
กลุ่มอำพัน: การตีความที่ครอบคลุมของการพิสูจน์ที่ไม่มีความรู้
ที่มา: แอมเบอร์ กรุ๊ป

ที่มา: แอมเบอร์ กรุ๊ป
1. บทนำ
การพิสูจน์ด้วยความรู้เป็นศูนย์ช่วยให้ฝ่ายหนึ่งสามารถพิสูจน์ความถูกต้องกับอีกฝ่ายได้โดยไม่ต้องเปิดเผยข้อมูลเพิ่มเติมใดๆ ดังนั้นจึงสามารถใช้เพื่อปกป้องความเป็นส่วนตัวและตรวจสอบความถูกต้องของการทำธุรกรรมในขณะที่ซ่อนรายละเอียดทั้งหมด สิ่งสำคัญคือโปรโตคอลที่ไม่มีความรู้บางอย่างจะสะดวกสำหรับการตรวจสอบหลักฐานที่ไม่มีความรู้ เช่น STARK และ SNARK โปรโตคอลเหล่านี้สร้างการพิสูจน์ที่น้อยลง และการตรวจสอบการพิสูจน์ดังกล่าวทำได้เร็วกว่ามาก สิ่งนี้เหมาะสมอย่างยิ่งสำหรับบล็อกเชนที่มีทรัพยากรจำกัด และมีความสำคัญอย่างยิ่งในการแก้ไขปัญหาความสามารถในการขยายขนาดในอุตสาหกรรมคริปโต นอกเหนือจากนี้ กรณีการใช้งานอื่น ๆ ของเทคโนโลยีที่ไม่มีความรู้รวมถึง:
DID (Decentralized ID) - เพื่อพิสูจน์ว่าบัญชีหรือนิติบุคคลมีบางอย่าง"คุณสมบัติ"คุณสมบัติ
เช่น Sismo, First Batch
การกำกับดูแลชุมชน - สำหรับการลงคะแนนโดยไม่ระบุชื่อ และกรณีการใช้งานนี้สามารถขยายไปสู่การกำกับดูแลในโลกแห่งความจริงได้หลังจากได้รับการพิสูจน์และนำไปใช้อย่างกว้างขวาง
งบการเงิน – หน่วยงานสามารถแสดงให้เห็นถึงการปฏิบัติตามเกณฑ์ที่กำหนดโดยไม่ต้องเปิดเผยตัวเลขทางการเงินที่แน่นอน
……
ความสมบูรณ์ของบริการคลาวด์ - ช่วยให้ผู้ให้บริการคลาวด์ปฏิบัติภารกิจได้ดียิ่งขึ้น
ระบบความรู้ทั่วไปเป็นศูนย์
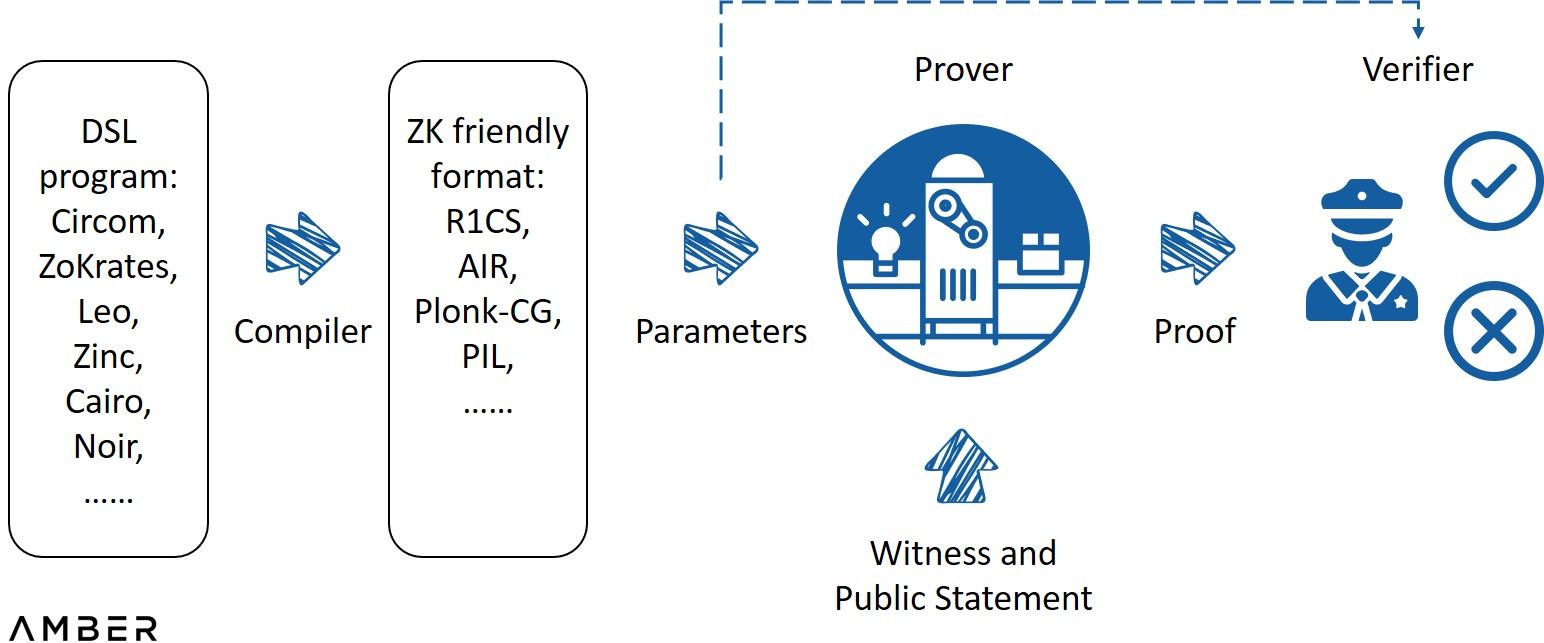
คำอธิบายภาพ
ที่มา: ZK Whiteboard Sessions - Module One เขียนโดย Prof. Dan Boneh
มีการเปิดตัวระบบพิสูจน์ที่ยอดเยี่ยมหลายตัว เช่น Marlin, Plonky2, Halo2 เป็นต้น ระบบการพิสูจน์ที่แตกต่างกันมีการเน้นย้ำในลักษณะต่างๆ กัน เช่น ขนาดของหลักฐานที่สร้างขึ้น เวลาที่ต้องใช้ในการตรวจสอบ และการตั้งค่าที่เชื่อถือได้นั้นจำเป็นหรือไม่ หลังจากการสำรวจเป็นเวลาหลายปี เป็นไปได้ที่จะบรรลุขนาดการพิสูจน์คงที่ (หลายร้อยไบต์) และเวลาการตรวจสอบสั้น (มิลลิวินาที) ไม่ว่าคำสั่งจะซับซ้อนเพียงใด
อย่างไรก็ตาม ความซับซ้อนของการสร้างการพิสูจน์มาตราส่วนเกือบจะเป็นเส้นตรงกับขนาดของลูปเลขคณิต ดังนั้นความยากอาจเป็นร้อยเท่าของงานดั้งเดิม เนื่องจากอย่างน้อยผู้พิสูจน์จำเป็นต้องอ่านและประเมินการวนซ้ำ จึงอาจใช้เวลาตั้งแต่วินาทีไปจนถึงนาทีหรือแม้แต่ชั่วโมง ต้นทุนการประมวลผลที่สูงและเวลาในการพิสูจน์ที่ยาวนานเป็นอุปสรรคสำคัญต่อความก้าวหน้าและการประยุกต์ใช้เทคโนโลยีที่ไม่มีความรู้ในวงกว้าง
การเร่งฮาร์ดแวร์สามารถช่วยแก้ปัญหาคอขวดได้ อัลกอริทึมหรือการเพิ่มประสิทธิภาพซอฟต์แวร์ใช้เพื่อกระจายงานหลายอย่างไปยังฮาร์ดแวร์ที่เหมาะสมที่สุด ซึ่งเสริมซึ่งกันและกัน
รายงานนี้มีจุดมุ่งหมายเพื่อช่วยให้ผู้อ่านเข้าใจภาพรวมของตลาด ผลกระทบของเทคโนโลยีที่ไม่มีความรู้ในตลาดการขุด และโอกาสที่เป็นไปได้ รายงานประกอบด้วยสามส่วน:
บทส่งท้าย
บทส่งท้าย
ชื่อระดับแรก
2. กรณีการใช้งาน
การแจกแจงกรณีการใช้ความรู้เป็นศูนย์จะช่วยแสดงให้เห็นว่าตลาดมีการพัฒนาอย่างไร เนื่องจากหมวดหมู่ที่แตกต่างกันมีความต้องการที่แตกต่างกัน การจัดหาฮาร์ดแวร์จึงมีความเกี่ยวข้องด้วย ในตอนท้ายของส่วนนี้ เราจะเปรียบเทียบ ZKP และ PoW โดยสังเขป (โดยเฉพาะสำหรับ Bitcoin)
2.1 บล็อกเชนที่เกิดขึ้นใหม่และข้อกำหนดที่แตกต่าง
