
Gate Ventures Research Insights: สงครามเบราว์เซอร์ครั้งที่ 3 การต่อสู้ครั้งสำคัญในยุคของ AI Agent
สรุปแล้ว
สงครามเบราว์เซอร์ครั้งที่สามกำลังดำเนินไปอย่างเงียบๆ เมื่อมองย้อนกลับไปในประวัติศาสตร์ ตั้งแต่ Netscape และ IE ของ Microsoft ในช่วงทศวรรษ 1990 ไปจนถึง Firefox โอเพนซอร์สและ Chrome ของ Google สงครามเบราว์เซอร์มักสะท้อนให้เห็นการควบคุมแพลตฟอร์มและการเปลี่ยนแปลงกระบวนทัศน์ทางเทคโนโลยีอย่างเข้มข้น Chrome ครองตำแหน่งผู้นำด้วยความเร็วในการอัปเดตและการเชื่อมโยงทางระบบนิเวศน์ ขณะที่ Google ได้สร้างวงจรปิดของการป้อนข้อมูลผ่านโครงสร้าง "การผูกขาดสองราย" ของการค้นหาและเบราว์เซอร์
แต่ในปัจจุบัน รูปแบบดังกล่าวเริ่มสั่นคลอน การเพิ่มขึ้นของโมเดลภาษาขนาดใหญ่ (LLM) ทำให้ผู้ใช้จำนวนมากขึ้นเรื่อยๆ สามารถทำงานต่างๆ ในหน้าผลการค้นหาได้โดยไม่ต้องคลิกเลย และจำนวนการคลิกหน้าเว็บแบบเดิมก็ลดลง ในขณะเดียวกัน ข่าวลือที่ว่า Apple ตั้งใจจะแทนที่เครื่องมือค้นหาเริ่มต้นใน Safari ยิ่งคุกคามฐานกำไรของ Alphabet (บริษัทแม่ของ Google) มากขึ้น และตลาดก็เริ่มแสดงความกังวลต่อ "ความดั้งเดิมของการค้นหา"
เบราว์เซอร์เองก็กำลังเผชิญกับการเปลี่ยนแปลงบทบาทใหม่เช่นกัน ไม่ใช่แค่เครื่องมือสำหรับแสดงหน้าเว็บเท่านั้น แต่ยังมีความสามารถหลายอย่าง เช่น การป้อนข้อมูล พฤติกรรมของผู้ใช้ และการระบุตัวตนความเป็นส่วนตัว แม้ว่า AI Agent จะมีประสิทธิภาพ แต่ก็ยังต้องอาศัยขอบเขตความน่าเชื่อถือของเบราว์เซอร์และแซนด์บ็อกซ์ฟังก์ชันเพื่อดำเนินการโต้ตอบกับหน้าที่ซับซ้อน เรียกข้อมูลระบุตัวตนในพื้นที่ และควบคุมองค์ประกอบของหน้าเว็บ เบราว์เซอร์กำลังเปลี่ยนจากอินเทอร์เฟซของมนุษย์ไปเป็นแพลตฟอร์มการเรียกใช้ระบบของตัวแทน
ในบทความนี้ เราจะมาสำรวจว่าเบราว์เซอร์ยังจำเป็นอยู่หรือไม่ ในขณะเดียวกัน เราเชื่อว่าสิ่งที่น่าจะทำให้ตลาดเบราว์เซอร์ในปัจจุบันพังทลายลงไม่ใช่ "Chrome ที่ดีกว่า" ตัวใหม่ แต่เป็นโครงสร้างการโต้ตอบแบบใหม่ ไม่ใช่การแสดงข้อมูล แต่เป็นการเรียกใช้งาน ในอนาคต เบราว์เซอร์ควรได้รับการออกแบบสำหรับตัวแทน AI ไม่ใช่แค่การอ่านเท่านั้น แต่ยังรวมถึงการเขียนและการดำเนินการด้วย โปรเจ็กต์อย่าง Browser Use กำลังพยายามทำให้โครงสร้างของหน้ามีความหมาย โดยเปลี่ยนอินเทอร์เฟซภาพเป็นข้อความที่มีโครงสร้างซึ่ง LLM สามารถเรียกใช้ได้ ทำให้การจับคู่หน้ากับคำสั่งเป็นจริง และลดต้นทุนการโต้ตอบได้อย่างมาก
โครงการกระแสหลักในตลาดได้เริ่มทำการทดสอบแล้ว: Perplexity สร้างเบราว์เซอร์ Comet ดั้งเดิมโดยใช้ AI เพื่อแทนที่ผลการค้นหาแบบดั้งเดิม Brave ผสมผสานการปกป้องความเป็นส่วนตัวกับการใช้เหตุผลในพื้นที่โดยใช้ LLM เพื่อปรับปรุงการค้นหาและฟังก์ชันการบล็อก และโครงการ Crypto ดั้งเดิมเช่น Donut กำลังกำหนดเป้าหมายจุดเข้าใหม่สำหรับ AI เพื่อโต้ตอบกับสินทรัพย์บนเชน คุณสมบัติทั่วไปของโครงการเหล่านี้คือพยายามสร้างส่วนอินพุตของเบราว์เซอร์ใหม่แทนที่จะทำให้เลเยอร์เอาต์พุตสวยงามขึ้น
สำหรับผู้ประกอบการ โอกาสถูกซ่อนอยู่ในความสัมพันธ์สามเหลี่ยมระหว่างอินพุต โครงสร้าง และตัวแทน ในฐานะอินเทอร์เฟซสำหรับตัวแทนในการเรียกโลกในอนาคต เบราว์เซอร์หมายความว่าใครก็ตามที่สามารถจัดเตรียม "บล็อกความสามารถ" ที่มีโครงสร้าง เรียกได้ และน่าเชื่อถือได้ สามารถเป็นส่วนหนึ่งของแพลตฟอร์มรุ่นใหม่ได้ ตั้งแต่ SEO ไปจนถึง AEO (Agent Engine Optimization) ตั้งแต่ปริมาณการเข้าชมหน้าไปจนถึงการเรียกชุดงาน แบบฟอร์มผลิตภัณฑ์และการคิดเชิงออกแบบกำลังถูกสร้างขึ้นใหม่ สงครามเบราว์เซอร์ครั้งที่สามเกิดขึ้นใน "อินพุต" มากกว่า "การแสดงผล" ผู้ชนะไม่ได้ถูกกำหนดโดยใครที่ดึงดูดความสนใจของผู้ใช้อีกต่อไป แต่ใครจะได้รับความไว้วางใจจากตัวแทนและได้รับจุดเข้าสำหรับการโทร
ประวัติโดยย่อของการพัฒนาเบราว์เซอร์
ในช่วงต้นทศวรรษ 1990 เมื่ออินเทอร์เน็ตยังไม่กลายมาเป็นส่วนหนึ่งของชีวิตประจำวัน Netscape Navigator จึงถือกำเนิดขึ้น เสมือนเรือใบที่เปิดทวีปใหม่ เปิดประตูสู่โลกดิจิทัลสำหรับผู้ใช้หลายล้านคน เบราว์เซอร์นี้ไม่ใช่เบราว์เซอร์ตัวแรก แต่เป็นผลิตภัณฑ์ตัวแรกที่เข้าถึงคนทั่วไปได้อย่างแท้จริงและกำหนดรูปแบบประสบการณ์อินเทอร์เน็ต ในเวลานั้น เป็นครั้งแรกที่ผู้คนสามารถท่องเว็บได้อย่างง่ายดายผ่านอินเทอร์เฟซแบบกราฟิก ราวกับว่าทั้งโลกอยู่ใกล้แค่เอื้อม
อย่างไรก็ตาม ชื่อเสียงมักอยู่ได้ไม่นาน Microsoft ก็ได้ตระหนักถึงความสำคัญของเบราว์เซอร์ในไม่ช้า และตัดสินใจที่จะรวม Internet Explorer เข้ากับระบบปฏิบัติการ Windows อย่างเต็มที่ ทำให้เป็นเบราว์เซอร์เริ่มต้น กลยุทธ์นี้เรียกได้ว่าเป็น "ผู้ทำลายแพลตฟอร์ม" และทำลายความโดดเด่นของ Netscape โดยตรง ผู้ใช้จำนวนมากไม่ได้เลือกใช้ IE อย่างจริงจัง แต่ยอมรับเพราะระบบยอมรับเป็นค่าเริ่มต้น ด้วยความช่วยเหลือของความสามารถในการจัดจำหน่ายของ Windows IE จึงกลายเป็นผู้นำในอุตสาหกรรมอย่างรวดเร็ว และ Netscape ก็ตกต่ำลง

วิวัฒนาการของโลโก้ Firefox
ในสถานการณ์ที่ยากลำบาก วิศวกรของ Netscape เลือกเส้นทางที่ก้าวหน้าและอุดมคติ นั่นคือการเปิดเผยซอร์สโค้ดของเบราว์เซอร์ต่อสาธารณะและเรียกร้องชุมชนโอเพนซอร์ส การตัดสินใจครั้งนี้ดูเหมือนจะเป็น "การประนีประนอมของมาซิโดเนีย" ในโลกเทคโนโลยี ซึ่งเป็นสัญญาณแห่งการสิ้นสุดของยุคเก่าและพลังใหม่กำลังเกิดขึ้น โค้ดนี้ต่อมาได้กลายเป็นพื้นฐานของโปรเจ็กต์เบราว์เซอร์ Mozilla ซึ่งเดิมมีชื่อว่า Phoenix (แปลว่านิพพานแห่งฟีนิกซ์) แต่ถูกเปลี่ยนชื่อหลายครั้งเนื่องจากปัญหาเครื่องหมายการค้า และในที่สุดก็ได้เปลี่ยนชื่อเป็น Firefox
