
DAOrayaki: อนาคตของแอปพลิเคชัน AI ในระบบนิเวศ Web3
นับตั้งแต่เปิดตัว ChatGPT และ GPT-4 ก็มีการเขียนมากมายเกี่ยวกับวิธีที่ AI สามารถปฏิวัติทุกสิ่ง รวมถึง Web 3 นักพัฒนาในหลายอุตสาหกรรมรายงานการเพิ่มผลผลิตอย่างมีนัยสำคัญตั้งแต่ 50% ถึง 500% โดยใช้ประโยชน์จาก ChatGPT เป็นตัวขับเคลื่อนร่วมเพื่อทำงานอัตโนมัติ เช่น การสร้างรหัสสำเร็จรูป การทดสอบหน่วย การสร้างเอกสาร การดีบัก และการตรวจหาจุดบกพร่อง % แตกต่างกันไป แม้ว่าบทความนี้จะสำรวจว่า AI สามารถเปิดใช้งานกรณีการใช้งาน Web 3 ใหม่และน่าสนใจได้อย่างไร แต่จุดเน้นหลักอยู่ที่ความสัมพันธ์ที่เป็นประโยชน์ร่วมกันระหว่าง Web 3 และ AI มีเทคโนโลยีน้อยมากที่มีความสามารถในการมีอิทธิพลอย่างมากต่อทิศทางของปัญญาประดิษฐ์ และ Web 3 ก็เป็นหนึ่งในนั้น

Web3 อำนวยความสะดวกด้านปัญญาประดิษฐ์อย่างไร
แม้จะมีศักยภาพมหาศาล แต่โมเดล AI ในปัจจุบันต้องเผชิญกับความท้าทายหลายประการ เช่น ความเป็นส่วนตัวของข้อมูล ความเป็นธรรมในการดำเนินการของโมเดลที่เป็นกรรมสิทธิ์ และความสามารถในการสร้างและเผยแพร่เนื้อหาปลอมที่น่าเชื่อถือ เทคโนโลยี Web 3 ที่มีอยู่บางส่วนได้รับการจัดตำแหน่งเฉพาะเพื่อจัดการกับความท้าทายเหล่านี้
01 สร้างชุดข้อมูลที่เป็นกรรมสิทธิ์สำหรับการฝึกอบรมแมชชีนเลิร์นนิง (ML)
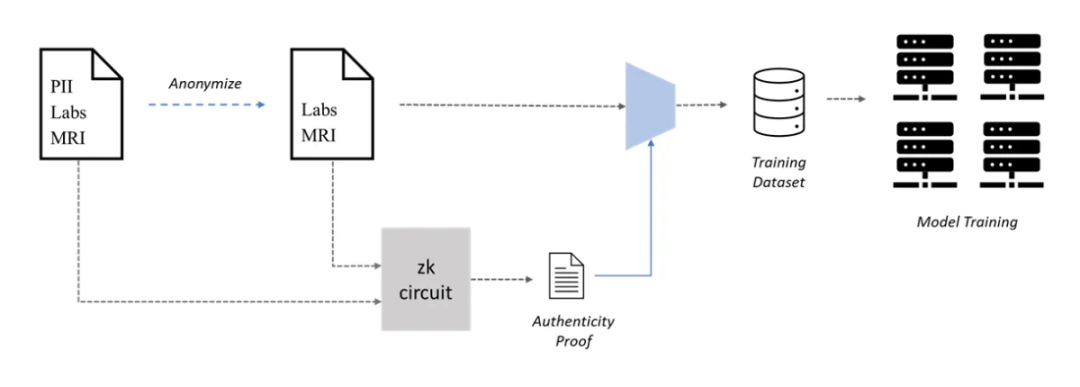
พื้นที่หนึ่งที่ Web 3 สามารถช่วย AI ได้คือการสร้างชุดข้อมูลที่เป็นกรรมสิทธิ์ร่วมกันสำหรับการฝึกอบรมแมชชีนเลิร์นนิง (ML) เช่น การใช้เครือข่าย PoPW สำหรับการสร้างชุดข้อมูล ชุดข้อมูลขนาดใหญ่มีความสำคัญต่อโมเดล ML ที่แม่นยำ แต่การสร้างอาจกลายเป็นปัญหาคอขวดในกรณีการใช้งานที่ต้องใช้ข้อมูลส่วนตัว เช่น การวินิจฉัยทางการแพทย์โดยใช้ ML การเข้าถึงเวชระเบียนเป็นสิ่งจำเป็นในการฝึกอบรมโมเดลเหล่านี้เนื่องจากข้อกังวลด้านความเป็นส่วนตัวของข้อมูลผู้ป่วย แต่ผู้ป่วยอาจลังเลที่จะแบ่งปันเวชระเบียนของตนเนื่องจากข้อกังวลด้านความเป็นส่วนตัว เพื่อแก้ไขปัญหานี้ ผู้ป่วยสามารถยืนยันตัวตนในเวชระเบียนของตนได้เพื่อรักษาความเป็นส่วนตัวในขณะที่ยังพร้อมสำหรับการฝึกอบรม ML
