
연합 학습 프레임워크 분석
【머리말】
▲ 연합학습 문제 검토 앞서 언급한 바와 같이, 구글은 2016년에 "연합학습"이라는 입력 방식 모델을 훈련시키는 새로운 방법을 제안했다. 시간이 지남에 따라 연합 학습은 더 이상 Google 입력 방식 모델에 대한 단순한 솔루션이 아니며 새로운 학습 모델이 형성되었습니다. 연합 학습에 의해 해결되는 문제는 일반적으로 TMMPP(프라이버시가 있는 여러 데이터 소스에 대한 기계 학습 모델 학습)라고 합니다. 연합 학습으로 해결되는 TMMPP 문제에는 n개의 데이터 큐브(Data Controller) {D1, D2,...Dn}가 포함되며, 각 데이터 큐브는 n개의 데이터{P1, P2,...Pn}에 해당합니다. 연합 학습의 훈련 모드 관점에서 훈련이 필요한 연합 학습 알고리즘을 선택한 후 연합 학습에 해당 입력을 제공하고 훈련 후 최종적으로 출력을 얻을 필요가 있습니다.
연합 학습의 입력(Input): 각 데이터 당사자는 Pi가 소유한 원본 데이터 Di를 공동 모델링의 입력으로 사용하여 연합 학습 과정에 입력합니다.
연합 학습의 출력(Output): 모든 참가자의 데이터를 결합하고 글로벌 모델 M을 연합하여 훈련합니다(훈련 과정에서 데이터 당사자의 원본 데이터에 대한 정보는 다른 엔터티에 공개되지 않음).
▲ 연합 학습에서 직면한 과제
연합 학습 기술은 여전히 지속적으로 개선되고 있습니다. 개발 과정에서 연합 학습은 통계적 문제, 효율성 문제 및 보안 문제라는 세 가지 주요 문제에 직면하게 됩니다.
[통계적 과제] 통계적 과제는 연합 학습을 수행하는 동안 사용자마다 데이터의 분포나 양의 차이로 인해 발생하는 과제입니다.
a) 비독립적이고 동일하게 분포된 데이터(Non-IID 데이터), 즉 서로 다른 사용자의 데이터 분포가 독립적이지 않고 분포 차이가 분명합니다.예를 들어 A측은 중국 북부에 모내기 데이터가 있고 당사자 B는 중국 남부에 모내기 데이터를 가지고 있습니다. 위도, 기후, 인문학 등의 영향으로 인해 양 당사자의 데이터는 동일한 분포를 따르지 않습니다.
b) 언밸런스 데이터(Unbalanced data), 즉 사용자의 데이터 양에 분명한 차이가 있는 경우 예를 들어 거대 기업은 수천만 개에 가까운 데이터를 보유하고 있는 반면, 소규모 기업은 수만 개에 불과한 데이터를 보유하고 있다. 데이터가 거대 기업에 미치는 영향은 미미하고 모델 교육에 기여하기 어렵습니다.
[효율성 챌린지] 효율성 챌린지는 연합 학습에서 각 노드의 로컬 컴퓨팅 및 통신 소비로 인해 발생하는 문제를 말합니다.
a) 통신 오버헤드, 즉 사용자(참가자) 노드 간의 통신은 일반적으로 제한된 대역폭을 전제로 각 사용자 간에 전송되는 데이터 양을 말하며 데이터 양이 많을수록 통신 손실이 커집니다.
b) 계산 복잡도, 즉 기본 암호화 프로토콜을 기반으로 한 계산 복잡도는 일반적으로 기본 암호화 프로토콜 계산의 시간 복잡도를 말하며 알고리즘의 계산 논리가 복잡할수록 더 많은 시간이 걸립니다.
[보안 문제] 보안 문제는 연합 학습 과정에서 서로 다른 사용자가 서로 다른 공격 방법을 사용하여 발생하는 정보 크래킹 및 중독과 같은 문제를 말합니다.
a) 준정직 모델, 즉 각 사용자는 연합 학습에서 모든 프로토콜을 정직하게 구현하지만 획득한 정보를 사용하여 다른 사람의 데이터를 분석하고 푸시백합니다.
b) 악의적인 모델, 즉 노드 간의 합의를 엄격히 준수하지 않고 원본 데이터 또는 중간 데이터를 독살하여 연합 학습 프로세스를 파괴할 수 있는 클라이언트가 있습니다.
[연합 학습을 위한 공통 프레임워크]
위의 세 가지 과제에 직면하여 학계는 표적 연구를 수행하고 연합 학습 교육 프로세스를 최적화하기 위해 많은 효과적이고 전용 연합 학습 프레임워크를 제안했습니다. 아래에서 이러한 프레임워크를 간략하게 소개합니다.
제휴 학습 1.0 - 전통적인 제휴 학습
먼저 연합학습의 개념과 원리를 다시 설명하자면, 연합학습 작업을 공동으로 수행하기 위해 여러 참여자와 협력자가 있고, 참여자(즉, 데이터 소유자)는 미리 설정된 연합학습 알고리즘을 통해 기울기와 유사한 중간 데이터를 생성한다. , 추가 처리를 위해 코디네이터에게 전달한 다음 각 참가자에게 반환하여 다음 교육을 준비합니다.
반복적으로 연합 학습 작업이 완료됩니다. 작업 전반에 걸쳐 참가자의 로컬 데이터는 각 FL 프레임워크에서 교환되지 않지만 코디네이터와 참가자 간에 전송되는 매개 변수(예: 그래디언트)는 민감한 정보를 유출할 수 있습니다.
데이터 소유자의 로컬 데이터가 유출되지 않도록 보호하고 훈련 중에 중간 데이터의 개인 정보를 보호하기 위해 참가자가 코디네이터와 상호 작용할 때 매개 변수를 개인적으로 교환하기 위해 FL 프레임워크에 일부 개인 정보 보호 기술이 적용됩니다. 또한 FL 프레임워크에서 사용되는 개인 정보 보호 메커니즘의 관점에서 FL 프레임워크는 다음과 같이 나뉩니다.
