
LUCIDA: วิธีใช้กลยุทธ์แบบหลายปัจจัยเพื่อสร้างพอร์ตโฟลิโอสินทรัพย์ crypto ที่ทรงพลัง (การประมวลผลข้อมูลล่วงหน้า)
คำนำ
ต่อจากบทที่แล้วเราเผยแพร่บทความแรกในซีรีส์ การสร้างพอร์ตโฟลิโอ Crypto-Asset ที่มีประสิทธิภาพโดยใช้กลยุทธ์หลายปัจจัย - พื้นฐานทางทฤษฎีบทความนี้เป็นบทความที่สอง - การประมวลผลข้อมูลล่วงหน้า
ก่อน/หลังการคำนวณข้อมูลปัจจัย และก่อนที่จะทดสอบความถูกต้องของปัจจัยเดียว จำเป็นต้องประมวลผลข้อมูลที่เกี่ยวข้อง การประมวลผลข้อมูลล่วงหน้าเฉพาะเกี่ยวข้องกับการประมวลผลค่าที่ซ้ำกัน ค่าผิดปกติ/ค่าที่หายไป/ค่าสูงสุด การกำหนดมาตรฐาน และความถี่ของข้อมูล
1. ค่าที่ซ้ำกัน
คำจำกัดความที่เกี่ยวข้องกับข้อมูล:
คีย์: แสดงถึงดัชนีเฉพาะ เช่น สำหรับข้อมูลที่มีโทเค็นทั้งหมดและวันที่ทั้งหมด คีย์คือ token_id/contract_address - date
ค่า: วัตถุที่จัดทำดัชนีโดยคีย์เรียกว่า ค่า
การวินิจฉัยค่าที่ซ้ำกันก่อนอื่นต้องทำความเข้าใจว่าข้อมูล ควร มีลักษณะอย่างไร โดยปกติแล้วข้อมูลจะอยู่ในรูปแบบ:
ข้อมูลอนุกรมเวลา สิ่งสำคัญคือ เวลา เช่น ข้อมูลราคาห้าปีสำหรับโทเค็นเดียว
ข้อมูลภาพตัดขวาง (Cross Section) สิ่งสำคัญคือ ปัจเจกบุคคล เช่น2023.11.01 ข้อมูลราคาของโทเค็นทั้งหมดในตลาด crypto ในวันนั้น
ข้อมูลพาเนล (พาเนล) สิ่งสำคัญคือการผสมผสานระหว่าง เวลาส่วนบุคคล ตัวอย่างเช่น ข้อมูลราคาของโทเค็นทั้งหมดในช่วงสี่ปีตั้งแต่ 2019.01.01 ถึง 2023.11.01
หลักการ: เมื่อกำหนดดัชนี (คีย์) ของข้อมูลแล้ว คุณจะทราบได้ว่าข้อมูลไม่ควรมีค่าซ้ำกันในระดับใด
วิธีการตรวจสอบ:
pd.DataFrame.duplicated(subset=[key 1, key 2, ...])
ตรวจสอบจำนวนค่าที่ซ้ำกัน: pd.DataFrame.duplicated(subset=[key 1, key 2, ...]).sum()
การสุ่มตัวอย่างเพื่อดูตัวอย่างที่ซ้ำกัน: df[df.duplicated(subset=[...])].sample() หลังจากค้นหาตัวอย่างแล้ว ให้ใช้ df.loc เพื่อเลือกตัวอย่างที่ซ้ำกันทั้งหมดที่สอดคล้องกับดัชนี
pd.merge(df 1, df 2, on=[key 1, key 2, ...], indicator=True, validate='1: 1')
ในฟังก์ชันการรวมแนวนอน การเพิ่มพารามิเตอร์ตัวบ่งชี้จะสร้างฟิลด์ _merge ใช้ dfm[_merge].value_counts() เพื่อตรวจสอบจำนวนตัวอย่างจากแหล่งต่างๆ หลังจากการรวมเข้าด้วยกัน
ด้วยการเพิ่มพารามิเตอร์ตรวจสอบ คุณสามารถตรวจสอบว่าดัชนีในชุดข้อมูลที่ผสานเป็นไปตามที่คาดไว้หรือไม่ (1 ต่อ 1, 1 ต่อหลายรายการ หรือหลายต่อหลายรายการ กรณีสุดท้ายหมายความว่าไม่จำเป็นต้องมีการตรวจสอบความถูกต้อง) ถ้าไม่เป็นไปตามที่คาดไว้ กระบวนการผสานจะรายงานข้อผิดพลาดและยกเลิกการดำเนินการ
2. ค่าผิดปกติ/ค่าที่หายไป/ค่าสูงสุด
สาเหตุทั่วไปของค่าผิดปกติ:
กรณีที่รุนแรงตัวอย่างเช่น หากราคาโทเค็นคือ 0.000001 $ หรือโทเค็นมีมูลค่าตลาดเพียง 500,000 ดอลลาร์สหรัฐ หากมีการเปลี่ยนแปลงเล็กน้อยก็จะได้รับผลตอบแทนหลายสิบเท่า