Firefox ไม่ใช่แค่การคัดลอก Netscape มาแบบธรรมดาๆ แต่ประสบความสำเร็จอย่างมากในด้านประสบการณ์ผู้ใช้ ระบบนิเวศของปลั๊กอิน ความปลอดภัย ฯลฯ การถือกำเนิดของ Firefox ถือเป็นชัยชนะของจิตวิญญาณโอเพนซอร์สและเติมพลังใหม่ให้กับอุตสาหกรรมทั้งหมด บางคนบรรยาย Firefox ว่าเป็น "ผู้สืบทอดจิตวิญญาณ" ของ Netscape เช่นเดียวกับที่จักรวรรดิออตโตมันสืบทอดมรดกจากจักรวรรดิไบแซนไทน์ แม้ว่าคำอุปมาอุปไมยนี้จะเกินจริง แต่ก็มีความหมายมากทีเดียว
แต่ไม่กี่ปีก่อนที่ Firefox จะเปิดตัวอย่างเป็นทางการ Microsoft ได้เปิดตัว IE ไปแล้วหกเวอร์ชัน โดยอาศัยข้อได้เปรียบด้านเวลาและกลยุทธ์การรวมระบบ Firefox จึงอยู่ในตำแหน่งที่ไล่ตามมาตั้งแต่แรก ซึ่งหมายความว่าการแข่งขันครั้งนี้ไม่ใช่การแข่งขันที่ยุติธรรมเมื่อมีจุดเริ่มต้นที่เท่าเทียมกัน
ในเวลาเดียวกัน ผู้เล่นรุ่นแรกๆ อีกรายหนึ่งก็เปิดตัวอย่างเงียบๆ ในปี 1994 เบราว์เซอร์ Opera ได้เปิดตัวในประเทศนอร์เวย์และในช่วงแรกเป็นเพียงโครงการทดลอง แต่เริ่มด้วยเวอร์ชัน 7.0 ในปี 2003 เบราว์เซอร์นี้ได้เปิดตัวเอนจิ้น Presto ของตัวเอง และเป็นตัวแรกที่รองรับเทคโนโลยีล้ำสมัย เช่น CSS การจัดวางแบบปรับได้ การควบคุมด้วยเสียง และการเข้ารหัส Unicode แม้ว่าจำนวนผู้ใช้จะจำกัด แต่เบราว์เซอร์นี้ก็อยู่แถวหน้าของอุตสาหกรรมเสมอในแง่ของเทคโนโลยี และกลายเป็น "ที่ชื่นชอบของเหล่า Geek"
ในปีเดียวกันนั้น Apple ได้เปิดตัวเบราว์เซอร์ Safari ซึ่งถือเป็นจุดเปลี่ยนที่สำคัญ ในเวลานั้น Microsoft ได้ลงทุน 150 ล้านเหรียญสหรัฐใน Apple ซึ่งกำลังอยู่ในภาวะล้มละลาย เพื่อรักษาภาพลักษณ์ของการแข่งขันและหลีกเลี่ยงการตรวจสอบการผูกขาด แม้ว่าเครื่องมือค้นหาเริ่มต้นของ Safari จะเป็น Google มาตั้งแต่แรกเริ่ม แต่ความยุ่งยากทางประวัติศาสตร์กับ Microsoft นี้เป็นสัญลักษณ์ถึงความสัมพันธ์ที่ซับซ้อนและละเอียดอ่อนระหว่างยักษ์ใหญ่ทางอินเทอร์เน็ต: ความร่วมมือและการแข่งขันมักจะมาคู่กันเสมอ
ในปี 2007 IE 7 เปิดตัวพร้อมกับ Windows Vista แต่ผลตอบรับจากตลาดอยู่ในระดับปานกลาง ในทางกลับกัน Firefox ซึ่งมีจังหวะการอัปเดตที่รวดเร็วกว่า กลไกส่วนขยายที่เป็นมิตรต่อผู้ใช้มากขึ้น และดึงดูดนักพัฒนาได้อย่างเป็นธรรมชาติ ได้เพิ่มส่วนแบ่งการตลาดขึ้นอย่างต่อเนื่องเป็นประมาณ 20% อิทธิพลของ IE กำลังลดลงเรื่อยๆ และทิศทางของกระแสก็กำลังเปลี่ยนแปลงไป
Google มีแนวทางที่แตกต่างออกไป แม้ว่าจะวางแผนสร้างเบราว์เซอร์ของตัวเองมาตั้งแต่ปี 2001 แต่กว่าจะโน้มน้าวใจให้ Eric Schmidt ซีอีโออนุมัติโครงการนี้ได้ก็ใช้เวลาถึง 6 ปี Chrome เปิดตัวในปี 2008 โดยใช้โครงการโอเพ่นซอร์ส Chromium และเอ็นจิ้น WebKit ที่ Safari ใช้ Chrome ได้รับฉายาว่าเป็นเบราว์เซอร์ "ขนาดใหญ่" แต่กลับได้รับความนิยมอย่างรวดเร็วเนื่องจาก Google มีความเชี่ยวชาญด้านการโฆษณาและการสร้างแบรนด์อย่างลึกซึ้ง
อาวุธสำคัญของ Chrome ไม่ใช่ฟีเจอร์ต่างๆ แต่เป็นการอัปเดตเวอร์ชันบ่อยครั้ง (ทุกๆ หกสัปดาห์) และประสบการณ์แบบรวมศูนย์ในทุกแพลตฟอร์ม ในเดือนพฤศจิกายน 2011 Chrome แซงหน้า Firefox เป็นครั้งแรก โดยมีส่วนแบ่งตลาด 27% และหกเดือนต่อมา Chrome ก็แซงหน้า IE สำเร็จ โดยเปลี่ยนจากผู้ท้าชิงเป็นผู้เล่นที่ครองตลาดได้สำเร็จ
ในเวลาเดียวกัน อินเทอร์เน็ตบนมือถือของจีนก็กำลังสร้างระบบนิเวศของตัวเองเช่นกัน UC Browser ของ Alibaba ได้รับความนิยมอย่างรวดเร็วในช่วงต้นทศวรรษ 2010 โดยเฉพาะในตลาดเกิดใหม่ เช่น อินเดีย อินโดนีเซีย และจีน ได้รับความนิยมจากผู้ใช้เครื่องมือระดับล่างด้วยดีไซน์น้ำหนักเบา การบีบอัดข้อมูล และคุณสมบัติการประหยัดปริมาณการรับส่งข้อมูล ในปี 2015 ส่วนแบ่งตลาดเบราว์เซอร์บนมือถือทั่วโลกเกิน 17% และครั้งหนึ่งเคยสูงถึง 46% ในอินเดีย แต่ชัยชนะนี้ไม่ได้คงอยู่นาน เมื่อรัฐบาลอินเดียเข้มงวดการตรวจสอบความปลอดภัยของแอปพลิเคชันของจีน UC Browser ก็ถูกบังคับให้ถอนตัวออกจากตลาดสำคัญและค่อยๆ สูญเสียความรุ่งโรจน์ในอดีตไป

ส่วนแบ่งตลาดเบราว์เซอร์ แหล่งที่มา: statcounter
เมื่อเข้าสู่ทศวรรษ 2020 Chrome ก็ครองตลาดโลกด้วยส่วนแบ่งตลาดราว 65% ที่น่าสังเกตก็คือ แม้ว่าเครื่องมือค้นหา Google และเบราว์เซอร์ Chrome จะเป็นของ Alphabet แต่ทั้งสองถือเป็นระบบที่ครองตลาดอย่างอิสระ โดยระบบแรกควบคุมพอร์ทัลค้นหาประมาณ 90% ของโลก ในขณะที่ระบบหลังควบคุม "หน้าต่างแรก" ของผู้ใช้ส่วนใหญ่ในการเข้าสู่อินเทอร์เน็ต
เพื่อรักษาโครงสร้างการผูกขาดแบบคู่ขนานนี้ไว้ Google ได้ลงทุนอย่างหนัก ในปี 2022 Alphabet จ่ายเงินให้ Apple ประมาณ 2 หมื่นล้านดอลลาร์เพื่อให้ Google ยังคงเป็นเครื่องมือค้นหาเริ่มต้นใน Safari นักวิเคราะห์บางคนชี้ให้เห็นว่าค่าใช้จ่ายนี้เทียบเท่ากับ 36% ของรายได้จากการโฆษณาค้นหาของ Google จากปริมาณการเข้าชม Safari กล่าวอีกนัยหนึ่งก็คือ Google กำลังจ่าย "ค่าธรรมเนียมการป้องกัน" สำหรับคูน้ำ
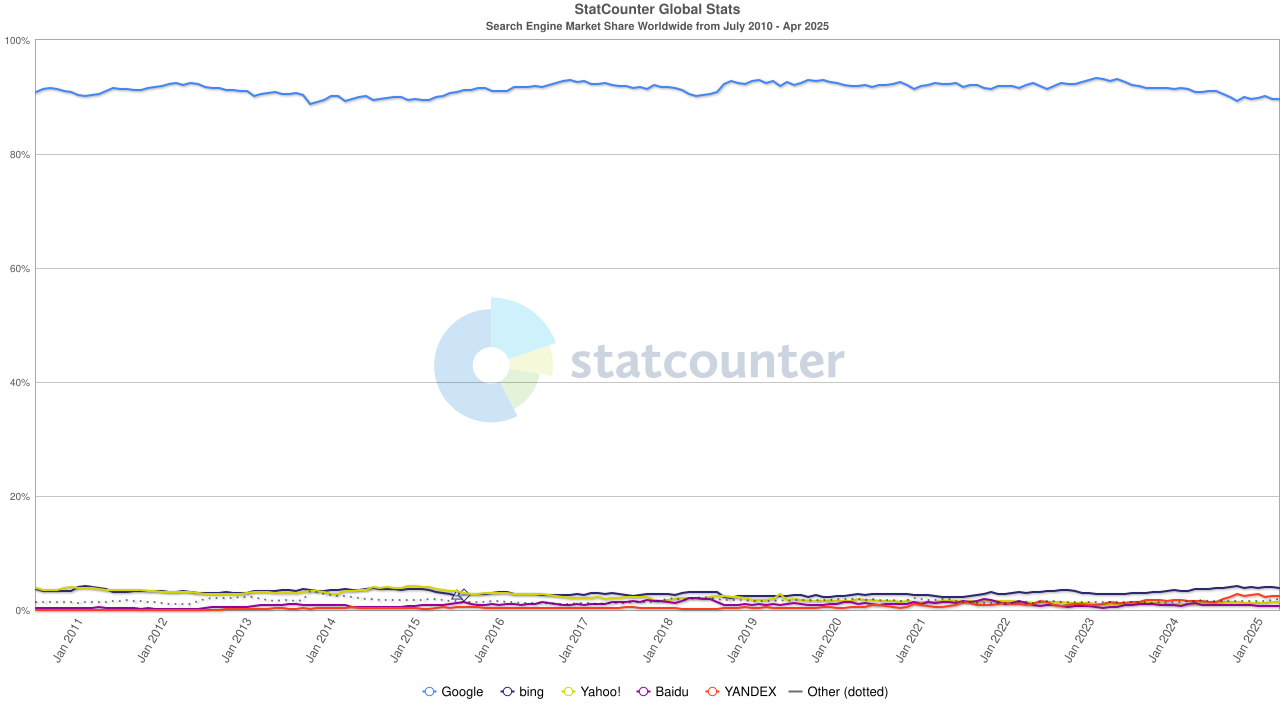
ส่วนแบ่งการตลาดเครื่องมือค้นหา แหล่งที่มา: statcounter
แต่ทิศทางของลมได้เปลี่ยนไปอีกครั้ง ด้วยการเพิ่มขึ้นของโมเดลภาษาขนาดใหญ่ (LLM) การค้นหาแบบดั้งเดิมก็เริ่มได้รับผลกระทบ ในปี 2024 ส่วนแบ่งการตลาดการค้นหาของ Google ลดลงจาก 93% เหลือ 89% แม้ว่าจะยังคงครองตลาดอยู่ แต่ก็เริ่มมีรอยร้าวปรากฏขึ้น ข่าวลือที่ว่า Apple อาจเปิดตัวเครื่องมือค้นหา AI ของตัวเองนั้นยิ่งสร้างความปั่นป่วนมากขึ้นไปอีก หากการค้นหาเริ่มต้นของ Safari เปลี่ยนไปใช้ค่ายของตัวเอง ไม่เพียงแต่จะเขียนภูมิทัศน์ทางนิเวศวิทยาใหม่เท่านั้น แต่ยังอาจสั่นคลอนเสาหลักด้านผลกำไรของ Alphabet อีกด้วย ตลาดตอบสนองอย่างรวดเร็ว และราคาหุ้นของ Alphabet ลดลงจาก 170 ดอลลาร์เหลือ 140 ดอลลาร์ ซึ่งสะท้อนให้เห็นไม่เพียงแต่ความตื่นตระหนกของนักลงทุนเท่านั้น แต่ยังรวมถึงความกังวลอย่างมากเกี่ยวกับทิศทางในอนาคตของยุคการค้นหาอีกด้วย

