
การวิเคราะห์รอยเท้า
การเกิดขึ้นของ GPT ดึงดูดความสนใจจากทั่วโลกไปยังโมเดลภาษาขนาดใหญ่ ทุกสาขาอาชีพพยายามใช้ เทคโนโลยีสีดำ นี้เพื่อปรับปรุงประสิทธิภาพการทำงานและเร่งการพัฒนาอุตสาหกรรม Future 3 Campus ร่วมมือกับ Footprint Analytics เพื่อทำการวิจัยเชิงลึกเกี่ยวกับความเป็นไปได้ที่ไม่มีที่สิ้นสุดของการรวมกันของ AI และ Web3 และร่วมกันเผยแพร่รายงานการวิจัยในหัวข้อ การวิเคราะห์สถานการณ์ปัจจุบัน แนวการแข่งขัน และโอกาสในอนาคตของการบูรณาการของ อุตสาหกรรมข้อมูล AI และ Web3 รายงานการวิจัยแบ่งออกเป็น 2 ส่วน บทความนี้เป็นส่วนแรก เรียบเรียงโดย Lesley และ Shelly นักวิจัยจาก Footprint Analytics บทความถัดไปแก้ไขร่วมกันโดยนักวิจัย Future 3 Campus Sherry และ Humphrey
สรุป:
การพัฒนาเทคโนโลยี LLM ทำให้ผู้คนให้ความสนใจกับการผสมผสานระหว่าง AI และ Web3 มากขึ้น และกระบวนทัศน์แอปพลิเคชันใหม่ก็ค่อยๆ เผยออกมา ในบทความนี้ เราจะเน้นที่วิธีใช้ AI เพื่อปรับปรุงประสบการณ์และประสิทธิภาพของข้อมูล Web3
เนื่องจากอยู่ในช่วงเริ่มต้นของอุตสาหกรรมและลักษณะของเทคโนโลยีบล็อกเชน อุตสาหกรรมข้อมูล Web3 เผชิญกับความท้าทายมากมาย รวมถึงแหล่งข้อมูล ความถี่ในการอัปเดต คุณลักษณะที่ไม่เปิดเผยตัวตน ฯลฯ ทำให้การใช้ AI เพื่อแก้ไขปัญหาเหล่านี้เป็นจุดสนใจใหม่
เมื่อเปรียบเทียบกับปัญญาประดิษฐ์แบบดั้งเดิม ข้อดีของ LLM เช่น ความสามารถในการปรับขนาด ความสามารถในการปรับตัว การปรับปรุงประสิทธิภาพ การแบ่งย่อยงาน การเข้าถึงได้ และความสะดวกในการใช้งาน มอบพื้นที่จินตนาการสำหรับการปรับปรุงประสบการณ์และประสิทธิภาพการผลิตข้อมูลบล็อกเชน
LLM ต้องการข้อมูลคุณภาพสูงจำนวนมากสำหรับการฝึกอบรม และสาขาบล็อกเชนมีความรู้แนวดิ่งและข้อมูลเปิดที่หลากหลาย ซึ่งสามารถจัดหาสื่อการเรียนรู้สำหรับ LLM
LLM ยังช่วยสร้างและเพิ่มมูลค่าของข้อมูลบล็อกเชน เช่น การล้างข้อมูล คำอธิบายประกอบ การสร้างข้อมูลที่มีโครงสร้าง เป็นต้น
LLM ไม่ใช่ยาครอบจักรวาลและจำเป็นต้องนำไปใช้กับความต้องการทางธุรกิจที่เฉพาะเจาะจง จำเป็นต้องใช้ประโยชน์จากประสิทธิภาพสูงของ LLM และในขณะเดียวกันก็ให้ความสนใจกับความถูกต้องของผลลัพธ์ด้วย
1. การพัฒนาและการผสมผสานระหว่าง AI และ Web3
1.1 ประวัติการพัฒนา AI
ประวัติศาสตร์ของปัญญาประดิษฐ์ (AI) มีประวัติย้อนกลับไปในช่วงทศวรรษปี 1950 ตั้งแต่ปี 1956 ผู้คนเริ่มให้ความสนใจกับสาขาปัญญาประดิษฐ์ และค่อยๆ พัฒนาระบบผู้เชี่ยวชาญตั้งแต่เนิ่นๆ เพื่อช่วยแก้ปัญหาในสาขาวิชาชีพ ตั้งแต่นั้นเป็นต้นมา การเรียนรู้ของเครื่องได้ขยายขอบเขตการประยุกต์ใช้ AI ออกไป และ AI ก็เริ่มมีการใช้กันอย่างแพร่หลายมากขึ้นในทุกสาขาอาชีพ จนถึงตอนนี้ การเรียนรู้เชิงลึกและปัญญาประดิษฐ์เชิงสร้างสรรค์ที่แพร่หลายได้นำพาผู้คนไปสู่ความเป็นไปได้อย่างไม่มีที่สิ้นสุด ทุกขั้นตอนเต็มไปด้วยความท้าทายและนวัตกรรมอย่างต่อเนื่องเพื่อแสวงหาระดับสติปัญญาที่สูงขึ้นและขอบเขตการใช้งานที่กว้างขึ้น
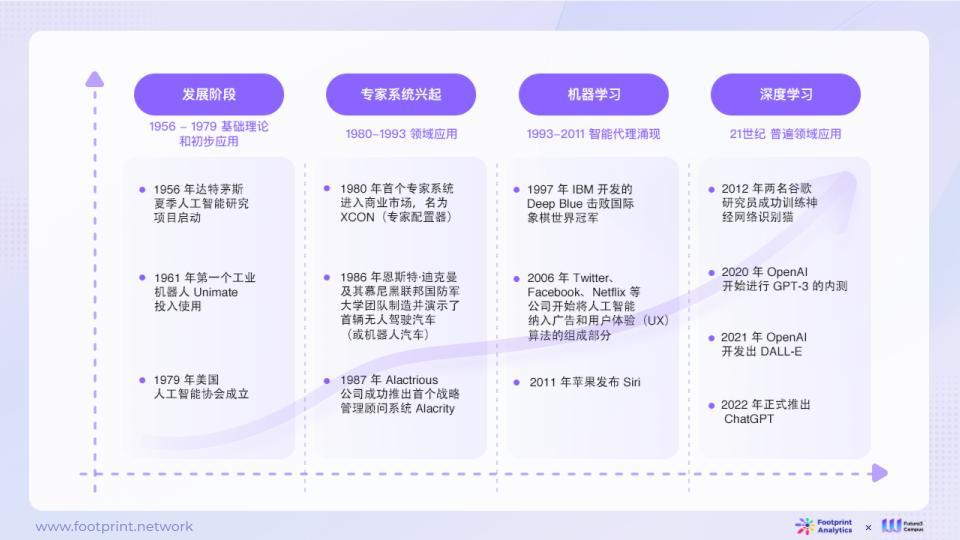
รูปที่ 1: ประวัติการพัฒนา AI
เมื่อวันที่ 30 พฤศจิกายน 2022 ได้มีการเปิดตัว ChatGPT ซึ่งแสดงให้เห็นเป็นครั้งแรกถึงความเป็นไปได้ของการโต้ตอบที่มีเกณฑ์ต่ำและมีประสิทธิภาพสูงระหว่าง AI และมนุษย์ ChatGPT ได้กระตุ้นให้เกิดการอภิปรายอย่างกว้างขวางมากขึ้นเกี่ยวกับปัญญาประดิษฐ์ กำหนดวิธีการโต้ตอบกับ AI ใหม่ ทำให้มีประสิทธิภาพ ใช้งานง่าย และมีมนุษยธรรมมากขึ้น และยังส่งเสริมความสนใจของผู้คนต่อปัญญาประดิษฐ์ที่สร้างสรรค์มากขึ้น Anthropic (Amazon) , DeepMind (Google) Llama และ รุ่นอื่นๆ ก็เข้ามาอยู่ในขอบเขตการมองเห็นของผู้คนในเวลาต่อมา ในเวลาเดียวกัน ผู้ปฏิบัติงานในอุตสาหกรรมต่างๆ ได้เริ่มสำรวจอย่างแข็งขันว่า AI จะส่งเสริมการพัฒนาในสาขาของตนได้อย่างไร หรือแสวงหาความโดดเด่นในอุตสาหกรรมโดยการรวมเข้ากับเทคโนโลยี AI เพื่อเร่งการรุกของ AI ในสาขาต่างๆ ต่อไป
1.2. การบูรณาการ AI และ Web3
วิสัยทัศน์ของ Web3 เริ่มต้นด้วยการปฏิรูประบบการเงิน โดยมีเป้าหมายเพื่อให้บรรลุอำนาจของผู้ใช้มากขึ้น และคาดว่าจะเป็นผู้นำในการเปลี่ยนแปลงเศรษฐกิจและวัฒนธรรมสมัยใหม่ เทคโนโลยีบล็อคเชนมอบรากฐานทางเทคนิคที่แข็งแกร่งเพื่อให้บรรลุเป้าหมายนี้ ไม่เพียงแต่ออกแบบกลไกการส่งผ่านคุณค่าและแรงจูงใจใหม่เท่านั้น แต่ยังให้การสนับสนุนการจัดสรรทรัพยากรและการกระจายอำนาจ
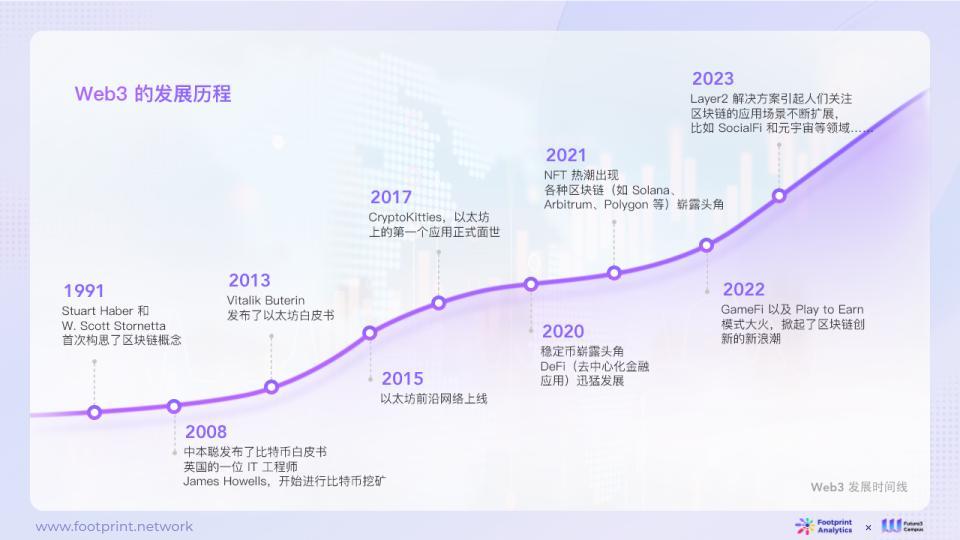
รูปที่ 2: ประวัติการพัฒนา Web3
ในช่วงต้นปี 2020 บริษัทการลงทุนในสาขาบล็อคเชนFourth Revolution Capital(4 RC)มีการชี้ให้เห็นว่าเทคโนโลยีบล็อกเชนจะรวมเข้ากับ AI เพื่อล้มล้างอุตสาหกรรมที่มีอยู่ผ่านการกระจายอำนาจของอุตสาหกรรมระดับโลก เช่น การเงิน การรักษาพยาบาล อีคอมเมิร์ซ และความบันเทิง
ในปัจจุบัน การผสมผสานระหว่าง AI และ Web3 มุ่งเน้นไปที่สองทิศทางหลักเป็นหลัก:
● ใช้ AI เพื่อปรับปรุงประสิทธิภาพการทำงานและประสบการณ์ผู้ใช้
● เมื่อรวมกับคุณสมบัติทางเทคนิคของบล็อกเชนที่โปร่งใส ความปลอดภัย พื้นที่จัดเก็บแบบกระจายอำนาจ การตรวจสอบย้อนกลับ และการตรวจสอบได้ และความสัมพันธ์ในการผลิตแบบกระจายอำนาจของ Web3 จะสามารถแก้ไขจุดปวดที่ไม่สามารถแก้ไขได้ด้วยเทคโนโลยีแบบดั้งเดิม หรือส่งเสริมการมีส่วนร่วมของชุมชนเพื่อปรับปรุงประสิทธิภาพการผลิต
การรวมกันของ AI และ Web3 ในตลาดมีแนวทางการสำรวจดังต่อไปนี้:
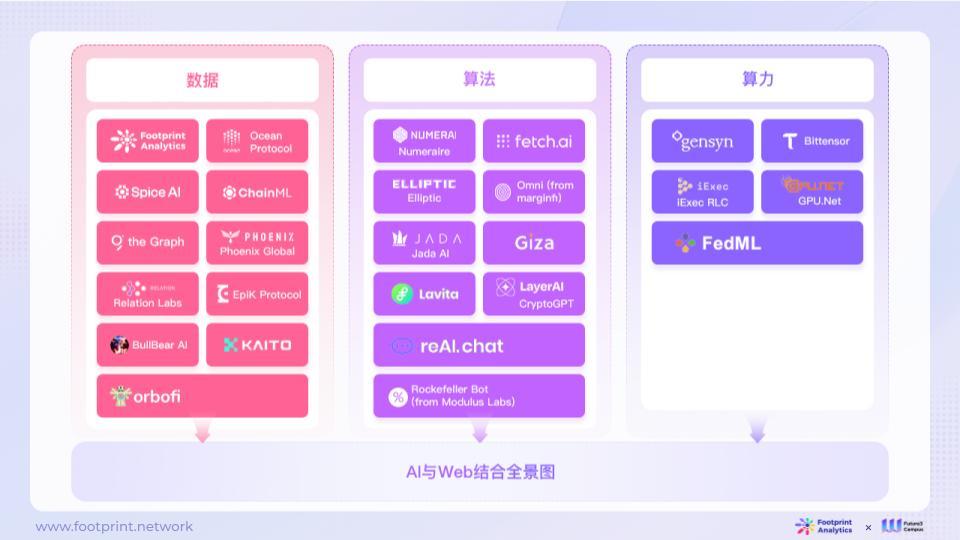
รูปที่ 3: พาโนรามาของการผสมผสานระหว่าง AI และ Web3
● ข้อมูล: เทคโนโลยีบล็อกเชนสามารถนำไปใช้กับการจัดเก็บข้อมูลโมเดล การจัดหาชุดข้อมูลที่เข้ารหัส การปกป้องความเป็นส่วนตัวของข้อมูล บันทึกแหล่งที่มาและการใช้ข้อมูลโมเดล และการตรวจสอบความถูกต้องของข้อมูล ด้วยการเข้าถึงและวิเคราะห์ข้อมูลที่จัดเก็บไว้ในบล็อกเชน AI สามารถดึงข้อมูลอันมีค่าและใช้สำหรับการฝึกโมเดลและการเพิ่มประสิทธิภาพได้ ในขณะเดียวกัน AI ยังสามารถใช้เป็นเครื่องมือในการผลิตข้อมูลเพื่อปรับปรุงประสิทธิภาพการผลิตข้อมูล Web3 ได้อีกด้วย
