
จากไซโลสู่การทำงานร่วมกัน: ความสำคัญของไปป์ไลน์ข้อมูลดั้งเดิมของ Web3
ผู้เขียน:Jay : : FP
การรวบรวม: Deep Tide TechFlow
การเปิดตัวสมุดปกขาวของ Bitcoin ในปี 2551 ได้จุดประกายให้เกิดการคิดใหม่เกี่ยวกับแนวคิดเรื่องความไว้วางใจ จากนั้นบล็อกเชนได้ขยายคำจำกัดความให้รวมแนวคิดของระบบที่ไร้ความน่าเชื่อถือ และพัฒนาอย่างรวดเร็วเพื่อโต้แย้งว่าคุณค่าประเภทต่างๆ เช่น อำนาจอธิปไตยส่วนบุคคล การทำให้เป็นประชาธิปไตยทางการเงิน และความเป็นเจ้าของ สามารถนำไปใช้กับระบบที่มีอยู่ได้ แน่นอนว่าอาจต้องมีการตรวจสอบและอภิปรายกันเป็นจำนวนมากก่อนที่บล็อคเชนจะสามารถนำมาใช้ได้จริง เนื่องจากลักษณะของบล็อคเชนอาจดูค่อนข้างรุนแรงเมื่อเทียบกับระบบต่างๆ ที่มีอยู่ อย่างไรก็ตาม หากเรามองโลกในแง่ดีเกี่ยวกับสถานการณ์เหล่านี้ การสร้างไปป์ไลน์ข้อมูล และการวิเคราะห์ข้อมูลอันมีค่าที่มีอยู่ในที่เก็บข้อมูลบล็อคเชนมีศักยภาพที่จะกลายเป็นจุดเปลี่ยนสำคัญอีกจุดหนึ่งในการพัฒนาอุตสาหกรรม เนื่องจากเราสามารถสังเกต Web3 ที่ไม่เคยมีมาก่อน ธุรกิจพื้นเมือง ปัญญา.
บทความนี้สำรวจศักยภาพของไปป์ไลน์ข้อมูลแบบ Web3 โดยการฉายไปป์ไลน์ข้อมูลที่ใช้กันทั่วไปในตลาดไอทีที่มีอยู่ในสภาพแวดล้อม Web3 บทความนี้กล่าวถึงประโยชน์ของไปป์ไลน์เหล่านี้ ความท้าทายที่ต้องแก้ไข และผลกระทบของไปป์ไลน์เหล่านี้ต่ออุตสาหกรรม
1. Singularity มาจากนวัตกรรมสารสนเทศ
“ภาษาเป็นหนึ่งในความแตกต่างที่สำคัญที่สุดระหว่างมนุษย์กับสัตว์ชั้นล่าง ไม่ใช่แค่ความสามารถในการสร้างเสียงเท่านั้น แต่ยังเชื่อมโยงเสียงที่ชัดเจนกับความคิดที่ชัดเจน และใช้เสียงเหล่านั้นเป็นสัญลักษณ์ในการสื่อสารความคิด” - ดาร์วิน
ในอดีต ความก้าวหน้าที่สำคัญในอารยธรรมของมนุษย์มาพร้อมกับนวัตกรรมในการแบ่งปันข้อมูล บรรพบุรุษของเราใช้ภาษาทั้งพูดและเขียนในการสื่อสารระหว่างกันและถ่ายทอดความรู้ไปยังรุ่นต่อ ๆ ไป สิ่งนี้ทำให้พวกเขาได้เปรียบเหนือสายพันธุ์อื่นอย่างมาก การประดิษฐ์การเขียน กระดาษ และการพิมพ์ทำให้สามารถแบ่งปันข้อมูลได้อย่างกว้างขวางมากขึ้น ซึ่งนำไปสู่ความก้าวหน้าครั้งใหญ่ในด้านวิทยาศาสตร์ เทคโนโลยี และวัฒนธรรม การพิมพ์พระคัมภีร์กูเทนเบิร์กแบบเคลื่อนย้ายได้โดยใช้โลหะเป็นช่วงเวลาสำคัญ เนื่องจากทำให้สามารถผลิตหนังสือและสิ่งพิมพ์อื่นๆ จำนวนมากได้ สิ่งนี้มีผลกระทบอย่างลึกซึ้งต่อจุดเริ่มต้นของการปฏิรูป การปฏิวัติประชาธิปไตย และความก้าวหน้าทางวิทยาศาสตร์
การพัฒนาอย่างรวดเร็วของเทคโนโลยีไอทีในช่วงปี 2000 ทำให้เราเข้าใจพฤติกรรมของมนุษย์อย่างลึกซึ้งยิ่งขึ้น สิ่งนี้นำไปสู่การเปลี่ยนแปลงวิถีชีวิตที่คนส่วนใหญ่ในยุคปัจจุบันตัดสินใจได้หลากหลายโดยใช้ข้อมูลดิจิทัล ด้วยเหตุนี้เราจึงเรียกสังคมสมัยใหม่ว่า ยุคนวัตกรรมไอที
เพียง 20 ปีหลังจากอินเทอร์เน็ตเชิงพาณิชย์อย่างเต็มรูปแบบ เทคโนโลยีปัญญาประดิษฐ์ก็ได้สร้างความประหลาดใจให้กับโลกอีกครั้ง มีแอปพลิเคชั่นมากมายที่สามารถทดแทนแรงงานมนุษย์ได้ และหลายคนกำลังพูดถึงอารยธรรมที่ AI จะเปลี่ยนแปลงไป บางคนถึงกับถูกปฏิเสธ โดยสงสัยว่าเทคโนโลยีดังกล่าวเกิดขึ้นเร็วมากจนสั่นคลอนรากฐานของสังคมของเราได้อย่างไร แม้ว่าจะมี กฎของมัวร์ ที่แสดงให้เห็นว่าประสิทธิภาพของเซมิคอนดักเตอร์จะเพิ่มขึ้นแบบทวีคูณเมื่อเวลาผ่านไป แต่การเปลี่ยนแปลงที่เกิดจากการเกิดขึ้นของ GPT นั้นกะทันหันเกินกว่าจะเผชิญได้ในทันที
