
LUCIDA: 강력한 암호화 자산 포트폴리오를 구축하기 위해 다중 요소 전략을 사용하는 방법(데이터 전처리)
머리말
이전 장에 이어 우리는 출판했습니다.시리즈의 첫 번째 기사 다단계 전략을 사용하여 강력한 암호화폐 자산 포트폴리오 구축 - 이론적 기초, 이번 글은 데이터 전처리의 두 번째 글입니다.
요인 데이터를 계산하기 전/후, 단일 요인의 타당성을 검정하기 전에 해당 데이터를 처리해야 합니다. 특정 데이터 전처리에는 중복 값, 이상값/결측값/극값, 표준화 및 데이터 빈도 처리가 포함됩니다.
1. 중복된 값
데이터 관련 정의:
Key: 고유 인덱스를 나타냅니다. 예: 모든 토큰과 모든 날짜가 포함된 데이터의 경우 키는 token_id/contract_address - 날짜입니다.
값: 키로 인덱싱된 개체를 값이라고 합니다.
중복 값을 진단하려면 먼저 데이터가 어떤 모습이어야 하는지 이해해야 합니다. 일반적으로 데이터는 다음과 같은 형식입니다.
시계열 데이터. 핵심은 시간이다. 예: 단일 토큰에 대한 5년간의 가격 데이터
단면 데이터(단면). 핵심은 개인이다. 예.2023.11.01 해당일 암호화폐 시장의 모든 토큰 가격 데이터
패널 데이터(패널). 핵심은 개인시간의 조합이다. 예를 들어 2019.01.01부터 2023.11.01까지 4년 동안의 모든 토큰 가격 데이터입니다.
원리: 데이터의 인덱스(키)가 결정되면 데이터에 중복된 값이 없어야 하는 수준을 알 수 있습니다.
확인 방법:
pd.DataFrame.duplicated(subset=[key 1, key 2, ...])
중복 값 수 확인: pd.DataFrame.duplicated(subset=[key 1, key 2, ...]).sum()
중복 샘플을 보기 위한 샘플링: df[df.duplicated(subset=[...])].sample() 샘플을 찾은 후 df.loc를 사용하여 인덱스에 해당하는 모든 중복 샘플을 선택합니다.
pd.merge(df 1, df 2, on=[key 1, key 2, ...], indicator=True, validate='1: 1')
수평 병합 기능에서 표시 매개변수를 추가하면 _merge 필드가 생성됩니다. 병합 후 dfm[_merge].value_counts()를 사용하여 여러 소스의 샘플 수를 확인하세요.
유효성 검사 매개변수를 추가하면 병합된 데이터 세트의 인덱스가 예상한 대로인지 확인할 수 있습니다(1 대 1, 1 대 다 또는 다대다. 마지막 경우는 실제로 확인이 필요하지 않음을 의미함). 예상과 다르면 병합 프로세스에서 오류를 보고하고 실행을 중단합니다.
2. 이상값/결측값/극값
이상치의 일반적인 원인:
극단적인 경우.예를 들어 토큰 가격이 0.000001$이거나 토큰의 시장 가치가 미화 500,000달러에 불과한 경우 조금만 변경하면 수십 배의 수익이 발생합니다.
데이터 특성.예를 들어, 2020년 1월 1일에 토큰 가격 데이터 다운로드가 시작된다면, 전일 종가가 없기 때문에 당연히 2020년 1월 1일 수익률 데이터를 계산하는 것은 불가능합니다.
데이터 오류.데이터 제공자는 토큰당 12위안을 토큰당 1.2위안으로 기록하는 등 필연적으로 실수를 하게 됩니다.
이상값 및 누락값 처리 원칙:
삭제. 합리적으로 수정되거나 수정될 수 없는 이상값은 삭제가 고려될 수 있습니다.
바꾸다. 일반적으로 Winsorizing 또는 로그 계산(일반적으로 사용되지 않음)과 같은 극단값을 처리하는 데 사용됩니다.
충전재. ~을 위한누락된 값합리적인 방법으로 작성하는 것도 고려할 수 있습니다. 일반적인 방법은 다음과 같습니다.평균(또는 이동 평균),보간(Interpolation)、0을 입력하세요df.fillna(0), 앞으로 df.fillna(ffill)/뒤로 채우기 df.fillna(bfill) 등 채우기가 의존하는 가정이 일관성이 있는지 여부를 고려해야 합니다.
기계 학습에서는 미리 예측 편향의 위험이 있으므로 뒤로 채우기를 주의해서 사용하십시오.
극단값을 처리하는 방법:
1. 백분위수 방법.
작은 것부터 큰 것 순서로 정렬하여 최소 및 최대 비율을 초과하는 데이터는 중요한 데이터로 대체됩니다. 이 방법은 과거 데이터가 풍부한 데이터의 경우 상대적으로 거칠고 적용성이 떨어지며, 고정된 비율의 데이터를 강제로 삭제하면 일정 비율의 손실이 발생할 수 있습니다.
2.3σ / 3개의 표준편차 방법

데이터 범위 내의 모든 요소를 다음과 같이 조정합니다.
