
에테르 로밍: 과거, 현재, 미래
원작자: Hakeen, W3.Hitchhiker
원본 편집자: Evelyn, W3.Hitchhiker

1. 이더리움 M2SVPS 업그레이드 로드맵
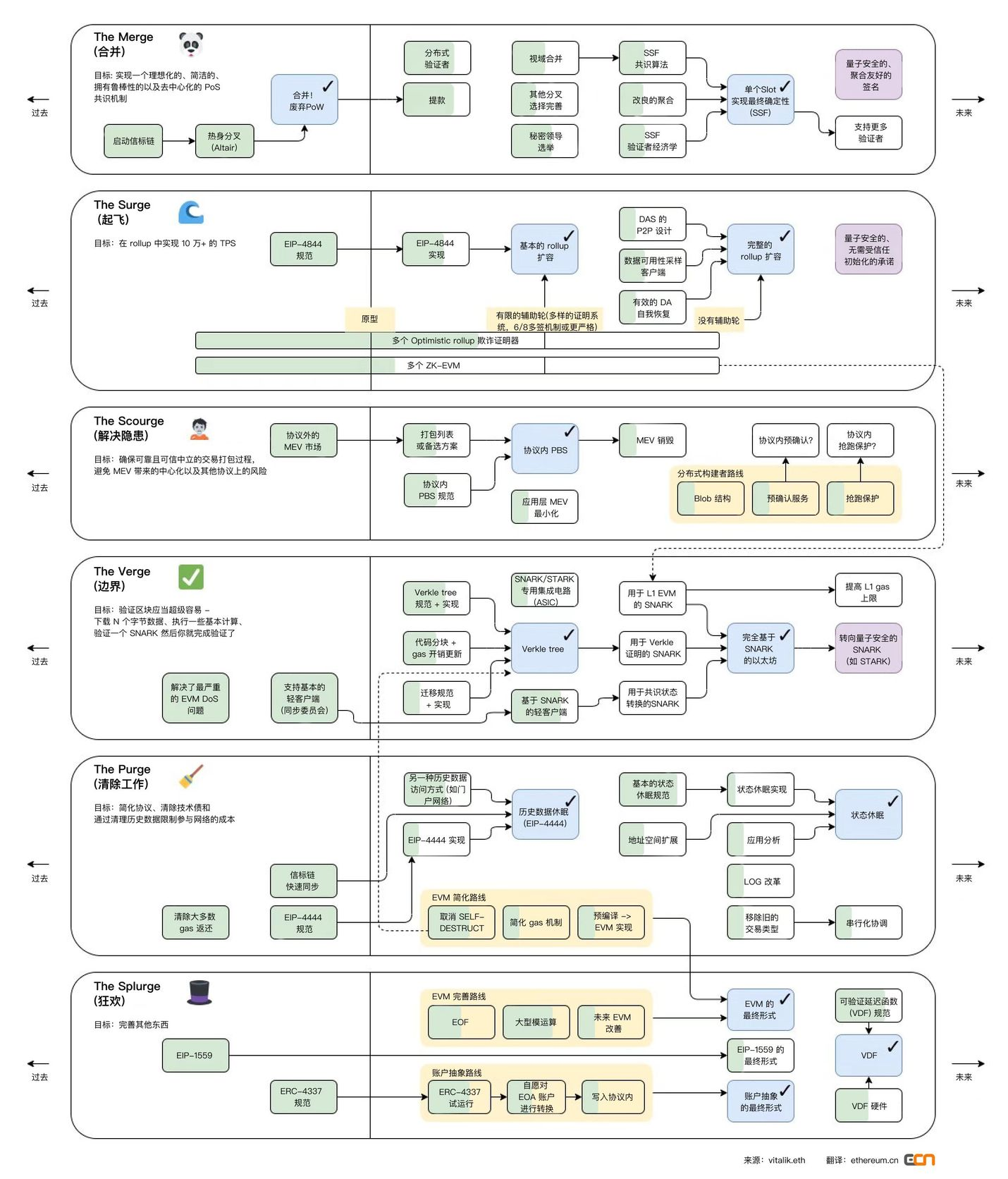
The Merge

The Merge 단계에서는 POW 합의 메커니즘이 POS로 전환되고 비콘 체인이 함께 병합됩니다. 이해를 돕기 위해 Ethereum의 구조를 다음 다이어그램으로 단순화합니다.
여기에서 먼저 단편화가 무엇인지 정의합니다. 간단한 이해는 데이터베이스를 수평으로 분할하여 로드를 분산시키는 프로세스입니다.
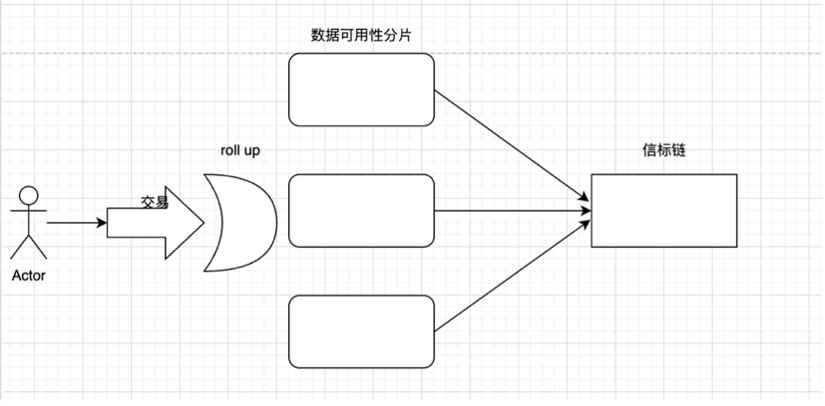
POS로 전환한 후: 블록 제안자와 블록 검증자가 분리되고 POS 작업 흐름은 다음과 같습니다(위의 이해에 따라).
롤업에서 트랜잭션 제출
유효성 검사기는 샤드 블록에 트랜잭션을 추가합니다.
비콘 체인은 검증자를 선택하여 새로운 블록을 제안합니다.
나머지 검증자는 무작위 위원회를 구성하고 샤드에서 제안을 검증합니다.
블록 제안 및 제안 제안은 일반적으로 12초인 하나의 슬롯 내에서 완료되어야 합니다. 매 32개의 슬롯은 에포크 주기를 구성하며 각 에포크는 유효성 검사기 순서를 방해하고 위원회를 다시 선출합니다.
합병 후 Ethereum은 합의 계층을 구현할 것입니다.제안자-빌더 분리(PBS). Vitalik은 모든 블록체인의 최종 목표는 중앙 집중식 블록 생성과 분산형 블록 검증이 될 것이라고 믿습니다. 조각난 이더리움 블록 데이터는 매우 밀도가 높기 때문에 데이터 가용성에 대한 높은 요구 사항으로 인해 블록 생산의 중앙 집중화가 필요합니다. 동시에 블록을 검증하고 데이터 가용성 샘플링을 수행할 수 있는 분산된 검증자 세트를 유지 관리하는 방법이 있어야 합니다.
채굴자와 블록 검증은 분리되어 있습니다. 채굴자는 블록을 만들고 검증자에게 제출합니다. 자신의 블록을 선택하기 위해 검증자에게 입찰한 다음 검증자는 블록이 유효한지 여부를 결정하기 위해 투표합니다.
Fragmentation은 P2P 네트워크에서 컴퓨팅 작업과 스토리지 워크로드를 분산시킬 수 있는 파티셔닝 방식으로, 이 처리 방식 이후 각 노드는 전체 네트워크의 트랜잭션 부하 처리를 담당하지 않고 자신의 파티션과 관련된 데이터만 유지하면 된다( 또는 단편화) 정보는 괜찮습니다. 각 샤드에는 자체 유효성 검사기 또는 노드 네트워크가 있습니다.
조각화 보안 문제: 예를 들어 전체 네트워크에 10개의 샤드 체인이 있는 경우 전체 네트워크를 파괴하는 데 컴퓨팅 성능의 51%가 필요하고 단일 샤드를 파괴하는 데 컴퓨팅 성능의 5.1%만 필요합니다. 따라서 후속 개선에는 51% 컴퓨팅 파워 공격을 효과적으로 방지할 수 있는 SSF 알고리즘이 포함됩니다. ~에 따르면vitalik요약하면 SSF로의 이동은 다년간의 로드맵이며 지금까지 많은 작업을 수행했음에도 불구하고 이더리움이 나중에 구현할 주요 변경 사항 중 하나가 될 것이며 이더리움의 PoS 증명 메커니즘인 샤딩에 훨씬 뒤쳐질 것입니다. , 및 Verkle 트리는 이후에 완전히 시작됩니다.
비콘 체인은 난수 생성, 샤드에 노드 할당, 단일 샤드의 스냅샷 캡처 및 기타 다양한 기능을 담당하고 샤드 간 통신 완료 및 네트워크 동기화 조정을 담당합니다.
비콘 체인의 실행 단계는 다음과 같습니다.
블록 생산자는 입찰과 함께 블록 헤더를 약속합니다.