1) 암호화되지 않은 연합 학습 프레임워크(즉, 정보가 암호화되지 않음)
2) 차등 프라이버시에 기반한 연합 학습 프레임워크(정보를 혼동하고 암호화하기 위해 차등 프라이버시 사용)
3) 안전한 다자간 컴퓨팅을 기반으로 하는 연합 학습 프레임워크(보안 다자간 컴퓨팅을 사용하여 정보를 암호화)
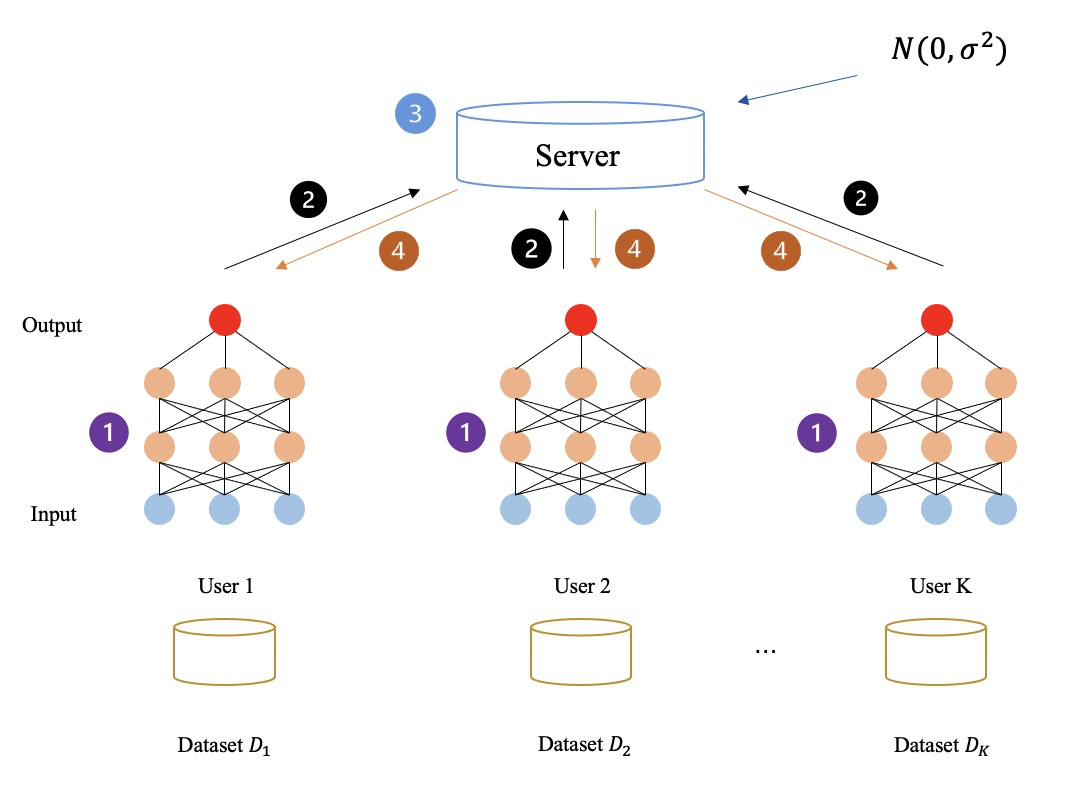
▲ 비암호화 연합 학습 프레임워크
많은 FL 프레임워크는 효율성을 개선하거나 통계적 이질성 문제를 해결하는 데 초점을 맞추는 반면 평문 매개변수 교환으로 인한 잠재적 위험을 무시합니다.
2015년 Nishio 등이 제안한 머신러닝용 모바일 에지 컴퓨팅 프레임워크인 FedCS[3]는 이기종 데이터 소유자 설정을 기반으로 빠르고 효율적으로 FL을 실행할 수 있다.
2017년 Smith 등은 FL과 다중 작업 학습을 결합하고 통계적 문제를 처리하기 위해 다중 작업 학습을 사용하는 MOCHA[2]라는 시스템 인식 최적화 프레임워크를 제안했습니다. 데이터 양의 차이로 인해.
같은 해에 Liang 등은 로컬 표현 학습과 결합된 LG-FEDAVG[4]를 제안했습니다. 로컬 모델이 이기종 데이터를 더 잘 처리하고 공정한 표현을 효율적으로 학습하여 보호된 속성을 난독화할 수 있음을 보여줍니다.
아래 그림과 같이 연합 학습 프로세스는 중간 데이터를 전혀 암호화하지 않으며 모든 중간 데이터(예: 그래디언트)는 일반 텍스트로 전송 및 계산됩니다. 위의 방법을 통해 참가자들은 최종적으로 연합 학습 모델을 얻기 위해 함께 학습합니다.
▲ 차등 프라이버시 기반 연합 학습 프레임워크
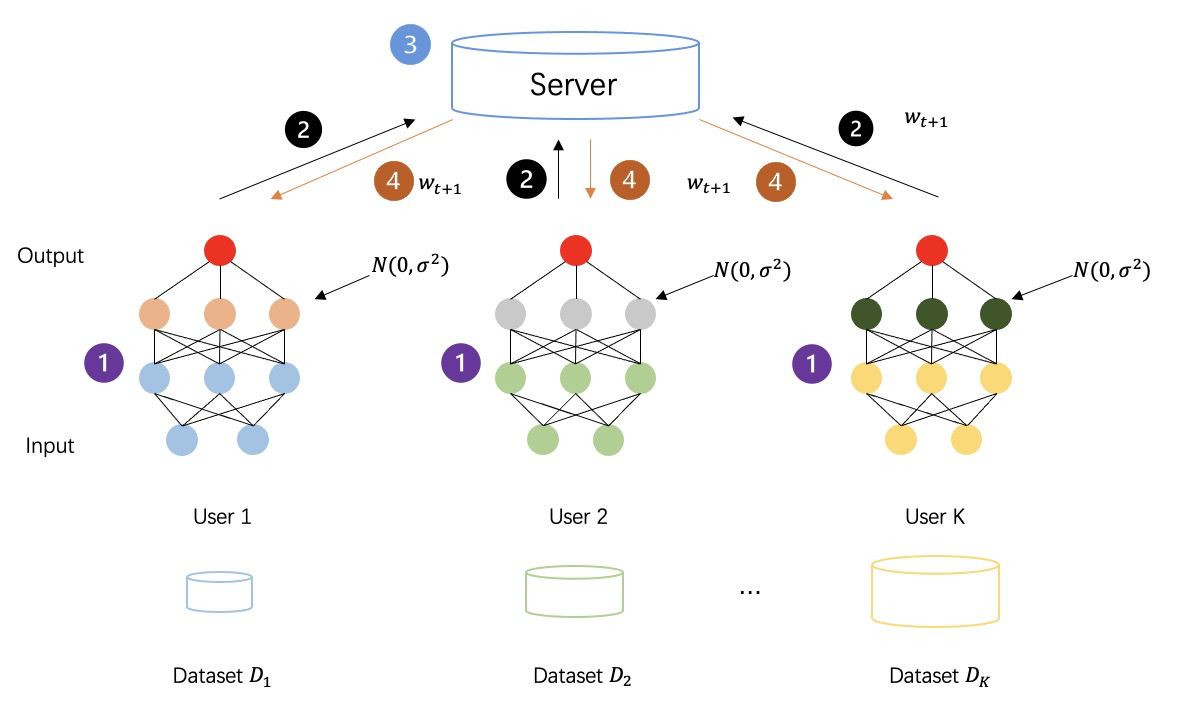
DP(차등 프라이버시)는 데이터에 노이즈를 추가하기 위한 강력한 정보 이론적 보장이 있는 프라이버시 기술[5-7]입니다[8-10]. DP를 만족하는 데이터 세트는 개인 데이터의 분석에 내성이 있습니다. 즉, 획득한 데이터 공격자는 동일한 데이터 세트에서 다른 데이터를 추론하는 데 거의 쓸모가 없습니다. 원시 데이터 또는 모델 매개변수에 무작위 노이즈를 추가함으로써 DP는 개별 레코드에 대한 통계적 개인 정보 보호를 보장하여 데이터 소유자의 개인 정보를 보호하기 위해 데이터를 검색할 수 없도록 만듭니다.