บล็อกเชนที่เกิดขึ้นใหม่ในปัจจุบันใช้เทคโนโลยีที่ไม่มีความรู้เป็นด้านความต้องการหลักสำหรับการเร่งด้วยฮาร์ดแวร์ ซึ่งสามารถแบ่งคร่าวๆ ออกเป็นโซลูชันการปรับขนาดและบล็อกเชนที่รักษาความเป็นส่วนตัว Rollup หรือ Volition ที่ไม่มีความรู้จะทำธุรกรรมนอกเครือข่ายและส่งหลักฐานการตรวจสอบที่รวบรัดผ่านฟังก์ชัน "calldata" บล็อกเชนที่รักษาความเป็นส่วนตัวใช้ ZKP เพื่อให้ผู้ใช้ตรวจสอบความถูกต้องของธุรกรรมที่เริ่มต้นโดยไม่ต้องเปิดเผยรายละเอียดธุรกรรม
บล็อกเชนเหล่านี้แลกเปลี่ยนคุณสมบัติต่างๆ เช่น ขนาดการพิสูจน์ เวลาการตรวจสอบ และการตั้งค่าที่เชื่อถือได้โดยใช้ระบบพิสูจน์ที่แตกต่างกัน ตัวอย่างเช่น การพิสูจน์ที่สร้างขึ้นโดย Plonk จะมีขนาดการพิสูจน์คงที่ (ประมาณ 400 ไบต์) และเวลาในการตรวจสอบ (ประมาณ 6 มิลลิวินาที) แต่ก็ยังต้องมีการตั้งค่าที่เชื่อถือได้ทั่วไป ในทางตรงกันข้าม Stark ไม่ต้องการการตั้งค่าที่เชื่อถือได้ แต่ขนาดการพิสูจน์ (~80KB) และเวลาในการตรวจสอบ (~10ms) นั้นต่ำกว่ามาตรฐานและเพิ่มขึ้นตามขนาดลูป ระบบอื่นๆ ก็มีข้อดีข้อเสียเช่นกัน การแลกเปลี่ยนระหว่างระบบพิสูจน์เหล่านี้จะนำไปสู่การเปลี่ยนแปลงใน "จุดศูนย์ถ่วง" ของจำนวนการคำนวณ
โดยเฉพาะอย่างยิ่ง ระบบการพิสูจน์ปัจจุบันโดยทั่วไปสามารถอธิบายได้ว่าเป็น PIOP (Polynomial Interactive Proof of Prophecy) + PCS (Polynomial Commitment Scheme) โปรแกรมแรกอาจถูกมองว่าเป็นโปรแกรมที่ตกลงกันโดยผู้พิสูจน์เพื่อโน้มน้าวใจผู้ตรวจสอบ ในขณะที่โปรแกรมหลังใช้วิธีทางคณิตศาสตร์เพื่อให้แน่ใจว่าโปรแกรมจะไม่เสียหาย มันเหมือนกับว่า PCS เป็นปืนและ PIOP เป็นกระสุน ฝ่ายโครงการสามารถแก้ไข PIOP ได้ตามต้องการ และสามารถเลือกระหว่าง PCS ต่างๆ ได้Georgios Konstantopoulos แห่ง Paradigm ในรายงานการเร่งด้วยฮาร์ดแวร์
ตามที่อธิบายไว้ใน เวลาที่ต้องใช้ในการสร้างการพิสูจน์ส่วนใหญ่ขึ้นอยู่กับงานการคำนวณสองประเภท: MSM (อัลกอริทึมการคูณสเกลาร์หลายตัว) และ FFT (การแปลงฟูเรียร์แบบเร็ว) อย่างไรก็ตาม แทนที่จะใช้พารามิเตอร์คงที่ การสร้าง PIOP ที่แตกต่างกันและการเลือกจาก PCS ที่แตกต่างกันจะทำให้การคำนวณ FFT หรือ MSM แตกต่างกัน ยกตัวอย่าง Stark PCS ที่ Stark ใช้คือ FRI (Fast Reed-Solomon Code Proximity Interaction Proof) ซึ่งอิงตามรหัส Liso แทนที่จะเป็นเส้นโค้งวงรีที่ใช้โดย KZG หรือ IPA ดังนั้นจึงเป็นอิสระอย่างสมบูรณ์ในภาพรวม กระบวนการสร้างหลักฐาน ชายรักชาย มีส่วนเกี่ยวข้อง เราได้เรียงลำดับจำนวนการคำนวณของระบบพิสูจน์ที่แตกต่างกันอย่างคร่าว ๆ ในตารางด้านล่าง ควรสังเกตว่า 1) เป็นการยากที่จะประมาณจำนวนการคำนวณที่แน่นอนของระบบทั้งหมด 2) ฝ่ายโครงการมักจะแก้ไขระบบตามความจำเป็นระหว่างการใช้งาน .
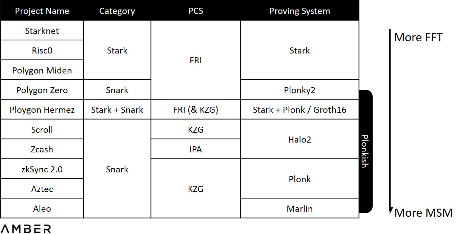
ปริมาณการคำนวณของระบบพิสูจน์ที่แตกต่างกัน
สถานการณ์ข้างต้นจะทำให้ฝ่ายโครงการมีการตั้งค่าประเภทฮาร์ดแวร์ของตนเอง ปัจจุบัน GPU (หน่วยประมวลผลกราฟิก) ถูกใช้อย่างแพร่หลายที่สุดเนื่องจากอุปทานจำนวนมากและการพัฒนาที่ง่าย นอกจากนี้ โครงสร้างแบบมัลติคอร์ของ GPU ยังสะดวกมากสำหรับการคำนวณ MSM แบบขนาน อย่างไรก็ตาม FPGA (Field Programmable Gate Arrays) อาจดีกว่าในการจัดการ FFT ซึ่งเราจะให้รายละเอียดในส่วนที่ 2 โครงการที่ใช้ Stark เช่น Starknet และ Hermez อาจต้องใช้ FPGA มากกว่า