จาก Navigator ไปจนถึง Chrome จากอุดมคติโอเพ่นซอร์สไปจนถึงการโฆษณาเชิงพาณิชย์ จากเบราว์เซอร์น้ำหนักเบาไปจนถึงผู้ช่วยค้นหา AI สงครามเบราว์เซอร์เป็นสงครามเกี่ยวกับเทคโนโลยี แพลตฟอร์ม เนื้อหา และการควบคุมมาโดยตลอด สนามรบยังคงเปลี่ยนแปลงไป แต่แก่นแท้ไม่เคยเปลี่ยนแปลง: ใครก็ตามที่ควบคุมทางเข้าได้คือผู้กำหนดอนาคต
ในสายตาของ VC ที่พึ่งพาความต้องการใหม่ๆ ของผู้คนในเครื่องมือค้นหาในยุค LLM และ AI สงครามเบราว์เซอร์ครั้งที่สามกำลังค่อยๆ เกิดขึ้น ต่อไปนี้คือสถานะการเงินของโครงการเบราว์เซอร์ AI ที่มีชื่อเสียงบางโครงการ

สถาปัตยกรรมเก่าของเบราว์เซอร์สมัยใหม่
เมื่อพูดถึงสถาปัตยกรรมของเบราว์เซอร์ สถาปัตยกรรมแบบคลาสสิกดั้งเดิมจะปรากฏดังภาพด้านล่าง:

สถาปัตยกรรมโดยรวม ที่มา: Damien Benveniste
1. รายการไคลเอนต์-ฟรอนต์เอนด์
คำถามจะถูกส่งไปยัง Google Front End ที่ใกล้ที่สุดผ่าน HTTPS โดยทำการถอดรหัส TLS สุ่มตัวอย่าง QoS และกำหนดเส้นทางตามภูมิศาสตร์ให้เสร็จสมบูรณ์ หากตรวจพบการรับส่งข้อมูลที่ผิดปกติ (DDoS การรวบรวมข้อมูลอัตโนมัติ) ก็สามารถจำกัดหรือท้าทายได้ในเลเยอร์นี้
2. การทำความเข้าใจคำถาม
ส่วนหน้าจำเป็นต้องเข้าใจความหมายของคำที่ผู้ใช้พิมพ์ ซึ่งมี 3 ขั้นตอน คือ การแก้ไขการสะกดคำแบบประสาท ซึ่งจะแก้ไขคำว่า "recpie" เป็น "recipe" การขยายคำพ้องความหมาย ซึ่งจะขยายคำว่า "how to repair bike" เป็น "repair bicycle" และการวิเคราะห์เจตนา ซึ่งจะกำหนดว่าแบบสอบถามนั้นเป็นข้อมูล การนำทาง หรือเจตนาในการทำธุรกรรม แล้วกำหนดคำขอตามแนวตั้ง
3. การเรียกคืนผู้สมัคร
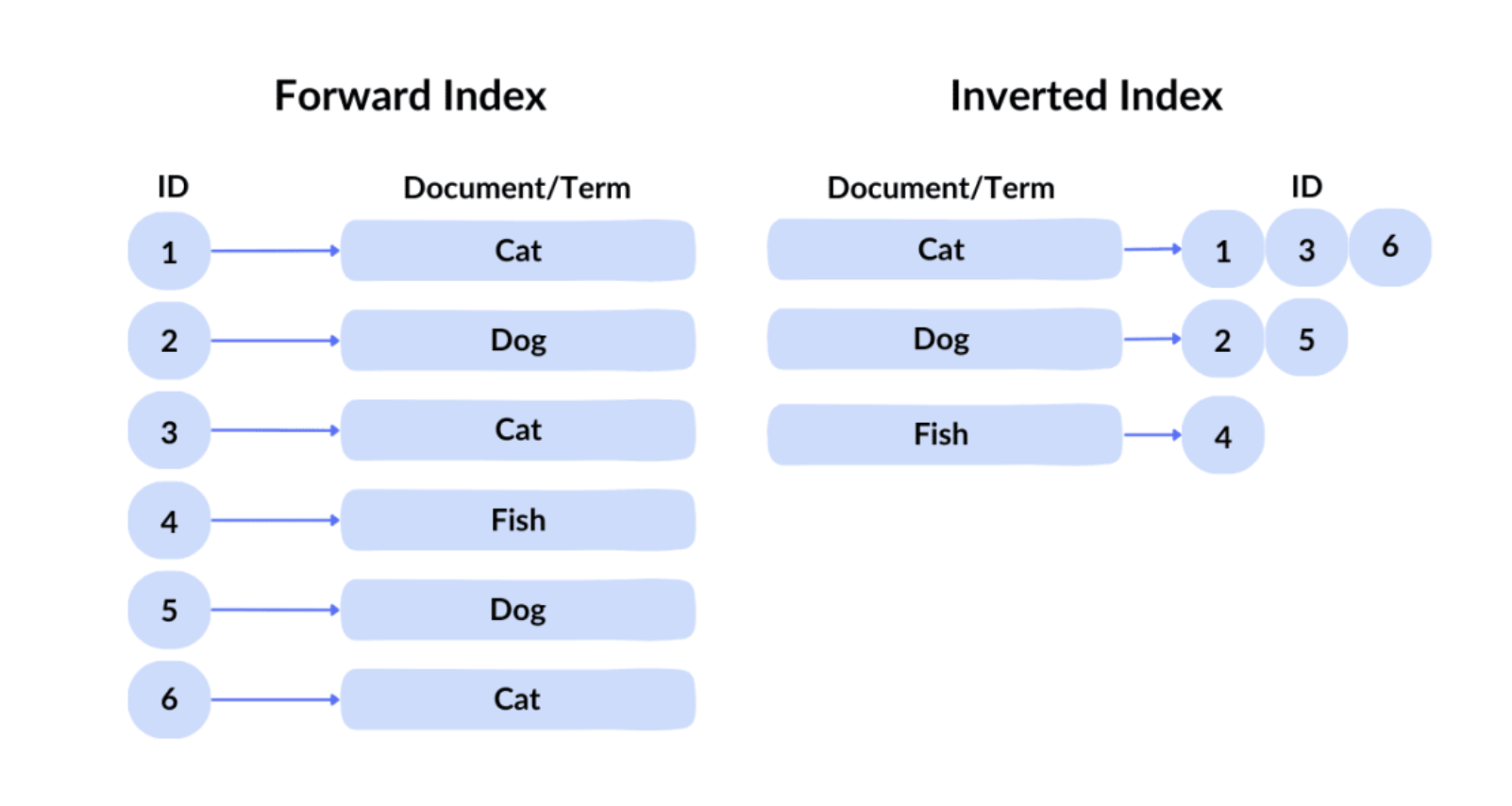
ดัชนีผกผัน แหล่งที่มา: ข่าวกรองเฉพาะจุด
เทคโนโลยีการค้นหาที่ Google ใช้เรียกว่า: ดัชนีย้อนกลับ ในดัชนีไปข้างหน้า เราสามารถสร้างดัชนีไฟล์โดยระบุ ID อย่างไรก็ตาม ผู้ใช้ไม่สามารถทราบจำนวนเนื้อหาที่ต้องการในไฟล์นับแสนล้านไฟล์ได้ ดังนั้น Google จึงใช้ดัชนีย้อนกลับแบบดั้งเดิมมากในการค้นหาว่าไฟล์ใดมีคำสำคัญที่เกี่ยวข้องผ่านเนื้อหา จากนั้น Google จะใช้ดัชนีเวกเตอร์ในการประมวลผลการค้นหาเชิงความหมาย นั่นคือค้นหาเนื้อหาที่มีความหมายคล้ายกับการค้นหา Google จะแปลงข้อความ รูปภาพ และเนื้อหาอื่นๆ เป็นเวกเตอร์มิติสูง (การฝัง) และค้นหาตามความคล้ายคลึงกันระหว่างเวกเตอร์เหล่านี้ ตัวอย่างเช่น แม้ว่าผู้ใช้จะค้นหา "วิธีทำแป้งพิซซ่า" เครื่องมือค้นหาก็สามารถแสดงผลลัพธ์ที่เกี่ยวข้องกับ "คู่มือการทำแป้งพิซซ่า" ได้ เนื่องจากผลลัพธ์เหล่านี้มีความคล้ายคลึงกันในเชิงความหมาย หลังจากดัชนีย้อนกลับและดัชนีเวกเตอร์แล้ว หน้าเว็บประมาณ 100,000 หน้าจะถูกคัดกรองออกในเบื้องต้น
4. การเรียงลำดับหลายระดับ
ระบบนี้มักใช้ฟีเจอร์พื้นฐานนับพันรายการ เช่น BM2 5, TF-IDF และคะแนนคุณภาพหน้าเพจ เพื่อกรองหน้าเพจที่เป็นตัวเลือกตั้งแต่หลักแสนไปจนถึงประมาณ 1,000 หน้าเพื่อสร้างชุดตัวเลือกเบื้องต้น ระบบดังกล่าวเรียกรวมกันว่าเครื่องมือแนะนำ ซึ่งอาศัยฟีเจอร์จำนวนมากที่สร้างขึ้นโดยเอนทิตีต่างๆ รวมถึงพฤติกรรมของผู้ใช้ แอตทริบิวต์ของหน้า เจตนาในการค้นหา และสัญญาณบริบท ตัวอย่างเช่น Google จะรวบรวมข้อมูล เช่น ประวัติของผู้ใช้ ข้อเสนอแนะด้านพฤติกรรมจากผู้ใช้รายอื่น ความหมายของหน้าเพจ ความหมายของการค้นหา เป็นต้น พร้อมทั้งพิจารณาปัจจัยบริบท เช่น เวลา (เวลาของวัน วันเฉพาะในสัปดาห์) และเหตุการณ์ภายนอก เช่น ข่าวสารแบบเรียลไทม์
5. การเรียนรู้เชิงลึกสำหรับการเรียงลำดับเบื้องต้น
ในขั้นตอนการค้นหาเบื้องต้น Google จะใช้เทคโนโลยีต่างๆ เช่น RankBrain และ Neural Matching เพื่อทำความเข้าใจความหมายของคำค้นหาและกรองผลลัพธ์ที่เกี่ยวข้องเบื้องต้นออกจากเอกสารจำนวนมาก RankBrain เป็นระบบการเรียนรู้ของเครื่องที่เปิดตัวโดย Google ในปี 2015 ซึ่งออกแบบมาเพื่อให้เข้าใจความหมายของคำค้นหาของผู้ใช้ได้ดียิ่งขึ้น โดยเฉพาะอย่างยิ่งคำค้นหาที่ปรากฏเป็นครั้งแรก ระบบจะค้นหาผลลัพธ์ที่เกี่ยวข้องมากที่สุดโดยการแปลงคำค้นหาและเอกสารเป็นการแสดงเวกเตอร์และคำนวณความคล้ายคลึงกันระหว่างทั้งสอง ตัวอย่างเช่น สำหรับคำค้นหา "วิธีทำแป้งพิซซ่า" RankBrain สามารถระบุเนื้อหาที่เกี่ยวข้องกับ "พื้นฐานของพิซซ่า" หรือ "การทำแป้ง" ได้ แม้ว่าจะไม่มีคำหลักที่ตรงกันในเอกสารก็ตาม
Neural Matching เป็นอีกเทคโนโลยีหนึ่งที่ Google เปิดตัวในปี 2018 เพื่อให้เข้าใจความสัมพันธ์เชิงความหมายระหว่างแบบสอบถามและเอกสารได้ลึกซึ้งยิ่งขึ้น เทคโนโลยีนี้ใช้โมเดลเครือข่ายประสาทเทียมเพื่อจับความสัมพันธ์ที่ไม่ชัดเจนระหว่างคำต่างๆ ช่วยให้ Google จับคู่แบบสอบถามกับเนื้อหาหน้าเว็บได้ดีขึ้น ตัวอย่างเช่น สำหรับแบบสอบถาม "ทำไมพัดลมแล็ปท็อปของฉันดังจัง" Neural Matching สามารถเข้าใจว่าผู้ใช้กำลังค้นหาข้อมูลการแก้ไขปัญหาเกี่ยวกับความร้อนสูงเกินไป การสะสมของฝุ่น หรือการใช้งาน CPU สูง แม้ว่าคำเหล่านี้จะไม่ปรากฏในแบบสอบถามโดยตรงก็ตาม
6. การจัดอันดับใหม่เชิงลึก: การประยุกต์ใช้โมเดล BERT
