
Firedancer 검증인이 출시되어 솔라나가 대량 채택될 수 있는 길을 열었습니다.
이 기사의 출처는 다음과 같습니다.《What is Firedancer? A Deep Dive into Solana 2.0 》
원저자: 0xIchigo
오데일리 번역기: 남편 어떻게

우리 모두 알고 있듯이 솔라나는 현재 퍼블릭 체인에서 고성능을 대표하는 기업 중 하나입니다. 솔라나의 더 빠른 온체인 처리 속도는 많은 프로젝트 당사자들이 추구하고 있으며 Visa와 같은 전통적인 거대 기업들의 선호를 받고 있습니다. 그러나 솔라나는 항상 네트워크 다운타임의 위험을 안고 있었습니다.네트워크 다운타임 문제를 해결하는 방법 Jump가 클라이언트를 검증하기 위해 시작하는 Firedancer 클라이언트가 이에 대한 답을 줄 수 있을 것입니다.
이 글은 블록체인에서 검증인과 검증인 클라이언트의 역할부터 시작하여 Firedancer 검증인 클라이언트가 Solana 네트워크를 지원하는 방법을 살펴보겠습니다.
다음은 Odaily에서 편집한 것입니다.
검증인과 검증인 클라이언트의 다양성이란 무엇입니까?
검증인은 지분 증명 블록체인에 참여하는 컴퓨터입니다. 검증인은 솔라나 네트워크의 중추로서 거래 처리와 합의 프로세스 참여를 담당합니다. 검증인은 일정량의 솔라나 기본 토큰을 담보로 보관하여 네트워크를 보호합니다. 스테이킹 토큰은 검증인을 네트워크에 경제적으로 연결하는 보증금으로 생각할 수 있습니다. 이러한 연결은 검증인이 기여에 따라 보상을 받기 때문에 정확하고 효율적으로 작업을 수행하도록 장려합니다. 동시에 검증인은 악의적이거나 오작동하는 행위로 인해 처벌을 받게 됩니다. 부적절한 행동으로 인해 검증인의 자산이 줄어들게 되는데, 이를 축소라고 하는 프로세스입니다. 따라서 검증인은 자신의 지분을 늘리기 위해 자신의 의무를 올바르게 수행하려는 모든 인센티브를 갖습니다.
유효성 검사기 클라이언트는 유효성 검사기가 작업을 수행하는 데 사용하는 응용 프로그램입니다. 클라이언트는 암호학적으로 고유한 ID를 통해 합의 프로세스에 참여하는 검증자의 기초입니다.
여러 클라이언트를 사용하면 내결함성이 향상됩니다. 예를 들어 단일 클라이언트가 공유의 33% 이상을 제어하지 않는 경우 충돌이나 활성에 영향을 미치는 버그로 인해 네트워크가 다운되지는 않습니다. 마찬가지로 클라이언트에 잘못된 상태 전환을 유발하는 버그가 있고 공유의 33% 미만이 해당 클라이언트를 사용하는 경우 네트워크는 보안 오류로부터 보호됩니다. 이는 네트워크의 대부분이 유효한 상태로 유지되어 블록체인이 분할되거나 분기되는 것을 방지하기 때문입니다. 따라서 검증인 클라이언트의 다양성은 네트워크의 탄력성을 향상시킬 수 있으며, 한 클라이언트의 오류나 취약점이 전체 네트워크에 심각한 영향을 미치지 않습니다.
클라이언트 다양성은 각 클라이언트가 실행하는 스테이크 비율과 사용 가능한 총 클라이언트 수로 측정할 수 있습니다. 이 글을 쓰는 시점에서는,솔라나 네트워크에는 1979명의 검증인이 있습니다.메인넷에서 이러한 검증인이 사용하는 두 클라이언트는 Solana Labs와 Jito Labs에서 제공합니다. 솔라나는 2020년 3월 출시 당시 솔라나 랩스(Solana Labs)가 개발한 검증 클라이언트를 사용했습니다. 2022년 8월 Jito Labs는 두 번째 검증인 클라이언트를 출시했습니다. 클라이언트는 Jito가 유지 관리하고 배포하는 Solana Labs 코드의 포크입니다. 클라이언트는 블록 단위의 MEV(최대 추출 가능 값) 추출을 최적화합니다. Solana는 메모리 풀 없이 청크를 스트리밍하기 때문에 Jito의 클라이언트는 의사 메모리 풀을 생성합니다. mempool은 확인되지 않은 보류 중인 트랜잭션의 대기열이라는 점은 주목할 가치가 있습니다. 의사 멤풀을 사용하면 유효성 검사기가 이러한 트랜잭션을 검색하고 최적으로 함께 묶어 Jito의 블록 엔진에 제출할 수 있습니다.
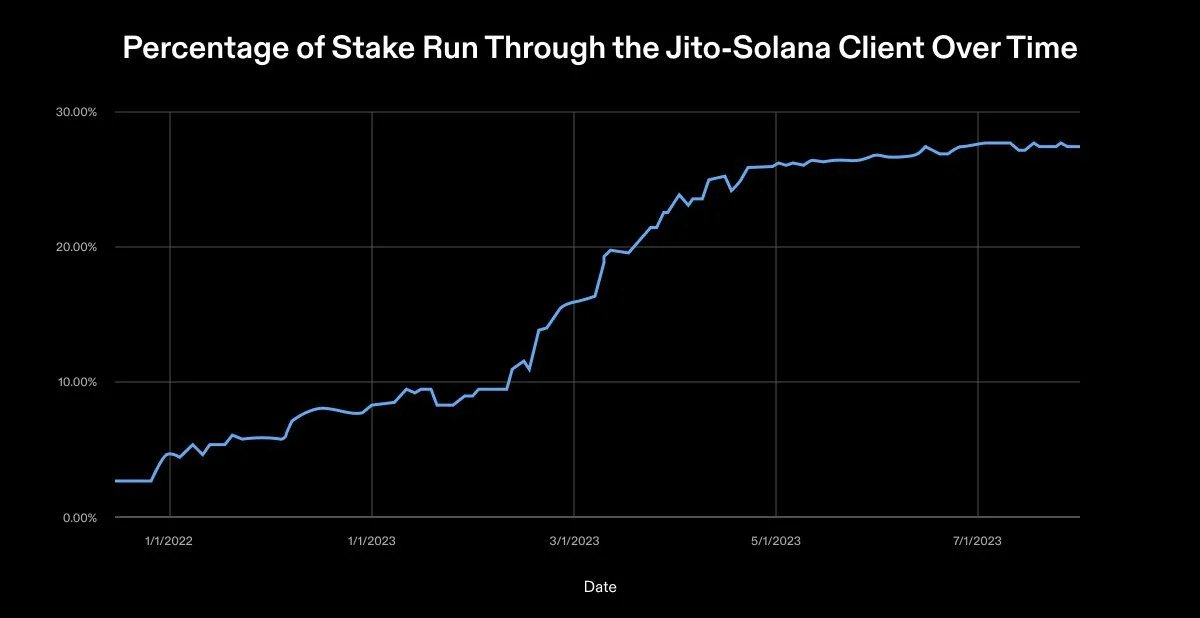
2023년 10월 기준으로 Solana Labs 고객은 활성 스테이킹의 68.55%를 보유하고 있으며 Jito는 31.45%를 보유하고 있습니다. Jito 클라이언트를 사용하는 검증인의 수는 솔라나 재단의 이전 건강 보고서에 비해 16% 증가했습니다. Jito 클라이언트 사용의 증가는 클라이언트 다양화의 진화 추세를 보여줍니다.
