
[합의 칼럼] 정족수 메커니즘과 PBFT
텍스트
PBFT(Practical Byzantine Fault Tolerance)는 채널이 신뢰할 수 있을 때 비잔틴 장군 문제를 해결하는 실용적인 방법입니다. 비잔틴 장군 문제는 Leslie Lamport 등이 1982년에 발표한 논문 [1]에서 처음 제안되었다. 덜 충성스러운 장군은 명령에 대한 합의에 도달할 수 있습니다. 즉, 3f+1<=n, 알고리즘 복잡도는 O(n^(f+1))입니다. 이후 Miguel Castro와 Barbara Liskov는 1999년에 발표된 논문 [2]에서 PBFT 알고리즘을 처음 제안하였다. 알고리즘의 내결함성 개수도 3f+1<=n을 만족하며, 알고리즘 복잡도는 O(n^ 2).
PBFT 합의 알고리즘에 대한 이해가 있다면 총 노드 수 n과 내결함성 상한 f 사이의 관계에 익숙할 것입니다. 시스템의 총 노드 수 n은 n>3f를 만족해야 하며 합의를 진행하는 과정에서 인증 프로세스를 완료하기 위해 일정 수의 투표를 수집해야 합니다. 이 섹션에서는 먼저 이러한 값 간의 관계를 도출할 수 있는 방법에 대해 설명합니다.
--쿼럼 메커니즘--
중복 데이터가 있는 분산 스토리지 시스템에서 중복 데이터 개체는 서로 다른 시스템 간에 여러 복사본을 저장합니다. 그러나 동시에 데이터 개체의 여러 복사본은 읽기 또는 쓰기에만 사용할 수 있습니다. 데이터 중복성과 일관성을 유지하기 위해서는 이를 유지하기 위한 상응하는 투표 메커니즘이 필요하며, 이것이 바로 쿼럼 메커니즘입니다. 분산 시스템으로서 블록체인은 클러스터 유지 관리를 위해 이 메커니즘도 필요합니다.
쿼럼 메커니즘을 더 잘 이해하기 위해 먼저 비슷하지만 더 극단적인 투표 메커니즘인 WARO 메커니즘(Write All Read One)을 이해해 봅시다. 총 노드 수가 n인 클러스터를 유지하기 위해 WARO 메커니즘을 사용하는 경우 쓰기 작업을 수행할 노드에 대한 "votes"는 n이어야 하고 읽기 작업에 대한 "votes"는 1로 설정할 수 있습니다. 즉, 쓰기 작업을 수행할 때 작업이 완료된 것으로 간주되기 전에 모든 노드가 쓰기 작업을 완료해야 하며, 그렇지 않으면 쓰기 작업이 실패합니다. 한 노드의 읽기가 필요한 경우 시스템 상태를 확인할 수 있습니다. WARO 메커니즘을 사용하는 클러스터에서 쓰기 작업 실행이 매우 취약하다는 것을 알 수 있습니다. 한 노드가 쓰기를 수행하지 못하는 한 작업을 완료할 수 없습니다. 그러나 쓰기 작업의 견고성은 희생되지만 WARO 메커니즘에서는 클러스터에서 읽기 작업을 수행하는 것이 매우 쉽습니다.
쿼럼 메커니즘[3]은 읽기 및 쓰기 작업에 대한 타협 고려 사항입니다.동일한 데이터 개체의 각 복사본에 대해 두 개 이상의 액세스 개체를 읽고 쓸 수 없으며 읽기 및 쓰기에 대한 설정된 크기 요구 사항이 평가됩니다. 분산 클러스터에서 각 데이터 복사 개체에는 투표가 제공됩니다. 가정:
시스템에 V개의 티켓이 있습니다. 즉, 데이터 개체에 V개의 중복 복사본이 있습니다.
각 읽기 작업에 대해 획득한 투표 수는 성공적으로 읽기 위한 최소 읽기 투표 수 R(읽기 정족수) 이상이어야 합니다.
각 쓰기 작업에 대해 획득한 투표 수는 성공적으로 쓰기 위한 최소 쓰기 투표 수 W(쓰기 쿼럼) 이상이어야 합니다.