อย่างไรก็ตาม สิ่งที่น่าสนใจคือตัวโมเดล GPT เองก็ไม่ใช่สถาปัตยกรรมที่แหวกแนวมากนัก ในทางกลับกัน อุตสาหกรรม AI จะแสดงรายการต่อไปนี้เป็นปัจจัยความสำเร็จหลักสำหรับโมเดล GPT: 1) คำจำกัดความของโดเมนธุรกิจที่สามารถกำหนดเป้าหมายกลุ่มลูกค้าขนาดใหญ่ได้ และ 2) การปรับแต่งโมเดลผ่านไปป์ไลน์ข้อมูลตั้งแต่การรับข้อมูลจนถึงขั้นสุดท้าย ผลลัพธ์และการตอบรับตามผลลัพธ์ของ กล่าวโดยสรุป แอปพลิเคชันเหล่านี้ทำให้เกิดนวัตกรรมโดยการปรับปรุงวัตถุประสงค์ในการให้บริการ และอัปเกรดกระบวนการประมวลผลข้อมูล/ข้อมูล
2. การตัดสินใจที่ขับเคลื่อนด้วยข้อมูลมีอยู่ทั่วไป
สิ่งที่เราเรียกว่านวัตกรรมส่วนใหญ่นั้นแท้จริงแล้วมีพื้นฐานมาจากการบิดเบือนข้อมูลที่สะสมมา ไม่ใช่โอกาสหรือสัญชาตญาณ ดังสุภาษิตที่ว่า ในตลาดทุนนิยม ไม่ใช่ผู้เข้มแข็งเท่านั้นที่จะอยู่รอด แต่เป็นผู้รอดชีวิตที่เข้มแข็ง ธุรกิจในปัจจุบันมีการแข่งขันสูงและตลาดอิ่มตัว ดังนั้น ธุรกิจต่างๆ จึงรวบรวมและวิเคราะห์ข้อมูลทุกประเภทเพื่อคว้าแม้แต่กลุ่มที่เล็กที่สุด
เราอาจหมกมุ่นอยู่กับทฤษฎี การทำลายอย่างสร้างสรรค์ ของชุมปีเตอร์มากเกินไป และให้ความสำคัญกับการตัดสินใจตามสัญชาตญาณมากเกินไป อย่างไรก็ตาม แม้แต่สัญชาตญาณที่ยิ่งใหญ่ก็ยังเป็นผลมาจากข้อมูลและสารสนเทศที่สะสมไว้ของแต่ละบุคคลในท้ายที่สุด โลกดิจิทัลจะเจาะลึกเข้ามาในชีวิตของเรามากขึ้นในอนาคต และข้อมูลที่ละเอียดอ่อนจะถูกนำเสนอในรูปแบบของข้อมูลดิจิทัลมากขึ้นเรื่อยๆ
ตลาด Web3 ได้รับความสนใจอย่างมากถึงศักยภาพในการให้ผู้ใช้ควบคุมข้อมูลของตนได้ อย่างไรก็ตาม ฟิลด์บล็อกเชนซึ่งเป็นเทคโนโลยีพื้นฐานของ Web3 ในปัจจุบันมีความกังวลมากขึ้นกับการแก้ปัญหาไตรเล็มม่า (หมายเหตุ Deep Tide: ปัญหาสามเหลี่ยมสามเหลี่ยม นั่นคือ ปัญหาด้านความปลอดภัย การกระจายอำนาจ และความสามารถในการขยายขนาด) เพื่อให้เทคโนโลยีใหม่น่าเชื่อถือในโลกแห่งความเป็นจริง สิ่งสำคัญคือต้องพัฒนาแอปพลิเคชันและความชาญฉลาดที่สามารถนำมาใช้ได้หลายวิธี เราได้เห็นสิ่งนี้เกิดขึ้นในพื้นที่ Big Data และวิธีการสร้างการประมวลผล Big Data และไปป์ไลน์ข้อมูลได้ก้าวหน้าไปอย่างมากนับตั้งแต่ประมาณปี 2010 ในบริบทของ Web3 จะต้องพยายามขับเคลื่อนอุตสาหกรรมไปข้างหน้า และสร้างระบบกระแสข้อมูลเพื่อสร้างความฉลาดทางข้อมูล
3. โอกาสตามการไหลของข้อมูลในห่วงโซ่
ดังนั้นโอกาสใดที่เราสามารถคว้ามาจากระบบสตรีมมิ่งแบบ Web3-native และเราต้องจัดการกับความท้าทายอะไรบ้างเพื่อคว้าโอกาสเหล่านี้
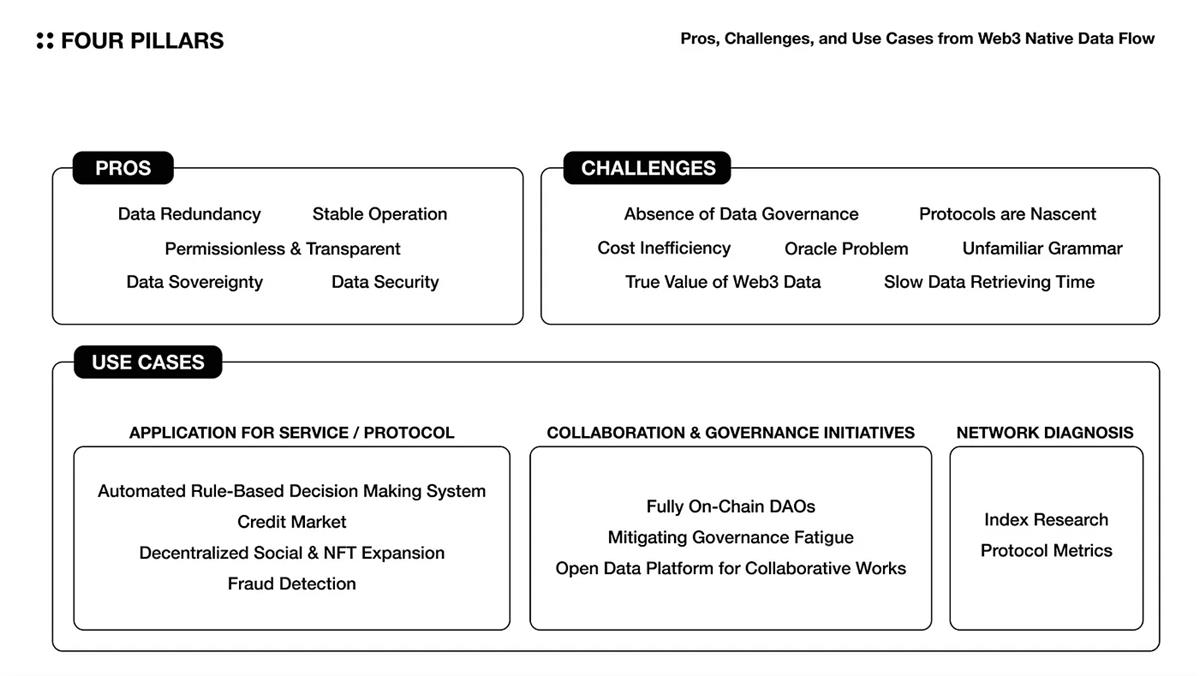
3.1 ข้อดี
กล่าวโดยสรุป คุณค่าของการกำหนดค่าสตรีมข้อมูลแบบ Web3 ก็คือข้อมูลที่เชื่อถือได้สามารถกระจายได้อย่างปลอดภัยและมีประสิทธิภาพไปยังหลาย ๆ เอนทิตี เพื่อให้สามารถดึงข้อมูลเชิงลึกอันมีค่าออกมาได้
ความซ้ำซ้อนของข้อมูล - ข้อมูลออนไลน์มีแนวโน้มที่จะสูญหายน้อยลงและมีความยืดหยุ่นมากขึ้น เนื่องจากเครือข่ายโปรโตคอลจะจัดเก็บส่วนย่อยของข้อมูลไว้บนหลายโหนด
ความปลอดภัยของข้อมูล - ข้อมูล On-chain นั้นป้องกันการงัดแงะ เนื่องจากได้รับการตรวจสอบและยินยอมโดยเครือข่ายของโหนดแบบกระจายอำนาจ
