희귀도 매핑 기반 NFT 평가 시스템 소개
이 기사의 출처:Blockin.ai & nftin.ai,이 기사의 출처:
허가를 받아 Odaily에서 게시했습니다.
디지털 자산 시장의 발전 이후 그것이 나타내는 지위 기호와 사회적 가치는 새로운 상업 가치가 되었으며 NFT(Non-fungible Token)는 이러한 상업 가치의 상징입니다. 고유하고 희소하며 복제할 수 없는 스마트 계약에 의해 생성, 유지 및 실행되는 비균질 디지털 자산 인증서입니다. NFT의 가치 평가는 희소성, 커뮤니티 인지도, 보유자 등 여러 측면에서 나옵니다. 같은 시리즈라도 각 NFT의 특징과 형태가 다르고, 다른 속성에 대한 관심도, 소유 이력 등이 다릅니다. 고유한 가치를 형성하므로 그에 대한 평가는 매우 중요하며 보다 나은 평가 시스템을 형성하고 시장에서의 빠른 거래를 위한 신뢰할 수 있는 기준 가격을 제공하기를 바랍니다.
NFT의 온체인 거래 내역과 NFT 메타데이터의 도움으로 먼저 서로 다른 컬렉션에 있는 항목의 희소성 점수를 계산했습니다. 두 번째로 NFT 희소성과 가격 사이의 상관 관계를 평가했습니다. 희귀도 매핑에 기반한 가격 체계를 연구하고 여러 프로젝트에서 소급 검증합니다.
보조 제목
1부. NFT 희소성 계산
이름에서 알 수 있듯이 NFT 희귀도는 NFT가 다른 수집품에 비해 얼마나 희귀한지를 측정합니다. 속성을 살펴보면 NFT에 몇 가지 희귀한 특성이 있음을 확인할 수 있지만 이 NFT는 다른 NFT에 비해 얼마나 희귀합니까?nftin.aiBAYC를 예로 들어
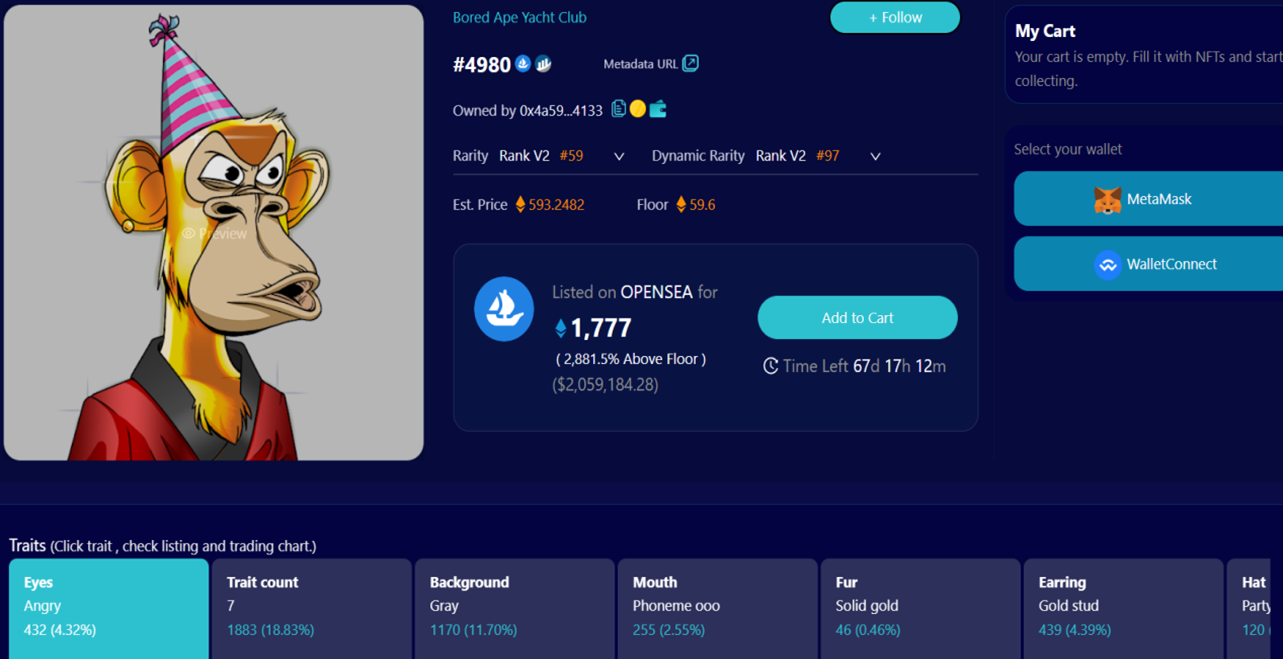
위와 같이 BAYC에는 배경, 옷, 귀걸이, 눈, 털, 모자, 입 등 7가지 특징이 있습니다.