클러스터의 합의 노드의 경우 합의 알고리즘을 발전시킬 때 합의에 참여하는 노드는 클러스터에서 동시에 읽기 및 쓰기 작업을 수행합니다. 컬렉션 크기에 대한 읽기 및 쓰기 작업 요구 사항의 균형을 맞추기 위해 각 노드의 R 및 W는 Q로 표시되는 동일한 크기를 취합니다. 클러스터에 총 n개의 노드가 있고 최대 f개의 오류 노드가 있는 경우 n, f 및 Q 간의 관계를 어떻게 계산합니까? 다음으로 가장 간단한 CFT 시나리오에서 시작하여 BFT 시나리오에서 이러한 수치 간의 관계를 얻는 방법을 점차 탐색합니다.
▲CFT
텍스트
CFT(Crash Fault Tolerance)는 시스템의 노드가 충돌(Crash)의 오류 동작만 경험하고 어떤 노드도 적극적으로 오류 메시지를 보내지 않음을 의미합니다. 합의 알고리즘의 신뢰성을 논의할 때 우리는 일반적으로 알고리즘의 두 가지 기본 속성인 활성과 안전성에 초점을 맞춥니다. Q의 크기를 계산할 때 이 두 가지 각도에서도 고려할 수 있습니다.
활동 및 보안에 대해 다음을 설명하는 보다 직관적인 방법이 있습니다.
어떤 일이 결국 일어난다[4], 사건은 결국 일어날 것이다
결국 좋은 일이 일어난다[4], 결국 일어날 이 사건은 합리적이다
활동의 관점에서 우리 클러스터는 계속 실행될 수 있어야 하며 일부 노드의 오류로 인해 합의를 계속할 수 없습니다. 보안의 관점에서 우리 클러스터는 합의 추진 과정에서 계속 합리적인 결과를 얻을 수 있습니다.분산 시스템의 경우 이 "합리적인" 결과에 대한 가장 기본적인 요구 사항은 클러스터의 전체 상태입니다.일관성.
따라서 CFT 시나리오에서 Q 값의 결정은 간단하고 명확해집니다.<=n-f。
활동: 클러스터가 계속 실행될 수 있는지 확인해야 하므로 컬렉션에 대한 데이터를 읽고 쓸 수 있도록 모든 시나리오에서 Q 티켓을 얻을 수 있는 가능성을 확인해야 합니다. 클러스터에서 최대 f개의 노드가 다운되기 때문에 Q 티켓을 확보하려면 이 값의 크기가 다음을 충족해야 합니다. Q
▲BFT
보안: 쿼럼 메커니즘의 기본 요구 사항에 따라 클러스터가 분기되지 않도록 해야 하므로 이전 섹션에서 언급한 두 가지 부등식을 충족해야 하며 Q는 최소 읽기로 이 부등식 집합에 포함됩니다. 이때 Q는 부등식 Q+Q>n 및 Q>n/2를 만족하므로 이 값의 크기는 Q>n/2를 충족해야 합니다.
BFT(Byzantine Fault Tolerance)는 클러스터의 잘못된 노드가 다운될 수 있을 뿐만 아니라 악의적인 동작, 즉 활성 상태 포크와 같은 비잔틴 동작을 가질 수 있음을 의미합니다. 이 경우 클러스터 전체에 대해 nf 노드만 신뢰할 수 있는 상태이며 Q 투표를 수집할 때 Qf 투표만 신뢰할 수 있는 노드에서 나옵니다. 따라서 보안 측면에서 BFT 시나리오에서는 신뢰할 수 있는 상태의 노드 간에 차이가 없도록 해야 하므로 다음 두 가지 관계를 얻습니다.<=n-f。
활동: 항상 Q 티켓을 얻을 수 있는 가능성이 있는지 확인하는 것만이 여전히 필요하므로 Q
▲총 노드 수와 내결함성 상한
텍스트
총 노드 수 n과 내결함성 상한 f에 대해 PBFT 논문[1]에 설명이 나와 있습니다. 다운될 가능성이 있는 노드가 f개이므로 최소한 nf 메시지를 받았을 때 응답해야 하며, nf 노드에서 메시지를 수신하려면 신뢰할 수 없는 비잔틴 노드에서 최대 f 메시지가 있을 수 있으므로 nff>f를 충족해야 하므로 n>3f를 충족해야 합니다.간단히 말해서 PBFT 작성자는 클러스터 활동과 보안의 관점에서 총 노드 수와 내결함성 상한 간의 관계를 얻었습니다. 이전 섹션에서 우리는 또한 활동과 보안의 관점에서 n, f 및 Q 간의 관계를 얻었으며 여기에서 n과 f 간의 관계를 도출하는 데에도 사용할 수 있습니다. 동시에 Q는 부등식 관계 Q<=nf 및 Q>(n+f)/2를 만족해야 하므로 n과 f 사이의 부등식 관계는 (n+f)/2를 얻을 수 있습니다.