อธิปไตยของข้อมูล - อธิปไตยของข้อมูลเป็นสิทธิ์ของผู้ใช้ในการเป็นเจ้าของและควบคุมข้อมูลของตนเอง ด้วยการสตรีมข้อมูลแบบออนไลน์ ผู้ใช้สามารถดูว่าข้อมูลของตนถูกนำไปใช้อย่างไร และเลือกที่จะแบ่งปันเฉพาะกับผู้ที่มีความต้องการที่ถูกต้องตามกฎหมายในการเข้าถึงข้อมูลเท่านั้น
ไม่ได้รับอนุญาตและโปร่งใส - ข้อมูลออนไลน์มีความโปร่งใสและป้องกันการงัดแงะ เพื่อให้แน่ใจว่าข้อมูลที่กำลังประมวลผลเป็นแหล่งข้อมูลที่เชื่อถือได้
การทำงานที่เสถียร - เมื่อกระแสข้อมูลถูกควบคุมโดยโปรโตคอลในสภาพแวดล้อมแบบกระจาย แต่ละเลเยอร์จะมีความเสี่ยงต่อการหยุดทำงานน้อยลงอย่างมาก เนื่องจากไม่มีจุดล้มเหลวเพียงจุดเดียว
3.2 กรณีการสมัคร
ความไว้วางใจเป็นพื้นฐานของหน่วยงานต่างๆ ในการโต้ตอบกันและตัดสินใจ ดังนั้น เมื่อข้อมูลที่เชื่อถือได้สามารถเผยแพร่ได้อย่างปลอดภัย ก็หมายความว่าการโต้ตอบและการตัดสินใจหลายอย่างสามารถทำได้ผ่านบริการ Web3 ซึ่งมีหน่วยงานต่างๆ เข้าร่วม ซึ่งจะช่วยเพิ่มทุนทางสังคมให้สูงสุด และเราสามารถจินตนาการถึงกรณีการใช้งานต่างๆ ด้านล่างนี้
3.2.1 แอปพลิเคชันบริการ/โปรโตคอล
ระบบการตัดสินใจอัตโนมัติตามกฎ - โปรโตคอลใช้พารามิเตอร์หลักในการรันบริการ พารามิเตอร์เหล่านี้ได้รับการปรับเปลี่ยนเป็นประจำเพื่อรักษาเสถียรภาพของสถานะการบริการและมอบประสบการณ์ที่ดีที่สุดแก่ผู้ใช้ อย่างไรก็ตาม โปรโตคอลไม่สามารถตรวจสอบสถานะการบริการได้เสมอไป และทำการเปลี่ยนแปลงพารามิเตอร์แบบไดนามิกได้ทันเวลา นี่คือสิ่งที่กระแสข้อมูลออนไลน์ทำ สตรีมข้อมูลออนไลน์สามารถใช้เพื่อวิเคราะห์สถานะการบริการแบบเรียลไทม์ และแนะนำชุดพารามิเตอร์ที่ดีที่สุดเพื่อให้ตรงกับข้อกำหนดของบริการ (เช่น การใช้กลไกอัตราดอกเบี้ยลอยตัวอัตโนมัติสำหรับข้อตกลงการให้ยืม)
การเติบโตของตลาดสินเชื่อ - เครดิตถูกนำมาใช้ในตลาดการเงินมาแต่โบราณเพื่อวัดความสามารถในการชำระคืนของแต่ละบุคคล ซึ่งจะช่วยปรับปรุงประสิทธิภาพของตลาด อย่างไรก็ตาม คำจำกัดความของเครดิตยังไม่ชัดเจนในตลาด Web3 นี่เป็นเพราะข้อมูลส่วนบุคคลขาดแคลนและขาดการกำกับดูแลข้อมูลในอุตสาหกรรมต่างๆ ดังนั้นจึงเป็นการยากที่จะบูรณาการและรวบรวมข้อมูล ด้วยการสร้างกระบวนการรวบรวมและประมวลผลข้อมูลออนไลน์ที่กระจัดกระจาย ทำให้สามารถกำหนดตลาดสินเชื่อใหม่ในตลาด Web3 ได้ (เช่น การให้คะแนน MACRO (oracle ความเสี่ยงด้านเครดิตหลายสินทรัพย์) ของ Spectral)
ส่วนขยายทางสังคม/NFT ที่กระจายอำนาจ - สังคมที่กระจายอำนาจให้ความสำคัญกับการควบคุมผู้ใช้ การปกป้องความเป็นส่วนตัว การต่อต้านการเซ็นเซอร์ และการกำกับดูแลของชุมชน นี่เป็นกระบวนทัศน์ทางสังคมทางเลือก ดังนั้นจึงสามารถสร้างไปป์ไลน์เพื่อควบคุมและอัปเดตข้อมูลเมตาต่างๆ ได้อย่างราบรื่นยิ่งขึ้น และอำนวยความสะดวกในการโยกย้ายระหว่างแพลตฟอร์ม
การตรวจจับการฉ้อโกง - บริการ Web3 ที่ใช้สัญญาอัจฉริยะมีความเสี่ยงต่อการโจมตีที่เป็นอันตรายซึ่งสามารถขโมยเงิน ประนีประนอมระบบ และนำไปสู่การแยกส่วนและการโจมตีสภาพคล่อง ด้วยการสร้างระบบที่สามารถตรวจจับการโจมตีเหล่านี้ล่วงหน้า บริการ Web3 สามารถพัฒนาแผนการตอบสนองที่รวดเร็วและปกป้องผู้ใช้จากอันตราย
3.2.2 ความร่วมมือและการริเริ่มการกำกับดูแล
