
【컨센서스 칼럼】HotStuff 컨센서스
우리는 분산 시스템이 일반적으로 상태 복제기[1]의 원리를 통해 일관성을 달성한다는 것을 배웠습니다. 핵심 아이디어는 시스템의 모든 복제본이 동일한 상태 머신을 실행한다는 것입니다. 모든 복제본이 동일한 초기 상태로 시작하고 동일한 초기 상태를 기반으로 동일한 시퀀스에서 일련의 작업을 수행하는 한 모든 상태는 결국 수렴됩니다. 즉, 전체 시스템이 외부적으로 일관성을 나타냅니다. 이 작업 그룹을 동일한 순서로 결정하려면 시스템이 합의에 도달해야 합니다. 또한 모든 정직한 노드는 실행 순서에 대한 합의에 도달합니다. 이것이 유명한 Byzantine Generals [2] 문제입니다.
우리는 분산 시스템이 일반적으로 상태 복제기[1]의 원리를 통해 일관성을 달성한다는 것을 배웠습니다. 핵심 아이디어는 시스템의 모든 복제본이 동일한 상태 머신을 실행한다는 것입니다. 모든 복제본이 동일한 초기 상태로 시작하고 동일한 초기 상태를 기반으로 동일한 시퀀스에서 일련의 작업을 수행하는 한 모든 상태는 결국 수렴됩니다. 즉, 전체 시스템이 외부적으로 일관성을 나타냅니다. 이 작업 그룹을 동일한 순서로 결정하려면 시스템이 합의에 도달해야 합니다. 또한 모든 정직한 노드는 실행 순서에 대한 합의에 도달합니다. 이것이 유명한 Byzantine Generals [2] 문제입니다.
비잔틴 합의 알고리즘의 이론적 보안 보장, 즉 n>3f, n은 총 노드 수, f는 악성 노드 수입니다. 비잔틴 합의 알고리즘은 두 가지 속성을 보장해야 합니다.
보안: 모든 정직한 노드는 시스템 상태가 특정 순간에 있다고 믿습니다.
활동: 모든 정직한 노드는 최종적으로 s를 시스템 상태로 결정할 수 있습니다.
그 중 s는 추상적인 개념으로 시스템에 변수 S가 존재하는 것으로 이해할 수 있다. 특정 순간 (각 노드의 시계에 오류가 없다고 가정) S의 값에 대한 합의, 모든 정직한 노드는 보안을 충족하기 위해 변수 S=s를 결정하고, 모든 정직한 노드는 변수 S의 값에 대한 결정을 내려야 합니다. 생동감을 충족하기 위해 종료합니다.
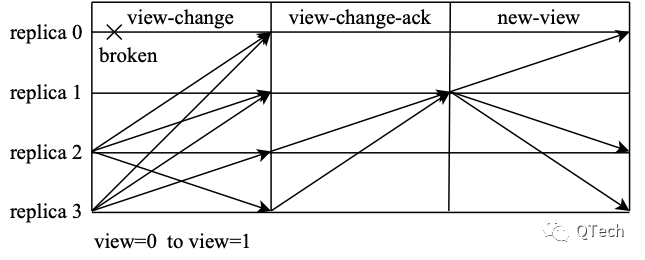
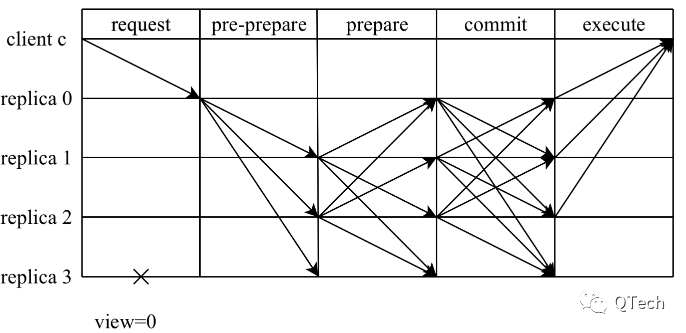
과거 분산 시스템 연구에서 비잔틴 합의는 종종 높은 통신 복잡성을 수반하여 네트워크의 많은 소비를 초래했으며 시스템의 규모 확장이 쉽지 않았습니다. 예를 들어 고전적인 PBFT 알고리즘에서는 합의에 도달하기 위해 세 단계를 거쳐야 합니다.PRE-PREPARE 단계에서는 마스터 노드가 다른 노드에 요청 메시지를 보내고 다른 노드가 메시지를 확인한 후 준비를 보냅니다. 다른 노드에 대한 메시지 이 단계는 n ^2 메시지를 생성합니다. 뷰 간의 일관성을 보장하기 위해 노드는 최소한 쿼럼 준비 메시지를 수신한 후 커밋 메시지를 다른 노드로 보냅니다. 노드가 최종적으로 최소 쿼럼의 커밋 메시지를 수신하면 최종적으로 요청을 제출합니다. 그러나 네트워크 비정상 노드가 타임 아웃되어 뷰 전환이 발생하면 o(n^3)의 통신 복잡도가 필요합니다.
