
การวิเคราะห์กรอบการเรียนรู้ของสหพันธ์
【คำนำ】
▲ การทบทวนปัญหาการเรียนรู้แบบสมาพันธ์ ตามที่กล่าวไว้ข้างต้น ในปี 2559 Google ได้เสนอวิธีการใหม่สำหรับการฝึกโมเดลวิธีการป้อนข้อมูลที่เรียกว่า "การเรียนรู้แบบสมาพันธ์" เมื่อเวลาผ่านไป การเรียนรู้แบบสมาพันธ์จะไม่ใช่วิธีแก้ปัญหาง่ายๆ สำหรับรูปแบบวิธีการป้อนข้อมูลของ Google อีกต่อไป และรูปแบบการเรียนรู้ใหม่ก็ได้เกิดขึ้นแล้ว ปัญหาที่แก้ไขโดยการเรียนรู้แบบสมาพันธ์มักเรียกว่า TMMPP--Training Machine Learning Models บนแหล่งข้อมูลหลายแหล่งด้วย Privacy นั่นคือการร่วมกันดำเนินการฝึกอบรมโมเดลที่กำหนดไว้ล่วงหน้าให้เสร็จสิ้น ขณะเดียวกันก็ต้องแน่ใจว่าข้อมูลของผู้เข้าร่วมหลายคนไม่รั่วไหล ในปัญหา TMMPP ที่แก้ไขโดยการเรียนรู้แบบสมาพันธ์ มีการรวมคิวบ์ข้อมูล n รายการ (ตัวควบคุมข้อมูล) {D1, D2,...Dn} และแต่ละคิวบ์ข้อมูลสอดคล้องกับ n ข้อมูล {P1, P2,... Pn} จากมุมมองของโหมดการฝึกอบรมของสมาพันธ์เลิร์นนิง หลังจากเลือกอัลกอริทึมการเรียนรู้แบบสมาพันธ์ที่จำเป็นต้องได้รับการฝึกฝน จำเป็นต้องจัดเตรียมอินพุตที่สอดคล้องกันสำหรับการเรียนรู้แบบสมาพันธ์ และรับผลลัพธ์หลังการฝึกอบรมในที่สุด
อินพุตของการเรียนรู้แบบสมาพันธ์ (อินพุต): แต่ละฝ่ายข้อมูลใช้ข้อมูลดั้งเดิมที่ Pi เป็นเจ้าของเป็นอินพุตของการสร้างแบบจำลองร่วมและป้อนเข้าสู่กระบวนการของการเรียนรู้แบบสมาพันธ์
ผลลัพธ์ของการเรียนรู้แบบสมาพันธ์ (Output): รวมข้อมูลของผู้เข้าร่วมทั้งหมด และฝึกอบรมโมเดล M ทั่วโลกโดยส่วนกลาง (ในระหว่างกระบวนการฝึกอบรม จะไม่มีการเปิดเผยข้อมูลเกี่ยวกับข้อมูลดั้งเดิมของกลุ่มข้อมูลใด ๆ ต่อหน่วยงานอื่น ๆ )
▲ ความท้าทายที่พบในการเรียนรู้แบบสมาพันธ์
เทคโนโลยีการเรียนรู้ของสหพันธ์ยังคงอยู่ในการปรับปรุงอย่างต่อเนื่อง ในกระบวนการพัฒนา การเรียนรู้แบบสมาพันธ์จะเผชิญกับความท้าทายหลักสามประการ ซึ่งเป็นความท้าทายทางสถิติ ความท้าทายด้านประสิทธิภาพ และความท้าทายด้านความปลอดภัย
[ความท้าทายทางสถิติ] ความท้าทายทางสถิติเป็นความท้าทายที่เกิดจากความแตกต่างในการกระจายหรือจำนวนข้อมูลของผู้ใช้ที่แตกต่างกันระหว่างการดำเนินการของการเรียนรู้แบบสมาพันธ์
ก) ข้อมูลที่ไม่อิสระและกระจายเหมือนกัน (Non-IID data) กล่าวคือ การกระจายข้อมูลของผู้ใช้ที่แตกต่างกันไม่เป็นอิสระต่อกันและมีความแตกต่างของการกระจายอย่างชัดเจน เช่น ฝ่าย A มีข้อมูลการปลูกข้าวทางตอนเหนือของประเทศจีน ฝ่าย B มีข้อมูลการปลูกข้าวทางตอนใต้ของจีน ข้อมูลเนื่องจากอิทธิพลของละติจูด ภูมิอากาศ มนุษยศาสตร์ ฯลฯ ข้อมูลของทั้งสองฝ่ายจึงไม่อยู่ภายใต้การกระจายเดียวกัน
ข) ข้อมูลที่ไม่สมดุล (Unbalanced Data) กล่าวคือ มีปริมาณข้อมูลของผู้ใช้แตกต่างกันอย่างเห็นได้ชัด ตัวอย่างเช่น บริษัทยักษ์ใหญ่มีข้อมูลเกือบสิบล้านข้อมูลในขณะที่บริษัทขนาดเล็กเก็บข้อมูลไว้เพียงหลายหมื่นชิ้น ข้อมูล ผลกระทบของข้อมูลต่อบริษัทยักษ์ใหญ่มีน้อยมากและเป็นการยากที่จะมีส่วนร่วมในการฝึกอบรมแบบจำลอง
