
일반인들은 AI 시대의 자본 물결에서 어떻게 한몫을 차지할 수 있을까
- 핵심 관점: AI 산업의 가치 사슬은 에너지, 칩, 클라우드 컴퓨팅, 모델, 애플리케이션의 5계층 기술 스택으로 나타나며, 현재 대부분의 자본은 대중이 주목하는 표면적 애플리케이션이 아닌 하부 인프라(전체 3계층)로 흐르고 있다; 진정한 이익도 인프라 계층에 집중되어 "수익은 위로 흐르고, 자본은 아래로 침전된다"는 구도를 형성하고 있다.
- 핵심 요소:
- 자본의 인프라 유입: 2026년 4대 클라우드 업체의 자본 지출이 6500-7000억 달러에 이를 것으로 예상되며, 이 중 약 75%(4500억 달러)가 데이터 센터, 칩, 전력 시스템과 같은 AI 인프라에 투자될 것이다.
- 모델 계층의 높은 성장과 높은 소비: OpenAI의 연간 수익은 2년 만에 10배 증가하여 200억 달러에 이르렀지만, 2026년에는 170억 달러를 소진할 것으로 예상되며, 추론 비용이 높아 이익이 하부 컴퓨팅 파워 비용에 의해 압박받고 있다.
- 인프라 계층의 높은 집중도와 수익성: Nvidia는 약 92%의 AI GPU 시장 점유율을 차지하며, 총이익률은 약 75%에 이른다; TSMC는 약 70%의 칩 제조를 독점하고 있다; ASML은 유일한 EUV 리소그래피 장비 공급업체이다.
- 역사적 패턴 유사성: 현재의 AI 발전은 전력 혁명, 인터넷 초기와 유사하며, 가장 먼저 부를 창출하는 사람들은 최종 애플리케이션이 아닌 '삽을 파는' 인프라 건설자들이다.
- 애플리케이션 계층의 치열한 경쟁과 얇은 이익: 애플리케이션 계층의 시장 규모는 거대하지만 현재 가장 이익이 얇고 경쟁이 가장 불확실하며, 독특한 데이터 호를 가진 기업이 최종적으로 승리할 수 있다.
- 주요 위험: 자본의 잘못된 배분(막대한 투자가 수익 성장으로 지지받지 못할 수 있음), 공급망의 높은 집중도(지정학적 충격 등 위험), 그리고 DeepSeek과 같은 효율적인 오픈소스 모델이 인프라 투자 논리를 약화시킬 수 있다는 점을 포함한다.
원문 제목: If you don't understand AI by the end of this, the next decade will confuse you
원문 저자: Anish Moonka
원문 번역: Peggy, BlockBeats
편집자 주: 사람들이 AI를 논할 때, 주의는 종종 가장 눈에 띄는 곳에 집중됩니다: 채팅봇, AI 어시스턴트, 그리고 다양한 새로운 애플리케이션. 그러나 이러한 제품 뒤에서, 더 깊은 차원의 산업 재구성이 진행 중입니다. 전력, 반도체에서 데이터 센터, 그리고 모델과 애플리케이션에 이르기까지, AI는 사실상 여러 계층의 인프라로 구성된 기술 스택이며, 자본과 이익의 흐름도 표면적으로 보이는 것보다 훨씬 복잡합니다.
이 글은 'AI 5계층 구조'의 관점에서 이 가치 사슬을 체계적으로 정리합니다: 왜 수천억 달러가 에너지, 반도체, 클라우드 인프라로 흘러가는지; 왜 모델 회사들이 고속 성장 중에도 여전히 막대한 자금을 소모하는지; 그리고 이 기술 혁명에서 진정한 가치가 어느 부분에 먼저 집중될 수 있는지.
AI를 전력 혁명, 인터넷 인프라 건설과 같은 역사적 주기와 비교함으로써, 저자는 핵심 질문에 답하려 합니다: 세계 산업 구조를 재형성할 가능성이 있는 이 기술 물결에서, 자본은 어디로 흐르며, 일반인은 이 AI 부의 기회에 어떻게 참여할 수 있을까.