ข้อสรุปอีกประการหนึ่งจากข้างต้นคือเทคโนโลยียังอยู่ในช่วงเริ่มต้นและยังขาดโซลูชันที่ได้มาตรฐานหรือโดดเด่น นอกจากนี้ยังอาจเร็วเกินไปที่จะใช้ ASIC (วงจรรวมเฉพาะแอปพลิเคชัน) อย่างเต็มที่สำหรับอัลกอริทึมเฉพาะ ดังนั้นนักพัฒนาซอฟต์แวร์จึงกำลังสำรวจจุดกึ่งกลาง ซึ่งเราจะอธิบายเพิ่มเติมในภายหลัง
2.2 เทรนด์และกระบวนทัศน์ใหม่
2.2.1 ข้อความที่ซับซ้อนมากขึ้นจากกรณีการใช้งานที่ระบุไว้ในตอนต้น เราคาดว่าความรู้ที่ไม่มีศูนย์จะมีประโยชน์มากขึ้นในอุตสาหกรรมการเข้ารหัสและโลกแห่งความจริง และเพื่อให้มีการพิสูจน์ที่ซับซ้อนมากขึ้น ซึ่งบางกรณีไม่จำเป็นต้องปฏิบัติตามระบบการพิสูจน์ในปัจจุบันด้วยซ้ำ แทนที่จะใช้ PIOP และ PCS ฝ่ายโครงการสามารถพัฒนาสิ่งดั้งเดิมใหม่ที่เหมาะสมที่สุดสำหรับพวกเขาได้ และในสาขาอื่นๆ เช่น MPC (การคำนวณแบบหลายฝ่ายที่ปลอดภัย) การใช้โปรโตคอลที่ไม่มีความรู้ในการทำงานบางอย่างจะช่วยปรับปรุงยูทิลิตี้ได้อย่างมาก เมื่อเร็ว ๆ นี้ Ethereum วางแผนที่จะโฮสต์ Proto-Dankshardingพิธีสถาปนาที่น่าเชื่อถือของ KZGในอนาคต เราวางแผนที่จะใช้ Danksharding เวอร์ชันเต็มเพิ่มเติมเพื่อจัดการการสุ่มตัวอย่างความพร้อมใช้งานของข้อมูล แม้แต่การยกเลิกในแง่ดีเป็นไปได้ที่จะนำ ZKP มาใช้ในอนาคต
เพื่อปรับปรุงความปลอดภัยและลดระยะเวลาดำเนินการข้อพิพาทในขณะที่หลายคนอาจมองว่าความรู้ที่ไม่มีศูนย์เป็นภาคส่วนแยกต่างหากในอุตสาหกรรม crypto ในวงกว้าง เราเชื่อว่าความรู้ที่ไม่มีศูนย์ควรถูกมองว่าเป็นเทคโนโลยีที่จัดการกับปัญหาต่างๆ ในอุตสาหกรรม
ในทางกลับกัน เพื่อให้บริการแก่ระบบและลูกค้าที่แตกต่างกัน การเร่งด้วยฮาร์ดแวร์จะมีความยืดหยุ่นและหลากหลายมากขึ้นในอนาคต
. การให้เวอร์ชันไคลเอ็นต์เป็นวิธีแก้ปัญหาง่ายๆ สำหรับ dapp ประเภทนี้ แต่ความจำเป็นในการดาวน์โหลดอาจทำให้ผู้มีโอกาสเป็นผู้ใช้บางรายสูญเสีย และไคลเอ็นต์ไม่เหมาะกับกระเป๋าเงินส่วนขยายปัจจุบันหรือเครื่องมืออื่นๆอีกวิธีหนึ่งคือการสร้างการพิสูจน์จากภายนอกบางส่วน Pratyush Mishra นำเสนอในงาน Zero Knowledge Summit ครั้งที่ 7วิธีนี้
การสร้างหลักฐานจากภายนอก
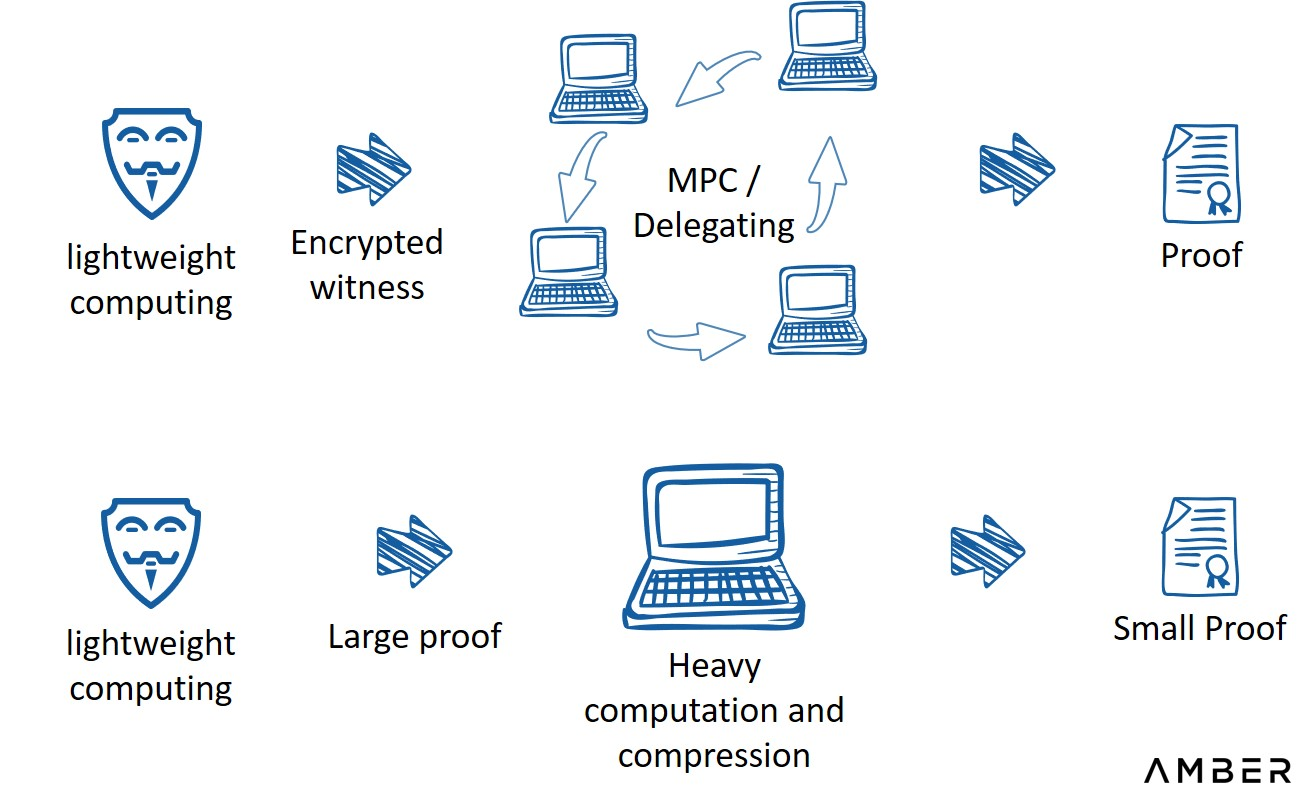
คำอธิบายภาพ
ที่มา: Zero Knowledge Summit ครั้งที่ 7 นำเสนอโดย Pratyush Mishra จาก Aleo
2.3 เปรียบเทียบกับการขุด PoW
แม้ว่าจะเป็นเรื่องธรรมดาที่จะคิดว่า ZKP เป็นรูปแบบใหม่ของ PoW และมองว่าฮาร์ดแวร์เร่งความเร็วเป็นเครื่องขุดประเภทใหม่ แต่การสร้าง ZKP นั้นแตกต่างโดยพื้นฐานจากการขุด PoW ในแง่ของวัตถุประสงค์และโครงสร้างตลาด
2.3.1 การแข่งขันไฟฟ้าและการคำนวณค่าสาธารณูปโภค
Rates-are-Odds (Aleo):เพื่อรับรางวัลบล็อกและค่าธรรมเนียมการทำธุรกรรม นักขุด Bitcoin ย้ำ nonces เพื่อหาค่าแฮชที่น้อยพอ ซึ่งจริงๆ แล้วเกี่ยวข้องกับฉันทามติเท่านั้น ในทางตรงกันข้าม การสร้าง ZKP เป็นกระบวนการที่จำเป็นเพื่อให้ได้ยูทิลิตี้ที่ใช้งานได้จริง เช่น การบีบอัดข้อมูลหรือการปกป้องความเป็นส่วนตัว โดยไม่ต้องรับผิดชอบต่อความเห็นพ้องต้องกัน ความแตกต่างนี้ส่งผลต่อรูปแบบการมีส่วนร่วมในวงกว้างและการกระจายรางวัลของ ZKP ด้านล่างเราแสดงรายการการออกแบบที่มีอยู่สามรายการเพื่อแสดงให้เห็นว่านักขุดจะประสานการสร้าง ZKP อย่างไร