(유사한 방법으로 CFT 장면에서 n과 f의 관계도 n>2f로 구할 수 있습니다.)
--PBFT 및 RBFT--
BFT 시나리오에서 n, f 및 Q 간의 관계를 이해한 후 PBFT 소개로 이동하겠습니다. 그 전에 SMR(State Machine Replication) 복제 상태 머신[5]에 대해 간단히 언급합니다. 이 모델에서 다른 상태 기계에 대해 동일한 초기 상태에서 시작하여 동일한 명령 세트를 동일한 순서로 입력하면 항상 동일한 최종 결과를 얻습니다. 합의 알고리즘의 경우 각 상태 머신에서 동일한 상태를 얻기 위해 "동일한 명령이 동일한 순서로 입력"되는지 확인하기만 하면 됩니다. PBFT는 명령 실행 순서에 대한 합의입니다.
▲ 2단계 합의
텍스트
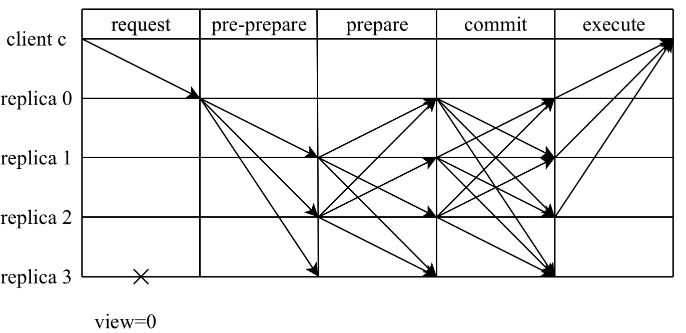
보다 일반적인 "3단계" 개념(사전 준비, 준비, 커밋)과 비교하여 PBFT를 2단계 합의 프로토콜로 보는 것은 제안 단계(사전 준비 및 준비) 및 커밋이라는 각 단계의 목적을 더 잘 반영할 수 있습니다. 단계(커밋). 각 단계에서 각 노드는 다음 단계에 진입하기 전에 Q 노드로부터 만장일치 투표를 받아야 합니다. 쉬운 논의를 위해 여기서는 총 노드 수가 3f+1일 때 시나리오를 논의할 것입니다. 이때 읽기 및 쓰기 티켓 수 Q는 2f+1입니다.
1) 제안 단계
이 단계에서 마스터 노드는 사전 준비를 전송하여 합의를 시작하고 슬레이브 노드는 준비를 전송하여 마스터 노드의 제안을 확인합니다. 클라이언트로부터 요청을 받은 후 마스터 노드는 사전 준비 메시지를 다른 노드에 능동적으로 브로드캐스트합니다.
v는 현재 보기입니다.
n 마스터 노드가 할당한 요청 시퀀스 번호
D(m)은 메시지 다이제스트입니다.
m은 메시지 자체입니다.
사전 준비 메시지를 수신한 후 슬레이브 노드는 메시지의 유효성을 검증하고 검증이 통과되면 노드는 사전 준비 상태로 들어가 슬레이브 노드에서 요청이 적법성 검증을 통과했음을 나타냅니다. 그렇지 않으면 슬레이브 노드가 요청을 거부하고 보기 전환 프로세스를 트리거합니다. 슬레이브 노드가 사전 준비 상태에 진입하면 준비 메시지를 다른 노드에 브로드캐스트합니다.
i는 현재 노드 식별 번호입니다.
다른 노드가 메시지를 수신한 후 요청이 현재 노드에서 사전 준비 상태에 진입하고 다른 노드에서 2f 해당 준비 메시지(자신 포함)를 수신하면 준비 상태로 진입하고 제안 단계가 완료됩니다. 이때 2f+1개의 노드는 메시지 m에 시퀀스 번호 n을 할당하는 데 동의합니다. 이는 합의 클러스터가 메시지 m에 시퀀스 번호 n을 할당했음을 의미합니다.
2) 제출 단계
▲체크포인트 메커니즘
텍스트
PBFT 합의 알고리즘이 작동하는 동안 많은 양의 합의 데이터가 생성되므로 합리적인 가비지 수집 메커니즘을 구현하여 중복 합의 데이터를 적시에 정리해야 합니다. 이 목표를 달성하기 위해 PBFT 알고리즘은 가비지 수집을 위한 체크포인트 프로세스를 설계합니다.