● อัลกอริธึม: อัลกอริธึมใน Web3 สามารถจัดเตรียมสภาพแวดล้อมการประมวลผลที่ปลอดภัย เชื่อถือได้ และควบคุมโดยอัตโนมัติสำหรับ AI และให้การป้องกันการเข้ารหัสสำหรับระบบ AI รั้วรักษาความปลอดภัยถูกฝังอยู่ในพารามิเตอร์โมเดลเพื่อป้องกันไม่ให้ระบบถูกละเมิดหรือเป็นอันตราย ดำเนินการ AI สามารถโต้ตอบกับอัลกอริธึมใน Web3 เช่น การใช้สัญญาอัจฉริยะเพื่อดำเนินงาน ตรวจสอบข้อมูล และดำเนินการตัดสินใจ ในเวลาเดียวกัน อัลกอริธึม AI ยังสามารถให้การตัดสินใจและบริการที่ชาญฉลาดและมีประสิทธิภาพมากขึ้นสำหรับ Web3
● พลังการประมวลผล: ทรัพยากรการประมวลผลแบบกระจายของ Web3 สามารถมอบความสามารถในการประมวลผลประสิทธิภาพสูงสำหรับ AI AI สามารถใช้ทรัพยากรการประมวลผลแบบกระจายใน Web3 สำหรับการฝึกโมเดล การวิเคราะห์ข้อมูล และการทำนาย ด้วยการกระจายงานการประมวลผลไปยังหลายโหนดบนเครือข่าย AI จึงสามารถเร่งความเร็วในการคำนวณและประมวลผลข้อมูลจำนวนมากขึ้นได้
ในบทความนี้ เราจะเน้นที่การสำรวจวิธีการใช้เทคโนโลยี AI เพื่อปรับปรุงประสิทธิภาพการทำงานและประสบการณ์ผู้ใช้ของข้อมูล Web3
2. สถานะปัจจุบันของข้อมูล Web3
2.1. การเปรียบเทียบอุตสาหกรรมข้อมูล Web2 และ Web3
เนื่องจากเป็นองค์ประกอบหลักของ AI ข้อมูล Web3 จึงแตกต่างจาก Web2 ที่เราคุ้นเคยอย่างมาก ความแตกต่างส่วนใหญ่อยู่ที่สถาปัตยกรรมแอปพลิเคชันของ Web2 และ Web3 ซึ่งส่งผลให้มีลักษณะข้อมูลที่แตกต่างกัน
2.1.1. การเปรียบเทียบสถาปัตยกรรมแอปพลิเคชัน Web2 และ Web3
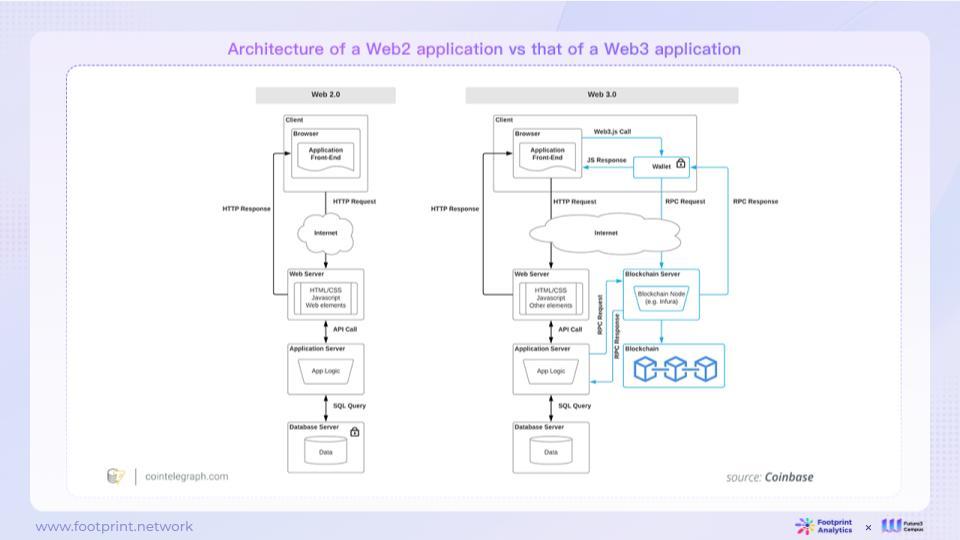
รูปที่ 4: สถาปัตยกรรมแอปพลิเคชัน Web2 และ Web3
ในสถาปัตยกรรม Web2 เอนทิตีเดียว (โดยปกติคือบริษัท) มักจะควบคุมเว็บเพจหรือ APP บริษัทสามารถควบคุมเนื้อหาที่พวกเขาสร้างได้อย่างสมบูรณ์ พวกเขาสามารถตัดสินใจได้ว่าใครสามารถเข้าถึงเนื้อหาและตรรกะบนเซิร์ฟเวอร์ของตนและผู้ใช้ได้ สิทธิ์ที่คุณมีสามารถกำหนดระยะเวลาที่เนื้อหาจะออนไลน์ได้ หลายๆ กรณีได้แสดงให้เห็นว่าบริษัทอินเทอร์เน็ตมีสิทธิ์ที่จะเปลี่ยนแปลงกฎเกณฑ์บนแพลตฟอร์มของตน และแม้กระทั่งระงับการให้บริการแก่ผู้ใช้ โดยที่ผู้ใช้ไม่สามารถรักษามูลค่าที่สร้างขึ้นได้
สถาปัตยกรรม Web3 ขึ้นอยู่กับแนวคิดของ Universal State Layer เพื่อวางเนื้อหาและตรรกะบางส่วนหรือทั้งหมดบนบล็อกเชนสาธารณะ เนื้อหาและตรรกะเหล่านี้ได้รับการบันทึกแบบสาธารณะบน Blockchain และทุกคนสามารถเข้าถึงได้ ผู้ใช้สามารถควบคุมเนื้อหาและตรรกะบนห่วงโซ่ได้โดยตรง ใน Web2 ผู้ใช้ต้องมีบัญชีหรือคีย์ API เพื่อโต้ตอบกับเนื้อหาบนบล็อกเชน ผู้ใช้สามารถควบคุมเนื้อหาและตรรกะออนไลน์ที่เกี่ยวข้องได้โดยตรง ต่างจาก Web2 ผู้ใช้ Web3 ไม่ต้องการบัญชีที่ได้รับอนุญาตหรือคีย์ API เพื่อโต้ตอบกับเนื้อหาบนบล็อกเชน (ยกเว้นการดำเนินการด้านการดูแลระบบบางอย่าง)
2.1.2. การเปรียบเทียบลักษณะข้อมูลระหว่าง Web2 และ Web3
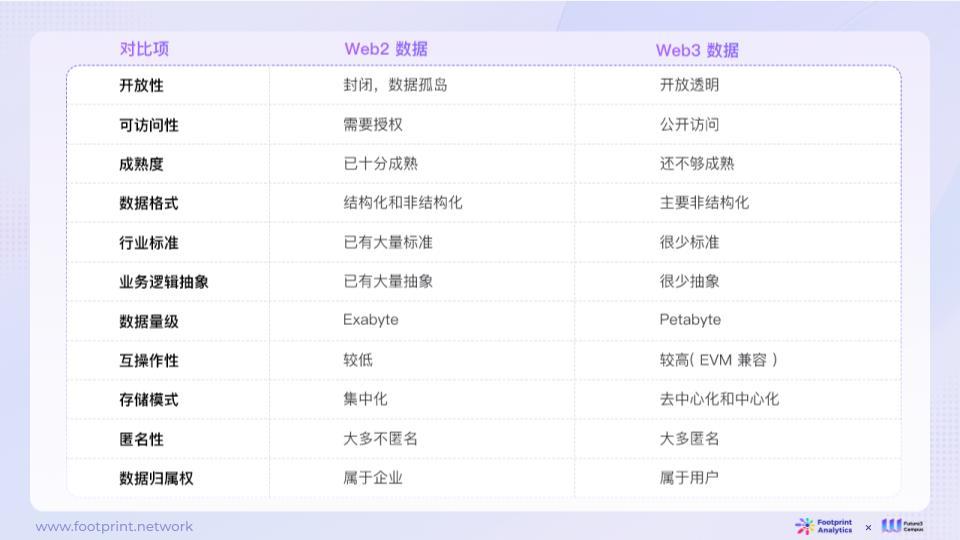
รูปที่ 5: การเปรียบเทียบลักษณะข้อมูลระหว่าง Web2 และ Web3
โดยทั่วไปข้อมูล Web2 จะถูกปิดและถูกจำกัดอย่างมาก โดยมีการควบคุมสิทธิ์ที่ซับซ้อน มีวุฒิภาวะสูง มีรูปแบบข้อมูลที่หลากหลาย ปฏิบัติตามมาตรฐานอุตสาหกรรมอย่างเข้มงวด และนามธรรมทางธุรกิจที่ซับซ้อน ข้อมูลเหล่านี้มีขนาดใหญ่ แต่มีความสามารถในการทำงานร่วมกันค่อนข้างต่ำ โดยปกติจะจัดเก็บไว้ในเซิร์ฟเวอร์กลาง ไม่ใส่ใจกับการปกป้องความเป็นส่วนตัว และส่วนใหญ่จะไม่เปิดเผยตัวตน
ในทางตรงกันข้าม ข้อมูล Web3 นั้นเปิดกว้างกว่าและมีสิทธิ์การเข้าถึงที่กว้างกว่า แม้ว่าจะมีความสมบูรณ์น้อยกว่า แต่ถูกครอบงำโดยข้อมูลที่ไม่มีโครงสร้าง การกำหนดมาตรฐานนั้นหาได้ยาก และการสรุปตรรกะทางธุรกิจนั้นค่อนข้างง่าย ขนาดข้อมูลของ Web3 นั้นเล็กกว่าของ Web2 แต่มีความสามารถในการทำงานร่วมกันสูง (เช่น ความเข้ากันได้ของ EVM) และสามารถจัดเก็บข้อมูลในลักษณะกระจายหรือรวมศูนย์ได้ นอกจากนี้ยังเน้นความเป็นส่วนตัวของผู้ใช้ และผู้ใช้มักจะโต้ตอบบนห่วงโซ่โดยไม่เปิดเผยตัวตน
2.2. สถานะปัจจุบันและโอกาสของอุตสาหกรรมข้อมูล Web3 และความท้าทายที่พบ
ในยุค Web2 ข้อมูลมีค่าพอๆ กับ การสำรอง น้ำมัน และการเข้าถึงและรับข้อมูลขนาดใหญ่ถือเป็นความท้าทายที่ยิ่งใหญ่มาโดยตลอด ใน Web3 การเปิดกว้างและแบ่งปันข้อมูลทำให้ทุกคนรู้สึกว่า น้ำมันมีอยู่ทุกหนทุกแห่ง ทำให้โมเดล AI ได้รับข้อมูลการฝึกอบรมมากขึ้นได้ง่ายขึ้น ซึ่งเป็นสิ่งสำคัญในการปรับปรุงประสิทธิภาพและความชาญฉลาดของโมเดล อย่างไรก็ตาม ยังมีปัญหาอีกมากมายที่ต้องแก้ไขในการประมวลผลข้อมูลของ Web3 หรือ “น้ำมันใหม่” ซึ่งส่วนใหญ่รวมถึงสิ่งต่อไปนี้:
● แหล่งข้อมูล: ข้อมูล มาตรฐาน ในห่วงโซ่มีความซับซ้อนและกระจัดกระจาย และการประมวลผลข้อมูลใช้ต้นทุนแรงงานจำนวนมาก
เมื่อประมวลผลข้อมูลออนไลน์ จะต้องดำเนินการกระบวนการจัดทำดัชนีที่ใช้เวลานานและใช้แรงงานเข้มข้นซ้ำๆ กัน ทำให้นักพัฒนาและนักวิเคราะห์ข้อมูลต้องใช้เวลาและทรัพยากรจำนวนมากในการปรับให้เข้ากับความแตกต่างของข้อมูลระหว่างเครือข่ายต่างๆ และโครงการต่างๆ อุตสาหกรรมข้อมูล on-chain ขาดมาตรฐานการผลิตและการประมวลผลแบบครบวงจร นอกเหนือจากการถูกบันทึกไว้ในบัญชีแยกประเภท blockchain แล้ว เหตุการณ์ บันทึก และการติดตามโดยพื้นฐานแล้วถูกกำหนดและสร้าง (หรือสร้าง) โดยตัวโครงการเอง ซึ่งนำไปสู่ผู้ค้าที่ไม่ใช่มืออาชีพ เป็นการยากที่จะแยกแยะและค้นหาข้อมูลที่แม่นยำและน่าเชื่อถือที่สุด ทำให้เกิดความยากลำบากในการทำธุรกรรมออนไลน์และการตัดสินใจลงทุน ตัวอย่างเช่น การแลกเปลี่ยนแบบกระจายอำนาจ Uniswap และ Pancakeswap อาจมีความแตกต่างในวิธีการประมวลผลข้อมูลและความสามารถด้านข้อมูล และขั้นตอนต่างๆ เช่น การตรวจสอบและการรวมความสามารถในกระบวนการ จะเพิ่มความซับซ้อนของการประมวลผลข้อมูลต่อไป