이하 원문:
대부분의 사람들은 AI가 단지 채팅봇이라고 생각합니다.
이런 생각을 이해할 수 있습니다. ChatGPT를 열어 이메일 수정을 부탁하면, 즉시 완료해줍니다. 마치 마법 같죠. 그런 다음 페이지를 닫고, AI가 무엇인지 이미 이해했다고 생각합니다. 하지만 이는 Visa 신용카드로 레스토랑에서 한 번 결제한 후, Visa가 어떻게 돈을 버는지 이해했다고 생각하는 것과 같습니다. 당신은 제품을 사용했을 뿐, 그 뒤의 시스템을 보지 못한 것입니다.
지난해 대부분의 시간 동안, 저는 AI의 진정한 이익이 정확히 어디로 흐르는지 파악하려고 노력했습니다. 그리고 약간 당혹스러운 사실은: 제가 계속 잘못된 계층을 보고 있다는 것을 깨닫는 데 오랜 시간이 걸렸다는 점입니다. 저는 계속 ChatGPT, Claude, Gemini처럼 직접 접할 수 있는 것들만 바라보고 있었습니다.
그동안 7000억 달러는 제가 이름도 모르는 다른 인프라로 조용히 흘러 들어갔습니다: 들어본 적 없는 칩, 만들어낸 것 같은 포장 기술 약어, 냉각 시스템, 발전소. 텍사스, 아이오와, 하이데라바드에서는 데이터 센터 건설을 위해 막대한 양의 콘크리트가 부어지고 있습니다.
1년 전, 제 주변에서는 거의 아무도 이런 이야기를 하지 않았습니다. 하지만 지금은 모두가 이야기하기 시작했습니다.
이 글은 꽤 길 것입니다. 지금 다 읽을 시간이 없다면, 나중에 읽을 수 있도록 저장해 두세요.
저는 AI의 가치 사슬 전체를 안내하고 싶습니다: 데이터 센터에 전력을 공급하는 전력부터 시작하여, 당신의 휴대폰 안의 애플리케이션까지.