DAO แบบออนไลน์เต็มรูปแบบ - องค์กรอิสระแบบกระจายอำนาจ (DAO) พึ่งพาเครื่องมือนอกเครือข่ายอย่างมากเพื่อการกำกับดูแลที่มีประสิทธิภาพและการระดมทุนสาธารณะ ด้วยการสร้างกระบวนการประมวลผลข้อมูลแบบออนไลน์และสร้างกระบวนการที่โปร่งใสสำหรับการดำเนินงาน DAO มูลค่าของ DAO ดั้งเดิมของ Web3 จึงสามารถปรับปรุงเพิ่มเติมได้
การบรรเทาความเหนื่อยล้าในการกำกับดูแล - การตัดสินใจเกี่ยวกับโปรโตคอล Web3 มักกระทำผ่านการกำกับดูแลของชุมชน อย่างไรก็ตาม มีปัจจัยหลายประการที่ทำให้ผู้เข้าร่วมมีส่วนร่วมในการกำกับดูแลได้ยาก เช่น อุปสรรคทางภูมิศาสตร์ แรงกดดันในการติดตาม การขาดความเชี่ยวชาญที่จำเป็นสำหรับการกำกับดูแล วาระการกำกับดูแลที่เผยแพร่แบบสุ่ม และประสบการณ์ผู้ใช้ที่ไม่สะดวก กรอบการกำกับดูแลโปรโตคอลสามารถทำงานได้อย่างมีประสิทธิภาพและประสิทธิผลมากขึ้นหากสามารถสร้างเครื่องมือที่ทำให้กระบวนการสำหรับผู้เข้าร่วมเปลี่ยนจากการทำความเข้าใจไปสู่การนำวาระการกำกับดูแลแต่ละรายการไปใช้จริงได้
แพลตฟอร์มข้อมูลแบบเปิดสำหรับการทำงานร่วมกัน – ในวงการวิชาการและอุตสาหกรรมที่มีอยู่ ข้อมูลและสื่อการวิจัยจำนวนมากไม่ได้รับการเปิดเผยต่อสาธารณะ ซึ่งอาจทำให้การพัฒนาโดยรวมของตลาดไม่มีประสิทธิภาพอย่างมาก ในทางกลับกัน แหล่งรวมข้อมูลแบบออนไลน์สามารถอำนวยความสะดวกในการริเริ่มการทำงานร่วมกันได้มากกว่าตลาดที่มีอยู่ เนื่องจากมีความโปร่งใสและทุกคนสามารถเข้าถึงได้ การพัฒนามาตรฐานโทเค็นจำนวนมากและโซลูชัน DeFi เป็นตัวอย่างที่ดี นอกจากนี้ เราอาจดำเนินการแหล่งรวมข้อมูลสาธารณะเพื่อวัตถุประสงค์ต่างๆ
3.2.3 การวินิจฉัยเครือข่าย
การวิจัยดัชนี - ผู้ใช้ Web3 สร้างตัวบ่งชี้ต่างๆ เพื่อวิเคราะห์และเปรียบเทียบสถานะของโปรโตคอล สามารถศึกษาและแสดงผลการวัดวัตถุประสงค์หลายรายการ (เช่น ค่าสัมประสิทธิ์ Satoshi ของ Nakaflow) ได้แบบเรียลไทม์
การวัดโปรโตคอล - โดยการกระทืบข้อมูล เช่น จำนวนที่อยู่ที่ใช้งานอยู่ จำนวนธุรกรรม การไหลเข้า/ออกของสินทรัพย์ และค่าธรรมเนียมที่เกิดขึ้นโดยเครือข่าย ทำให้สามารถวิเคราะห์ประสิทธิภาพของโปรโตคอลได้ ข้อมูลนี้สามารถใช้เพื่อประเมินผลกระทบของการอัปเดตโปรโตคอลเฉพาะ สถานะของ MEV และสถานภาพของเครือข่าย
3.3 ความท้าทาย
ข้อมูลออนไลน์มีข้อดีเฉพาะตัวที่สามารถเพิ่มมูลค่าอุตสาหกรรมได้ อย่างไรก็ตาม เพื่อให้ได้รับประโยชน์เหล่านี้อย่างเต็มที่ ความท้าทายหลายประการต้องได้รับการแก้ไขทั้งภายในและภายนอกอุตสาหกรรม
ขาดการกำกับดูแลข้อมูล - การกำกับดูแลข้อมูลเป็นกระบวนการในการสร้างนโยบายและมาตรฐานข้อมูลที่สอดคล้องและใช้ร่วมกัน เพื่ออำนวยความสะดวกในการรวมข้อมูลดั้งเดิมแต่ละรายการ ในปัจจุบัน โปรโตคอลออนไลน์แต่ละโปรโตคอลจะสร้างมาตรฐานของตัวเองและดึงข้อมูลประเภทข้อมูลของตัวเอง อย่างไรก็ตาม ปัญหาคือการขาดการกำกับดูแลข้อมูลระหว่างเอนทิตีที่รวบรวมข้อมูลโปรโตคอลเหล่านี้และให้บริการ API แก่ผู้ใช้ ทำให้การบูรณาการระหว่างบริการต่างๆ เป็นเรื่องยาก และเป็นผลให้ผู้ใช้ได้รับข้อมูลเชิงลึกที่เชื่อถือได้และครอบคลุมได้ยาก
ความไร้ประสิทธิภาพด้านต้นทุน - การจัดเก็บข้อมูลเย็นในโปรโตคอลช่วยประหยัดความปลอดภัยของข้อมูลผู้ใช้และต้นทุนเซิร์ฟเวอร์ อย่างไรก็ตาม หากจำเป็นต้องเข้าถึงข้อมูลบ่อยครั้งเพื่อการวิเคราะห์หรือต้องใช้ทรัพยากรการประมวลผลจำนวนมาก การจัดเก็บข้อมูลบนบล็อกเชนอาจไม่คุ้มค่า