Winner-Dominates(Polygon Hermez):การออกแบบโมเดลเศรษฐกิจของ Aleo นั้นใกล้เคียงกับ Bitcoin และโปรโตคอล PoW อื่นๆ มากที่สุด กลไกที่เป็นเอกฉันท์ PoSW (Concise Proof of Work) ยังคงต้องการนักขุดเพื่อค้นหาค่าสุ่มที่มีประสิทธิภาพ แต่กระบวนการตรวจสอบนั้นส่วนใหญ่ขึ้นอยู่กับการสร้างการพิสูจน์ SNARK ซ้ำ ๆ ซึ่งใช้ค่าสุ่มและค่าแฮชของสถานะรูทเป็นอินพุต และกระบวนการจะดำเนินต่อไปจนกว่าค่าแฮชการพิสูจน์ที่สร้างขึ้นในรอบหนึ่งจะน้อยพอ เราเรียกกลไกที่คล้าย PoW นี้ว่าแบบจำลองอัตราเป็นอัตราต่อรอง เนื่องจากจำนวนการตรวจสอบที่สามารถดำเนินการได้ในหน่วยเวลาหนึ่งๆ จะกำหนดความน่าจะเป็นที่จะได้รับรางวัลอย่างคร่าว ๆ ในโมเดลนี้ นักขุดจะเพิ่มโอกาสในการรับรางวัลโดยการกักตุนเครื่องคอมพิวเตอร์จำนวนมากPolygon Hermez ใช้โมเดลที่เรียบง่ายกว่า ตามที่พวกเขาเอกสารสาธารณะ
Party-Thresholds (Scroll):จากมุมมองของเนื้อหา ผู้เล่นหลักสองคนคือผู้สั่งซื้อและผู้รวบรวม ผู้สั่งซื้อรวบรวมธุรกรรมทั้งหมดและประมวลผลล่วงหน้าเป็นชุด L2 ใหม่ และผู้รวบรวมระบุความตั้งใจในการตรวจสอบและแข่งขันเพื่อสร้างการพิสูจน์ สำหรับชุดที่กำหนด ผู้รวบรวมรายแรกที่ส่งหลักฐานจะได้รับค่าธรรมเนียมที่จ่ายโดยผู้สั่งซื้อ ผู้รวบรวมข้อมูลที่มีการกำหนดค่าและฮาร์ดแวร์ที่ล้ำสมัยมีแนวโน้มที่จะครองตำแหน่งโดยไม่คำนึงถึงการกระจายทางภูมิศาสตร์ เงื่อนไขของเครือข่าย และกลยุทธ์การตรวจสอบ
Scroll อธิบายการออกแบบของพวกเขาว่าเป็น "การเอาท์ซอร์สการพิสูจน์เลเยอร์ 2" ซึ่งนักขุดที่เดิมพันสกุลเงินดิจิทัลจำนวนหนึ่งจะถูกเลือกโดยพลการเพื่อสร้างการพิสูจน์ นักขุดที่ได้รับเลือกจำเป็นต้องส่งหลักฐานภายในเวลาที่กำหนด มิฉะนั้นความน่าจะเป็นในการเลือกของพวกเขาสำหรับยุคถัดไปจะลดลง การสร้างหลักฐานที่ไม่ถูกต้องจะส่งผลให้มีค่าปรับ ในตอนแรก Scroll อาจจะทำงานร่วมกับนักขุดหลายสิบคนหรือมากกว่านั้นเพื่อปรับปรุงความเสถียร และแม้แต่เรียกใช้ GPU ของตัวเอง และเมื่อเวลาผ่านไป พวกเขาวางแผนที่จะกระจายอำนาจของกระบวนการทั้งหมด เราใช้โหนดเวลาการใช้งานแบบกระจายอำนาจนี้เป็นพารามิเตอร์เพื่อวัดการปรับจุดศูนย์ถ่วงของ Scroll ระหว่างประสิทธิภาพและการกระจายอำนาจ สตาร์คแวร์อาจจัดอยู่ในหมวดหมู่นี้ด้วย ในระยะยาว เฉพาะเครื่องจักรที่มีความสามารถในการพิสูจน์ให้เสร็จสิ้นในเวลาที่เหมาะสมเท่านั้นที่สามารถเข้าร่วมในการสร้างการพิสูจน์ได้การออกแบบที่ประสานกันเหล่านี้มีจุดเน้นที่แตกต่างกัน เราคาดหวังว่า Aleo จะมีการกระจายอำนาจสูงสุด Hermez จะมีประสิทธิภาพสูงสุด และ Scroll จะมีอุปสรรคต่อการมีส่วนร่วมน้อยที่สุด
แต่จากการออกแบบข้างต้น การแข่งขันอาวุธฮาร์ดแวร์ที่ไม่มีความรู้ไม่น่าจะเกิดขึ้นเร็ว ๆ นี้
2.3.2 อัลกอริทึมสแตติกและอัลกอริทึมวิวัฒนาการ
เราเชื่อว่าเมื่อเปรียบเทียบกับตลาด PoW ที่เรียบง่ายและคงที่แล้ว ความแตกต่างของ ZKP นั้นมีส่วนช่วยให้โครงสร้างตลาดมีการกระจายอำนาจและมีไดนามิกมากขึ้น เราเสนอให้คิดว่าการสร้าง ZKP เป็นบริการ (สตาร์ทอัพบางแห่งเรียกมันว่า ZK-as-a-Service) โดยที่การสร้าง ZKP เป็นวิธีการไปสู่จุดจบมากกว่าจุดจบ กระบวนทัศน์ใหม่นี้จะนำไปสู่รูปแบบธุรกิจหรือรายได้ใหม่ในที่สุด ซึ่งเราจะให้รายละเอียดในส่วนสุดท้าย ก่อนหน้านั้น เรามาดูวิธีแก้ไขหลายๆ วิธีกันก่อน
ชื่อระดับแรก
3. โซลูชั่น
CPU (หน่วยประมวลผลกลาง) เป็นชิปหลักในคอมพิวเตอร์ที่ใช้งานทั่วไป และมีหน้าที่กระจายคำสั่งไปยังส่วนประกอบต่างๆ บนเมนบอร์ด อย่างไรก็ตาม เนื่องจาก CPU ได้รับการออกแบบให้จัดการงานหลายอย่างได้อย่างรวดเร็ว ซึ่งจำกัดความเร็วในการประมวลผล จึงมักใช้ GPU, FPGA และ ASIC เป็นผู้ช่วยเมื่อต้องรับมือกับงานบางอย่างที่ทำพร้อมกันหรือเฉพาะบางงาน ในส่วนนี้ เราจะมุ่งเน้นไปที่คุณลักษณะ กระบวนการเพิ่มประสิทธิภาพ สถานะที่เป็นอยู่ และตลาด