หลังจากคัดกรองเอกสารที่เกี่ยวข้องออกไปในเบื้องต้นแล้ว Google จะใช้โมเดล BERT (Bidirectional Encoder Representations from Transformers) เพื่อจัดเรียงเอกสารเหล่านี้อย่างละเอียดมากขึ้นเพื่อให้แน่ใจว่าผลลัพธ์ที่เกี่ยวข้องที่สุดจะได้รับการจัดอันดับเป็นอันดับแรก BERT เป็นโมเดลภาษาที่ผ่านการฝึกอบรมล่วงหน้าโดยอิงตาม Transformer ซึ่งสามารถเข้าใจความสัมพันธ์เชิงบริบทระหว่างคำในประโยคได้ ในการค้นหา BERT จะถูกใช้เพื่อจัดอันดับเอกสารที่ดึงมาในตอนแรกใหม่ โดยจะจัดอันดับเอกสารใหม่โดยการเข้ารหัสแบบสอบถามและเอกสารร่วมกันและคำนวณคะแนนความเกี่ยวข้องระหว่างทั้งสอง ตัวอย่างเช่น สำหรับแบบสอบถาม "จอดรถบนทางลาดโดยไม่มีขอบถนน" BERT สามารถเข้าใจความหมายของ "ไม่มีขอบถนน" และส่งคืนหน้าที่แนะนำให้ผู้ขับขี่หมุนพวงมาลัยไปทางขอบถนน แทนที่จะตีความผิดว่าเป็นสถานการณ์ที่มีขอบถนน สำหรับวิศวกร SEO จำเป็นต้องเรียนรู้อัลกอริทึมคำแนะนำของการจัดอันดับของ Google และการเรียนรู้ของเครื่องอย่างแม่นยำเพื่อเพิ่มประสิทธิภาพเนื้อหาของหน้าเว็บในลักษณะที่กำหนดเป้าหมายเพื่อให้ได้การแสดงผลในอันดับที่สูงขึ้น
ข้างต้นคือเวิร์กโฟลว์ทั่วไปของเครื่องมือค้นหา Google อย่างไรก็ตาม ในยุคปัจจุบันที่มี AI และข้อมูลขนาดใหญ่เพิ่มขึ้นอย่างรวดเร็ว ผู้ใช้มีความต้องการใหม่ๆ สำหรับการโต้ตอบกับเบราว์เซอร์
เหตุใด AI จึงจะปรับเปลี่ยนเบราว์เซอร์
ก่อนอื่น เราจำเป็นต้องชี้แจงก่อนว่าทำไมแบบฟอร์มเบราว์เซอร์จึงยังคงมีอยู่ มีแบบฟอร์มที่สามซึ่งเป็นตัวเลือกอื่นนอกเหนือจากตัวแทนปัญญาประดิษฐ์และเบราว์เซอร์หรือไม่
เราเชื่อว่าการดำรงอยู่เป็นสิ่งที่ไม่สามารถทดแทนได้ ทำไมปัญญาประดิษฐ์จึงใช้เบราว์เซอร์ได้ แต่ไม่สามารถแทนที่ได้ทั้งหมด เนื่องจากเบราว์เซอร์เป็นแพลตฟอร์มสากล ไม่เพียงแต่เป็นจุดเข้าสำหรับการอ่านข้อมูลเท่านั้น แต่ยังเป็นจุดเข้าสากลสำหรับการป้อนข้อมูลอีกด้วย โลกนี้ไม่เพียงแต่มีข้อมูลอินพุตเท่านั้น แต่ยังต้องสร้างข้อมูลและโต้ตอบกับเว็บไซต์ด้วย ดังนั้นเบราว์เซอร์ที่ผสานรวมข้อมูลผู้ใช้ส่วนบุคคลจึงยังคงมีอยู่ทั่วไป
เราเข้าใจประเด็นนี้: เบราว์เซอร์เป็นจุดเข้าใช้งานสากล ไม่เพียงแต่สำหรับการอ่านข้อมูลเท่านั้น แต่ผู้ใช้มักต้องโต้ตอบกับข้อมูลด้วย เบราว์เซอร์เองเป็นสถานที่ที่ยอดเยี่ยมสำหรับจัดเก็บลายนิ้วมือผู้ใช้ พฤติกรรมผู้ใช้ที่ซับซ้อนกว่าและพฤติกรรมอัตโนมัติจะต้องดำเนินการผ่านเบราว์เซอร์ เบราว์เซอร์สามารถจัดเก็บลายนิ้วมือพฤติกรรมผู้ใช้ทั้งหมด บัตรผ่าน และข้อมูลความเป็นส่วนตัวอื่นๆ และใช้การโทรแบบไม่ต้องไว้วางใจระหว่างกระบวนการอัตโนมัติ การดำเนินการโต้ตอบกับข้อมูลสามารถพัฒนาเป็น:
ผู้ใช้ → เรียกใช้ AI Agent → เบราว์เซอร์
กล่าวอีกนัยหนึ่ง ส่วนเดียวที่อาจจะถูกแทนที่ได้คือส่วนที่สอดคล้องกับแนวโน้มวิวัฒนาการของโลก ซึ่งก็คือมีความชาญฉลาดมากขึ้น มีความเป็นส่วนตัวมากขึ้น และทำงานอัตโนมัติมากขึ้น ยอมรับว่าส่วนนี้สามารถจัดการได้โดย AI Agent แต่ตัว AI Agent เองนั้นไม่เหมาะที่จะนำมาใช้ในการนำเสนอเนื้อหาที่ปรับแต่งตามผู้ใช้ เนื่องจากต้องเผชิญกับความท้าทายหลายประการในแง่ของความปลอดภัยและความสะดวกของข้อมูล โดยเฉพาะอย่างยิ่ง:
เบราว์เซอร์เป็นที่จัดเก็บเนื้อหาที่ปรับแต่งตามความต้องการ:
1. โมเดลขนาดใหญ่ส่วนใหญ่โฮสต์อยู่ในระบบคลาวด์ และบริบทของเซสชันจะถูกบันทึกไว้บนเซิร์ฟเวอร์ ทำให้ยากต่อการเรียกข้อมูลที่ละเอียดอ่อน เช่น รหัสผ่านในเครื่อง กระเป๋าสตางค์ และคุกกี้โดยตรง
2. การส่งข้อมูลการเรียกดูและการชำระเงินทั้งหมดไปยังบุคคลที่สามนั้นต้องได้รับอนุญาตอีกครั้งจากผู้ใช้ ทั้ง DMA ของสหภาพยุโรปและกฎหมายความเป็นส่วนตัวของรัฐต่างๆ ในสหรัฐอเมริกาต่างก็กำหนดให้ลดการถ่ายโอนข้อมูลขาออกให้เหลือน้อยที่สุด
3. การกรอกรหัสตรวจสอบสองปัจจัยโดยอัตโนมัติ การเรียกใช้กล้อง หรือการใช้ GPU สำหรับการอนุมาน WebGPU จะต้องดำเนินการทั้งหมดในแซนด์บ็อกซ์ของเบราว์เซอร์
4. บริบทของข้อมูลขึ้นอยู่กับเบราว์เซอร์เป็นอย่างมาก รวมถึงแท็บ คุกกี้ IndexedDB แคช Service Worker ข้อมูลประจำตัว Passkey และข้อมูลขยาย ซึ่งทั้งหมดนี้จะถูกฝากไว้ในเบราว์เซอร์
การเปลี่ยนแปลงอย่างลึกซึ้งในรูปแบบของการโต้ตอบ
กลับมาที่หัวข้อเดิม พฤติกรรมการใช้เบราว์เซอร์ของเราสามารถแบ่งได้คร่าวๆ เป็น 3 รูปแบบ ได้แก่ การอ่านข้อมูล การป้อนข้อมูล และการโต้ตอบกับข้อมูล โมเดลบิ๊กโมเดลของปัญญาประดิษฐ์ (LLM) ได้เปลี่ยนแปลงประสิทธิภาพและวิธีการอ่านข้อมูลไปอย่างมาก ในอดีต พฤติกรรมของผู้ใช้ในการค้นหาหน้าเว็บโดยใช้คีย์เวิร์ดนั้นดูเก่าและไม่มีประสิทธิภาพมากนัก
มีการศึกษาจำนวนมากที่วิเคราะห์ถึงวิวัฒนาการของพฤติกรรมการค้นหาของผู้ใช้ ไม่ว่าจะเป็นการรับคำตอบโดยสรุปหรือการคลิกบนหน้าเว็บ
จากการศึกษาในปี 2024 พบว่าจากการค้นหาใน Google 1,000 ครั้งในสหรัฐอเมริกา มีเพียง 374 ครั้งเท่านั้นที่คลิกบนหน้าเว็บที่เปิดอยู่ กล่าวอีกนัยหนึ่ง พฤติกรรม "ไม่ต้องคลิกเลย" มีอยู่เกือบ 63% ผู้ใช้คุ้นเคยกับการรับข้อมูล เช่น สภาพอากาศ อัตราแลกเปลี่ยน และการ์ดความรู้โดยตรงจากหน้าผลการค้นหา
จากการสำรวจในปี 2023 พบว่าผู้ตอบแบบสอบถาม 44% เชื่อว่าผลลัพธ์ตามธรรมชาติทั่วไปมีความน่าเชื่อถือมากกว่าสไนเป็ตที่โดดเด่น นอกจากนี้ การวิจัยทางวิชาการยังพบด้วยว่าในหัวข้อที่ถกเถียงกันหรือไม่มีข้อเท็จจริงที่เป็นหนึ่งเดียวกัน ผู้ใช้จะชอบหน้าผลลัพธ์ที่มีลิงก์แหล่งที่มาหลายแหล่ง
กล่าวคือ ผู้ใช้บางคนไม่ค่อยเชื่อถือสรุปของ AI มากนัก แต่พฤติกรรมของผู้ใช้จำนวนมากได้เปลี่ยนไปเป็น "ไม่ต้องคลิกเลย" ดังนั้น เบราว์เซอร์ AI ยังคงต้องสำรวจรูปแบบโต้ตอบที่เหมาะสม โดยเฉพาะในส่วนการอ่านข้อมูล เนื่องจาก "ปัญหาภาพหลอน" ของโมเดลขนาดใหญ่ในปัจจุบันยังไม่ถูกกำจัด และผู้ใช้จำนวนมากยังคงพบว่ายากที่จะไว้วางใจสรุปเนื้อหาที่สร้างขึ้นโดยอัตโนมัติได้อย่างสมบูรณ์ ในเรื่องนี้ หากฝังโมเดลขนาดใหญ่ไว้ในเบราว์เซอร์ จริงๆ แล้วไม่จำเป็นต้องทำการเปลี่ยนแปลงที่ก่อให้เกิดความวุ่นวายกับเบราว์เซอร์ แต่เพียงแก้ไขความแม่นยำและการควบคุมของโมเดลทีละน้อยเท่านั้น การปรับปรุงนี้ได้รับการส่งเสริมอย่างต่อเนื่องเช่นกัน