각 기능 아래에는 서로 다른 하위 기능이 있으며 해당 하위 기능의 비율 빈도를 계산합니다. 비율을 계산하기 위해 파생된 기능으로 기능의 특성 수를 사용한다는 점은 주목할 가치가 있습니다. 각 NFT에는 여러 기능과 하위 기능이 있기 때문에 모든 기능의 희귀도를 단일 값으로 결합하여 희귀도 순위를 매길 수 있는 방법이 있어야 합니다.
이전에는 희귀도를 계산하는 몇 가지 방법이 있었습니다. 특성 희귀도 순위(가장 희귀한 특성에만 순위를 매김), 평균 특성 희귀도(모든 특성의 희귀도를 함께 평균화), 통계적 희귀도(모든 특성 곱셈의 희귀도를 결합)입니다. 희귀도 순위는 희귀 특성을 너무 강조하고 평균 및 통계적 희귀도 계산은 희귀 특성을 희석시킵니다. 따라서 특징의 희소성 점수를 희소성 점수로 누적하는 것이 위의 문제를 더 잘 해결할 수 있습니다.
주요 아이디어는 단일 NFT의 각 기능에 대한 희귀도 점수를 매긴 다음 NFT의 모든 기능에 대한 희귀도 점수를 추가하여 최종적으로 NFT의 전체 희귀도 점수를 얻는 것입니다. 즉, NFT의 총 희소성 점수는 모든 특징 값의 희소성 점수의 합이며 구체적인 계산 공식은 부록에 자세히 설명되어 있습니다.
예는 다음과 같습니다.

먼저 하위 기능의 비율을 계산합니다.

그런 다음 비율의 역수에 따라 하위 기능 점수와 총 점수를 계산합니다.
위와 같이 각 특징값의 희소성 점수와 각 NFT ID의 총 희소성 점수를 얻을 수 있으므로, 희소성 점수는 NFT ID 2가 총점수가 높기 때문에 더 가치가 있다고 판단합니다.
다른 기능 아래에 있는 다른 유형의 하위 기능을 고려하면 기능 빈도의 비율에 자연스러운 차이가 있다는 점은 주목할 가치가 있습니다. 위의 V1 버전을 개선했습니다.V2 버전의 주요 아이디어는 V1과 동일하므로 여기서는 자세히 다루지 않겠습니다.차이점은 하위 기능 수의 정규화가 고려된다는 것입니다. , 특징의 조합이 새롭게 파생된 특징으로 추가되어 더욱 풍부해진 특징의 조합은 NFT의 희소성을 보다 종합적으로 반영할 수 있습니다.
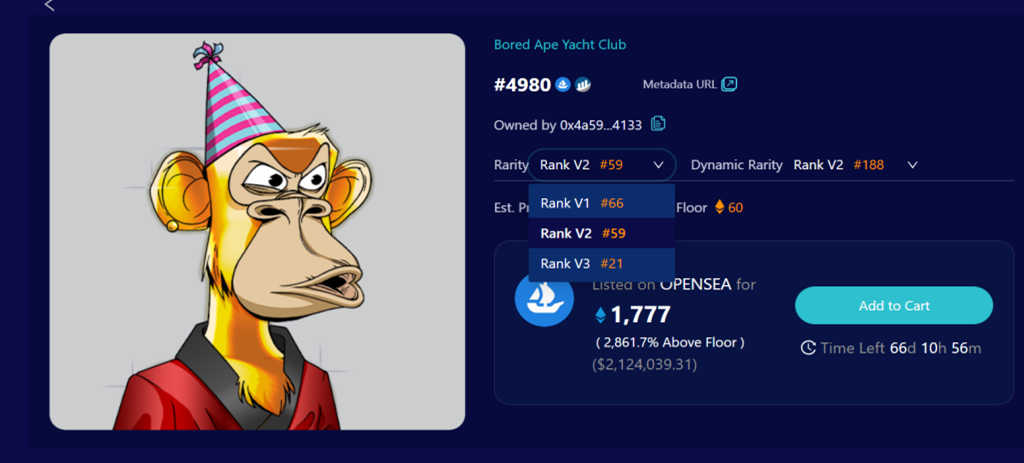
또한 일부 프로젝트의 경우 V3 버전도 계산했는데 V3 버전과 V2의 차이점은 세 가지 기능 조합이 추가되었다는 것입니다. 특성의 비율 값은 그다지 구별할 수 없기 때문에 일부 항목의 V3 희귀도 점수만 계산했습니다.