PBFT의 각 단계의 작업을 이해하는 것은 HotStuff의 기본이며 PBFT의 각 단계의 목표는 안전과 활성을 보장하는 것입니다.
시스템이 특정 순간에 S'=S+1 명령을 받았다고 가정하면 마스터 노드는 이 명령 S'=S+1을 마스터가 아닌 노드에게 보냅니다(이것은 사전 준비 메시지입니다). 비잔틴 문제, 정직한 노드는 수신된 메시지가 다른 정직한 노드와 일치하는지 여부를 확신할 수 없으며(마스터 노드가 일치하지 않는 메시지를 전송함) 노드는 메시지가 수신되었는지 확인하기 위해 서로 한 번 통신해야 합니다. 다른 정직한 노드는 일관성이 있고(마스터 노드가 일관성 없는 메시지를 보내지 않았는지 확인), 각 노드는 다른 모든 노드에 준비 메시지를 보내고 쿼럼 준비 메시지를 수신하면 확인을 통과합니다(준비 시 지시 사항이 지시되었는지 확인) 자신과 일치함) 첫 번째 합의에 도달합니다(이것이 PREPARE 단계입니다). 이 시점에서 정직한 노드가 수신한 메시지는 일관성이 있는 것으로 보입니다. 그러나 여기서 암묵적인 조건은 합의에 도달한 노드가 자신의 관점에서만 볼 수 있다는 것입니다. 쿼럼 일치 메시지를 수신하고 확인했습니다. 그러나 다른 노드는 합의에 도달하기 위해 반드시 정족수 준비 메시지를 수신하지 않을 수 있으며 이때 제출이 이루어지고 네트워크 장애가 발생하면 제출된 노드는 합의가 이루어진 것으로 알고 네트워크가 복구되는 한 이 지시는 전체 시스템에서 확실히 받아들일 것입니다. 그러나 다른 노드는 네트워크 장애로 인해 합의에 도달하지 못했을 수 있으며 대기 후 제출할 수 있는지 여부를 확신할 수 없습니다. 시스템이 살아있도록 하기 위해 뷰 전환이 이루어지며, 이때 새로운 마스터 노드는 S' 또는 S를 기반으로 새로운 명령어를 실행할지 여부를 결정해야 합니다. 일부 노드가 명령을 제출한 것이 발견되지 않고 다른 명령 S''=S+2가 동의 및 제출된 경우 시스템은 변수 S의 값에 불일치를 갖게 됩니다. 따라서 현재 제출해야 할 보안 문제가 있습니다.
합의의 또 다른 단계가 수행되면 PREPARE 합의에 도달한 후 각각 다른 커밋 메시지를 보내고 각 노드는 제출하기 전에 쿼럼 커밋 메시지를 수락하고 확인하기 위해 기다립니다. COMMIT 합의에 도달한 노드는 제출했습니다.네트워크가 정상이면 시스템이 조만간 제출할 것이라는 것을 알고 있지만 COMMIT 합의에 도달하지 않은 다른 노드는 자신이 있는지 확실하지 않습니다. 최종적으로 제출할 수 있습니다. 네트워크 장애가 발생한 후 새 보기의 마스터 노드가 제출된 노드를 찾지 못하면 여전히 불일치가 발생합니다. 여기서 모순은 활동에 대한 합의를 계속하려면 보기를 전환해야 한다는 것입니다. 보다. PBFT에서는 뷰가 전환될 때 자신의 S 상태를 증명하기 위해 다른 노드에 메시지를 보내는 방법, 즉 최신 S의 사전 준비 메시지와 해당 쿼럼 준비 메시지를 보내는 방법을 사용합니다. 관점이 전환되면 새로운 마스터 노드는 합의 전에 S'=S+1을 제출해야 하는지 여부를 판단할 수 있습니다.