이러한 성장 소식은 고무적이지만 완벽하지는 않습니다. Jito의 클라이언트는 Solana Labs 클라이언트의 포크라는 점을 강조해야 합니다. 이는 Jito가 원본 유효성 검사기 코드베이스와 많은 구성 요소를 공유하며 Solana Labs 클라이언트에 영향을 미치는 버그나 취약점에 취약할 수 있음을 의미합니다. 이상적인 미래에는 솔라나가 최소한 4개의 독립 검증인 클라이언트를 보유해야 합니다. 다양한 팀에서 다양한 프로그래밍 언어를 사용하여 이러한 클라이언트를 구축합니다. 각 클라이언트가 약 25%를 보유하므로 단일 구현은 33% 지분 지분을 초과하지 않습니다. 이 이상적인 설정은 유효성 검사기 스택 전체에서 단일 실패 지점을 제거합니다.
두 번째 독립 검증인 클라이언트를 개발하는 것은 이러한 미래를 달성하는 데 매우 중요하며 Jump는 이를 실현하기 위해 최선을 다하고 있습니다.
Jump가 새로운 검증 클라이언트를 구축하는 이유는 무엇입니까?
솔라나의 메인넷은 과거에 4번이나 다운되었으며, 매번 수백 명의 검증인이 수동으로 수리해야 했습니다. 이번 중단은 솔라나 네트워크의 신뢰성에 대한 우려를 부각시켰습니다.Jump는 프로토콜 자체가 신뢰할 수 있다고 믿으며 합의에 영향을 미치는 소프트웨어 모듈 문제로 인해 다운타임이 발생한다고 생각합니다.따라서 Jump는 이러한 문제를 해결하기 위해 새로운 검증인 클라이언트를 개발하고 있습니다. 이 클라이언트의 전반적인 목표는 솔라나 네트워크의 안정성과 효율성을 향상시키는 것입니다.
독립형 유효성 검사기 클라이언트를 개발하는 것은 어려운 작업입니다. 하지만 Jump가 안정적인 글로벌 네트워크를 구축한 것은 이번이 처음이 아닙니다. 과거에는 증권 거래(즉, 주식 매매)가 시장 전문가에 의해 수동으로 수행되었습니다. 전자거래플랫폼의 등장으로 증권거래가 더욱 개방화되었습니다. 이러한 개방성은 경쟁과 자동화를 강화하고 투자자가 거래하는 데 드는 시간과 비용을 줄입니다. 시장 전문가들 사이에서 기술 경쟁이 시작됐다.
상인은 생계를 위해 거래합니다. 더 나은 거래 경험을 위해서는 소프트웨어, 하드웨어 및 네트워크 솔루션에 더 큰 집중이 필요합니다.이러한 시스템은 높은 기계 지능, 낮은 실시간 대기 시간, 높은 처리량, 높은 적응성, 높은 확장성, 높은 신뢰성 및 높은 책임성을 갖추어야 합니다.
모든 경우에 적용되는 단일 솔루션(즉, 기업이 직접 구매할 수 있는 소프트웨어)은 경쟁 우위가 아닙니다. 올바른 주문을 2위로 거래소에 보내는 것은 돈을 잃을 수 있는 비용이 많이 드는 방법입니다. 초단타 트레이딩 분야의 치열한 경쟁으로 인해 업계 최고의 글로벌 트레이딩 인프라를 구축하기 위한 끊임없는 개발 사이클이 이루어졌습니다.
이 시나리오는 익숙하게 들릴 수 있습니다. 성공적인 거래 시스템의 요구 사항은 성공적인 블록체인의 요구 사항과 유사합니다. 블록체인은 뛰어난 성능, 강력한 내결함성, 낮은 대기 시간을 갖춘 네트워크여야 합니다. 느린 블록체인은 현대 기업 애플리케이션의 요구 사항을 충족할 수 없고 혁신, 확장성 및 실제 유용성을 방해할 뿐인 실패한 기술입니다. 20년 넘게 글로벌 네트워크와 고성능 시스템을 개발한 경험을 보유한 Jump는 독립 검증인 클라이언트를 만드는 데 완벽한 팀입니다. Jump Trading 최고 과학 책임자 Kevin Bowers는 빌드 프로세스를 처음부터 끝까지 감독했습니다.
빛의 속도가 너무 느린 이유는 무엇입니까?
Kevin Bowers는 빛이 너무 느려지는 문제에 대해 자세히 설명합니다. 빛의 속도는 단일 트랜지스터가 처리할 수 있는 계산 수에 자연적인 한계를 제공하는 유한 상수입니다. 현재 비트는 트랜지스터를 통해 이동하는 전자로 모델링됩니다. 채널에서 전송할 수 있는 오류 없는 데이터의 최대량인 Shannon의 용량 정리는 트랜지스터를 통해 전송될 수 있는 비트 수를 제한합니다. 기본적인 물리학과 정보 이론의 한계로 인해 컴퓨팅 속도는 전자가 물질을 통과하는 속도와 전송할 수 있는 데이터의 양에 따라 제한됩니다. 이러한 제약은 슈퍼컴퓨터를 한계까지 밀어붙일 때 명백해집니다. 그 결과, 컴퓨터의 데이터 처리 능력과 데이터 전송 능력 사이에는 심각한 불일치가 있습니다.
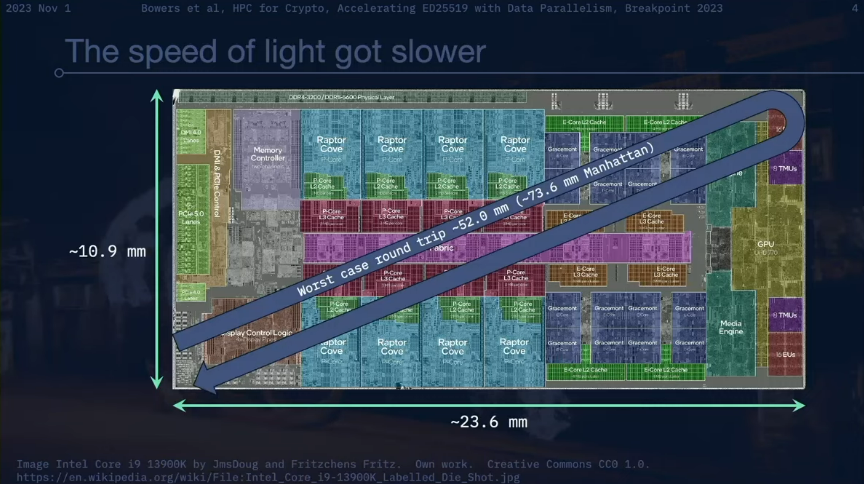
Intel Core i 9 13900 K CPU를 예로 들어 보겠습니다. 기본 클럭 속도가 2.2GHz이고 최대 터보 클럭 속도가 5.8GHz인 24 x 86 코어가 있습니다. 최악의 시나리오는 빛이 CPU 내에서 약 52.0mm의 총 거리를 이동해야 한다는 것입니다. CPU의 맨해튼 거리(즉, 직각 축을 따라 측정한 두 지점 사이의 거리)는 약 73.6mm입니다. CPU의 최대 터보 클록 주파수인 5.8GHz에서 빛은 공기를 통해 약 51.7mm를 이동할 수 있습니다. 이는 단일 클록 주기에서 신호가 CPU의 거의 모든 두 지점 사이의 왕복을 완료할 수 있음을 의미합니다.
그러나 현실은 훨씬 더 나쁩니다. 이러한 측정은 공기를 통해 이동하는 빛의 속도를 사용하는 반면 신호는 실제로 이산화규소(SiO2)를 통해 전송됩니다. 5.8GHz의 클록 주기에서 빛은 이산화규소 내에서 약 26.2mm를 이동할 수 있습니다. 실리콘(Si)에서 빛은 5.8GHz 클록 주기에서 약 15.0mm만 이동할 수 있으며, 이는 CPU 긴 쪽의 절반보다 약간 더 긴 거리입니다.