위 세 가지 버전의 희소성 계산과 더불어 역사상 거래된 적이 없는 일부 NFT를 고려하여 거래된 모든 NFT의 희소성 점수를 측정하고자 하므로 동적 희소성을 정의합니다. 정적 희소성 계산 방법과 일치하지만 동적 희소성 계산을 위한 데이터는 역사상 일정 기간 동안 거래된 NFT뿐이므로 데이터는 NFT 전체 수량의 일부일뿐입니다. . 또한 시간이 바뀌면 계산 데이터 세트가 수시로 바뀌기 때문에 다이내믹 레어리티를 매일 실시간으로 업데이트합니다. 요컨대, 동적 희소성은 객관적 속성의 비율을 고려할 뿐만 아니라 거래 기간 내 NFT의 희소성을 동적으로 반영하는 과거 거래 상황도 고려합니다.
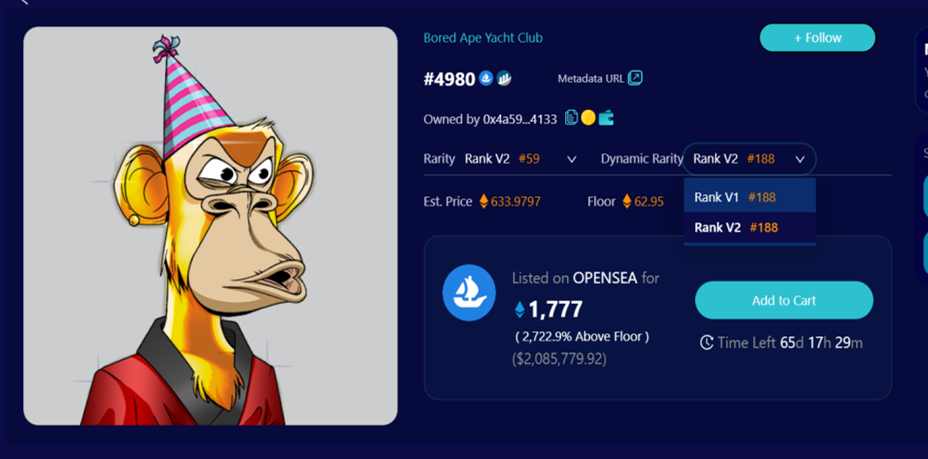
또한 jaccard 거리와 같은 희소성의 다른 계산 방법도 탐색했습니다. jaccard 거리는 두 세트의 비 유사성을 측정하는 지표이며 두 NFT 기능 간의 유사성을 계산할 수 있습니다. NFT 희소성이 높을수록 구체적인 계산 방법은 부록을 참조할 수 있습니다.
보조 제목
2부 희소성과 가격의 상관관계 연구
많은 경우에 사람들은 희소성에 대한 프리미엄을 기꺼이 지불하지만 희소성이 가격에 정확히 어떤 영향을 미칩니 까? 체인의 과거 거래 데이터의 도움으로 우리는 NFT 가격과 희소성 사이의 본질적인 상관관계를 평가하기 위해 여러 우량 프로젝트를 예로 들었습니다.
이미 각 아이템에 대한 희소성 점수를 계산한 점을 고려하여 희소성 점수와 가격 사이의 상관 관계를 직접 탐색하여 둘 사이의 Spearman 상관 계수를 계산했습니다.
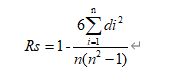
구체적인 계산 방법은 다음과 같습니다.
