
ジェンセン・フアンGTC講演全文:推論時代の到来、ロブスターは新たなOSとなる
- 核心的な視点:NVIDIAはGTC 2026カンファレンスにおいて、チップ企業から「AIインフラストラクチャー&ファクトリー企業」への転換を説明し、「トークンファクトリー経済学」というビジネスロジックに基づき、2027年までに少なくとも1兆ドルの強力な需要見通しを示した。
- 重要な要素:
- 業績見通し:ジェンセン・フアンは、NVIDIAの2027年までの需要見通しは少なくとも1兆ドルであり、実際の需要はさらに高くなると考えており、この見通しが株価を一時的に4.3%以上押し上げたと述べた。
- トークンファクトリー経済学:将来のデータセンターはAIトークンを生産する「工場」であり、固定された電力制限の下で、ワット当たりのトークンスループットが最も高いシステムの生産コストが最も低く、収益を直接決定する。
- 技術的ブレークスルー:新世代AIコンピューティングシステム「Vera Rubin」は、エンドツーエンドの協調設計により、2年間でトークン生成速度を350倍向上させ、ムーアの法則による1.5倍の向上をはるかに上回った。
- エコシステムとソフトウェア革命:オープンソースプロジェクト「OpenClaw」は、エージェント時代の「オペレーティングシステム」と見なされており、ジェンセン・フアンはすべてのSaaS企業がAaaS(エージェント・アズ・ア・サービス)企業に転換すると断言した。
- 市場構造:NVIDIAのビジネスの60%は上位5大クラウドサービスプロバイダーから、40%は主権クラウド、企業、産業、ロボット、エッジコンピューティングなど広範な分野に分布しており、幅広い業界カバレッジを示している。
原文著者:鲍奕龍
原文ソース:ウォールストリート・ジャーナル

2026年3月16日、NVIDIA GTC 2026カンファレンスが正式に開幕し、NVIDIAの創業者兼CEOであるジェンスン・フアンが基調講演を行いました。
この「AI業界の年間巡礼」と見なされる大会で、ジェンスン・フアンはNVIDIAが「チップ企業」から「AIインフラストラクチャーおよびファクトリー企業」への変貌を説明しました。市場が最も関心を持つ業績の持続性と成長余地の問題に対し、ジェンスン・フアンは将来の成長を駆動する根本的なビジネスロジック——「トークンファクトリー経済学」を詳細に解説しました。
業績見通しは極めて楽観的、「2027年には少なくとも1兆ドルの需要」
過去2年間、世界のAI計算需要は指数関数的に爆発しました。大規模モデルが「知覚」、「生成」から「推論」と「行動(タスク実行)」へと進化するにつれ、計算能力の消費量が急激に上昇しています。市場が高い関心を寄せる注文と売上高の上限に対して、ジェンスン・フアンは非常に強力な見通しを示しました。
ジェンスン・フアンは講演で率直に述べました:
昨年の今頃、私はBlackwellとRubinの2026年までの需要について、5000億ドルの高い確信度があると言いました。今、ここで、私は2027年までに少なくとも1兆ドルの需要(at least $1 trillion)を見ています。

ジェンスン・フアンの1兆ドル予想は一時的にNVIDIA株価を4.3%以上上昇させました。
それだけでなく、彼はこの数字についてさらに補足しました:
これは合理的ですか?これから話すことです。実際、私たちは供給が追いつかなくなるでしょう。私は、実際の計算需要はこれよりもはるかに高いと確信しています。
ジェンスン・フアンは、現在のNVIDIAシステムが世界で「最もコスト効率の良いインフラストラクチャー」であることを証明したと指摘しました。NVIDIAがほぼすべての分野のAIモデルを実行できるため、この汎用性により顧客が投入するこの1兆ドルが十分に活用され、長いライフサイクルを維持できると述べました。
現在、NVIDIAのビジネスの60%は上位5社の超大規模クラウドサービスプロバイダーから、残りの40%は主権クラウド、企業、産業、ロボット、エッジコンピューティングなど幅広い分野に分布しています。
トークンファクトリー経済学、ワットあたり性能が商業の命運を決定
この1兆ドルの需要の合理性を説明するため、ジェンスン・フアンは世界中の企業CEOに新しいビジネス思考を提示しました。彼は、将来のデータセンターはもはやファイルを保存する倉庫ではなく、トークン(AIが生成する基本単位)を生産する「ファクトリー」であると指摘しました。

ジェンスン・フアンは強調しました:
すべてのデータセンター、すべてのファクトリーは、定義上、電力によって制限されています。1GW(ギガワット)のファクトリーが2GWになることは決してありません。これは物理と原子の法則です。固定された電力の下で、誰がワットあたりのトークンスループットが最も高いか、それが生産コストを最も低くします。
ジェンスン・フアンは将来のAIサービスを5つのビジネス階層に分類しました:
- 無料層(高スループット、低速度)
- 中級層(~100万トークンあたり3ドル)
- 高級層(~100万トークンあたり6ドル)
- 高速層(~100万トークンあたり45ドル)
- 超高速層(~100万トークンあたり150ドル)
彼は、モデルがますます大きくなり、コンテキストが長くなるにつれ、AIはより賢くなりますが、トークンの生成速度は低下すると指摘しました。ジェンスン・フアンは述べました:
このトークンファクトリーでは、あなたのスループットとトークン生成速度が、来年の正確な収入に直接変換されます。
ジェンスン・フアンは、NVIDIAのアーキテクチャが顧客が無料層で非常に高いスループットを実現できる一方で、最も価値の高い推論階層では、性能を驚異的な35倍向上させることができると強調しました。
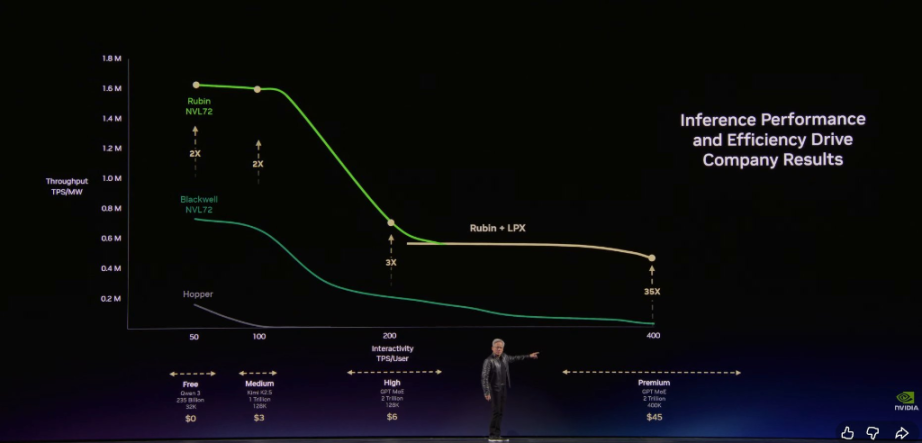
Vera Rubinは2年で350倍の加速を実現、Groqが極速推論を補完
この物理的限界の制約の下で、NVIDIAは史上最も複雑なAI計算システムであるVera Rubinを紹介しました。ジェンスン・フアンは述べました:
以前Hopperについて話すとき、私はチップを1枚持ち上げました、それは可愛らしいものでした。しかしVera Rubinについて言えば、皆が考えるのはシステム全体です。この100%液体冷却、従来のケーブルを完全に排除したシステムでは、過去に2日かけて設置していたラックが、今ではわずか2時間で済みます。
ジェンスン・フアンは、極限のエンドツーエンドのソフトウェア・ハードウェア協調設計により、Vera Rubinは同じ1GWデータセンター内で驚異的なデータ飛躍を生み出したと指摘しました:
わずか2年の間に、私たちはトークンの生成速度を2200万から7億に引き上げ、350倍の成長を実現しました。ムーアの法則は同時期に約1.5倍の向上しかもたらせません。