● การอัปเดตข้อมูล: ข้อมูลในห่วงโซ่มีขนาดใหญ่และอัปเดตบ่อยครั้ง ทำให้ยากต่อการประมวลผลเป็นข้อมูลที่มีโครงสร้างในเวลาที่เหมาะสม
บล็อกเชนเปลี่ยนแปลงตลอดเวลา และการอัปเดตข้อมูลจะวัดเป็นวินาทีหรือมิลลิวินาที การสร้างและอัปเดตข้อมูลบ่อยครั้งทำให้ยากต่อการรักษาการประมวลผลข้อมูลคุณภาพสูงและการอัปเดตตามกำหนดเวลา ดังนั้นกระบวนการประมวลผลอัตโนมัติจึงมีความสำคัญมาก ซึ่งเป็นความท้าทายที่สำคัญต่อต้นทุนและประสิทธิภาพของการประมวลผลข้อมูล อุตสาหกรรมข้อมูล Web3 ยังอยู่ในช่วงเริ่มต้น ด้วยการเกิดขึ้นอย่างต่อเนื่องของสัญญาใหม่และการอัปเดตซ้ำๆ การขาดมาตรฐานและรูปแบบข้อมูลที่หลากหลายทำให้การประมวลผลข้อมูลมีความซับซ้อนมากขึ้น
● การวิเคราะห์ข้อมูล: คุณลักษณะที่ไม่ระบุตัวตนของข้อมูลในห่วงโซ่ทำให้ยากต่อการแยกแยะข้อมูลประจำตัวของข้อมูล
ข้อมูลออนไลน์มักไม่มีข้อมูลเพียงพอที่จะระบุที่อยู่แต่ละแห่งได้อย่างชัดเจน ทำให้ยากต่อการเชื่อมโยงข้อมูลกับการพัฒนาทางเศรษฐกิจ สังคม หรือกฎหมายนอกเครือข่าย อย่างไรก็ตาม แนวโน้มของข้อมูลในห่วงโซ่มีความเกี่ยวข้องอย่างใกล้ชิดกับโลกแห่งความเป็นจริง การทำความเข้าใจความสัมพันธ์ระหว่างกิจกรรมในห่วงโซ่กับบุคคลหรือหน่วยงานเฉพาะในโลกแห่งความเป็นจริงถือเป็นสิ่งสำคัญมากสำหรับสถานการณ์เฉพาะ เช่น การวิเคราะห์ข้อมูล
จากการอภิปรายเกี่ยวกับการเปลี่ยนแปลงด้านประสิทธิภาพการทำงานที่เกิดจากเทคโนโลยีโมเดลภาษาขนาดใหญ่ (LLM) ไม่ว่า AI จะสามารถนำมาใช้แก้ปัญหาความท้าทายเหล่านี้ได้หรือไม่ ก็กลายเป็นประเด็นสำคัญในสาขา Web3 เช่นกัน
3. ปฏิกิริยาเคมีที่เกิดจากการชนกันของข้อมูล AI และ Web3
3.1. การเปรียบเทียบคุณลักษณะระหว่าง AI แบบดั้งเดิมและ LLM
ในแง่ของการฝึกโมเดล โมเดล AI แบบดั้งเดิมมักจะมีขนาดเล็กโดยมีจำนวนพารามิเตอร์ตั้งแต่หลายหมื่นถึงล้าน อย่างไรก็ตาม เพื่อให้มั่นใจในความถูกต้องของผลลัพธ์เอาต์พุตจึงจำเป็นต้องมีข้อมูลที่ติดป้ายกำกับด้วยตนเองจำนวนมาก . เหตุผลส่วนหนึ่งที่ทำให้ LLM มีประสิทธิภาพมากก็คือ ใช้คลังข้อมูลขนาดใหญ่เพื่อให้พอดีกับพารามิเตอร์นับหมื่นล้านและหลายแสนล้าน ซึ่งช่วยเพิ่มความสามารถในการเข้าใจภาษาธรรมชาติได้อย่างมาก แต่ก็หมายความว่าจำเป็นต้องมีข้อมูลมากขึ้นในการฝึกอบรมเป็นอย่างมาก แพง.
ในแง่ของขอบเขตความสามารถและวิธีการดำเนินการ AI แบบดั้งเดิมเหมาะสำหรับงานในสาขาเฉพาะมากกว่า และสามารถให้คำตอบที่ค่อนข้างแม่นยำและเป็นมืออาชีพได้ ในทางตรงกันข้าม LLM เหมาะสำหรับงานทั่วไปมากกว่า แต่มีแนวโน้มที่จะเกิดปัญหาประสาทหลอน ซึ่งหมายความว่าในบางกรณีคำตอบอาจไม่แม่นยำหรือเป็นมืออาชีพเพียงพอ หรือแม้แต่ผิดทั้งหมด ดังนั้น หากต้องการผลลัพธ์ที่เป็นรูปธรรม เชื่อถือได้ และตรวจสอบย้อนกลับได้ อาจจำเป็นต้องมีการตรวจสอบหลายครั้ง การฝึกอบรมหลายครั้ง หรือการแนะนำกลไกและกรอบงานการแก้ไขข้อผิดพลาดเพิ่มเติม

รูปที่ 6: การเปรียบเทียบคุณสมบัติระหว่าง AI แบบดั้งเดิมและโมเดลภาษาโมเดลขนาดใหญ่ (LLM)
3.1.1. การปฏิบัติงานของ AI แบบดั้งเดิมในด้านข้อมูล Web3
AI แบบดั้งเดิมได้แสดงให้เห็นถึงความสำคัญในอุตสาหกรรมข้อมูลบล็อกเชน โดยนำนวัตกรรมและประสิทธิภาพมาสู่สาขานี้มากขึ้น ตัวอย่างเช่น ทีมงาน 0x Scope ใช้เทคโนโลยี AI เพื่อสร้างอัลกอริธึมการวิเคราะห์คลัสเตอร์โดยใช้การประมวลผลกราฟ ซึ่งช่วยระบุที่อยู่ที่เกี่ยวข้องระหว่างผู้ใช้ได้อย่างแม่นยำ ผ่านการกระจายน้ำหนักของกฎต่างๆ การใช้อัลกอริธึมการเรียนรู้เชิงลึกนี้ช่วยเพิ่มความแม่นยำของการจัดกลุ่มที่อยู่ ทำให้เป็นเครื่องมือในการวิเคราะห์ข้อมูลที่แม่นยำยิ่งขึ้น Nansen ใช้ AI สำหรับการคาดการณ์ราคา NFT โดยให้ข้อมูลเชิงลึกเกี่ยวกับแนวโน้มของตลาด NFT ผ่านการวิเคราะห์ข้อมูลและเทคโนโลยีการประมวลผลภาษาธรรมชาติ ในทางกลับกัน Trusta Labs ใช้วิธีการเรียนรู้ของเครื่องตามการขุดกราฟสินทรัพย์และการวิเคราะห์ลำดับพฤติกรรมผู้ใช้ เพื่อเพิ่มความน่าเชื่อถือและเสถียรภาพของโซลูชันการตรวจจับ Sybil และช่วยรักษาความปลอดภัยของระบบนิเวศเครือข่ายบล็อกเชน ในทางกลับกัน Trusta Labs ใช้วิธีการขุดกราฟและการวิเคราะห์พฤติกรรมผู้ใช้เพื่อเพิ่มความน่าเชื่อถือและความเสถียรของโซลูชันการตรวจจับ Sybil และช่วยรักษาความปลอดภัยของเครือข่ายบล็อกเชน Goplus ใช้ประโยชน์จากปัญญาประดิษฐ์แบบดั้งเดิมในการดำเนินงานเพื่อปรับปรุงความปลอดภัยและประสิทธิภาพของแอปพลิเคชันแบบกระจายอำนาจ (dApps) พวกเขารวบรวมและวิเคราะห์ข้อมูลความปลอดภัยจาก dApps และแจ้งเตือนความเสี่ยงอย่างรวดเร็วเพื่อช่วยลดความเสี่ยงบนแพลตฟอร์มเหล่านี้ ซึ่งรวมถึงการตรวจจับความเสี่ยงในสัญญาหลักของ dApp โดยการประเมินปัจจัยต่างๆ เช่น สถานะโอเพ่นซอร์สและพฤติกรรมที่เป็นอันตรายที่อาจเกิดขึ้น รวมถึงการรวบรวมข้อมูลการตรวจสอบโดยละเอียด รวมถึงข้อมูลประจำตัวของบริษัทตรวจสอบ เวลาตรวจสอบ และลิงก์รายงานการตรวจสอบ Footprint Analytics ใช้ AI เพื่อสร้างโค้ดที่สร้างข้อมูลที่มีโครงสร้าง วิเคราะห์ธุรกรรม NFT ล้างธุรกรรมการซื้อขาย และการคัดกรองบัญชีโรบ็อตและการแก้ไขปัญหา
อย่างไรก็ตาม AI แบบดั้งเดิมมีข้อมูลที่จำกัดและมุ่งเน้นไปที่การใช้อัลกอริธึมและกฎที่กำหนดไว้ล่วงหน้าเพื่อดำเนินงานที่กำหนดไว้ล่วงหน้า ในขณะที่ LLM เรียนรู้จากข้อมูลภาษาธรรมชาติขนาดใหญ่ และสามารถเข้าใจและสร้างภาษาธรรมชาติได้ ซึ่งทำให้เหมาะสำหรับการประมวลผลงานที่ซับซ้อนและใหญ่มากขึ้น จำนวนข้อมูลข้อความ
เมื่อเร็วๆ นี้ เนื่องจาก LLM มีความก้าวหน้าอย่างมาก ผู้คนยังได้ดำเนินการคิดและสำรวจใหม่ๆ เกี่ยวกับการผสมผสานระหว่างข้อมูล AI และ Web3
3.1.2. ข้อดีของ LLM
LLM มีข้อได้เปรียบเหนือปัญญาประดิษฐ์แบบดั้งเดิมดังต่อไปนี้:
● ความสามารถในการปรับขนาด: LLM รองรับการประมวลผลข้อมูลขนาดใหญ่