체크포인트는 클러스터가 안정적인 상태에 진입했는지 확인하는 과정인 체크포인트다. 확인할 때 노드는 체크포인트 메시지를 방송합니다.
n은 현재 요청 시퀀스 번호입니다.
d는 메시지 실행 후 얻은 다이제스트입니다.
i는 현재 노드를 나타냅니다.
체크포인트 메시지 이후 현재 클러스터가 시퀀스 번호 n에 대해 안정적인 체크포인트(stable checkpoint)에 진입한 것으로 간주할 수 있다. 이 시점에서 안정적인 체크포인트 이전의 합의 데이터는 더 이상 필요하지 않으며 정리할 수 있습니다. 그러나 가비지 수집을 위해 체크포인트를 자주 실행하면 시스템 운영에 상당한 부담이 된다. 따라서 PBFT는 체크포인트 프로세스의 실행 간격을 설계하고 k개의 요청이 실행될 때마다 노드가 체크포인트를 적극적으로 시작하여 최신 안정 체크포인트를 얻습니다.
또한 PBFT는 가비지 수집을 지원하기 위해 하이/로우 워터마크 개념을 도입했습니다. 합의 과정에서 노드 간 성능 차이로 인해 노드 간 동작 속도 차이가 너무 큰 상황이 발생할 수 있습니다. 일부 노드가 실행한 시퀀스 번호는 다른 노드보다 앞서 있을 수 있으며, 그 결과 선두 노드의 합의 데이터가 오랫동안 지워지지 않아 과도한 메모리 사용 문제가 발생하고 고수위 및 저수위 기능이 저하됩니다. 클러스터의 전체 실행 속도를 제한하기 위해 노드의 합의 데이터 크기가 제한됩니다.
▲보기 변경
텍스트
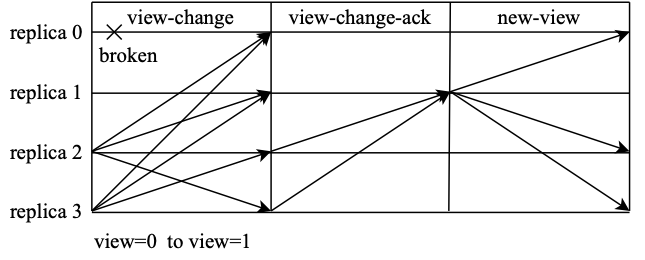
보기 변경은 마스터 노드가 시간 초과되어 응답하지 않거나 슬레이브 노드가 집합적으로 마스터 노드가 문제 노드라고 믿을 때 트리거됩니다. 뷰 변경이 완료되면 뷰 번호가 1씩 증가한 후 마스터 노드가 다음 노드로 전환됩니다. 그림과 같이 노드 0에서 예외가 발생하여 보기 변경 프로세스가 트리거되고 변경이 완료되면 노드 1이 새로운 기본 노드가 됩니다.
뷰 변경이 발생하면 노드는 새로운 뷰 v+1에 능동적으로 진입하고 마스터 노드 전환을 요청하는 뷰 변경 메시지를 브로드캐스트합니다. 이 시점에서 합의 클러스터는 이전 보기에서 합의를 완료한 요청이 새 보기에서 유지될 수 있는지 확인해야 합니다. 따라서 뷰 변경 요청에서는 일반적으로 이전 뷰에 합의 로그의 일부를 추가해야 하며 노드에서 브로드캐스트하는 요청은
i는 발신자 노드의 ID입니다.
v+1은 요청이 들어가는 새 보기를 나타냅니다.
h는 현재 노드의 최신 안정적인 체크포인트 높이입니다.
같은 방식으로 저장하면 현재 노드가 시퀀스 번호 n과 다이제스트 d로 체크포인트 검사를 수행하고 해당 합의 메시지를 전송했음을 의미합니다.
같은 방식으로 저장하면 뷰 v에서 요약이 d이고 시퀀스 번호가 n인 요청이 준비 상태에 진입했음을 의미합니다. 요청이 준비 상태에 도달했으므로 최소 2f+1개의 노드가 요청을 소유하고 승인하며 일관성 확인은 커밋 단계에서만 완료할 수 있음을 의미합니다. 새 시퀀스 번호를 할당하지 않고 원래 시퀀스 번호를 직접 사용합니다.