สิ่งที่อาจกระตุ้นให้เกิดการเปลี่ยนแปลงครั้งใหญ่ในเบราว์เซอร์ได้จริง ๆ ก็คือเลเยอร์การโต้ตอบข้อมูล ในอดีต ผู้คนทำการโต้ตอบโดยป้อนคำหลัก ซึ่งเป็นขีดจำกัดของสิ่งที่เบราว์เซอร์สามารถเข้าใจได้ ปัจจุบัน ผู้ใช้มีแนวโน้มที่จะใช้ภาษาธรรมชาติทั้งย่อหน้าเพื่ออธิบายงานที่ซับซ้อน เช่น:
● “ค้นหาเที่ยวบินตรงจากนิวยอร์กไปลอสแองเจลิสในช่วงระยะเวลาหนึ่ง”
● “ค้นหาเที่ยวบินจากนิวยอร์กไปเซี่ยงไฮ้แล้วไปลอสแองเจลิส”
พฤติกรรมเหล่านี้ แม้แต่สำหรับมนุษย์ ก็ต้องใช้เวลานานในการเข้าชมเว็บไซต์หลายแห่ง รวบรวมและเปรียบเทียบข้อมูล อย่างไรก็ตาม งานเหล่านี้ค่อยๆ ถูกแทนที่โดยตัวแทน AI
ซึ่งยังสอดคล้องกับทิศทางของวิวัฒนาการทางประวัติศาสตร์ นั่นคือ ระบบอัตโนมัติและปัญญาประดิษฐ์ ผู้คนต่างกระตือรือร้นที่จะปล่อยมือให้เป็นอิสระ และเอเจนต์ AI จะถูกฝังลึกอยู่ในเบราว์เซอร์ เบราว์เซอร์ในอนาคตจะต้องได้รับการออกแบบให้ทำงานอัตโนมัติเต็มรูปแบบ โดยเฉพาะอย่างยิ่งเมื่อพิจารณาถึง:
● วิธีสร้างสมดุลระหว่างประสบการณ์การอ่านของมนุษย์และความสามารถในการแยกวิเคราะห์ของ AI Agent
● วิธีการให้บริการทั้งผู้ใช้และตัวแทนบนหน้าเดียวกัน
เมื่อการออกแบบตรงตามข้อกำหนดสองข้อนี้เท่านั้น เบราว์เซอร์จึงจะกลายเป็นตัวพาที่มีเสถียรภาพสำหรับ AI Agent เพื่อดำเนินการงานต่างๆ ได้อย่างแท้จริง
ต่อไป เราจะมุ่งเน้นไปที่โครงการที่ได้รับการรอคอยอย่างสูง 5 โครงการ ได้แก่ Browser Use, Arc (The Browser Company), Perplexity, Brave และ Donut โครงการเหล่านี้แสดงถึงวิวัฒนาการในอนาคตของเบราว์เซอร์ AI และศักยภาพในการบูรณาการแบบเนทีฟในสถานการณ์ Web3 และ Crypto
การใช้เบราว์เซอร์
นี่คือเหตุผลหลักเบื้องหลังการระดมทุนมหาศาลสำหรับ Perplexity และ Browser Use โดยเฉพาะอย่างยิ่ง Browser Use ถือเป็นโอกาสด้านนวัตกรรมที่มีความแน่นอนและมีศักยภาพในการเติบโตสูงเป็นอันดับสอง ซึ่งจะเกิดขึ้นในช่วงครึ่งแรกของปี 2025

การใช้เบราว์เซอร์ แหล่งที่มา: การใช้เบราว์เซอร์
เบราว์เซอร์ได้สร้างเลเยอร์ความหมายที่แท้จริง ซึ่งมีแกนหลักเพื่อสร้างสถาปัตยกรรมการจดจำความหมายสำหรับเบราว์เซอร์รุ่นถัดไป
Browser Use ถอดรหัส "DOM = node tree แบบดั้งเดิมสำหรับมนุษย์" เป็น "DOM แบบซีแมนติก = คำสั่ง tree สำหรับ LLM" ซึ่งช่วยให้เอเจนต์สามารถคลิก กรอกข้อมูล และอัปโหลดได้อย่างแม่นยำโดยไม่ต้อง "ดูพิกัดของจุดฟิล์ม" เส้นทางนี้แทนที่ OCR แบบภาพหรือ Selenium พิกัดด้วย "ข้อความที่มีโครงสร้าง → การเรียกใช้ฟังก์ชัน" ดังนั้นการดำเนินการจึงเร็วขึ้น โทเค็นจะถูกบันทึก และมีข้อผิดพลาดน้อยลง TechCrunch เรียกสิ่งนี้ว่า "ชั้นกาวที่ช่วยให้ AI เข้าใจหน้าเว็บได้อย่างแท้จริง" และรอบเริ่มต้นมูลค่า 17 ล้านเหรียญสหรัฐที่เสร็จสิ้นในเดือนมีนาคมเป็นการเดิมพันกับนวัตกรรมพื้นฐานนี้
หลังจากการเรนเดอร์ HTML แล้ว จะมีการสร้างต้นไม้ DOM มาตรฐานขึ้นมา จากนั้นเบราว์เซอร์จะสร้างต้นไม้การช่วยสำหรับการเข้าถึงเพื่อให้โปรแกรมอ่านหน้าจอได้รับแท็ก "บทบาท" และ "สถานะ" ที่สมบูรณ์ยิ่งขึ้น
1. สรุปองค์ประกอบเชิงโต้ตอบแต่ละองค์ประกอบ (<ปุ่ม>, <อินพุต> ฯลฯ) ลงในส่วน JSON ที่มีข้อมูลเมตาเช่น บทบาท ความสามารถในการมองเห็น พิกัด การดำเนินการที่ดำเนินการได้ ฯลฯ
2. แปลหน้าทั้งหมดเป็น "รายการโหนดความหมาย" ที่เรียบเพื่อให้ LLM อ่านในพรอมต์ระบบพร้อมกัน
3. รับคำสั่งระดับสูง (เช่น click(node_id="btn-Checkout")) ที่ส่งออกโดย LLM และเล่นกลับไปยังเบราว์เซอร์จริง บล็อกอย่างเป็นทางการเรียกกระบวนการนี้ว่า "การแปลงอินเทอร์เฟซเว็บไซต์เป็นข้อความที่มีโครงสร้างซึ่งสามารถแยกวิเคราะห์ได้โดย LLM"
ในเวลาเดียวกัน เมื่อนำชุดมาตรฐานนี้ไปใช้ใน W3C ก็สามารถแก้ปัญหาอินพุตของเบราว์เซอร์ได้ในระดับหนึ่ง เราใช้จดหมายเปิดผนึกและกรณีศึกษาของ The Browser Company เพื่ออธิบายเพิ่มเติมว่าเหตุใดแนวคิดของ The Browser Company จึงผิด
อาร์ค
บริษัท Browser Company (บริษัทแม่ของ Arc) ระบุในจดหมายเปิดผนึกว่าเบราว์เซอร์ ARC จะเข้าสู่ระยะบำรุงรักษาตามปกติ และทีมงานจะมุ่งเน้นไปที่ DIA ซึ่งเป็นเบราว์เซอร์ที่เน้น AI เป็นหลัก จดหมายฉบับดังกล่าวยังยอมรับว่ายังไม่มีการกำหนดเส้นทางการใช้งาน DIA อย่างชัดเจน ในขณะเดียวกัน ทีมงานได้ทำนายเกี่ยวกับตลาดเบราว์เซอร์ในอนาคตหลายประการในจดหมายดังกล่าว จากการคาดการณ์เหล่านี้ เราเชื่อต่อไปว่าหากเราต้องการโค่นล้มภูมิทัศน์ของเบราว์เซอร์ที่มีอยู่จริง สิ่งสำคัญคือการเปลี่ยนแปลงเอาต์พุตในฝั่งอินเทอร์แอคทีฟ
นี่คือสามคำทำนายที่เราได้รับจากทีม ARC เกี่ยวกับอนาคตของตลาดเบราว์เซอร์
เว็บเพจจะไม่ใช่อินเทอร์เฟซหลักอีกต่อไป เบราว์เซอร์แบบดั้งเดิมถูกสร้างขึ้นมาเพื่อโหลดเว็บเพจ แต่เว็บเพจ เช่น แอป บทความ และไฟล์ จะกลายเป็นเครื่องมือเรียกใช้อินเทอร์เฟซแชท AI มากขึ้นเรื่อยๆ อินเทอร์เฟซแชททำหน้าที่เหมือนเบราว์เซอร์อยู่แล้ว โดยจะค้นหา อ่าน สร้าง และตอบสนอง อินเทอร์เฟซจะโต้ตอบกับ API, LLM, ฐานข้อมูล และผู้คนใช้เวลากับอินเทอร์เฟซเหล่านี้วันละหลายชั่วโมง หากคุณยังลังเลใจ ให้โทรหาลูกพี่ลูกน้องในโรงเรียนมัธยมหรือมหาวิทยาลัย อินเทอร์เฟซภาษาธรรมชาติซึ่งแยกความน่าเบื่อของรูปแบบการคำนวณแบบเก่าออกไปจะคงอยู่ต่อไป
แต่เว็บจะไม่หายไปไหนอย่างแน่นอน อย่างน้อยก็ไม่ใช่ในเร็วๆ นี้ Figma และ The New York Times ไม่ได้มีความสำคัญน้อยลง เจ้านายของคุณไม่ได้ทิ้งเครื่องมือ SaaS ของทีมคุณ ตรงกันข้ามเลย เรายังคงต้องแก้ไขเอกสาร ดูวิดีโอ อ่านบทความสุดสัปดาห์จากผู้จัดพิมพ์ที่เราชื่นชอบ พูดตรงๆ ก็คือ เว็บเพจจะไม่ถูกแทนที่ แต่ยังคงมีความจำเป็น แท็บของเราไม่ใช่ของสิ้นเปลือง แต่เป็นบริบทหลักของเรา นั่นคือเหตุผลที่เราคิดว่าอินเทอร์เฟซที่ทรงพลังที่สุดสำหรับ AI บนเดสก์ท็อปจะไม่ใช่เว็บเบราว์เซอร์หรืออินเทอร์เฟซแชท AI แต่จะเป็นทั้งสองอย่าง เหมือนเนยถั่วกับเยลลี่ เช่นเดียวกับที่ iPhone รวมหมวดหมู่เก่าเข้าด้วยกันเป็นสิ่งใหม่ที่แตกต่างอย่างสิ้นเชิง เบราว์เซอร์ AI ก็เช่นกัน แม้ว่าไม่ใช่ของเราที่ชนะ