LLM เป็นเลิศในด้านความสามารถในการปรับขนาดและสามารถรองรับข้อมูลจำนวนมากและการโต้ตอบกับผู้ใช้ได้อย่างมีประสิทธิภาพ ทำให้เหมาะสำหรับงานที่ต้องใช้การประมวลผลข้อมูลขนาดใหญ่ เช่น การวิเคราะห์ข้อความหรือการทำความสะอาดข้อมูลขนาดใหญ่ ความสามารถในการประมวลผลข้อมูลระดับสูงทำให้มีการวิเคราะห์ที่ทรงพลังและศักยภาพการใช้งานสำหรับอุตสาหกรรมข้อมูลบล็อกเชน
● ความสามารถในการปรับตัว: LLM สามารถเรียนรู้ที่จะปรับตัวให้เข้ากับความต้องการของหลายสาขาได้
LLM สามารถปรับเปลี่ยนได้สูงและสามารถปรับอย่างละเอียดสำหรับงานเฉพาะหรือฝังอยู่ในฐานข้อมูลอุตสาหกรรมหรือส่วนตัว ทำให้สามารถเรียนรู้และปรับให้เข้ากับความแตกต่างของโดเมนต่างๆ ได้อย่างรวดเร็ว คุณลักษณะนี้ทำให้ LLM เป็นตัวเลือกที่เหมาะสำหรับการแก้ปัญหาหลายโดเมนและหลายวัตถุประสงค์ โดยให้การสนับสนุนที่กว้างขึ้นสำหรับแอปพลิเคชันบล็อกเชนที่หลากหลาย
● ปรับปรุงประสิทธิภาพ: LLM ทำงานอัตโนมัติเพื่อปรับปรุงประสิทธิภาพ
ประสิทธิภาพสูงของ LLM นำความสะดวกสบายอย่างมากมาสู่อุตสาหกรรมข้อมูลบล็อกเชน โดยทำให้งานต่างๆ ต้องใช้เวลาและทรัพยากรจำนวนมากโดยอัตโนมัติ ซึ่งจะช่วยเพิ่มประสิทธิภาพการผลิตและลดต้นทุน LLM สามารถสร้างข้อความจำนวนมาก วิเคราะห์ชุดข้อมูลขนาดใหญ่ หรือทำงานซ้ำๆ มากมายได้ภายในไม่กี่วินาที ลดเวลาในการรอและประมวลผล และทำให้การประมวลผลข้อมูลบล็อกเชนมีประสิทธิภาพมากขึ้น
● การแบ่งย่อยงาน: คุณสามารถสร้างแผนเฉพาะสำหรับงานบางอย่างและแบ่งงานใหญ่ออกเป็นขั้นตอนเล็กๆ ได้
ตัวแทน LLM มีความสามารถเฉพาะตัวในการสร้างแผนเฉพาะสำหรับงานบางงาน โดยแบ่งงานที่ซับซ้อนออกเป็นขั้นตอนเล็กๆ ที่สามารถจัดการได้ คุณสมบัตินี้มีประโยชน์อย่างมากสำหรับการประมวลผลข้อมูลบล็อกเชนขนาดใหญ่และดำเนินการวิเคราะห์ข้อมูลที่ซับซ้อน ด้วยการแบ่งงานใหญ่ออกเป็นงานเล็กๆ LLM จึงสามารถจัดการกระบวนการประมวลผลข้อมูลและวิเคราะห์ผลลัพธ์คุณภาพสูงได้ดีขึ้น
ความสามารถนี้มีความสำคัญอย่างยิ่งสำหรับระบบ AI ที่ดำเนินงานที่ซับซ้อน เช่น ระบบอัตโนมัติของหุ่นยนต์ การจัดการโครงการ และการทำความเข้าใจและการสร้างภาษาธรรมชาติ ช่วยให้ระบบสามารถแปลงเป้าหมายภารกิจระดับสูงให้เป็นเส้นทางการดำเนินการโดยละเอียด และปรับปรุงประสิทธิภาพและความแม่นยำในการดำเนินภารกิจ
● การเข้าถึงและความสะดวกในการใช้งาน: LLM ให้การโต้ตอบที่เป็นมิตรกับผู้ใช้ในภาษาธรรมชาติ
ความสามารถในการเข้าถึงของ LLM ช่วยให้ผู้ใช้โต้ตอบกับข้อมูลและระบบได้ง่ายขึ้น ทำให้การโต้ตอบเหล่านี้เป็นมิตรต่อผู้ใช้มากขึ้น ด้วยภาษาที่เป็นธรรมชาติ LLM ทำให้ข้อมูลและระบบเข้าถึงและโต้ตอบได้ง่ายขึ้น โดยไม่ต้องให้ผู้ใช้เรียนรู้คำศัพท์ทางเทคนิคที่ซับซ้อนหรือคำสั่งเฉพาะ เช่น SQL, R, Python ฯลฯ สำหรับการได้มาและการวิเคราะห์ข้อมูล คุณลักษณะนี้ขยายขอบเขตผู้ชมของแอปพลิเคชันบล็อกเชน และช่วยให้ผู้คนเข้าถึงและใช้แอปพลิเคชันและบริการ Web3 ได้มากขึ้น ไม่ว่าพวกเขาจะเชี่ยวชาญด้านเทคโนโลยีหรือไม่ก็ตาม ดังนั้นจึงส่งเสริมการพัฒนาและการแพร่หลายของอุตสาหกรรมข้อมูลบล็อกเชน
3.2. การรวมข้อมูล LLM และ Web3
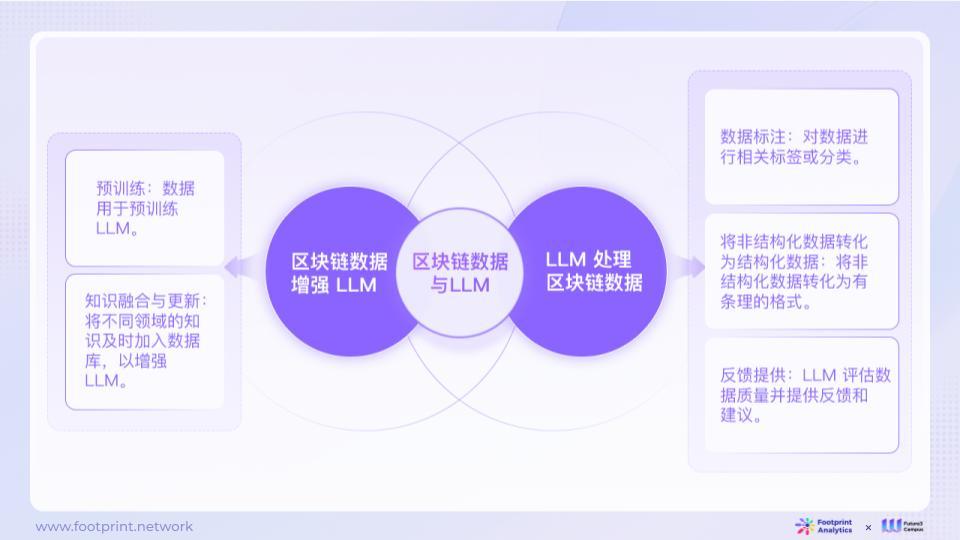
รูปที่ 7: การบูรณาการข้อมูลบล็อกเชนและ LLM
การฝึกอบรมโมเดลภาษาขนาดใหญ่ต้องอาศัยข้อมูลขนาดใหญ่เพื่อสร้างโมเดลโดยการเรียนรู้รูปแบบในข้อมูล รูปแบบการโต้ตอบและพฤติกรรมที่มีอยู่ในข้อมูลบล็อกเชนเป็นเชื้อเพลิงสำหรับการเรียนรู้ LLM ปริมาณและคุณภาพของข้อมูลส่งผลโดยตรงต่อผลการเรียนรู้ของแบบจำลอง LLM
ข้อมูลไม่ได้เป็นเพียงการบริโภคสำหรับ LLM เท่านั้น LLM ยังช่วยสร้างข้อมูลและยังสามารถให้ข้อเสนอแนะได้อีกด้วย ตัวอย่างเช่น LLM สามารถช่วยเหลือนักวิเคราะห์ข้อมูลในการประมวลผลข้อมูลล่วงหน้า เช่น การล้างข้อมูลและคำอธิบายประกอบ หรือการสร้างข้อมูลที่มีโครงสร้างเพื่อขจัดสิ่งรบกวนออกจากข้อมูลและเน้นข้อมูลที่มีประสิทธิภาพ
3.3. โซลูชันทางเทคนิคทั่วไปเพื่อปรับปรุง LLM
การเกิดขึ้นของ ChatGPT ไม่เพียงแต่แสดงให้เราเห็นถึงความสามารถทั่วไปของ LLM ในการแก้ปัญหาที่ซับซ้อนเท่านั้น แต่ยังกระตุ้นให้เกิดการสำรวจทั่วโลกเกี่ยวกับการซ้อนทับความสามารถภายนอกบนความสามารถทั่วไป ซึ่งรวมถึงการปรับปรุงความสามารถทั่วไป (รวมถึงความยาวของบริบท การใช้เหตุผลที่ซับซ้อน คณิตศาสตร์ รหัส ความหลากหลาย ฯลฯ) เช่นเดียวกับการขยายความสามารถภายนอก (การประมวลผลข้อมูลที่ไม่มีโครงสร้าง การใช้เครื่องมือที่ซับซ้อนมากขึ้น การโต้ตอบกับโลกทางกายภาพ ฯลฯ ). วิธีการต่อยอดความรู้ที่เป็นกรรมสิทธิ์ในสาขา crypto และข้อมูลส่วนตัวส่วนบุคคลไปยังความสามารถทั่วไปของโมเดลขนาดใหญ่คือปัญหาทางเทคนิคหลักสำหรับการนำโมเดลขนาดใหญ่ในฟิลด์แนวดิ่งของ crypto เชิงพาณิชย์
ในปัจจุบัน แอปพลิเคชันส่วนใหญ่มุ่งเน้นไปที่การสร้างการดึงข้อมูล (RAG) เช่น วิศวกรรมคำแนะนำและเทคโนโลยีการฝัง และเครื่องมือตัวแทนที่มีอยู่ส่วนใหญ่มุ่งเน้นไปที่การปรับปรุงประสิทธิภาพและความแม่นยำของงาน RAG สถาปัตยกรรมอ้างอิงหลักของสแต็กแอปพลิเคชันที่ใช้เทคโนโลยี LLM ในตลาดมีดังนี้:
● Prompt Engineering
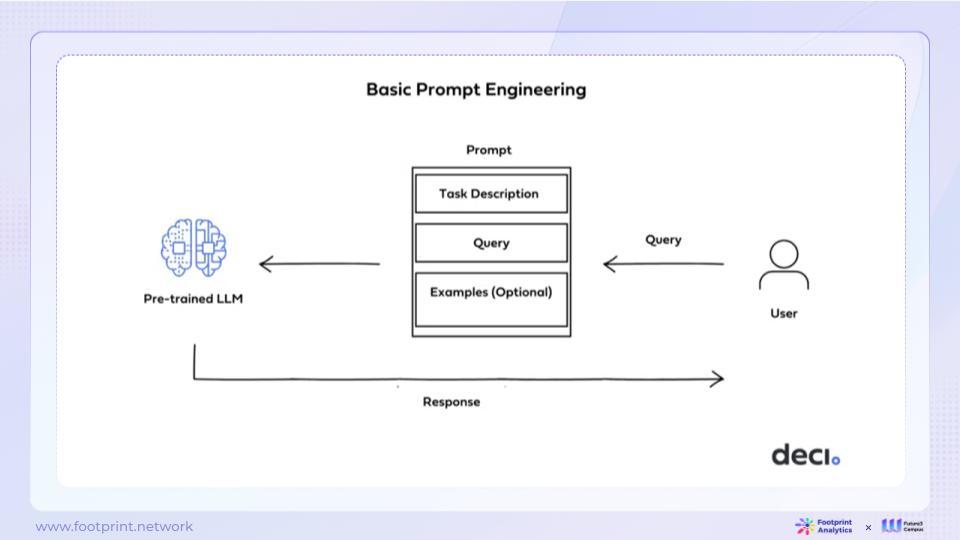
รูปที่ 8: วิศวกรรมพร้อมท์
ปัจจุบันผู้ปฏิบัติงานส่วนใหญ่ใช้โซลูชันพื้นฐาน เช่น Prompt Engineering ในการสร้างแอปพลิเคชัน วิธีนี้เป็นวิธีที่สะดวกและรวดเร็วที่สุดในการเปลี่ยนอินพุตของโมเดลโดยการออกแบบ Prompts เฉพาะเพื่อตอบสนองความต้องการของแอปพลิเคชันเฉพาะ อย่างไรก็ตาม พื้นฐาน Prompt Engineering มีข้อจำกัดบางประการ เช่น การอัพเดตฐานข้อมูลไม่ทันเวลา เนื้อหาที่ยุ่งยาก การรองรับความยาวบริบทอินพุต (In-Context length) และข้อจำกัดของคำถามและคำตอบหลายรอบ
ดังนั้น อุตสาหกรรมยังกำลังศึกษาโซลูชันการปรับปรุงขั้นสูงเพิ่มเติม รวมถึงการฝังและการปรับแต่งอย่างละเอียด
● การฝัง