아래 그림과 같이 중간 데이터를 암호화하기 위해 차등 프라이버시를 채택한 후 연합 학습 프로세스, 모든 당사자가 생성한 중간 데이터는 더 이상 일반 텍스트 전송 계산이 아니라 노이즈가 추가된 프라이버시 데이터이므로 보안을 더욱 강화합니다. 훈련 과정 섹스의.
▲ 안전한 다자간 컴퓨팅 기반 연합 학습 프레임워크
FL 프레임워크에서는 HE(Homomorphic Encryption), MPC(Secure Multi-party Computation) 등의 방법이 널리 사용되었으나 참여자와 코디네이터에게만 계산 결과를 공개할 뿐, 계산 이외의 정보는 공개하지 않는다. 프로세스 중 결과 추가 정보.
실제로 HE는 보안 다자간 학습(MPL) 프레임워크(FL에서 파생된 프레임워크, MPL 프레임워크는 아래에서 자세히 설명함)에 적용되는 것과 유사한 방식으로 FL 프레임워크에 적용되지만 약간 다릅니다. 세부. FL 프레임워크에서 HE는 MPL 프레임워크에 적용된 HE와 같이 참여자 간의 데이터 상호 작용을 직접 보호하는 대신 참여자와 코디네이터 간에 상호 작용하는 모델 매개변수(예: 그래디언트)의 프라이버시를 보호하는 데 사용됩니다. [1] FL 모델에 AHE(Additive Homomorphism)를 적용하여 기울기의 프라이버시를 보존하여 반무결성 중앙 집중식 코디네이터에 대한 보안을 제공합니다.
MPC는 많은 측면을 포함하며 높은 보안 보장과 함께 원래 정확도를 유지합니다. MPC는 각 당사자가 결과만 알도록 보장합니다. 따라서 로컬 모델의 안전한 집계 및 보호를 위해 MPC를 FL 모델에 적용할 수 있습니다. MPC 기반 FL 프레임워크에서 중앙 집중식 코디네이터는 로컬 정보 및 로컬 업데이트를 얻을 수 없지만 각 협업 라운드에서 집계된 결과를 얻습니다. 그러나 MPC 기법을 FL 프레임워크에 적용할 경우 추가적인 통신 및 연산 비용이 많이 발생하게 된다.
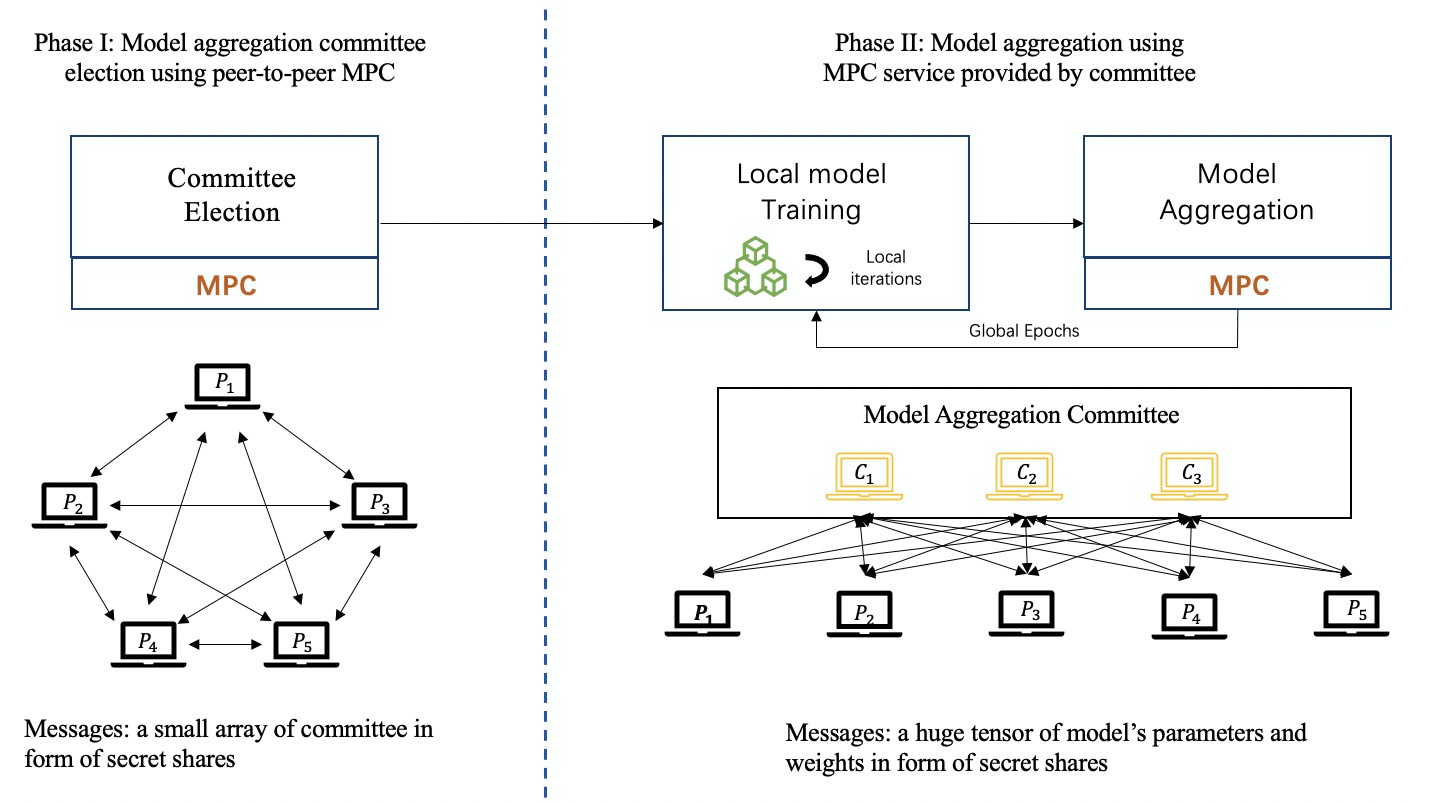
지금까지 비밀 공유(SS)는 FL 프레임워크, 특히 Shamir의 SS[24]에서 가장 널리 사용되는 MPC 기반 프로토콜입니다.