비컨체인의 블록 생성자(검증자)는 낙찰된 블록 헤더와 입찰을 선택하며, 블록 패키저가 최종적으로 블록 본체를 생성하는지 여부에 관계없이 무조건 낙찰 수수료를 받습니다.
위원회(유효성 검사자 중에서 무작위로 선택)는 획득한 블록 헤더를 확인하기 위해 투표합니다.
블록 패커는 블록 본체를 공개합니다.
The Surge
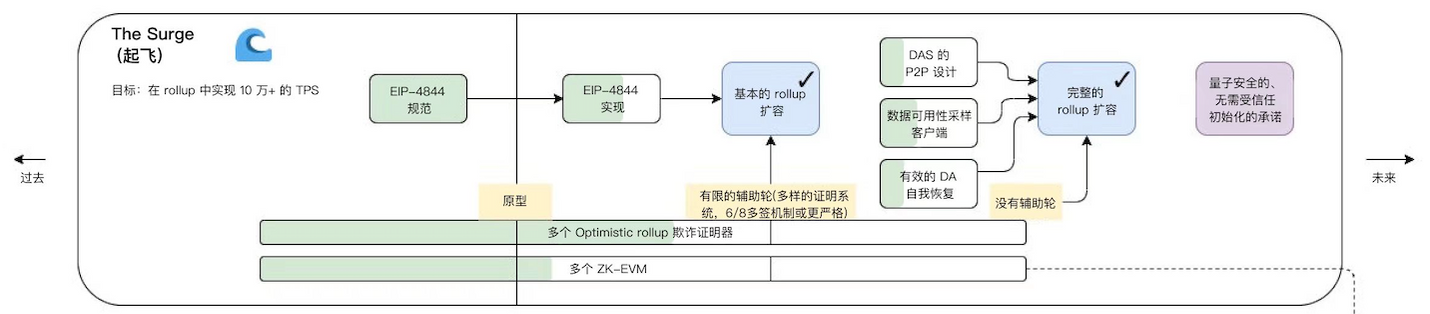
이 경로의 주요 목표는 롤업 중심의 확장을 촉진하는 것입니다. 서지는 스케일링 솔루션인 이더리움 샤딩을 추가하는 것을 말하며,이더리움 재단 주장: 이 솔루션은 가스 요금이 낮은 레이어 2 블록체인을 더욱 활성화하고, 롤업 또는 번들 트랜잭션 비용을 줄이고, 사용자가 이더리움 네트워크를 보호하는 노드를 더 쉽게 운영할 수 있도록 합니다.
다이어그램은 다음과 같은 단순화된 다이어그램으로 여전히 이해할 수 있습니다.
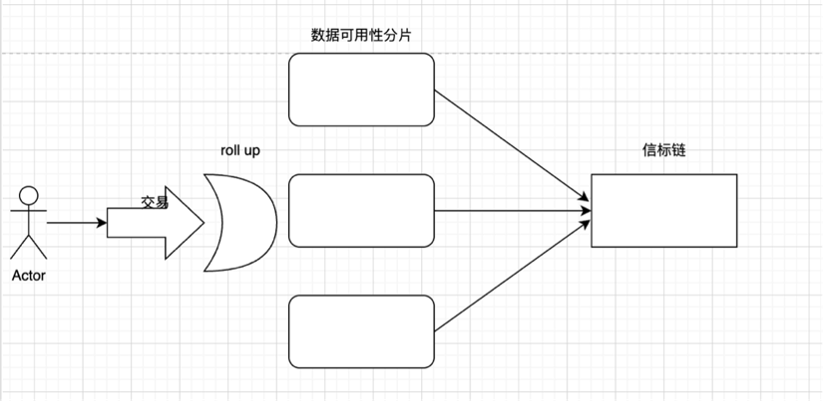
zkrollup의 작동 원리를 예로 들어 보겠습니다: zkrollup은 시퀀서(sequencer)와 어그리게이터(aggregator)로 구분되며, 시퀀서는 사용자 트랜잭션을 정렬하고 배치로 패키징하여 어그리게이터로 보내는 역할을 합니다. aggregator는 트랜잭션을 실행하고 prev state root에서 post state root(post state root)를 생성한 후 proof(proof)를 생성하고 aggregator는 최종적으로 pre-state root, post-state root, transaction data, and Proof to L1 계약에 대한 계약은 증명이 유효한지 여부를 확인하는 책임이 있으며 거래 데이터는 calldata에 저장됩니다. Zkrollup 데이터 가용성을 통해 누구나 체인에 저장된 트랜잭션 데이터를 기반으로 계정의 글로벌 상태를 복원할 수 있습니다.
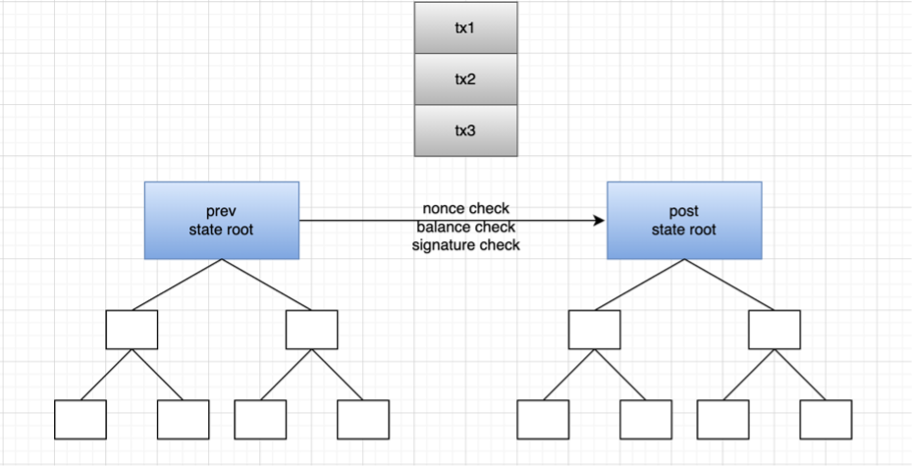
하지만 calldata를 사용하는 것은 매우 비싸므로 전체EIP-4844 프로토콜(언제든 변경될 수 있음) 트랜잭션 블록의 크기를 1-2MB로 변경하여 향후 롤업 및 데이터 조각화에 대한 견고한 기반을 마련할 것을 제안합니다. 현재 이더리움의 블록 크기는 약 60KB ~ 100KB 정도이며, EIP-4844를 예로 들면 블록 크기 제한을 10 ~ 34배까지 늘릴 수 있습니다. 블록 형식을 blob(데이터 샤드라고도 함)이라고 합니다.

The Scourge
이 단계의 Scourge는 로드맵을 보완하는 것으로 주로 MEV의 문제를 해결하는 데 사용됩니다. 그렇다면 MEV는 무엇입니까?

MEV의 정식 명칭은 Miner Extractable Value / Maximal Extractable Value입니다.작업 증명병합병합지분 증명으로 전환한 후에는 유효성 검사기가 이러한 역할을 담당하고 채굴은 더 이상 적용되지 않습니다(여기에서 설명하는 가치 추출 방법은 이 전환 후에도 유지되므로 이름 변경이 필요함). 동일한 기본 의미를 유지하면서 연속성을 보장하기 위해 동일한 약어를 계속 사용하기 위해 이제 "최대 추출 가능 가치"가 보다 포괄적인 대안으로 사용됩니다.
재정 거래 공간에는 다음이 포함됩니다.
저장 공간을 압축하여 가스 요금의 가격 차이를 얻습니다.
심판이 앞서갑니다: mempool에서 거래를 광범위하게 검색하고, 기계는 로컬에서 계산을 실행하여 수익성이 있는지 확인하고, 그렇다면 자체 주소로 동일한 거래를 시작하고 더 높은 가스 요금을 사용합니다.
청산 대상 찾기: 봇은 블록체인 데이터를 가장 빨리 분석하여 청산할 수 있는 대출자를 결정한 다음 가장 먼저 청산 거래를 제출하고 자체 청산 수수료를 징수합니다.
샌드위치 트랜잭션: 검색자는 mempool에서 DEX의 대규모 트랜잭션을 모니터링합니다. 예를 들어 누군가가 Uniswap에서 DAI를 사용하여 10,000 UNI를 구매하려고 합니다. 이러한 대규모 거래는 UNI/DAI 쌍에 상당한 영향을 미칠 수 있으며 잠재적으로 DAI에 비해 UNI의 가격을 크게 높일 수 있습니다. 검색자는 UNI/DAI 쌍에 대한 대량 거래의 대략적인 가격 영향을 계산하고 대량 거래 직전에 최적의 매수 주문을 실행하고, 낮은 가격에 UNI를 매수한 다음 대량 거래 직후에 매도 주문을 실행할 수 있습니다. 금액 거래, 많은 양의 주문으로 인해 더 높은 판매 가격이 발생합니다.