อินเทอร์เฟซใหม่เริ่มต้นจากอินเทอร์เฟซที่คุ้นเคย ในโลกใหม่นี้ พลังตรงข้ามสองประการเกิดขึ้นพร้อมกัน วิธีการใช้งานคอมพิวเตอร์ของเราเปลี่ยนแปลงไปเร็วกว่ามาก (เนื่องมาจาก AI) มากกว่าที่คนส่วนใหญ่ยอมรับ แต่ในขณะเดียวกัน เราก็ห่างไกลจากการละทิ้งวิธีการแบบเก่าไปมาก ซึ่งมากกว่าที่ผู้เชี่ยวชาญด้าน AI ให้ความสำคัญ Cursor พิสูจน์ทฤษฎีนี้ในพื้นที่การเขียนโค้ด: แอป AI ที่ก้าวล้ำในปีที่แล้วเป็น IDE (เก่า) ที่ออกแบบมาให้เป็น AI ดั้งเดิม OpenAI ยืนยันทฤษฎีนี้เมื่อพวกเขาซื้อ Windsurf (IDE AI อีกตัวหนึ่ง) แม้ว่าจะมี Codex ที่ทำงานเงียบๆ อยู่เบื้องหลัง เราเชื่อว่าเบราว์เซอร์ AI จะมาถึงในลำดับต่อไป
ประการแรก เชื่อว่าเว็บเพจไม่ใช่อินเทอร์เฟซแบบโต้ตอบหลักอีกต่อไป ยอมรับว่านี่เป็นการตัดสินใจที่ท้าทาย และเป็นสาเหตุสำคัญที่ทำให้เรามีข้อสงสัยเกี่ยวกับผลลัพธ์ของการไตร่ตรองของผู้ก่อตั้ง ในความเห็นของเรา มุมมองนี้ประเมินบทบาทของเบราว์เซอร์ต่ำเกินไปอย่างมาก ซึ่งเป็นประเด็นสำคัญที่มองข้ามเมื่อสำรวจเส้นทางของเบราว์เซอร์ AI
โมเดลขนาดใหญ่มีความโดดเด่นในการจับเจตนา เช่น การเข้าใจคำสั่ง เช่น "จองตั๋วเครื่องบินให้ฉัน" อย่างไรก็ตาม โมเดลเหล่านี้ยังคงขาดความหนาแน่นของข้อมูล เมื่อผู้ใช้ต้องการแดชบอร์ด แผ่นจดบันทึกแบบ Bloomberg Terminal หรือผืนผ้าใบภาพอย่าง Figma ไม่มีอะไรจะดีไปกว่าหน้าเว็บเฉพาะที่จัดเรียงด้วยความแม่นยำระดับพิกเซล การออกแบบตามหลักสรีรศาสตร์ที่ปรับแต่งให้เหมาะกับผลิตภัณฑ์แต่ละชิ้น เช่น แผนภูมิ ฟังก์ชันลากและวาง ฮ็อตคีย์ ไม่ใช่สิ่งที่ไร้ค่าแต่เป็นความสามารถในการรับรู้ที่บีบอัด ความสามารถเหล่านี้ไม่สามารถทำได้ด้วยการโต้ตอบแบบสนทนาธรรมดา หากใช้ Gate.com เป็นตัวอย่าง หากผู้ใช้ต้องการดำเนินการลงทุน การพึ่งพาการสนทนาด้วย AI เพียงอย่างเดียวยังไม่เพียงพอ เนื่องจากผู้ใช้ต้องพึ่งพาข้อมูลอินพุต ความแม่นยำ และการนำเสนอที่มีโครงสร้างสูง
ทีม RC มีความเบี่ยงเบนที่สำคัญในสมมติฐานเส้นทางของตน นั่นคือ ไม่สามารถแยกแยะอย่างชัดเจนว่า "ปฏิสัมพันธ์" ประกอบด้วยสองมิติ: อินพุตและเอาต์พุต ในด้านอินพุต มุมมองของทีมนั้นสมเหตุสมผลในบางสถานการณ์ และ AI สามารถปรับปรุงประสิทธิภาพของการโต้ตอบตามคำสั่งได้ แต่ในด้านเอาต์พุต การตัดสินนั้นไม่สมดุลอย่างเห็นได้ชัด โดยละเลยบทบาทหลักของเบราว์เซอร์ในการนำเสนอข้อมูลและประสบการณ์ส่วนบุคคล ตัวอย่างเช่น Reddit มีเค้าโครงและสถาปัตยกรรมข้อมูลที่เป็นเอกลักษณ์ ในขณะที่ AAVE มีอินเทอร์เฟซและโครงสร้างที่แตกต่างไปโดยสิ้นเชิง ในฐานะแพลตฟอร์มที่สามารถรองรับข้อมูลส่วนตัวสูงและแสดงอินเทอร์เฟซผลิตภัณฑ์ที่หลากหลาย ความสามารถในการแทนที่เบราว์เซอร์ในเลเยอร์อินพุตนั้นมีจำกัด และในด้านเอาต์พุต ความซับซ้อนและการไม่เป็นมาตรฐานทำให้ยากที่จะถูกโค่นล้ม ในทางตรงกันข้าม เบราว์เซอร์ AI ในปัจจุบันในตลาดมีการมุ่งเน้นไปที่ระดับ "สรุปผลลัพธ์" มากขึ้น ซึ่งได้แก่ การสรุปหน้าเว็บ การปรับแต่งข้อมูล และการสรุปผล ซึ่งยังไม่เพียงพอที่จะเป็นความท้าทายพื้นฐานต่อเบราว์เซอร์กระแสหลักหรือระบบค้นหาเช่น Google และมีเพียงส่วนแบ่งการตลาดของสรุปการค้นหาเท่านั้นที่ถูกแบ่งออก
ดังนั้น ผู้ที่สามารถเขย่า Chrome ซึ่งมีส่วนแบ่งการตลาดสูงถึง 66% ได้อย่างแท้จริงนั้น ถูกกำหนดให้ไม่ใช่ "Chrome ตัวต่อไป" เพื่อให้บรรลุการเปลี่ยนแปลงนี้ โหมดการแสดงผลของเบราว์เซอร์จะต้องถูกปรับเปลี่ยนโดยพื้นฐานเพื่อให้สามารถปรับให้เข้ากับความต้องการแบบโต้ตอบที่ถูกครอบงำโดยตัวแทน AI ในยุคอัจฉริยะ โดยเฉพาะอย่างยิ่งในการออกแบบสถาปัตยกรรมของฝั่งอินพุต ด้วยเหตุนี้ เราจึงสนับสนุนแนวทางทางเทคนิคของ Browser Use มากกว่า โดยมุ่งเน้นไปที่การเปลี่ยนแปลงโครงสร้างในกลไกพื้นฐานของเบราว์เซอร์ เมื่อระบบใดๆ ถูก "ทำให้เป็นอะตอม" หรือ "แยกส่วน" ความสามารถในการเขียนโปรแกรมและการผสมผสานที่เกิดขึ้นจะนำมาซึ่งศักยภาพในการทำลายล้างที่รุนแรงอย่างยิ่ง และนี่คือทิศทางที่ Browser Use กำลังก้าวไปในปัจจุบัน
โดยสรุป การทำงานของ AI Agent ยังคงขึ้นอยู่กับการมีอยู่ของเบราว์เซอร์เป็นอย่างมาก เบราว์เซอร์ไม่เพียงแต่เป็นที่เก็บข้อมูลส่วนตัวที่ซับซ้อนเป็นหลักเท่านั้น แต่ยังเป็นอินเทอร์เฟซการแสดงผลสากลสำหรับแอปพลิเคชันที่หลากหลายอีกด้วย ดังนั้นในอนาคต AI Agent จะยังคงทำหน้าที่เป็นช่องทางการโต้ตอบหลักต่อไป เนื่องจาก AI Agent ฝังตัวอยู่ในเบราว์เซอร์อย่างลึกซึ้งเพื่อทำงานที่กำหนด จึงโต้ตอบกับแอปพลิเคชันเฉพาะโดยเรียกข้อมูลผู้ใช้ นั่นคือ ทำหน้าที่หลักที่ฝั่งอินพุต เพื่อจุดประสงค์นี้ โหมดการแสดงผลที่มีอยู่ของเบราว์เซอร์จำเป็นต้องได้รับการสร้างสรรค์ใหม่เพื่อให้มีความเข้ากันได้และปรับตัวสูงสุดกับ AI Agent เพื่อให้จับภาพแอปพลิเคชันได้อย่างมีประสิทธิภาพมากขึ้น
ความสับสน
Perplexity คือเสิร์ชเอ็นจิ้น AI ที่รู้จักกันในระบบแนะนำข้อมูล โดยมูลค่าล่าสุดอยู่ที่ 14,000 ล้านดอลลาร์ ซึ่งเกือบ 5 เท่าของ 3,000 ล้านดอลลาร์ในเดือนมิถุนายน 2024 โดยประมวลผลคำค้นหามากกว่า 400 ล้านคำต่อเดือน และประมวลผลคำค้นหาประมาณ 250 ล้านคำในเดือนกันยายน 2024 จำนวนคำค้นหาของผู้ใช้เพิ่มขึ้นแปดเท่าเมื่อเทียบเป็นรายปี และจำนวนผู้ใช้ที่ใช้งานจริงต่อเดือนเกิน 30 ล้านราย