ปัญหาของออราเคิล - สัญญาอัจฉริยะสามารถทำงานได้อย่างสมบูรณ์ก็ต่อเมื่อพวกเขาสามารถเข้าถึงข้อมูลจากโลกแห่งความเป็นจริงเท่านั้น อย่างไรก็ตาม ข้อมูลเหล่านี้อาจไม่น่าเชื่อถือหรือสอดคล้องกันเสมอไป ต่างจากบล็อกเชนที่รักษาความสมบูรณ์ผ่านอัลกอริธึมที่เป็นเอกฉันท์ ข้อมูลภายนอกไม่สามารถกำหนดได้ โซลูชันของ Oracle ต้องมีการพัฒนาเพื่อให้มั่นใจถึงความสมบูรณ์ คุณภาพ และความสามารถในการปรับขนาดของข้อมูลภายนอก โดยไม่ขึ้นอยู่กับเลเยอร์แอปพลิเคชันเฉพาะ
โปรโตคอลยังอยู่ในช่วงเริ่มต้น - โปรโตคอลใช้โทเค็นของตัวเองเพื่อจูงใจผู้ใช้ให้ให้บริการทำงานต่อไปและชำระเงิน อย่างไรก็ตาม พารามิเตอร์ที่จำเป็นในการใช้งานโปรโตคอล (เช่น คำจำกัดความที่ชัดเจนและรูปแบบแรงจูงใจของผู้ใช้บริการ) มักจะได้รับการจัดการอย่างไร้เดียงสา ซึ่งหมายความว่าความยั่งยืนทางเศรษฐกิจของโปรโตคอลนั้นยากต่อการตรวจสอบ หากโปรโตคอลจำนวนมากเชื่อมต่อกันแบบออร์แกนิกและสร้างไปป์ไลน์ข้อมูล ก็จะมีความไม่แน่นอนมากขึ้นว่าไปป์ไลน์จะทำงานได้ดีหรือไม่
เวลาเรียกข้อมูลช้า - โดยทั่วไปโปรโตคอลจะประมวลผลธุรกรรมผ่านความเห็นพ้องของหลายโหนด ซึ่งจะจำกัดความเร็วและปริมาณของการประมวลผลข้อมูลเมื่อเปรียบเทียบกับตรรกะทางธุรกิจไอทีแบบดั้งเดิม คอขวดนี้แก้ไขได้ยาก เว้นแต่ประสิทธิภาพของโปรโตคอลทั้งหมดที่ประกอบเป็นไปป์ไลน์จะดีขึ้นอย่างมาก
คุณค่าที่แท้จริงของข้อมูล Web3 - Blockchains เป็นระบบแยกส่วนที่ยังไม่ได้เชื่อมต่อกับโลกแห่งความเป็นจริง เมื่อรวบรวมข้อมูล Web3 เราต้องพิจารณาว่าข้อมูลที่รวบรวมสามารถให้ข้อมูลเชิงลึกที่มีความหมายเพียงพอที่จะครอบคลุมต้นทุนในการสร้างไปป์ไลน์ข้อมูลหรือไม่
ไวยากรณ์ที่ไม่คุ้นเคย - โครงสร้างพื้นฐานข้อมูลไอทีที่มีอยู่และโครงสร้างพื้นฐานบล็อกเชนทำงานแตกต่างกันมาก แม้แต่ภาษาการเขียนโปรแกรมที่ใช้ก็แตกต่างกัน และโครงสร้างพื้นฐานบล็อกเชนก็มักจะใช้ภาษาระดับต่ำหรือภาษาใหม่ที่ออกแบบมาโดยเฉพาะสำหรับความต้องการบล็อกเชน สิ่งนี้ทำให้ยากสำหรับนักพัฒนาใหม่และผู้ใช้บริการในการเรียนรู้วิธีจัดการกับข้อมูลดั้งเดิมแต่ละรายการ เนื่องจากพวกเขาจำเป็นต้องเรียนรู้ภาษาการเขียนโปรแกรมใหม่หรือวิธีคิดใหม่เกี่ยวกับการทำงานกับข้อมูลบล็อกเชน
4. Lego Data Web3 ไปป์ไลน์
ไม่มีการเชื่อมต่อระหว่างข้อมูลดั้งเดิมของ Web3 ปัจจุบัน แต่จะแยกและประมวลผลข้อมูลอย่างอิสระ ทำให้ยากต่อการทดสอบการทำงานร่วมกันในการประมวลผลข้อมูล เพื่อแก้ไขปัญหานี้ บทความนี้จะแนะนำไปป์ไลน์ข้อมูลที่ใช้กันทั่วไปในตลาด IT และแมปข้อมูลดั้งเดิมของ Web3 ที่มีอยู่ลงบนไปป์ไลน์นี้ ซึ่งจะทำให้กรณีการใช้งานเป็นรูปธรรมมากขึ้น
4.1 ไปป์ไลน์ข้อมูลทั่วไป
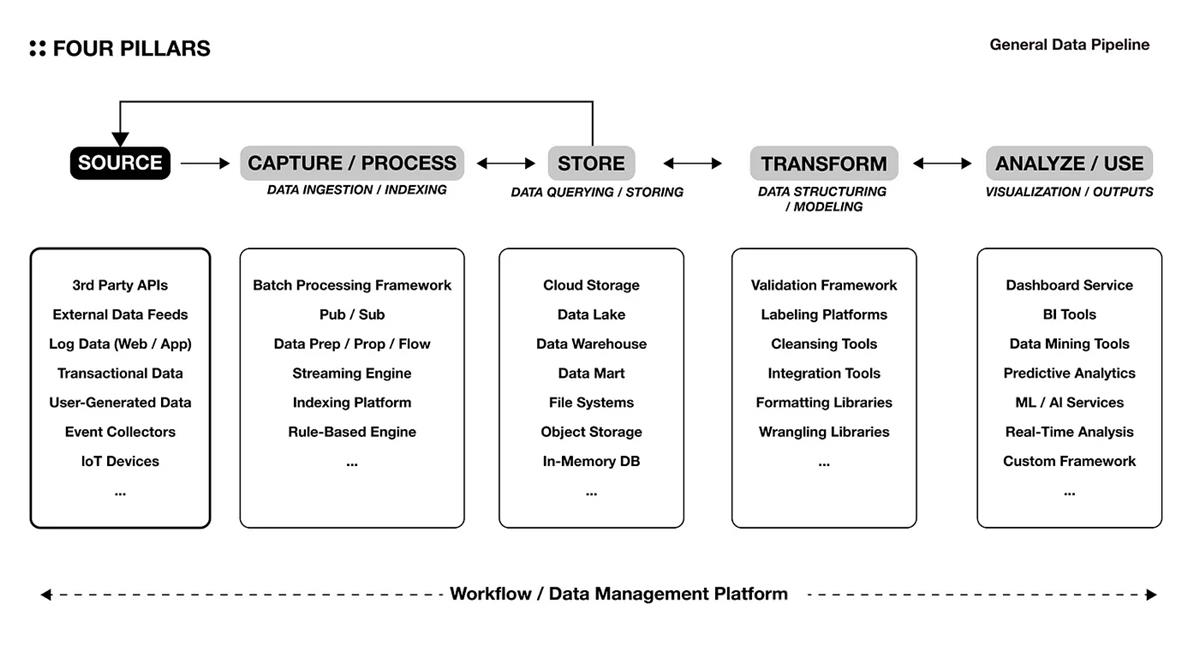
การสร้างไปป์ไลน์ข้อมูลเป็นเหมือนกระบวนการสร้างกรอบความคิดและทำให้กระบวนการตัดสินใจที่ซ้ำซากเป็นอัตโนมัติในชีวิตประจำวัน การทำเช่นนี้จะทำให้ข้อมูลที่มีคุณภาพเฉพาะเจาะจงพร้อมใช้งานและนำไปใช้ในการตัดสินใจได้ ยิ่งข้อมูลที่ไม่มีโครงสร้างต้องประมวลผลมากเท่าใด ข้อมูลก็ยิ่งถูกใช้บ่อยขึ้น หรือต้องมีการวิเคราะห์แบบเรียลไทม์มากขึ้นเท่านั้น เวลาและต้นทุนในการได้รับการดำเนินการเชิงรุกที่จำเป็นสำหรับการตัดสินใจในอนาคตสามารถบันทึกไว้ได้ด้วยการทำให้กระบวนการเหล่านี้เป็นอัตโนมัติ