MEV의 단점:
샌드위치 거래와 같은 일부 형태의 MEV는 사용자 경험을 상당히 악화시킬 수 있습니다. 중간에 갇힌 사용자는 더 높은 슬리피지와 열악한 거래 실행에 직면합니다. 네트워크 계층에서 일반적으로 선두주자와 가스 경매에 자주 참여하는(2명 이상의 선두주자가 자신의 거래가 다음 블록에 포함되도록 자신의 거래에 대한 가스 수수료를 점진적으로 인상하는 경우) 네트워크 정체와 높은 가스 수수료로 이어집니다. 다른 사람들은 정상적인 거래를 시도합니다. 블록 내에서 발생하는 것 외에도 MEV는 블록 간에 해로운 영향을 미칠 수 있습니다. 블록에서 사용 가능한 MEV가 표준 블록 보상을 크게 초과하는 경우 채굴자는 블록을 재채굴하고 MEV를 캡처하여 블록체인 재구성 및 합의 불안정으로 이어질 수 있습니다.
대부분의 MEV는 "탐색자"라고 하는 독립적인 네트워크 참여자에 의해 추출됩니다. Seeker는 블록체인 데이터에서 복잡한 알고리즘을 실행하여 수익성 있는 MEV 기회를 감지하고 이러한 수익성 있는 거래를 네트워크에 자동으로 제출하는 봇이 있습니다. Ethereum의 MEV 문제는 봇을 사용하여 네트워크 트랜잭션을 악용하여 혼잡과 높은 수수료를 유발하는 것과 관련이 있습니다.
The Verge
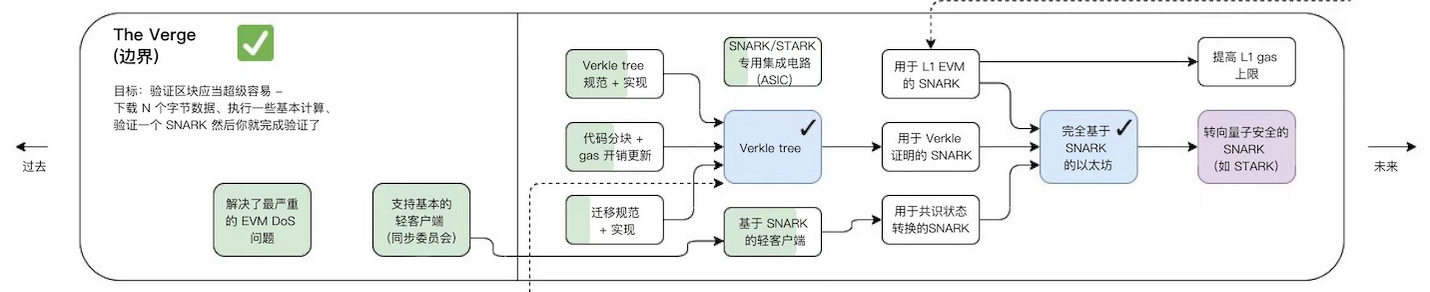
Verge는 "버클 트리"(일종의 수학적 증명) 및 "상태 비저장 클라이언트". 이러한 기술 업그레이드를 통해 사용자는 컴퓨터에 대량의 데이터를 저장하지 않고도 네트워크의 검증자가 될 수 있습니다. 이는 또한 롤업 확장에 대한 단계 중 하나라고 언급했습니다. 앞서 zk 롤업의 간단한 작동 원리를 통해 애그리게이터는 증명을 제출하고 레이어 1의 검증 계약은 blob의 KZG 커밋과 생성된 증명만 확인하면 됩니다.다음은 KZG 커밋에 대한 간략한 소개입니다. 모든 트랜잭션이 포함되도록 하십시오. 롤업은 증명을 생성하기 위해 일부 트랜잭션을 제출할 수 있기 때문에 KZG를 사용하면 모든 트랜잭션이 증명을 생성하기 위해 포함되도록 보장됩니다.
The Verge는 검증이 매우 간단하도록 하기 위한 것입니다.N바이트의 데이터를 다운로드하고 기본 계산을 수행하여 롤업에서 제출한 증명을 검증하기만 하면 됩니다.
이 기사이 기사。
The Purge
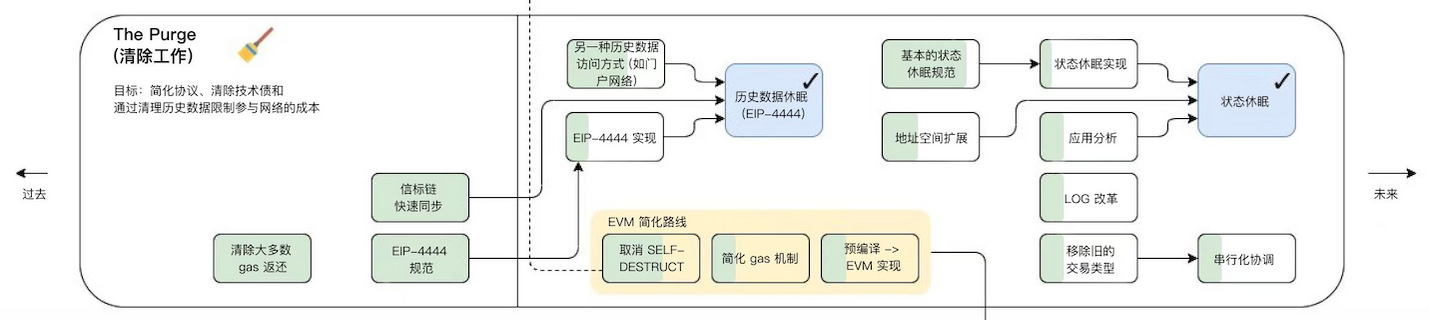
퍼지는 하드 드라이브에 ETH를 저장하는 데 필요한 공간을 줄여 이더리움 프로토콜을 단순화하고 노드가 기록을 저장할 필요가 없도록 합니다. 이것은 네트워크의 대역폭을 크게 증가시킬 수 있습니다.
EIP-4444:
클라이언트는 P2P 계층에서 1년 이상 된 헤더, 본문 및 수신자 서비스를 중단해야 합니다. 클라이언트는 이러한 기록 데이터를 로컬에서 정리할 수 있습니다. 이더리움의 역사를 보존하는 것은 기본이며 이를 달성하기 위한 다양한 대역 외 방법이 있다고 생각합니다. 기록 데이터는 토렌트 마그넷 링크 또는 IPFS와 같은 네트워크를 통해 패키지화 및 공유될 수 있습니다. 또한 Portal Network 또는 The Graph와 같은 시스템을 사용하여 기록 데이터를 얻을 수 있습니다. 클라이언트는 기록 데이터의 가져오기 및 내보내기를 허용해야 합니다. 클라이언트는 데이터를 가져오고 유효성을 검사하고 자동으로 가져오는 스크립트를 제공할 수 있습니다.
The Splurge

이 경로는 주로 계정 추상화, EVM 최적화 및 난수 체계 VDF 등과 같은 단편적인 최적화 수정입니다.
여기서 언급한 계정 추상화(Account Abstraction, AA)는 항상 ZK 시스템의 레이어 2가 먼저 달성하고자 하는 목표였습니다. 그렇다면 계정 추상화란 무엇입니까? 계정 추상화를 구현한 후 스마트 계약 계정은 "메타 트랜잭션" 메커니즘(EIP-4844에서 제안됨)에 의존하지 않고 트랜잭션을 시작할 수도 있습니다.
이더리움에서 계정은 계약 계정과 외부 계정으로 나뉩니다. 현재 이더리움에는 외부 주소로 시작해야 하는 트랜잭션 유형이 한 가지뿐이며 계약 주소는 트랜잭션을 적극적으로 시작할 수 없습니다. 따라서 계약 자체의 상태 변경은 외부 주소에 의해 시작된 트랜잭션에 따라야 하며 다중 서명 계정, 통화 혼합기 또는 스마트 계약의 구성 변경 여부에 따라 트리거되어야 합니다. 적어도 하나의 외부 계정.
이더리움에서 어떤 애플리케이션을 사용하든 사용자는 이더리움을 보유해야 합니다(그리고 이더리움 가격 변동의 위험을 감수해야 합니다). 둘째, 사용자는 복잡한 수수료 논리, 가스 가격, 가스 제한, 트랜잭션 차단을 처리해야 합니다. 이러한 개념은 사용자에게 너무 복잡합니다. 많은 블록체인 지갑이나 애플리케이션이 제품 최적화를 통해 사용자 경험을 개선하려고 하지만 거의 효과가 없습니다.
계정 중심 솔루션의 목표는 스마트 계약 관리를 기반으로 사용자 계정을 생성하는 것입니다. 계정 추상화 구현의 이점은 다음과 같습니다.
현재 계약은 ETH를 보유하고 모든 서명을 포함한 트랜잭션을 직접 제출할 수 있습니다.사용자는 트랜잭션에 대해 반드시 가스 비용을 지불할 필요가 없으며 모두 프로젝트에 따라 다릅니다.
사용자 지정 암호화 구현으로 인해 서명에 ESCDA 타원 곡선을 사용하는 것은 향후 필수 사항이 아니며 지문 인식, 안면 인식, 생체 인식 및 기타 휴대 전화 기술을 서명 방법으로 사용할 수 있습니다.
이것은 이더리움과 상호 작용하는 사용자 경험을 크게 향상시킵니다.