極速推論(例:1000トークン/秒)条件下での帯域幅ボトルネックを解決するため、NVIDIAは買収した会社Groqを統合する最終的なソリューションを示しました:非対称分離推論。ジェンスン・フアンは説明しました:
これら2つのプロセッサの特性は全く異なります。Groqチップは500MBのSRAMを持ち、一方のRubinチップは288GBのメモリを持っています。

ジェンスン・フアンは、NVIDIAがDynamoソフトウェアシステムを通じて、膨大な計算とビデオメモリを必要とする「事前充填(Pre-fill)」段階をVera Rubinに任せ、遅延に極度に敏感な「デコード」段階をGroqに任せると指摘しました。ジェンスン・フアンはまた、企業の計算能力構成についてアドバイスをしました:
もしあなたの仕事が主に高スループットであれば、100% Vera Rubinを使用してください。もし大量の高価値なプログラミングレベルのトークン生成ニーズがあれば、データセンター規模の25%をGroqに割り当ててください。
明らかになったところによると、サムスンが製造を請け負うGroq LP30チップは量産中で、第3四半期に出荷が予定されており、最初のVera RubinラックはすでにマイクロソフトAzureクラウド上で稼働しています。
さらに、光相互接続技術について、ジェンスン・フアンは世界初の量産型共封入光学(CPO)スイッチSpectrum Xを展示し、市場の「銅退光進」の路線争いを鎮めました:
私たちはより多くの銅ケーブル生産能力、より多くの光チップ生産能力、より多くのCPO生産能力を必要としています。
Agentが従来のSaaSを終わらせ、「年俸+トークン」がシリコンバレーの標準に
ハードウェアの障壁に加えて、ジェンスン・フアンは多くの紙幅をAIソフトウェアとエコシステムの革命、特にAgent(インテリジェントエージェント)の爆発的普及に割きました。
彼はオープンソースプロジェクトOpenClawを「人類史上最も人気のあるオープンソースプロジェクト」と表現し、わずか数週間でLinuxが過去30年間に達成した成果を超えたと述べました。ジェンスン・フアンは率直に、OpenClawは本質的にAgentコンピュータの「オペレーティングシステム」であると述べました。
ジェンスン・フアンは断言しました:
すべてのSaaS(サービスとしてのソフトウェア)企業はAaaS(Agent-as-a-Service、サービスとしてのエージェント)企業になります。間違いなく、機密データへのアクセスとコード実行能力を備えたこのようなインテリジェントエージェントを安全に展開するために、NVIDIAは企業向けのNeMo Clawリファレンス設計を発表し、ポリシーエンジンとプライバシールーターを追加しました。
一般の職場人にとって、この変革は同様に目前に迫っています。ジェンスン・フアンは将来の職場の新しい形態を描きました:
将来、私たちの会社のすべてのエンジニアは年間トークン予算を必要とします。彼らの基本年俸は数十万ドルかもしれませんが、私はそれに加えて約半分の金額をトークン割り当てとして彼らに与え、10倍の効率向上を実現させます。これはすでにシリコンバレーの新しい採用条件になっています:あなたのオファーにはどれだけのトークンが付いていますか?