[ความท้าทายด้านประสิทธิภาพ] ความท้าทายด้านประสิทธิภาพหมายถึงความท้าทายที่เกิดจากการใช้คอมพิวเตอร์และการสื่อสารภายในเครื่องของแต่ละโหนดในการเรียนรู้แบบสมาพันธ์
ก) ค่าโสหุ้ยในการสื่อสาร กล่าวคือ การสื่อสารระหว่างโหนดผู้ใช้ (ผู้เข้าร่วม) โดยปกติหมายถึงปริมาณข้อมูลที่ส่งระหว่างผู้ใช้แต่ละรายภายใต้สมมติฐานของแบนด์วิธที่จำกัด ยิ่งข้อมูลมีปริมาณมาก การสูญเสียการสื่อสารก็จะยิ่งสูงขึ้น
b) ความซับซ้อนในการคำนวณ กล่าวคือ ความซับซ้อนในการคำนวณตามโปรโตคอลการเข้ารหัสพื้นฐาน มักจะหมายถึงความซับซ้อนของเวลาของการคำนวณโปรโตคอลการเข้ารหัสพื้นฐาน ยิ่งตรรกะการคำนวณของอัลกอริทึมซับซ้อนมากเท่าใด ก็จะยิ่งใช้เวลามากขึ้นเท่านั้น
[ความท้าทายด้านความปลอดภัย] ความท้าทายด้านความปลอดภัยหมายถึงความท้าทายต่างๆ เช่น การถอดรหัสข้อมูลและพิษที่เกิดจากผู้ใช้ที่แตกต่างกันโดยใช้วิธีการโจมตีที่แตกต่างกันในระหว่างกระบวนการเรียนรู้แบบสมาพันธ์
ก) รูปแบบกึ่งซื่อสัตย์ กล่าวคือ ผู้ใช้แต่ละรายใช้โปรโตคอลทั้งหมดในการเรียนรู้แบบสมาพันธ์โดยสุจริต แต่ใช้ข้อมูลที่ได้รับเพื่อพยายามวิเคราะห์และผลักดันข้อมูลของผู้อื่นกลับคืน
b) แบบจำลองที่เป็นอันตราย กล่าวคือ มีไคลเอนต์ที่ไม่ปฏิบัติตามข้อตกลงระหว่างโหนดอย่างเคร่งครัด และอาจทำให้ข้อมูลต้นฉบับหรือข้อมูลกลางเสียหายเพื่อทำลายกระบวนการการเรียนรู้แบบสมาพันธ์
[กรอบงานทั่วไปสำหรับการเรียนรู้แบบสมาพันธ์]
เมื่อเผชิญกับความท้าทายสามประการข้างต้น ชุมชนวิชาการได้ดำเนินการวิจัยที่ตรงเป้าหมายและเสนอกรอบการเรียนรู้แบบรวมศูนย์ที่มีประสิทธิภาพและเฉพาะเพื่อเพิ่มประสิทธิภาพกระบวนการฝึกอบรมการเรียนรู้แบบรวมศูนย์ เราแนะนำกรอบเหล่านี้โดยสังเขปด้านล่างนี้
การเรียนรู้แบบสหพันธ์ 1.0 – การเรียนรู้แบบสหพันธ์แบบดั้งเดิม
ก่อนอื่น เรามาอธิบายแนวคิดและหลักการของการเรียนรู้แบบรวมศูนย์กันอีกครั้ง: มีผู้เข้าร่วมและผู้ทำงานร่วมกันหลายคนเพื่อร่วมกันปฏิบัติงานการเรียนรู้แบบรวมศูนย์ และผู้เข้าร่วม (นั่นคือ เจ้าของข้อมูล) สร้างข้อมูลระดับกลางที่คล้ายกับการไล่ระดับสีผ่านอัลกอริทึมการเรียนรู้แบบรวมศูนย์ที่ตั้งไว้ล่วงหน้า มอบให้ผู้ประสานงานดำเนินการต่อไปแล้วส่งคืนให้กับผู้เข้าอบรมแต่ละคนเพื่อเตรียมพร้อมสำหรับการฝึกอบรมรอบต่อไป
งานการเรียนรู้แบบสมาพันธ์เสร็จสิ้นซ้ำแล้วซ้ำเล่า ตลอดทั้งงาน ข้อมูลท้องถิ่นของผู้เข้าร่วมจะไม่ถูกแลกเปลี่ยนในแต่ละเฟรมเวิร์ก FL แต่พารามิเตอร์ (เช่น การไล่ระดับสี) ที่ส่งระหว่างผู้ประสานงานและผู้เข้าร่วมอาจทำให้ข้อมูลที่ละเอียดอ่อนรั่วไหลได้
เพื่อป้องกันข้อมูลในเครื่องของเจ้าของข้อมูลจากการรั่วไหลและเพื่อรักษาความเป็นส่วนตัวของข้อมูลระดับกลางในระหว่างการฝึกอบรม เทคนิคความเป็นส่วนตัวบางอย่างถูกนำมาใช้ในกรอบของ FL เพื่อแลกเปลี่ยนพารามิเตอร์แบบส่วนตัวเมื่อผู้เข้าร่วมโต้ตอบกับผู้ประสานงาน นอกจากนี้ จากมุมมองของกลไกการปกป้องความเป็นส่วนตัวที่ใช้ในกรอบ FL กรอบ FL แบ่งออกเป็น:
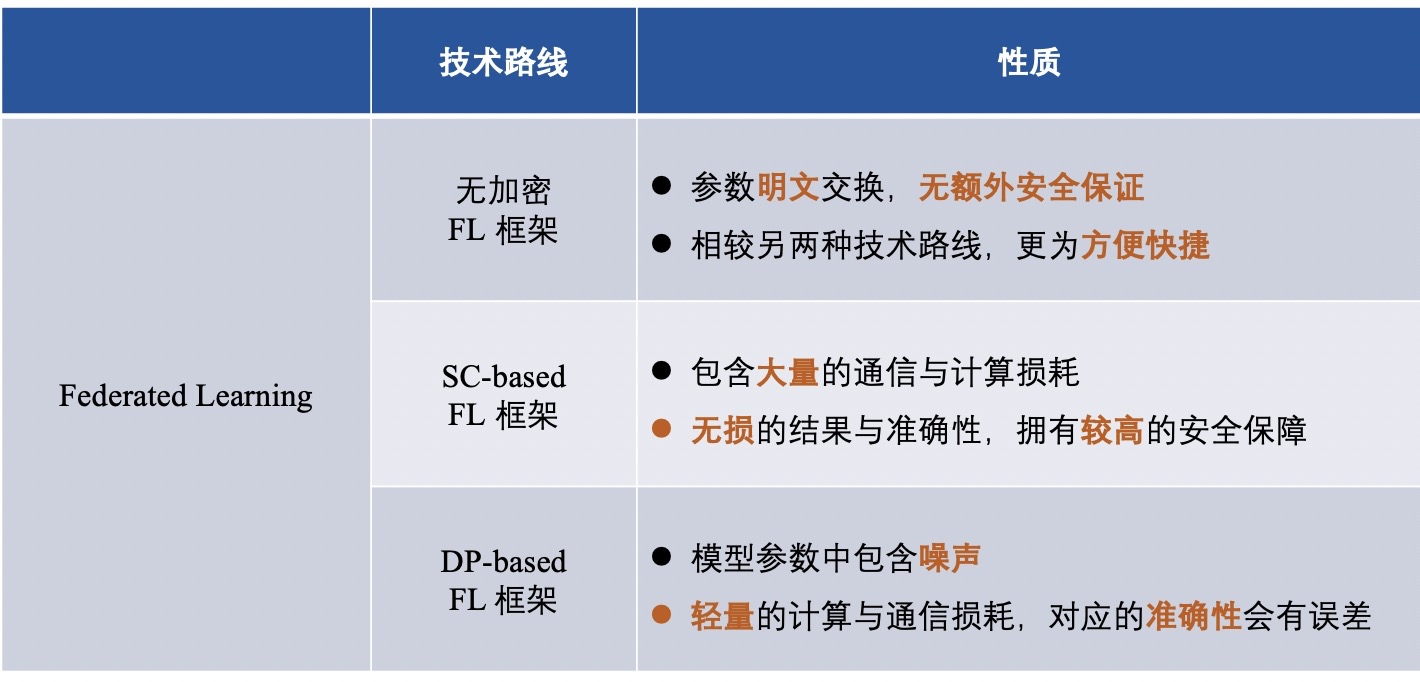
1) กรอบการเรียนรู้แบบสมาพันธ์ที่ไม่ได้เข้ารหัส (นั่นคือไม่มีการเข้ารหัสข้อมูล)
2) กรอบการเรียนรู้แบบรวมศูนย์ตามความเป็นส่วนตัวที่แตกต่างกัน (การใช้ความเป็นส่วนตัวที่แตกต่างกันเพื่อสร้างความสับสนและเข้ารหัสข้อมูล)
3) เฟรมเวิร์กการเรียนรู้แบบรวมศูนย์ที่อิงจากการประมวลผลหลายฝ่ายที่ปลอดภัย (ใช้การประมวลผลหลายฝ่ายที่ปลอดภัยเพื่อเข้ารหัสข้อมูล)
▲ เฟรมเวิร์กการเรียนรู้แบบสมาพันธ์ที่ไม่ได้เข้ารหัส
เฟรมเวิร์ก FL จำนวนมากมุ่งเน้นไปที่การปรับปรุงประสิทธิภาพหรือจัดการกับความท้าทายของความแตกต่างทางสถิติ ในขณะที่มองข้ามความเสี่ยงที่อาจเกิดขึ้นจากการแลกเปลี่ยนพารามิเตอร์ข้อความล้วน
ในปี 2015 FedCS[3] ซึ่งเป็นเฟรมเวิร์กการประมวลผล Edge สำหรับอุปกรณ์เคลื่อนที่สำหรับแมชชีนเลิร์นนิงที่เสนอโดย Nishio และคณะ สามารถดำเนินการ FL ได้อย่างรวดเร็วและมีประสิทธิภาพตามการตั้งค่าของเจ้าของข้อมูลที่ต่างกัน
ในปี 2560 Smith et al. ได้เสนอเฟรมเวิร์กการเพิ่มประสิทธิภาพการรับรู้ระบบที่เรียกว่า MOCHA[2] ซึ่งรวม FL กับการเรียนรู้แบบหลายงานและใช้การเรียนรู้แบบหลายงานเพื่อจัดการกับความท้าทายทางสถิติ ข้อมูลกระจายไม่สม่ำเสมอและความท้าทายต่างๆ ที่เกิดขึ้น โดยความแตกต่างของปริมาณข้อมูล
ในปีเดียวกัน Liang et al. ได้เสนอ LG-FEDAVG [4] ร่วมกับการเรียนรู้การเป็นตัวแทนของท้องถิ่น พวกเขาแสดงให้เห็นว่าแบบจำลองในท้องถิ่นสามารถจัดการข้อมูลที่ต่างกันได้ดีขึ้นและเรียนรู้การแสดงที่ยุติธรรมได้อย่างมีประสิทธิภาพ ซึ่งทำให้คุณสมบัติที่ได้รับการคุ้มครองสับสน
ดังที่แสดงในรูปด้านล่าง: กระบวนการการเรียนรู้แบบรวมศูนย์ไม่ได้เข้ารหัสข้อมูลระดับกลางใดๆ เลย และข้อมูลระดับกลางทั้งหมด (เช่น การไล่ระดับสี) จะถูกส่งและคำนวณเป็นข้อความล้วน ด้วยวิธีการข้างต้น ในที่สุดผู้เข้าร่วมก็เรียนรู้ร่วมกันเพื่อให้ได้รูปแบบการเรียนรู้แบบสมาพันธ์
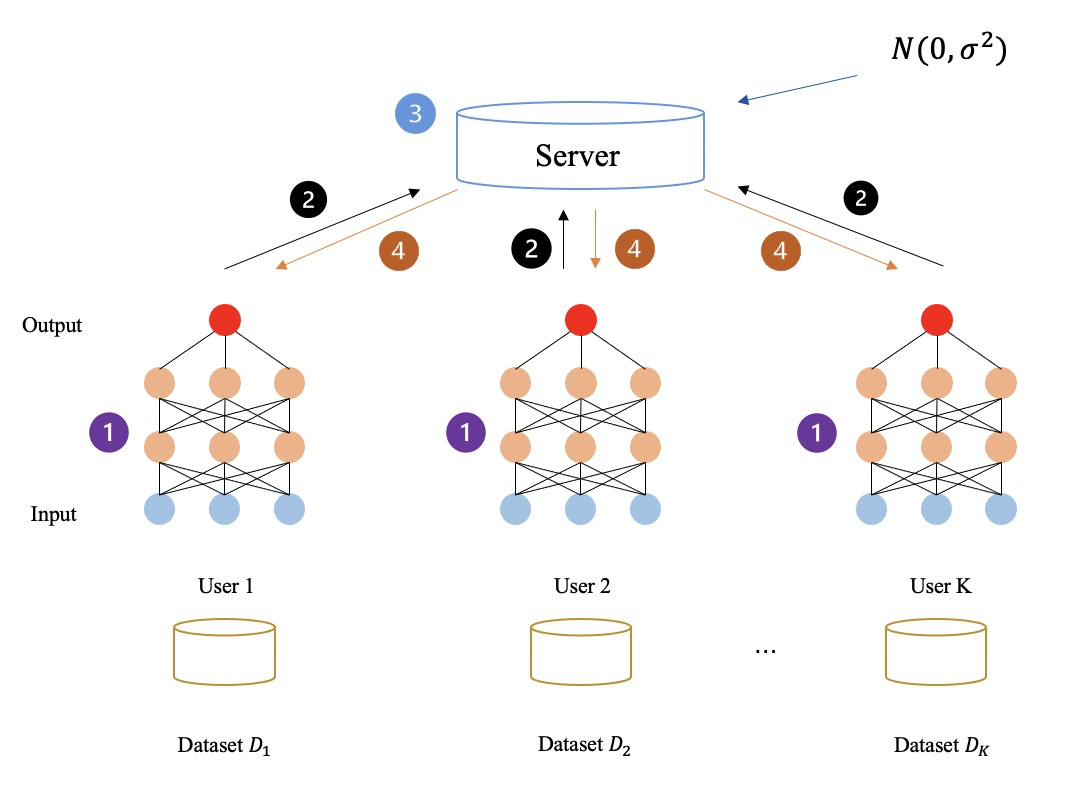
▲ กรอบการเรียนรู้แบบรวมศูนย์ขึ้นอยู่กับความเป็นส่วนตัวที่แตกต่างกัน
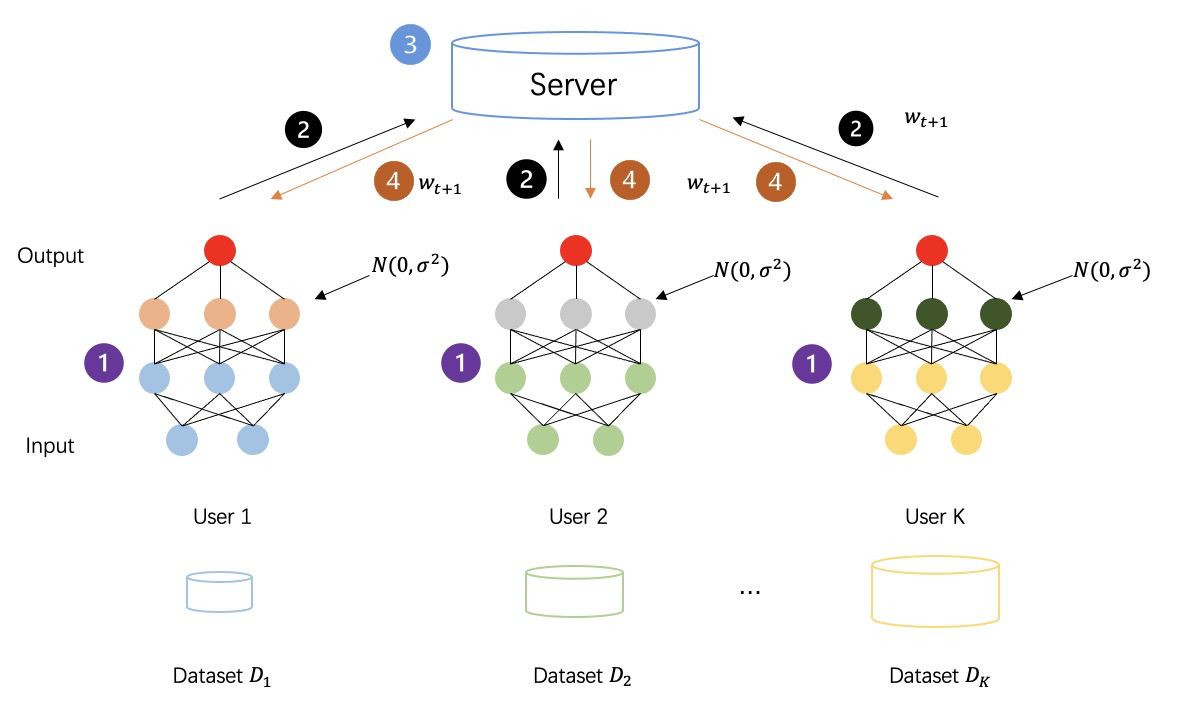
ความเป็นส่วนตัวที่แตกต่าง (DP) เป็นเทคนิคความเป็นส่วนตัว [5-7] ที่มีการรับประกันทางทฤษฎีข้อมูลที่แข็งแกร่งสำหรับการเพิ่มสัญญาณรบกวนในข้อมูล [8-10] ชุดข้อมูลที่ตอบสนอง DP นั้นทนทานต่อการวิเคราะห์ข้อมูลส่วนตัว หรืออีกนัยหนึ่ง ข้อมูลที่ได้รับนั้นแทบไม่มีประโยชน์เลยสำหรับการอนุมานข้อมูลอื่นๆ ในชุดข้อมูลเดียวกัน ด้วยการเพิ่มสัญญาณรบกวนแบบสุ่มให้กับข้อมูลดิบหรือพารามิเตอร์แบบจำลอง DP ให้การรับประกันความเป็นส่วนตัวทางสถิติสำหรับบันทึกแต่ละรายการ ทำให้ข้อมูลไม่สามารถเรียกคืนได้เพื่อปกป้องความเป็นส่วนตัวของเจ้าของข้อมูล
ดังแสดงในรูปด้านล่าง: กระบวนการเรียนรู้แบบรวมศูนย์หลังจากใช้ความเป็นส่วนตัวที่แตกต่างกันในการเข้ารหัสข้อมูลระดับกลาง ข้อมูลระดับกลางที่สร้างโดยทุกฝ่ายจะไม่คำนวณการส่งผ่านข้อความธรรมดาอีกต่อไป แต่เป็นข้อมูลความเป็นส่วนตัวที่มีสัญญาณรบกวนเพิ่มขึ้น เพื่อเพิ่มความปลอดภัย ของกระบวนการฝึกเพศ