3.1 GPU: ฮาร์ดแวร์ที่ใช้กันมากที่สุดในปัจจุบันpippengerเดิมที GPU ได้รับการออกแบบมาเพื่อจัดการกราฟิกคอมพิวเตอร์และประมวลผลรูปภาพ แต่โครงสร้างแบบขนานทำให้เป็นตัวเลือกที่ดีในด้านต่างๆ เช่น คอมพิวเตอร์วิทัศน์ การประมวลผลภาษาธรรมชาติ ซูเปอร์คอมพิวเตอร์ และการขุด PoW GPU สามารถเร่ง MSM และ FFT โดยเฉพาะอย่างยิ่งสำหรับ MSM โดยใช้ประโยชน์จากสิ่งที่เรียกว่า "
" อัลกอริทึม กระบวนการพัฒนา GPU นั้นง่ายกว่า FPGA หรือ ASIC มาก
แนวคิดของการเร่งความเร็วบน GPU นั้นง่ายมาก: ถ่ายโอนงานที่ต้องใช้การคำนวณเหล่านี้จาก CPU ไปยัง GPU วิศวกรจะเขียนส่วนเหล่านี้ใหม่เป็น CUDA หรือ OpenCL CUDA เป็นแพลตฟอร์มการประมวลผลแบบขนานและรูปแบบการเขียนโปรแกรมที่พัฒนาโดย Nvidia สำหรับการประมวลผลทั่วไปบน Nvidia GPUs คู่แข่งของ CUDA คือการประมวลผลแบบต่างกันที่พัฒนาโดย Apple และ Khronos Group มอบ OpenCL มาตรฐานซึ่งทำให้ผู้ใช้ไม่ใช้งานอีกต่อไป จำกัด เฉพาะ NVIDIA GPUs รหัสเหล่านี้จะถูกรวบรวมและเรียกใช้โดยตรงบน GPU เพื่อการเร่งความเร็วเพิ่มเติม นักพัฒนายังสามารถ:
(1) เพื่อลดต้นทุนการถ่ายโอนข้อมูล (โดยเฉพาะระหว่าง CPU และ GPU) ให้เพิ่มประสิทธิภาพหน่วยความจำโดยใช้พื้นที่จัดเก็บที่เร็วที่สุดเท่าที่จะเป็นไปได้และที่เก็บข้อมูลที่ช้าน้อยลง
(2) เพื่อปรับปรุงการใช้งานฮาร์ดแวร์และทำให้ฮาร์ดแวร์ทำงานได้เต็มประสิทธิภาพมากที่สุด ให้ปรับการกำหนดค่าการดำเนินการให้เหมาะสมโดยสร้างสมดุลระหว่างการทำงานระหว่างโปรเซสเซอร์หลายตัว สร้างการทำงานพร้อมกันแบบมัลติคอร์ และจัดสรรทรัพยากรสำหรับงานอย่างสมเหตุสมผล
ในระยะสั้นเราต้องการทำให้ดีที่สุดเพื่อให้กระบวนการทำงานทั้งหมดขนานกัน ในขณะเดียวกัน ควรหลีกเลี่ยงกระบวนการดำเนินการตามลำดับซึ่งรายการหลังขึ้นอยู่กับผลลัพธ์ของรายการก่อนหน้าให้มากที่สุด
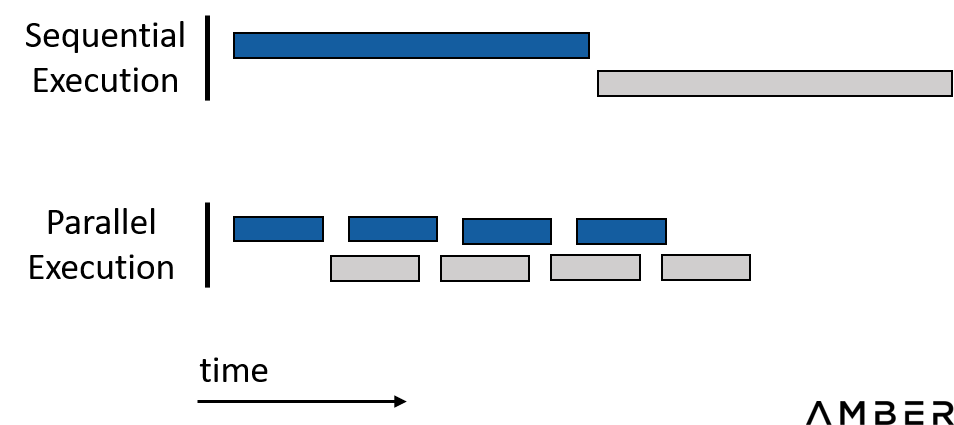
ประหยัดเวลาด้วยการขนาน

โฟลว์การออกแบบที่เร่งด้วย GPU
3.1.1 กลุ่มนักพัฒนาขนาดใหญ่และความสะดวกสบายในการพัฒนาซึ่งแตกต่างจาก FPGA และ ASIC การพัฒนา GPU ไม่เกี่ยวข้องกับการออกแบบฮาร์ดแวร์ CUDA หรือ OpenCL ยังมีชุมชนนักพัฒนาขนาดใหญ่ นักพัฒนาสามารถสร้างเวอร์ชันแก้ไขของตนเองได้อย่างรวดเร็วตามรหัสโอเพ่นซอร์ส ตัวอย่างเช่น Filecoin เปิดตัวในปี 2020. Supranational เพิ่งเปิดแหล่งที่มาของการเร่งความเร็วทั่วไปสารละลายสารละลาย
ซึ่งน่าจะเป็นโซลูชันโอเพ่นซอร์สที่ดีที่สุดในขณะนี้ข้อได้เปรียบนี้เด่นชัดยิ่งขึ้นเมื่อพิจารณาการทำงานนอกเหนือจาก MSM และ FFT การสร้างหลักฐานถูกครอบงำโดยสองรายการนี้ แต่ส่วนอื่น ๆ ยังคงมีสัดส่วนประมาณ 20% (ที่มา:สมุดปกขาวของ Sin7Y
) ดังนั้นการเร่ง MSM และ FFT เท่านั้นจึงมีผลจำกัดในการย่นระยะเวลาการพิสูจน์ แม้ว่าเวลาในการคำนวณของทั้งสองรายการนี้จะถูกบีบอัดให้สั้นลง แต่เวลาทั้งหมดที่ใช้ก็ยังเป็นเพียงหนึ่งในห้าของเวลาเดิม นอกจากนี้ เนื่องจากเป็นเฟรมเวิร์กที่เกิดขึ้นใหม่และกำลังพัฒนา จึงเป็นเรื่องยากที่จะคาดการณ์ว่าอัตราส่วนนี้จะเปลี่ยนแปลงอย่างไรในอนาคต เนื่องจากจำเป็นต้องมีการกำหนดค่า FPGA ใหม่ และ ASIC อาจต้องได้รับการออกแบบใหม่สำหรับการผลิต GPU จึงสะดวกกว่าสำหรับการเร่งความเร็วงานการคำนวณที่แตกต่างกัน
3.1.2 GPU ส่วนเกิน
ส่วนแบ่งตลาดชิป GPU
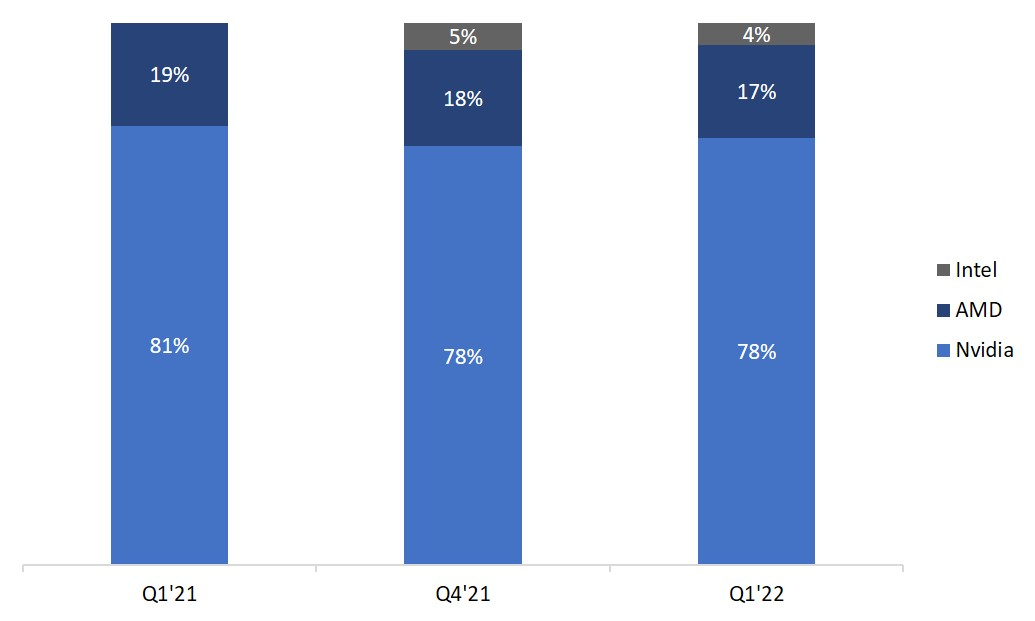
คำอธิบายภาพ
ที่มา: จอน เพดดี รีเสิร์ชโดยเฉพาะอย่างยิ่งสำหรับการขุด เราประเมินอย่างระมัดระวังที่การควบรวมกิจการของ ethereum