어떤 노드도 S'=S+1에 대한 PREPARE에 대한 합의에 도달하지 않으면 S'=S+1을 계속 제출하지 않습니다.
S'=S+1의 PREPARE 단계에서 합의에 도달한 노드 쌍이 있는 경우 충돌하는 명령 S''=S+2에 대한 합의에 도달하여 제출하는 것은 불가능합니다.
이 규칙에 따르면 보안과 활동이 보장되지만 이 방법으로 인한 복잡성은 o(n^3)입니다. 따라서 이 알고리즘은 여전히 대규모 네트워크에서 사용할 수 없습니다. Yin Maofan 등이 제안한 HotStuff 합의 알고리즘[4]은 선형 보기 변경의 특성을 가지고 있어 기존 PBFT 또는 BFT 합의의 병목 현상을 해결합니다.마스터 노드의 전환은 다른 프로토콜과 비용을 증가시킬 필요가 없으며, 시스템은 여전히 일관된 외부 작업을 수행할 수 있으며, 합의 프로세스의 통신 복잡성을 o(n)으로 줄입니다.
——HotStuff 기본 개념——
hotstuff 알고리즘을 이해하려면 합의 프로세스와 관련된 몇 가지 개념을 소개해야 합니다.
1) 임계값 서명[5](임계값 서명): A(k, n) 임계값 서명 방식은 n명의 구성원으로 구성된 서명 그룹을 말하며, 모든 구성원은 공통 키를 공유하고 각 구성원은 자신의 개인 키를 가집니다. k 구성원의 서명이 수집되고 완전한 서명이 생성되는 한 공개 키로 서명을 확인할 수 있습니다.
2) 인증서(Quorum Certificate, QC): 마스터 노드가 제안에 대한 최소 쿼럼 노드 쌍 투표 메시지(서명 포함)를 수신한 후 임계값 서명을 사용하여 QC를 합성합니다. 이 QC는 완전한 임계값 서명으로 이해될 수 있습니다. 생성된 서명은 제안에 대한 합의에 도달했음을 의미합니다.
3) 보기: 보기는 합의의 기본 단위입니다.보기는 최대 한 번 합의에 도달할 수 있으며 단조롭게 증가합니다.각 보기는 점차적으로 회전하여 합의를 진행합니다.
4) 합의 상태 트리: 각 합의 블록은 트리 노드로 간주될 수 있으며, 각 트리 노드에는 해당 제안 내용(이전 작업 지침) 및 해당 QC가 포함되며, 각 트리 노드에는 부모 트리 노드 해시가 포함되어 트리를 형성합니다. 구조이고 마스터 노드는 가장 긴 로컬 분기를 기반으로 새 트리 노드를 생성합니다. 지연 노드는 다른 노드의 가장 긴 분기에 있는 최신 트리 노드에 대해 누락된 중간 트리 노드를 동기화합니다.
—— HotStuff 합의 프로세스 ——
텍스트
▲ Basic Hotstuff
Basic HotStuff는 합의의 기본 프로세스입니다. 그 중 뷰는 단조롭게 증가하는 방식으로 계속 전환됩니다. 각 뷰에는 제안, 메시지 수집 및 전달, QC 생성을 담당하는 고유한 마스터 노드가 있습니다. 전체 프로세스는 준비 단계(PREPARE), 제출 전 단계(PRE-COMMIT), 제출 단계(COMMIT), 결정 단계(DECIDE), 마스터 노드가 특정 브랜치를 제출(합의에 도달)하고 PREPARE, PRE-COMMIT, COMMIT의 3단계에서 쿼럼 합의 노드로부터 서명이 있는 투표 메시지를 수집하고 임계값 서명을 사용하여 QC를 합성합니다. , 그런 다음 다른 노드로 브로드캐스트합니다.