Firedancer 팀은 최근 몇 년간 컴퓨팅 기술의 발전이 CPU를 더 빠르게 만드는 것보다 더 많은 코어를 CPU에 넣는 데 더 가깝다고 믿습니다. 사람들이 더 많은 성능이 필요할 때 더 많은 하드웨어를 구입하도록 권장됩니다. 이는 현재 처리량으로 인해 병목 현상이 발생하는 상황에서 작동합니다. 실제 병목 현상은 빛의 속도입니다. 이러한 자연스러운 제한은 의사결정 마비로 이어집니다. 모든 종류의 최적화와 마찬가지로 시스템에는 제대로 최적화되지 않았기 때문에 즉각적인 보상을 받을 수 없는 구성 요소가 많이 있습니다. 최적화되지 않은 부품은 사용할 수 있는 컴퓨팅 리소스가 적기 때문에 시간이 지남에 따라 성능이 저하됩니다. 이제 무엇을 해야 할까요?
고성능 컴퓨팅에서는 모든 것이 궁극적으로 최적화되어야 합니다. 그 결과, 양적 거래와 양적 연구를 지향하는 생산 시스템이 탄생했으며, 전 세계적으로 물리학과 정보 이론의 한계에서 운영됩니다. 여기에는 이러한 물리적 제약을 충족하기 위해 맞춤형 네트워크 스위칭 기술을 생성하는 잠금 없는 알고리즘이 포함됩니다. Jump는 기술 회사인 동시에 무역 회사이기도 합니다. SF와 현실의 최첨단에서 현재 직면하고 있는 문제와 Firedancer를 개발 중인 Solana 사이에는 놀랄 만큼 유사한 점이 있습니다.
파이어댄서란 무엇인가요?
Firedancer는 Firedancer 팀이 C 언어로 개발한 새로운 독립형 유효성 검사기 클라이언트입니다. Firedancer는 모듈식 아키텍처, 최소한의 종속성 및 광범위한 테스트 프로세스를 사용하여 안정성을 염두에 두고 설계되었습니다. 이는 Solana Labs 클라이언트의 세 가지 기능 구성 요소(네트워크, 런타임 및 합의)에 대한 대대적인 재작성을 제안합니다. 각 레벨은 최대 성능을 위해 최적화되어 있으므로 클라이언트의 실행 능력은 현재 직면한 소프트웨어 비효율성으로 인한 성능 제한이 아니라 검증기 하드웨어에 의해서만 제한됩니다. Firedancer를 사용하면 Solana는 대역폭과 하드웨어를 기반으로 확장할 수 있습니다.
Firedancer의 목표는 다음과 같습니다.
Solana 프로토콜을 문서화하고 표준화합니다(결국 사람들은 Rust 검증 코드가 아닌 문서를 보고 Solana 검증기를 만들 수 있어야 합니다).
검증인 클라이언트의 다양성을 높입니다.
생태계 성능을 향상시킵니다.
Firedancer 작동 방식
모듈형 아키텍처
Firedancer는 고유한 모듈식 아키텍처를 통해 현재 Solana 검증인 클라이언트와 차별화됩니다. 단일 프로세스로 실행되는 Solana Labs의 Rust 검증자 클라이언트와 달리 Firedancer는 타일이라고 불리는 많은 독립적인 Linux C 프로세스로 구성됩니다. 타일은 프로세스이자 메모리입니다. 이 타일 아키텍처는 견고성과 효율성을 향상시키기 위한 Firedancer의 운영 철학과 접근 방식의 기초입니다.
프로세스는 실행 중인 프로그램의 인스턴스입니다. 이는 최신 운영 체제의 기본 구성 요소이며 일련의 명령 실행을 나타냅니다. 각 프로세스에는 고유한 메모리 공간과 자원이 있으며, 운영체제는 다른 프로세스의 영향을 받지 않고 독립적으로 이러한 자원을 할당하고 관리합니다. 프로세스는 특정 작업을 처리하기 위해 자체 도구와 작업 공간을 사용하는 대규모 공장의 독립적인 작업자와 같습니다.
Firedancer에서 각 타일은 특정 역할을 가진 독립적인 프로세스입니다. 예를 들어, QUIC 타일은 들어오는 QUIC 트래픽을 처리하고 캡슐화된 트랜잭션을 확인 타일로 전달하는 역할을 담당합니다. 확인 타일은 서명 확인을 담당하며 다른 타일도 유사한 작업을 수행합니다. 이러한 타일은 독립적으로 동시에 실행되며 함께 전체 시스템의 기능을 구성합니다. 독립적인 Linux 프로세스는 작고 독립적인 오류 도메인을 형성할 수 있습니다. 이는 하나의 타일에 대한 문제가 전체 유효성 검사기를 즉시 위험에 빠뜨리지 않고 전체 시스템 또는 작은 영향 범위에 최소한의 영향만 미친다는 것을 의미합니다.
Firedancer 아키텍처의 주요 장점은 가동 중지 시간 없이 몇 초 만에 각 타일을 교체하고 업그레이드할 수 있다는 것입니다. 이는 업그레이드하기 전에 Solana Labs의 Rust 검증자 클라이언트를 완전히 종료해야 한다는 요구 사항과 대조됩니다. 이러한 차이점은 Rust의 ABI(Application Binary Interface) 안정성 부족으로 인해 발생합니다. 이는 순수한 Rust 환경에서 즉각적인 업그레이드를 방해합니다. C 프로세스 접근 방식을 사용하면 C 런타임 모델의 바이너리 안정성을 활용하여 업그레이드 관련 가동 중지 시간을 크게 줄일 수 있습니다. 이는 개별 타일이 서로 다른 작업 영역에서 유효성 검사기 상태를 관리하기 때문입니다. 이러한 공유 메모리 개체는 유효성 검사기의 전원이 켜져 있고 실행되는 동안 지속됩니다. 재부팅 또는 업그레이드 중에 각 타일은 중단된 부분부터 원활하게 시작할 수 있습니다.
전반적으로 Firedancer는 NUMA 인식 타일 기반 아키텍처를 기반으로 구축되었습니다. 이 아키텍처에서는 각 타일이 하나의 CPU 코어를 사용합니다. 타일 간 고성능 메시징 기능을 통해 메모리 위치, 리소스 레이아웃 및 구성 요소 대기 시간을 최적화합니다.
네트워크 처리
Firedancer의 네트워크 처리는 초당 기가비트 속도로 업그레이드됨에 따라 Solana 네트워크의 높은 수요를 처리하도록 설계되었습니다. 이 프로세스는 인바운드 활동과 아웃바운드 활동으로 구분됩니다.
인바운드 활동에는 주로 사용자로부터 거래를 받는 것이 포함됩니다. Firedancer의 성능은 매우 중요합니다. 검증인이 패킷 처리에 뒤처지면 합의 메시지가 손실될 수 있기 때문입니다. Solana 노드는 현재 약 0.2Gbps로 작동하는 반면, Jump 노드는 약 40GBps의 최대 대역폭 피크를 기록했습니다. 이러한 대역폭 급증은 강력하고 확장 가능한 인바운드 처리 솔루션의 필요성을 강조합니다.
아웃바운드 활동에는 블록 패킹, 블록 생성 및 샤드 전송이 포함됩니다. 이러한 단계는 솔라나 네트워크의 안전하고 효율적인 운영에 매우 중요합니다. 이러한 작업의 성능은 처리량뿐만 아니라 네트워크의 전반적인 안정성에도 영향을 미칩니다.