แผนภาพด้านบนแสดงสถาปัตยกรรมทั่วไปสำหรับการสร้างช่องทางข้อมูลในตลาดโครงสร้างพื้นฐานด้านไอทีที่มีอยู่ ข้อมูลที่เหมาะสมสำหรับวัตถุประสงค์ในการวิเคราะห์จะถูกรวบรวมจากแหล่งข้อมูลที่ถูกต้องและจัดเก็บไว้ในโซลูชันการจัดเก็บข้อมูลที่เหมาะสมตามลักษณะของข้อมูลและข้อกำหนดในการวิเคราะห์ ตัวอย่างเช่น Data Lake มอบโซลูชันการจัดเก็บข้อมูลดิบสำหรับการวิเคราะห์ที่ปรับขนาดได้และยืดหยุ่น ในขณะที่คลังข้อมูลมุ่งเน้นไปที่การจัดเก็บข้อมูลที่มีโครงสร้างสำหรับการสืบค้นและการวิเคราะห์ที่ปรับให้เหมาะสมสำหรับตรรกะทางธุรกิจเฉพาะ จากนั้นข้อมูลจะถูกประมวลผลเป็นข้อมูลเชิงลึกหรือข้อมูลที่เป็นประโยชน์ในรูปแบบต่างๆ
โซลูชันแต่ละระดับยังมีให้บริการในรูปแบบแพ็คเกจอีกด้วย นอกจากนี้ยังมีความสนใจเพิ่มขึ้นในกลุ่มผลิตภัณฑ์ SaaS ของ ETL (แยก, แปลง, โหลด) ที่เชื่อมโยงห่วงโซ่กระบวนการตั้งแต่การแยกข้อมูลไปจนถึงการโหลด (เช่น FiveTran, Panoply, Hivo, Rivery) ลำดับไม่ได้เป็นแบบทิศทางเดียวเสมอไป และเลเยอร์ต่างๆ สามารถเชื่อมต่อถึงกันได้หลายวิธี ขึ้นอยู่กับความต้องการเฉพาะขององค์กร สิ่งที่สำคัญที่สุดในการสร้างไปป์ไลน์ข้อมูลคือการลดความเสี่ยงของการสูญเสียข้อมูลที่อาจเกิดขึ้นเมื่อมีการส่งและรับข้อมูลไปยังเซิร์ฟเวอร์แต่ละระดับ ซึ่งสามารถทำได้โดยการปรับการแยกเซิร์ฟเวอร์ให้เหมาะสม และใช้โซลูชันการจัดเก็บและประมวลผลข้อมูลที่เชื่อถือได้
4.2 ไปป์ไลน์พร้อมสภาพแวดล้อมออนไลน์
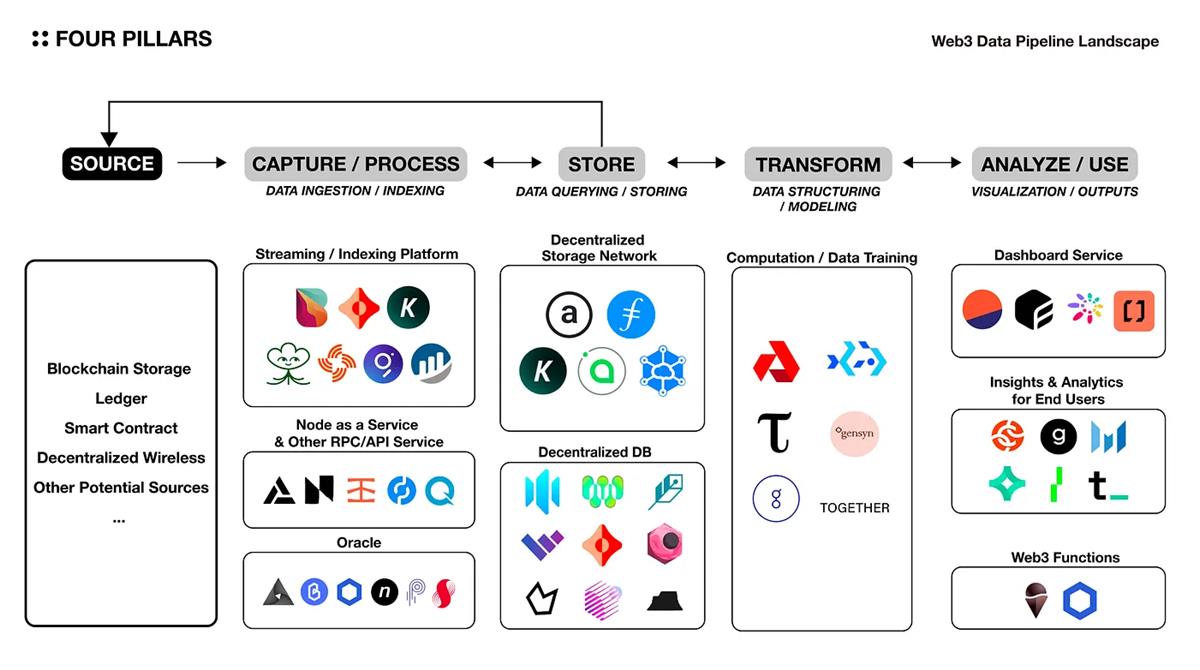
แผนภาพแนวคิดของไปป์ไลน์ข้อมูลที่นำมาใช้ก่อนหน้านี้สามารถนำไปใช้กับสภาพแวดล้อมออนไลน์ได้ ดังแสดงในรูปด้านบน แต่ควรสังเกตว่าไม่สามารถสร้างไปป์ไลน์แบบกระจายอำนาจโดยสมบูรณ์ได้ เนื่องจากองค์ประกอบพื้นฐานแต่ละส่วนขึ้นอยู่กับขอบเขตบางส่วน โซลูชันนอกเครือข่ายแบบรวมศูนย์ นอกจากนี้ ตัวเลขข้างต้นไม่ได้รวมโซลูชัน Web3 ทั้งหมดในปัจจุบัน และขอบเขตของการจัดประเภทอาจไม่ชัดเจน ตัวอย่างเช่น KYVE นอกเหนือจากการทำหน้าที่เป็นแพลตฟอร์มสื่อสตรีมมิ่งแล้ว ยังรวมถึงฟังก์ชันของ Data Lake ซึ่งสามารถ ถือเป็นไปป์ไลน์ข้อมูลนั่นเอง นอกจากนี้ Space and Time ยังจัดเป็นฐานข้อมูลแบบกระจายอำนาจ แต่มีบริการเกตเวย์ API เช่น RestAPI และการสตรีม รวมถึงบริการ ETL
4.2.1 การจับ/กระบวนการ
เพื่อให้ผู้ใช้ทั่วไปหรือ dApps ใช้งาน/ดำเนินการบริการได้อย่างมีประสิทธิภาพ พวกเขาจำเป็นต้องสามารถระบุและเข้าถึงแหล่งข้อมูลที่สร้างขึ้นภายในโปรโตคอลเป็นหลัก เช่น ธุรกรรม สถานะ และเหตุการณ์บันทึกได้อย่างง่ายดาย เลเยอร์นี้เป็นจุดที่มิดเดิลแวร์เข้ามามีบทบาท ซึ่งช่วยในกระบวนการต่างๆ รวมถึง oracles การส่งข้อความ การรับรองความถูกต้อง และการจัดการ API แนวทางแก้ไขหลักมีดังนี้
แพลตฟอร์มสตรีมมิ่ง / การจัดทำดัชนี
Bitquery, Ceramic, KYVE, Lens, Streamr Network, The Graph, block explorers ของโปรโตคอลต่างๆ ฯลฯ
Node-as-a-Service และบริการ RPC/API อื่นๆ
ออราเคิล
ออราเคิล
API 3, Band Protocol, Chainlink, Nest Protocol, Pyth, Supra oracles ฯลฯ
4.2.2 การจัดเก็บ