여기서 n은 샘플 수이고 d는 데이터 x와 y 사이의 순위 차이를 나타냅니다.
절대값이 1에 가까울수록 두 변수 사이의 관계가 가깝고, 0에 가까울수록 두 변수 사이의 관계가 덜 가깝습니다. 상관 계수에 해당하는 상관 강도는 다음과 같습니다.
0.8-1.0 매우 강한 상관관계
0.6-0.8 강한 상관관계
0.4-0.6 중간 상관관계
0.2-0.4 약한 상관관계
0.0-0.2 상관관계가 매우 약하거나 없음
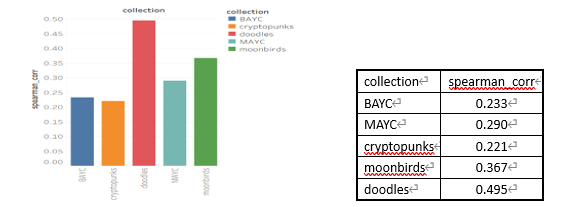
BAYC, MAYC, 크립토펑크, 문버드, 두들 등 5개의 블루칩 프로젝트를 예로 들어 지난 2개월 동안의 거래 가격과 희소성 점수(V2) 간의 상관관계를 계산합니다. 차트는 다음과 같습니다.
위의 차트는 대부분의 아이템 중 단일 아이템의 희귀도 점수와 가격 사이에 약한 상관관계가 있음을 보여줍니다.
x > 10: Legendary
6 < x <= 10: Rare
2 < x <= 6: Classic
x <= 2: Normal
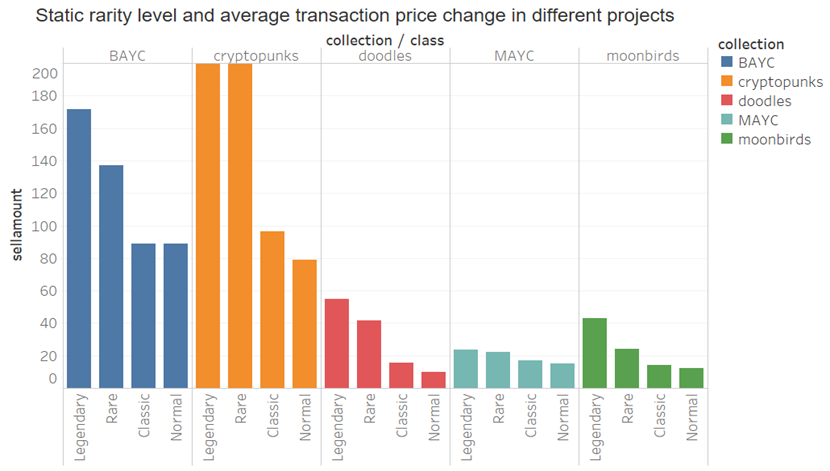
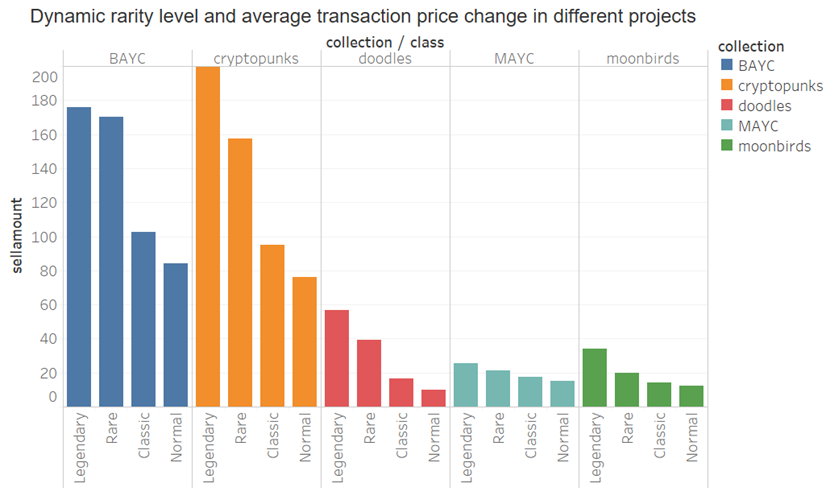
위의 그림에서 동적 희소성이든 정적 희소성이든 NFT 수준이 높을수록 평균 과거 거래 가격이 높다는 것을 알 수 있습니다. 가격, 그러나 전반적으로 고급 NFT의 판매 가격은 여전히 상대적으로 높습니다. 즉, 사람들은 희귀한 NFT에 대해 더 높은 가격을 기꺼이 지불합니다.