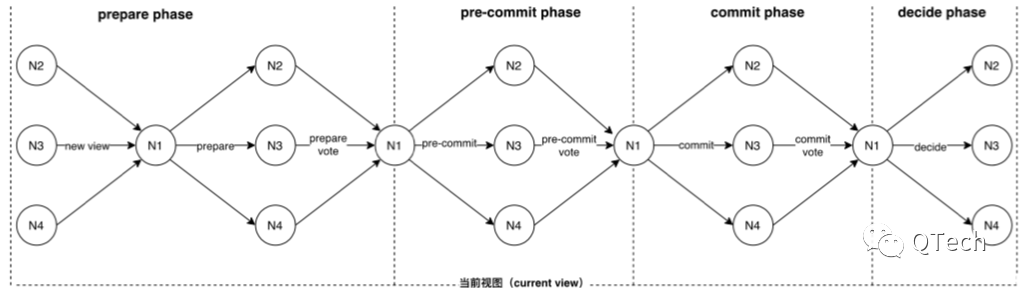
임계값 서명과 결합하여 HotStuff는 처리, 병합 및 전달을 위해 합의 메시지를 마스터 노드로 브로드캐스팅하는 이전 방법을 변환할 수 있으며 통신 복잡성을 o(n)으로 줄일 수 있습니다. 달성하기 위한 통신 PBFT 통신 라운드의 합의 효과.
PBFT 알고리즘과 비교하여 사전 준비 단계에서 마스터 노드가 다른 노드에 요청을 보내면 합의가 시작되며, 마스터 노드는 이번 합의의 책임을 다하고 다른 노드와 동일합니다. 전체 합의 프로세스는 브로드캐스트 제안 단계(PRE-PREPARE 단계)와 두 개의 합의 단계(PREPARE 단계, COMMIT 단계)를 포함합니다.
준비 단계:
마스터 노드: 1) 보낸 사람의 상태 트리에서 가장 높이가 높은 prepareQC를 포함하는 수신된 쿼럼 New-View 메시지에 따라 마스터 노드는 수신된 prepareQC에서 가장 높은 높이 QC를 계산하며 이는 highQC로 기록됩니다.
2) 이 highQC의 노드가 가리키는 분기에 따라 블록을 패킹하여 새로운 트리 노드를 생성하고 그 부모 노드는 highQC가 가리키는 노드입니다.
3) 생성된 Proposal을 다른 슬레이브 노드들에게 prepare 메시지로 전송하며, 현재의 Proposal에는 highQC가 포함되어 있습니다.
슬레이브 노드: 1) 준비 메시지를 수신한 후 qc의 서명 유효성, 현재 보기의 제안인지 여부를 포함하여 준비에서 정보를 확인합니다.
2) Prepare 메시지의 노드가 lockedQC의 분기(즉, 자식 노드)에서 확장되었는지 또는 Prepare 메시지의 highQC의 뷰 수가 lockedQC보다 큰지(전자는 보안 조건이며, 후자는 노드가 뒤쳐질 때 적시에 동기화를 보장하기 위한 활성 조건입니다.
3) 투표 준비 메시지를 생성하고 서명과 함께 마스터 노드로 보냅니다.
사전 커밋 단계:
마스터 노드가 현재 제안에 대한 쿼럼 준비-투표 메시지를 수신하면 쿼럼 부분 서명을 집계하여 prepareQC를 얻은 다음 마스터 노드는 집계된 prepareQC와 함께 사전 커밋 메시지를 브로드캐스트합니다.
슬레이브 노드: 다른 노드는 pre-commit 메시지를 수신하고 확인 후 마스터 노드에 pre-commit 투표 메시지를 보냅니다.
⚠️이때 마스터노드가 보낸 pre-commit에 있는 prepareQC는 준비 메시지에 제안 메시지를 표시하고 모든 노드가 성공적으로 합의에 도달하도록 투표했습니다. 이 순간은 PREPARE 단계에서 합의에 도달한 것과 유사합니다. PBFT에서.
커밋 단계:
마스터 노드: 커밋 전 단계와 유사합니다. 1) 마스터 노드는 먼저 쿼럼 사전 커밋 투표 메시지를 수집한 다음 이 단계의 pre-commitQC를 집계하고 커밋 메시지에서 다른 노드로 보냅니다. 2) 로컬 lockedQC를 pre-commitQC로 설정합니다.