การฝังเป็นวิธีการแสดงข้อมูลที่ใช้กันอย่างแพร่หลายในด้านปัญญาประดิษฐ์ ซึ่งสามารถเก็บข้อมูลความหมายของวัตถุได้อย่างมีประสิทธิภาพ ด้วยการแมปคุณลักษณะของวัตถุในรูปแบบเวกเตอร์ เทคโนโลยีการฝังสามารถค้นหาคำตอบที่ถูกต้องที่สุดได้อย่างรวดเร็วโดยการวิเคราะห์ความสัมพันธ์ระหว่างเวกเตอร์ การฝังสามารถสร้างขึ้นบน LLM เพื่อใช้ประโยชน์จากความรู้ทางภาษาที่หลากหลายที่เรียนรู้โดยแบบจำลองในองค์กรที่หลากหลาย ข้อมูลเกี่ยวกับงานหรือสาขาเฉพาะเจาะจงจะถูกนำเสนอในโมเดลขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าผ่านเทคโนโลยีแบบฝัง ทำให้โมเดลมีความเชี่ยวชาญมากขึ้นและสามารถปรับให้เข้ากับงานเฉพาะได้มากขึ้น ในขณะที่ยังคงรักษาความอเนกประสงค์ของโมเดลพื้นฐานไว้
ในแง่ของคนธรรมดา การฝังจะคล้ายกับการให้หนังสืออ้างอิงแก่นักศึกษาที่ได้รับการฝึกอบรมอย่างครอบคลุมและขอให้เขาทำงานให้สำเร็จด้วยหนังสืออ้างอิงที่มีความรู้ที่เกี่ยวข้องกับงานเฉพาะ เขาสามารถปรึกษาหนังสืออ้างอิงได้ตลอดเวลาแล้วจึงแก้ไข ปัญหาเฉพาะ ปัญหา
● การปรับแต่งแบบละเอียด
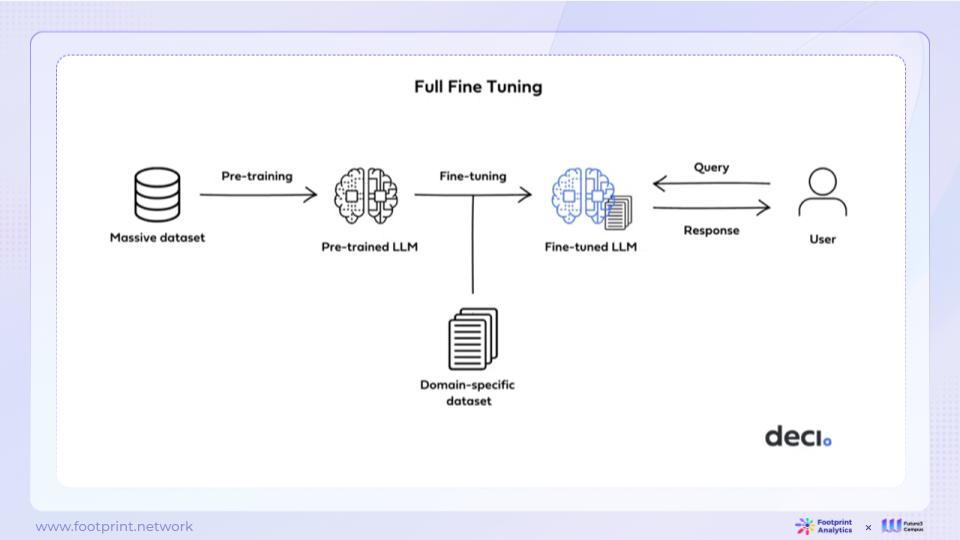
รูปที่ 9: การปรับแต่งแบบละเอียด
การปรับแต่งอย่างละเอียดแตกต่างจากการฝังโดยการอัปเดตพารามิเตอร์ของโมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้าเพื่อปรับให้เข้ากับงานเฉพาะ แนวทางนี้ช่วยให้แบบจำลองสามารถแสดงประสิทธิภาพที่ดีขึ้นในงานเฉพาะเจาะจงในขณะที่ยังคงความทั่วไปอยู่ แนวคิดหลักของการปรับแต่งอย่างละเอียดคือการปรับพารามิเตอร์โมเดลเพื่อจับรูปแบบและความสัมพันธ์เฉพาะที่เกี่ยวข้องกับงานเป้าหมาย อย่างไรก็ตาม ขีดจำกัดบนของความสามารถทั่วไปของรุ่นในการปรับแต่งแบบละเอียดยังคงถูกจำกัดโดยตัวรุ่นพื้นฐานเอง
ในแง่ของคนธรรมดา การปรับอย่างละเอียดนั้นคล้ายคลึงกับการให้หลักสูตรความรู้ทางวิชาชีพแก่นักศึกษาที่ได้รับการฝึกอบรมอย่างครอบคลุม ช่วยให้พวกเขาเชี่ยวชาญความรู้ในหลักสูตรวิชาชีพ นอกเหนือจากความสามารถที่ครอบคลุม และสามารถแก้ไขปัญหาในภาควิชาชีพได้ด้วยตนเอง
● ฝึกอบรม LLM อีกครั้ง
แม้ว่า LLM ในปัจจุบันจะมีประสิทธิภาพ แต่ก็อาจไม่สามารถตอบสนองทุกความต้องการได้ การฝึกอบรม LLM ใหม่เป็นโซลูชันที่ปรับแต่งได้สูงโดยการแนะนำชุดข้อมูลใหม่และการปรับน้ำหนักแบบจำลองเพื่อให้เหมาะสมกับงาน ความต้องการ หรือโดเมนเฉพาะมากขึ้น อย่างไรก็ตาม วิธีการนี้ต้องใช้ทรัพยากรการประมวลผลและข้อมูลจำนวนมาก และการจัดการและการบำรุงรักษาโมเดลที่ได้รับการฝึกอบรมใหม่ก็เป็นหนึ่งในความท้าทายเช่นกัน
● โมเดลตัวแทน
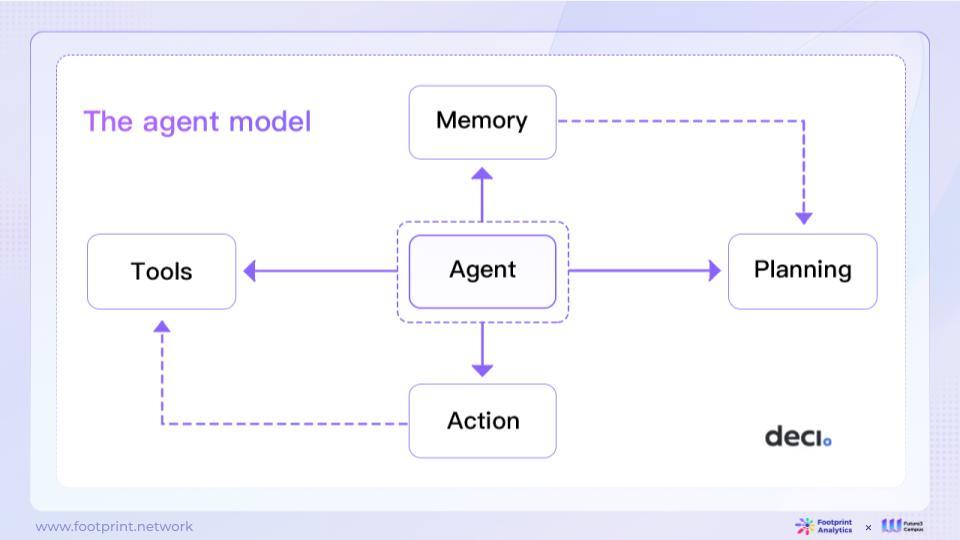
รูปที่ 10: โมเดลตัวแทน
โมเดลตัวแทนเป็นวิธีการสร้างตัวแทนอัจฉริยะ ซึ่งใช้ LLM เป็นตัวควบคุมหลัก ระบบยังมีองค์ประกอบสำคัญหลายประการเพื่อให้ข้อมูลข่าวกรองที่ครอบคลุมมากขึ้น
● การวางแผน: แบ่งงานใหญ่ออกเป็นงานย่อยเพื่อให้เสร็จได้ง่ายขึ้น
● ความทรงจำ การไตร่ตรอง: ปรับปรุงแผนการในอนาคตโดยไตร่ตรองถึงการกระทำในอดีต
● เครื่องมือ การใช้เครื่องมือ: ตัวแทนสามารถเรียกเครื่องมือภายนอกเพื่อรับข้อมูลเพิ่มเติม เช่น การเรียกเครื่องมือค้นหา เครื่องคิดเลข ฯลฯ
โมเดลตัวแทนปัญญาประดิษฐ์มีความเข้าใจภาษาและความสามารถในการสร้างที่แข็งแกร่ง และสามารถแก้ปัญหาทั่วไป แยกแยะงาน และการสะท้อนกลับตนเองได้ ทำให้มีศักยภาพในการใช้งานที่หลากหลาย อย่างไรก็ตาม โมเดลเอเจนต์ยังมีข้อจำกัดบางประการ เช่น การถูกจำกัดด้วยความยาวของบริบท มีแนวโน้มที่จะเกิดข้อผิดพลาดในการวางแผนระยะยาวและการแยกงาน และความน่าเชื่อถือที่ไม่เสถียรของเนื้อหาเอาต์พุต ข้อจำกัดเหล่านี้จำเป็นต้องมีการวิจัยและนวัตกรรมอย่างต่อเนื่องในระยะยาวเพื่อขยายการประยุกต์ใช้โมเดลตัวแทนในสาขาต่างๆ
เทคนิคต่างๆ ข้างต้นไม่แยกจากกันและสามารถนำไปใช้ร่วมกันในกระบวนการฝึกฝนและยกระดับโมเดลเดียวกันได้ นักพัฒนาสามารถใช้ประโยชน์จากศักยภาพของโมเดลภาษาขนาดใหญ่ที่มีอยู่ได้อย่างเต็มที่ และลองใช้วิธีการต่างๆ เพื่อตอบสนองความต้องการของแอปพลิเคชันที่ซับซ้อนมากขึ้น การใช้งานที่ครอบคลุมนี้ไม่เพียงแต่ช่วยปรับปรุงประสิทธิภาพของโมเดลเท่านั้น แต่ยังช่วยส่งเสริมนวัตกรรมที่รวดเร็วและความก้าวหน้าของเทคโนโลยี Web3
อย่างไรก็ตาม เราเชื่อว่าแม้ว่า LLM ที่มีอยู่จะมีบทบาทสำคัญในการพัฒนาอย่างรวดเร็วของ Web3 ก่อนที่จะลองใช้โมเดลที่มีอยู่เหล่านี้อย่างเต็มที่ (เช่น OpenAI, Llama 2 และ LLM โอเพ่นซอร์สอื่นๆ) เราก็สามารถเริ่มต้นจากระดับตื้นไปจนถึงลึกยิ่งขึ้น เริ่มต้นด้วยกลยุทธ์ RAG เช่น วิศวกรรมและการฝังที่รวดเร็ว และพิจารณาการปรับแต่งและฝึกอบรมโมเดลพื้นฐานอย่างละเอียดอย่างรอบคอบ
3.4. LLM เร่งกระบวนการต่างๆ ของการผลิตข้อมูลบล็อกเชนอย่างไร
3.4.1. ขั้นตอนการประมวลผลทั่วไปของข้อมูลบล็อคเชน
ปัจจุบันนี้ ผู้สร้างในด้านบล็อกเชนกำลังค่อยๆ ตระหนักถึงคุณค่าของผลิตภัณฑ์ข้อมูล ค่านี้ครอบคลุมหลายด้าน เช่น การตรวจสอบการทำงานของผลิตภัณฑ์ แบบจำลองการคาดการณ์ ระบบการแนะนำ และแอปพลิเคชันที่ขับเคลื่อนด้วยข้อมูล แม้ว่าการรับรู้นี้จะค่อยๆ เพิ่มขึ้น แต่การประมวลผลข้อมูลมักถูกมองข้ามว่าเป็นขั้นตอนสำคัญที่ขาดไม่ได้ตั้งแต่การรับข้อมูลไปจนถึงการประยุกต์ใช้ข้อมูล
รูปที่ 11: กระบวนการประมวลผลข้อมูล Blockchain
● แปลงข้อมูลที่ไม่มีโครงสร้างดั้งเดิมของบล็อกเชน เช่น เหตุการณ์หรือบันทึก ฯลฯ ให้เป็นข้อมูลที่มีโครงสร้าง
ทุกธุรกรรมหรือเหตุการณ์บนบล็อกเชนจะสร้างเหตุการณ์หรือบันทึก และข้อมูลเหล่านี้มักจะไม่มีโครงสร้าง ขั้นตอนนี้เป็นจุดเริ่มต้นแรกในการรับข้อมูล แต่ข้อมูลยังคงต้องมีการประมวลผลเพิ่มเติมเพื่อแยกข้อมูลที่เป็นประโยชน์และรับข้อมูลดิบที่มีโครงสร้าง ซึ่งรวมถึงการจัดระเบียบข้อมูล การจัดการข้อยกเว้น และการแปลงเป็นรูปแบบทั่วไป
● แปลงข้อมูลดิบที่มีโครงสร้างเป็นตารางนามธรรมที่มีความหมายทางธุรกิจ
หลังจากได้รับข้อมูลดิบที่มีโครงสร้างแล้ว คุณจะต้องสรุปธุรกิจเพิ่มเติมและแมปข้อมูลกับเอนทิตีและตัวบ่งชี้ทางธุรกิจ เช่น ปริมาณธุรกรรม ปริมาณผู้ใช้ และตัวบ่งชี้ทางธุรกิจอื่นๆ เพื่อแปลงข้อมูลดิบให้เป็นข้อมูลที่มีความหมายสำหรับธุรกิจและการตัดสินใจ .