2. 이더리움의 모듈화
이더리움 전체가 모듈화 추세를 보이고 있으며 실행 레이어는 레이어 2(예: arbitrum, zksync, starknet, 폴리곤 zkevm 등)를 담당하고 있습니다. 그들은 L2에서 사용자 트랜잭션을 실행하고 증명을 제출할 책임이 있습니다. 레이어 2는 일반적으로 OP 기술/ZK 기술을 사용합니다.이론적으로 ZK 기술의 TPS는 OP보다 훨씬 높습니다.현재 많은 생태계가 OP 시스템에 있지만 앞으로 ZK 기술의 개선으로 , 점점 더 많은 애플리케이션이 ZK 부서로 마이그레이션될 것입니다. 이 섹션은 로드맵에 대한 자세한 설명과 보충 이유 및 방법입니다.
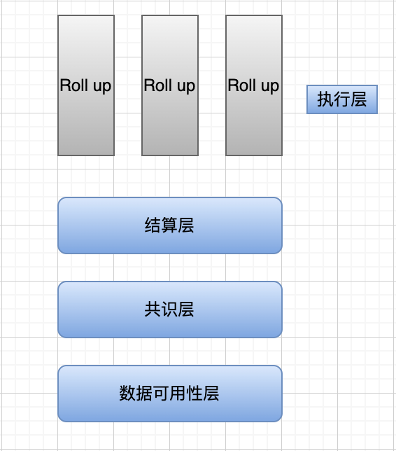
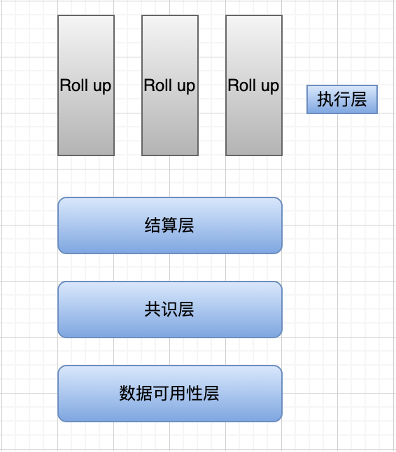
현재 이더리움은 실행 계층만 분리하고 있고, 사실 다른 계층은 아직 혼재되어 있습니다. Celestia의 비전에서 실행 계층은 단일 트랜잭션의 경우 트랜잭션을 실행하고 상태를 변경하고 동일한 트랜잭션 배치에 대해 배치의 상태 루트를 계산하는 두 가지 작업만 수행합니다. 현재 Ethereum 실행 계층 작업의 일부는 StarkNet, zkSync, Arbitrum 및 Optimism으로 알려진 Rollup에 할당됩니다.
이제 옵티미즘, 폴리곤, 스타크넷, zksync 등 모두 모듈화의 길을 모색하고 있습니다.
Optimism은 기반암/op 스택을 제안하고, 폴리곤은 또한 데이터 가용성 계층으로 폴리곤 가용성을 개발하고 있으며, 슈퍼넷은 체인 생성을 단순화하고 유효성 검사기 세트를 공유하는 데 사용됩니다.
Settlement Layer: 위에서 언급한 Pre-state Root, Post-state Root, Proof Validity(zkRollup) 또는 Fraud Proof(Optimistic Rollup)를 Main Chain에서 Rollup 컨트랙트로 검증하는 과정으로 이해할 수 있습니다.
합의 계층: PoW, PoS 또는 기타 합의 알고리즘에 관계없이 합의 계층은 분산 시스템에서 무언가에 대한 합의에 도달하는 것입니다. 즉, 상태 전환의 유효성에 대한 합의에 도달하는 것입니다(이전 상태는 계산 루트 후 사후 상태). 모듈화의 맥락에서 정산층과 합의층의 의미는 다소 비슷하기 때문에 일부 연구자들은 정산층과 합의층을 통합하기도 했다.
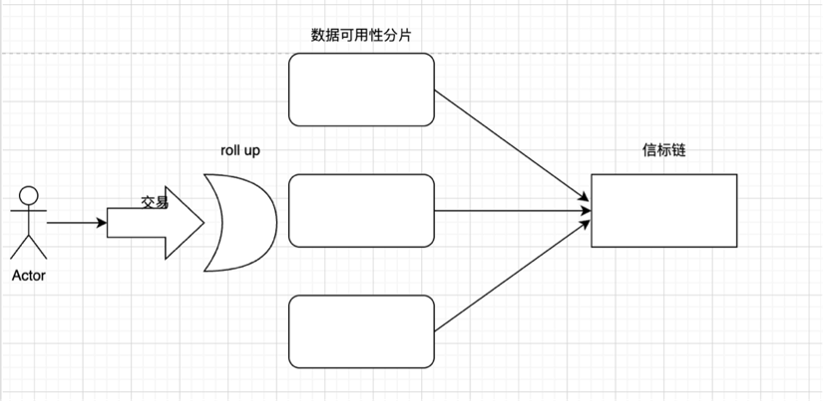
데이터 가용성 계층: 트랜잭션 데이터가 데이터 가용성 계층에 완전히 업로드되고 검증 노드가 이 계층의 데이터를 통해 모든 상태 변경을 재현할 수 있는지 확인합니다.
여기서 구별해야 할 것은 데이터 가용성과 데이터 스토리지의 차이입니다.
데이터 가용성은 데이터 저장소와 분명히 다릅니다. 전자는 최신 블록 릴리스를 기준으로 데이터의 가용성과 관련이 있는 반면 후자는 데이터를 안전하게 저장하고 필요할 때 액세스할 수 있도록 보장하는 것과 관련됩니다.
1. 정산 레이어의 다양한 롤업
정산 계층의 관점에서 볼 때 현재 롤업의 초점은 ZK 시스템에 있다고 생각됩니다. ZK 증명 시스템의 롤업을 통해 ZK 증명 시스템의 크기, 가스 소비, 비용을 개선하고 재귀 및 병렬 처리와 결합하면 TPS를 크게 확장할 수 있습니다. ZK 롤업부터 시작하겠습니다.
이더리움 확장의 발전과 함께 ZKP(Zero Knowledge Proof) 기술은 Vitalik이 확장 전쟁의 끝이 될 것으로 예상되는 솔루션으로 간주됩니다.
ZKP의 본질은 누군가가 무언가를 알고 있거나 가지고 있음을 증명하는 것입니다. 예를 들어, 나는 열쇠를 꺼내지 않고도 문 열쇠를 가지고 있음을 증명할 수 있습니다. 계정 암호를 입력하지 않고 노출 위험이 있음을 증명하는 것은 개인 정보 보호, 암호화, 비즈니스 및 심지어 핵 군축에도 영향을 미치는 기술입니다. Yao의 백만장자 문제 수정 버전으로 이해를 심화하십시오. 이 문제는 두 명의 백만장자 Alice와 Bob에 대해 설명합니다. 이들은 실제 재산을 밝히지 않고 누가 더 부자인지 알고 싶어합니다.
아파트 임대료가 월 $1,000라고 가정하면 임대 후보 자격을 얻으려면 한 달 임대료의 최소 40배를 지불해야 합니다. 그런 다음 우리(임차인)는 연간 소득이 $40,000 이상이어야 함을 증명해야 합니다. 그러나 집주인은 우리가 허점을 찾는 것을 원하지 않았기 때문에 구체적인 임대료를 발표하지 않기로 결정했습니다. 그의 목적은 우리가 기준을 충족하는지 여부를 테스트하는 것이었고 답변은 충족되었는지 여부일 뿐 특정에 대한 책임은 없습니다. 양.
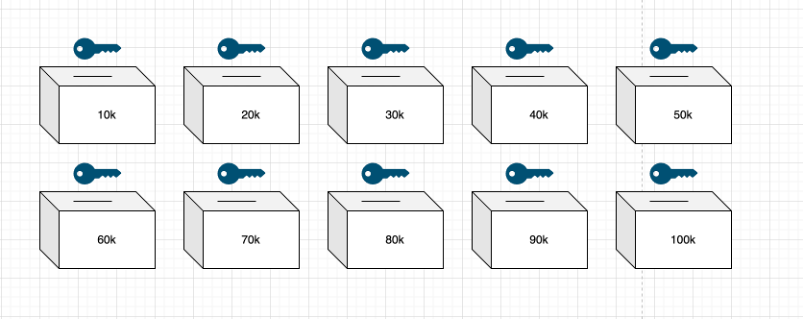
이제 $10,000 단위로 $10-$100,000라고 표시된 상자가 10개 있습니다. 각각에는 키와 슬롯이 있습니다. 집주인은 상자를 들고 방에 들어와 9개의 열쇠를 부수고 $40,000 상자라고 표시된 열쇠를 가져갑니다.
임차인의 연봉은 미화 75,000달러에 달하며, 특정 자금을 명시하지 않고 자산 증명서 발급을 은행 대리인이 감독합니다.이 문서의 본질은 은행의 자산 명세서로 청구 문서를 확인할 수 있다는 것입니다. 그런 다음 해당 파일을 10k에서 70k 범위의 저장소에 놓습니다. 그런 다음 집주인이 40k 키를 사용하여 상자를 열고 내부에 있는 확인 가능한 청구 문서를 보면 세입자가 기준을 충족한다고 판단됩니다.