อย่างไรก็ตาม ความถูกต้องของเวชระเบียนที่ไม่ระบุตัวตนนั้นเป็นปัญหา เนื่องจากข้อมูลปลอมอาจส่งผลกระทบต่อประสิทธิภาพการทำงานของแบบจำลองอย่างร้ายแรง เพื่อแก้ไขปัญหานี้ สามารถใช้ Zero-knowledge Proofs (ZKP) เพื่อตรวจสอบความถูกต้องของเวชระเบียนที่ไม่ระบุชื่อได้ ผู้ป่วยสามารถสร้าง ZKP เพื่อพิสูจน์ว่าบันทึกที่ไม่ระบุตัวตนเป็นสำเนาของบันทึกต้นฉบับจริง ๆ แม้ว่าหลังจากลบข้อมูลส่วนบุคคล (PII) แล้วก็ตาม ด้วยวิธีนี้ ผู้ป่วยสามารถจัดทำบันทึกที่ไม่ระบุตัวตนด้วย ZKP แก่ผู้มีส่วนได้ส่วนเสีย และแม้แต่รับรางวัลสำหรับการบริจาคของพวกเขาโดยไม่สูญเสียความเป็นส่วนตัว
02 เรียกใช้การอนุมานข้อมูลส่วนตัว
จุดอ่อนที่สำคัญของ LLM ในปัจจุบันคือการจัดการข้อมูลส่วนตัว ตัวอย่างเช่น เมื่อผู้ใช้โต้ตอบกับ chatGPT OpenAI จะรวบรวมข้อมูลส่วนตัวของผู้ใช้และใช้สำหรับการฝึกอบรมแบบจำลอง ซึ่งจะนำไปสู่การเปิดเผยข้อมูลที่ละเอียดอ่อน นี่เป็นกรณีของซัมซุง เทคนิค Zero-knowledge (zk) สามารถช่วยแก้ปัญหาบางอย่างที่เกิดขึ้นเมื่อโมเดล ML ให้เหตุผลกับข้อมูลส่วนตัวได้ ในที่นี้ เราพิจารณาสองกรณี: โมเดลโอเพ่นซอร์สและโมเดลที่เป็นกรรมสิทธิ์
สำหรับโมเดลโอเพ่นซอร์ส ผู้ใช้สามารถดาวน์โหลดโมเดลในเครื่องบนข้อมูลส่วนตัวและเรียกใช้งานได้ ตัวอย่างเช่น Worldcoin วางแผนที่จะอัปเกรด World ID ในกรณีการใช้งานนี้ Worldcoin จำเป็นต้องประมวลผลข้อมูลไบโอเมตริกส่วนตัวของผู้ใช้ เช่น การสแกนม่านตาของผู้ใช้ เพื่อสร้างตัวระบุเฉพาะสำหรับผู้ใช้แต่ละคนที่เรียกว่า IrisCode ในกรณีนี้ ผู้ใช้สามารถเก็บข้อมูลไบโอเมตริกซ์เป็นส่วนตัวบนอุปกรณ์ ดาวน์โหลดโมเดล ML ที่ใช้สำหรับการสร้าง IrisCode รันการอนุมานในเครื่อง และสร้างหลักฐานว่าสร้าง IrisCode สำเร็จ หลักฐานที่สร้างขึ้นรับประกันความถูกต้องของเหตุผลในขณะที่รักษาความเป็นส่วนตัวของข้อมูล กลไกการพิสูจน์ zk ที่มีประสิทธิภาพสำหรับโมเดล ML เช่นเดียวกับที่พัฒนาโดย Modulus Labs เป็นสิ่งสำคัญสำหรับกรณีการใช้งานนี้
อีกกรณีหนึ่งคือเมื่อโมเดล ML ที่ใช้สำหรับการอนุมานเป็นกรรมสิทธิ์ งานนี้ค่อนข้างยาก เนื่องจากการอนุมานเฉพาะที่ไม่ใช่ตัวเลือก อย่างไรก็ตาม ZKP สามารถช่วยได้สองวิธี วิธีแรกคือการทำให้ข้อมูลผู้ใช้เป็นนิรนามโดยใช้ ZKP ตามที่กล่าวไว้ในตัวอย่างการสร้างชุดข้อมูลก่อนหน้า จากนั้นจึงส่งข้อมูลที่ไม่ระบุชื่อไปยังโมเดล ML