เมื่อเปรียบเทียบกับโซลูชันการจัดเก็บข้อมูล Web2 โซลูชันการจัดเก็บข้อมูล Web3 มีข้อดีหลายประการ เช่น ความคงอยู่และการกระจายอำนาจ อย่างไรก็ตาม ยังมีข้อเสียอยู่บ้าง เช่น ค่าใช้จ่ายสูง ความยากในการอัปเดตข้อมูลและการสืบค้น ด้วยเหตุนี้ จึงมีโซลูชั่นต่างๆ เกิดขึ้นเพื่อแก้ไขข้อบกพร่องเหล่านี้และช่วยให้สามารถประมวลผลข้อมูลที่มีโครงสร้างและไดนามิกได้อย่างมีประสิทธิภาพบน Web3 ซึ่งแต่ละข้อมูลมีลักษณะเฉพาะที่แตกต่างกัน เช่น ประเภทของข้อมูลที่ประมวลผล ไม่ว่าจะเป็นแบบมีโครงสร้างหรือไม่ และด้วยฟังก์ชันการสืบค้นแบบฝังหรือไม่ เป็นต้น บน.
เครือข่ายการจัดเก็บข้อมูลแบบกระจายอำนาจ
Arweave, Filecoin, KYVE, Sia, Storj ฯลฯ
ฐานข้อมูลแบบกระจายอำนาจ
ฐานข้อมูลที่ใช้ Arweave (Glacier, HollowDB, Kwil, WeaveDB), ComposeDB, OrbitDB, Polybase, Space and Time, Tableland ฯลฯ
* แต่ละโปรโตคอลมีกลไกการจัดเก็บข้อมูลถาวรที่แตกต่างกัน ตัวอย่างเช่น Arweave เป็นโมเดลที่ใช้บล็อกเชน ซึ่งคล้ายกับพื้นที่เก็บข้อมูล Ethereum โดยจัดเก็บข้อมูลแบบออนไลน์อย่างถาวร ในขณะที่ Filecoin, Sia และ Storj เป็นโมเดลตามสัญญา ซึ่งจัดเก็บข้อมูลแบบออฟไลน์
4.2.3 การแปลง
ในบริบทของ Web3 เลเยอร์การแปลมีความสำคัญเท่ากับเลเยอร์การจัดเก็บข้อมูล เนื่องจากโครงสร้างของบล็อกเชนโดยพื้นฐานแล้วประกอบด้วยคอลเลกชันโหนดแบบกระจาย ซึ่งทำให้ง่ายต่อการใช้ตรรกะแบ็กเอนด์ที่ปรับขนาดได้ ในอุตสาหกรรม AI ผู้คนต่างกระตือรือร้นที่จะสำรวจการใช้ข้อดีเหล่านี้เพื่อการวิจัยในด้านการเรียนรู้แบบสมาพันธ์ และโปรโตคอลสำหรับการเรียนรู้ของเครื่องและการทำงานของ AI ได้เกิดขึ้นโดยเฉพาะ
การฝึกอบรมข้อมูล/การสร้างแบบจำลอง/คอมพิวเตอร์
Akash, Bacalhau, Bittensor, Gensyn, Golem, ทูเกเตอร์ ฯลฯ
* การเรียนรู้แบบสหพันธรัฐเป็นวิธีการฝึกอบรมโมเดลปัญญาประดิษฐ์โดยการกระจายโมเดลดั้งเดิมบนไคลเอ็นต์เนทีฟหลายเครื่อง โดยใช้ข้อมูลที่เก็บไว้เพื่อฝึกโมเดล จากนั้นรวบรวมพารามิเตอร์ที่เรียนรู้บนเซิร์ฟเวอร์กลาง
4.2.4 การวิเคราะห์/การใช้งาน
บริการแดชบอร์ดและข้อมูลเชิงลึกของผู้ใช้ปลายทางและโซลูชันการวิเคราะห์ที่แสดงด้านล่างนี้เป็นแพลตฟอร์มที่อนุญาตให้ผู้ใช้สามารถสังเกตและค้นพบข้อมูลเชิงลึกต่างๆ จากโปรโตคอลเฉพาะ โซลูชันเหล่านี้บางส่วนยังให้บริการ API แก่ผลิตภัณฑ์ขั้นสุดท้ายด้วย อย่างไรก็ตาม สิ่งสำคัญที่ควรทราบก็คือข้อมูลในโซลูชันเหล่านี้อาจไม่แม่นยำเสมอไป เนื่องจากส่วนใหญ่จะใช้เครื่องมือนอกเครือข่ายแยกต่างหากเพื่อจัดเก็บและประมวลผลข้อมูล สามารถสังเกตข้อผิดพลาดระหว่างวิธีแก้ปัญหาได้
ในเวลาเดียวกัน มีแพลตฟอร์มที่เรียกว่า ฟังก์ชั่น Web3 ที่สามารถ/กระตุ้นการดำเนินการของสัญญาอัจฉริยะได้โดยอัตโนมัติ เช่นเดียวกับแพลตฟอร์มแบบรวมศูนย์ เช่น Google Cloud ทริกเกอร์/ดำเนินการตรรกะทางธุรกิจเฉพาะ การใช้แพลตฟอร์มนี้ ผู้ใช้สามารถใช้ตรรกะทางธุรกิจในลักษณะ Web3-native แทนที่จะประมวลผลข้อมูลออนไลน์เพื่อรับข้อมูลเชิงลึก
บริการแดชบอร์ด
Dune Analytics, Flipside Crypto, Footprint, Transpose ฯลฯ
ข้อมูลเชิงลึกและการวิเคราะห์ผู้ใช้ปลายทาง
Chainalaysis, Glassnode, Messari, Nansen, The Tie, Token Terminal ฯลฯ
Web3 Functions
ฟังก์ชั่นของ Chainlink, Gelato Network ฯลฯ
5. การสรุปความคิด