아래 그림과 같이 MPC 기반의 연합 학습 교육 과정에서 위원회 구성원 그룹은 참가자들에 의해 공정하게 코디네이터로 선출되고 MPC 기술은 모델 집계 작업을 완료하기 위해 협력하도록 구현됩니다.
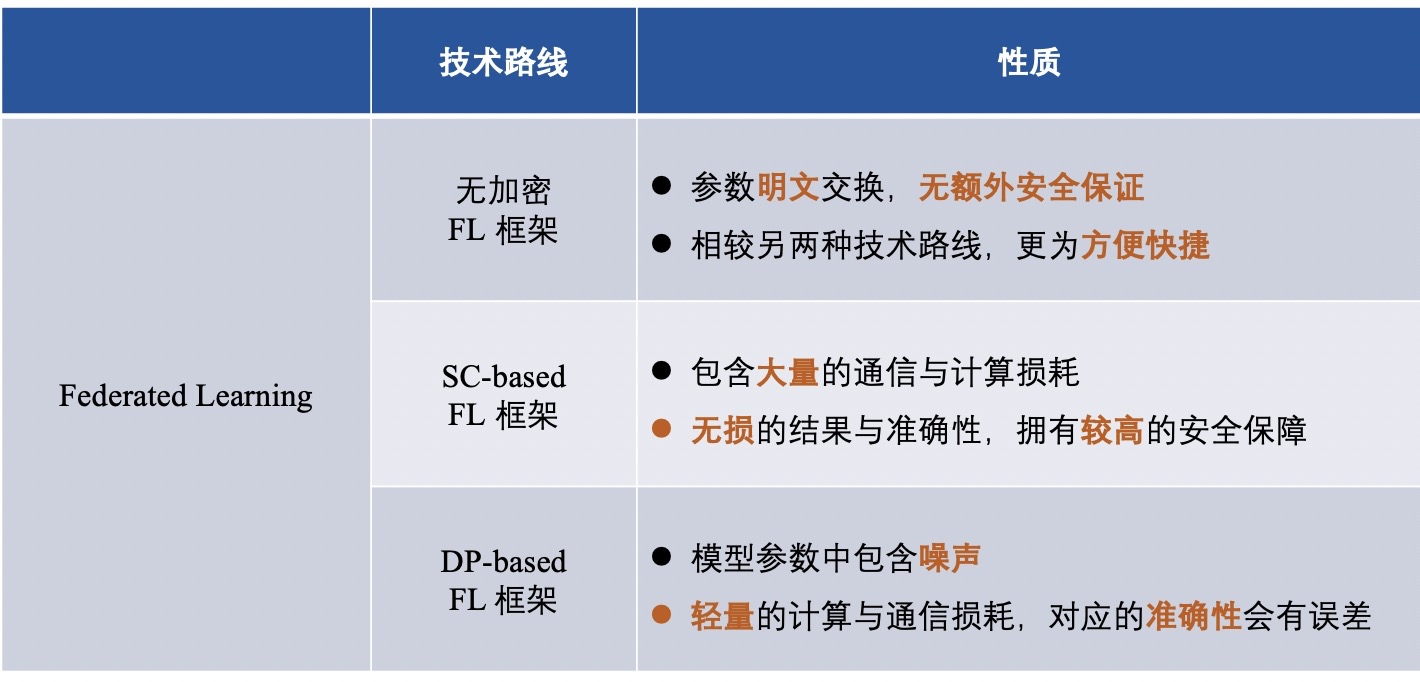
세 가지 FL 프레임워크를 소개한 후 다양한 기술 경로의 프레임워크 차이점을 다음과 같이 요약합니다.
제휴 학습 2.0 -- 안전한 다자간 학습
연합 학습에서 파생된 용어인 "안전한 다자간 학습" 위에서 언급했습니다. 간단히 말해서 제3자 협력자가 없는 연합 학습을 안전한 다자간 학습(MPL)이라고 합니다. FL 구분이 도입되었습니다. 즉, 연합학습을 기반으로 안전한 다자간 학습은 기존의 연합학습 모델에서 코디네이터를 없애고 코디네이터의 능력을 약화시키며 원래의 스타 네트워크를 P2P 네트워크로 대체하고 모든 참여자를 동일한 상태를 갖습니다.
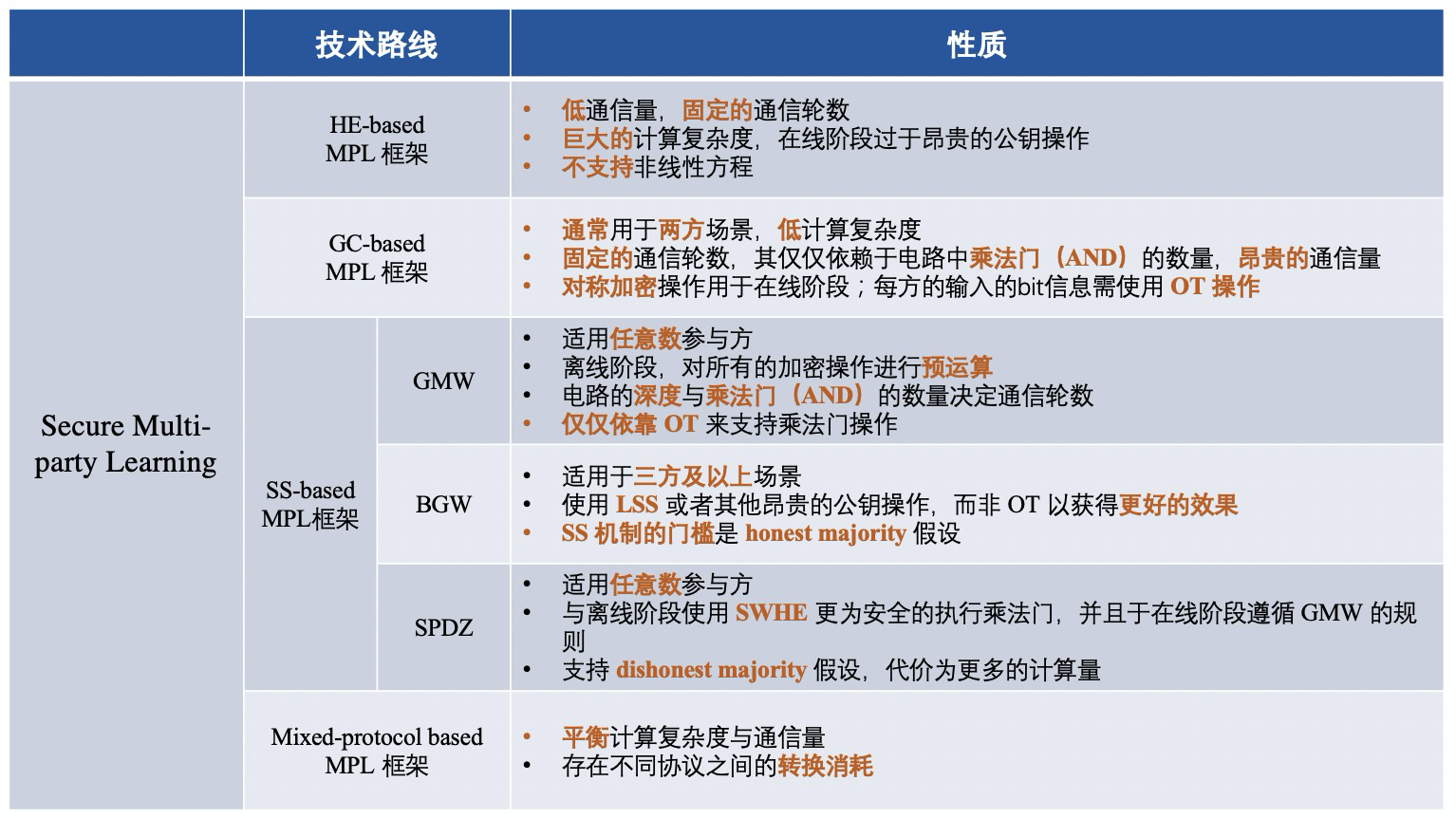
MPL의 프레임워크는 대략 다음과 같은 네 가지 범주로 나뉩니다.