อัตราแฮช Ethereum
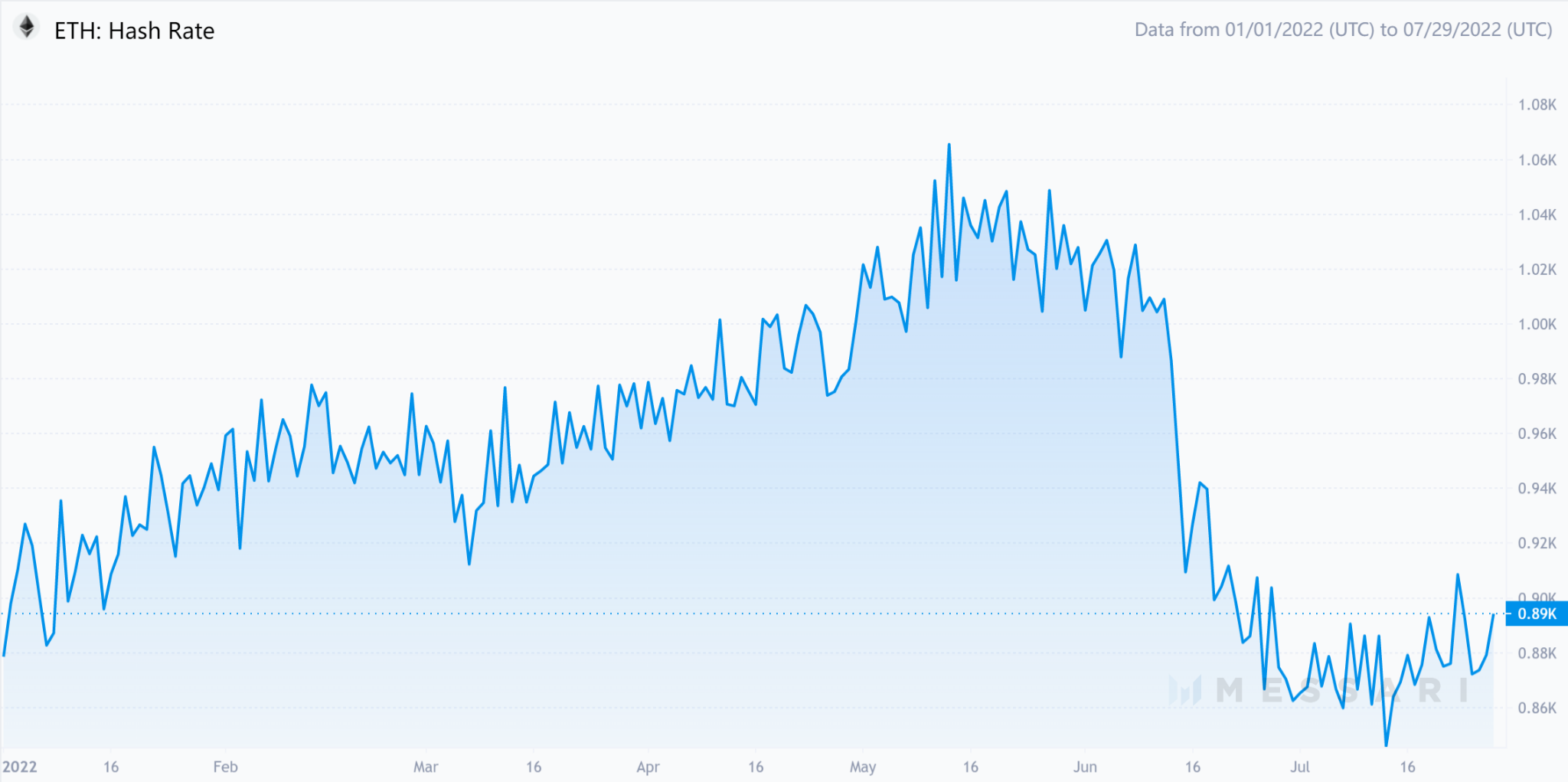
คำอธิบายภาพ
ที่มา: เมสซารี
3.2 FPGA: สร้างสมดุลระหว่างต้นทุนและประสิทธิภาพ
FPGA เป็นวงจรรวมที่มีโครงสร้างที่ตั้งโปรแกรมได้ เนื่องจากวงจรภายในชิป FPGA นั้นไม่ได้ผ่านการแกะสลักอย่างหนัก นักออกแบบจึงสามารถตั้งโปรแกรมใหม่ได้หลายครั้งตามต้องการ ในแง่หนึ่ง ช่วยลดต้นทุนการผลิตที่สูงของ ASIC ได้อย่างมีประสิทธิภาพ ในทางกลับกัน การใช้ทรัพยากรฮาร์ดแวร์มีความยืดหยุ่นมากกว่า GPU ซึ่งทำให้ FPGA มีศักยภาพในการเร่งความเร็วและประหยัดพลังงานมากขึ้น ตัวอย่างเช่น ในขณะที่เป็นไปได้ที่จะใช้ FFT ที่ปรับให้เหมาะสมบน GPU การสับเปลี่ยนข้อมูลบ่อยๆ ส่งผลให้เกิดการถ่ายโอนข้อมูลจำนวนมากระหว่าง GPU และ CPU อย่างไรก็ตาม การสับเปลี่ยนไม่ได้สุ่มอย่างสมบูรณ์ และด้วยการเขียนโปรแกรมลอจิกที่แท้จริงลงในการออกแบบวงจรโดยตรง FPGA สัญญาว่าจะทำงานได้เร็วขึ้น
เพื่อให้บรรลุการเร่ง ZKP บน FPGA ยังคงต้องมีขั้นตอนหลายขั้นตอน ขั้นแรก จำเป็นต้องใช้การอ้างอิงของระบบพิสูจน์เฉพาะที่เขียนด้วย C/C++ จากนั้น เพื่ออธิบายวงจรลอจิกดิจิทัลในระดับที่สูงขึ้น การใช้งานนี้จำเป็นต้องอธิบายใน HDL (ภาษาคำอธิบายฮาร์ดแวร์)
จากนั้นคุณต้องจำลองการดีบักเพื่อแสดงรูปคลื่นอินพุตและเอาต์พุตเพื่อดูว่าโค้ดทำงานตามที่คาดไว้หรือไม่ ขั้นตอนนี้เป็นขั้นตอนที่เกี่ยวข้องกับการใช้งานมากที่สุด วิศวกรไม่ต้องการกระบวนการทั้งหมด แต่เพียงแค่เปรียบเทียบผลลัพธ์ทั้งสองก็สามารถระบุข้อผิดพลาดเล็กน้อยได้ จากนั้นซินธิไซเซอร์จะแปลง HDL ให้เป็นการออกแบบวงจรจริงที่มีองค์ประกอบต่างๆ เช่น เกทและฟลิปฟล็อป และนำการออกแบบไปใช้กับสถาปัตยกรรมอุปกรณ์และการวิเคราะห์แบบแอนะล็อกเพิ่มเติม เมื่อวงจรได้รับการยืนยันว่าทำงานได้อย่างถูกต้อง ไฟล์โปรแกรมจะถูกสร้างขึ้นและโหลดลงในอุปกรณ์ FPGA ในที่สุด
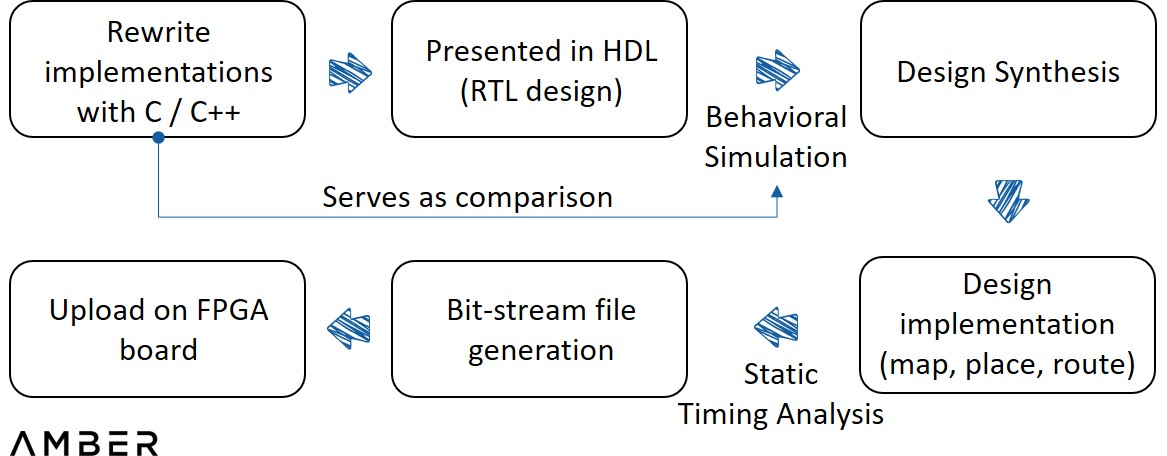
ขั้นตอนการออกแบบ FPGA
3.2.1 อุปสรรคในปัจจุบันและโครงสร้างพื้นฐานที่ไม่สมบูรณ์
แม้ว่าการเพิ่มประสิทธิภาพโมดูลบางอย่างที่ทำงานบน GPU จะสามารถนำมาใช้ซ้ำได้ แต่ก็เผชิญกับความท้าทายใหม่ ๆ เช่นกัน:
(1) เพื่อความปลอดภัยของหน่วยความจำที่สูงขึ้นและความเข้ากันได้ข้ามแพลตฟอร์มที่ดีขึ้น การใช้งานโอเพ่นซอร์สที่ไม่มีความรู้ส่วนใหญ่ได้รับการเขียนใน Rust มานานแล้ว แต่เครื่องมือพัฒนา FPGA ส่วนใหญ่เขียนด้วย C/C++ ซึ่งวิศวกรฮาร์ดแวร์คุ้นเคยมากกว่า ของ. ทีมอาจต้องเขียนใหม่หรือคอมไพล์การใช้งานเหล่านี้ก่อนที่จะนำไปใช้งาน
(2) เมื่อเขียนการใช้งานเหล่านี้ วิศวกรซอฟต์แวร์สามารถเลือกรหัสในไลบรารีโอเพ่นซอร์ส C/C++ ที่จำกัดซึ่งสามารถแมปเข้ากับสถาปัตยกรรมฮาร์ดแวร์ผ่านการสนับสนุนการพัฒนาที่มีอยู่
(3) นอกเหนือจากงานที่วิศวกรซอฟต์แวร์และวิศวกรฮาร์ดแวร์สามารถดำเนินการได้อย่างอิสระ พวกเขายังต้องการความร่วมมืออย่างใกล้ชิดเพื่อทำการเพิ่มประสิทธิภาพในเชิงลึกให้เสร็จสมบูรณ์ ตัวอย่างเช่น การปรับเปลี่ยนอัลกอริทึมบางอย่างจะช่วยประหยัดทรัพยากรฮาร์ดแวร์จำนวนมาก ในขณะเดียวกันก็มั่นใจได้ว่าจะมีบทบาทเหมือนเดิม แต่การเพิ่มประสิทธิภาพนี้ขึ้นอยู่กับความเข้าใจของฮาร์ดแวร์และซอฟต์แวร์กล่าวโดยสรุป วิศวกรต้องเรียนรู้และสร้างตั้งแต่เริ่มต้น ซึ่งไม่เหมือนกับ AI หรือสาขาที่พัฒนาแล้วอื่นๆ เพื่อให้บรรลุการเร่ง ZKP โชคดีที่เราได้เห็นความคืบหน้ามากขึ้น ตัวอย่างเช่น Ingonyama ในพวกเขาเอกสารล่าสุด