อีกวิธีหนึ่งคือการใช้ขั้นตอนการประมวลผลล่วงหน้าในเครื่องกับข้อมูลส่วนตัวก่อนที่จะส่งเอาต์พุตที่ประมวลผลล่วงหน้าไปยังโมเดล ML ในกรณีนี้ ขั้นตอนการประมวลผลล่วงหน้าจะซ่อนข้อมูลส่วนตัวของผู้ใช้เพื่อไม่ให้สร้างใหม่ได้ ผู้ใช้สร้าง ZKP ที่ระบุการดำเนินการที่ถูกต้องของขั้นตอนก่อนการประมวลผล จากนั้นโมเดลที่เป็นกรรมสิทธิ์ส่วนที่เหลือสามารถดำเนินการได้จากระยะไกลบนเซิร์ฟเวอร์ของเจ้าของโมเดล ตัวอย่างกรณีการใช้งานในที่นี้อาจรวมถึงแพทย์ AI ที่สามารถวิเคราะห์เวชระเบียนของผู้ป่วยเพื่อการวินิจฉัยที่เป็นไปได้ และอัลกอริทึมการประเมินความเสี่ยงทางการเงินที่ประเมินข้อมูลทางการเงินส่วนตัวของลูกค้า
03 ความถูกต้องของเนื้อหาและการต่อสู้กับเทคโนโลยีของปลอม
chatGPT อาจขโมยความโดดเด่นจากโมเดล AI เจนเนอเรทีฟที่เน้นการสร้างภาพ เสียง และวิดีโอ อย่างไรก็ตาม ปัจจุบัน โมเดลเหล่านี้สามารถสร้าง Deepfake ที่เหมือนจริงได้ เพลงที่สร้างโดย AI ล่าสุดโดย Drake เป็นตัวอย่างของสิ่งที่โมเดลเหล่านี้สามารถทำได้ เนื่องจากมนุษย์ถูกตั้งโปรแกรมให้เชื่อในสิ่งที่พวกเขาเห็นและได้ยิน ของปลอมเหล่านี้จึงเป็นภัยคุกคามที่สำคัญ มีสตาร์ทอัพจำนวนมากที่พยายามแก้ปัญหานี้โดยใช้เทคโนโลยี Web 2 อย่างไรก็ตาม เทคโนโลยี Web 3 เช่น ลายเซ็นดิจิทัล เหมาะสมกว่าในการแก้ปัญหานี้
ใน Web 3 การโต้ตอบของผู้ใช้ เช่น ธุรกรรม จะถูกลงนามโดยคีย์ส่วนตัวของผู้ใช้เพื่อพิสูจน์ความถูกต้อง ในทำนองเดียวกัน ไม่ว่าจะเป็นข้อความ รูปภาพ เสียงหรือวิดีโอ เนื้อหายังสามารถลงนามโดยรหัสส่วนตัวของผู้สร้างเพื่อพิสูจน์ความถูกต้อง ทุกคนสามารถตรวจสอบลายเซ็นกับที่อยู่สาธารณะของผู้สร้างซึ่งมีให้บนเว็บไซต์ของผู้สร้างหรือบัญชีโซเชียลมีเดีย เครือข่าย Web 3 ได้สร้างโครงสร้างพื้นฐานที่จำเป็นทั้งหมดเพื่อเปิดใช้งานกรณีการใช้งานนี้ Fred Wilson อภิปรายว่าการเชื่อมโยงเนื้อหากับคีย์เข้ารหัสสาธารณะสามารถต่อสู้กับข้อมูลที่ผิดได้อย่างมีประสิทธิภาพได้อย่างไร บริษัทร่วมลงทุนที่มีชื่อเสียงหลายแห่งได้เชื่อมโยงโปรไฟล์โซเชียลมีเดียที่มีอยู่แล้ว เช่น Twitter หรือแพลตฟอร์มโซเชียลมีเดียแบบกระจายศูนย์ เช่น Lens Protocol และ Mirror กับที่อยู่สาธารณะที่เข้ารหัส ซึ่งให้ลายเซ็นดิจิทัลเป็นเนื้อหา ความน่าเชื่อถือของวิธีการพิสูจน์ตัวตนให้การสนับสนุน .