● คำนวณและแยกตัวชี้วัดทางธุรกิจออกจากตารางนามธรรม
หลังจากมีข้อมูลธุรกิจเชิงนามธรรมแล้ว ก็สามารถคำนวณเพิ่มเติมกับข้อมูลธุรกิจเชิงนามธรรมเพื่อรับตัวบ่งชี้ที่ได้รับที่สำคัญต่างๆ ตัวอย่างเช่น ตัวบ่งชี้หลัก เช่น อัตราการเติบโตรายเดือนของปริมาณธุรกรรมทั้งหมดและอัตราการรักษาผู้ใช้ ตัวบ่งชี้เหล่านี้สามารถนำไปใช้ได้ด้วยความช่วยเหลือของเครื่องมือเช่น SQL และ Python และมีแนวโน้มที่จะช่วยตรวจสอบสถานะทางธุรกิจและเข้าใจพฤติกรรมและแนวโน้มของผู้ใช้เพื่อสนับสนุนการตัดสินใจและการวางแผนเชิงกลยุทธ์
3.4.2. การเพิ่มประสิทธิภาพหลังจากเพิ่ม LLM ในกระบวนการสร้างข้อมูลบล็อคเชน
LLM สามารถแก้ปัญหาหลายประการในการประมวลผลข้อมูลบล็อคเชน รวมถึงแต่ไม่จำกัดเพียงปัญหาต่อไปนี้:
ประมวลผลข้อมูลที่ไม่มีโครงสร้าง:
● แยกข้อมูลที่มีโครงสร้างออกจากบันทึกธุรกรรมและเหตุการณ์: LLM สามารถวิเคราะห์บันทึกธุรกรรมและเหตุการณ์ของบล็อกเชน แยกข้อมูลสำคัญ เช่น จำนวนธุรกรรม ที่อยู่ฝ่ายธุรกรรม การประทับเวลา ฯลฯ และแปลงข้อมูลที่ไม่มีโครงสร้างเป็นข้อมูลที่มีความหมายทางธุรกิจ ทำให้ง่ายต่อการวิเคราะห์และทำความเข้าใจ
● ล้างข้อมูลและระบุข้อมูลที่ผิดปกติ: LLM สามารถระบุและล้างข้อมูลที่ไม่สอดคล้องกันหรือผิดปกติได้โดยอัตโนมัติ เพื่อช่วยให้มั่นใจในความถูกต้องและความสม่ำเสมอของข้อมูล ซึ่งจะช่วยปรับปรุงคุณภาพของข้อมูล
ดำเนินการนามธรรมทางธุรกิจ:
● การแมปข้อมูลออนไลน์เชนดั้งเดิมกับเอนทิตีธุรกิจ: LLM สามารถแมปข้อมูลบล็อกเชนดั้งเดิมกับเอนทิตีธุรกิจ เช่น การแมปที่อยู่บล็อกเชนกับผู้ใช้หรือสินทรัพย์จริง ทำให้การประมวลผลทางธุรกิจใช้งานง่ายและมีประสิทธิภาพมากขึ้น
● ประมวลผลเนื้อหาออนไลน์ที่ไม่มีโครงสร้างและติดป้ายกำกับ: LLM สามารถวิเคราะห์ข้อมูลที่ไม่มีโครงสร้าง เช่น ผลการวิเคราะห์ความรู้สึกของ Twitter และทำเครื่องหมายว่าเป็นความรู้สึกเชิงบวก ลบ หรือเป็นกลาง ดังนั้นจึงช่วยให้ผู้ใช้เข้าใจความรู้สึกเกี่ยวกับแนวโน้มของโซเชียลมีเดียได้ดีขึ้น
การตีความข้อมูลด้วยภาษาธรรมชาติ:
● คำนวณตัวบ่งชี้หลัก: ตามนามธรรมทางธุรกิจ LLM สามารถคำนวณตัวบ่งชี้ธุรกิจหลัก เช่น ปริมาณการทำธุรกรรมของผู้ใช้ มูลค่าสินทรัพย์ ส่วนแบ่งการตลาด ฯลฯ เพื่อช่วยให้ผู้ใช้เข้าใจประสิทธิภาพหลักของธุรกิจของตนได้ดียิ่งขึ้น
● ข้อมูลการสืบค้น: LLM สามารถเข้าใจความตั้งใจของผู้ใช้และสร้างการสืบค้น SQL ผ่าน AIGC ทำให้ผู้ใช้สามารถส่งคำขอการสืบค้นในภาษาธรรมชาติโดยไม่ต้องเขียนคำสั่งการสืบค้น SQL ที่ซับซ้อน สิ่งนี้จะเพิ่มการเข้าถึงแบบสอบถามฐานข้อมูล
● การเลือกตัวบ่งชี้ การเรียงลำดับและการวิเคราะห์ความสัมพันธ์: LLM สามารถช่วยให้ผู้ใช้เลือก จัดเรียง และวิเคราะห์ตัวบ่งชี้ต่างๆ เพื่อทำความเข้าใจความสัมพันธ์และความสัมพันธ์ระหว่างตัวบ่งชี้เหล่านั้นได้ดีขึ้น ซึ่งจะช่วยสนับสนุนการวิเคราะห์ข้อมูลที่ลึกยิ่งขึ้นและการตัดสินใจ
● สร้างคำอธิบายที่เป็นภาษาธรรมชาติของนามธรรมทางธุรกิจ: LLM สามารถสร้างบทสรุปหรือคำอธิบายที่เป็นภาษาที่เป็นธรรมชาติโดยอิงตามข้อมูลข้อเท็จจริง เพื่อช่วยให้ผู้ใช้เข้าใจนามธรรมทางธุรกิจและตัวบ่งชี้ข้อมูลได้ดีขึ้น ปรับปรุงความสามารถในการตีความ และตัดสินใจได้อย่างมีเหตุผลมากขึ้น
3.5. กรณีการใช้งานปัจจุบัน
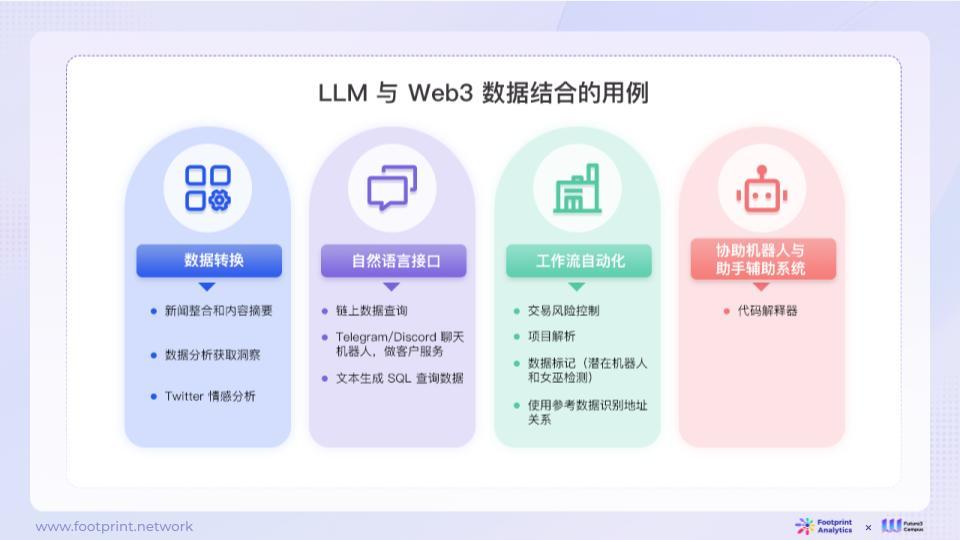
ตามข้อดีด้านเทคโนโลยีและประสบการณ์ผลิตภัณฑ์ของ LLM เอง สามารถนำไปใช้กับสถานการณ์ข้อมูล on-chain ต่างๆ ได้ ในทางเทคนิค สถานการณ์เหล่านี้สามารถแบ่งออกเป็นสี่ประเภทจากง่ายไปยาก:
● การแปลงข้อมูล: ดำเนินการต่างๆ เช่น การปรับปรุงข้อมูลและการสร้างใหม่ เช่น การสรุปข้อความ การจัดหมวดหมู่ และการดึงข้อมูล แอปพลิเคชันประเภทนี้พัฒนาได้เร็วกว่า แต่เหมาะสำหรับสถานการณ์ทั่วไปมากกว่า และไม่เหมาะสำหรับการประมวลผลข้อมูลจำนวนมากเป็นชุดอย่างง่าย
● อินเทอร์เฟซภาษาธรรมชาติ: เชื่อมต่อ LLM กับฐานความรู้หรือเครื่องมือเพื่อทำให้คำถามและคำตอบหรือการใช้เครื่องมือพื้นฐานเป็นแบบอัตโนมัติ สามารถใช้เพื่อสร้างแชทบอทมืออาชีพได้ แต่คุณค่าที่แท้จริงของมันจะได้รับผลกระทบจากปัจจัยอื่น ๆ เช่น คุณภาพของฐานความรู้ที่เชื่อมต่ออยู่
● เวิร์กโฟลว์อัตโนมัติ: ใช้ LLM เพื่อสร้างมาตรฐานและทำให้กระบวนการทางธุรกิจเป็นแบบอัตโนมัติ ซึ่งสามารถนำไปใช้กับกระบวนการประมวลผลข้อมูลบล็อกเชนที่ซับซ้อนมากขึ้น เช่น การแยกโครงสร้างกระบวนการดำเนินการสัญญาอัจฉริยะ การระบุความเสี่ยง เป็นต้น
● หุ่นยนต์ช่วยเหลือและระบบเสริมผู้ช่วย: ระบบเสริมเป็นระบบที่ได้รับการปรับปรุงซึ่งรวมแหล่งข้อมูลและฟังก์ชันต่างๆ มากขึ้นตามอินเทอร์เฟซภาษาธรรมชาติ ซึ่งช่วยปรับปรุงประสิทธิภาพการทำงานของผู้ใช้อย่างมาก
รูปที่ 12: สถานการณ์การใช้งาน LLM
3.6. ข้อจำกัดของ LLM
3.6.1. สถานะปัจจุบันของอุตสาหกรรม: การใช้งานที่ครบกำหนด ปัญหาที่กำลังเอาชนะ และความท้าทายที่ยังไม่ได้รับการแก้ไข
ในด้านข้อมูล Web3 แม้ว่าจะมีความก้าวหน้าที่สำคัญบางประการ แต่ก็ยังมีความท้าทายอยู่บ้าง
แอปพลิเคชันที่ค่อนข้างสมบูรณ์:
● ใช้ LLM สำหรับการประมวลผลข้อมูล: เทคโนโลยี AI เช่น LLM ถูกนำมาใช้อย่างประสบความสำเร็จในการสร้างข้อความสรุป สรุป คำอธิบาย ฯลฯ ช่วยให้ผู้ใช้ดึงข้อมูลสำคัญจากบทความขนาดยาวและรายงานระดับมืออาชีพ และปรับปรุงความสามารถในการอ่านและทำความเข้าใจข้อมูล
● ใช้ AI เพื่อแก้ไขปัญหาการพัฒนา: LLM ถูกนำมาใช้เพื่อแก้ไขปัญหาในกระบวนการพัฒนา เช่น การแทนที่ StackOverflow หรือเครื่องมือค้นหาเพื่อให้นักพัฒนาได้รับคำตอบสำหรับคำถามและการสนับสนุนด้านการเขียนโปรแกรม
ปัญหาที่ต้องแก้ไขและกำลังสำรวจ:
● ใช้ LLM เพื่อสร้างโค้ด: อุตสาหกรรมกำลังทำงานอย่างหนักเพื่อใช้เทคโนโลยี LLM ในการแปลงภาษาธรรมชาติเป็นภาษาคิวรี SQL เพื่อปรับปรุงระบบอัตโนมัติและความเข้าใจของการสืบค้นฐานข้อมูล อย่างไรก็ตาม จะมีปัญหามากมายในกระบวนการนี้ ตัวอย่างเช่น ในบางสถานการณ์ โค้ดที่สร้างขึ้นจำเป็นต้องมีความแม่นยำสูงมากและไวยากรณ์จะต้องถูกต้อง 100% เพื่อให้แน่ใจว่าโปรแกรมสามารถทำงานได้โดยไม่มีจุดบกพร่องและได้รับผลลัพธ์ที่ถูกต้อง ความยากลำบากยังรวมถึงการรับรองอัตราความสำเร็จและความถูกต้องในการตอบคำถาม รวมถึงความเข้าใจอย่างลึกซึ้งในธุรกิจ
● ปัญหาเกี่ยวกับคำอธิบายประกอบข้อมูล: คำอธิบายประกอบข้อมูลมีความสำคัญอย่างยิ่งต่อการฝึกฝนแมชชีนเลิร์นนิงและโมเดลการเรียนรู้เชิงลึก แต่ในช่องข้อมูล Web3 โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับข้อมูลบล็อกเชนที่ไม่ระบุชื่อ ความซับซ้อนของข้อมูลคำอธิบายประกอบมีสูง
● ปัญหาความแม่นยำและภาพหลอน: การเกิดขึ้นของภาพหลอนในโมเดล AI อาจได้รับผลกระทบจากปัจจัยหลายประการ รวมถึงข้อมูลการฝึกอบรมที่มีอคติหรือไม่เพียงพอ ความเหมาะสมมากเกินไป ความเข้าใจบริบทที่จำกัด การขาดความรู้เกี่ยวกับโดเมน การโจมตีของฝ่ายตรงข้าม และสถาปัตยกรรมโมเดล นักวิจัยและนักพัฒนาจำเป็นต้องปรับปรุงวิธีการฝึกอบรมและการสอบเทียบของแบบจำลองอย่างต่อเนื่อง เพื่อปรับปรุงความน่าเชื่อถือและความแม่นยำของข้อความที่สร้างขึ้น
● การใช้ข้อมูลเพื่อการวิเคราะห์ธุรกิจและผลลัพธ์ของบทความ: การใช้ข้อมูลเพื่อการวิเคราะห์ธุรกิจและการสร้างบทความยังคงเป็นปัญหาที่ท้าทาย ความซับซ้อนของปัญหา ความจำเป็นในการแจ้งเตือนที่ออกแบบมาอย่างระมัดระวัง ตลอดจนข้อมูลคุณภาพสูง ปริมาณข้อมูล และวิธีการลดปัญหาภาพหลอนล้วนเป็นประเด็นที่ต้องได้รับการแก้ไข
● การทำดัชนีข้อมูลสัญญาอัจฉริยะโดยอัตโนมัติตามโดเมนธุรกิจสำหรับการแยกข้อมูล: การทำดัชนีข้อมูลสัญญาอัจฉริยะโดยอัตโนมัติในโดเมนธุรกิจต่างๆ สำหรับการแยกข้อมูลยังคงเป็นปัญหาที่ยังไม่ได้รับการแก้ไข สิ่งนี้จำเป็นต้องพิจารณาอย่างครอบคลุมถึงลักษณะของสาขาธุรกิจที่แตกต่างกัน รวมถึงความหลากหลายและความซับซ้อนของข้อมูล