신고자(은행)는 자산준수증명서를 발급하고, 검증자(집주인)는 키를 통해 임차인의 적격 여부를 확인하는 부분이 포함된다. 검증 결과는 적격과 부적격의 두 가지 옵션만 있으며 임차인에게 자산 금액을 지정하도록 요구하지도 않으며 요구할 수도 없음을 다시 한 번 강조합니다.
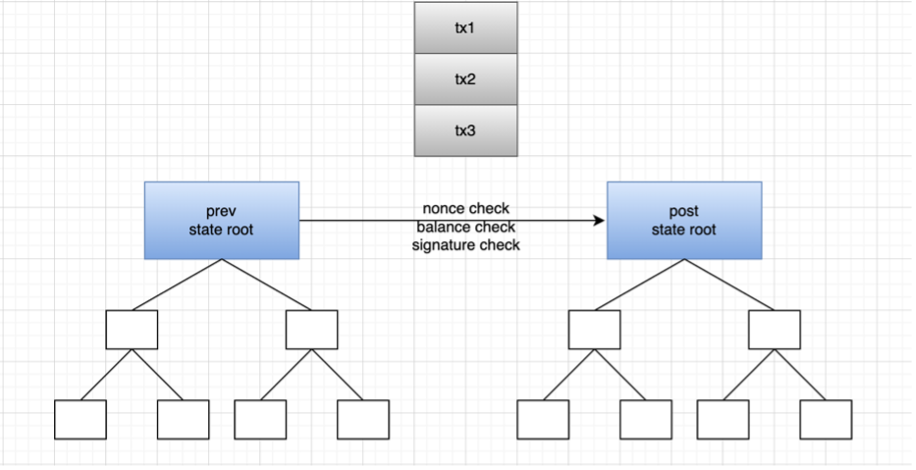
우리는 여전히 다음 그림을 이해로 사용할 수 있으며 트랜잭션은 레이어 2에서 실행되고 트랜잭션은 샤드에서 제출됩니다. 레이어 2는 일반적으로 롤업 형식을 채택합니다. 즉, 여러 트랜잭션이 레이어 2에서 일괄 처리되어 트랜잭션을 처리한 다음 레이어 1의 롤업 스마트 계약에 제출됩니다. 여기에는 이전 상태 루트와 새 상태 루트가 포함됩니다.레이어 1의 계약은 두 상태 루트가 일치하는지 여부를 확인하고 일치하면 메인 체인의 이전 상태 루트가 새 상태 루트로 대체됩니다. 그러면 배치 처리 후 얻은 상태 루트가 올바른지 확인하는 방법 낙관적 롤업과 zk 롤업이 여기에서 파생됩니다. 사기 방지 및 zk 기술을 사용하여 각각 트랜잭션을 확인하고 상태 루트를 확인합니다.
여기서 2계층(롤업)은 위 예시의 신고자(은행)에 해당하며, 그 패키징 작업은 이 신고 작업으로 특정 금액에 대한 진술을 하지 않고 기준에 부합하는지 여부를 확인합니다. 포장되어 레이어 1에 제출되는 것은 이 청구 가능한 선언 문서입니다. 신·구 신분 검증의 근본은 집주인이 열쇠를 이용해 자신이 기대하는 세입자의 경제력이 기준에 부합하는지 검증하는 데 있다. 상태 루트 검증 문제는 은행에서 제출한 명세서로, 진술을 어떻게 하면 문제를 신뢰할 수 있게 만들 수 있는지에 대한 문제입니다.
사기 증거인 낙관적 롤업을 기반으로 메인 체인의 롤업 계약은 롤업의 내부 상태 루트 변경에 대한 전체 기록과 각 배치의 해시 값(상태 루트 변경 트리거)을 기록합니다. 누군가 배치에 해당하는 새로운 상태 루트가 잘못되었음을 발견하면 배치에 의해 생성된 새로운 상태 루트가 잘못되었다는 증거를 메인 체인에 게시할 수 있습니다. 계약서는 그 증명을 검증하고, 검증이 통과되면 일괄 처리 이후의 모든 일괄 처리 트랜잭션이 롤백됩니다.
여기서 검증 방법은 신고자(은행)가 검증 가능한 자산 신고 문서를 제출한 다음 모든 자산 문서를 체인에 게시하고 데이터도 체인에 게시하고 다른 도전자가 원본을 기반으로 계산을 수행하는 것과 같습니다. 자산 문서에 오류나 위조가 있는지 여부를 확인할 수 있는 데이터로 문제가 있으면 도전하고 도전에 성공하면 은행에 청구하십시오. 여기서 가장 중요한 문제는 도전자가 데이터를 수집하고 문서의 진위를 확인할 수 있는 시간을 허용하는 것입니다.
ZKP(Zero Knowledge Proof) 기술을 사용하는 롤업의 경우 각 배치에는 ZK-SNARK라는 암호화 증명이 포함됩니다. 은행은 암호화 증명 기술을 통해 자산 신고 문서를 생성합니다. 이렇게 하면 도전자를 위해 시간을 예약할 필요가 없으므로 도전자의 역할이 존재하지 않습니다.
2. 현재 ZK 시스템 롤업이 예상과 다릅니다.
현재 폴리곤 시리즈의 헤르메즈가 출시되었고 zksync dev 메인넷과 starknet 메인넷도 출시되었습니다. 그러나 그들의 트랜잭션 속도는 우리의 이론과는 거리가 먼 것으로 보이며, 특히 스타크넷 사용자들은 메인넷 속도가 놀라울 정도로 느리다는 것을 분명히 인지할 수 있습니다. 그 이유는 여전히 영지식 증명 기술로 증명을 생성하는 것이 매우 어렵고 비용이 여전히 높으며 이더리움의 호환성과 zkevm의 성능의 균형을 맞출 필요가 있기 때문입니다. Polygon 팀도 다음과 같이 인정합니다.Polygon zkEVM의 테스트넷 버전도 처리량이 제한되어 있어 최적화된 스케일링 머신으로서의 최종 버전과는 거리가 멉니다.”
3. 데이터 가용성 계층
Ethereum의 추상 실행 단계는 다음과 같습니다.
이더리움의 탈중앙화 과정에서 The Merge 로드맵 - 탈중앙 검증자에서도 볼 수 있습니다. 이 중 가장 중요한 것은 고객의 다양성을 실현하고 기계의 진입 문턱을 낮추고 검증자의 수를 늘리는 것입니다. 따라서 기계가 기준에 미달하는 일부 검증자가 네트워크에 참여하고자 할 경우 라이트 클라이언트를 이용할 수 있으며, 라이트 노드의 작동 원리는 인접한 풀 노드를 통해 블록 헤더를 요청하는 것입니다. 블록 헤더를 다운로드하고 확인해야 합니다. 라이트노드가 참여하지 않으면 풀노드가 모든 거래를 검증해야 하므로 풀노드는 블록내의 각 거래를 다운로드하여 검증해야 하며 동시에 거래량이 증가함에 따라 풀노드는 점점 더 큰 압력을 받고 있기 때문에 노드 네트워크는 점차 고성능화되고 중앙 집중화되는 경향이 있습니다.
그러나 여기서 문제는 악의적인 풀노드가 누락/유효하지 않은 블록 헤더를 줄 수 있지만 라이트 노드는 위조할 수 있는 방법이 없다는 것입니다. 블록의 유효성을 모니터링하고 유효하지 않은 블록을 찾은 후 사기 증명을 구성하고 일정 기간 동안 사기 증명을 받지 못하면 유효한 블록 헤더로 판단합니다. 그러나 여기에는 신뢰할 수 있는 전체 노드가 분명히 필요합니다. 즉, 신뢰할 수 있는 설정 또는 정직한 가정이 필요합니다. 그러나 블록 생산자는 일부 트랜잭션을 숨길 수 있으며 정직한 노드도 블록 생산자의 데이터에 의존하기 때문에 사기 증명이 명백히 유효하지 않습니다.데이터 자체가 숨겨져 있으면 신뢰할 수 있는 노드는 제출된 데이터가 모두 데이터, 그러면 당연히 사기 증거가 생성되지 않습니다.
Mustarfa AI-Bassam과 Vitalik은 공동 저술한 논문에서 새로운 솔루션인 삭제 코딩을 제안합니다. 삭제 코드는 데이터 가용성 문제를 해결하기 위해 사용됩니다.예를 들어 셀레스티아 및 폴리곤 Avail은 리드 솔로몬 삭제 코드를 사용합니다. 그러나 전송된 데이터가 KZG 약속/사기 증명과 결합된 완전한 데이터인지 확인하는 방법.
KZG 커밋/사기 증명에서 블록 생산자가 트랜잭션을 숨기지 않고 완전한 데이터를 게시한 다음 삭제 코드를 통해 데이터를 인코딩한 다음 샘플 데이터 가용성을 확인하여 라이트 노드가 데이터를 올바르게 확인할 수 있도록 할 수 있습니다.
Rollup에서 애그리게이터가 제출한 데이터는 calldata 데이터가 다른 저장 영역보다 저렴하기 때문에 calldata 형태로 체인에 저장됩니다.