มีการเสนอ PipeMSM ใน ซึ่งเป็นวิธีการเร่ง MSM บน FPGA หรือ ASIC
3.2.2 ตลาดดูโอโพลี
ตลาด FPGA เป็นตลาดดูโอโพลีทั่วไป
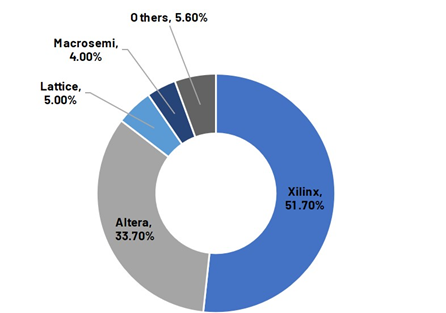
คำอธิบายภาพ
ที่มา: ฟรอสต์ แอนด์ ซัลลิแวน
วิศวกรตระหนักว่า FPGA เดียวไม่สามารถจัดหาทรัพยากรฮาร์ดแวร์เพียงพอสำหรับการสร้าง ZKP ที่ซับซ้อน ดังนั้นจึงต้องใช้การ์ดหลายใบพร้อมกันในการตรวจสอบ แม้จะมีการออกแบบที่สมบูรณ์ ข้อเสนอระบบคลาวด์ FPGA มาตรฐานที่มีอยู่จาก AWS และผู้จำหน่ายอื่นๆ ก็ยังไม่เหมาะ นอกจากนี้ สตาร์ทอัพที่นำเสนอโซลูชันการเร่งความเร็วมักมีขนาดเล็กเกินไปที่จะให้ AWS หรือผู้ให้บริการรายอื่นโฮสต์ฮาร์ดแวร์แบบกำหนดเองของตน และไม่มีทรัพยากรในการเรียกใช้เซิร์ฟเวอร์ของตนเอง อาจเป็นทางเลือกที่ดีกว่าในการร่วมมือกับนักขุดขนาดใหญ่หรือร่วมมือกับผู้ให้บริการคลาวด์เนทีฟ Web3 อย่างไรก็ตาม การเป็นหุ้นส่วนอาจมีความละเอียดอ่อน เมื่อพิจารณาว่าวิศวกรภายในของบริษัทเหมืองมีแนวโน้มที่จะพัฒนาโซลูชันการเร่งความเร็ว
3.3 ASIC: สุดยอดอาวุธ
ASIC เป็นชิปวงจรรวม (IC) ที่ปรับแต่งเพื่อวัตถุประสงค์เฉพาะ โดยทั่วไปแล้ว วิศวกรยังคงใช้ HDL เพื่ออธิบายตรรกะของ ASIC ในลักษณะที่คล้ายกับการใช้ FPGA แต่วงจรสุดท้ายจะถูกดึงเข้าไปในซิลิกอนอย่างถาวร ในขณะที่วงจรใน FPGA ถูกสร้างขึ้นโดยการเชื่อมต่อบล็อกที่กำหนดค่าได้หลายพันรายการ แทนที่จะต้องจัดหาฮาร์ดแวร์จาก Nvidia, Intel หรือ AMD บริษัทต่างๆ จะต้องจัดการกระบวนการทั้งหมดด้วยตนเอง ตั้งแต่การออกแบบวงจรไปจนถึงการผลิตและการทดสอบ ASIC จะถูกจำกัดไว้เฉพาะบางฟังก์ชัน แต่ให้อิสระแก่นักออกแบบในระดับสูงสุดในแง่ของการจัดสรรทรัพยากรและการออกแบบวงจร ดังนั้น ASIC จึงมีศักยภาพที่ดีในแง่ของประสิทธิภาพและประสิทธิภาพการใช้พลังงาน นักออกแบบสามารถกำจัดความสูญเปล่าในด้านพื้นที่ พลังงาน และฟังก์ชันการทำงานได้โดยเพียงแค่ออกแบบจำนวนประตูที่แน่นอน หรือกำหนดขนาดของโมดูลต่างๆ ตามการใช้งานที่ต้องการ
ในแง่ของกระบวนการออกแบบ เมื่อเปรียบเทียบกับ FPGA แล้ว ASIC จำเป็นต้องเพิ่มการตรวจสอบ pre-slice (และ DFT) ระหว่างสองขั้นตอนของการเขียนและการรวม HDL และจำเป็นต้องมีการวางผังพื้นก่อนนำไปใช้งาน แบบแรกคือที่ที่วิศวกรทดสอบการออกแบบในสภาพแวดล้อมเสมือนจริงโดยใช้เครื่องมือจำลองที่ซับซ้อน และแบบหลังใช้เพื่อกำหนดขนาด รูปร่าง และตำแหน่งของบล็อกในชิป หลังจากการออกแบบเป็นจริง ไฟล์ทั้งหมดจะถูกส่งไปยังโรงหล่อเช่น TSMC หรือ Samsung เพื่อทดสอบเทปออก หากการทดสอบสำเร็จจะส่งต้นแบบไปประกอบและทดสอบ
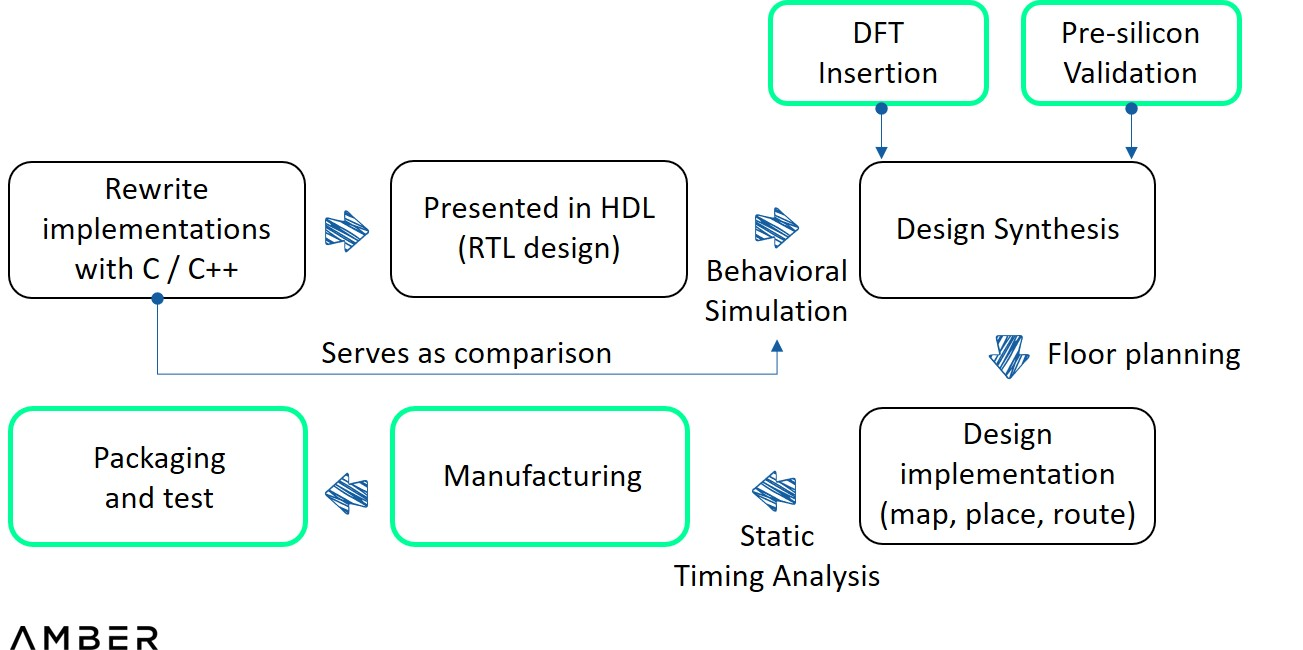
ขั้นตอนการออกแบบ ASIC
3.3.1 ASIC ที่ค่อนข้างพบได้ทั่วไปในฟิลด์ที่ไม่มีความรู้
คำวิจารณ์ทั่วไปของ ASIC คือเมื่ออัลกอริธึมเปลี่ยนแปลง ชิปรุ่นก่อนหน้าจะไร้ประโยชน์โดยสิ้นเชิง แต่ก็ไม่จำเป็นต้องเป็นเช่นนั้น
บังเอิญ ไม่มีบริษัทใดที่เราพูดคุยด้วยที่วางแผนพัฒนา ASICs ทั้งหมดอยู่ในระบบพิสูจน์หรือโครงการเฉพาะ แทนที่จะพัฒนาโมดูลที่ตั้งโปรแกรมได้บน ASIC แทน เพื่อให้สามารถจัดการกับระบบพิสูจน์หลักฐานต่างๆ ผ่านโมดูลเหล่านี้ได้ และกำหนดเฉพาะงาน MSM และ FFT ให้กับ ASIC สิ่งนี้ไม่เหมาะสำหรับชิปเฉพาะสำหรับโครงการเฉพาะ แต่ในระยะสั้น อาจเป็นการดีกว่าที่จะเสียสละประสิทธิภาพเพื่อส่วนรวมที่ดีกว่าการออกแบบสำหรับงานเฉพาะ
3.3.1 ค่าใช้จ่ายที่แพงแต่ไม่เกิดขึ้นประจำ