Firedancer는 트랜잭션 처리를 위한 지점 간 인터페이스를 통해 Solana의 과거 문제를 해결하는 것을 목표로 합니다. 과거 Solana 지점간 인터페이스의 중요한 단점은 인바운드 트랜잭션을 처리할 때 혼잡 제어가 부족하다는 것이었습니다. 이러한 단점으로 인해 2021년 9월 14일(17시간)과 2022년 4월 30일(7시간)에 서비스 중단이 발생했습니다.
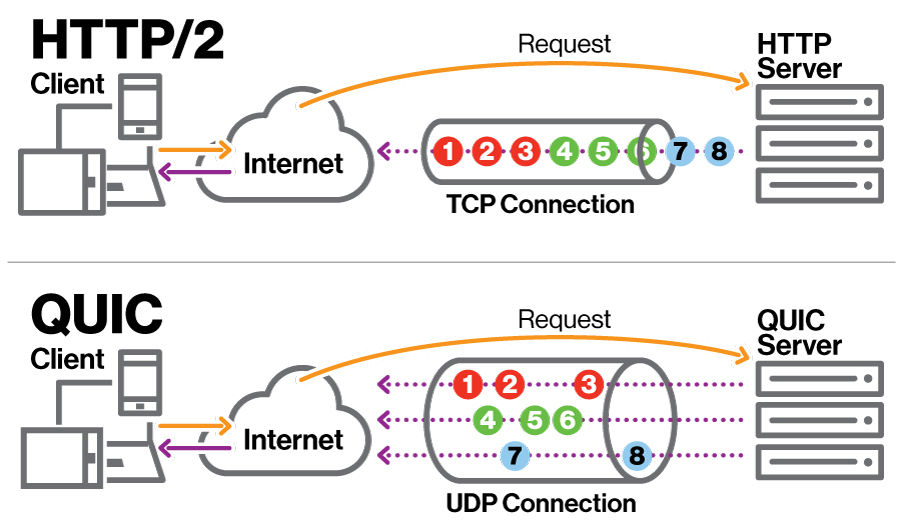
이에 대응하여 솔라나는 높은 트랜잭션 로드를 적절하게 처리하기 위해 여러 가지 네트워크 업그레이드를 실시했습니다. Firedancer는 이에 따라 트래픽 제어 체계로 QUIC를 채택했습니다.QUIC은 HTTP/3의 기반이 되는 다중화된 전송 네트워크 프로토콜입니다.DDoS 공격을 방어하고 네트워크 트래픽을 관리하는 데 중요한 역할을 합니다. 그러나 어떤 경우에는 비용이 이점보다 더 크다는 점에 유의하는 것이 중요합니다. QUIC는 전용 데이터 센터 하드웨어와 함께 사용되어 DDoS 공격을 완화하고 트랜잭션 플러딩 공격에 대한 인센티브를 제거합니다.
QUIC의 151페이지 사양은 개발에 상당한 복잡성을 가져옵니다. 라이선스, 성능 및 안정성 요구 사항을 충족하는 기존 C 라이브러리를 찾을 수 없어서 Firedancer 팀은 자체 구현을 구축했습니다. fd_quic이라는 별명을 가진 Firedancer의 QUIC 구현은 최적화된 데이터 구조와 알고리즘을 도입하여 메모리 할당을 최소화하고 메모리 고갈을 방지합니다.
Firedancer의 맞춤형 네트워크 스택은 처리 능력의 핵심입니다. 스택은 처음부터 RSS(Receive Side Scaling)를 활용하도록 설계되었습니다. RSS는 네트워크 처리의 병렬성을 높이기 위해 네트워크 트래픽을 다른 CPU 코어에 분산시키는 하드웨어 가속 형태의 네트워크 로드 밸런싱입니다. 각 CPU 코어는 추가 오버헤드가 거의 없이 들어오는 트래픽의 일부를 처리합니다. 이 접근 방식은 복잡한 스케줄러, 잠금 및 원자적 작업을 제거하여 기존 소프트웨어 기반 로드 밸런싱보다 성능이 뛰어납니다.
Firedancer는 고성능 타일 애플리케이션을 구성하기 위한 새로운 메시징 프레임워크를 도입합니다. 이러한 타일은 고성능 패킷 처리에 최적화된 주소 계열인 AF_XDP를 활용하여 소켓 기반 커널 네트워킹의 제한을 우회할 수 있습니다. AF_XDP를 사용하면 Firedancer가 네트워크 인터페이스 버퍼에서 직접 데이터를 읽을 수 있습니다.
이 타일 시스템은 다음을 포함하여 Firedancer 스택 내에서 다양한 고성능 컴퓨팅 개념을 구현합니다.
NUMA 인식 - NUMA(Non-Uniform Memory Access)는 프로세서가 다른 프로세서와 연결된 메모리에 액세스하는 것보다 더 빠르게 자체 메모리에 액세스하는 컴퓨터 메모리 설계입니다. Firedancer의 경우 NUMA를 인식한다는 것은 클라이언트가 다중 프로세서 구성에서 메모리를 효율적으로 처리할 수 있음을 의미합니다. 이는 사용 가능한 하드웨어 리소스의 활용을 최적화하므로 높은 트랜잭션 볼륨 처리에 중요합니다.
캐시 지역성 - 캐시 지역성은 프로세서에 가까운 캐시에 이미 저장되어 있는 데이터를 활용하는 것을 의미합니다. 이는 일반적으로 시간적 지역성(즉, 가장 최근에 액세스한 데이터)의 변형입니다. Firedancer에서 캐시 지역성에 초점을 맞춘다는 것은 대기 시간을 최소화하고 속도를 최대화하면서 네트워크 데이터를 처리하도록 설계되었음을 의미합니다.
잠금 없는 동시성 - 잠금 없는 동시성은 동시 작업을 관리하기 위해 잠금 메커니즘(예: 뮤텍스)이 필요하지 않은 알고리즘을 설계하는 것을 의미합니다. Firedancer의 경우 잠금 없는 동시성을 통해 잠금으로 인한 지연 없이 여러 네트워크 작업을 병렬로 실행할 수 있습니다. 잠금 없는 동시성은 많은 수의 트랜잭션을 동시에 처리하는 Firedancer의 능력을 향상시킵니다.
큰 페이지 크기 - 메모리 관리에서 큰 페이지 크기를 사용하면 데이터 세트 처리에 도움이 되고 페이지 테이블 조회 및 잠재적인 메모리 조각화를 줄일 수 있습니다. Firedancer의 경우 이는 메모리 처리 효율성이 향상되었음을 의미합니다. 이는 대량의 네트워크 데이터를 처리하는 데 매우 유용합니다.
시스템 구축
Firedancer의 빌드 시스템은 신뢰성과 일관성을 보장하기 위해 일련의 지침 원칙을 따릅니다. 외부 종속성을 최소화하는 것을 강조하고 빌드 프로세스에 관련된 모든 도구를 종속성으로 처리합니다. 여기에는 모든 종속성(컴파일러 포함)을 정확한 버전으로 고정하는 것이 포함됩니다. 이 시스템의 주요 측면은 빌드 단계 중 환경 격리입니다. 환경 격리는 빌드 프로세스가 시스템 환경의 영향을 받지 않기 때문에 이식성을 향상시킵니다.
Firedancer가 더 빠른 이유
고급 데이터 병렬성
Firedancer는 ED 25519 서명 확인과 같은 암호화 작업에서 최신 프로세서 내부에서 사용할 수 있는 고급 데이터 병렬성을 활용합니다. 최신 CPU에는 여러 데이터 요소를 동시에 처리하기 위한 SIMD(Single Instruction Multiple Data) 명령과 CPU 주기당 여러 명령 실행을 최적화하는 기능이 있습니다. 데이터 요소의 배열이나 벡터에 대한 단일 명령을 병렬로 작동하는 것이 면적, 시간 및 전력 측면에서 더 효율적인 경우가 많습니다. 여기서 병렬 데이터 처리의 개선은 순수한 처리 속도 개선에 비해 처리량 개선을 지배할 수 있습니다.