슬레이브 노드: 커밋 메시지를 수신하면 메시지 검증을 통과하고 로컬 lockedQC도 커밋 메시지의 pre-commitQC로 업데이트하고 서명하고 커밋 투표를 생성하여 마스터 노드로 전송
⚠️ 이때 마스터 노드가 보낸 커밋 메시지에 첨부된 pre-commitQC는 PBFT의 두 번째 COMMIT 단계 합의와 유사하며, 여기서 PBFT에서 이 단계의 합의는 첫 번째 단계의 합의를 나타냅니다. 합의에 도달하기 위한 노드 쌍, 즉 최소한 쿼럼 노드가 PREPARE 단계를 완료했는지 확인하고 보기 전환이 발생하면 충분한 노드가 제안에 대한 PREPARE 합의에 도달했음을 증명할 수 있으며 제안 내용이 필요합니다. 새 보기에서 제출할 수 있습니다.
결정 단계:
마스터 노드: 1) 쿼럼 커밋 투표 메시지가 수집되면 commitQC가 집계되어 결정 메시지의 다른 노드로 전송됩니다.
2) 다른 노드가 결정 메시지를 수신하면 commitQC가 가리키는 제안의 트랜잭션이 실행됩니다.
3) 그런 다음 뷰 번호 viewnumber를 늘리고 다음 합의 라운드를 시작하고 prepareQC에 따라 New-View 메시지를 구성합니다.
슬레이브 노드: 메시지 확인 후 결정 메시지에서 commitQC가 가리키는 트리 노드의 트랜잭션을 실행합니다.
nextView 인터럽트 단계: 합의의 다른 단계에서 시간 초과 이벤트가 발생하면 새로운 보기에 대한 새로운 보기 메시지를 보내면 새로운 합의의 다음 라운드가 바로 시작됩니다.
텍스트
▲ Chained HotStuff
Basic HotStuff의 각 단계의 프로세스가 매우 유사함을 알 수 있으며, HotStuff 작성자는 Basic HotStuff의 메시지 유형을 단순화하고 Basic HotStuff의 각 단계에서 파이프라인 방식으로 트랜잭션을 처리할 수 있도록 Chained HotStuff를 제안했습니다.
Chained HotStuff의 프로세스는 다음과 같습니다.
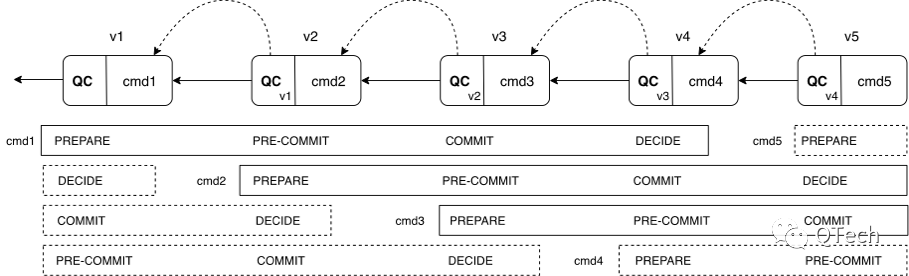
그림에서 볼 수 있듯이 각 단계는 보기를 전환하므로 각 제안마다 고유한 보기가 있습니다. 노드는 다른 제안에 대해 다른 보기에 있음 PREPARE 단계의 투표는 현재 보기의 마스터 노드에 의해 QC로 합성되어 다음 보기의 마스터 노드로 전달됩니다. 이전 보기의 PRE-COMMIT 단계로 진행합니다. 각 단계는 유사한 구조를 가지며 v+1 관점의 PREPARE 단계는 v 관점의 PRE-COMMIT 단계로 볼 수 있다. 뷰 v+2의 PREPARE 단계는 뷰 v+1의 PRE-COMMIT 단계 및 뷰 v의 COMMIT 단계로 간주됩니다. v1의 cmd1은 뷰 v1, v2 및 v3에서 각각 PREPARE, PRE-COMMIT 및 COMMIT 단계를 수행하고 v4에서 커밋합니다. cmd2 등. 각 단계의 cmd 제안서 생성에는 이전 단계에서 투표된 QC가 수반됩니다. 간소화된 HotStuff 버전의 작업 프로세스는 다음과 같습니다.
마스터 노드: 1) NEW-VIEW 메시지를 기다리고 자체 제안을 보냅니다.
2) 다른 노드가 투표하기를 기다립니다.
3) 다음 마스터노드로 NEW-VIEW 메시지를 보낸다.
슬레이브 노드: 1) 마스터 노드의 제안 메시지를 기다립니다.
2) 제안서에서 QC를 확인하고 로컬 highQC, lockedQC를 업데이트하고 투표를 보냅니다.
3) 다음 마스터노드로 NEW-VIEW 메시지를 보낸다.