ลักษณะข้อมูลตัวอย่างเช่น หากข้อมูลราคาโทเค็นเริ่มดาวน์โหลดในวันที่ 1 มกราคม 2020 ก็เป็นไปไม่ได้เลยที่จะคำนวณข้อมูลส่งคืนในวันที่ 1 มกราคม 2020 เนื่องจากไม่มีราคาปิดของวันก่อนหน้า
ข้อผิดพลาดของข้อมูลผู้ให้บริการข้อมูลจะทำผิดพลาดอย่างหลีกเลี่ยงไม่ได้ เช่น บันทึก 12 หยวนต่อโทเค็นเป็น 1.2 หยวนต่อโทเค็น
หลักการจัดการค่าผิดปกติและค่าที่หายไป:
ลบ. ค่าผิดปกติที่ไม่สามารถแก้ไขได้ตามสมควรอาจได้รับการพิจารณาให้ลบออก
แทนที่. มักใช้ในการประมวลผลค่าสุดขั้ว เช่น การชนะหรือการหาลอการิทึม (ไม่ได้ใช้กันทั่วไป)
การกรอก. สำหรับค่าที่หายไปคุณยังอาจพิจารณากรอกข้อมูลด้วยวิธีที่เหมาะสมได้อีกด้วย วิธีทั่วไปได้แก่หมายถึง(หรือค่าเฉลี่ยเคลื่อนที่)การแก้ไข(Interpolation)、กรอก 0df.fillna(0), ส่งต่อ df.fillna(ffill)/การเติมแบบย้อนกลับ df.fillna(bfill) ฯลฯ มีความจำเป็นต้องพิจารณาว่าสมมติฐานที่การเติมอาศัยนั้นสอดคล้องกันหรือไม่
ใช้การเติมแบบย้อนกลับด้วยความระมัดระวังในแมชชีนเลิร์นนิง เนื่องจากมีความเสี่ยงที่จะมีอคติแบบมองไปข้างหน้า
วิธีจัดการกับค่าที่มากเกินไป:
1. วิธีเปอร์เซ็นไทล์
ด้วยการเรียงลำดับจากน้อยไปมาก ข้อมูลที่เกินอัตราส่วนขั้นต่ำและสูงสุดจะถูกแทนที่ด้วยข้อมูลสำคัญ สำหรับข้อมูลที่มีข้อมูลในอดีตจำนวนมาก วิธีการนี้ค่อนข้างหยาบและใช้งานไม่ได้มากนัก การบังคับลบข้อมูลในสัดส่วนคงที่อาจทำให้เกิดการสูญเสียในสัดส่วนหนึ่งได้
2.3σ / สามวิธีส่วนเบี่ยงเบนมาตรฐาน

ทำการปรับเปลี่ยนต่อไปนี้กับปัจจัยทั้งหมดภายในช่วงข้อมูล:
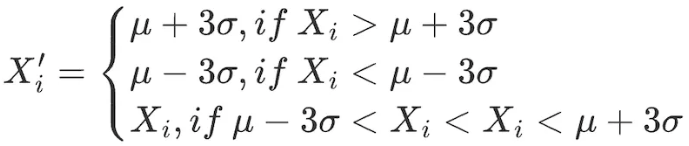
ข้อเสียของวิธีนี้คือข้อมูลที่ใช้กันทั่วไปในสาขาเชิงปริมาณ เช่น ราคาหุ้นและราคาโทเค็น มักแสดงการกระจายแบบ Peaked และ Thick-tailed ซึ่งไม่สอดคล้องกับสมมติฐานของการแจกแจงแบบปกติ ในกรณีนี้ การใช้ วิธีการ 3 σ จะระบุข้อมูลจำนวนมากผิดพลาดโดยไม่ได้ตั้งใจ
3. วิธีค่ามัธยฐานส่วนเบี่ยงเบนสัมบูรณ์ (MAD)
วิธีการนี้ขึ้นอยู่กับค่ามัธยฐานและค่าเบี่ยงเบนสัมบูรณ์ ทำให้ข้อมูลที่ประมวลผลมีความไวต่อค่าสุดขีดหรือค่าผิดปกติน้อยลง แข็งแกร่งกว่าวิธีการตามค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน
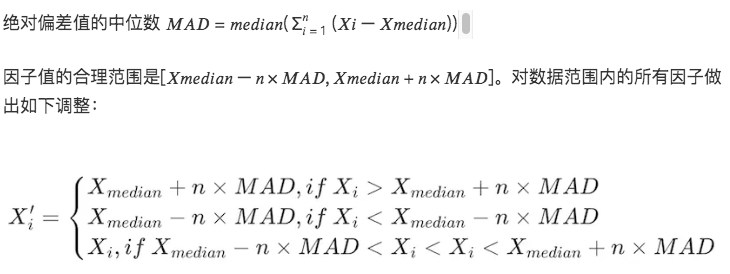
# จัดการกับสถานการณ์ที่มีมูลค่าสูงของข้อมูลปัจจัย
class Extreme(object):
def __init__(s, ini_data):
s.ini_data = ini_data
def three_sigma(s, n= 3):
mean = s.ini_data.mean()
std = s.ini_data.std()
low = mean - n*std
high = mean + n*std
return np.clip(s.ini_data, low, high)
def mad(s, n= 3):
median = s.ini_data.median()
mad_median = abs(s.ini_data - median).median()