Firedancer가 데이터 병렬성을 사용하는 영역 중 하나는 계산 서명 확인을 최적화하는 것입니다. 이 접근 방식을 사용하면 배열이나 벡터의 데이터 요소를 동시에 처리하여 처리량을 최대화하고 대기 시간을 최소화할 수 있습니다. ED 25519 구현의 핵심은 Galois 현장 작업입니다. 이러한 형태의 산술은 암호화 알고리즘 및 이진 계산에 매우 적합합니다. 갈루아장에서는 덧셈, 뺄셈, 곱셈, 나눗셈과 같은 연산이 컴퓨터 시스템의 이진 특성을 기반으로 정의됩니다. 다음은 2^3으로 정의된 갈루아 필드의 예입니다.
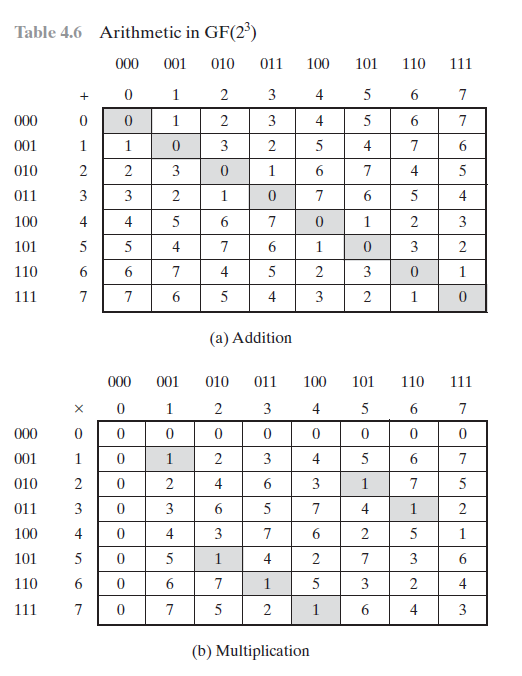
유일한 문제는 ED 25519가 2^(255-19)로 정의된 갈루아 필드를 사용한다는 것입니다. 도메인 요소를 0에서 2^(255-19)까지의 숫자로 생각할 수 있습니다. 기본 작업은 다음과 같습니다.

덧셈, 뺄셈 및 곱셈은 거의 uint 256 _t 수학입니다(즉, 최대값이 2^(256-1)인 부호 없는 정수를 사용한 계산). 나눗셈 계산은 어렵습니다. 일반적인 CPU 및 GPU는 uint 256 _t Math를 지원하지 않습니다. 엄청나게 어려운 나눗셈은 말할 것도 없고 거의 uint 256 _t 수학입니다. 이 수학을 구현하고 성능을 높이는 것은 이 수학을 얼마나 잘 시뮬레이션할 수 있는지에 따라 중요한 문제입니다.

Firedancer의 구현은 숫자를 보다 유연하게 처리하여 산술 연산을 세분화합니다. 한 열에서 다음 열로 숫자를 전달하는 일반적인 긴 나눗셈과 곱셈의 원리를 적용하면 열을 병렬로 처리할 수 있습니다. 이 수학을 시뮬레이션하는 가장 빠른 방법은 단위 256 _t를 9비트 캐리를 사용하여 6개의 43비트 숫자로 표현하는 것입니다. 이를 통해 기존 64비트 작업을 CPU에서 수행하는 동시에 캐리 비트에 충분한 공간을 제공할 수 있습니다. 이러한 숫자 배열은 빈번한 캐리 전파의 필요성을 줄이고 Firedancer가 많은 숫자를 보다 효율적으로 처리할 수 있게 해줍니다.
이 구현에서는 산술 계산을 병렬화된 열 합계로 재구성하여 데이터 병렬성을 활용합니다. 열을 병렬로 처리하면 순차적 병목 현상이 발생할 수 있는 작업이 병렬화 가능한 작업으로 전환되므로 전체 계산 속도가 빨라질 수 있습니다. Firedancer는 AVX 512 및 해당 IFMA 확장(AVX 512-IFMA)과 같은 벡터화된 명령 세트도 사용합니다. 이러한 명령어 세트를 사용하면 위에서 설명한 갈루아 필드 산술을 처리할 수 있어 속도와 효율성이 향상됩니다.
Firedancer의 AVX 512 가속 구현은 매우 빠릅니다. 단일 2.3GHz Icelake 서버 코어에서 코어당 클럭 성능은 2022 Breakpoint 데모의 두 배 이상입니다. 구현은 100% 벡터 채널 활용과 대규모 데이터 병렬 처리를 특징으로 합니다. 이는 광속 대기 시간 덕분에 맞춤형 하드웨어를 사용해도 한 번에 한 가지 작업을 수행하는 것보다 독립적인 병렬 작업을 동시에 수행하는 것이 훨씬 쉽다는 Firedancer 팀의 또 다른 훌륭한 시연입니다.
FPGA로 고속 네트워크 통신 가능
CPU는 코어당 초당 약 30,000개의 서명 확인을 처리할 수 있습니다. 에너지 효율적인 옵션이지만 대규모 작업에는 단점이 있습니다. 이러한 제한은 순차 처리 방식에서 비롯됩니다. GPU는 이 처리 능력을 코어당 초당 약 100만 번의 검증으로 향상시킵니다. 그러나 장치당 약 300W를 소비하고 일괄 처리로 인해 고유한 대기 시간이 발생합니다.
FPGA가 더 나은 선택이 되었습니다. 이는 GPU의 처리량과 일치하지만 FPGA당 약 50W로 훨씬 적은 전력을 소비합니다. 지연 시간도 GPU의 10밀리초 지연 시간보다 낮습니다. FPGA는 대기 시간이 약 200마이크로초인 보다 응답성이 뛰어난 실시간 처리 솔루션을 제공합니다. GPU의 일괄 처리와 달리 Firedancer의 FPGA는 스트리밍 방식으로 각 트랜잭션을 개별적으로 처리합니다. Firedancer의 FPGA 사용 결과, 8개의 FPGA는 400W 미만의 전력을 소비하면서 초당 800만 개의 서명을 처리할 수 있습니다.
팀은 Breakpoint 2022에서 Firedancer의 ED 25519 서명 확인 프로세스를 시연했습니다. 이 프로세스에는 순수 RTL 파이프라인의 SHA-512 계산과 맞춤형 ECC-CPU 프로세서 파이프라인의 다양한 검사 및 계산을 포함한 여러 단계가 포함됩니다. 기본적으로 Firedancer 팀은 맞춤형 프로세서를 위한 컴파일러와 어셈블러를 작성하고, RFC(Request for Comments)에서 Python 코드를 가져오고, 연산자 오버로드 개체를 사용하여 기계어 코드를 생성한 다음 기계어 코드를 ECC -On top of CPU.

특히 Firedancer는 견고성과 네트워크 연결 사이의 균형을 유지하기 위해 AWS 액셀러레이터의 폼 팩터 스타일을 채택합니다. 이 옵션은 클라우드 공급자 사이에서 종종 제한되는 기능인 직접 네트워크 연결과 관련된 문제를 해결합니다. 이러한 선택을 통해 Firedancer는 고급 기능이 클라우드 인프라의 제약 내에서 원활하게 통합될 수 있도록 보장합니다.