▲ เฟรมเวิร์กการเรียนรู้แบบสหพันธรัฐขึ้นอยู่กับการประมวลผลแบบหลายฝ่ายที่ปลอดภัย
ในกรอบ FL วิธีการต่างๆ เช่น การเข้ารหัสแบบโฮโมมอร์ฟิก (HE) และการคำนวณหลายฝ่ายที่ปลอดภัย (MPC) ถูกนำมาใช้กันอย่างแพร่หลาย แต่จะเปิดเผยผลการคำนวณต่อผู้เข้าร่วมและผู้ประสานงานเท่านั้น และไม่เปิดเผยข้อมูลอื่นใดนอกเหนือจากการคำนวณ ผลลัพธ์ระหว่างทำ ข้อมูลเพิ่มเติม
ในความเป็นจริง HE ถูกนำไปใช้กับเฟรมเวิร์ก FL ในลักษณะที่คล้ายคลึงกับเฟรมเวิร์กการเรียนรู้หลายฝ่ายที่ปลอดภัย (MPL) (เฟรมเวิร์กที่ได้รับมาจาก FL เฟรมเวิร์ก MPL มีรายละเอียดด้านล่าง) โดยมีรายละเอียดที่แตกต่างกันเล็กน้อย ในเฟรมเวิร์ก FL นั้น HE ใช้เพื่อปกป้องความเป็นส่วนตัวของพารามิเตอร์โมเดล (เช่น การไล่ระดับสี) ที่โต้ตอบระหว่างผู้เข้าร่วมและผู้ประสานงาน แทนที่จะปกป้องข้อมูลโดยตรงที่โต้ตอบระหว่างผู้เข้าร่วม เช่น HE ที่ใช้ในเฟรมเวิร์ก MPL [1] ใช้ Additive Homomorphism (AHE) ในแบบจำลอง FL เพื่อรักษาความเป็นส่วนตัวของการไล่ระดับสีเพื่อให้มีความปลอดภัยต่อผู้ประสานงานส่วนกลางกึ่งสมบูรณ์
MPC เกี่ยวข้องกับหลายด้านและคงไว้ซึ่งความถูกต้องดั้งเดิมพร้อมการรับประกันความปลอดภัยระดับสูง กนง.รับรองว่าต่างฝ่ายต่างไม่รู้แต่ผล ดังนั้นจึงสามารถใช้ MPC กับโมเดล FL เพื่อการรวมที่ปลอดภัยและปกป้องโมเดลในพื้นที่ ในกรอบ FL ตาม MPC ผู้ประสานงานส่วนกลางไม่สามารถรับข้อมูลท้องถิ่นและการอัปเดตในท้องถิ่น แต่ได้รับผลลัพธ์โดยรวมในแต่ละรอบของการทำงานร่วมกัน อย่างไรก็ตาม หากนำเทคนิค MPC ไปใช้ในเฟรมเวิร์ก FL จะทำให้เกิดค่าใช้จ่ายด้านการสื่อสารและการคำนวณเพิ่มเติมจำนวนมาก
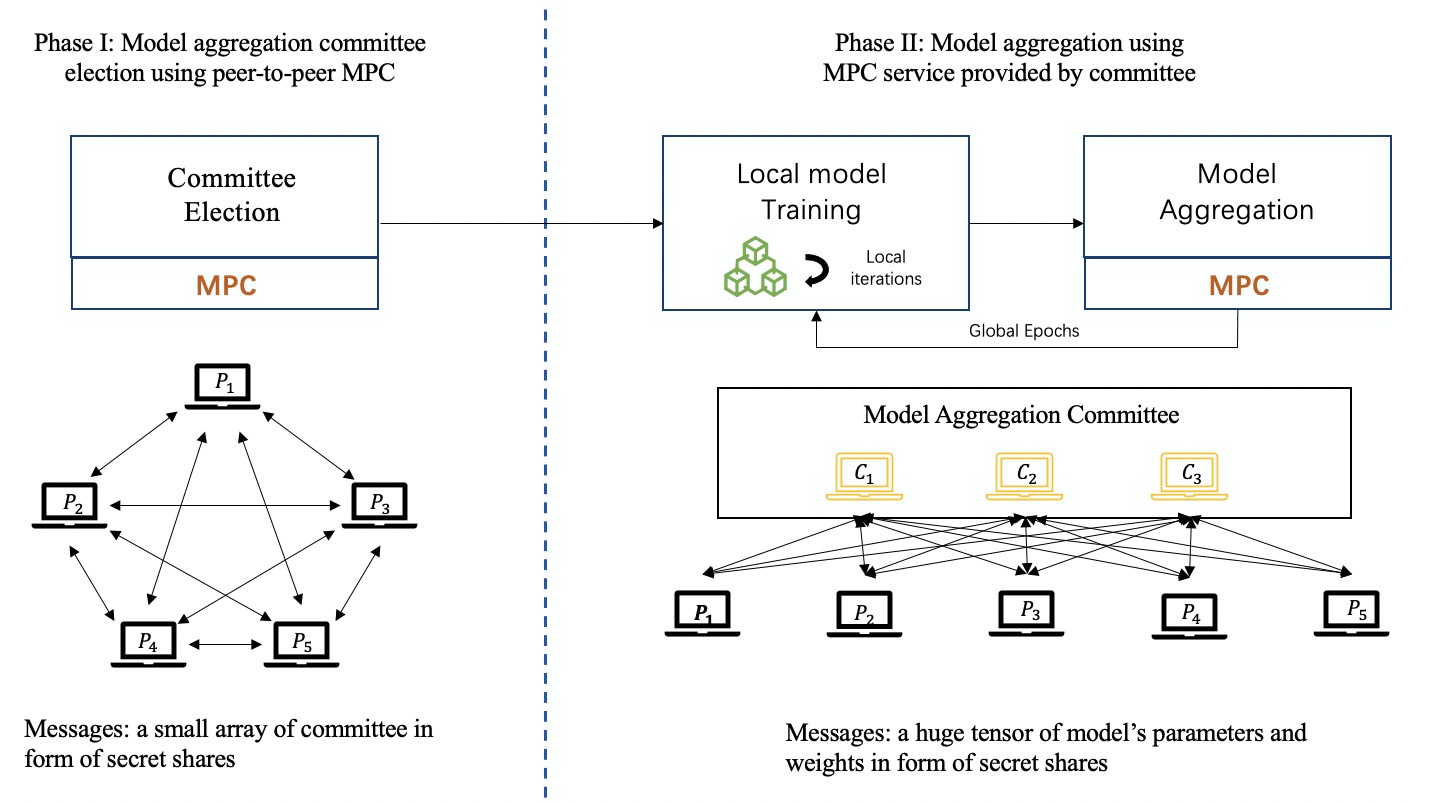
จนถึงตอนนี้ การแบ่งปันความลับ (SS) เป็นโปรโตคอลที่ใช้ MPC กันอย่างแพร่หลายในเฟรมเวิร์ก FL โดยเฉพาะ SS ของ Shamir [24]
ดังแสดงในรูปด้านล่าง: ในกระบวนการฝึกอบรมการเรียนรู้แบบสมาพันธรัฐที่ใช้ MPC กลุ่มของคณะกรรมการจะได้รับเลือกอย่างเป็นธรรมจากผู้เข้าร่วมเป็นผู้ประสานงาน และเทคโนโลยี MPC จะถูกนำมาใช้เพื่อทำงานร่วมกันเพื่อให้งานของการรวมแบบจำลองเสร็จสมบูรณ์
หลังจากแนะนำกรอบ FL ทั้งสามแล้ว เราสรุปความแตกต่างของกรอบของเส้นทางทางเทคนิคต่างๆ ดังนี้:
Federated Learning 2.0 -- การเรียนรู้แบบหลายฝ่ายที่ปลอดภัย
"การเรียนรู้หลายฝ่ายที่ปลอดภัย" ข้างต้น ซึ่งเป็นคำที่มาจากการเรียนรู้แบบรวมศูนย์ พูดง่ายๆ คือ: การเรียนรู้แบบรวมศูนย์โดยไม่มีผู้ทำงานร่วมกันจากบุคคลที่สามเรียกว่าการเรียนรู้แบบหลายฝ่ายที่ปลอดภัย (MPL) ความแตกต่างของ FL ถูกนำมาใช้ กล่าวอีกนัยหนึ่ง บนพื้นฐานของการเรียนรู้แบบสมาพันธ์ การเรียนรู้หลายฝ่ายที่ปลอดภัยจะกำจัดผู้ประสานงานในรูปแบบการเรียนรู้แบบรวมศูนย์แบบดั้งเดิม ลดความสามารถของผู้ประสานงาน แทนที่เครือข่ายดาวเดิมด้วยเครือข่ายเพียร์ทูเพียร์ และทำให้ผู้เข้าร่วมทั้งหมด มีฐานะเหมือนกัน.