보조 제목
3부 희귀도 매핑을 위한 평가 시스템
위의 연구에서 희소도가 높을수록 해당 수준의 일반 거래 가격이 높아지는 것을 알 수 있으므로 과거 거래 데이터와 NFT 희소도 수준에 의존하는 희소도 매핑을 기반으로 한 평가 시스템 설계를 고려했습니다. 최신 NFT 시장 가격.
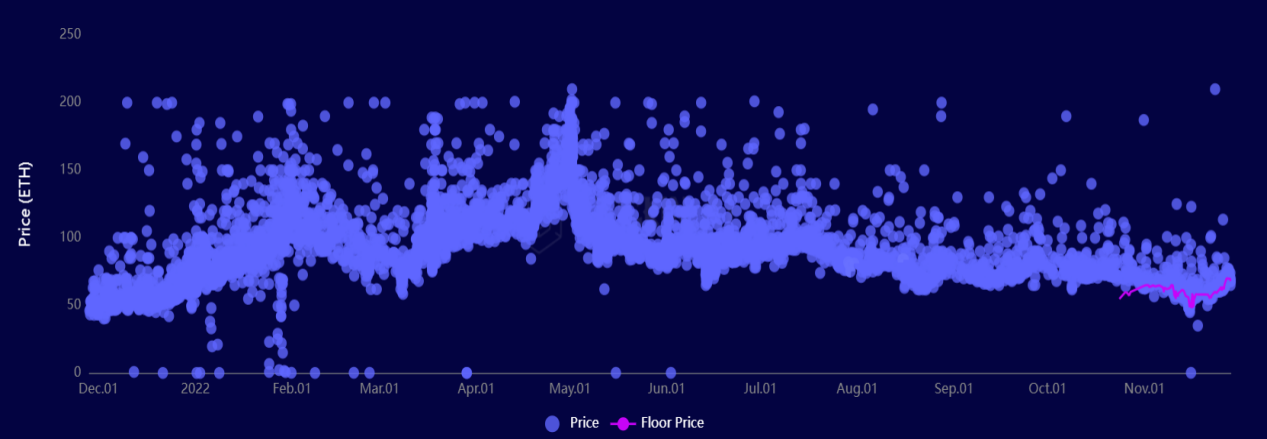
시장에서 NFT 가격의 불안정성으로 인해 과거 거래의 가로선은 현재 거래의 가로선을 나타낼 수 없으며 매일, 매월 거래되는 NFT의 가격도 해당 가로선 범위 내에서 변동합니다. 예를 들어 BAYC의 트랜잭션 변동을 다음 그림과 같이 보여줍니다.
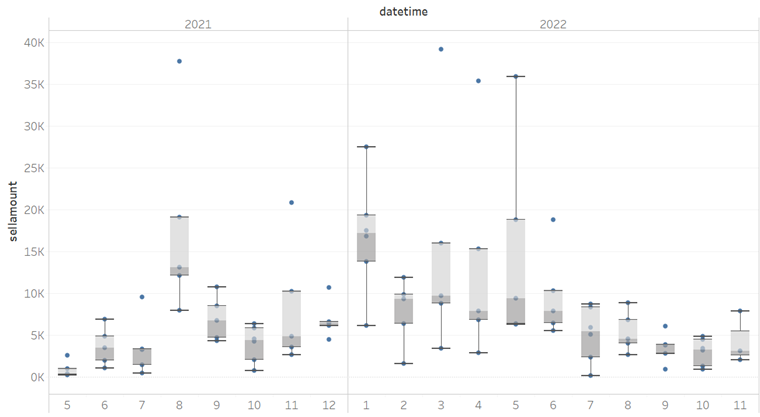
따라서 서로 다른 프로젝트의 NFT 거래에 대해서는 거래 분포의 기준점으로 일일 거래 상황을 측정할 수 있는 수평선 값을 찾는 것을 고려합니다. 중앙값을 일일 거래 가격으로 사용 앵커 포인트는 중앙값을 기준으로 다른 지표를 계산하며 아래 그림과 같이 상한가와 하한가 등이 있으므로 대략적으로 복원합니다. 다른 기간의 거래 분포, 과거 거래의 분포 규칙에 따라 다른 NFT의 최신 거래 가격을 추정합니다.