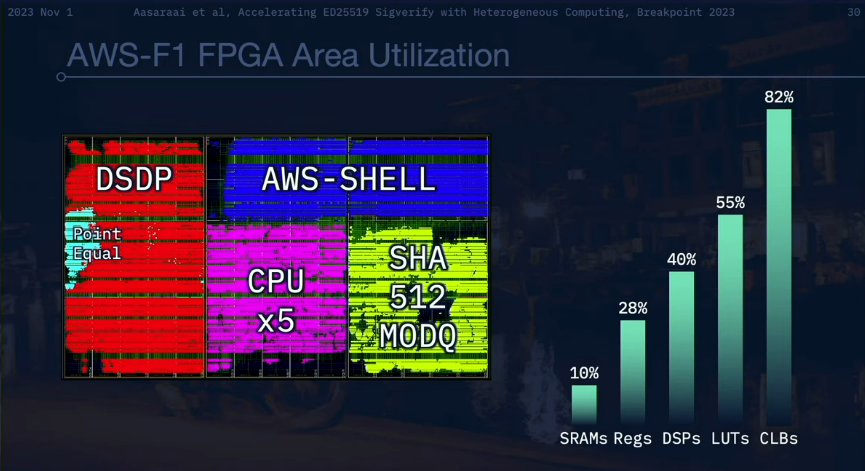
다양한 작업에는 개념적 데이터 공간뿐만 아니라 실제 물리적 공간이 필요하다는 점을 깨달아야 합니다. Firedancer는 물리적 구성 요소의 위치를 전략적으로 배열하여 컴팩트하고 재사용 가능하게 만드는 방식으로 작동합니다. 이 구성을 통해 Firedancer는 FPGA의 효율성을 극대화하여 8년 된 시스템에서 7년 된 FPGA를 사용하여 초당 800만 건의 트랜잭션을 달성할 수 있었습니다.
네트워크 통신의 근본적인 과제는 새로운 거래를 전 세계적으로 방송하는 것입니다.
인터넷의 지점 간 특성, 제한된 대역폭 및 대기 시간 문제로 인해 네트워크를 사용한 직접 방송과 같은 기존 방법의 실행 가능성이 제한됩니다. 링이나 트리 구조로 데이터를 분산하면 이러한 문제가 부분적으로 해결되지만 전송 중에 패킷이 손실될 수 있습니다.
리드 솔로몬 코딩은 이러한 문제에 대해 선호되는 솔루션입니다. 손실된 패킷을 복구하기 위해 데이터 전송 중복성(즉, 패리티 정보)을 도입합니다. 기본 개념은 두 점이 직선을 정의할 수 있고 이 직선 위의 두 점이 원래 데이터 점을 재구성할 수 있다는 것입니다. 데이터 포인트를 기반으로 다항식을 구축하고 이 함수의 다양한 포인트를 별도의 패킷에 분산함으로써 수신기가 최소 두 개의 패킷을 수신하는 한 원본 데이터를 재구성할 수 있습니다.
직선(y = mx + b)의 점에 대한 전통적인 공식을 사용하는 것은 계산 속도가 느리기 때문에 다항식을 구성합니다. Firedancer는 작업 속도를 높이기 위해 라그랑지 다항식(다항식 구성을 위한 특수 방법)을 사용합니다. 리드 솔로몬 인코딩에 필요한 다항식 생성을 단순화합니다. 또한 프로세스를 고차 다항식에 대한 보다 효율적인 행렬-벡터 곱셈으로 변환합니다. 이 행렬은 패턴의 첫 번째 행이 완전히 결정되도록 재귀적인 방식으로 반복되는 패턴으로 고도로 구조화되어 있습니다. 이 구조는 곱셈 계산을 수행하는 더 빠른 방법이 있음을 의미합니다. Firedancer는 현재 알려진 Reed-Solomon 인코딩의 가장 빠른 이론적 방법인 곱셈에 이 행렬을 사용하는 방법에 대한 2016년 기사에 설명된 O(n log n) 방법을 사용합니다. 그 결과 기존 방법에 비해 패리티 정보를 계산하는 매우 효율적인 방법이 탄생했습니다.
코어당 120Gbps 이상의 RS 인코딩 속도;
RS 디코딩 속도는 코어당 최대 50Gbps입니다.
이 지표는 현재 ~8Gbps/코어 RS 인코딩(rust-rse)과 비교됩니다.
Firedancer는 최적화된 Reed-Solomon 인코딩 방법을 사용하여 기존 방법보다 14배 빠르게 패리티 정보를 계산할 수 있습니다. 이는 데이터 인코딩 및 디코딩 프로세스를 빠르고 안정적으로 만들어 전 세계적으로 높은 처리량과 짧은 대기 시간을 유지하는 데 중요합니다.
Firedancer는 어떻게 안전을 유지하나요?
가능성
모든 검증인은 현재 원래 검증인 클라이언트를 기반으로 한 소프트웨어를 사용합니다. Firedancer가 Solana Labs의 고객과 다르다면 Firedancer는 Solana의 고객과 공급망 다양성을 향상시킬 수 있습니다. 여기에는 유사한 종속성을 사용하고 Rust를 사용하여 클라이언트를 개발하는 것이 포함됩니다.
Solana Labs와 Jito 검증자 클라이언트는 별도의 프로세스로 실행됩니다. 모놀리식 애플리케이션이 프로덕션 환경에서 실행되면 보안을 추가하는 것은 어렵습니다. 이러한 클라이언트를 실행하는 검증자는 순수한 Rust로의 즉각적인 보안 업그레이드를 위해 종료되어야 합니다. Firedancer 팀은 처음부터 보안 아키텍처가 내장된 새로운 클라이언트를 개발할 수 있었습니다.
Firedancer는 과거 경험을 통해 배울 수 있다는 장점도 있습니다. Solana Labs는 스타트업 환경에서 검증자 클라이언트를 개발했습니다. 이렇게 빠르게 변화하는 환경은 실험실이 빠르게 시장에 출시하기 위해 빠르게 움직여야 함을 의미합니다. 이로 인해 향후 개발 전망이 걱정됩니다. Firedancer 팀은 Labs가 수행한 작업과 다른 체인의 팀이 수행한 작업을 살펴보고 처음부터 검증자 클라이언트를 개발할 수 있다면 무엇을 다르게 할 것인지 물어볼 수 있습니다.
도전
Firedancer는 Solana Labs의 클라이언트와 다르지만 동작을 밀접하게 복제해야 합니다. 이를 수행하지 않으면 일관성 오류가 발생하여 보안 위험이 발생할 수 있습니다. 이 문제는 공유의 일부를 두 클라이언트 모두에서 실행하도록 장려하고 Firedancer의 총 공유를 장기간 총 공유의 33% 미만으로 유지함으로써 완화될 수 있습니다. 그럼에도 불구하고 Firedancer 팀은 구현이 얼마나 어렵거나 안전한지에 관계없이 프로토콜의 전체 기능 세트를 구현해야 합니다. 모든 것이 Firedancer와 일치해야 합니다. 따라서 팀은 코드를 단독으로 개발할 수 없으며 Labs 클라이언트의 기능과 비교하여 검토해야 합니다. 이는 사양과 문서가 부족하여 더욱 악화되며, 이는 Firedancer가 프로토콜에 비효율적인 구성을 도입해야 함을 의미합니다.
Firedancer 팀은 또한 C에서 새 클라이언트를 개발하고 있다는 사실도 알고 있어야 했습니다. C 언어는 Rust와 같은 언어와 같이 기본적으로 메모리 안전 보장을 제공하지 않습니다. Firedancer 코드베이스의 주요 목표는 메모리 안전 취약점의 발생과 영향을 줄이는 것입니다. Firedancer는 빠르게 진행되는 프로젝트이기 때문에 이 목표에는 특별한 주의가 필요합니다. Firedancer는 이러한 버그를 발생시키지 않고 개발 속도를 유지할 수 있는 방법을 찾아야 합니다. 운영 체제 샌드박싱은 타일을 운영 체제에서 분리하는 방식입니다. 타일은 리소스에 액세스하고 해당 작업에 필요한 시스템 호출을 수행하는 것만 허용됩니다. Tile은 목적이 잘 정의되어 있고 Firedancer 팀은 대부분 클라이언트 측 코드를 개발하기 때문에 Tile의 권한은 최소 권한 원칙에 따라 제거됩니다.