그리고 평생 상장 기업의 연차 보고서를 한 번도 읽어본 적이 없는 사람도 이해할 수 있는 방식으로 설명하겠습니다. 모든 용어를 설명할 것이며; 모든 판단에는 실제 데이터를 제시할 것이며; 제가 여전히 확신하지 못하는 부분에 대해서는 솔직히 말씀드리겠습니다. 왜냐하면 정말로 그런 부분들이 있기 때문입니다.
그럼 시작해 보겠습니다.
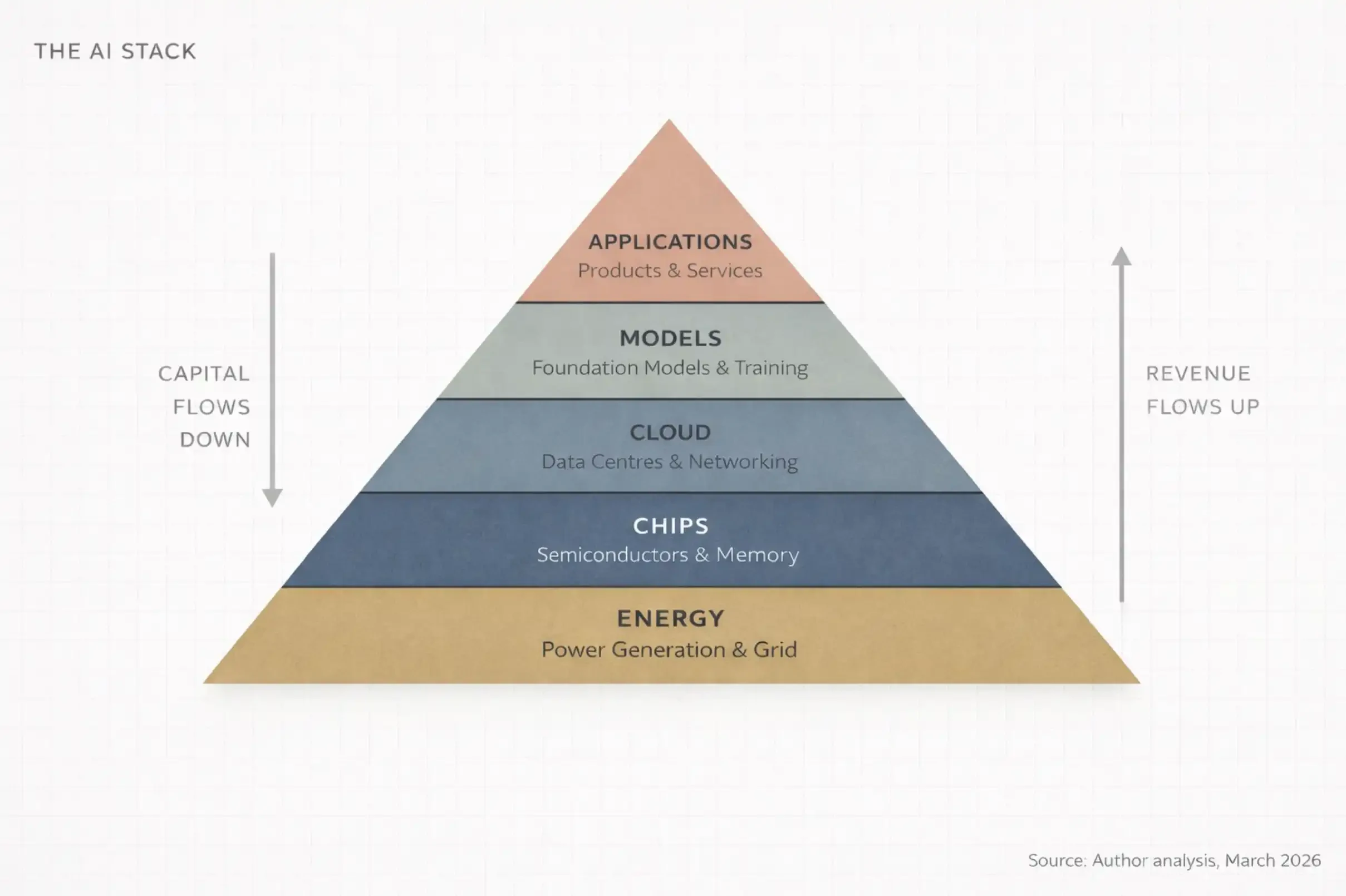
1. 5단계 케이크 (왜 아무도 아래 4단계를 논하지 않는가)
AI는 인프라입니다. 인터넷처럼, 전력처럼, 그것은 공장이 필요합니다. — Jensen Huang
대부분의 사람들이 AI를 이해하는 방식은 이렇습니다: 똑똑한 컴퓨터가 질문에 답하는 것.
이는 인터넷을 '동영상을 볼 수 있는 곳'이라고 말하는 것과 같습니다. 기술적으로는 틀리지 않지만, 완전히 핵심을 놓치고 있습니다.
2026년 1월 World Economic Forum에서 Jensen Huang은 AI를 5계층 시스템으로 묘사했습니다:
에너지 (Energy)
칩 (Chips)
클라우드 컴퓨팅 (Cloud)
모델 (Models)
애플리케이션 (Applications)
그는 이 전체 시스템을 '인류 역사상 가장 규모가 큰 인프라 건설'이라고 불렀습니다.
먼저 이 단어를 생각해 보세요: 인프라 (Infrastructure).
도로. 전력망. 상수도 시스템. 이것들은 현대 문명이 작동하게 하지만, 사람들은 보통 그것들이 고장 났을 때만 주목합니다.
AI도 똑같이 변하고 있습니다, 보이지 않고, 필수불가결하며, 건설 비용이 극도로 높은 것으로. 저는 이 전체 구조를 AI 스택 (AI Stack)이라고 부릅니다. 이는 5개의 계층으로 구성되어 있으며, 한 계층이 다른 계층 위에 쌓여 있고, 각 계층은 위의 계층을 지지하며, 자금은 이 계층들 사이에서 양방향으로 흐릅니다.