● การประมวลผลข้อมูลอนุกรมเวลา ข้อมูลเอกสารตาราง และรูปแบบที่ซับซ้อนมากขึ้น: โมเดลหลายรูปแบบ เช่น DALL·E 2 สามารถสร้างรูปแบบทั่วไป เช่น รูปภาพและคำพูดจากข้อความได้ดีมาก ในสาขาบล็อกเชนและการเงิน ข้อมูลอนุกรมเวลาบางรายการจำเป็นต้องได้รับการปฏิบัติเป็นพิเศษ ซึ่งไม่สามารถแก้ไขได้โดยการทำให้ข้อความเป็นเวกเตอร์ การผสมผสานข้อมูลอนุกรมเวลาและข้อความ การฝึกร่วมแบบข้ามโมดัล ฯลฯ เป็นแนวทางการวิจัยที่สำคัญเพื่อให้เกิดการวิเคราะห์และประยุกต์ใช้ข้อมูลอันชาญฉลาด
3.6.2. เหตุใด LLM เพียงอย่างเดียวจึงไม่สามารถแก้ไขปัญหาของอุตสาหกรรมข้อมูลบล็อคเชนได้อย่างสมบูรณ์แบบ
ในฐานะแบบจำลองภาษา LLM เหมาะสมกว่าสำหรับการจัดการสถานการณ์ที่ต้องการความคล่องแคล่วที่สูงขึ้น แต่เพื่อให้ได้ความถูกต้องแม่นยำ อาจต้องมีการปรับเปลี่ยนเพิ่มเติมในแบบจำลอง เมื่อใช้ LLM กับอุตสาหกรรมข้อมูลบล็อคเชน กรอบงานต่อไปนี้สามารถให้ข้อมูลอ้างอิงได้
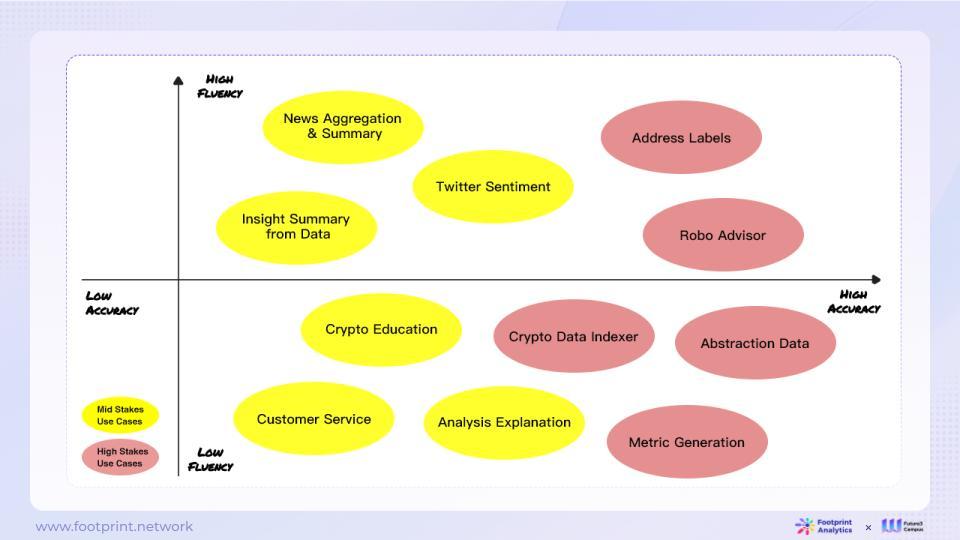
รูปที่ 13: ความคล่องแคล่ว ความแม่นยำ และความเสี่ยงในการใช้งานของเอาท์พุต LLM ในอุตสาหกรรมข้อมูลบล็อกเชน
เมื่อประเมินความเหมาะสมของ LLM ในการใช้งานต่างๆ การมุ่งเน้นไปที่ความคล่องแคล่วและความแม่นยำเป็นสิ่งสำคัญ ความคล่องแคล่วหมายถึงว่าผลลัพธ์ของโมเดลนั้นเป็นธรรมชาติและราบรื่นหรือไม่ ในขณะที่ความแม่นยำจะบ่งบอกว่าคำตอบของโมเดลนั้นแม่นยำหรือไม่ มิติทั้งสองนี้มีข้อกำหนดที่แตกต่างกันในสถานการณ์การใช้งานที่แตกต่างกัน
สำหรับงานที่มีข้อกำหนดด้านความคล่องแคล่วสูง เช่น การสร้างภาษาธรรมชาติ การเขียนเชิงสร้างสรรค์ ฯลฯ LLM มักจะเพียงพอแล้ว เนื่องจากประสิทธิภาพที่ยอดเยี่ยมในการประมวลผลภาษาธรรมชาติทำให้สามารถสร้างข้อความได้อย่างคล่องแคล่ว
ข้อมูล Blockchain ประสบปัญหามากมาย เช่น การวิเคราะห์ข้อมูล การประมวลผลข้อมูล และการประยุกต์ใช้ข้อมูล LLM มีความสามารถในการเข้าใจภาษาและการให้เหตุผลที่เหนือกว่า ทำให้เป็นเครื่องมือที่เหมาะสำหรับการโต้ตอบ จัดระเบียบ และสรุปข้อมูลบล็อกเชน อย่างไรก็ตาม LLM ไม่สามารถแก้ปัญหาทั้งหมดในช่องข้อมูลบล็อคเชนได้
ในแง่ของการประมวลผลข้อมูล LLM เหมาะสำหรับการวนซ้ำอย่างรวดเร็วและการประมวลผลเชิงสำรวจของข้อมูลออนไลน์ และพยายามใช้วิธีการประมวลผลใหม่ๆ อย่างต่อเนื่อง อย่างไรก็ตาม LLM ยังคงมีข้อจำกัดบางประการสำหรับงานต่างๆ เช่น การกระทบยอดโดยละเอียดในสภาพแวดล้อมการผลิต ปัญหาทั่วไปคือโทเค็นไม่ยาวพอที่จะจัดการเนื้อหาบริบทที่ยาว ข้อความแจ้งที่ใช้เวลานานจะตอบคำถามเรื่องความไม่เสถียรที่ส่งผลต่องานดาวน์สตรีม ส่งผลให้อัตราความสำเร็จไม่เสถียร และมีประสิทธิภาพต่ำในการดำเนินงานชุดใหญ่
ประการที่สอง ปัญหาภาพหลอนมีแนวโน้มที่จะเกิดขึ้นในการประมวลผลเนื้อหาโดย LLM ประมาณว่าความน่าจะเป็นที่จะเกิดอาการประสาทหลอนของ ChatGPT อยู่ที่ประมาณ 15% ถึง 20% และเนื่องจากความทึบของการประมวลผล จึงตรวจพบข้อผิดพลาดจำนวนมากได้ยาก ดังนั้นการจัดทำกรอบการทำงานและการรวบรวมความรู้จากผู้เชี่ยวชาญจึงมีความสำคัญ นอกจากนี้ ยังมีความท้าทายมากมายเมื่อ LLM รวมข้อมูลออนไลน์:
● มีเอนทิตีข้อมูลหลายประเภทและปริมาณมหาศาลในห่วงโซ่ เอนทิตีข้อมูลควรป้อนให้กับ LLM ในรูปแบบใดและใช้อย่างมีประสิทธิภาพในสถานการณ์เชิงพาณิชย์เฉพาะ เช่นเดียวกับอุตสาหกรรมแนวดิ่งอื่นๆ ซึ่งต้องมีการวิจัยและการสำรวจเพิ่มเติม
● ข้อมูลออนไลน์ประกอบด้วยข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง โซลูชันข้อมูลปัจจุบันส่วนใหญ่ในอุตสาหกรรมจะขึ้นอยู่กับความเข้าใจในข้อมูลธุรกิจ ในกระบวนการแยกวิเคราะห์ข้อมูลออนไลน์ ETL ใช้ในการกรอง ทำความสะอาด เสริม และกู้คืนตรรกะทางธุรกิจ และจัดระเบียบข้อมูลที่ไม่มีโครงสร้างให้เป็นข้อมูลที่มีโครงสร้าง ซึ่งสามารถให้การวิเคราะห์ที่มีประสิทธิภาพมากขึ้นสำหรับสถานการณ์ทางธุรกิจต่างๆ ในอนาคต ตัวอย่างเช่น การซื้อขาย DEX แบบมีโครงสร้าง ธุรกรรมตลาด NFT พอร์ตโฟลิโอที่อยู่กระเป๋าสตางค์ ฯลฯ มีลักษณะที่กล่าวมาข้างต้นคือคุณภาพสูง มูลค่าสูง ความแม่นยำและความถูกต้อง และสามารถให้บริการเสริมที่มีประสิทธิภาพแก่ LLM ทั่วไปได้
4. LLM เข้าใจผิด
4.1. LLM สามารถจัดการข้อมูลที่ไม่มีโครงสร้างได้โดยตรง ดังนั้น จึงไม่จำเป็นต้องใช้ข้อมูลที่มีโครงสร้างอีกต่อไป
โดยปกติ LLM จะได้รับการฝึกอบรมล่วงหน้าโดยอิงตามข้อมูลข้อความขนาดใหญ่ และโดยธรรมชาติแล้วเหมาะสำหรับการประมวลผลข้อมูลข้อความที่ไม่มีโครงสร้างทุกประเภท อย่างไรก็ตาม อุตสาหกรรมต่างๆ มีข้อมูลที่มีโครงสร้างจำนวนมากอยู่แล้ว โดยเฉพาะข้อมูลที่แยกวิเคราะห์ในช่อง Web3 วิธีใช้ข้อมูลเหล่านี้อย่างมีประสิทธิภาพเพื่อปรับปรุง LLM ถือเป็นหัวข้อการวิจัยที่กำลังเป็นที่นิยมในอุตสาหกรรม
สำหรับ LLM ข้อมูลที่มีโครงสร้างยังคงมีข้อดีดังต่อไปนี้:
● ใหญ่โต: ข้อมูลจำนวนมากถูกจัดเก็บไว้ในฐานข้อมูลและรูปแบบมาตรฐานอื่นๆ ที่อยู่เบื้องหลังแอปพลิเคชันต่างๆ โดยเฉพาะข้อมูลส่วนตัว ทุกบริษัทและอุตสาหกรรมยังคงมี LLM จำนวนมากโดยไม่มีข้อมูลภายในสำหรับการฝึกอบรมล่วงหน้า
● มีอยู่: ข้อมูลนี้ไม่จำเป็นต้องสร้างซ้ำ และต้นทุนการลงทุนต่ำมาก ปัญหาเดียวคือวิธีใช้งาน
● คุณภาพสูงและมีมูลค่าสูง: ความรู้ของผู้เชี่ยวชาญที่สั่งสมมาเป็นเวลานานในสาขานี้ มักจะจัดเก็บไว้ในข้อมูลที่มีโครงสร้างและใช้ในอุตสาหกรรม สถาบันการศึกษา และการวิจัย คุณภาพของข้อมูลที่มีโครงสร้างเป็นกุญแจสำคัญต่อความพร้อมใช้งานของข้อมูล รวมถึงความสมบูรณ์ของข้อมูล ความสม่ำเสมอ ความถูกต้อง ความเป็นเอกลักษณ์ และข้อเท็จจริง
● ประสิทธิภาพสูง: ข้อมูลที่มีโครงสร้างจะถูกจัดเก็บไว้ในตาราง ฐานข้อมูล หรือรูปแบบมาตรฐานอื่นๆ และสคีมาได้รับการกำหนดไว้ล่วงหน้าและสอดคล้องกันทั่วทั้งชุดข้อมูล ซึ่งหมายความว่ารูปแบบ ประเภท และความสัมพันธ์ของข้อมูลสามารถคาดการณ์และควบคุมได้ ทำให้การวิเคราะห์ข้อมูลและการสืบค้นง่ายขึ้นและเชื่อถือได้มากขึ้น นอกจากนี้ อุตสาหกรรมมี ETL ที่ครบกำหนดแล้ว และเครื่องมือการประมวลผลและการจัดการข้อมูลต่างๆ ซึ่งมีประสิทธิภาพและสะดวกในการใช้งานมากขึ้น LLM สามารถใช้ข้อมูลนี้ผ่าน API
● ความถูกต้องและข้อเท็จจริง: ขณะนี้ข้อมูลข้อความของ LLM ซึ่งอิงตามความน่าจะเป็นของโทเค็น ยังไม่สามารถให้คำตอบที่แน่นอนได้อย่างเสถียร ปัญหาภาพหลอนเป็นปัญหาพื้นฐานหลักที่ LLM ต้องแก้ไขมาโดยตลอด สำหรับอุตสาหกรรมและสถานการณ์ต่างๆ มากมาย ปัญหาด้านความปลอดภัยและความน่าเชื่อถือจะเกิดขึ้น เช่น การรักษาพยาบาล การเงิน ฯลฯ ข้อมูลที่มีโครงสร้างเป็นแนวทางที่สามารถช่วยเหลือและแก้ไขปัญหาเหล่านี้ของ LLM
● สะท้อนกราฟเชิงสัมพันธ์และตรรกะทางธุรกิจเฉพาะ: ข้อมูลที่มีโครงสร้างประเภทต่างๆ สามารถป้อนลงใน LLM ในรูปแบบองค์กรเฉพาะ (ฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูลกราฟ ฯลฯ) เพื่อแก้ไขปัญหาโดเมนประเภทต่างๆ ข้อมูลที่มีโครงสร้างใช้ภาษาการสืบค้นที่เป็นมาตรฐาน (เช่น SQL) ทำให้การสืบค้นและการวิเคราะห์ข้อมูลที่ซับซ้อนมีประสิทธิภาพและแม่นยำยิ่งขึ้น กราฟความรู้สามารถแสดงความสัมพันธ์ระหว่างเอนทิตีได้ดีขึ้น และทำให้การค้นหาที่เกี่ยวข้องง่ายขึ้น
● ต้นทุนการใช้งานต่ำ: LLM ไม่จำเป็นต้องฝึกโมเดลพื้นฐานทั้งหมดใหม่จากด้านล่างทุกครั้ง สามารถใช้ร่วมกับวิธีการเปิดใช้งาน LLM เช่น Agent และ LLM API เพื่อเข้าถึง LLM ได้เร็วขึ้นและมีค่าใช้จ่ายน้อยลง
ยังคงมีมุมมองเชิงจินตนาการบางอย่างในตลาดที่เชื่อว่า LLM มีความสามารถในการประมวลผลข้อมูลข้อความและข้อมูลที่ไม่มีโครงสร้างอย่างมาก ซึ่งสามารถทำได้โดยการนำเข้าข้อมูลดิบ รวมถึงข้อมูลที่ไม่มีโครงสร้าง เข้าสู่ LLM แนวคิดนี้คล้ายกับการขอให้ LLM วัตถุประสงค์ทั่วไปแก้ปัญหาทางคณิตศาสตร์ LLM ส่วนใหญ่มีแนวโน้มที่จะทำผิดพลาดเมื่อจัดการกับปัญหาการบวกและการลบของโรงเรียนประถมศึกษาแบบง่ายๆ หากไม่มีแบบจำลองความสามารถทางคณิตศาสตร์ที่สร้างขึ้นโดยเฉพาะ ในทางตรงกันข้าม การสร้างแบบจำลองแนวตั้งของ Crypto LLM ซึ่งคล้ายกับแบบจำลองความสามารถทางคณิตศาสตร์และแบบจำลองการสร้างภาพเป็นโซลูชันที่ใช้งานได้จริงมากกว่าสำหรับ LLM ในฟิลด์ Crypto