Calldata cost in gas = Transaction size × 16 gas per byte
각 트랜잭션의 주요 오버헤드는 calldata 비용인데, 이는 체인에 저장하는 비용이 매우 비싸고 이 부분이 롤업 비용의 80~95%를 차지하기 때문입니다.
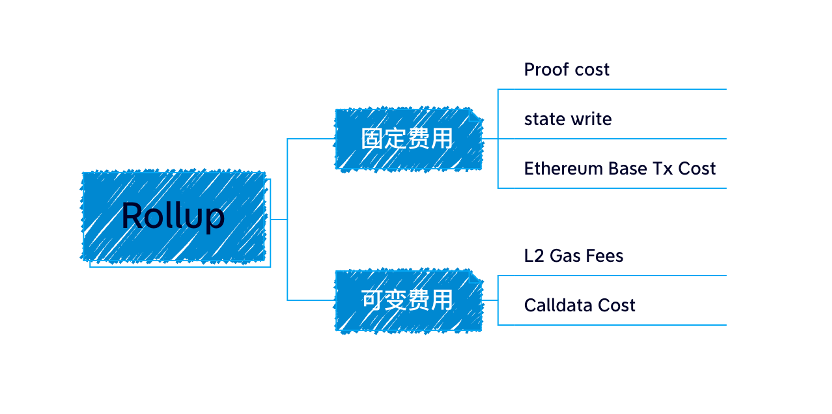
이 문제 때문에 우리는 블록 용량을 확장하고 체인에 제출하는 데 필요한 가스 요금을 줄이는 EIP-4844의 새로운 트랜잭션 형식 Blob을 제안했습니다.
4. 데이터 가용성 레이어의 온체인 및 오프체인
그렇다면 체인의 값비싼 데이터 문제를 해결하는 방법은 무엇입니까? 몇 가지 방법이 있습니다.
첫 번째는 L1에 업로드되는 calldata 데이터의 크기를 압축하는 것으로, 이와 관련하여 많은 최적화가 이루어졌습니다.
두 번째는 체인에 데이터를 저장하는 비용을 줄이고 Ethereum의 proto-danksharding 및 danksharding을 통해 롤업을 위한 "빅 블록"을 제공하고 더 큰 데이터 가용성 공간을 제공하고 삭제 코드 및 KZG 약속을 사용하여 라이트 노드의 문제를 해결하는 것입니다. . EIP-4844와 같은.
세 번째는 데이터 가용성을 체인에서 분리하는 것입니다. 이 부분에 대한 일반적인 솔루션에는 celestia/polygon avail 등이 있습니다.
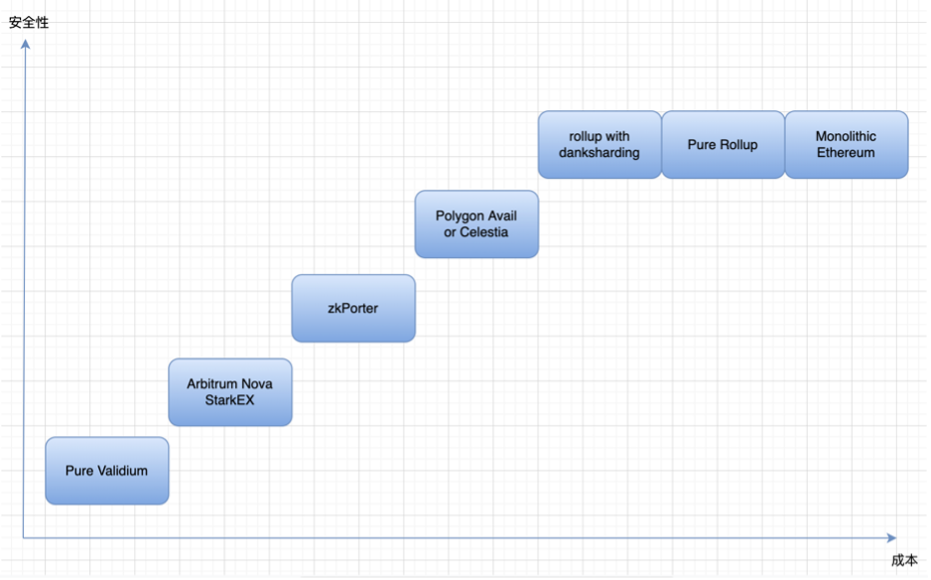
데이터 가용성이 저장되는 위치에 따라 다음 그림으로 나눕니다.
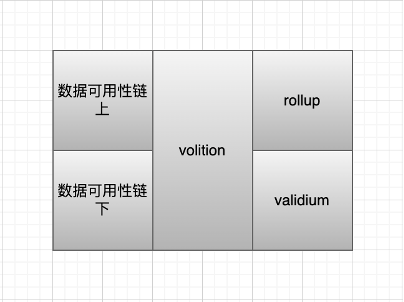
Validium의 솔루션: 데이터 가용성을 오프체인에 넣으면 이러한 트랜잭션 데이터는 중앙 집중식 운영자가 유지 관리하고 사용자는 신뢰할 수 있는 설정이 필요하지만 비용은 매우 낮지만 동시에 거의 보안이 없습니다. 나중에 starkex와 arbitrum nova 모두 트랜잭션 데이터 저장을 담당하도록 DAC를 설정할 것을 제안했습니다. DAC 회원은 법적 관할권 내에서 잘 알려진 개인 또는 조직이며, 그들이 공모하고 악을 행하지 않을 것이라는 신뢰 가정입니다.
Zkporter는 가디언(zksync 토큰 보유자)에게 데이터 가용성 유지 서약을 제안합니다.데이터 가용성 실패가 발생하면 서약된 자금은 몰수됩니다. Volition은 사용자가 온체인/오프체인 데이터 가용성을 선택하고 필요에 따라 보안과 비용 중에서 선택합니다.
이때 셀레스티아와 폴리곤 어베일이 등장했다. Validium이 오프체인 데이터 가용성에 대한 요구 사항을 가지고 있고 탈중앙화 정도가 낮아 크로스체인 브리지와 유사한 개인 키 공격으로 이어질 것을 우려하는 경우 탈중앙화 일반 DA 솔루션이 이 문제를 해결할 수 있습니다. 셀레스티아와 폴리곤 어베일은 별도의 체인이 되어 오프체인 DA 솔루션으로 발리디움을 제공합니다. 그러나 별도의 체인을 통해 보안은 향상되지만 그에 따라 비용이 증가합니다.
Rollup의 확장은 실제로 두 부분으로 나뉩니다. 하나는 aggregator의 실행 속도이고 다른 하나는 데이터 가용성 계층의 협력이 필요합니다.현재 aggregator는 트랜잭션 실행 속도가 도달할 수 있다고 가정하고 중앙 집중식 서버에 의해 실행됩니다. 무한한 정도라면 주요 확장 딜레마는 기본 데이터 가용성 솔루션의 데이터 처리량에 의해 영향을 받는다는 것입니다. 롤업이 트랜잭션 처리량을 최대화하는 것이라면 데이터 가용성 솔루션의 데이터 공간 처리량을 최대화하는 방법이 중요합니다.
처음으로 돌아가서 KZG 약정 또는 사기 증명을 사용하여 데이터 무결성을 보장하고 삭제 코드를 통해 트랜잭션 데이터를 확장하여 라이트 노드가 데이터 가용성을 샘플링하여 라이트 노드가 데이터를 올바르게 확인할 수 있도록 추가로 보장합니다.
또한 데이터의 무결성을 보장하기 위해 KZG 약속이 어떻게 작동하는지 묻고 싶을 수도 있습니다. 약간의 답변이 있을 수 있습니다.
KZG 약속: 특정 위치에서 다항식 값이 지정된 값과 일치함을 증명합니다.
KZG 커미션은 특정 메시지를 주지 않고 메시지를 검증할 수 있는 일종의 다항식 커미션에 지나지 않습니다. 대략적인 프로세스는 다음과 같습니다.
삭제 코딩을 통해 데이터를 다항식으로 변환하고 확장합니다. KZG를 사용하면 확장이 유효하고 원본 데이터가 유효함을 보장합니다. 그런 다음 확장을 사용하여 데이터를 재구성하고 마지막으로 데이터 가용성 샘플링을 수행합니다.
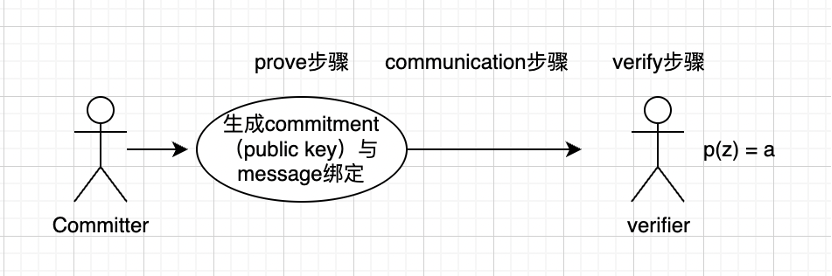
커미터는 커밋을 생성하고 이를 메시지에 바인딩합니다.