심층 방어 설계 구현
모든 소프트웨어에는 어느 시점에서 보안 취약점이 있습니다. 소프트웨어에 버그가 있을 것이라는 전제에서 시작하여 Firedancer는 하나의 취약점의 잠재적 영향을 제한하기로 선택합니다. 이러한 접근 방식을 심층 방어라고 합니다. 심층 방어는 자산을 보호하기 위해 다양한 보안 조치를 사용하는 전략입니다. 공격자가 시스템의 한 부분을 손상시키는 경우 위협이 전체 시스템에 영향을 미치는 것을 방지하기 위한 추가 조치가 있습니다.
Firedancer는 취약점과 악용 단계 사이의 위험을 완화하도록 설계되었습니다. 예를 들어 메모리 안전 취약점은 공격자가 악용하기 어렵습니다. 이러한 유형의 공격을 방지하는 것은 잘 연구된 문제이기 때문입니다. C에서는 메모리 안전에 대한 집중적인 연구를 통해 팀이 Firedancer에서 사용한 일련의 강화 기술과 컴파일러 기능이 탄생했습니다. 공격자가 업계 모범 사례를 우회할 수 있더라도 취약점을 악용하여 시스템을 손상시키는 것은 어렵습니다. 이는 타일 격리와 운영 체제 샌드박싱으로 인해 발생합니다.
타일 격리는 Firedancer의 병렬 아키텍처의 결과입니다. 각 타일은 자체 Linux 프로세스에서 실행되므로 명확하고 단일한 목적을 가지고 있습니다. 예를 들어, QUIC 타일은 들어오는 QUIC 트래픽을 처리하고 캡슐화된 트랜잭션을 유효성 검사 타일로 전달하는 역할을 담당합니다. 그런 다음 확인 타일은 서명 확인을 담당합니다. QUIC 타일과 검증 타일 간의 통신은 공유 메모리 인터페이스를 통해 수행됩니다(즉, Linux 프로세스는 서로 데이터를 전달할 수 있습니다). 두 타일 간의 공유 메모리 인터페이스는 격리 경계 역할을 합니다. QUIC 타일에 공격자가 악성 QUIC 패킷을 처리할 때 임의의 코드를 실행할 수 있는 버그가 포함되어 있어도 다른 타일에는 영향을 미치지 않습니다. 단일 프로세스에서는 즉각적인 손상이 발생합니다. 공격자가 이 취약점을 악용하여 여러 유효성 검사기를 대상으로 하는 경우 전체 네트워크에 해를 끼칠 수 있습니다. 공격자가 QUIC 타일 성능을 저하시키는 것이 가능하지만 Firedancer의 설계는 이를 QUIC 타일로 제한합니다.
운영 체제 샌드박싱은 타일을 운영 체제에서 분리하는 방식입니다. 타일은 리소스에 액세스하고 해당 작업에 필요한 시스템 호출을 수행하는 것만 허용됩니다. Tile은 명확하게 정의된 목적을 가지고 있고 거의 모든 코드가 Firedancer 팀에서 개발되었기 때문에 Tile의 권한은 최소 권한 원칙에 따라 최소한으로 박탈됩니다. 타일은 자체 Linux 네임스페이스에 배치되어 시스템에 대한 제한된 보기를 제공합니다. 이러한 좁은 보기는 Tile이 대부분의 파일 시스템, 네트워크 및 동일한 시스템에서 실행되는 기타 프로세스에 액세스하는 것을 방지합니다. 네임스페이스는 보안 우선 경계를 제공합니다. 그러나 공격자가 권한을 상승시키는 커널 취약성을 갖고 있는 경우에도 이 격리를 우회할 수 있습니다. 시스템 호출 인터페이스는 Tile에서 연결할 수 있는 커널의 마지막 공격 벡터입니다. 이를 방지하기 위해 Firedancer는 seccomp-BPF를 사용하여 커널에서 시스템 호출을 처리하기 전에 시스템 호출을 필터링합니다. 클라이언트는 타일을 선택된 시스템 호출 세트로 제한할 수 있습니다. 어떤 경우에는 시스템 호출의 매개변수를 필터링하는 것이 가능합니다. Firedancer는 읽기 및 쓰기 시스템 호출이 특정 파일 설명자에서만 작동하도록 보장하기 때문에 이는 중요합니다.
내장형 보안 계획 채택
Firedancer를 개발하는 동안 모든 단계에 포괄적인 안전 절차를 내장하는 데 주의를 기울였습니다. 고객의 보안 프로그램은 개발 팀과 보안 팀 간의 지속적인 협력의 결과이며 보안 블록체인 기술의 새로운 표준을 설정합니다.
프로세스는 셀프 서비스 퍼즈 테스트 인프라로 시작됩니다. 퍼지 테스트는 취약점을 나타내는 충돌이나 오류 조건을 자동으로 감지하는 기술입니다. 퍼즈 테스트는 P2P 인터페이스(파서) 및 SBPF 가상 머신을 포함하여 신뢰할 수 없는 사용자 입력을 허용하는 모든 구성 요소를 스트레스 테스트하여 수행됩니다. OSS-Fuzz는 코드 변경 중에 지속적인 퍼지 범위를 유지합니다. 또한 보안 팀은 지속적인 적용 범위 안내 퍼즈 테스트를 위해 전용 ClusterFuzzer 인스턴스를 설정했습니다. 개발자와 보안 엔지니어는 퍼지 테스트(즉, 보안에 중요한 구성 요소의 특수 버전에 대한 단위 테스트)를 위한 도구도 제공합니다. 개발자는 자동으로 수신 및 테스트되는 새로운 퍼즈 테스트에 기여할 수도 있습니다. 목표는 다음 단계로 이동하기 전에 모든 부품을 완전히 퍼즈 테스트하는 것입니다.
내부 코드 검토는 도구가 놓칠 수 있는 취약점을 찾는 데 도움이 됩니다. 이 단계에서는 위험도가 높고 영향이 큰 구성 요소에 중점을 둡니다. 이 단계는 보안 프로그램의 다른 부분에 피드백을 제공하는 피드백 메커니즘입니다. 팀은 퍼지 테스트 범위를 개선하고, 특정 취약성 클래스에 대한 새로운 정적 분석 검사를 도입하고, 복잡한 공격 벡터를 배제하기 위해 대규모 코드 리팩토링을 구현하기 위해 이러한 검토에서 배운 모든 교훈을 적용합니다. 외부 보안 검토는 출시 전후에 업계 최고의 전문가와 활발한 버그 바운티 프로그램을 통해 보완됩니다.
Firedancer는 또한 다양한 테스트 네트워크에서 광범위한 스트레스 테스트를 거쳤습니다. 이러한 테스트 네트워크는 노드 복제, 네트워크 링크 장애, 패킷 플러딩, 합의 위반 등 다양한 공격과 장애에 노출됩니다. 이러한 네트워크가 견디는 부하는 메인넷의 현실적인 부하를 훨씬 초과합니다.
그렇다면 다음과 같은 질문이 제기됩니다. Firedancer의 현재 상태는 무엇입니까?
Firedancer의 현재 상태는 어떻고, Frankendancer는 무엇인가요?