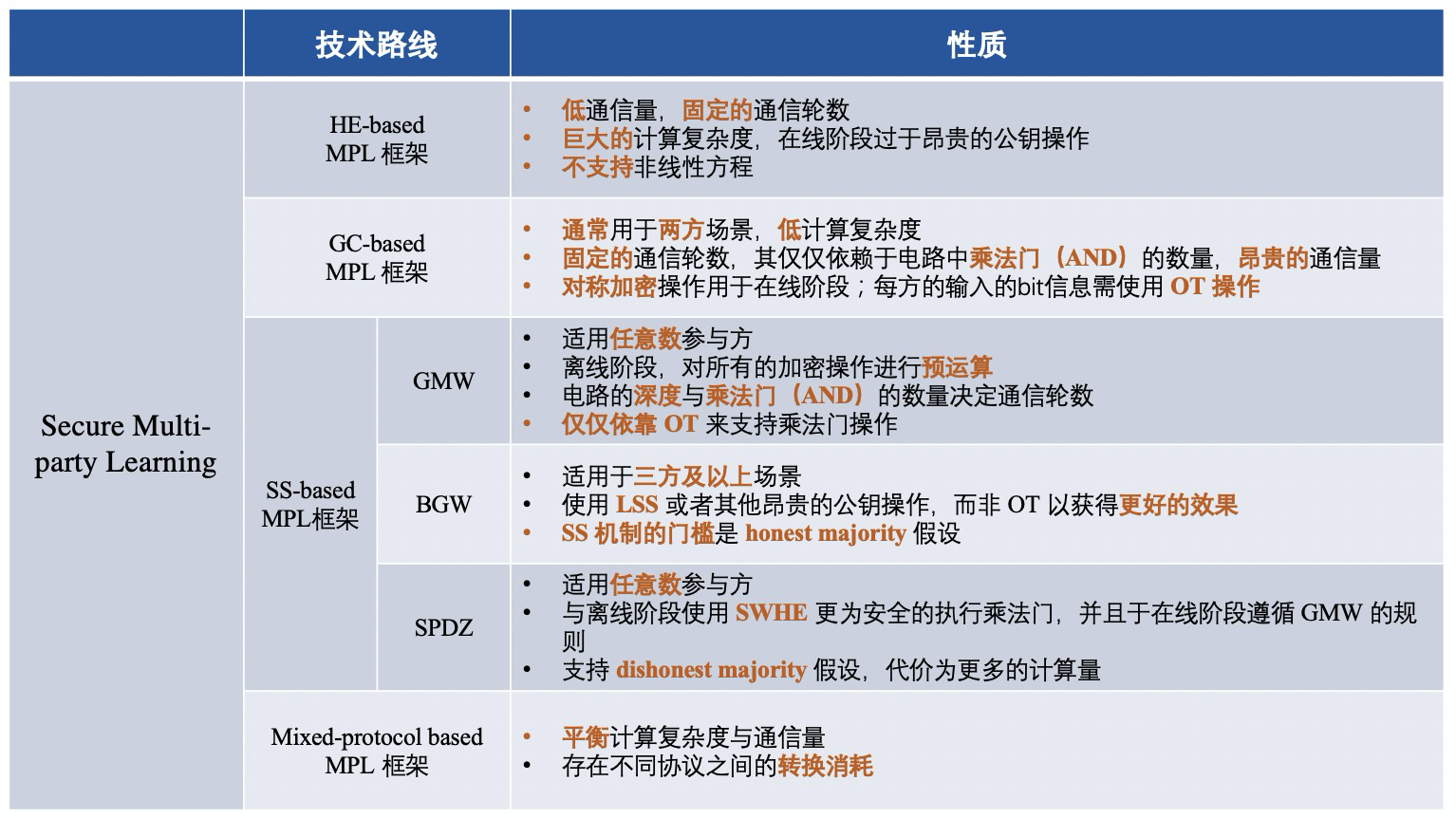
กรอบการทำงานของ MPL แบ่งออกเป็นสี่ประเภท ได้แก่ :
1) กรอบ MPL ขึ้นอยู่กับการเข้ารหัสแบบโฮโมมอร์ฟิค (HE);
2) กรอบ MPL ตามวงจรสับสน (GC);
3) กรอบ MPL ขึ้นอยู่กับการแบ่งปันความลับ (SS)
4) กรอบ MPL ตามโปรโตคอลแบบไฮบริด
เฟรมเวิร์ก MPL ที่แตกต่างกันคือ: เฟรมเวิร์กที่ใช้โปรโตคอลการเข้ารหัสที่แตกต่างกันเพื่อให้มั่นใจถึงความปลอดภัยของข้อมูลระดับกลาง กระบวนการของ MPL นั้นคล้ายกับของ FL โดยประมาณ มาดูโปรโตคอลการเข้ารหัสสี่แบบที่ใช้กัน:
▲ การเข้ารหัสแบบโฮโมมอร์ฟิก (HE)
การเข้ารหัสแบบโฮโมมอร์ฟิก (HE) เป็นรูปแบบหนึ่งของการเข้ารหัสที่เราสามารถดำเนินการเกี่ยวกับพีชคณิตเฉพาะบนไซเฟอร์เท็กซ์ได้โดยตรงโดยไม่ต้องถอดรหัสหรือรู้คีย์ จากนั้นจะสร้างผลลัพธ์ที่เข้ารหัสซึ่งผลลัพธ์ที่ถอดรหัสนั้นเหมือนกันทุกประการกับผลลัพธ์ของการดำเนินการเดียวกันที่ทำกับข้อความธรรมดา
HE สามารถแบ่งออกได้เป็น "สามประเภท": 1) การเข้ารหัสแบบโฮโมมอร์ฟิคบางส่วน (PHE) PHE อนุญาตให้ดำเนินการได้ไม่จำกัดจำนวนเท่านั้น (เพิ่มหรือคูณ) 2)-3) เข้ารหัสแบบจำกัดโฮโมมอร์ฟิค (SWHE) และเข้ารหัสแบบระบุสถานะ (FHE) ที่เหมือนกัน ) สำหรับการบวกและการคูณ SWHE และ FHE พร้อมกันในไซเฟอร์เท็กซ์ SWHE สามารถดำเนินการบางประเภทได้ในจำนวนครั้งที่จำกัด ในขณะที่ FHE สามารถดำเนินการทั้งหมดได้ไม่จำกัดจำนวนครั้ง ความซับซ้อนในการคำนวณของ FHE นั้นแพงกว่า SWHE และ PHE มาก
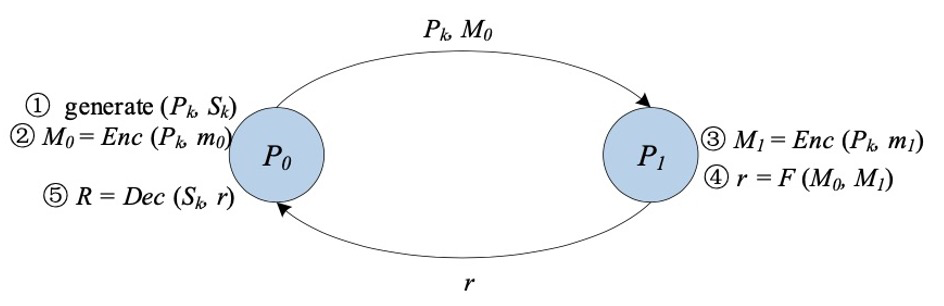
▲ วงจรความสับสน (GC)
วงจรความสับสน[11][12] (GC) หรือที่เรียกว่าวงจรความสับสนของเหยา เป็นเทคโนโลยีพื้นฐานของคอมพิวเตอร์สองฝ่ายที่ปลอดภัยที่เสนอโดยนักวิชาการ Yao Qizhi GC จัดเตรียมโปรโตคอลแบบโต้ตอบสำหรับสองฝ่าย (ผู้อ่านไม่ออกและผู้ประเมิน) เพื่อทำการประเมินฟังก์ชันโดยพลการโดยไม่ได้ตั้งใจ ซึ่งโดยปกติจะแสดงเป็นวงจรบูลีน
การสร้าง GC แบบคลาสสิกประกอบด้วยสามขั้นตอน: การเข้ารหัส การส่งผ่าน และการประเมิน
ขั้นแรก สำหรับแต่ละสายในวงจร obfuscator จะสร้างสตริงสุ่มสองสายเป็นป้ายกำกับ แทนค่าบิต "0" และ "1" ที่เป็นไปได้สองค่าสำหรับสายนั้นตามลำดับ สำหรับแต่ละประตูในวงจร obfuscator จะสร้างตารางความจริง แต่ละเอาต์พุตของตารางความจริงจะถูกเข้ารหัสด้วยป้ายกำกับสองอันที่สอดคล้องกับอินพุต ขึ้นอยู่กับผู้สร้างความสับสนที่จะเลือกฟังก์ชันการสืบทอดคีย์ที่ใช้ป้ายกำกับทั้งสองนี้เพื่อสร้างคีย์สมมาตร
จากนั้นตัวสร้างความสับสนจะตัดแถวของตารางความจริง หลังจากขั้นตอนการทำให้งงงวยสิ้นสุดลงแล้ว คนทำสิ่งที่สับสนจะผ่านตารางที่คลุมเครือและป้ายกำกับบรรทัดอินพุตที่สอดคล้องกับอินพุตนั้นไปยังผู้ประเมิน
นอกจากนี้ ผู้ประเมินยังได้รับป้ายชื่อที่สอดคล้องกับข้อมูลที่พวกเขาป้อนอย่างปลอดภัยผ่านการถ่ายโอนแบบลืมเลือน (Oblivious Transfer [13, 14, 15]) ด้วยตารางที่ทำให้สับสนและป้ายกำกับของบรรทัดอินพุต ผู้ประเมินมีหน้าที่รับผิดชอบในการถอดรหัสตารางที่ทำให้งงงวยซ้ำๆ จนกว่าจะได้ผลลัพธ์สุดท้ายของฟังก์ชัน
▲ การแบ่งปันความลับ (SS)
โปรโตคอล GMW เป็นโปรโตคอลการคำนวณหลายฝ่ายที่ปลอดภัยตัวแรก ซึ่งช่วยให้หลายฝ่ายสามารถคำนวณฟังก์ชันที่สามารถแสดงเป็นวงจรบูลีนหรือวงจรเลขคณิตได้อย่างปลอดภัย ยกตัวอย่างวงจรบูลีน ทุกฝ่ายใช้โครงร่าง SS ที่ใช้ XOR เพื่อแบ่งปันอินพุต และฝ่ายต่างๆ โต้ตอบเพื่อคำนวณผลลัพธ์ ประตูต่อประตู โปรโตคอลที่ใช้ GMW ไม่จำเป็นต้องสร้างความสับสนให้กับตารางความจริง แต่ต้องดำเนินการ XOR และ AND ในการคำนวณเท่านั้น ดังนั้นจึงไม่จำเป็นต้องดำเนินการเข้ารหัสและถอดรหัสแบบสมมาตร นอกจากนี้ โปรโตคอลที่ใช้ GMW อนุญาตให้มีการคำนวณล่วงหน้าของการดำเนินการเข้ารหัสทั้งหมด แต่ต้องมีการโต้ตอบหลายรอบระหว่างหลายฝ่ายในช่วงออนไลน์ ดังนั้น GMW จึงได้รับประสิทธิภาพที่ดีในเครือข่ายที่มีเวลาแฝงต่ำ