1) 동형암호(HE)에 기반한 MPL 프레임워크;
2) Confused Circuit(GC)에 기반한 MPL 프레임워크;
3) 비밀 공유(SS) 기반의 MPL 프레임워크;
4) 하이브리드 프로토콜에 기반한 MPL 프레임워크;
간단히 말해서 서로 다른 MPL 프레임워크는 중간 데이터의 보안을 보장하기 위해 서로 다른 암호화 프로토콜을 사용하는 프레임워크입니다. MPL의 프로세스는 FL의 프로세스와 대략 비슷합니다. 사용된 네 가지 암호화 프로토콜을 살펴보겠습니다.
▲ 동형암호(HE)
HE(Homomorphic Encryption)는 키를 해독하거나 알지 않고도 암호문에서 특정 대수 연산을 직접 수행할 수 있는 암호화 형식입니다. 그런 다음 암호 해독된 결과가 일반 텍스트에서 수행된 동일한 작업의 결과와 정확히 동일한 암호화된 결과를 생성합니다.
HE는 "3가지 유형"으로 나눌 수 있습니다: 1) 부분 동형 암호화(PHE), PHE는 무제한 연산(더하기 또는 곱하기)만 허용합니다. ), 암호문에서 SWHE 및 FHE를 동시에 더하고 곱하기 위한 것입니다. SWHE는 제한된 횟수로 특정 유형의 작업을 수행할 수 있는 반면 FHE는 모든 작업을 무제한으로 처리할 수 있습니다. FHE의 계산 복잡성은 SWHE 및 PHE보다 훨씬 더 비쌉니다.
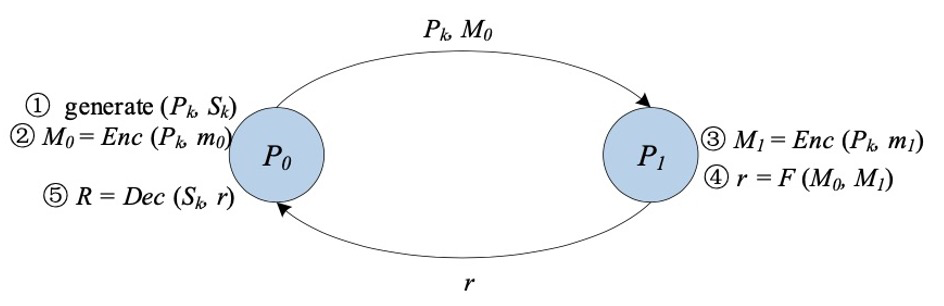
▲ 혼란회로(GC)
Yao의 혼동 회로라고도 하는 Confusion circuit[11][12](GC)은 학자 Yao Qizhi가 제안한 안전한 양 당사자 컴퓨팅 기본 기술입니다. GC는 두 당사자(가블러와 평가자)가 일반적으로 부울 회로로 표시되는 임의의 함수를 아무 생각 없이 평가할 수 있는 대화형 프로토콜을 제공합니다.
클래식 GC의 구성에는 주로 암호화, 전송 및 평가의 세 단계가 포함됩니다.
먼저, 회로의 각 와이어에 대해 obfuscator는 두 개의 임의 문자열을 레이블로 생성하여 해당 와이어에 대해 각각 가능한 두 비트 값 "0" 및 "1"을 나타냅니다. 회로의 각 게이트에 대해 obfuscator는 진리표를 생성합니다. 진리표의 각 출력은 입력에 해당하는 두 개의 레이블로 암호화됩니다. 이 두 레이블을 사용하여 대칭 키를 생성하는 키 유도 함수를 선택하는 것은 난독화기에 달려 있습니다.
그런 다음 obfuscator는 진리표의 행을 래핑합니다. 난독화 단계가 끝난 후 난독화기는 난독화된 테이블과 해당 입력에 해당하는 입력 라인 레이블을 평가자에게 전달합니다.
또한 평가자는 무지 전송(Oblivious Transfer [13, 14, 15])을 통해 입력에 해당하는 레이블을 안전하게 얻습니다. 난독화 테이블과 입력 라인의 레이블을 사용하여 평가자는 함수의 최종 결과를 얻을 때까지 난독화 테이블을 반복적으로 해독해야 합니다.
▲ 시크릿쉐어링(SS)
GMW 프로토콜은 여러 당사자가 부울 회로 또는 산술 회로로 표현할 수 있는 함수를 안전하게 계산할 수 있는 최초의 안전한 다자간 계산 프로토콜입니다. 부울 회로를 예로 들면 모든 당사자는 XOR 기반 SS 체계를 사용하여 입력을 공유하고 당사자는 게이트별로 결과를 계산하기 위해 상호 작용합니다. GMW 기반의 프로토콜은 진리표를 혼동할 필요가 없고 계산을 위해 XOR 및 AND 연산만 수행하면 되므로 대칭적 암호화 및 복호화 작업을 수행할 필요가 없습니다. 또한 GMW 기반 프로토콜은 모든 암호화 작업의 사전 계산을 허용하지만 온라인 단계에서 여러 당사자 간의 여러 라운드의 상호 작용이 필요합니다. 따라서 GMW는 대기 시간이 짧은 네트워크에서 우수한 성능을 달성합니다.