Firedancer 팀은 검증인 클라이언트를 모듈화하기 위해 Firedancer를 점진적으로 개발하고 있습니다. 이는 문서화 및 표준화에 대한 목표와 일치합니다. 이러한 접근 방식을 통해 Firedancer는 Solana의 최신 개발 내용을 최신 상태로 유지할 수 있습니다. 이로 인해 Frankendancer가 탄생하게 되었습니다. Frankendancer는 Firedancer 팀이 개발된 구성 요소를 기존 검증자 클라이언트 인프라에 통합하는 하이브리드 클라이언트 모델입니다. 이 개발 프로세스를 통해 새로운 기능을 점진적으로 개선하고 테스트할 수 있습니다.
Frankendancer는 스포츠카를 교통 한가운데에 놓는 것과 같습니다. 더 많은 구성요소가 개발되고 병목 현상이 제거됨에 따라 성능은 계속해서 향상될 것입니다. 이 모듈식 개발 프로세스는 사용자 정의 가능하고 유연한 유효성 검사기 환경을 촉진합니다. 여기에서 개발자는 필요에 따라 유효성 검사기 클라이언트의 특정 구성 요소를 수정하거나 교체할 수 있습니다.
실제로 실행되는 것
Frankendancer는 Solana 검증인의 모든 네트워킹 기능을 구현합니다:
인바운드: QUIC, TPU, Sigverify, Dedup
아웃바운드: 블록 포장, 파쇄 생성/서명/전송(터빈)
Frankendancer는 Solana Labs의 Rust 런타임 및 합의 코드 위에 Firedancer의 고성능 C 네트워킹 코드를 사용합니다.
Frankendancer의 아키텍처 설계는 고급 하드웨어 최적화에 중점을 둡니다. Firedancer 팀은 표준 Linux 운영 체제를 실행하는 저가형 클라우드 호스트를 지원하는 동시에 코어 수가 많은 서버에 맞게 Frankendancer를 최적화하고 있습니다. 장기적인 목표는 클라우드의 기존 하드웨어 리소스를 활용하여 효율성과 성능을 향상시키는 것입니다. 클라이언트는 동시에 여러 연결, 하드웨어 가속, 부하 분산을 위한 무작위 트래픽 조정(네트워크 트래픽의 균일한 분산 보장) 및 구성 요소 간 추가 보안을 제공하는 다중 프로세스 경계를 지원합니다.
기술적 효율성은 Frankendancer의 초석입니다. 시스템은 중요한 경로에서 메모리 할당 및 원자성 작업을 방지하며 모든 할당은 초기화 시 NUMA 최적화됩니다. 이 디자인은 최대의 효율성과 성능을 보장합니다. 또한 시스템 구성 요소를 비동기식 및 원격으로 검사하는 기능과 타일의 유연한 관리(비동기식 시작, 중지 및 다시 시작) 기능을 통해 시스템에 견고성과 적응성을 한층 더 강화합니다.
Frankendancer의 가격은 어떻게 되나요?
Frankendancer의 각 타일은 네트워크의 인바운드 측에서 초당 1,000,000건의 트랜잭션(TPS)을 처리할 수 있습니다. 각 타일은 하나의 CPU 코어를 사용하므로 성능은 사용된 코어 수에 따라 선형적으로 확장됩니다. Frankendancer는 4개의 코어만 사용하고 각 코어에서 25Gbps 네트워크 인터페이스 카드(NIC)를 완전히 활용하여 이러한 성과를 달성합니다.
네트워크 아웃바운드 작업과 관련하여 Frankendancer는 터빈 최적화를 통해 상당한 개선을 달성했습니다. 현재 표준 노드 하드웨어는 타일당 6Gbps의 속도를 달성합니다. 여기에는 샤딩(예: 데이터 블록을 분할하여 검증자 네트워크로 전송하는 방법)의 엄청난 속도 향상이 포함됩니다. 현재 표준 Solana 노드와 비교하여 Frankendancer는 Merkle 트리가 없을 때 약 22%의 샤딩 속도 향상을 보여주며 Merkle 트리를 사용할 때 거의 두 배의 속도 향상을 보여줍니다. 이는 현재 검증인 블록 전파 및 거래 수신 성능에 비해 크게 개선된 것입니다.
Firedancer의 네트워크 성능은 하드웨어의 한계에 도달하여 오늘날의 표준 검증기 하드웨어와 비교하여 최대 성능을 달성한다는 것을 보여줍니다. 이는 극한의 작업 부하를 효과적이고 효율적으로 처리할 수 있는 클라이언트의 능력을 보여주는 중요한 기술 이정표입니다.
Frankendancer가 테스트넷에 출시되었습니다.
Frankendancer는 현재 테스트 네트워크에서 스테이킹, 투표, 블록 생성을 진행하고 있습니다. Solana Labs, Jito 및 기타 약 2900개의 검증기와 호환됩니다. 이 실제 배포는 상용 하드웨어에서 Firedancer의 강력한 성능을 보여줍니다. 현재 AMD EPYC 7513 CPU가 장착된 Equinix Metal m 3.large.x 86 서버에 배포되어 있습니다. 다른 많은 검증자들도 동일한 유형의 서버를 사용합니다. 위치에 따라 시간당 $3.10~$4.65 범위의 온디맨드 가격으로 저렴한 솔루션을 제공합니다.
메인넷 출시를 향한 Firedancer의 진전은 노드 하드웨어에 대한 몇 가지 가능성을 열어줍니다.
현재 검증기 하드웨어는 더 높은 노드당 성능 용량을 가능하게 합니다.
Firedancer의 효율성을 통해 검증자는 비슷한 성능 수준을 유지하면서 보다 저렴하고 낮은 사양의 하드웨어를 사용할 수 있습니다.
Firedancer는 하드웨어 및 대역폭의 발전을 활용하도록 설계되었습니다.
Wiredancer(Firedancer 팀의 하드웨어 가속 실험) 및 Rust 기반 모듈형 런타임/SVM과 같은 다른 이니셔티브와 함께 이러한 개발은 Firedancer를 미래 지향적인 솔루션으로 만듭니다.
Firedancer의 발전은 검증인이 병렬 실행으로 알려진 Firedancer와 함께 Solana Labs 클라이언트를 실행하도록 할지 여부에 대한 논의를 촉발시켰습니다. 이 접근 방식은 두 클라이언트의 장점을 활용하고 두 클라이언트가 전체 네트워크에 미치는 잠재적인 영향을 완화함으로써 네트워크 활동을 최대화합니다. 또한 이로 인해 Jito와 같은 프로젝트가 Firedancer 포크를 고려할 것인지에 대한 추측이 이어졌습니다. 이는 MEV 추출 및 트랜잭션 처리 효율성을 더욱 최적화할 수 있습니다. 단지 시간이 말해 줄 것이다.
결론적으로
개발자는 작업이 물리적 공간이 아닌 데이터 공간을 차지하는 것으로 생각하는 경우가 많습니다. 자연적인 한계인 빛의 속도를 사용하면 이러한 가정으로 인해 시스템이 느려지고 하드웨어를 적절하게 최적화할 수 없게 됩니다. 매우 적대적이고 경쟁적인 환경에서 단순히 솔라나에 더 많은 하드웨어를 투입하고 더 나은 성능을 기대할 수는 없습니다. 최적화가 필요합니다. Firedancer는 검증인 클라이언트의 구조와 운영을 혁신합니다. Firedancer 팀은 신뢰할 수 있고 고도로 모듈화된 고성능 검증 클라이언트를 구축함으로써 솔라나의 대량 채택을 준비하고 있습니다.
주니어 개발자이든 일반 Solana 사용자이든 Firedancer와 그 의미를 이해하는 것이 중요합니다. 이러한 기술적 위업은 시장에서 가장 빠르고 성능이 뛰어난 블록체인을 더욱 향상시킵니다. Solana는 처리량이 높고 대기 시간이 짧은 전역 상태 머신으로 설계되었습니다. Firedancer는 이러한 목표를 완성하기 위한 큰 진전입니다.