แม้จะมีความเรียบง่ายของแนวคิด แต่ก็ยังต้องการการทำงานอีกมากเพื่อปรับปรุงประสบการณ์ผู้ใช้ของกระบวนการตรวจสอบสิทธิ์นี้ ตัวอย่างเช่น ลายเซ็นดิจิทัลสำหรับการสร้างเนื้อหาจำเป็นต้องทำให้เป็นอัตโนมัติเพื่อให้ผู้สร้างใช้กระบวนการที่ราบรื่น ความท้าทายอีกประการหนึ่งคือวิธีสร้างชุดย่อยของข้อมูลที่มีการเซ็นชื่อ เช่น คลิปเสียงหรือวิดีโอ โดยไม่ต้องเซ็นซ้ำ เทคโนโลยี Web 3 ที่มีอยู่จำนวนมากอยู่ในตำแหน่งที่ไม่ซ้ำใครเพื่อแก้ไขปัญหาเหล่านี้
04 ลดความเชื่อถือในโมเดลที่เป็นกรรมสิทธิ์ให้เหลือน้อยที่สุด
พื้นที่อื่นที่ Web 3 สามารถช่วย AI ได้คือการลดความเชื่อถือในผู้ให้บริการให้เหลือน้อยที่สุด เมื่อมีการให้บริการโมเดลการเรียนรู้ของเครื่องที่เป็นกรรมสิทธิ์ ผู้ใช้อาจต้องยืนยันว่าบริการที่จ่ายไปนั้นมีให้จริง หรือเพื่อให้มั่นใจว่าโมเดลแมชชีนเลิร์นนิงทำงานอย่างยุติธรรม โดยผู้ใช้ทั้งหมดใช้โมเดลเดียวกัน สามารถใช้หลักฐานที่ไม่มีความรู้เป็นศูนย์เพื่อรับประกันดังกล่าวได้ ในสถาปัตยกรรมนี้ ผู้สร้างโมเดลแมชชีนเลิร์นนิงจะสร้างวงจรที่ไม่มีความรู้ซึ่งเป็นตัวแทนของโมเดล เมื่อจำเป็น วงจรนี้จะใช้เพื่อสร้างการพิสูจน์ที่ไม่มีความรู้สำหรับการอนุมานของผู้ใช้ สามารถส่งหลักฐานที่ไม่มีความรู้เป็นศูนย์ไปยังผู้ใช้เพื่อตรวจสอบ หรือสามารถเผยแพร่บนเครือข่ายสาธารณะที่จัดการงานตรวจสอบผู้ใช้ หากโมเดลแมชชีนเลิร์นนิงเป็นแบบส่วนตัว บุคคลที่สามอิสระสามารถตรวจสอบได้ว่าวงจร zk ที่ใช้เป็นตัวแทนของโมเดล แง่มุมของการลดความน่าเชื่อถือของโมเดลแมชชีนเลิร์นนิงจะมีประโยชน์อย่างยิ่งเมื่อผลการปฏิบัติงานของโมเดลมีความเสี่ยงสูง ตัวอย่างเช่น:
โมเดลการเรียนรู้ของเครื่องสำหรับการวินิจฉัยทางการแพทย์
ในกรณีการใช้งานนี้ ผู้ป่วยจะส่งข้อมูลทางการแพทย์ของตนสำหรับโมเดลแมชชีนเลิร์นนิงเพื่อทำการวินิจฉัยที่เป็นไปได้ ผู้ป่วยต้องแน่ใจว่าโมเดลแมชชีนเลิร์นนิงเป้าหมายถูกนำไปใช้กับข้อมูลของตนอย่างถูกต้อง กระบวนการอนุมานสร้างการพิสูจน์ความรู้เป็นศูนย์ซึ่งพิสูจน์ว่าโมเดลแมชชีนเลิร์นนิงทำงานได้อย่างถูกต้อง
การประเมินมูลค่าสินเชื่อของสินเชื่อ
หลักฐานที่ไม่มีความรู้สามารถรับประกันได้ว่าธนาคารและสถาบันการเงินจะพิจารณาข้อมูลทางการเงินทั้งหมดที่ผู้สมัครส่งมาเมื่อทำการประเมินความน่าเชื่อถือทางเครดิต นอกจากนี้ การพิสูจน์ด้วยความรู้ที่ไม่มีความรู้สามารถพิสูจน์ความยุติธรรมได้ กล่าวคือ พิสูจน์ว่าผู้ใช้ทั้งหมดใช้โมเดลเดียวกัน
การดำเนินการเรียกร้องค่าสินไหมทดแทน
การประมวลผลการเรียกร้องค่าสินไหมทดแทนในปัจจุบันเป็นแบบแมนนวลและอัตนัย โมเดลแมชชีนเลิร์นนิงสามารถประเมินการอ้างสิทธิ์ในกรมธรรม์และรายละเอียดการเรียกร้องได้อย่างเป็นกลางมากขึ้น เมื่อรวมกับการพิสูจน์ความรู้ที่ไม่มีความรู้แล้ว โมเดลแมชชีนเลิร์นนิงการประมวลผลการเรียกร้องเหล่านี้สามารถพิสูจน์ได้ว่ามีการพิจารณานโยบายและรายละเอียดการเรียกร้องทั้งหมด และการเรียกร้องทั้งหมดภายใต้นโยบายการประกันเดียวกันได้รับการประมวลผลโดยใช้แบบจำลองเดียวกัน