BGW 프로토콜은 당사자가 세 명 이상인 산술 회로를 위한 안전한 다자 컴퓨팅 프로토콜입니다. 계약의 전체 구조는 GMW와 유사합니다. 일반적으로 BGW는 모든 산술 회로를 계산하는 데 사용할 수 있습니다. GMW 프로토콜과 유사하게 회로의 덧셈 게이트의 경우 로컬에서 계산을 수행할 수 있는 반면 곱셈 게이트의 경우 모든 당사자가 상호 작용해야 합니다. 그러나 GMW와 BGW는 상호 작용의 형태가 다릅니다. 당사자 간의 통신에 OT를 사용하는 대신 BGW는 곱셈을 지원하기 위해 선형 SS(예: Shamir의 SS)에 의존합니다. 그러나 BGW는 정직한 다수결에 의존합니다. BGW 프로토콜은 t의 제거에 맞서 싸울 수 있습니다.
SPDZ는 Damgard et al.이 제안한 부정직한 다수 컴퓨팅 프로토콜로, 둘 이상의 당사자가 있는 컴퓨팅 산술 회로를 지원할 수 있습니다. 오프라인 단계와 온라인 단계로 나뉩니다. SPDZ의 장점은 오프라인 단계에서 값비싼 공개 키 암호화 계산을 수행할 수 있는 반면 온라인 단계에서는 순수하게 저렴하고 정보 이론적으로 안전한 프리미티브를 사용한다는 것입니다. SWHE는 오프라인 단계에서 상수 라운드 보안 곱셈을 수행하는 데 사용됩니다. SPDZ의 온라인 단계는 선형 라운드이며 GMW 패러다임을 따르고 유한 필드에 대한 비밀 공유를 사용하여 보안을 보장합니다. SPDZ는 기껏해야 t<=n개의 부패한 악의적인 상대방과 싸울 수 있습니다. 여기서 t는 상대방의 수이고 n은 컴퓨팅 당사자의 수입니다.
중앙 집중식 암호화 프로토콜은 단계별로 요약되며 다양한 기술 경로에 해당하는 프레임워크 차이점은 대략 다음과 같습니다.
연합 학습 3.0 -- 군집 학습
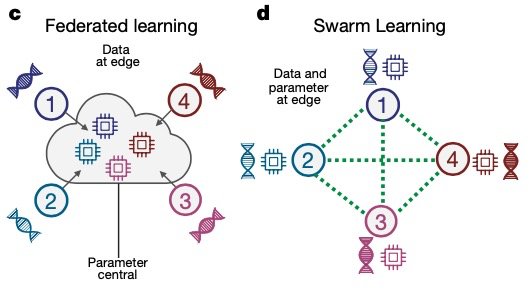
2021년 본 대학의 Joachim Schultze와 그의 파트너는 Swarm Learning(그룹 학습)이라는 "분산형 기계 학습 시스템"을 제안했는데, 이는 MPL을 기반으로 한 추가 진화 및 업그레이드로 현재의 기관 간 학습을 대체하는 방법입니다. 의료 연구에서 데이터 공유를 중앙 집중화합니다. Swarm 학습은 Swarm 네트워크를 통해 매개 변수를 공유하고, 각 참여자의 로컬 데이터에서 독립적으로 모델을 구축하고, 블록체인 기술을 사용하여 Swarm 네트워크를 파괴하려는 부정직한 참여자에 대해 강력한 조치를 취합니다.
FL 및 MPL과 비교하여 Swarm Learning은 연합 학습의 훈련 과정에 블록체인 기술을 도입하고 신뢰할 수 있는 제3자를 블록체인으로 대체하여 훈련 시너지 역할을 합니다.
【요약 및 전망】▲ 연합학습 기술 루트 비교
연합 학습의 과거와 현재를 통틀어 이미 문제를 해결하기 위한 다양한 기술적 경로를 가지고 있으며 요약하면 DML(Distributed Machine Learning), 연합 학습(FL), 안전한 다자간 학습(MPL), 그룹 학습(SL) ) 차이점은 대체로 다음과 같습니다.
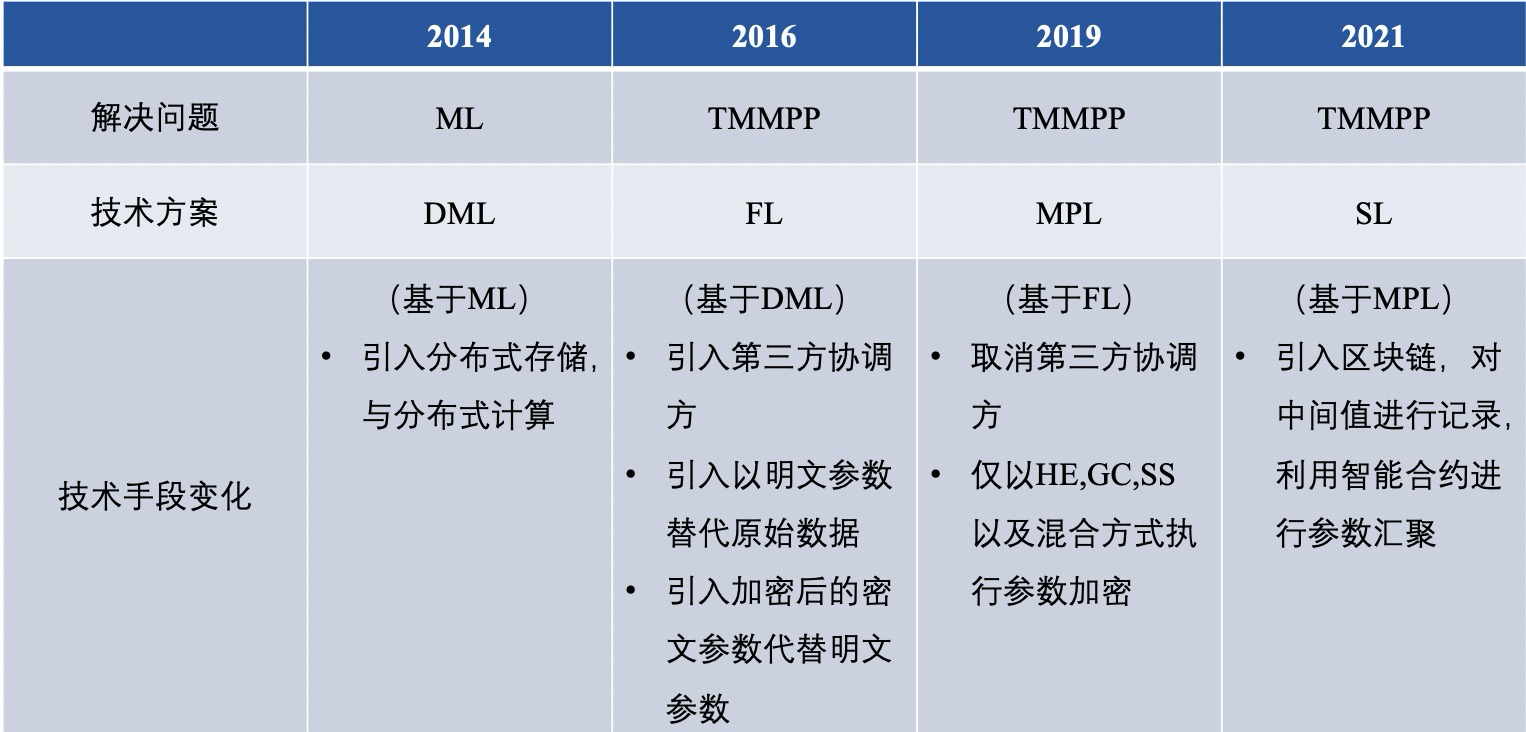
그중에서 우리는 전통적인 FL과 MPL을 더 심층적으로 비교하며 다음 6가지 사항에 반영됩니다.