보관 방법. 요청이 사전 준비 상태에 진입했으므로 현재 노드에서 요청을 승인했음을 의미합니다.
그러나 다른 노드에서 보낸 view-change 메시지를 수신한 후 view v+1에 해당하는 새로운 기본 노드 P는 View-change 메시지가 Byzantine 노드에서 전송되었는지 여부를 확인할 수 없으며 올바른 메시지를 사용해야 함을 보장할 수 없습니다. 의사 결정을 위해. PBFT는 모든 노드가 view-change-ack 메시지를 통해 수신한 모든 view-change 메시지를 확인하고 확인한 후 확인된 결과를 P로 전송합니다. 마스터 노드 P는 view-change-ack 메시지를 세고 어떤 view-change가 올바르고 비잔틴 노드에서 보낸 것인지 식별할 수 있습니다.
노드가 보기 변경 메시지를 확인하면 그 안에 있는 P 및 Q 집합을 확인하고 집합의 요청 메시지는 보기 v보다 작거나 같아야 합니다. 요구 사항이 충족되면 보기 변경 -ack 메시지가 전송됩니다
i는 ack 메시지를 보낸 노드 ID입니다.
j는 확인할 보기 변경 메시지의 발신자 ID입니다.
d는 확인할 보기 변경 메시지의 다이제스트입니다.
일반 메시지 브로드캐스트와 달리 디지털 서명은 더 이상 메시지 발신자를 식별하는 데 사용되지 않지만 세션 키는 현재 노드와 마스터 노드 간의 통신 신뢰도를 보장하여 마스터 노드를 돕습니다. 보기 변경 메시지의 신뢰성을 판단합니다.
새로운 기본 노드 P는 확인된 올바른 보기 변경 메시지를 저장하기 위해 집합 S를 유지합니다. P가 view-change 메시지와 총 2f-1개의 해당 view-change-ack 메시지를 획득하면 이 view-change 메시지를 세트 S에 추가합니다. 집합 S의 크기가 2f+1에 도달하면 보기 변경을 시작하기에 충분한 비비잔틴 노드가 있음을 증명합니다. 마스터 노드 P는 새로운 보기 메시지를 생성하고 수신된 보기 변경 메시지에 따라 브로드캐스트합니다.
즉, 노드 i가 보낸 뷰 변경 메시지의 다이제스트는 d이며, 이는 집합 S의 메시지에 해당하며 다른 노드는 집합의 다이제스트와 노드 ID를 사용하여 뷰 변경의 적법성을 확인할 수 있습니다.
X: 안정적인 체크포인트와 새 보기를 선택하기 위한 요청을 포함합니다. 새로운 기본 노드 P는 세트 내 S의 뷰 변경 메시지에 따라 계산하고, C, P, Q 세트에 따라 최대 안정 체크포인트와 새 뷰에서 유지해야 하는 요청을 결정하고, 그 중에서 구체적인 선별 과정이 비교적 번거롭기 때문에 관심 있는 독자는 원문[6]을 참고할 수 있다.
▲개선공간과 RBFT
RBFT(Robust Byzantine Fault Tolerance)는 기업 수준의 제휴 체인 플랫폼을 위해 PBFT를 기반으로 Qulian Technology에서 개발한 매우 강력한 합의 알고리즘입니다. PBFT와 비교하여 합의 메시지 처리, 노드 상태 복구, 클러스터 동적 유지 및 기타 측면을 최적화하고 개선하여 RBFT 합의 알고리즘이 더 복잡하고 다양한 실제 시나리오에 대처할 수 있습니다.
1) 트레이딩 풀
RBFT를 포함한 많은 합의 알고리즘의 산업적 구현에서 독립적인 트랜잭션 풀 모듈이 설계되었습니다. 트랜잭션을 받은 후 트랜잭션 자체는 트랜잭션 풀에 저장되고 트랜잭션 풀을 통해 트랜잭션이 공유되므로 각 합의 노드가 공유 트랜잭션을 얻을 수 있습니다. 합의 과정에서는 트랜잭션 해시만 합의하면 됩니다.
대규모 트랜잭션을 처리할 때 트랜잭션 풀은 합의의 안정성이 크게 향상됩니다. 합의 알고리즘 자체에서 트랜잭션 풀을 분리하면 트랜잭션 중복 제거와 같은 트랜잭션 풀을 통해 더 많은 기능을 쉽게 구현할 수 있습니다.