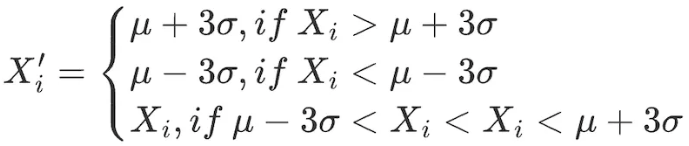
이 방법의 단점은 주가, 토큰 가격 등 정량적 분야에서 일반적으로 사용되는 데이터가 정규 분포의 가정을 따르지 않는 정점 및 두꺼운 꼬리 분포를 나타내는 경우가 많다는 점입니다. 3 σ 방법은 많은 양의 데이터를 이상치로 잘못 식별합니다.
3. 중앙절대편차(MAD) 방법
이 방법은 중앙값과 절대 편차를 기반으로 하므로 처리된 데이터가 극단값이나 이상값에 덜 민감하게 됩니다. 평균 및 표준편차를 기반으로 하는 방법보다 더 강력합니다.
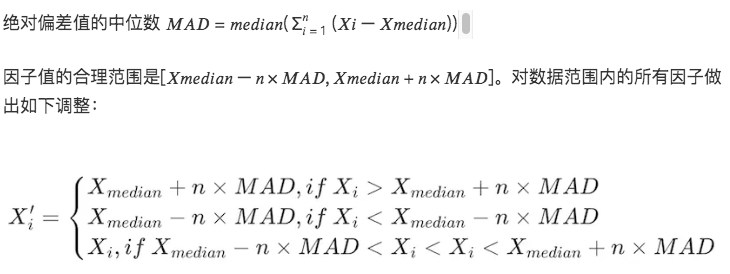
# 요인 데이터의 극값 상황을 처리합니다.
class Extreme(object):
def __init__(s, ini_data):
s.ini_data = ini_data
def three_sigma(s, n= 3):
mean = s.ini_data.mean()
std = s.ini_data.std()
low = mean - n*std
high = mean + n*std
return np.clip(s.ini_data, low, high)
def mad(s, n= 3):
median = s.ini_data.median()
mad_median = abs(s.ini_data - median).median()
high = median + n * mad_median
low = median - n * mad_median
return np.clip(s.ini_data, low, high)
def quantile(s, l = 0.025, h = 0.975):
low = s.ini_data.quantile(l)
high = s.ini_data.quantile(h)
return np.clip(s.ini_data, low, high)
3. 표준화
1.Z-점수 표준화

2. 최대값과 최소값 차이 표준화(Min-Max Scaling)
각 요인 데이터를 (0, 1) 간격의 데이터로 변환하여 크기나 범위가 다른 데이터의 비교가 가능하지만 데이터 내 분포가 변경되지 않으며 합계가 1이 되지도 않습니다.
최대값과 최소값을 고려하기 때문에 이상값에 민감합니다.
차원을 통합하면 다양한 차원의 데이터를 쉽게 비교할 수 있습니다.
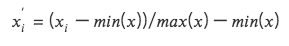
3. 순위 조정
데이터 기능을 순위로 변환하고 이러한 순위를 0과 1 사이의 점수(일반적으로 데이터 세트의 백분위수)로 변환합니다. *
순위는 이상값의 영향을 받지 않으므로 이 방법은 이상값의 영향을 받지 않습니다.
데이터 내 지점 간 절대 거리는 유지되지 않고, 상대적 순위로 변환됩니다.
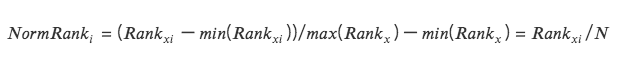
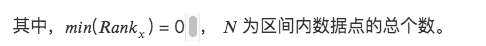
# 표준화된 요인 데이터 클래스 Scale(object):
def __init__(s, ini_data, date):
s.ini_data = ini_data
s.date = date
def zscore(s):
mean = s.ini_data.mean()
std = s.ini_data.std()
return s.ini_data.sub(mean).div(std)
def maxmin(s):
min = s.ini_data.min()
max = s.ini_data.max()
return s.ini_data.sub(min).div(max - min)
def normRank(s):
# 지정된 열의 순위를 매깁니다. method=min은 동일한 값이 평균 순위가 아닌 동일한 순위를 갖는다는 의미입니다.
ranks = s.ini_data.rank(method='min')
return ranks.div(ranks.max())
4. 데이터 빈도
때로는 얻은 데이터가 분석에 필요한 빈도가 아닌 경우가 있습니다. 예를 들어 분석 수준이 월별이고 원본 데이터의 빈도가 일별인 경우 다운샘플링, 즉 집계된 데이터가 월별 데이터를 사용해야 합니다.
다운샘플링
추천컬렉션의 데이터를 하나의 데이터 행으로 집계예를 들어 일일 데이터는 월별 데이터로 집계됩니다. 이때 각 집계지표의 특성을 고려해야 하며, 일반적인 작업은 다음과 같습니다.
첫 번째 값/마지막 값
평균/중앙값
표준 편차
업샘플링
월별 분석에 사용되는 연간 데이터와 같이 한 행의 데이터를 여러 행의 데이터로 분할하는 것을 의미합니다. 이러한 상황은 대개 단순 반복이 필요하며 때로는 연간 데이터를 비례하여 매월 집계해야 할 때도 있습니다.