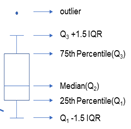
참고: 상위 사분위수: Q3 중앙값: Q2 하위 사분위수: Q1 사분위 범위(IQR): Q3 - Q1 상한: Q3 + 1.5*IQR
하한: Q1 - 1.5*IQR 최대값: 최대 최소값: 최소 평균값: 평균
1. 방법은 다음과 같이 요약됩니다.역사적 비율 계산
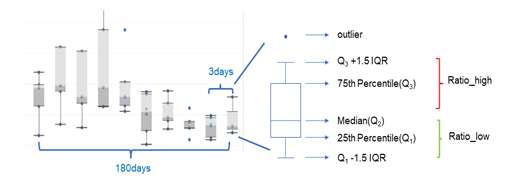
2. : 지난 6개월 동안 3일마다 ratio_high와 ratio_low를 계산하여 모든 ratio_high와 ratio_low, ratio_high_avg, ratio_low_avg의 평균을 구합니다.과거 비율을 기반으로 최신 가상 상한 및 하한을 계산합니다.
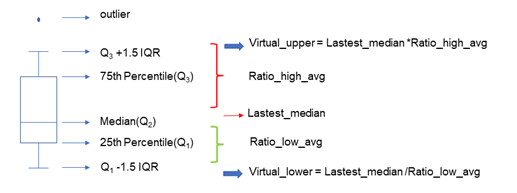
3. : 위에서 구한 ratio_high_avg/ratio_low_avg와 최신 중앙값으로부터 가상 상하한 Virtual_upper와 Virtual_lower를 계산최신 평가 코호트 구성
4. : 가상의 상하한가와 최근 기간의 모든 거래분포를 바탕으로 최신 평가대기열을 생성하고, 상한가와 하한가 내의 원본 거래 데이터를 구간[하한가, 상한가]에 채우고, 평가 코호트의 최종 피팅 분포로 외부 데이터.:
평가 코호트 순위 매핑
a. 다른 클래스 내의 원시 거래 가격을 평균화합니다. (최신 거래주기에 일부 레벨 값이 존재하지 않는 경우 전후 두 레벨의 평균값을 사용하여 순서를 채웁니다)

b.아이템의 희귀도(정규화된 희귀도 점수(V2)에 따라 20단계로 구분됨)에 따라 서로 다른 등급의 거래 평균값을 다른 등급의 모든 아이템에 매핑하여 평가를 얻습니다.
평가의 객관적 정확성을 보장하기 위해 먼저 다음과 같이 평가 전에 거래 데이터를 정리했습니다.
A. 명백한 칫솔질 행동과 해당 거래 플랫폼을 제거하십시오.
b.프로젝트 초기에는 거래 시장이 불안정한 점을 고려하여 프로젝트마다 이전 몇 개월 간의 거래 데이터를 제외합니다.
c.일중 거래중위대비 비율이 너무 작은 개인거래가 있어 시장수준을 객관적으로 반영할 수 없어 제외한다.
또한, 위의 계산 버전에서 과거 거래 결과를 역추적하여 일부 평가 결과가 당사의 평가 기대치를 충족하지 못함을 발견했습니다. 따라서 위 버전을 기준으로 희귀도가 높은 일부 ID의 평가를 수정하였습니다: 과거 고액 거래가 있었던 ID의 경우 과거 거래 비율의 평균 ratio_avg를 별도로 계산하고, 최신 주기 트랜잭션 숫자 median*ratio_avg를 사용하여 순위 맵의 추정치를 대체합니다.
여러 버전의 희귀도 등급이 존재하기 때문에 다양한 프로젝트에서 다양한 방식의 희귀 등급 매핑 평가를 실험하고 소급 검증을 수행했습니다. 종합적인 결과와 효율성의 관점에서 볼 때 V2 버전의 희귀도 등급 매핑이 더 좋으므로 현재 정적 희귀도 V2 매핑을 사용한 평가가 온라인에 표시됩니다.