05 แก้ปัญหาการรวมศูนย์ของการสร้างโมเดล
การสร้างและการฝึกอบรม LLM เป็นกระบวนการที่ใช้เวลานานและมีค่าใช้จ่ายสูง ซึ่งต้องใช้ความเชี่ยวชาญเฉพาะด้าน โครงสร้างพื้นฐานด้านคอมพิวเตอร์โดยเฉพาะ และค่าใช้จ่ายในการคำนวณหลายล้านดอลลาร์ คุณลักษณะเหล่านี้อาจนำไปสู่หน่วยงานกลางที่ทรงพลัง (เช่น OpenAI) ที่สามารถมีอิทธิพลอย่างมากต่อผู้ใช้โดยการจำกัดการเข้าถึงโมเดลของตน
เมื่อพิจารณาถึงความเสี่ยงของการรวมศูนย์เหล่านี้ การอภิปรายที่สำคัญจึงเกิดขึ้นเกี่ยวกับวิธีที่ Web 3 สามารถอำนวยความสะดวกในการกระจายอำนาจในแง่มุมต่างๆ ของ LLM ผู้เสนอ Web 3 บางรายได้เสนอการประมวลผลแบบกระจายอำนาจเพื่อเป็นวิธีการแข่งขันกับผู้เล่นแบบรวมศูนย์ แนวคิดพื้นฐานคือการประมวลผลแบบกระจายอำนาจอาจเป็นทางเลือกที่ถูกกว่า อย่างไรก็ตาม เราเชื่อว่านี่อาจไม่ใช่มุมที่ดีที่สุดในการแข่งขันกับผู้เล่นที่รวมศูนย์ ข้อเสียของการประมวลผลแบบกระจายอำนาจคือสามารถทำงานช้าลง 10-100 เท่าในการฝึกอบรม ML เนื่องจากค่าใช้จ่ายในการสื่อสารระหว่างอุปกรณ์คอมพิวเตอร์ที่แตกต่างกัน
โครงการ Web 3 สามารถมุ่งเน้นไปที่การสร้างแบบจำลอง ML ที่ไม่เหมือนใครและแข่งขันได้ในรูปแบบ PoPW เครือข่าย PoPW เหล่านี้ยังสามารถรวบรวมข้อมูลเพื่อสร้างชุดข้อมูลเฉพาะเพื่อฝึกโมเดลเหล่านี้ บางโครงการที่กำลังดำเนินไปในทิศทางนี้ ได้แก่ Together และ Bittensor
06 ช่องทางการชำระเงินและการดำเนินการสำหรับตัวแทน AI
ในช่วงไม่กี่สัปดาห์ที่ผ่านมา ตัวแทน AI ที่ใช้ LLM เพื่อให้เหตุผลเกี่ยวกับงานที่จำเป็นเพื่อให้บรรลุเป้าหมายและดำเนินงานเหล่านั้นเพื่อให้บรรลุเป้าหมายนั้นมีจำนวนเพิ่มมากขึ้น คลื่นของตัวแทน AI เริ่มต้นจากแนวคิดของ BabyAGI และแพร่กระจายอย่างรวดเร็วไปยังเวอร์ชันขั้นสูง รวมถึง AutoGPT คำทำนายที่สำคัญที่นี่คือตัวแทน AI จะมีความเชี่ยวชาญมากขึ้นเพื่อทำงานบางอย่างให้เก่งขึ้น หากมีตลาดสำหรับตัวแทน AI โดยเฉพาะ ตัวแทน AI จะสามารถค้นหา จ้าง และจ่ายเงินให้ตัวแทน AI คนอื่นเพื่อทำงานเฉพาะ ซึ่งนำไปสู่ความสำเร็จของโครงการหลัก ระหว่างทาง เครือข่าย Web 3 ให้สภาพแวดล้อมที่เหมาะสำหรับตัวแทน AI สำหรับการชำระเงิน ตัวแทน AI สามารถติดตั้งกระเป๋าเงินดิจิทัลเพื่อรับการชำระเงินและชำระเงินตัวแทน AI อื่น ๆ นอกจากนี้ ตัวแทน AI ยังสามารถเชื่อมต่อกับเครือข่ายที่เข้ารหัสเพื่อมอบหมายทรัพยากรโดยไม่ได้รับอนุญาต ตัวอย่างเช่น หากตัวแทน AI ต้องการจัดเก็บข้อมูล ตัวแทน AI สามารถสร้างกระเป๋าเงิน Filecoin และชำระค่าจัดเก็บแบบกระจายอำนาจบน IPFS เอเจนต์ AI ยังสามารถมอบหมายทรัพยากรการประมวลผลจากเครือข่ายคอมพิวเตอร์แบบกระจายอำนาจ เช่น Akash เพื่อดำเนินการบางอย่าง หรือแม้แต่ขยายการดำเนินการของตัวเอง
07 การป้องกันการละเมิดความเป็นส่วนตัวของ AI