4.2. LLM สามารถอนุมานเนื้อหาจากข้อมูลข้อความ เช่น ข่าว และทวีต ผู้คนไม่ต้องการการวิเคราะห์ข้อมูลออนไลน์เพื่อสรุปอีกต่อไป
แม้ว่า LLM สามารถรับข้อมูลจากข้อความ เช่น ข่าวสารและโซเชียลมีเดีย แต่ข้อมูลเชิงลึกที่ได้รับโดยตรงจากข้อมูลออนไลน์ยังคงขาดไม่ได้ด้วยเหตุผลหลักดังต่อไปนี้:
● ข้อมูลออนไลน์เป็นข้อมูลต้นฉบับโดยตรง ในขณะที่ข้อมูลในข่าวสารและโซเชียลมีเดียอาจเป็นข้อมูลด้านเดียวหรือทำให้เข้าใจผิด การวิเคราะห์ข้อมูลออนไลน์โดยตรงสามารถลดความลำเอียงของข้อมูลได้ แม้ว่าการใช้ LLM สำหรับการวิเคราะห์ข้อความจะมีความเสี่ยงต่ออคติในการตีความ แต่การวิเคราะห์ข้อมูลแบบออนไลน์โดยตรงสามารถลดการตีความที่ผิดได้
● ข้อมูลออนไลน์ประกอบด้วยการโต้ตอบในอดีตและบันทึกธุรกรรมที่ครอบคลุม และการวิเคราะห์สามารถค้นพบแนวโน้มและรูปแบบในระยะยาว ข้อมูลในห่วงโซ่ยังสามารถแสดงภาพที่สมบูรณ์ของระบบนิเวศทั้งหมด เช่น การไหลเวียนของเงินทุน ความสัมพันธ์ระหว่างฝ่ายต่างๆ เป็นต้น ข้อมูลเชิงลึกในภาพรวมเหล่านี้ช่วยให้เข้าใจสถานการณ์ได้อย่างลึกซึ้งยิ่งขึ้น ในทางกลับกัน ข้อมูลข่าวสารและโซเชียลมีเดียมักจะกระจัดกระจายและเป็นระยะสั้นมากกว่า
● ข้อมูลบนห่วงโซ่เปิดอยู่ ใครๆ ก็สามารถตรวจสอบผลการวิเคราะห์และหลีกเลี่ยงความไม่สมดุลของข้อมูลได้ ข่าวและโซเชียลมีเดียอาจไม่เปิดเผยความจริงเสมอไป ข้อมูลข้อความและข้อมูลออนไลน์สามารถตรวจสอบร่วมกันได้ การรวมทั้งสองเข้าด้วยกันจะทำให้เกิดการตัดสินแบบสามมิติและแม่นยำยิ่งขึ้น
การวิเคราะห์ข้อมูลแบบออนไลน์ยังคงเป็นสิ่งที่ขาดไม่ได้ LLM มีบทบาทเสริมในการรับข้อมูลจากข้อความ แต่ไม่สามารถแทนที่การวิเคราะห์ข้อมูลออนไลน์โดยตรงได้ ใช้ประโยชน์จากทั้งสองอย่างอย่างเต็มที่เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
4.3. การสร้างโซลูชันข้อมูลบล็อกเชนโดยใช้ LLM โดยใช้ LangChain, LlamaIndex หรือเครื่องมือ AI อื่น ๆ เป็นเรื่องง่ายหรือไม่
เครื่องมือต่างๆ เช่น LangChain และ LlamaIndex มอบความสะดวกสบายในการสร้างแอปพลิเคชัน LLM แบบเรียบง่ายที่ปรับแต่งเอง ทำให้สามารถสร้างได้อย่างรวดเร็ว อย่างไรก็ตาม การใช้เครื่องมือเหล่านี้ในสภาพแวดล้อมการผลิตจริงให้ประสบความสำเร็จนั้นเกี่ยวข้องกับความท้าทายที่มากขึ้น การสร้างแอปพลิเคชัน LLM ที่ทำงานอย่างมีประสิทธิภาพและรักษาคุณภาพสูงเป็นงานที่ซับซ้อนซึ่งต้องใช้ความเข้าใจอย่างลึกซึ้งว่าเทคโนโลยีบล็อกเชนและเครื่องมือ AI ทำงานอย่างไร และบูรณาการเข้าด้วยกันอย่างมีประสิทธิภาพ นี่เป็นงานที่สำคัญแต่ท้าทายสำหรับอุตสาหกรรมข้อมูลบล็อคเชน
ในกระบวนการนี้ เราต้องตระหนักถึงลักษณะของข้อมูลบล็อคเชน ซึ่งต้องการความแม่นยำสูงมากและการตรวจสอบซ้ำได้ เมื่อข้อมูลได้รับการประมวลผลและวิเคราะห์ผ่าน LLM ผู้ใช้จะมีความคาดหวังสูงในเรื่องความถูกต้องและความน่าเชื่อถือ มีข้อขัดแย้งที่อาจเกิดขึ้นระหว่างสิ่งนี้กับความทนทานต่อข้อผิดพลาดแบบคลุมเครือของ LLM ดังนั้น เมื่อสร้างโซลูชันข้อมูลบล็อกเชน ความต้องการทั้งสองนี้จะต้องได้รับการชั่งน้ำหนักอย่างรอบคอบเพื่อให้ตรงตามความคาดหวังของผู้ใช้
แม้ว่าตลาดปัจจุบันจะมีเครื่องมือพื้นฐานอยู่บ้างแล้ว แต่สาขานี้ยังคงมีการพัฒนาอย่างรวดเร็วและทำซ้ำอย่างต่อเนื่อง คล้ายคลึงกับกระบวนการพัฒนาของโลก Web2 ตั้งแต่ภาษาการเขียนโปรแกรม PHP เริ่มต้น ไปจนถึงโซลูชันที่เติบโตและปรับขนาดได้มากขึ้น เช่น Java, Ruby, Python, JavaScript และ Node.js เป็นต้น ไปจนถึงเทคโนโลยีเกิดใหม่ เช่น Go และ Rust พวกเขามี มีประสบการณ์การพัฒนาอย่างต่อเนื่อง วิวัฒนาการ เครื่องมือ AI ก็เปลี่ยนแปลงอยู่ตลอดเวลา เฟรมเวิร์ก GPT ที่เกิดขึ้นใหม่ เช่น AutoGPT, Microsoft AutoGen และ GPT และ Agent ของ ChatGPT 4.0 Turbo ที่เพิ่งเปิดตัวโดย OpenAI เองก็แสดงให้เห็นเพียงส่วนหนึ่งของความเป็นไปได้ในอนาคตเท่านั้น นี่แสดงให้เห็นว่าทั้งอุตสาหกรรมข้อมูลบล็อกเชนและเทคโนโลยี AI ยังมีพื้นที่อีกมากมายสำหรับการพัฒนา และต้องใช้ความพยายามและนวัตกรรมอย่างต่อเนื่อง
ปัจจุบัน มีข้อผิดพลาดสองประการที่ต้องให้ความสนใจเป็นพิเศษเมื่อสมัคร LLM:
● ความคาดหวังสูงเกินไป: หลายคนคิดว่า LLM สามารถแก้ปัญหาได้ทั้งหมด แต่จริงๆ แล้ว LLM มีข้อจำกัดที่ชัดเจน ต้องใช้ทรัพยากรคอมพิวเตอร์จำนวนมาก มีค่าใช้จ่ายสูงในการฝึกอบรม และกระบวนการฝึกอบรมอาจไม่เสถียร มีความคาดหวังตามความเป็นจริงเกี่ยวกับความสามารถของ LLM และเข้าใจว่าความสามารถนั้นยอดเยี่ยมในบางสถานการณ์ เช่น การประมวลผลภาษาธรรมชาติและการสร้างข้อความ แต่อาจไม่มีความสามารถในด้านอื่น
● การเพิกเฉยต่อความต้องการทางธุรกิจ: กับดักอีกประการหนึ่งคือการใช้เทคโนโลยี LLM อย่างแข็งขันโดยไม่พิจารณาถึงความต้องการทางธุรกิจอย่างเต็มที่ ก่อนที่จะสมัคร LLM สิ่งสำคัญคือต้องระบุความต้องการทางธุรกิจที่เฉพาะเจาะจง มีความจำเป็นต้องประเมินว่า LLM เป็นตัวเลือกเทคโนโลยีที่ดีที่สุดหรือไม่ และต้องดำเนินการประเมินและควบคุมความเสี่ยง โดยเน้นย้ำว่าการประยุกต์ใช้ LLM อย่างมีประสิทธิผลต้องพิจารณาอย่างรอบคอบตามสถานการณ์จริงเพื่อหลีกเลี่ยงการใช้งานในทางที่ผิด
แม้ว่า LLM จะมีศักยภาพสูงในหลายสาขา แต่นักพัฒนาและนักวิจัยจำเป็นต้องระมัดระวังในการใช้ LLM และใช้ทัศนคติที่เปิดกว้างในการสำรวจเพื่อค้นหาสถานการณ์การใช้งานที่เหมาะสมยิ่งขึ้นและเพิ่มข้อได้เปรียบให้สูงสุด
บทความนี้เผยแพร่ร่วมกันโดย Footprint Analytics, Future 3 Campus และ HashKey Capital
เกี่ยวกับเรา
Footprint Analyticsเป็นผู้ให้บริการโซลูชั่นข้อมูลบล็อกเชน ด้วยความช่วยเหลือของเทคโนโลยีปัญญาประดิษฐ์ที่ล้ำสมัย เรามอบแพลตฟอร์มการวิเคราะห์ข้อมูลแบบไร้โค้ดแห่งแรกและ API ข้อมูลแบบรวมในฟิลด์ Crypto ช่วยให้ผู้ใช้สามารถดึงข้อมูล NFT, GameFi และการติดตามการไหลของกองทุนที่อยู่กระเป๋าสตางค์ของสาธารณะมากกว่า 30 แห่งได้อย่างรวดเร็ว ระบบนิเวศน์แบบลูกโซ่
เว็บไซต์อย่างเป็นทางการของรอยเท้า: https://www.footprint.network
Twitter:https://twitter.com/Footprint_Data
บัญชีสาธารณะ WeChat: การวิเคราะห์รอยเท้าบล็อคเชน
เข้าร่วมชุมชน: เพิ่มผู้ช่วยกลุ่ม WeChatfootprint_analytics
Future 3 Campusเป็นแพลตฟอร์มบ่มเพาะนวัตกรรม Web3.0 ที่เปิดตัวร่วมกันโดย Wanxiang Blockchain Laboratory และ HashKey Capital โดยมุ่งเน้นไปที่ 3 เส้นทางหลักๆ ของ Web3.0 Massive Adoption, DePIN และ AI โดยมีเซี่ยงไฮ้ กวางตุ้ง-ฮ่องกง-มาเก๊า Greater Bay Area และสิงคโปร์เป็นศูนย์บ่มเพาะหลัก ฐาน แผ่ระบบนิเวศ Web3.0 ทั่วโลก ในเวลาเดียวกัน Future 3 Campus จะเปิดตัวกองทุนเริ่มต้นมูลค่า 50 ล้านดอลลาร์สหรัฐสำหรับการบ่มเพาะโครงการ Web3.0 ซึ่งให้บริการนวัตกรรมและการเป็นผู้ประกอบการในสาขา Web3.0 อย่างแท้จริง
HashKey Capitalเป็นสถาบันการจัดการสินทรัพย์ที่มุ่งเน้นการลงทุนในเทคโนโลยีบล็อคเชนและสินทรัพย์ดิจิทัล ขนาดการจัดการสินทรัพย์ในปัจจุบันเกิน 1 พันล้านดอลลาร์สหรัฐ ในฐานะหนึ่งในสถาบันการลงทุนบล็อกเชนที่ใหญ่ที่สุดและมีอิทธิพลมากที่สุดในเอเชียและยังเป็นนักลงทุนสถาบันรายแรกสุดใน Ethereum HashKey Capital นำเสนอเอฟเฟกต์ชั้นนำโดยเชื่อมโยง Web2 และ Web3 และเชื่อมต่อกับผู้ประกอบการ นักลงทุน ชุมชน และหน่วยงานกำกับดูแล ร่วมมือกัน เพื่อสร้างระบบนิเวศบล็อกเชนที่ยั่งยืน บริษัทตั้งอยู่ในฮ่องกง สิงคโปร์ ญี่ปุ่น สหรัฐอเมริกา และที่อื่นๆ บริษัทเป็นผู้นำในการปรับใช้บริษัทที่ลงทุนทั่วโลกมากกว่า 500 แห่งทั่วทั้งเลเยอร์ 1, โปรโตคอล, Crypto Finance, โครงสร้างพื้นฐาน Web3, แอปพลิเคชัน, NFT, Metaverse และ เพลงอื่นๆ และเป็นตัวแทน โครงการที่ลงทุน ได้แก่ Cosmos, Coinlist, Aztec, Blockdaemon, dYdX, imToken, Animoca Brands, Falcon X, Space and time, Mask Network, Polkadot, Moonbeam และ Galxe (เดิมชื่อ Project Galaxy) เป็นต้น