โปรโตคอล BGW เป็นโปรโตคอลการประมวลผลหลายฝ่ายที่ปลอดภัยสำหรับวงจรเลขคณิตที่มีมากกว่าสามฝ่าย โครงสร้างโดยรวมของข้อตกลงคล้ายกับ GMW โดยทั่วไปแล้ว BGW สามารถใช้คำนวณวงจรเลขคณิตใดๆ ก็ได้ คล้ายกับโปรโตคอล GMW สำหรับเกทการบวกในวงจร การคำนวณสามารถทำได้ภายในเครื่อง ในขณะที่สำหรับเกทการคูณ ทุกฝ่ายจำเป็นต้องโต้ตอบ อย่างไรก็ตาม GMW และ BGW ต่างกันที่รูปแบบการโต้ตอบ แทนที่จะใช้ OT สำหรับการสื่อสารระหว่างฝ่าย BGW อาศัย SS เชิงเส้น (เช่น SS ของ Shamir) เพื่อรองรับการคูณ แต่ BGW อาศัยความซื่อสัตย์เป็นส่วนใหญ่ โปรโตคอล BGW สามารถต่อสู้กับการลบ t
SPDZ เป็นโปรโตคอลการคำนวณส่วนใหญ่ที่ไม่ซื่อสัตย์ที่เสนอโดย Damgard และคณะ ซึ่งสามารถรองรับการคำนวณวงจรเลขคณิตที่มีมากกว่าสองฝ่าย แบ่งเป็นเฟสออฟไลน์และเฟสออนไลน์ ข้อได้เปรียบของ SPDZ คือการคำนวณการเข้ารหัสคีย์สาธารณะที่มีราคาแพงสามารถทำได้ในเฟสออฟไลน์ ในขณะที่เฟสออนไลน์ใช้ข้อมูลดั้งเดิมที่มีราคาถูกและปลอดภัยตามทฤษฎีเท่านั้น SWHE ใช้เพื่อดำเนินการคูณแบบปลอดภัยในรอบคงที่ในเฟสออฟไลน์ เฟสออนไลน์ของ SPDZ มีลักษณะเป็นเส้นตรง เป็นไปตามกระบวนทัศน์ของ GMW และใช้การแบ่งปันแบบลับบนฟิลด์จำกัดเพื่อความปลอดภัย SPDZ สามารถต่อสู้กับ t<=n ฝ่ายเสียหายของฝ่ายตรงข้ามที่เป็นอันตรายได้มากที่สุด โดยที่ t คือจำนวนของฝ่ายตรงข้าม และ n คือจำนวนของฝ่ายคอมพิวเตอร์
โปรโตคอลการเข้ารหัสแบบรวมศูนย์จะถูกสรุปเป็นขั้นตอน และความแตกต่างของเฟรมเวิร์กที่สอดคล้องกับเส้นทางทางเทคนิคที่แตกต่างกันมีดังนี้:
การเรียนรู้แบบสมาพันธ์ 3.0 -- การเรียนรู้แบบกลุ่ม
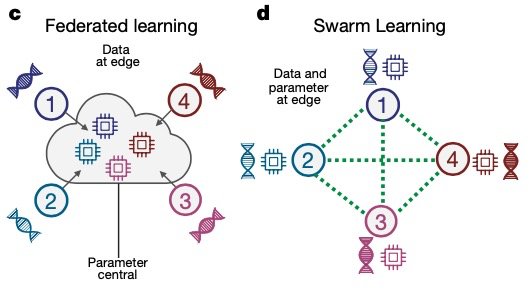
ในปี 2021 Joachim Schultze จาก University of Bonn และหุ้นส่วนของเขาได้เสนอ "ระบบการเรียนรู้ของเครื่องแบบกระจายอำนาจ" ที่เรียกว่า Swarm Learning (การเรียนรู้แบบกลุ่ม) ซึ่งเป็นวิวัฒนาการเพิ่มเติมและการอัปเกรดตาม MPL ซึ่งแทนที่ระบบระหว่างสถาบันในปัจจุบัน รวมศูนย์การแบ่งปันข้อมูลในการวิจัยทางการแพทย์ Swarm Learning แบ่งปันพารามิเตอร์ผ่านเครือข่าย Swarm สร้างแบบจำลองโดยอิสระจากข้อมูลในเครื่องของผู้เข้าร่วมแต่ละคน และใช้เทคโนโลยีบล็อกเชนเพื่อใช้มาตรการที่เข้มงวดกับผู้เข้าร่วมที่ไม่ซื่อสัตย์ซึ่งพยายามทำลายเครือข่าย Swarm
เมื่อเปรียบเทียบกับ FL และ MPL แล้ว Swarm Learning นำเทคโนโลยีบล็อกเชนเข้าสู่กระบวนการฝึกอบรมของการเรียนรู้แบบสมาพันธ์ และแทนที่บุคคลที่สามที่เชื่อถือได้ด้วยบล็อกเชนเพื่อมีบทบาทในการทำงานร่วมกันในการฝึกอบรม
【บทสรุปและอนาคต】▲ การเปรียบเทียบเส้นทางเทคโนโลยีการเรียนรู้ของสมาพันธ์
ตลอดอดีตและปัจจุบันของ federated learning มันมีเส้นทางทางเทคนิคที่หลากหลายในการแก้ปัญหา หลังจากสรุป การเรียนรู้ของเครื่องแบบกระจาย (DML), การเรียนรู้แบบรวมศูนย์ (FL), การเรียนรู้หลายฝ่ายที่ปลอดภัย (MPL), การเรียนรู้แบบกลุ่ม (SL ) ข้อแตกต่างอย่างกว้างๆ ดังนี้
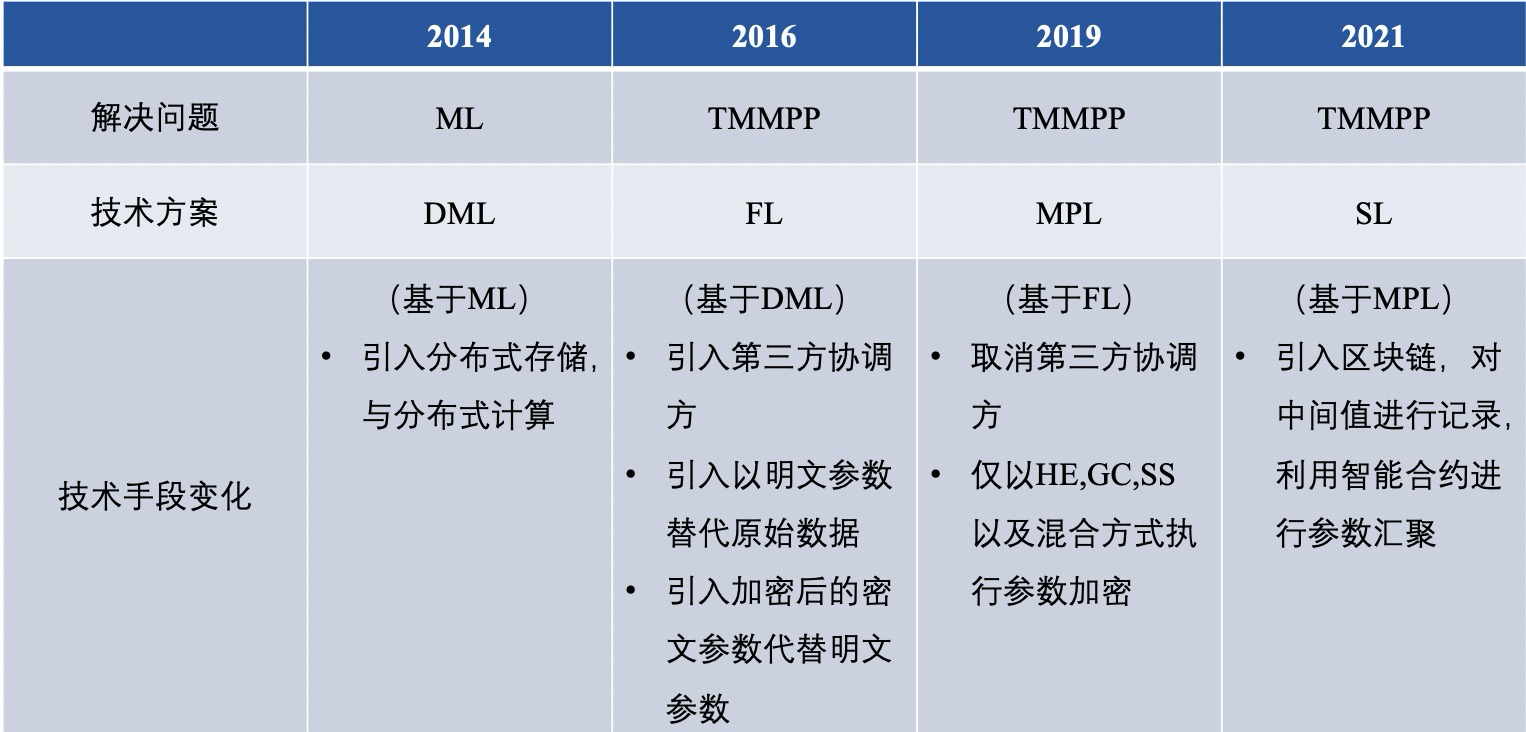
ในบรรดาสิ่งเหล่านี้ เราทำการเปรียบเทียบอย่างลึกซึ้งยิ่งขึ้นระหว่าง FL และ MPL แบบดั้งเดิม ซึ่งสะท้อนให้เห็นในหกประเด็นต่อไปนี้:
1) การคุ้มครองความเป็นส่วนตัว
โปรโตคอล MPC ที่ใช้ในกรอบ MPC ให้การรับประกันความปลอดภัยสูงสำหรับทั้งสองฝ่าย อย่างไรก็ตาม เฟรมเวิร์ก FL ที่ไม่ได้เข้ารหัสจะแลกเปลี่ยนพารามิเตอร์โมเดลระหว่างเจ้าของข้อมูลและเซิร์ฟเวอร์ในรูปแบบข้อความล้วน และข้อมูลที่ละเอียดอ่อนอาจรั่วไหลได้เช่นกัน
2) วิธีการสื่อสาร
ใน MPL การสื่อสารระหว่างเจ้าของข้อมูลมักจะอยู่ในรูปแบบเพียร์ทูเพียร์โดยไม่มีบุคคลที่สามที่เชื่อถือได้ ในขณะที่ FL มักจะอยู่ในรูปแบบไคลเอนต์-เซิร์ฟเวอร์ที่มีเซิร์ฟเวอร์รวมศูนย์ กล่าวอีกนัยหนึ่ง เจ้าของข้อมูลแต่ละคนใน MPL มีสถานะเท่ากัน ในขณะที่เจ้าของข้อมูลและเซิร์ฟเวอร์ส่วนกลางใน FL ไม่เท่ากัน
3) ค่าใช้จ่ายในการสื่อสาร
สำหรับ FL เนื่องจากการสื่อสารระหว่างเจ้าของข้อมูลสามารถประสานงานโดยเซิร์ฟเวอร์ส่วนกลาง ค่าใช้จ่ายในการสื่อสารจึงน้อยกว่ารูปแบบจุดต่อจุดของ MPL โดยเฉพาะอย่างยิ่งเมื่อเจ้าของข้อมูลมีจำนวนสูงมาก
4) รูปแบบข้อมูล
ปัจจุบัน การตั้งค่าที่ไม่ใช่ IID ไม่ได้รับการพิจารณาในโซลูชันของ MPL อย่างไรก็ตาม ในโซลูชันของ FL เนื่องจากเจ้าของข้อมูลแต่ละรายฝึกโมเดลภายในเครื่อง จึงง่ายต่อการปรับให้เข้ากับการตั้งค่าที่ไม่ใช่ IID
5) ความถูกต้องของแบบฝึก