ดังที่คานท์กล่าวไว้ เราสามารถเห็นได้เพียงการปรากฏของสิ่งต่าง ๆ เท่านั้น แต่ไม่ใช่แก่นแท้ของมัน ถึงกระนั้น เราใช้บันทึกข้อสังเกตที่เรียกว่า ข้อมูล เพื่อประมวลผลข้อมูลและความรู้ และเราเห็นว่านวัตกรรมในเทคโนโลยีสารสนเทศขับเคลื่อนการพัฒนาของอารยธรรมอย่างไร ดังนั้น การสร้างไปป์ไลน์ข้อมูลในตลาด Web3 นอกเหนือจากการกระจายอำนาจแล้ว ยังมีบทบาทสำคัญในการเป็นจุดเริ่มต้นในการคว้าโอกาสเหล่านี้ได้อย่างแท้จริง ผมอยากจะสรุปบทความนี้ด้วยข้อคิดเล็กๆ น้อยๆ
5.1 บทบาทของโซลูชั่นการจัดเก็บข้อมูลจะมีความสำคัญมากขึ้น
ข้อกำหนดเบื้องต้นที่สำคัญที่สุดในการมีไปป์ไลน์ข้อมูลคือการสร้างข้อมูลและการกำกับดูแล API ในระบบนิเวศที่มีความหลากหลายมากขึ้น ข้อมูลจำเพาะที่สร้างขึ้นโดยแต่ละโปรโตคอลจะยังคงถูกสร้างขึ้นใหม่ และบันทึกธุรกรรมที่กระจัดกระจายผ่านระบบนิเวศแบบหลายสายโซ่จะทำให้บุคคลได้รับข้อมูลเชิงลึกที่ครอบคลุมได้ยากขึ้น จากนั้น โซลูชันการจัดเก็บข้อมูล คือเอนทิตีที่สามารถให้ข้อมูลที่บูรณาการในรูปแบบเดียวโดยการรวบรวมข้อมูลที่กระจัดกระจายและอัปเดตข้อกำหนดของแต่ละโปรโตคอล เราสังเกตว่าโซลูชันการจัดเก็บข้อมูลในตลาดที่มีอยู่ เช่น Snowflake และ Databricks กำลังเติบโตอย่างรวดเร็ว มีฐานลูกค้าขนาดใหญ่ ได้รับการบูรณาการในแนวดิ่งโดยการดำเนินงานในระดับต่างๆ ในไปป์ไลน์ และเป็นผู้นำของอุตสาหกรรม
5.2 โอกาสในตลาดแหล่งข้อมูล
กรณีการใช้งานที่ประสบความสำเร็จเริ่มเกิดขึ้นเมื่อข้อมูลเข้าถึงได้มากขึ้นและปรับปรุงการประมวลผล สิ่งนี้สร้างผลกระทบเชิงบวกแบบวงกลมเมื่อแหล่งข้อมูลและเครื่องมือรวบรวมระเบิด ตั้งแต่ปี 2010 ประเภทและปริมาณของข้อมูลดิจิทัลที่รวบรวมในแต่ละปีได้เติบโตขึ้นอย่างทวีคูณตั้งแต่ปี 2010 ด้วยความก้าวหน้าอย่างมากในเทคโนโลยีสำหรับการสร้างไปป์ไลน์ข้อมูล การใช้พื้นหลังนี้กับตลาด Web3 แหล่งข้อมูลจำนวนมากจะสามารถสร้างแบบออนไลน์แบบวนซ้ำได้ในอนาคต นี่ก็หมายความว่าบล็อคเชนจะขยายไปสู่สาขาธุรกิจต่างๆ ณ จุดนี้ เราคาดหวังได้ว่าการรับข้อมูลจะก้าวหน้าผ่านตลาดข้อมูล เช่น Ocean Protocol หรือโซลูชัน DeWi (ระบบไร้สายแบบกระจายอำนาจ) เช่น Helium และ XNET รวมถึงโซลูชันการจัดเก็บข้อมูล
5.3 สิ่งที่สำคัญคือข้อมูลและการวิเคราะห์ที่มีความหมาย
อย่างไรก็ตาม สิ่งที่สำคัญที่สุดคือการถามเรื่อยๆ ว่าควรเตรียมข้อมูลใดบ้างเพื่อดึงข้อมูลเชิงลึกที่จำเป็นจริงๆ ไม่มีอะไรจะสิ้นเปลืองไปกว่าการสร้างไปป์ไลน์ข้อมูลเพื่อสร้างไปป์ไลน์ข้อมูลโดยไม่มีสมมติฐานที่ชัดเจนในการตรวจสอบ ตลาดที่มีอยู่ประสบความสำเร็จในการสร้างสรรค์นวัตกรรมมากมายผ่านการสร้างไปป์ไลน์ข้อมูล แต่ยังต้องจ่ายราคานับไม่ถ้วนจากความล้มเหลวที่ไร้จุดหมายซ้ำแล้วซ้ำอีก นอกจากนี้ยังเป็นการดีที่จะมีการอภิปรายเชิงสร้างสรรค์เกี่ยวกับการพัฒนา Technology Stack แต่อุตสาหกรรมต้องใช้เวลาในการคิดและหารือเกี่ยวกับคำถามพื้นฐานเพิ่มเติม เช่น ข้อมูลใดที่ควรเก็บไว้ใน Block Space หรือวัตถุประสงค์ใดที่ข้อมูลควรใช้เพื่อ . เป้าหมาย ควรคือการตระหนักถึงคุณค่าของ Web3 ผ่านทางข่าวกรองที่นำไปปฏิบัติได้และกรณีการใช้งาน และในกระบวนการนี้ การพัฒนาองค์ประกอบพื้นฐานหลายอย่างและการดำเนินการไปป์ไลน์ให้เสร็จสมบูรณ์ถือเป็น วิธีการ เพื่อให้บรรลุเป้าหมายนี้