เนื่องจากต้องใช้ข้อมูลจำนวนมากในการฝึกโมเดล ML ที่มีประสิทธิภาพ จึงปลอดภัยที่จะสันนิษฐานว่าข้อมูลสาธารณะใดๆ จะถูกใช้ในโมเดล ML เพื่อทำนายพฤติกรรมของแต่ละคน นอกจากนี้ ธนาคารและสถาบันทางการเงินสามารถสร้างโมเดล ML ของตนเองที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลทางการเงินของผู้ใช้ และสามารถคาดการณ์พฤติกรรมทางการเงินในอนาคตของผู้ใช้ได้ นี่อาจเป็นการบุกรุกความเป็นส่วนตัวครั้งใหญ่ การบรรเทาภัยคุกคามนี้เพียงอย่างเดียวคือความเป็นส่วนตัวของธุรกรรมทางการเงินตามค่าเริ่มต้น ความเป็นส่วนตัวนี้สามารถทำได้โดยใช้บล็อกเชนการชำระเงินส่วนตัว เช่น การชำระเงิน zCash หรือ Aztec และโปรโตคอล DeFi ส่วนตัว เช่น Penumbra และ Aleo
เคสแอปพลิเคชัน Web3 ที่ขับเคลื่อนด้วย AI
01 เกมออนไลน์
สร้างบอทสำหรับผู้เล่นที่ไม่ใช่โปรแกรมเมอร์
เกมออนไลน์อย่าง Dark Forest สร้างกระบวนทัศน์ที่ไม่เหมือนใครซึ่งผู้เล่นจะได้รับประโยชน์จากการพัฒนาและปรับใช้บอทที่ทำหน้าที่ในเกมที่ต้องการ การเปลี่ยนแปลงกระบวนทัศน์นี้อาจยกเว้นผู้เล่นที่ไม่สามารถเขียนโค้ดได้ อย่างไรก็ตาม LLM สามารถเปลี่ยนแปลงสิ่งนี้ได้ LLM สามารถปรับแต่งอย่างละเอียดเพื่อทำความเข้าใจตรรกะของเกมบนเครือข่ายและอนุญาตให้ผู้เล่นสร้างบอทที่สะท้อนถึงกลยุทธ์ของผู้เล่นโดยไม่ต้องให้ผู้เล่นเขียนโค้ดใดๆ โครงการอย่าง Primodium และ AI Arena กำลังทำงานเพื่อดึงดูด AI และผู้เล่นที่เป็นมนุษย์สำหรับเกมของพวกเขา
การต่อสู้ของหุ่นยนต์ การพนันและการเดิมพัน
ความเป็นไปได้อีกอย่างสำหรับการเล่นเกมออนไลน์คือผู้เล่น AI ที่เป็นอิสระอย่างเต็มที่ ในกรณีนี้ ผู้เล่นเป็นตัวแทน AI เช่น AutoGPT ที่ใช้ LLM เป็นแบ็กเอนด์และสามารถเข้าถึงทรัพยากรภายนอก เช่น การเข้าถึงอินเทอร์เน็ตและเงินทุนเริ่มต้นของสกุลเงินดิจิทัลที่อาจเกิดขึ้น ผู้เล่น AI เหล่านี้สามารถเดิมพันได้เหมือนสงครามหุ่นยนต์ สิ่งนี้สามารถเปิดตลาดสำหรับการเก็งกำไรและการเดิมพันผลลัพธ์ของการเดิมพันเหล่านี้
สร้างสภาพแวดล้อม NPC ที่สมจริงสำหรับเกมออนไลน์
เกมในปัจจุบันให้ความสนใจกับตัวละครที่ไม่ใช่ผู้เล่น (NPC) เพียงเล็กน้อย NPC มีการกระทำที่จำกัดและมีผลกระทบต่อความคืบหน้าของเกมเพียงเล็กน้อย จากการทำงานร่วมกันของ AI และ Web3 จึงเป็นไปได้ที่จะสร้าง NPC ที่ควบคุมโดย AI ที่มีส่วนร่วมมากขึ้น ซึ่งสามารถทำลายความสามารถในการคาดเดาและทำให้เกมน่าสนใจยิ่งขึ้น ความท้าทายพื้นฐานที่นี่คือวิธีแนะนำไดนามิกของ NPC ที่มีความหมายในขณะที่ลดปริมาณงาน (TPS) ที่เกี่ยวข้องกับกิจกรรมเหล่านี้ให้เหลือน้อยที่สุด ข้อกำหนด TPS ที่จำเป็นสำหรับกิจกรรม NPC ที่มากเกินไปอาจนำไปสู่ความแออัดของเครือข่าย สร้างประสบการณ์การใช้งานที่ไม่ดีสำหรับผู้เล่นจริง
02 โซเชียลมีเดียแบบกระจายอำนาจ