ใน MPL มักจะไม่สูญเสียความแม่นยำในโมเดลสากล แต่ถ้า FL ใช้ DP เพื่อปกป้องความเป็นส่วนตัว โมเดลสากลมักจะสูญเสียความแม่นยำไปบางส่วน
6) สถานการณ์การใช้งาน
เมื่อรวมกับการวิเคราะห์ข้างต้น จะพบว่า MPL เหมาะสำหรับสถานการณ์ที่มีความปลอดภัยและความแม่นยำสูงกว่า ในขณะที่ FL เหมาะสำหรับสถานการณ์ที่ต้องการประสิทธิภาพการทำงานสูงกว่า และใช้สำหรับเจ้าของข้อมูลจำนวนมากขึ้น
▲ การเปรียบเทียบหลายฝ่ายของกรอบการเรียนรู้แบบสมาพันธ์
การเปรียบเทียบเนื้อหาของกรอบพื้นฐาน FL ตั้งแต่ปี 2559
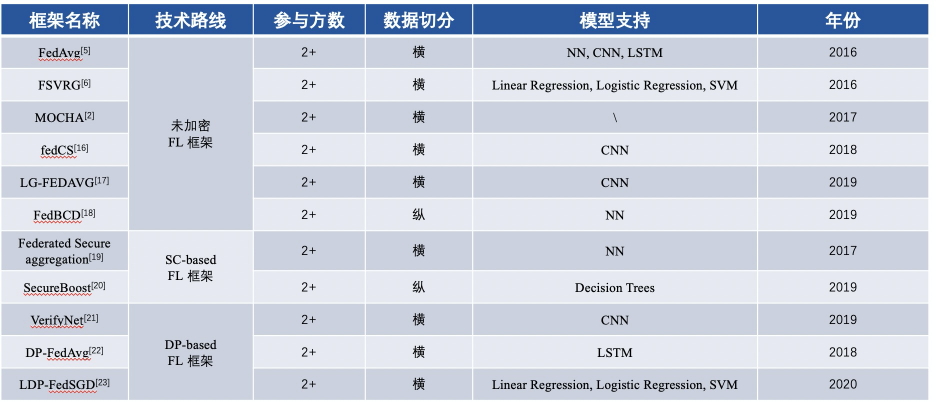
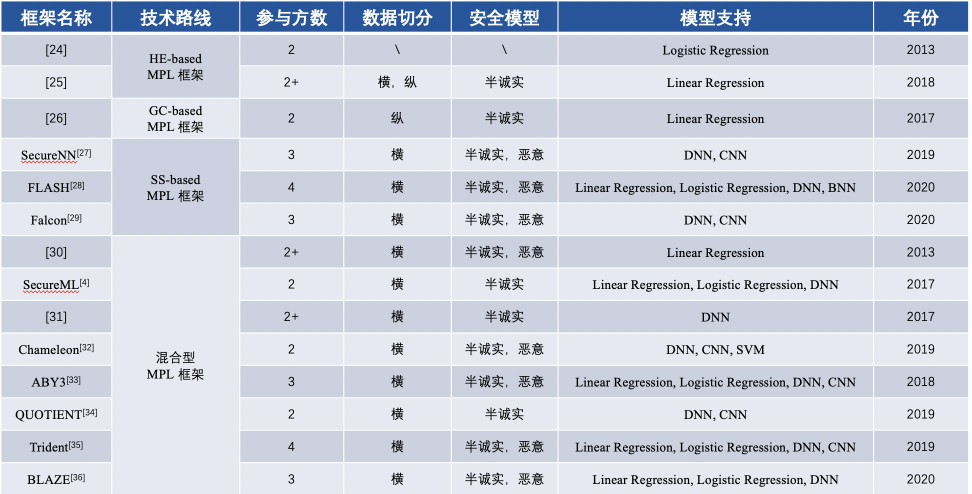
การเปรียบเทียบเนื้อหาของกรอบพื้นฐาน MPL ที่ใช้ FL
ด้วยการพัฒนาอย่างต่อเนื่องของเทคโนโลยีการเรียนรู้แบบรวมศูนย์ แพลตฟอร์มการเรียนรู้แบบรวมศูนย์สำหรับความท้าทายที่แตกต่างกันกำลังเกิดขึ้น แต่พวกเขายังไม่ถึงขั้นเต็มที่ ในปัจจุบัน ในด้านวิชาการ แพลตฟอร์มการเรียนรู้แบบรวมศูนย์ส่วนใหญ่แก้ปัญหาของข้อมูลที่ไม่สมดุลและกระจายไม่สม่ำเสมอ ในขณะที่อุตสาหกรรมมุ่งเน้นไปที่โปรโตคอลการเข้ารหัสเพื่อแก้ปัญหาความปลอดภัยของการเรียนรู้แบบรวมศูนย์
ทั้งสองฝ่ายจับมือกัน และอัลกอริธึมการเรียนรู้ของเครื่องที่มีอยู่จำนวนมากได้รับการรวมศูนย์แล้ว แต่ก็ยังไม่สมบูรณ์และยังไม่ถึงขั้นที่จะนำไปผลิตได้ ในช่วงไม่กี่ปีที่ผ่านมา การวิจัยและการดำเนินการตามกรอบการเรียนรู้แบบสมาพันธ์ยังอยู่ในช่วงเริ่มต้น ซึ่งต้องใช้ความพยายามและความก้าวหน้าอย่างต่อเนื่อง
เกี่ยวกับผู้เขียน
Yan Yang Federal Learning ผู้บุกเบิก
อ้างอิง
อ้างอิง
[1] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[2] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[3] D. Demmler, T. Schneider, and M. Zohner, “Aby-a framework for efficient mixed-protocol secure two-party computation.” in Proceedings of The Network and Distributed System Security Symposium, 2015.
[4] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy- preserving machine learning,” in Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 19–38.
[5] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Feder- ated learning of deep networks using model averaging,” CoRR, vol. abs/1602.05629, 2016.
[6] J. Konecˇny`, H. B. McMahan, D. Ramage, and P. Richta ́rik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016.
[7] J. Konecˇny`, H. B. McMahan, F. X. Yu, P. Richta ́rik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communica- tion efficiency,” arXiv preprint arXiv:1610.05492, 2016.
[8] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” in Proceedings of Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
[9] A. C.-C. Yao, “How to generate and exchange secrets,” in Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, pp. 162–167.
[10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proceedings of Advances in Neural Information Processing Systems, 2017, pp. 4424–4434.
[11] R. Fakoor, F. Ladhak, A. Nazi, and M. Huber, “Using deep learning to enhance cancer diagnosis and classification,” in Proceedings of the international conference on machine learning, vol. 28. ACM New York, USA, 2013.
[12] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proceedings of European conference on computer vision. Springer, 2016, pp. 525–542.
[13] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
[14] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[15] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[16] T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwith heterogeneous resources in mobile edge,” in Proceedings of 2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–7.
[17] P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,” arXiv preprint arXiv:2001.01523, 2020.