바인딩된 메시지를 검증자에게 전송합니다.여기서 통신 방식은 증명 크기의 크기와 관련됩니다.
검증자(verifier), 유한한 필드에 여러 값을 가져와 여전히 a와 같은지 확인(이것이 사용성 샘플링 과정임), 기본 원칙은 검증 횟수가 많을수록 확률이 높아진다는 것 옳은.
Celestia는 유효성 검사기가 전체 블록을 다운로드하도록 요구하며 오늘날의 댄크샤딩은 데이터 가용성 샘플링 기술을 활용합니다.
블록이 부분적으로 사용 가능하므로 언제든지 블록을 재구성할 때 동기화를 보장해야 합니다. 블록이 실제로 부분적으로 사용 가능한 경우 노드는 서로 통신하여 블록을 함께 조각합니다.
KZG 약속과 데이터 사기 증명의 비교:
KZG는 확장 및 데이터의 정확성을 보장할 것을 약속하고 사기 증명은 관찰을 위해 제3자를 도입하는 것을 볼 수 있습니다. 가장 분명한 차이점은 사기 증명은 사기를 보고하기 전에 관찰자에게 응답하는 시간 간격이 필요하며, 이때 전체 네트워크가 적시에 사기 증명을 받을 수 있도록 노드가 직접 동기화되어야 합니다. KZG는 수학적 방법을 사용하여 대기 기간 없이 데이터의 정확성을 보장하는 사기 방지보다 훨씬 빠릅니다.
데이터와 해당 확장을 정당화할 수 있습니다. 그러나 1차원 KZG 약정은 더 많은 자원을 소비해야 하므로 이더리움은 2차원 KZG 약정을 선택합니다.
예를 들어 100행 × 100열, 즉 100,00 공유(공유)입니다. 그러나 모든 샘플링이 만분의 일을 보장하는 것은 아닙니다. 그런 다음 4배 확장은 전체 공유의 최소 1/4을 사용할 수 없음을 의미하며 사용할 수 없는 공유를 그릴 수 있습니다. 즉, 복구할 수 없기 때문에 실제로 사용할 수 없음을 의미합니다. 1/4을 사용할 수 없을 때만 복구할 수 있으며 오류를 찾는 데 정말 효과적이므로 한 번 뽑을 확률은 약 1/4입니다. 10회 이상, 15회 펌핑하면 99%의 신뢰성을 보장할 수 있습니다. 이제 15~20번 범위에서 선택합니다.
5、EIP-4844(Proto-Danksharding)
proto-danksharding 구현에서 모든 검증자와 사용자는 여전히 전체 데이터의 가용성을 직접 확인해야 합니다.
Proto-danksharding에 의해 도입된 주요 기능은 Blob 운반 트랜잭션이라고 하는 새로운 트랜잭션 유형입니다. Blob이 있는 트랜잭션은 Blob이라는 추가 데이터 조각도 전달한다는 점을 제외하면 일반 트랜잭션과 유사합니다. Blob은 매우 크고(~125kB) 비슷한 양의 데이터를 호출하는 것보다 훨씬 저렴합니다. 그러나 이러한 blob은 EVM에서 액세스할 수 없습니다(blob에 대한 약속만 해당). 그리고 Blob은 실행 레이어가 아닌 합의 레이어(비콘 체인)에 의해 저장됩니다. 이것은 실제로 데이터 샤딩 개념의 점진적인 형성의 시작입니다.
유효성 검사기와 클라이언트는 여전히 전체 blob 콘텐츠를 다운로드해야 하므로 proto-danksharding의 데이터 대역폭 목표는 전체 16MB가 아닌 소켓당 1MB입니다. 그러나 이러한 수치는 기존 이더리움 트랜잭션의 가스 사용량과 경쟁하지 않기 때문에 여전히 큰 확장성 이점이 있습니다.
전체 샤딩(데이터 가용성 샘플링 등 사용)을 구현하는 것은 복잡한 작업이었고 프로토 댄크샤딩 후에도 복잡한 작업으로 남아 있지만 이러한 복잡성은 합의 계층에 포함됩니다. proto-danksharding이 출시되면 전체 샤딩으로의 전환을 완료하기 위해 경영진 계층 클라이언트 팀, 롤업 개발자 및 사용자의 추가 작업이 필요하지 않습니다. Proto-danksharding은 또한 blob 데이터를 calldata에서 분리하여 클라이언트가 더 짧은 시간에 blob 데이터를 더 쉽게 저장할 수 있도록 합니다.
클라이언트 팀, 사용자 또는 롤업 개발자가 추가 작업을 수행하지 않고 모든 작업이 합의 계층에서 수행된다는 점은 주목할 가치가 있습니다.
EIP-4488과 proto-danksharding 모두 소켓당 약 1MB(12초)의 장기 최대 사용량으로 이어집니다. 이는 연간 약 2.5TB에 해당하며 오늘날 이더리움이 필요로 하는 성장률보다 훨씬 높습니다.
EIP-4488의 경우 이를 수정하려면 기록 만료 제안이 필요합니다.EIP-4444(로드맵 섹션에서 언급됨) 클라이언트는 더 이상 특정 기간이 지난 기록을 저장할 필요가 없습니다.
6. 데이터 조각화
여기서는 이더리움 확장 과정에서 모두가 논의하고 있는 이슈들을 Xiaobai의 관점에서 최대한 설명하겠습니다. 다시 샤딩으로 돌아가서 샤딩의 일방적 개념을 다시 한 번 강조해 보겠습니다. 간단한 이해는 데이터베이스를 수평으로 분할하여 부하를 분산시키는 과정입니다.
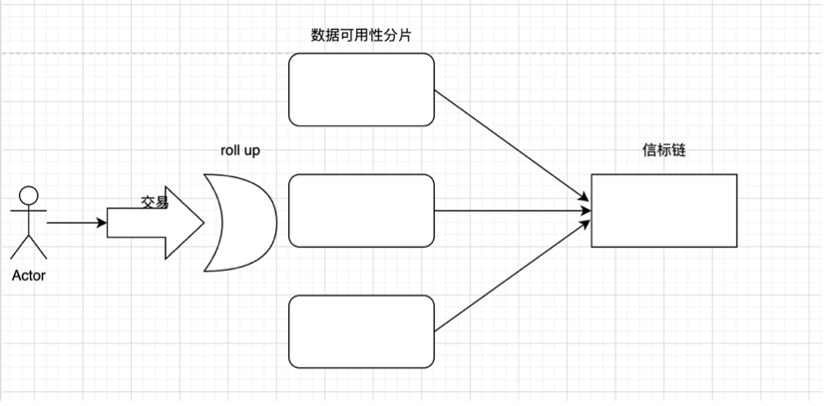
여기서 데이터 샤딩의 매우 중요한 문제는 PBS(로드맵 The Merge에서 언급한 것처럼 제안자는 블록 빌더와 분리됨)에서 샤딩에서 각 노드 그룹은 이 샤드의 트랜잭션이 상대적으로 독립적일 것이라는 점입니다. 그렇다면 AB와 AB의 두 사용자는 어떻게 서로 다른 샤드에 있고 서로에게 자금을 이체해야 할까요? 그렇다면 우수한 칩 간 통신 기능이 필요합니다.
예전 방식은 각각 독립적인 제안자와 위원회가 있는 데이터 가용성 계층을 샤딩하는 것이었습니다. 검증자 집합에서 각 검증자는 교대로 조각의 데이터를 검증하고 검증을 위해 모든 데이터를 다운로드합니다.
약점은:
유효성 검사기가 슬롯 내에서 동기화될 수 있도록 하려면 엄격한 동기화 기술이 필요합니다.
유효성 검사기는 모든 위원회 투표를 수집해야 하며 여기에서 지연이 발생합니다.
그리고 검증자는 데이터를 완전히 다운로드해야 한다는 큰 압박을 받고 있습니다.
두 번째 접근 방식은 전체 데이터 검증을 포기하고 대신 데이터 가용성 샘플링(나중에 The Surge에서 구현됨)을 사용하는 것입니다. 여기에는 두 가지 무작위 샘플링 방법이 있습니다. 1) 블록 무작위 샘플링, 데이터 조각의 일부 샘플링, 확인이 통과되면 검증자가 서명합니다. 하지만 여기서 문제는 트랜잭션이 누락되는 경우가 있을 수 있다는 것입니다. 2) 삭제 코드를 통해 데이터를 다항식으로 재해석한 후 특정 조건에서 데이터를 복원할 수 있는 다항식의 특성을 사용하여 데이터의 완전한 가용성을 보장합니다.
"분열"요점은 유효성 검사기가 모든 데이터를 다운로드할 책임이 없다는 것입니다. 이것이 Proto-danksharding이"조각난"(그 이름에도 불구하고"샤드 샤딩"첫 번째 레벨 제목
3. 이더리움의 미래 레이어 3
zksync, starknet 등 이더리움의 미래 확장으로 여겨지는 ZK 시리즈의 Layer 2는 모두 Layer 3의 개념을 제안했습니다. 간단한 이해는 레이어 2의 레이어 2입니다.