1) 프라이버시 보호
MPC 프레임워크에서 사용되는 MPC 프로토콜은 양 당사자에게 높은 보안을 보장합니다. 그러나 암호화되지 않은 FL 프레임워크는 데이터 소유자와 서버 간에 일반 텍스트로 모델 매개변수를 교환하며 민감한 정보도 유출될 수 있습니다.
2) 통신 방법
MPL에서 데이터 소유자 간의 통신은 일반적으로 신뢰할 수 있는 제3자가 없는 피어 투 피어 형식인 반면 FL은 일반적으로 중앙 집중식 서버가 있는 클라이언트-서버 형식입니다. 즉, MPL의 각 데이터 소유자는 상태가 동일하지만 FL의 데이터 소유자와 중앙 집중식 서버는 동일하지 않습니다.
3) 통신 오버헤드
FL의 경우 데이터 소유자 간의 통신이 중앙 집중식 서버에 의해 조정될 수 있기 때문에 통신 오버헤드는 특히 데이터 소유자 수가 매우 많은 경우 점대점 형식의 MPL보다 작습니다.
4) 데이터 형식
현재 비 IID 설정은 MPL 솔루션에서 고려되지 않습니다. 그러나 FL의 솔루션에서는 각 데이터 소유자가 로컬에서 모델을 교육하므로 비 IID 설정에 적응하기가 더 쉽습니다.
5) 훈련 모델의 정확도
MPL에서는 일반적으로 전역 모델에서 정밀도 손실이 없습니다. 그러나 FL이 개인 정보를 보호하기 위해 DP를 활용하는 경우 글로벌 모델은 일반적으로 특정 정확도 손실을 겪습니다.
6) 적용 시나리오
위의 분석과 결합하여 MPL은 보안 및 정확도가 더 높은 시나리오에 더 적합하고 FL은 더 높은 성능 요구 사항이 있는 시나리오에 더 적합하며 더 많은 데이터 소유자에게 사용됨을 알 수 있습니다.
▲ 연합 학습 프레임워크의 다자간 비교
2016년부터 FL 기본 프레임워크 내용 비교
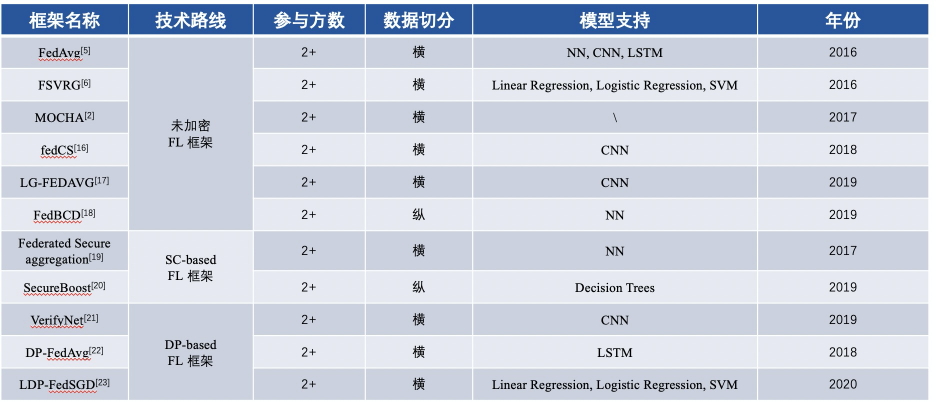
FL 기반 MPL 기본 프레임워크 내용 비교
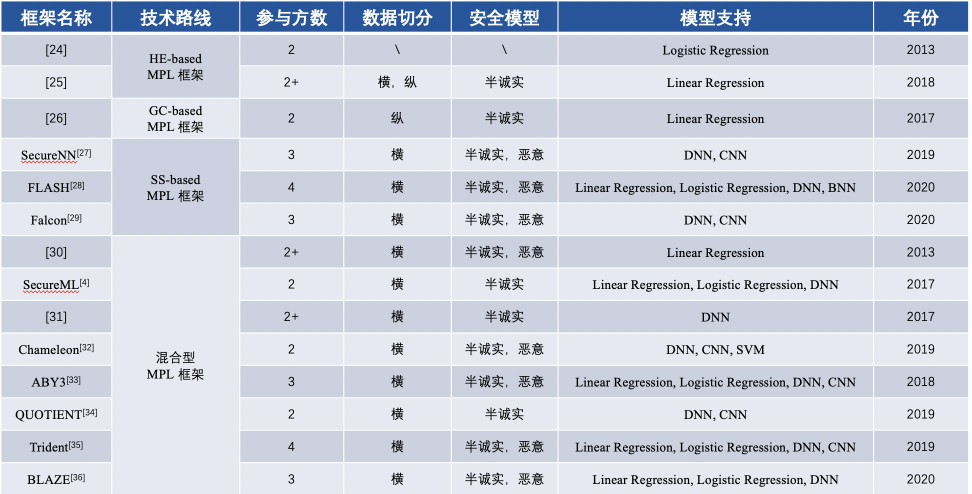
연합 학습 기술의 지속적인 발전으로 다양한 과제에 대한 연합 학습 플랫폼이 등장하고 있지만 아직 성숙 단계에 도달하지는 못했습니다. 현재 학계에서는 연합 학습 플랫폼이 주로 불균형하고 불균일하게 분산된 데이터 문제를 해결하는 반면 업계에서는 연합 학습의 보안 문제를 해결하기 위해 암호화 프로토콜에 더 중점을 둡니다.