หนึ่งในความท้าทายในปัจจุบันที่แพลตฟอร์มโซเชียลแบบกระจายอำนาจ (DeSo) เผชิญอยู่ในปัจจุบันก็คือ แพลตฟอร์มเหล่านี้ไม่ได้นำเสนอประสบการณ์ผู้ใช้ที่ไม่เหมือนใครเมื่อเทียบกับแพลตฟอร์มแบบรวมศูนย์ที่มีอยู่ การผสานรวมอย่างไร้รอยต่อกับ AI สามารถมอบประสบการณ์ที่ไม่เหมือนใครซึ่งทางเลือกของ Web2 ยังขาดอยู่ ตัวอย่างเช่น บัญชีที่จัดการโดย AI สามารถช่วยดึงดูดผู้ใช้ใหม่เข้าสู่เครือข่ายได้โดยการแบ่งปันเนื้อหาที่เกี่ยวข้อง แสดงความคิดเห็นในโพสต์ และเข้าร่วมในการสนทนา บัญชี AI ยังสามารถใช้สำหรับการรวมข่าว สรุปแนวโน้มล่าสุดที่ตรงกับความสนใจของผู้ใช้ [ 18 ]
03 การทดสอบความปลอดภัยและการออกแบบทางเศรษฐกิจของโปรโตคอลแบบกระจายอำนาจ
แนวโน้มไปสู่เอเจนต์ AI ที่ใช้ LLM ซึ่งสามารถกำหนดเป้าหมาย สร้างโค้ด และรันโค้ดสร้างโอกาสในการทดสอบความปลอดภัยและความมั่นคงทางเศรษฐกิจของเครือข่ายแบบกระจายอำนาจ ในกรณีนี้ ตัวแทน AI ได้รับคำสั่งให้ใช้ประโยชน์จากความปลอดภัยหรือความสมดุลทางเศรษฐกิจของโปรโตคอล ตัวแทน AI สามารถตรวจสอบเอกสารโปรโตคอลและสัญญาอัจฉริยะก่อน โดยระบุจุดอ่อน จากนั้นตัวแทน AI จะสามารถแข่งขันกันได้อย่างอิสระสำหรับกลไกการบังคับใช้เพื่อโจมตีโปรโตคอลเพื่อเพิ่มผลประโยชน์สูงสุดของตนเอง วิธีการนี้จำลองสภาพแวดล้อมจริงที่โปรโตคอลประสบหลังจากเริ่มทำงาน จากผลการทดสอบเหล่านี้ ผู้ออกแบบโปรโตคอลสามารถตรวจสอบการออกแบบโปรโตคอลและแพตช์จุดอ่อนได้ จนถึงปัจจุบัน เฉพาะบริษัทที่มีความเชี่ยวชาญ เช่น Gauntlet เท่านั้นที่มีทักษะทางเทคนิคที่จำเป็นในการให้บริการดังกล่าวสำหรับโปรโตคอลแบบกระจายอำนาจ อย่างไรก็ตาม เราคาดว่า LLM ที่ได้รับการฝึกอบรมเกี่ยวกับกลไก Solidity, DeFi และกลไกที่พัฒนาก่อนหน้านี้จะสามารถให้ความสามารถที่คล้ายคลึงกันได้
04 LLM สำหรับการจัดทำดัชนีข้อมูลและการแยกตัวบ่งชี้
แม้ว่าข้อมูลบล็อกเชนจะเป็นข้อมูลสาธารณะ แต่การจัดทำดัชนีข้อมูลนั้นและการดึงข้อมูลเชิงลึกที่เป็นประโยชน์ถือเป็นความท้าทายอย่างต่อเนื่อง ผู้เล่นบางรายในพื้นที่นี้ (เช่น CoinMetrics) เชี่ยวชาญในการจัดทำดัชนีข้อมูลและสร้างเมตริกที่ซับซ้อนเพื่อขาย ในขณะที่รายอื่น ๆ (เช่น Dune) มุ่งเน้นที่การจัดทำดัชนีองค์ประกอบหลักของธุรกรรมดิบและส่วนการแยกเมตริกแบบ crowdsourcing ผ่านการสนับสนุนของชุมชน ความก้าวหน้าของ LLM ล่าสุดแสดงให้เห็นว่าการจัดทำดัชนีข้อมูลและการดึงเมตริกอาจถูกบุกรุกได้ Dune ตระหนักถึงภัยคุกคามนี้และประกาศแผนงาน LLM ที่มีการตีความคิวรี SQL และศักยภาพสำหรับเคียวรีที่ใช้ NLP อย่างไรก็ตาม เราคาดการณ์ว่าผลกระทบของ LLM จะลงลึกกว่านี้ ความเป็นไปได้อย่างหนึ่งที่นี่คือการจัดทำดัชนีตาม LLM โดยที่โมเดล LLM โต้ตอบโดยตรงกับโหนดบล็อกเชนเพื่อจัดทำดัชนีข้อมูลสำหรับเมตริกเฉพาะ สตาร์ทอัพอย่าง Dune Ninja กำลังสำรวจแอปพลิเคชัน LLM ที่เป็นนวัตกรรมใหม่สำหรับการจัดทำดัชนีข้อมูล
05 แนะนำนักพัฒนาระบบนิเวศรายใหม่