คุณสมบัติหลักคือสามารถสรุปหน้าต่างๆ ได้แบบเรียลไทม์ ซึ่งทำให้ได้เปรียบในการรับข้อมูลทันที เมื่อต้นปีนี้ บริษัทได้เริ่มสร้างเบราว์เซอร์เนทีฟของตัวเองที่มีชื่อว่า Comet โดย Perplexity อธิบายว่า Comet รุ่นใหม่เป็นเบราว์เซอร์ที่ไม่เพียงแต่ "แสดง" เว็บเพจเท่านั้น แต่ยัง "คิด" เกี่ยวกับเว็บเพจเหล่านั้นด้วย เจ้าหน้าที่กล่าวว่าบริษัทจะฝังกลไกคำตอบของ Perplexity ไว้ภายในเบราว์เซอร์ ซึ่งเป็นแนวคิด "ทั้งเครื่อง" แบบเดียวกับที่ Steve Jobs ทำ นั่นคือฝังงาน AI ไว้ลึกๆ ในเลเยอร์ล่างสุดของเบราว์เซอร์ แทนที่จะสร้างปลั๊กอินแถบด้านข้าง แทนที่ "ลิงก์สีน้ำเงินสิบลิงก์" แบบดั้งเดิมด้วยคำตอบสั้นๆ พร้อมการอ้างอิง ซึ่งจะแข่งขันกับ Chrome โดยตรง
กูเกิล ไอ/โอ 2025
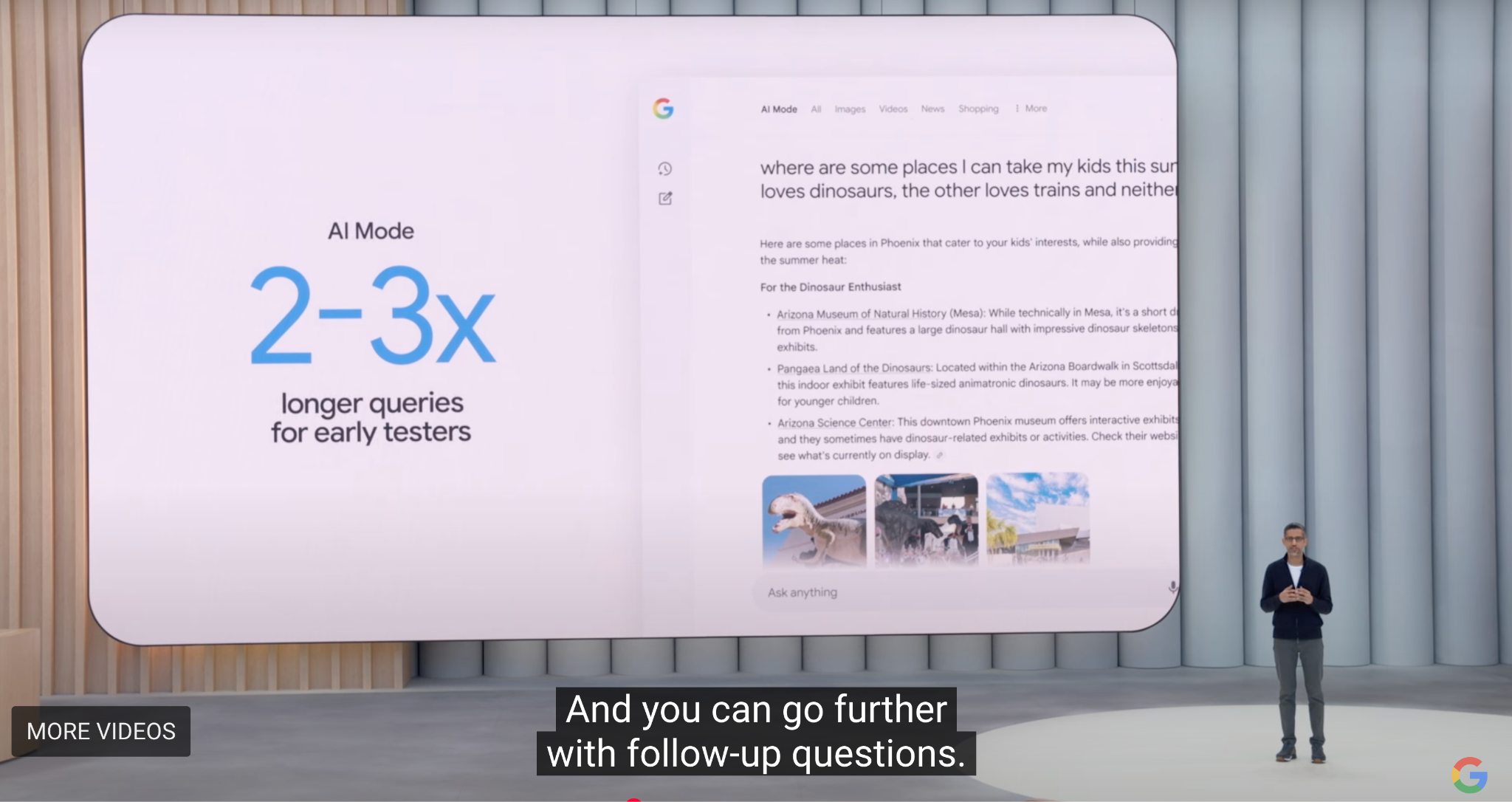
แต่ยังต้องแก้ปัญหาหลักสองประการ ได้แก่ ต้นทุนการค้นหาที่สูงและอัตรากำไรที่ต่ำจากผู้ใช้ที่ด้อยโอกาส แม้ว่า Perplexity จะอยู่ในตำแหน่งผู้นำในด้านการค้นหาด้วย AI แล้ว แต่ Google ยังได้ประกาศการปรับโฉมผลิตภัณฑ์หลักในระดับใหญ่ที่การประชุม I/O 2025 เพื่อตอบสนองต่อการปรับโฉมเบราว์เซอร์ Google ได้เปิดตัวประสบการณ์แท็บเบราว์เซอร์ใหม่ที่เรียกว่า AI Model ซึ่งผสานรวม Overview, Deep Research และฟีเจอร์ Agentic ในอนาคต โปรเจ็กต์โดยรวมนี้เรียกว่า "Project Mariner"
Google กำลังปรับเปลี่ยน AI อย่างแข็งขัน ดังนั้นจึงเป็นเรื่องยากที่จะก่อให้เกิดภัยคุกคามต่อ AI จริง ๆ ด้วยการเลียนแบบฟังก์ชันของ AI บนพื้นผิว เช่น Overview, DeepResearch หรือ Agentics สิ่งที่น่าจะสร้างระเบียบใหม่ท่ามกลางความสับสนวุ่นวายได้จริง ๆ คือการสร้างสถาปัตยกรรมเบราว์เซอร์ขึ้นมาใหม่ตั้งแต่ล่างขึ้นบน ฝังโมเดลภาษาขนาดใหญ่ (LLM) ลงในเคอร์เนลของเบราว์เซอร์อย่างลึกซึ้ง และทำให้เกิดการเปลี่ยนแปลงพื้นฐานในวิธีการโต้ตอบ
กล้าหาญ
Brave เป็นเบราว์เซอร์รุ่นแรกและประสบความสำเร็จมากที่สุดในอุตสาหกรรม Crypto เบราว์เซอร์นี้ใช้สถาปัตยกรรม Chromium จึงเข้ากันได้กับปลั๊กอินบน Google Store เบราว์เซอร์นี้ใช้ความเป็นส่วนตัวและรูปแบบการรับโทเค็นผ่านเบราว์เซอร์เพื่อดึงดูดผู้ใช้ เส้นทางการพัฒนาของ Brave ได้แสดงให้เห็นถึงศักยภาพในการเติบโตในระดับหนึ่ง อย่างไรก็ตาม จากมุมมองของผลิตภัณฑ์ ความเป็นส่วนตัวมีความสำคัญ แต่ความต้องการยังคงกระจุกตัวอยู่ในกลุ่มผู้ใช้เฉพาะ และการตระหนักถึงความเป็นส่วนตัวยังไม่ได้กลายมาเป็นปัจจัยหลักในการตัดสินใจสำหรับประชาชนทั่วไป ดังนั้น ความเป็นไปได้ในการพยายามโค่นล้มยักษ์ใหญ่ที่มีอยู่โดยอาศัยฟีเจอร์นี้จึงมีน้อย
ณ ตอนนี้ Brave มีผู้ใช้งานรายเดือน 82.7 ล้านคน และผู้ใช้งานรายวัน 35.6 ล้านคน โดยมีส่วนแบ่งการตลาดประมาณ 1% - 1.5% จำนวนผู้ใช้งานยังคงเติบโตอย่างต่อเนื่อง จาก 6 ล้านคนในเดือนกรกฎาคม 2019 เป็น 25 ล้านคนในเดือนมกราคม 2021, 57 ล้านคนในเดือนมกราคม 2023 และมากกว่า 82 ล้านคนในเดือนกุมภาพันธ์ 2025 โดยมีอัตราการเติบโตเฉลี่ยต่อปีแบบทบต้นสองหลัก ปริมาณการค้นหาเฉลี่ยต่อเดือนอยู่ที่ประมาณ 1.34 พันล้านครั้ง ซึ่งคิดเป็นประมาณ 0.3% ของ Google
ด้านล่างนี้คือแผนงานแบบวนซ้ำของ Brave

Brave กำลังวางแผนที่จะอัปเกรดเป็นเบราว์เซอร์ AI ที่ให้ความสำคัญกับความเป็นส่วนตัวเป็นอันดับแรก อย่างไรก็ตาม เนื่องจากการเข้าถึงข้อมูลผู้ใช้มีจำกัด ทำให้โมเดลขนาดใหญ่ปรับแต่งได้น้อยลง ซึ่งไม่เอื้อต่อการผลิตผลิตภัณฑ์ที่รวดเร็วและแม่นยำ ในยุคของ Agentic Browser ที่กำลังจะมาถึง Brave อาจรักษาส่วนแบ่งที่มั่นคงในกลุ่มผู้ใช้ที่ใส่ใจความเป็นส่วนตัวบางกลุ่มได้ แต่การจะกลายเป็นผู้เล่นหลักนั้นเป็นเรื่องยาก ผู้ช่วย AI อย่าง Leo นั้นเป็นเหมือนปลั๊กอินมากกว่า ซึ่งช่วยเพิ่มประสิทธิภาพการทำงานของผลิตภัณฑ์ที่มีอยู่เท่านั้น และมีความสามารถบางอย่างในการสรุปเนื้อหา แต่ไม่มีกลยุทธ์ที่ชัดเจนในการเปลี่ยนไปใช้ AI Agent อย่างสมบูรณ์ และนวัตกรรมในระดับการโต้ตอบยังไม่เพียงพอ
โดนัท
เมื่อไม่นานนี้ อุตสาหกรรม Crypto ก็มีความก้าวหน้าในด้าน Agentic Browser เช่นกัน โปรเจ็กต์สตาร์ทอัพ Donut ได้รับเงินทุน 7 ล้านเหรียญสหรัฐในรอบ Pre-seed ซึ่งนำโดย Sequoia China (Hongshan), HackVC และ Bitkraft Ventures โปรเจ็กต์นี้ยังอยู่ในขั้นเริ่มต้นของแนวคิด และวิสัยทัศน์คือการบรรลุความสามารถแบบบูรณาการของ "การค้นพบ การตัดสินใจ และการดำเนินการแบบ crypto-native"
หัวใจสำคัญของแนวทางนี้คือการรวมเส้นทางการดำเนินการอัตโนมัติที่เป็นพื้นฐานของการเข้ารหัสเข้าด้วยกัน ดังที่ a16z ทำนายไว้ ในอนาคต คาดว่าเอเจนต์จะเข้ามาแทนที่เครื่องมือค้นหาเป็นช่องทางเข้าหลัก ผู้ประกอบการจะไม่แข่งขันกันเกี่ยวกับอัลกอริทึมการจัดอันดับของ Google อีกต่อไป แต่จะแข่งขันกันเพื่อการเข้าถึงและการแปลงข้อมูลที่เกิดจากการดำเนินการของเอเจนต์ อุตสาหกรรมเรียกแนวโน้มนี้ว่า "AEO" (Answer/Agent Engine Optimization) หรือเรียกอีกอย่างว่า "ATF" (Agentic Task Fulfilment) ซึ่งก็คือไม่เพิ่มประสิทธิภาพการจัดอันดับการค้นหาอีกต่อไป แต่ให้บริการโมเดลอัจฉริยะโดยตรงที่สามารถทำงานต่างๆ เช่น การวางคำสั่งซื้อ การจองตั๋ว และการเขียนจดหมายให้กับผู้ใช้
สำหรับผู้ประกอบการ
ก่อนอื่น เราต้องยอมรับว่าเบราว์เซอร์เองยังคงเป็น "จุดเข้า" ที่ใหญ่ที่สุดในโลกอินเทอร์เน็ตที่ยังไม่ได้รับการสร้างขึ้นใหม่ มีผู้ใช้เดสก์ท็อปประมาณ 2,100 ล้านคนและผู้ใช้มือถือมากกว่า 4,300 ล้านคนทั่วโลก เบราว์เซอร์เป็นสื่อกลางสำหรับการป้อนข้อมูล พฤติกรรมเชิงโต้ตอบ และการจัดเก็บลายนิ้วมือส่วนบุคคล เหตุผลที่แบบฟอร์มนี้ยังคงอยู่ไม่ใช่เพราะความเฉื่อย แต่เป็นเพราะเบราว์เซอร์มีคุณลักษณะสองทางตามธรรมชาติ นั่นคือเป็นทั้ง "รายการอ่าน" สำหรับข้อมูลและ "ทางออกการเขียน" สำหรับพฤติกรรม