제가 줄 수 있는 가장 간단한 버전은 다음과 같습니다:
에너지 (Energy), 컴퓨터를 작동시키기 위해 전력이 필요하며, 그것도 막대한 양의 전력이 필요합니다.
칩 (Chips), 계산에 특화된 프로세서가 필요합니다. 이것은 당신의 노트북 안의 CPU가 아닙니다.
클라우드 (Cloud), 이 칩들로 가득 찬 거대한 창고형 데이터 센터가 필요하며, 초고속 네트워크로 연결되어 있어야 합니다.
모델 (Models), 진짜 AI 소프트웨어가 필요합니다 — 데이터에서 패턴을 학습하는 '지능적인 뇌'입니다.
애플리케이션 (Applications), 사람들이 실제로 사용하는 제품이 필요합니다, 예를 들어 ChatGPT, Google Search, 또는 은행의 사기 방지 시스템처럼.
5계층(애플리케이션 계층)만 논하는 어떤 AI 토론도 전체 현실의 80%를 놓치고 있는 것입니다. 그리고 만약 당신이 투자자, 창업자, 또는 단지 세계의 미래 방향을 이해하려는 사람이라면, 진정으로 중요한 점은 돈이 이 5계층에 고르게 분배되지 않는다는 것입니다. 그것은 집중되고, 복리로 증가하며, 극소수의 핵심 지점으로 흐릅니다.
그리고 오늘날, 이 자금은 대부분의 사람들이 전혀 눈치채지 못하는 곳에 집중되고 있습니다.
2. 자금 흐름 추적 (답은 당신이 생각하는 곳에 있지 않다)
사람들의 관심은 거의 항상 애플리케이션 계층에 집중됩니다. ChatGPT, GitHub Copilot, Claude, Perplexity.
이것들은 모두 당신이 직접 사용할 수 있는 제품들이므로, AI 이야기는 대략 이런 애플리케이션들일 것이라고 쉽게 생각하게 만듭니다.
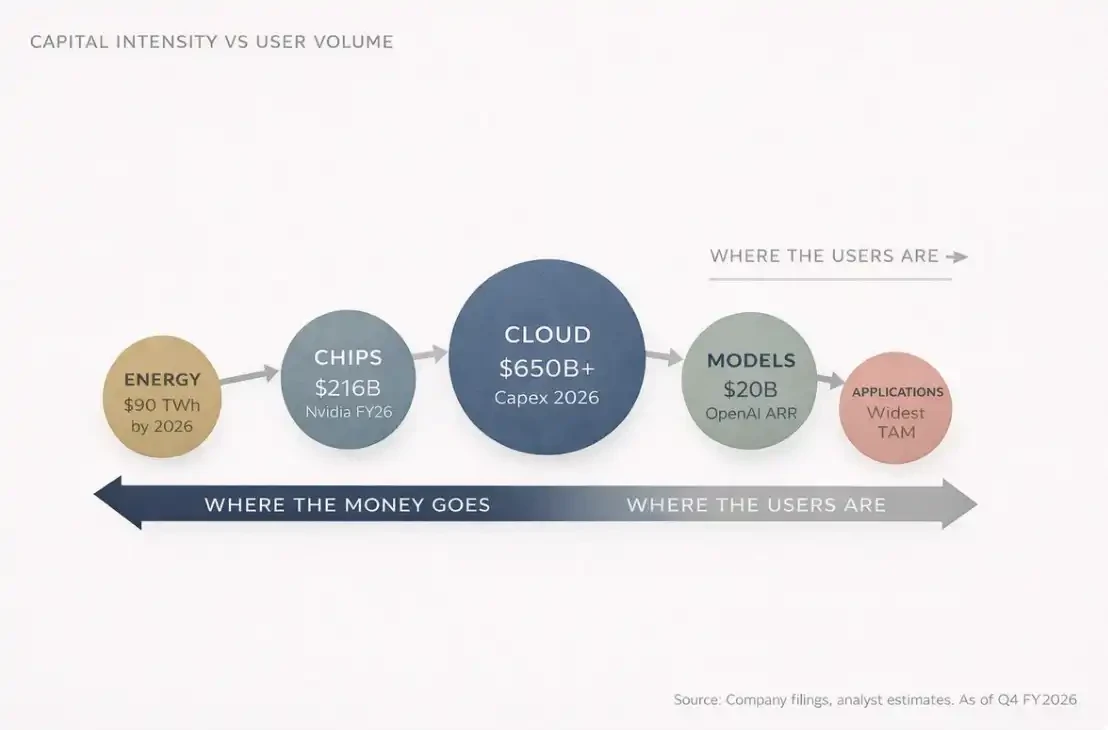
하지만 대부분의 사람들이 간과하는 한 가지가 있습니다. 2026년까지, 세계 4대 클라우드 컴퓨팅 회사(Amazon, Microsoft, Google, Meta)의 연간 자본 지출(CapEx) 총액은 6500억 달러에서 7000억 달러에 이를 것으로 예상됩니다.
