเทียบจำนวนการตรวจสอบที่สำเร็จและล้มเหลวสำหรับ Qwen3-32B FP8 (ซื่อสัตย์) กับการวัดปริมาณ INT4 (ฉ้อโกง):
รูปต่อไปนี้แสดงถึงการเปลี่ยนแปลงของระยะการแจกแจงความน่าจะเป็นของการวัดปริมาณ Qwen3-32B FP8 (ซื่อสัตย์) เทียบกับ INT4 (ฉ้อโกง) ตามฟังก์ชันของความยาวลำดับ:
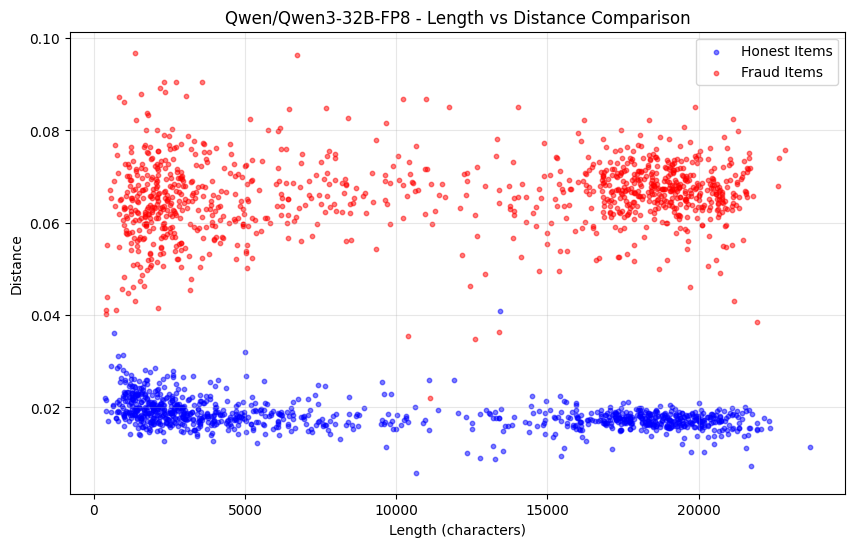
อย่างไรก็ตาม ข้อเสียของวิธีการนี้เพียงอย่างเดียวคือไม่ได้ป้องกันการโจมตีแบบ pre-filling หากความน่าจะเป็นตรงกับการแจกแจงของแบบจำลองทั้งหมด แต่ลำดับถูกสร้างขึ้นผ่านแบบจำลองที่เล็กลง เรามีวิธีการเพิ่มเติมหลายวิธีในการรับมือกับสถานการณ์นี้
โซลูชันที่ 2: การตรวจจับความสับสน (การป้องกันการโจมตีแบบเติมล่วงหน้า)
นอกเหนือจากการตรวจยืนยันว่าหลักฐานมาจากแบบจำลองที่ถูกต้องแล้ว เรายังตรวจสอบด้วยว่าข้อความเอาต์พุตมี "แนวโน้ม" ที่จะมาจากการแจกแจงความน่าจะเป็นของหลักฐานหรือไม่
หากลำดับถูกสร้างขึ้นโดยแบบจำลองอื่น ความสับสนของลำดับนั้นเมื่อเทียบกับการแจกแจงความน่าจะเป็นของแบบจำลองที่อ้างสิทธิ์จะสูงผิดปกติ ในการทดสอบ ความแตกต่างของความสับสนระหว่างการโจมตีที่เติมไว้ล่วงหน้าของ Qwen2.5-7B และ Qwen2.5-3B นั้นมีนัยสำคัญ
วิธีที่ใช้งานง่ายที่สุดในการตรวจจับการโจมตีแบบกรอกข้อมูลล่วงหน้าคือการตรวจสอบความสับสน นอกเหนือจากการตรวจยืนยันว่าการรับรองนั้นสร้างขึ้นโดยโมเดลที่อ้างสิทธิ์แล้ว เรายังตรวจสอบได้อีกด้วยว่าข้อความเอาต์พุตมีแนวโน้มที่จะสร้างขึ้นจากการแจกจ่ายที่ส่งมาหรือไม่
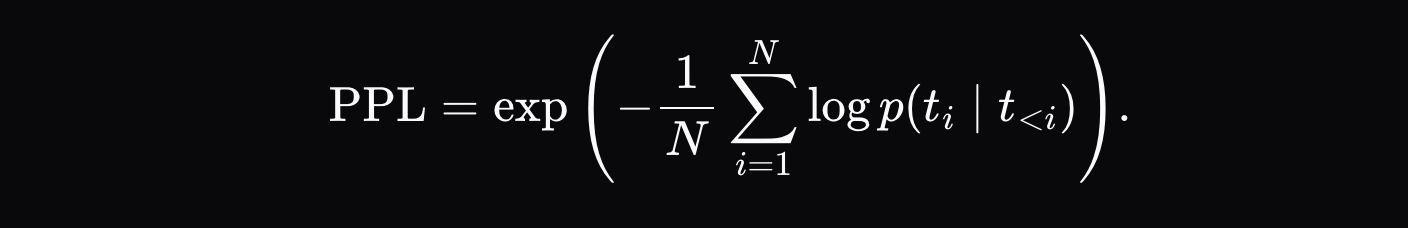
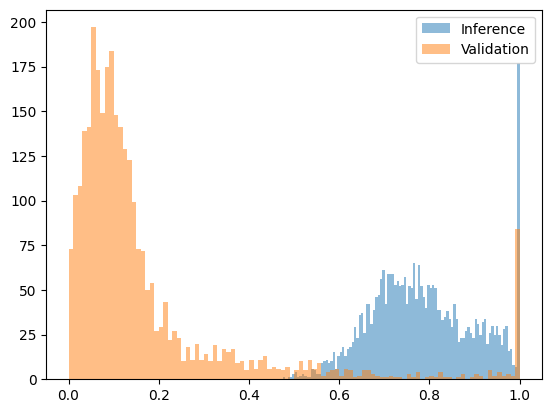