ดังนั้นสำหรับผู้ประกอบการ ศักยภาพในการสร้างความเปลี่ยนแปลงที่แท้จริงจึงไม่ใช่การเพิ่มประสิทธิภาพในระดับ "ผลลัพธ์ของหน้า" แม้ว่าคุณจะสามารถใช้ฟังก์ชันภาพรวมของ AI ที่คล้ายกับ Google ในแท็บใหม่ได้ แต่โดยพื้นฐานแล้วมันเป็นแค่การวนซ้ำของเลเยอร์ปลั๊กอินเบราว์เซอร์และยังไม่ได้สร้างการเปลี่ยนแปลงรูปแบบพื้นฐาน ความก้าวหน้าที่แท้จริงอยู่ที่ "ด้านอินพุต" นั่นคือวิธีทำให้เอเจนต์ AI เรียกใช้ผลิตภัณฑ์ของผู้ประกอบการอย่างแข็งขันเพื่อทำงานเฉพาะให้เสร็จสิ้น นี่จะเป็นกุญแจสำคัญว่าผลิตภัณฑ์ในอนาคตสามารถฝังลงในระบบนิเวศของเอเจนต์และรับปริมาณการใช้งานและการกระจายมูลค่าได้หรือไม่
ในยุคการค้นหา เรียกว่า “คลิก” ในยุคเอเจนซี่ เรียกว่า “โทร”
หากคุณเป็นผู้ประกอบการ คุณควรคิดใหม่เกี่ยวกับผลิตภัณฑ์ของคุณในฐานะส่วนประกอบของ API เพื่อให้ตัวแทนอัจฉริยะไม่เพียงแต่ "อ่าน" ผลิตภัณฑ์ได้เท่านั้น แต่ยังสามารถ "เรียกใช้" ผลิตภัณฑ์ได้อีกด้วย ซึ่งคุณจะต้องพิจารณาสามมิติตั้งแต่เริ่มต้นการออกแบบผลิตภัณฑ์:
1. การสร้างมาตรฐานโครงสร้างอินเทอร์เฟซ: ผลิตภัณฑ์ของคุณ “เรียกได้” หรือไม่
การที่ผลิตภัณฑ์สามารถเรียกใช้งานโดยตัวแทนอัจฉริยะได้หรือไม่นั้น ขึ้นอยู่กับว่าโครงสร้างข้อมูลของผลิตภัณฑ์นั้นสามารถมาตรฐานและสรุปออกมาเป็นโครงร่างที่ชัดเจนได้หรือไม่ ตัวอย่างเช่น การดำเนินการสำคัญๆ เช่น การลงทะเบียนผู้ใช้ ปุ่มสั่งซื้อ และการส่งความคิดเห็น สามารถอธิบายได้โดยใช้โครงสร้าง DOM เชิงความหมายหรือการแมป JSON หรือไม่ ระบบจัดเตรียมสเตตแมชชีนเพื่อให้ตัวแทนสามารถจำลองกระบวนการพฤติกรรมของผู้ใช้ได้อย่างเสถียรหรือไม่ การโต้ตอบของผู้ใช้บนเพจรองรับการคืนค่าด้วยสคริปต์หรือไม่ มี WebHook หรือ API Endpoint ที่เสถียรหรือไม่
นี่เป็นเหตุผลสำคัญที่ทำให้การจัดหาเงินทุนสำหรับ Browser Use ประสบความสำเร็จ เนื่องจากจะช่วยเปลี่ยนเบราว์เซอร์จาก HTML แบบแบนให้กลายเป็นต้นไม้แห่งความหมายที่ LLM เรียกใช้ได้ สำหรับผู้ประกอบการ การนำแนวคิดการออกแบบที่คล้ายกันมาใช้ในผลิตภัณฑ์เว็บก็เพื่อปรับโครงสร้างให้เข้ากับยุค AI Agent
2. การระบุตัวตนและการเข้าถึง: คุณสามารถช่วยให้ตัวแทน “ข้ามผ่านอุปสรรคความไว้วางใจ” ได้หรือไม่
สำหรับตัวแทน AI เพื่อทำธุรกรรม เรียกการชำระเงินหรือสินทรัพย์ พวกเขาต้องมีเลเยอร์กลางที่เชื่อถือได้บางประเภท - คุณสามารถทำได้หรือไม่? เบราว์เซอร์สามารถอ่านที่เก็บข้อมูลในเครื่อง เรียกกระเป๋าสตางค์ ระบุรหัสยืนยัน และเข้าถึงการตรวจสอบสิทธิ์สองปัจจัยได้ตามธรรมชาติ ซึ่งเป็นเหตุผลว่าทำไมจึงเหมาะสมกว่าสำหรับการดำเนินการมากกว่าโมเดลคลาวด์ขนาดใหญ่ โดยเฉพาะอย่างยิ่งในสถานการณ์ Web3: มาตรฐานอินเทอร์เฟซสำหรับการเรียกสินทรัพย์บนเชนไม่ได้รวมเป็นหนึ่ง และตัวแทนจะไม่สามารถดำเนินการต่อไปได้หากไม่มี "ความสามารถในการระบุตัวตน" หรือ "ลายเซ็น"
ดังนั้น สำหรับผู้ประกอบการด้าน Crypto จึงมีพื้นที่ว่างในจินตนาการ: "MCP (แพลตฟอร์มความสามารถหลากหลาย) ในโลกของบล็อคเชน" ซึ่งอาจเป็นชั้นคำสั่งทั่วไป (ให้ตัวแทนเรียกใช้ Dapp) ชุดอินเทอร์เฟซสัญญามาตรฐาน หรือแม้แต่กระเป๋าเงินน้ำหนักเบา + แพลตฟอร์มกลางการระบุตัวตนที่ทำงานภายในเครื่อง
3. การทำความเข้าใจกลไกการจราจรอีกครั้ง: อนาคตไม่ใช่ SEO แต่เป็น AEO/ATF
ในอดีต คุณต้องได้รับความโปรดปรานจากอัลกอริทึมของ Google แต่ตอนนี้ คุณต้องถูกฝังไว้ในห่วงโซ่งานโดย AI Agent ซึ่งหมายความว่าผลิตภัณฑ์จะต้องมีรายละเอียดของงานที่ชัดเจน ไม่ใช่ "หน้า" แต่เป็นสตริงของ "หน่วยความสามารถที่เรียกได้" ซึ่งหมายความว่าคุณต้องเริ่มทำ Agent Optimization (AEO) หรือ Task Scheduling Adaptation (ATF): ตัวอย่างเช่น กระบวนการลงทะเบียนสามารถลดความซับซ้อนลงเป็นขั้นตอนที่มีโครงสร้างได้หรือไม่ สามารถดึงราคาผ่านอินเทอร์เฟซได้หรือไม่ และสามารถตรวจสอบสินค้าคงคลังแบบเรียลไทม์ได้หรือไม่
คุณจำเป็นต้องเริ่มปรับเปลี่ยนรูปแบบการเรียกภายใต้กรอบงาน LLM ที่แตกต่างกัน - OpenAI และ Claude มีการตั้งค่าที่แตกต่างกันสำหรับการเรียกใช้ฟังก์ชันและการใช้เครื่องมือ Chrome เป็นเทอร์มินัลสู่โลกเก่า ไม่ใช่ทางเข้าสู่โลกใหม่ โปรเจ็กต์ผู้ประกอบการที่มีอนาคตที่แท้จริงไม่ใช่การสร้างเบราว์เซอร์ใหม่ แต่คือการทำให้เบราว์เซอร์ที่มีอยู่ให้บริการเอเจนต์และสร้างสะพานเชื่อมสำหรับ "กระแสคำสั่ง" รุ่นใหม่
สิ่งที่คุณจำเป็นต้องสร้างคือ "รูปแบบอินเทอร์เฟซ" สำหรับให้ตัวแทนเรียกใช้โลกของคุณ
สิ่งที่คุณกำลังมุ่งมั่นคือการกลายเป็นลิงก์ในห่วงโซ่ความไว้วางใจของหน่วยงานอัจฉริยะ
สิ่งที่คุณต้องสร้างคือ "API Castle" ในโหมดการค้นหาถัดไป
หาก Web2 อาศัย UI เพื่อดึงดูดความสนใจของผู้ใช้ ในยุคของ Web3 + AI Agent ก็ต้องอาศัยห่วงโซ่การโทรเพื่อรับรู้เจตนาในการดำเนินการของตัวแทน
ข้อสงวนสิทธิ์:
เนื้อหานี้ไม่ถือเป็นข้อเสนอ การร้องขอ หรือคำแนะนำใดๆ คุณควรขอคำแนะนำจากผู้เชี่ยวชาญอิสระก่อนตัดสินใจลงทุนใดๆ โปรดทราบว่า Gate และ/หรือ Gate Ventures อาจจำกัดหรือห้ามบริการทั้งหมดหรือบางส่วนจากภูมิภาคที่จำกัด โปรดอ่านข้อตกลงผู้ใช้ที่เกี่ยวข้องเพื่อดูข้อมูลเพิ่มเติม
เกี่ยวกับเกต เวนเจอร์
Gate Ventures คือบริษัทร่วมทุนของ Gate ซึ่งมุ่งเน้นการลงทุนในโครงสร้างพื้นฐานแบบกระจายอำนาจ ระบบนิเวศ และแอปพลิเคชันที่จะปรับเปลี่ยนโลกในยุคเว็บ 3.0 Gate Ventures ทำงานร่วมกับผู้นำอุตสาหกรรมระดับโลกเพื่อส่งเสริมให้ทีมงานและบริษัทสตาร์ทอัพมีความคิดสร้างสรรค์และมีศักยภาพในการกำหนดรูปแบบปฏิสัมพันธ์ทางสังคมและการเงินใหม่
เว็บไซต์อย่างเป็นทางการ: https://ventures.gate.io/
ทวิตเตอร์: https://x.com/gate_ventures
สื่อ: https://medium.com/gate_ventures