평가 정확도 검증
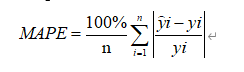
가치평가 시스템의 정확성을 측정하기 위해 특정일의 예상가격과 당일 실제 거래가격을 기준으로 절대평균오차(Mean Absolute Percentage Error, MAPE)를 계산한다.
이 중 yi는 실제 값을 나타내고 y^i는 예측 값을 나타내며 n은 NFT의 수입니다.

여러 블루칩 프로젝트의 검증 결과는 다음과 같으며 검증 날짜는 2022년 이후(2022-01-01 ~ 2022-11-15) 데이터입니다.
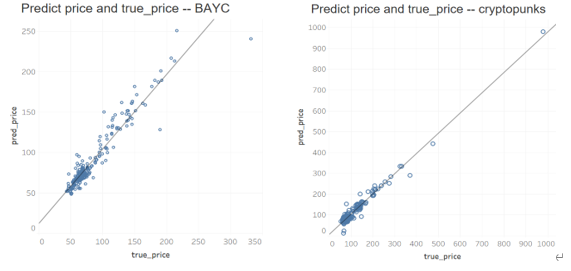
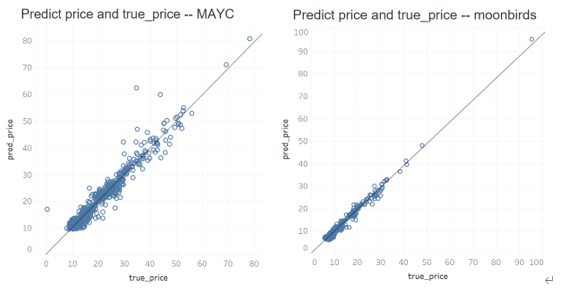
다음은 거의 두 달 전(2022-10-01 ~ 2022-11-15) 여러 프로젝트의 예상 가격과 실제 거래 가격의 산점도를 보여줍니다.
결론 및 요약
보조 제목
부록
V 1:

V2:
부록
a.특징 점수 계산의 정규화
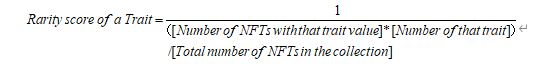
기능 정규화는 다른 기능 아래의 하위 기능 수로 인해 발생하는 기능 희귀도 점수의 차이를 고려합니다. 예를 들어, BAYC 프로젝트에서 Earring은 7개의 서로 다른 하위 기능을 가지고 있고 Mouth는 33개의 서로 다른 하위 기능을 가지고 있으며 일반적으로 Mouth는 Earring보다 차별적인 희소성 점수를 가지므로 기능 정규화를 고려합니다.
b. 특징의 쌍별 조합
여러 기능의 순열 및 조합을 기반으로 다양한 기능 조합의 비율 통계가 풍부해지고 희소성이 고차 방식으로 설명될 수 있습니다. 예를 들어, BAYC는 총 7개의 서로 다른 부분 특징을 가지고 있으며, 쌍으로 된 서로 다른 조합의 수는 Combine(7, 2) = 21이며, 쌍의 조합을 새로운 특징으로 사용하여 희소성 점수가 계산됩니다. 결합된 특징 희귀도 점수의 계산 방법은 위와 동일하며 여기서는 반복하지 않습니다.
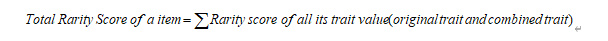
요약하자면,
자카드 거리:
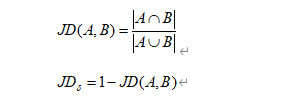
Jaccard Distance는 두 집합의 비유사도를 측정하는 지표로 그 범위는 [0, 1]이며 수식은 다음과 같다.
계산 프로세스는 네 단계로 구성됩니다.
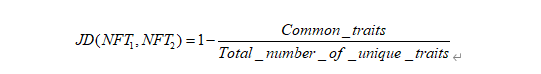
a. 1 - 고유 속성의 총 수로 나눈 유사한 기능의 수(모든 NFT 쌍에 대해 이 프로세스 반복)
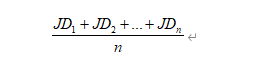
b. 모든 결과의 평균
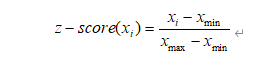
c. 정규화