บล็อกเชนต่างๆ แข่งขันกันเพื่อดึงดูดนักพัฒนาให้สร้างแอปพลิเคชันในระบบนิเวศนี้ กิจกรรมของนักพัฒนา Web 3 เป็นตัวบ่งชี้ที่สำคัญของความสำเร็จของระบบนิเวศ ปัญหาหลักที่นักพัฒนาเผชิญคือการได้รับการสนับสนุนเมื่อพวกเขาเริ่มเรียนรู้และสร้างระบบนิเวศใหม่ ระบบนิเวศได้ลงทุนหลายล้านดอลลาร์เพื่อสนับสนุนนักพัฒนาในการสำรวจระบบนิเวศในรูปแบบของทีมนักพัฒนาสัมพันธ์โดยเฉพาะ ในแง่นี้ LLM ที่เกิดใหม่ได้แสดงผลลัพธ์ที่น่าประทับใจ อธิบายโค้ดที่ซับซ้อน จับข้อผิดพลาด และแม้กระทั่งสร้างเอกสารประกอบ LLM ที่ดัดแปลงแล้วสามารถเสริมประสบการณ์ของมนุษย์ ขยายประสิทธิภาพการทำงานของทีมนักพัฒนาสัมพันธ์อย่างมีนัยสำคัญ ตัวอย่างเช่น สามารถใช้ LLM เพื่อสร้างเอกสารประกอบ บทช่วยสอน ตอบคำถามที่พบบ่อย และแม้แต่สนับสนุนนักพัฒนาแฮ็กกาธอนด้วยโค้ดเทมเพลตหรือสร้างการทดสอบหน่วย
06 ปรับปรุงโปรโตคอล DeFi
ด้วยการรวมปัญญาประดิษฐ์เข้ากับลอจิกของโปรโตคอล DeFi ประสิทธิภาพของโปรโตคอล DeFi จำนวนมากสามารถปรับปรุงได้อย่างมาก จนถึงวันนี้ ปัญหาคอขวดหลักในการผสานรวม AI เข้ากับ DeFi คือต้นทุนที่ห้ามปรามในการปรับใช้ AI บนเครือข่าย สามารถนำโมเดล AI ไปใช้งานนอกเครือข่ายได้ แต่ก่อนหน้านี้ไม่มีวิธีตรวจสอบการดำเนินการโมเดล อย่างไรก็ตาม การตรวจสอบความถูกต้องที่ดำเนินการนอกเครือข่ายเป็นไปได้ผ่านโครงการต่างๆ เช่น Modulus และ ChainML โปรเจ็กต์เหล่านี้อนุญาตให้ดำเนินการโมเดล ML แบบออฟไลน์ในขณะที่จำกัดค่าใช้จ่ายแบบออนเชน ในกรณีของโมดูลัส ค่าธรรมเนียมออนไลน์จะจำกัดอยู่ที่การตรวจสอบ ZKP ของโมเดลเท่านั้น ในกรณีของ ChainML ค่าใช้จ่ายบนเครือข่ายคือค่าธรรมเนียมของออราเคิลที่จ่ายให้กับเครือข่ายการดำเนินการ AI แบบกระจายอำนาจ
กรณีการใช้งาน DeFi บางกรณีที่อาจได้ประโยชน์จากการผสานรวม AI
การจัดหาสภาพคล่องของ AMM นั่นคือเพื่ออัปเดตช่วงของสภาพคล่อง Uniswap V3
การป้องกันการชำระบัญชีสำหรับตำแหน่งหนี้โดยใช้การป้องกันข้อมูลแบบออนไลน์และแบบออฟไลน์
ผลิตภัณฑ์ที่มีโครงสร้างซับซ้อนของ DeFi ซึ่งกลไกห้องนิรภัยถูกกำหนดโดยโมเดล AI ทางการเงิน แทนที่จะเป็นกลยุทธ์ตายตัว กลยุทธ์เหล่านี้อาจรวมถึงการซื้อขายที่จัดการโดย AI การให้กู้ยืมหรือออปชั่น
สรุปแล้ว
สรุปแล้ว
เราเชื่อว่า Web3 และ AI มีความเข้ากันได้ทางวัฒนธรรมและเทคโนโลยี ซึ่งแตกต่างจาก Web2 ซึ่งมีแนวโน้มที่จะขับไล่บอท Web3 ช่วยให้ AI เติบโตได้เนื่องจากความสามารถในการตั้งโปรแกรมที่ไม่ได้รับอนุญาต กว้างกว่านั้น หากคุณคิดว่าบล็อกเชนเป็นเครือข่าย เราคาดว่า AI จะครองส่วนขอบของเครือข่าย สิ่งนี้ใช้กับแอปพลิเคชันผู้บริโภคที่หลากหลาย ตั้งแต่โซเชียลมีเดียไปจนถึงเกม จนถึงตอนนี้ ขอบของเครือข่าย Web 3 นั้นเป็นของมนุษย์เป็นส่วนใหญ่ มนุษย์เริ่มต้นและลงนามข้อตกลงหรือใช้บอทด้วยกลยุทธ์ที่ตายตัว เมื่อเวลาผ่านไป เราจะเห็นตัวแทน AI ที่ส่วนขอบของเครือข่ายมากขึ้นเรื่อยๆ ตัวแทน AI จะโต้ตอบกับมนุษย์และกันและกันผ่านสัญญาอัจฉริยะ การโต้ตอบเหล่านี้จะช่วยให้ผู้บริโภคได้รับประสบการณ์ใหม่ๆ