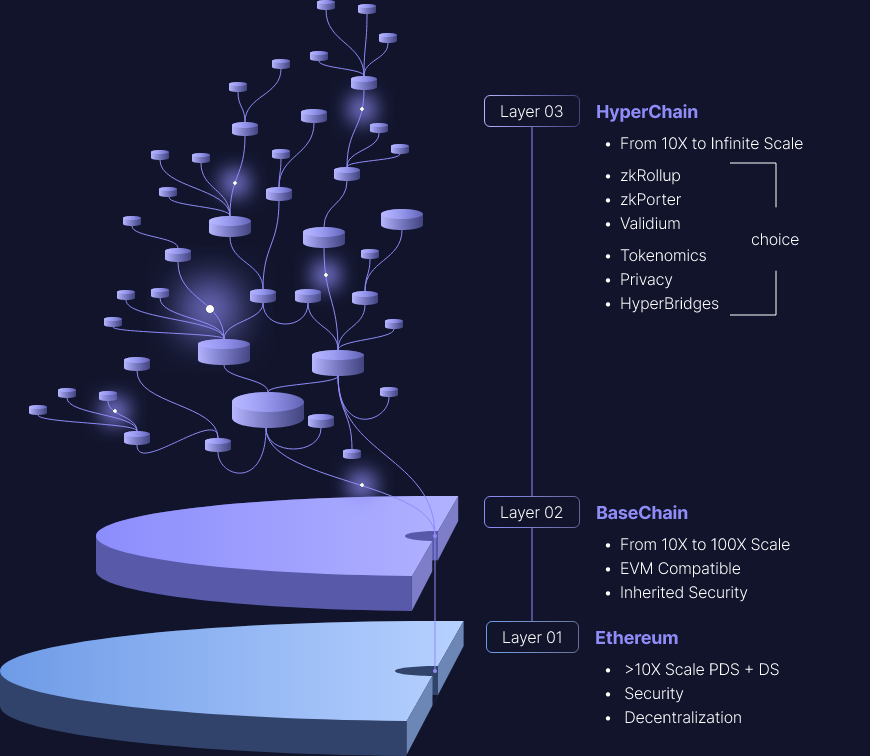
이더리움의 높은 거래 비용은 L2의 결제 계층이 되도록 L3를 밀어내고 있습니다. 가까운 장래에 거래 비용의 상당한 감소, DeFi 도구에 대한 지원 증가 및 L2가 제공하는 유동성 증가로 인해 최종 사용자는 대부분의 활동을 L2에서 수행할 것이며 이더리움은 점차 정착층.
L2는 트랜잭션당 가스 비용을 줄이고 트랜잭션 속도를 높여 확장성을 향상시킵니다. 동시에 L2는 분산화, 일반 논리 및 구성 가능성의 이점을 유지합니다. 그러나 특정 애플리케이션에는 특정 사용자 정의가 필요하며 이는 새로운 독립 계층인 L3에서 더 잘 제공될 수 있습니다!
L3은 L2와 관련이 있고 L2는 L1과 관련이 있습니다. L2가 검증자(Verifier) 스마트 계약을 지원할 수 있는 한 L3는 유효성 증명을 사용하여 달성할 수 있습니다. L2도 L1에 제출된 유효성 증명을 사용하는 경우 StarkNet에서와 같이 L2 증명의 압축 이점에 L3 증명의 압축 이점이 곱해지는 매우 우아한 재귀 구조가 됩니다. 이론적으로 각 계층이 예를 들어 1000배의 비용 절감을 달성한다면 L3는 L1보다 1,000,000배 낮을 수 있습니다. 그러면서도 L1의 보안을 계속 유지합니다. 이것은 또한 starknet이 자랑스러워하는 재귀 증명의 실제 사용 사례입니다.
여기에서 "데이터 가용성 계층의 온체인 및 오프체인" 지식의 일부가 필요합니다. 전체 레이어 3에는 다음이 포함됩니다.
롤업(온체인 데이터 가용성), validium(오프체인 데이터 가용성). 이 둘은 서로 다른 애플리케이션 요구 사항에 해당합니다. 가격과 데이터에 민감한 Web2 회사는 Validium을 사용하여 데이터를 오프체인에 넣을 수 있으므로 체인의 가스 비용이 크게 절감되고 개인 정보 보호를 위해 사용자 데이터를 공개할 수 없으므로 회사가 데이터에 대한 자체 제어를 완료할 수 있습니다. 맞춤형 데이터 형식, 이전 기업의 데이터 비즈니스 모델은 여전히 원활하게 실행될 수 있습니다.
L2는 확장 기능용이고 L3는 개인 정보 보호와 같은 사용자 지정 기능용입니다.
이 비전에서는 "2차 확장성"을 제공하려는 시도가 없으며, 대신 이 스택에는 애플리케이션 확장을 돕는 계층이 있으며, 다양한 사용 사례의 사용자 정의된 기능 요구 사항에 따라 계층이 분리됩니다.
L2는 일반 확장용이고 L3은 사용자 지정 확장용입니다.
사용자 지정 확장은 다양한 형태로 제공될 수 있습니다. 계산을 위해 EVM 이외의 것을 사용하는 특수 응용 프로그램, 특정 응용 프로그램의 데이터 형식에 대해 데이터 압축이 최적화된 롤업("데이터"를 "증명"에서 분리하고 증명을 블록당 단일 SNARK) 등
L2는 무신뢰 확장(롤업)에 사용되고 L3는 약한 신뢰 확장(validium)에 사용됩니다.
Validium은 SNARK를 사용하여 계산을 확인하지만 데이터 가용성을 신뢰할 수 있는 제3자 또는 위원회에 맡기는 시스템입니다. 내 생각에 Validium은 크게 과소평가되었습니다. 특히 많은 "엔터프라이즈 블록체인" 애플리케이션은 실제로 validium 증명기를 실행하고 주기적으로 해시를 체인에 제출하는 중앙 집중식 서버에서 가장 잘 제공될 수 있습니다. Validium은 롤업보다 덜 안전하지만 훨씬 저렴할 수 있습니다.
dApp 개발자에게는 인프라에 대한 몇 가지 옵션이 있습니다.
직접 롤업 개발(ZK 롤업 또는 낙관적 롤업)
이더리움의 생태계(사용자)와 그 보안성을 물려받을 수 있다는 장점이 있지만, dApp 팀 입장에서는 롤업의 개발 비용이 너무 높다.
Cosmos, Polkadot 또는 Avalanche 선택
개발 비용은 낮아지지만(예: dydx는 Cosmos를 선택함) 이더리움의 생태(사용자)와 보안을 잃게 됩니다.
스스로 Layer 1 블록체인 개발
개발 비용과 그에 따른 어려움은 높지만 가장 높은 통제력을 가질 수 있습니다.
세 가지 경우를 비교해 보겠습니다.
난이도/비용: 대체 레이어 1 > 롤업 > 코스모스
보안: 롤업 > 코스모스 > Alt 레이어 1
생태/사용자: 롤업 > 코스모스 > 대체 레이어 1
컨트롤: Alt 레이어 1 > 코스모스 > 롤업
첫 번째 레벨 제목
4. 레이어 2의 향후 개발
이더리움은 계정 모델을 기반으로 설계되었기 때문에 모든 사용자가 전체 상태 트리에 있으므로 병렬 처리가 불가능하므로 이더리움 자체의 족쇄는 실행 작업을 제거하고 여러 롤업 트랜잭션을 하나의 트랜잭션으로 결합해야 합니다. 정착층. 이제 모든 문제는 레이어 2의 처리량을 개선하는 데 집중되어 있습니다. 계층 3은 트랜잭션 처리량을 향상시킬 수 있을 뿐만 아니라 계층 2의 병렬 처리도 전체 네트워크의 처리량을 크게 증가시킬 수 있습니다.
스타크넷도 병렬화 문제에 대해 적극적으로 탐구하고 있는데, 알고리즘이 여전히 걸림돌이라는 것이 증명되었지만 앞으로 저항이 될 것 같지는 않다. 잠재적인 병목 현상은 다음과 같습니다.
분류기 tx는 다음을 처리합니다.일부 분류기 작업은 본질적으로 직렬인 것처럼 보입니다.
대역폭:여러 시퀀서 간의 상호 연결이 제한됩니다.
L2 상태 크기
스타크넷 커뮤니티에서 회원들도 제기Aptos의 병렬 처리첫 번째 레벨 제목
V. 요약
이더리움은 "글로벌" 정산 계층이라는 비전의 방향으로 실행 계층을 제거하고 있습니다. 현재 전체 이더리움의 진행이 느리지만 전체 규모가 너무 크고 각 업데이트에는 많은 이해관계와 트레이드오프가 포함되어 있기 때문입니다. 그러나 이더리움이 큰 변화를 겪고 있다는 것은 부인할 수 없으며, 이더리움 체인에 대한 많은 활동, 경제 메커니즘의 개선, 이더리움 2.0의 확장성이 기대됩니다. 점점 더 많은 국가에서 다음과 같은 Ethereum 노드를 배포함에 따라아르헨티나 수도 정부, 2023년에 이더리움 유효성 검사기 노드 배포 계획원본 링크