หากความน่าสับสนสูงเกินไป แสดงว่าลำดับนั้นน่าจะถูกสร้างขึ้นจากแบบจำลองอื่น วิธีนี้ใช้ได้ดีในการป้องกันการโจมตีโดยใช้แบบจำลองที่แตกต่างกันอย่างมีนัยสำคัญ เมื่อเราทดสอบลำดับที่สร้างโดย Qwen2.5-3B แต่อ้างว่ามาจาก Qwen2.5-7B ความแตกต่างของความน่าสับสนมีนัยสำคัญเพียงพอที่จะกำหนดเกณฑ์ที่ชัดเจน รูปด้านล่างแสดงฟังก์ชันความน่าสับสนที่แปลงแล้ว ซึ่งพอดีกับช่วง [0, 1] โดยที่เอาต์พุตของแบบจำลอง 7B ส่วนใหญ่ต่ำกว่า 0.2 ในขณะที่เอาต์พุตของการโจมตีที่เติมไว้ล่วงหน้า (เอาต์พุตของแบบจำลอง 3B ที่มีความน่าจะเป็นของแบบจำลอง 7B) ทั้งหมดสูงกว่า 0.4
รูปต่อไปนี้แสดงฟังก์ชันความสับสนหลังจากการแปลง Qwen2.5-7B (ซื่อสัตย์) เทียบกับการโจมตีที่เติมไว้ล่วงหน้าของ Qwen2.5-3B (ฉ้อโกง):
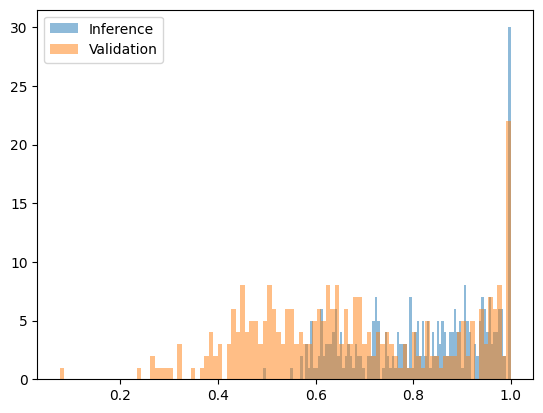
อย่างไรก็ตาม การตรวจจับความสับสนมีข้อจำกัดเมื่อเปรียบเทียบแบบจำลองที่คล้ายกันและแบบจำลองเดียวกันในเวอร์ชันควอนไทซ์ที่แตกต่างกัน ตัวอย่างเช่น เมื่อเปรียบเทียบเวอร์ชันควอนไทซ์ w8a16 และ w8a8 ของ Qwen2.5-7B Base ไม่พบความแตกต่างที่มีนัยสำคัญ
รูปต่อไปนี้แสดงฟังก์ชันความสับสนหลังจากการแปลงเชิงปริมาณ Qwen2.5-7B w8a16 (ซื่อสัตย์) เทียบกับ w8a8 (ฉ้อโกง):
โชคดีที่การใช้แบบจำลองที่มีลักษณะคล้ายกันในการโจมตีมักไม่คุ้มค่าทางเศรษฐกิจ หากพวกเขาใช้แบบจำลองที่มีต้นทุน 70-90% ของแบบจำลองที่อ้างสิทธิ์ บวกกับการคำนวณคะแนนเทียบกับแบบจำลองจริง พวกเขาอาจใช้ทรัพยากรคอมพิวเตอร์มากกว่าการใช้แบบจำลองจริงเพียงอย่างเดียว
สิ่งสำคัญที่ต้องทราบคือ ผลลัพธ์ความน่าจะเป็นต่ำเพียงผลลัพธ์เดียวที่สร้างขึ้นโดยผู้เข้าร่วมที่ซื่อสัตย์จะไม่ทำให้ชื่อเสียงของพวกเขาลดลงอย่างมีนัยสำคัญ หากผลลัพธ์ความน่าจะเป็นต่ำนี้ไม่คงอยู่สำหรับผู้เข้าร่วมรายนั้น กล่าวคือ เป็นเพียงค่าผิดปกติทางสถิติแบบสุ่ม พวกเขาจะยังคงได้รับรางวัลเต็มจำนวนเมื่อสิ้นสุดยุค