ไม่เพียงแต่กระบวนการออกแบบสำหรับ ASIC จะซับซ้อนกว่า FPGA มากเท่านั้น แต่กระบวนการผลิตยังใช้เวลาและเงินมากกว่าอีกด้วย สตาร์ทอัพสามารถติดต่อโรงหล่อโดยตรงเพื่อเทปเอาท์หรือผ่านผู้จัดจำหน่าย อาจใช้เวลาประมาณสามเดือนขึ้นไปในการรอจนกว่าการดำเนินการจะเริ่มขึ้นจริง ต้นทุนหลักของเทปออกมาจากเส้นเล็งและแผ่นเวเฟอร์ Reticles ใช้สร้างลวดลายบนแผ่นเวเฟอร์ ซึ่งเป็นแผ่นซิลิคอนบางๆ สตาร์ทอัพมักเลือก MPW (หลายโครงการเวเฟอร์) ซึ่งสามารถแบ่งปันต้นทุนการผลิตของเรติเคิลและเวเฟอร์กับฝ่ายโครงการอื่นๆ อย่างไรก็ตาม ขึ้นอยู่กับกระบวนการและจำนวนของชิปที่พวกเขาเลือก ต้นทุนของเทปเอาท์นั้นประเมินอย่างระมัดระวังว่าจะอยู่ในหน่วยหลายล้านดอลลาร์ การถอดเทป การประกอบและการทดสอบยังอยู่ห่างออกไปอีกหลายเดือน หากเป็นไปได้ ก็จะสามารถเริ่มเตรียมการผลิตจำนวนมากได้ในที่สุด อย่างไรก็ตาม หากมีสิ่งผิดปกติเกิดขึ้นกับการทดสอบ การดีบักและการวิเคราะห์ความล้มเหลวจะใช้เวลานับไม่ถ้วนและต้องมีการแยกส่วนอีกครั้ง จากการออกแบบเบื้องต้นไปจนถึงการผลิตจำนวนมากต้องใช้เงินทุนหลายสิบล้าน และจะใช้เวลาประมาณ 18 เดือน สบายใจในข้อเท็จจริงที่ว่าค่าใช้จ่ายส่วนสำคัญเหล่านี้ไม่เกิดซ้ำ นอกจากนี้ ASIC ยังมีประสิทธิภาพสูงและสามารถประหยัดพลังงานและพื้นที่ซึ่งเป็นสิ่งสำคัญมากและราคาอาจค่อนข้างต่ำ
ด้านล่างนี้เป็นการประเมินทั่วไปของโซลูชันฮาร์ดแวร์ต่างๆ
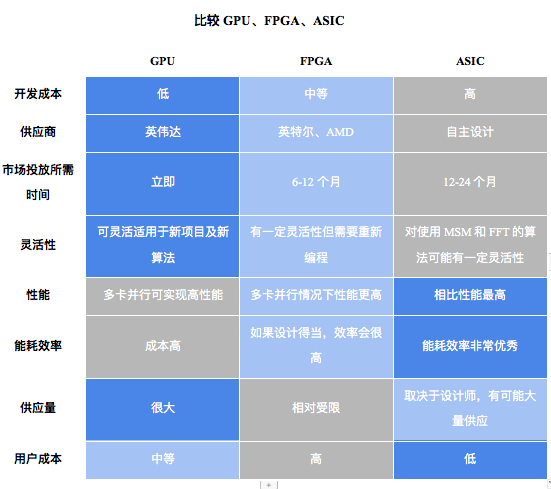
คำอธิบายภาพ
ที่มา: แอมเบอร์
เพื่อให้เข้าใจได้ง่ายขึ้นเกี่ยวกับรูปแบบธุรกิจที่มีอยู่ เราได้แสดงผู้เล่นในตลาดที่มีศักยภาพทั้งหมดในแผนภูมิด้านล่าง เนื่องจากอาจมีความสัมพันธ์ข้ามหรือซับซ้อนระหว่างนักแสดง เราจึงจัดหมวดหมู่ตามหน้าที่เท่านั้น
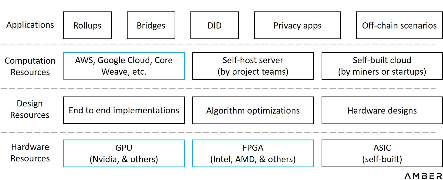
ชั้นการทำงานที่เร่งด้วยฮาร์ดแวร์
ยังไม่มีการนำความรู้ที่เป็นศูนย์ไปใช้ในวงกว้าง และการสร้างโซลูชันเร่งความเร็วจะเป็นกระบวนการที่ยาวนาน มารอดูกันว่าจุดเปลี่ยนต่อไปจะเป็นอย่างไร คำถามสำคัญสำหรับผู้สร้างและนักลงทุนคือเมื่อใดที่จุดเปลี่ยนนี้จะมาถึง
ขอบคุณ
ขอขอบคุณเป็นพิเศษสำหรับ Weikeng Chen (DZK), Ye Zhang (Scroll), Kelly (Supranational) และ Omer (Ingonyama) ที่ช่วยให้เราเข้าใจรายละเอียดทางเทคนิคทั้งหมด ขอขอบคุณ Kai (ZKMatrix), Slobodan (Ponos), Elias and Chris (Inaccel), Heqing Hong (Accseal) และคนอื่นๆ อีกมากมายที่ให้ข้อมูลเชิงลึกเกี่ยวกับการวิจัยนี้
ข้อจำกัดความรับผิดชอบ
ข้อมูลที่มีอยู่ในที่นี้ (“ข้อมูล”) จัดทำขึ้นเพื่อวัตถุประสงค์ในการให้ข้อมูลเท่านั้น ในรูปแบบสรุปและไม่ครอบคลุมทั้งหมด เนื้อหาเหล่านี้ไม่ใช่และไม่ได้มีวัตถุประสงค์เพื่อเป็นข้อเสนอหรือการชักชวนให้เสนอขายหรือซื้อหลักทรัพย์หรือผลิตภัณฑ์ใดๆ ข้อมูลดังกล่าวไม่ได้ให้ไว้และไม่ควรถือเป็นการให้คำแนะนำการลงทุน ข้อมูลเหล่านี้ไม่ได้คำนึงถึงวัตถุประสงค์ในการลงทุน สถานการณ์ทางการเงิน หรือความต้องการเฉพาะของนักลงทุนที่มีศักยภาพ ไม่มีการให้สัญญาหรือการรับประกันใด ๆ ไม่ว่าโดยชัดแจ้งหรือโดยปริยายเกี่ยวกับความยุติธรรม ความถูกต้อง ความถูกต้อง ความมีเหตุผล หรือความสมบูรณ์ของข้อมูล เราไม่มุ่งมั่นที่จะอัปเดตเนื้อหานี้ ไม่ควรพิจารณาโดยนักลงทุนที่มีศักยภาพเพื่อใช้แทนวิจารณญาณหรือการวิจัยของตนเอง นักลงทุนที่มีศักยภาพควรปรึกษาที่ปรึกษาด้านกฎหมาย กฎระเบียบ ภาษี ธุรกิจ การลงทุน การเงินและการบัญชีของตนเองตามขอบเขตที่พวกเขาเห็นว่าจำเป็น และตัดสินใจลงทุนตามวิจารณญาณและคำแนะนำของที่ปรึกษา