講演の最後に、ジェンスン・フアンは次世代計算アーキテクチャFeynmanを「予告」しました。それは初めて銅線とCPOの共同水平スケーリングを実現します。さらに想像をかき立てるのは、NVIDIAが宇宙に展開するデータセンターコンピュータ「Vera Rubin Space-1」を開発中であり、AI計算能力が地球の外へと拡張する想像の余地を完全に開きました。
ジェンスン・フアン GTC 2026 講演全文、全文翻訳は以下の通り(AIツール補助):
司会者: NVIDIA創業者兼CEOジェンスン・フアンの登場を歓迎します。
ジェンスン・フアン、創業者兼CEO:
GTCへようこそ。これは技術カンファレンスであることを思い出させてください。こんなに多くの人が早朝から列をなして入場し、ここにいる皆さんを見ることができて、非常に嬉しく思います。
GTCでは、私たちは3つの主要テーマに焦点を当てます:技術、プラットフォーム、エコシステム。NVIDIAは現在3つの主要プラットフォームを持っています:CUDA-Xプラットフォーム、システムプラットフォーム、そして最新のAIファクトリープラットフォームです。
正式に始める前に、私たちのウォームアップセッション司会者——Convictionのサラ・グオ、シーコイヤ・キャピタルのアルフレッド・リン(NVIDIAの最初のベンチャーキャピタリスト)、そしてNVIDIAの最初の主要機関投資家であるギャビン・ベイカーに感謝したいと思います。この3人は技術に対する深い洞察を持ち、技術エコシステム全体に非常に広い影響力を持っています。もちろん、今日私が個人的に招待したすべてのVIPゲストにも感謝します。このオールスターチームに感謝します。
私はまた、今日出席しているすべての企業にも感謝します。NVIDIAはプラットフォーム企業であり、私たちは技術、プラットフォーム、豊富なエコシステムを持っています。今日出席している企業は、100兆ドル規模の産業のほぼすべての参加者を代表しており、合計450社がこのイベントをスポンサーしています。心から感謝します。
このカンファレンスでは、1000の技術フォーラム、2000人の講演者を設け、人工知能の「五層ケーキ」アーキテクチャのすべての階層——土地、電力、機械室などのインフラストラクチャーから、チップ、プラットフォーム、モデル、そして最終的に業界全体を飛躍させるさまざまなアプリケーションまでをカバーします。
CUDA:20年の技術蓄積
すべての始まりは、ここにあります。今年はCUDA誕生20周年です。
20年間、私たちは常にこのアーキテクチャの研究開発に取り組んできました。CUDAは革命的な発明です——SIMT(単一命令多重スレッド)技術により、開発者はスカラーコードでプログラムを記述し、それをマルチスレッドアプリケーションに拡張することができ、以前のSIMDアーキテクチャよりもはるかにプログラミングが容易です。私たちは最近、開発者がテンソルコア(Tensor Core)や現代の人工知能が依存するさまざまな数学演算構造をより簡単にプログラミングできるようにするTiles機能を追加しました。現在、CUDAは数千のツール、コンパイラ、フレームワーク、ライブラリを持ち、オープンソースコミュニティには数十万の公開プロジェクトが存在し、あらゆる技術エコシステムに深く統合されています。
このチャートは、NVIDIAの100%の戦略的ロジックを明らかにしており、私は最初からこのスライドを話し続けています。その中で最も実現が難しく、最も核心的な要素は、チャートの下部にある「インストールベース」です。20年を経て、私たちは世界中で数億のCUDAを実行するGPUと計算システムを蓄積してきました。
私たちのGPUはすべてのクラウドプラットフォームをカバーし、ほぼすべてのコンピューターメーカーと業界にサービスを提供しています。CUDAの膨大なインストールベースこそが、このフライホイールが加速し続ける根本的な理由です。インストールベースが開発者を引き付け、開発者が新しいアルゴリズムを創造しブレークスルーを達成し、ブレークスルーが全く新しい市場を生み出し、新しい市場が新しいエコシステムを形成し、より多くの企業を引き付け、それによってインストールベースが拡大します——このフライホイールは加速し続けています。
NVIDIAライブラリのダウンロード数は驚異的な速度で成長しており、規模が大きく、成長速度が向上し続けています。このフライホイールにより、私たちの計算プラットフォームは膨大なアプリケーションと次々と現れる新しいブレークスルーをサポートすることができます。
さらに重要なのは、それはこれらのインフラストラクチャーに非常に長い使用寿命を与えることです。理由は明らかです:NVIDIA CUDA上で