โซลูชันที่ 3: การจับเมล็ดพันธุ์ RNG (โซลูชันแบบกำหนดได้)
นี่เป็นวิธีแก้ปัญหาที่รุนแรงที่สุด: เชื่อมโยงลำดับเอาต์พุตกับค่าเมล็ดพันธุ์ของเครื่องสร้างตัวเลขสุ่ม
ผู้ดำเนินการจะเริ่มต้น RNG โดยใช้ค่าเมล็ดพันธุ์ที่กำหนดไว้ล่วงหน้าซึ่งได้มาจากการร้องขอ (เช่น `run_seed = SHA256(user_seed || inference_id_from_chain)`) หลักฐานการตรวจสอบประกอบด้วยค่าเมล็ดพันธุ์นี้และการแจกแจงความน่าจะเป็น
ตัวตรวจสอบใช้ค่า seed เดียวกันเพื่อตรวจสอบว่าหากลำดับมาจากการแจกแจงความน่าจะเป็นของแบบจำลองที่อ้างจริง ผลลัพธ์เดียวกันจะถูกทำซ้ำ วิธีนี้ให้คำตอบแบบ "ใช่/ไม่ใช่" ที่กำหนดได้ ขจัดการโจมตีแบบเติมข้อมูลล่วงหน้าได้อย่างสมบูรณ์ และต้นทุนการตรวจสอบก็ต่ำกว่าการอนุมานแบบสมบูรณ์มาก
04. แนวโน้ม: สู่อนาคตของ AI แบบกระจายอำนาจ
เราแบ่งปันแนวปฏิบัติและข้อคิดเหล่านี้จากความเชื่อมั่นอันแน่วแน่ของเราในอนาคตของ AI แบบกระจายศูนย์ เมื่อโมเดล AI เข้ามามีบทบาทในชีวิตของเรามากขึ้น ความจำเป็นในการเชื่อมโยงผลลัพธ์ของโมเดลเข้ากับพารามิเตอร์เฉพาะก็จะยิ่งเพิ่มมากขึ้น
รูปแบบการตรวจสอบที่เครือข่าย Gonka เลือกนั้นได้รับการพิสูจน์แล้วว่าสามารถทำได้จริงในทางปฏิบัติ และส่วนประกอบต่างๆ ของรูปแบบการตรวจสอบยังสามารถนำกลับมาใช้ใหม่ในสถานการณ์อื่นๆ ที่ต้องการตรวจสอบความถูกต้องของการใช้เหตุผลของ AI ได้อีกด้วย
AI แบบกระจายศูนย์ไม่ได้เป็นเพียงแค่วิวัฒนาการทางเทคโนโลยีเท่านั้น แต่ยังเป็นการเปลี่ยนแปลงความสัมพันธ์ด้านการผลิตอีกด้วย โดยพยายามแก้ไขปัญหาความไว้วางใจขั้นพื้นฐานผ่านอัลกอริทึมและกลไกทางเศรษฐกิจในสภาพแวดล้อมแบบเปิด แม้ว่าเส้นทางข้างหน้าจะยังอีกยาวไกล แต่เราก็ได้ก้าวไปข้างหน้าอย่างมั่นคงแล้ว