2) 적극적인 회복
PBFT에서 노드가 체크포인트나 시점 변경을 통해 자신의 저수위가 뒤처진 것을 발견하면, 즉 안정적인 체크포인트가 뒤처지면 후행 노드는 해당 복구 프로세스를 트리거하여 안정적인 체크포인트 이전의 데이터를 가져옵니다. 이러한 역방향 복구 메커니즘에는 몇 가지 단점이 있습니다. 한편으로는 복구 프로세스의 트리거링이 수동적이며 역방향 복구는 체크포인트 프로세스 또는 트리거된 보기 변경이 완료될 때만 트리거될 수 있습니다. 역방향 노드, 만일 체크포인트가 자신의 안정적인 체크포인트 뒤에 있는 것이 발견되면, 역방향 노드는 최신 안정 체크포인트로만 복원할 수 있지만 체크포인트 뒤에 있는 합의 메시지를 얻을 수 없으며 진정으로 참여하지 못할 수 있습니다. 의견 일치.
RBFT에서는 활성 노드 복구 메커니즘을 설계했습니다. 한편으로는 지연된 노드가 더 빨리 복구되도록 복구 메커니즘을 능동적으로 트리거할 수 있습니다. 수위 간의 복구 메커니즘이 설정되어 후행 노드가 최신 합의 뉴스를 얻고 정상적인 합의 프로세스에 더 빨리 참여할 수 있습니다.
3) 클러스터 동적 유지 관리
엔지니어링에서 널리 사용되는 합의 알고리즘으로서 Raft의 중요한 장점 중 하나는 클러스터 구성원 변경을 동적으로 완료할 수 있다는 것입니다. 그러나 PBFT는 클러스터 구성원에 대한 동적 변경 체계를 제공하지 않으므로 실제 응용에는 충분하지 않습니다. RBFT에서는 클러스터 멤버를 동적으로 변경하는 방식을 설계하여 클러스터 전체를 중지하지 않고도 클러스터 멤버를 추가하거나 삭제할 수 있습니다.
노드를 추가하거나 삭제할 때 관리자는 노드를 운영하기 위한 제안을 생성하기 위해 트랜잭션을 클러스터에 보내고 다른 관리자의 투표를 기다리며 투표가 통과되면 제안을 생성한 관리자가 실행 제안 구성 트랜잭션을 전송합니다. 클러스터에 다시 연결되며 실행 구성 중에 클러스터가 변경됩니다.
합의 부분의 경우 제안 구성 트랜잭션을 처리하고 실행할 때 클러스터의 노드는 구성 변경 상태에 들어가고 다른 트랜잭션은 패키지되지 않습니다. 마스터 노드는 트랜잭션을 별도로 패키징하여 구성 패키지를 생성하고 구성 패키지에 동의합니다. 구성 패키지가 합의를 완료하면 실행되고 구성 블록이 생성됩니다. 수정된 구성 블록이 롤백되지 않도록 하기 위해 컨센서스 계층은 수정된 구성 패키지의 실행 결과를 기다리고 릴리스하기 전에 클러스터의 구성 패키지 높이에 대해 안정적인 체크포인트가 형성되었는지 확인합니다. 노드의 구성 상태 및 다른 트랜잭션을 계속 패키징합니다.
클러스터 구성원을 동적으로 변경하는 이 방법은 클러스터 구성 유지 관리를 보다 안정적이고 편리하게 만들고 더 많은 구성 정보를 동적으로 수정할 수 있는 가능성을 제공합니다.
저자 소개
저자 소개
FunChain 기술의 기본 플랫폼 부서의 합의 알고리즘 연구 그룹
참조
[1] Lamport L, Shostak R, Pease M. The Byzantine generals problem[M]//Concurrency: the Works of Leslie Lamport. 2019: 203-226.
[2] Castro M, Liskov B. Practical Byzantine fault tolerance[C]//OSDI.1999, 99(1999): 173-186.
[3] https://en.wikipedia.org/wiki/Quorum _ (distributed_computing)
[4] Owicki S, Lamport L. Proving liveness properties of concurrent programs[J]. ACM Transactions on Programming Languages and Systems (TOPLAS), 1982, 4(3): 455-495.
[5] Fred B. Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. ACM Comput. Surv., 22(4):299–319, 1990.
[6] Castro M, Liskov B. Practical Byzantine fault tolerance andproactive recovery[J]. ACM Transactions on Computer Systems (TOCS), 2002,20(4): 398-461.