[18] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient vertical federated learning framework,” arXiv preprint arXiv:1912.11187, 2019.
[19] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre- gation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191.
[20] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, and Q. Yang, “Se- cureboost: A lossless federated learning framework,” arXiv preprint arXiv:1901.08755, 2019.
[21] G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “Verifynet: Secure and verifiable federated learning,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019.
[22] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learn- ing differentially private recurrent language models,” arXiv preprint arXiv:1710.06963, 2017.
[23] Y. Zhao, J. Zhao, M. Yang, T. Wang, N. Wang, L. Lyu, D. Niyato, and K. Y. Lam, “Local differential privacy based federated learning for internet of things,” arXiv preprint arXiv:2004.08856, 2020.
[24] M. Hastings, B. Hemenway, D. Noble, and S. Zdancewic, “Sok: General purpose compilers for secure multi-party computation,” in Proceedings of 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1220–1237.
[25] I. Giacomelli, S. Jha, M. Joye, C. D. Page, and K. Yoon, “Privacy-
preserving ridge regression with only linearly-homomorphic encryp- tion,” in Proceedings of 2018 International Conference on Applied Cryptography and Network Security. Springer, 2018, pp. 243–261.
[26] A. Gasco ́n, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Privacy-preserving distributed linear regression on high- dimensional data,” Proceedings on Privacy Enhancing Technologies, vol. 2017, no. 4, pp. 345–364, 2017.
[27] S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 26–49, 2019.
[28] M. Byali, H. Chaudhari, A. Patra, and A. Suresh, “Flash: fast and robust framework for privacy-preserving machine learning,” Proceedings on Privacy Enhancing Technologies, vol. 2020, no. 2, pp. 459–480, 2020.
[29] S. Wagh, S. Tople, F. Benhamouda, E. Kushilevitz, P. Mittal, and T. Rabin, “Falcon: Honest-majority maliciously secure framework for private deep learning,” arXiv preprint arXiv:2004.02229, 2020.
[30] V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, and N. Taft, “Privacy-preserving ridge regression on hundreds of millions of records,” pp. 334–348, 2013.
[31] M. Chase, R. Gilad-Bachrach, K. Laine, K. E. Lauter, and P. Rindal, “Private collaborative neural network learning.” IACR Cryptol. ePrint Arch., vol. 2017, p. 762, 2017.
[32] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation frame- work for machine learning applications,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, pp. 707–721.
[33] P. Mohassel and P. Rindal, “Aby3: A mixed protocol framework for machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 35– 52.
[34] N. Agrawal, A. Shahin Shamsabadi, M. J. Kusner, and A. Gasco ́n, “Quotient: two-party secure neural network training and prediction,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 1231–1247.
[35] R. Rachuri and A. Suresh, “Trident: Efficient 4pc framework for pri- vacy preserving machine learning,” arXiv preprint arXiv:1912.02631, 2019.
[36] A. Patra and A. Suresh, “Blaze: Blazing fast privacy-preserving ma- chine learning,” arXiv preprint arXiv:2005.09042, 2020.
[37] Song L, Wu H, Ruan W, et al. SoK: Training machine learning models over multiple sources with privacy preservation[J]. arXiv preprint arXiv:2012.03386, 2020.