▲ Event-driven HotStuff
Chained HotStuff에서 Event-driven HotStuff에 이르기까지 원본 문서는 전체 프로토콜의 안전성(safety)과 활성도(liveness)를 분리하고 활성도는 별도의 페이스메이커 모듈이 됩니다. 심박조율기 모듈은 GST(Global Stability Time) 이후에도 활성을 보장합니다. 두 가지 기능을 제공합니다.
각 보기의 기본 노드를 선택하고 확인하십시오.
마스터노드가 제안서를 생성하도록 돕습니다.
즉, 이러한 낮은 보기 전환 비용으로 적절한 노드 회전 메커니즘과 제안 생성 전략을 심박 조율기에서 채택할 수 있습니다.
Event-driven Hotstuff 및 기타 버전의 원칙은 여전히 핵심 3단계 합의입니다. 차이점은 단지 엔지니어링 구현의 편의성입니다. 자세한 내용은 논문 [4]의 유사 코드를 참조하십시오.
보조 제목
활동 메커니즘 최적화
적극적인 메커니즘은 합의의 지속적인 발전의 열쇠입니다. 원래 HotStuff 논문에서 활성 메커니즘은 보기 시간 초과를 결정하기 위해 전역적으로 일관된 시간 초과를 사용했습니다. NoxBFT에서는 네트워크 환경의 불안정성에 대처하기 위해 보다 유연한 메커니즘을 설계했습니다.
보조 제목
트랜잭션 버퍼 풀
블록체인 적용 시 트랜잭션 손실을 방지하기 위해 클라이언트 트랜잭션을 캐시하는 트랜잭션 캐시 풀을 설계했습니다. 컨센서스 모듈은 패키징을 위해 트랜잭션을 적극적으로 가져옵니다. 트랜잭션 풀은 또한 합의 작업 부하를 줄이고 트랜잭션을 중복 제거할 수 있습니다 트랜잭션 콘텐츠 해시를 통해 트랜잭션을 식별하고 실행된 트랜잭션을 Bloom 필터에 기록하여 이중 지출 공격을 방지하고 합의 알고리즘의 안정성을 향상시킵니다.
빠른 복구 메커니즘
불안정한 네트워크 환경으로 인해 합의 노드가 합의 메시지를 잃어버리고 노드가 뒤쳐질 수 있습니다. 원래 HotStuff 논문에서 저자는 이 부분의 구체적인 구현을 개발자에게 맡겼습니다. 우리는 지연된 합의 노드의 순서 지정 기능을 복원하기 위해 프로젝트에서 사용할 수 있는 동기화 알고리즘을 구현했으며, 이는 두 단계로 나뉩니다.
1) 노드가 훨씬 뒤떨어져 있고 다른 노드에서 직접 블록을 끌어와 최신 체크포인트로 복원합니다.
2) 체크포인트 이후 합의 진행이 뒤처지고 최신 CommitQC를 다른 노드에서 가져와 합의 진행을 신속하게 복원합니다.
효율성을 향상시키기 위해 서로 다른 노드에서 블록을 병렬로 끌어오는 메커니즘을 채택하고 병렬도를 유연하게 구성할 수 있습니다. 병렬로 풀링된 블록은 먼저 지속되고 순서대로 실행되며 동시에 각 노드의 풀링 효율성 점수가 기록되어 다음 동기화 대상 노드를 효율적으로 선택할 수 있습니다. 전체 프로세스는 손실된 모든 트랜잭션을 가장 빠른 속도로 가져올 수 있으므로 전체 프로세스의 대기 시간이 줄어듭니다.
집계 서명
요약하다
요약하다
저자 소개
저자 소개
쳉 타이닝
참조
참조
[1] Schneider F B . The state machine approach: A tutorial[J]. Springer New York, 1990.
[2] Lamport L , Shostak R , Pease M . The Byzantine Generals Problem[J]. ACM Transactions on Programming Languages and Systems, 1982, 4(3).
[3] Castro M, Liskov B. Practical Byzantine fault tolerance[C]. OSDI.1999, 99(1999): 173-186.
[4] Yin M , Malkhi D , Reiter M K , et al. HotStuff: BFT Consensus in the Lens of Blockchain[J]. 2018.
[5] Shoup V . Practical Threshold Signatures[C]// International Conference on Theory & Application of Cryptographic Techniques. Springer-Verlag, 2000.