양측이 손을 맞잡고 기존의 많은 기계 학습 알고리즘이 연방화되었지만 아직 미숙하고 아직 생산에 투입할 수 있는 단계에 도달하지 못했습니다. 최근 몇 년 동안 연합 학습 프레임워크의 연구 및 구현은 아직 초기 단계이므로 지속적인 노력과 발전이 필요합니다.
저자 소개
Yan Yang Federal Learning 선구자
참조
참조
[1] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[2] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[3] D. Demmler, T. Schneider, and M. Zohner, “Aby-a framework for efficient mixed-protocol secure two-party computation.” in Proceedings of The Network and Distributed System Security Symposium, 2015.
[4] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy- preserving machine learning,” in Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 19–38.
[5] H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas, “Feder- ated learning of deep networks using model averaging,” CoRR, vol. abs/1602.05629, 2016.
[6] J. Konecˇny`, H. B. McMahan, D. Ramage, and P. Richta ́rik, “Federated optimization: Distributed machine learning for on-device intelligence,” arXiv preprint arXiv:1610.02527, 2016.
[7] J. Konecˇny`, H. B. McMahan, F. X. Yu, P. Richta ́rik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communica- tion efficiency,” arXiv preprint arXiv:1610.05492, 2016.
[8] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” in Proceedings of Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
[9] A. C.-C. Yao, “How to generate and exchange secrets,” in Proceedings of the 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). IEEE, 1986, pp. 162–167.
[10] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,” in Proceedings of Advances in Neural Information Processing Systems, 2017, pp. 4424–4434.
[11] R. Fakoor, F. Ladhak, A. Nazi, and M. Huber, “Using deep learning to enhance cancer diagnosis and classification,” in Proceedings of the international conference on machine learning, vol. 28. ACM New York, USA, 2013.
[12] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “Xnor-net: Imagenet classification using binary convolutional neural networks,” in Proceedings of European conference on computer vision. Springer, 2016, pp. 525–542.
[13] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 815–823.
[14] P. Voigt and A. Von dem Bussche, “The eu general data protection regulation (gdpr),” A Practical Guide, 1st Ed., Cham: Springer Inter- national Publishing, 2017.
[15] D. Bogdanov, S. Laur, and J. Willemson, “Sharemind: A framework for fast privacy-preserving computations,” in Proceedings of European Symposium on Research in Computer Security. Springer, 2008, pp. 192–206.
[16] T.NishioandR.Yonetani,“Clientselectionforfederatedlearningwith heterogeneous resources in mobile edge,” in Proceedings of 2019 IEEE International Conference on Communications (ICC). IEEE, 2019, pp. 1–7.
[17] P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency, “Think locally, act globally: Federated learning with local and global representations,” arXiv preprint arXiv:2001.01523, 2020.
[18] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient vertical federated learning framework,” arXiv preprint arXiv:1912.11187, 2019.
[19] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre- gation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 2017, pp. 1175–1191.
[20] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, and Q. Yang, “Se- cureboost: A lossless federated learning framework,” arXiv preprint arXiv:1901.08755, 2019.
[21] G. Xu, H. Li, S. Liu, K. Yang, and X. Lin, “Verifynet: Secure and verifiable federated learning,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 911–926, 2019.
[22] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learn- ing differentially private recurrent language models,” arXiv preprint arXiv:1710.06963, 2017.
[23] Y. Zhao, J. Zhao, M. Yang, T. Wang, N. Wang, L. Lyu, D. Niyato, and K. Y. Lam, “Local differential privacy based federated learning for internet of things,” arXiv preprint arXiv:2004.08856, 2020.
[24] M. Hastings, B. Hemenway, D. Noble, and S. Zdancewic, “Sok: General purpose compilers for secure multi-party computation,” in Proceedings of 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 1220–1237.
[25] I. Giacomelli, S. Jha, M. Joye, C. D. Page, and K. Yoon, “Privacy-
preserving ridge regression with only linearly-homomorphic encryp- tion,” in Proceedings of 2018 International Conference on Applied Cryptography and Network Security. Springer, 2018, pp. 243–261.
[26] A. Gasco ́n, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Privacy-preserving distributed linear regression on high- dimensional data,” Proceedings on Privacy Enhancing Technologies, vol. 2017, no. 4, pp. 345–364, 2017.
[27] S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 26–49, 2019.
[28] M. Byali, H. Chaudhari, A. Patra, and A. Suresh, “Flash: fast and robust framework for privacy-preserving machine learning,” Proceedings on Privacy Enhancing Technologies, vol. 2020, no. 2, pp. 459–480, 2020.
[29] S. Wagh, S. Tople, F. Benhamouda, E. Kushilevitz, P. Mittal, and T. Rabin, “Falcon: Honest-majority maliciously secure framework for private deep learning,” arXiv preprint arXiv:2004.02229, 2020.
[30] V. Nikolaenko, U. Weinsberg, S. Ioannidis, M. Joye, D. Boneh, and N. Taft, “Privacy-preserving ridge regression on hundreds of millions of records,” pp. 334–348, 2013.
[31] M. Chase, R. Gilad-Bachrach, K. Laine, K. E. Lauter, and P. Rindal, “Private collaborative neural network learning.” IACR Cryptol. ePrint Arch., vol. 2017, p. 762, 2017.
[32] M. S. Riazi, C. Weinert, O. Tkachenko, E. M. Songhori, T. Schneider, and F. Koushanfar, “Chameleon: A hybrid secure computation frame- work for machine learning applications,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 2018, pp. 707–721.
[33] P. Mohassel and P. Rindal, “Aby3: A mixed protocol framework for machine learning,” in Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 35– 52.
[34] N. Agrawal, A. Shahin Shamsabadi, M. J. Kusner, and A. Gasco ́n, “Quotient: two-party secure neural network training and prediction,” in Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 2019, pp. 1231–1247.
[35] R. Rachuri and A. Suresh, “Trident: Efficient 4pc framework for pri- vacy preserving machine learning,” arXiv preprint arXiv:1912.02631, 2019.
[36] A. Patra and A. Suresh, “Blaze: Blazing fast privacy-preserving ma- chine learning,” arXiv preprint arXiv:2005.09042, 2020.
[37] Song L, Wu H, Ruan W, et al. SoK: Training machine learning models over multiple sources with privacy preservation[J]. arXiv preprint arXiv:2012.03386, 2020.