high = median + n * mad_median
low = median - n * mad_median
return np.clip(s.ini_data, low, high)
def quantile(s, l = 0.025, h = 0.975):
low = s.ini_data.quantile(l)
high = s.ini_data.quantile(h)
return np.clip(s.ini_data, low, high)
3. การกำหนดมาตรฐาน
มาตรฐาน 1.Z-score

2. การกำหนดมาตรฐานความแตกต่างค่าสูงสุดและต่ำสุด (Min-Max Scaling)
แปลงข้อมูลปัจจัยแต่ละรายการให้เป็นข้อมูลในช่วงเวลา (0, 1) ทำให้สามารถเปรียบเทียบข้อมูลที่มีขนาดหรือช่วงต่างกันได้ แต่จะไม่เปลี่ยนการกระจายภายในข้อมูล และไม่ทำให้ผลรวมกลายเป็น 1
เนื่องจากการพิจารณาค่าสูงสุดและค่าต่ำสุด จึงมีความอ่อนไหวต่อค่าผิดปกติ
การรวมมิติข้อมูลเข้าด้วยกันช่วยให้สามารถเปรียบเทียบข้อมูลในมิติต่างๆ ได้
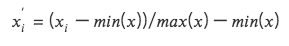
3. การปรับขนาดอันดับ
แปลงฟีเจอร์ข้อมูลเป็นการจัดอันดับ และแปลงการจัดอันดับเหล่านี้เป็นคะแนนระหว่าง 0 ถึง 1 ซึ่งโดยทั่วไปแล้วจะเป็นเปอร์เซ็นไทล์ในชุดข้อมูล *
วิธีนี้ไม่คำนึงถึงค่าผิดปกติเนื่องจากการจัดอันดับไม่ได้รับผลกระทบจากค่าผิดปกติ
ระยะทางที่แน่นอนระหว่างจุดต่างๆ ในข้อมูลจะไม่คงอยู่ แต่จะแปลงเป็นการจัดอันดับแบบสัมพันธ์กัน
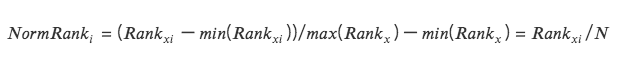
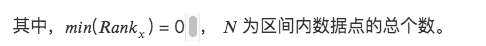
# ระดับข้อมูลปัจจัยที่เป็นมาตรฐานมาตราส่วน (วัตถุ):
def __init__(s, ini_data, date):
s.ini_data = ini_data
s.date = date
def zscore(s):
mean = s.ini_data.mean()
std = s.ini_data.std()
return s.ini_data.sub(mean).div(std)
def maxmin(s):
min = s.ini_data.min()
max = s.ini_data.max()
return s.ini_data.sub(min).div(max - min)
def normRank(s):
# จัดอันดับคอลัมน์ที่ระบุ method=min หมายความว่าค่าเดียวกันจะมีอันดับเดียวกัน ไม่ใช่อันดับเฉลี่ย
ranks = s.ini_data.rank(method='min')
return ranks.div(ranks.max())
4. ความถี่ข้อมูล
บางครั้งข้อมูลที่ได้รับไม่ตรงกับความถี่ที่จำเป็นสำหรับการวิเคราะห์ของเรา ตัวอย่างเช่น หากระดับการวิเคราะห์เป็นรายเดือน และความถี่ของข้อมูลต้นฉบับเป็นรายวัน คุณต้องใช้ การสุ่มตัวอย่าง กล่าวคือ ข้อมูลรวมจะเป็นรายเดือน
การสุ่มตัวอย่าง
อ้างอิงรวบรวมข้อมูลในคอลเลกชันเป็นข้อมูลแถวเดียวตัวอย่างเช่น ข้อมูลรายวันจะรวมเป็นข้อมูลรายเดือน ในเวลานี้ จำเป็นต้องพิจารณาถึงคุณลักษณะของตัวบ่งชี้รวมแต่ละตัว การดำเนินการทั่วไป ได้แก่:
ค่าแรก/ค่าสุดท้าย
ค่าเฉลี่ย/ค่ามัธยฐาน
ส่วนเบี่ยงเบนมาตรฐาน
การสุ่มตัวอย่าง
หมายถึงการแบ่งข้อมูลหนึ่งแถวออกเป็นข้อมูลหลายแถว เช่น ข้อมูลรายปีที่ใช้ในการวิเคราะห์รายเดือน สถานการณ์นี้มักต้องมีการทำซ้ำง่ายๆ และบางครั้งจำเป็นต้องรวบรวมข้อมูลประจำปีในแต่ละเดือนตามสัดส่วน