이것은 1년 동안, 4개 회사 합계입니다.
이 숫자는 스위스의 1년 전체 GDP와 대략 비슷합니다. 그리고 그 중 약 75%, 약 4500억 달러가 AI 인프라에 직접 투자될 것입니다.
채팅봇이 아니고, 애플리케이션이 아닙니다. 건물, 칩, 광섬유와 네트워크, 냉각 시스템, 칵테일 파티에서 거의 아무도 이야기하지 않는 것들입니다. 이것이 바로 돈이 거기에 있다는 것을 말해줍니다.
왜냐하면 자세히 생각해 보면, 누구든지 ChatGPT를 사용하기 전에, 누군가는 먼저 한 가지 일을 해야 합니다, 쇼핑몰 크기의 데이터 센터를 건설하고, 그 안에 수만 개의 전용 프로세서를 설치하고, 대부분의 회사 시가총액보다 훨씬 비싼 네트워크 장비로 연결하고, 작은 도시에 전력을 공급할 수 있을 만큼의 전력을 전체 시스템에 공급해야 합니다. 그리고 매일 그렇게 작동해야 합니다.
이것이 1계층부터 3계층까지입니다: 에너지, 칩, 클라우드 인프라, 이것들은 보이지 않는 계층들이며, 진정으로 막대한 자본이 배치되는 곳입니다.
누군가는 물을지도 모릅니다: '그럼 OpenAI는요? 그들은 이미 수십억 달러를 벌지 않았나요?'
사실입니다.
2025년 말까지, OpenAI의 연간화된 상시 수익(ARR)은 200억 달러에 달했습니다. 그리고 1년 전에는 60억 달러였고, 그 전 해에는 20억 달러에 불과했습니다.
2년 동안 10배 성장, 인간 비즈니스 역사상 이 규모에서 이렇게 빠른 수익 성장을 이룬 회사는 거의 없습니다.
하지만 문제는 비용도 마찬가지로 엄청나다는 점입니다.
2025년: OpenAI는 약 90억 달러의 현금을 소모했습니다.
2026년: 170억 달러 소모 예상.
추론 비용(inference cost)만 봐도, 즉 당신이 AI에게 질문할 때 시스템이 실제로 모델을 실행하는 비용:
2025년: 84억 달러
2026년 예상: 141억 달러
현재 예측에 따르면, OpenAI는 2029년 또는 2030년이 되어야 현금 흐름이 흑자로 전환될 수 있습니다.
그렇다면 질문은: 이 소모된 돈은 어디로 갔을까요?
답은: AI 기술 스택을 따라 아래로 흘러갔습니다.
흘러간 곳:
Microsoft Azure (OpenAI는 계약에 따라 2032년까지 Microsoft에 수익의 20%를 지불해야 함)
Nvidia의 GPU
데이터 센터를 건설하는 엔지니어링 회사들
그리고 전력을 공급하는 에너지 기업들
이 시스템을 조금 더 오래 바라보면, 거의 순환적인 구조를 발견하게 됩니다:
Microsoft가 OpenAI에 투자합니다.
OpenAI는 그 돈으로 Azure 클라우드 서비스를 구매합니다.
Azure는 수익으로 Nvidia 칩을 구매합니다.
Nvidia는 기록적인 이익을 발표합니다.
모두가 박수를 칩니다.
그리고 자금은 계속 아래로 흐릅니다.
AI 기술 스택에는 매우 중요한 구조적 사실이 하나 있습니다:
대부분의 사용자는 최상층(애플리케이션 계층)에 있습니다.
대부분의 이익은 최하층(인프라 계층)에 있습니다.
그리고 이 사용자 위치와 이익 위치 사이의 불일치가 바로 전체 AI 투자 논리의 핵심입니다.
이것이 AI 가치 사슬의 첫 번째 법칙입니다: 수익은 위로 흐르고, 자본은 아래로 침전됩니다.
3. 이 장면은 사실 본 적이 있다
인류의 모든 문제는 본질적으로 공학 문제이며, 공학 문제는 결국 해결될 수 있습니다. — Buckminster Fuller
AI에서 무슨 일이 일어나고 있는지 진정으로 이해하고 싶다면, 1880년부터 1920년 사이의 전력 혁명 역사를 돌아볼 수 있습니다.
1882년, Thomas Edison은 뉴욕 맨해튼 Pearl Street에 최초의 상업용 발전소를 건설했습니다. 당시 대부분의 사람들은 전력이 단지 신기한 장난감, 더 '고급진' 조명 방식이라고 생각했습니다. 결국, 가스등도 잘 작동했으니까요. 누가 정말로 이런 것이 필요할까요?
하지만 불과 40년 만에, 전력은 거의 모든 산업을 완전히 재형성했습니다: 제조업, 운송, 통신, 의료, 엔터테인먼트.
이 혁명에서 진정으로 승리한 사람은 전구를 발명한 사람이 아니라, 인프라를 건설한 사람들이었습니다: General Electric, Westinghouse Electric, 전력 회사, 구리 광산 기업, 엔지니어링 건설 회사들.
오늘날 AI는 동일한 패턴을 반복하고 있으며, 단지 속도가 수십 년이 아니라 몇 년으로 압축되었을 뿐입니다.
두 사슬을 비교해 보세요:
AI 시스템: AI → 데이터 센터 → 칩 → 원자재 → 에너지
전력 시스템: 전력 → 공장 → 기계 → 원자재 → 석탄 / 수력
두 경로는 거의 똑같습니다. 그리고 승리자는 다시 한번 주로 애플리케이션 계층이 아니라, 인프라 계층에 있습니다.
저는 이 현상을 인프라 중력(Infrastructure Gravity)이라고 부릅니다, 새로운 컴퓨팅 플랫폼이 등장할 때마다, 가장 먼저 부를 창출하는 사람들은 항상 '삽을 파는 사람들'입니다.
애플리케이션은 나중에 따라잡고, 애플리케이션은 모든 미디어의 관심을 받습니다. 하지만 인프라가 대부분의 이익을 가져갑니다.
예를 들어, Nvidia는 2026 회계연도(2026년 1월 종료)에 연간 수익 2159억 달러, 전년 대비 65% 증가를 기록했습니다. 그 중 데이터 센터 사업만 마지막 분기에 623억 달러의 수익을 창출했으며, 전년 대비 75% 증가했습니다. 이 사업은 현재 Nvidia 총 수익의 91%를 차지합니다.
다시 말해, 한 회사의 단일 분기 680억 달러 수익 중 90%가 동일한 사업 라인에서 나온 것입니다.
반도체 제조를 봅시다. TSMC는 2025년에 글로벌 파운드리 시장의 약 70% 점유율을 차지했으며, 매출액은 1225억 달러였습니다. 2위인 Samsung Electronics는 7.2%에 불과했습니다. 이러한 독점 정도는 심지어 당


