
ロブスターの11の重要な質問:最も分かりやすいOpenClawの原理解説
- 核心的な視点:本稿はOpenClawを例に、AIエージェントの核心的な動作原理を平易に解説し、その「シェル」フレームワークがどのように大規模言語モデルに記憶、ツール呼び出し、自発的実行などの能力を与えるかを明らかにし、強力な機能に伴う顕著なセキュリティリスクを強調しています。
- 重要な要素:
- 大規模モデルの本質は確率予測器であり、記憶と知覚を持たない。OpenClawは、設定、履歴、ツール結果を含む超長プロンプトを毎回の対話時に連結することで「記憶」をシミュレートする。
- ツール呼び出しはフレームワークとモデルの「掛け合い」である:モデルは約束された形式でテキスト命令を出力し、ローカルで実行されるOpenClawプログラムがそれを認識して具体的な操作を実行し、結果をモデルにフィードバックする。
- コンテキストウィンドウの制限に対処するため、OpenClawはサブエージェントメカニズムを導入し、複雑なタスクを分割して実行し、要約結果のみをメインエージェントに返すことで、トークンを節約し効率を向上させる。
- ハートビートメカニズムにより、エージェントは定期的にタスクを自発的にチェックして実行できるようになり、「アラーム設定」式の待機と組み合わせることで、受動的応答から能動的作業への転換を実現している。
- OpenClawはローカルで高い権限を持ち、暴走(例:命令を無視してメールを削除)やプロンプトインジェクション(ユーザー入力と悪意ある入力を区別できない)などのセキュリティリスクが存在するため、物理的に隔離された環境でのデプロイが推奨される。
- OpenClawは過去30日間でOpenRouter上で8.69兆トークンを消費し、ヘビーユーザーの月額費用は約7千元に達する可能性がある。この高いコストは、毎回の対話で膨大なコンテキストプロンプトを処理する必要があることに起因する。
元動画提供 | Youtuber:Hung-yi Lee
編集 | Odaily Suzz

OpenClaw(オープンクロー)がすごく流行っています。
このAI学習ブームの中で、AI(さらにはインターネットさえ)に触れたことのない多くの初心者ユーザーが、FOMO(取り残される恐怖)を感じながら学習、インストール、体験しています。
皆さんはもう多くの実用的なチュートリアルを見たことでしょうが、ここ数日YouTubeで話題になっているこの動画は、私が今まで見た中で最も分かりやすいAI Agentの原理説明です。彼は人間を比喩として使い、「おばあちゃんでも理解できる言葉」で、私たちが自然に疑問に思うこれらの問題を詳しく説明しています:AIの記憶力の形成、お金がかかる理由、ツール呼び出しの実現とプロセス、親エージェントから子エージェントを生成する必要性と境界、自発的に仕事をする設計、最も重要な安全な使用法。
すでにポケットからお金を出して、友達に自慢している人もいるかもしれませんが、これが実際にどう動いているのかと聞かれたら、このHung-yi Leeの動画を基に整理した重要な11の質問を見れば、あなたも(知識をひけらかして)スラスラと答えられるようになるでしょう。
一、脳の真実:黒い箱の中に住む「文字しりとり名人」
OpenClaw(オープンクロー)が実際に何をしているのかを理解するには、まず多くの人がAIに対して抱いている幻想を打ち破る必要があります。
多くの人が初めてAIとチャットするとき、強い錯覚を抱きます:向こう側に自分を本当に理解している誰かが座っていると。それは前回何を話したかを覚えていて、話題を続けることができ、さらには自分の好みや態度さえ持っているように見えます。しかし、真実はそれほどロマンチックなものではありません。
OpenClawの背後にある大規模言語モデル——Claude、GPT、DeepSeekのどれであっても——本質的には確率予測器です。その能力全体は、非常に単純な一つのことに要約できます:与えられた一連の文字から、次に最も現れそうな文字を予測する。まるで超優秀な「文字しりとり」プレイヤーのように、あなたが始まりを与えると、非常に自然に続きを考え、流暢に続けるので、あなたはそれが「あなたを理解している」と感じるのです。
しかし、実際には何も理解していません。目がなく、あなたの画面でどのソフトウェアが開いているか見えません。耳がなく、あなたの周囲の環境音を聞きません。カレンダーがなく、今日が何曜日か知りません。最も重要なのは、記憶がないことです——新しいリクエストは毎回「人生初めて」であり、3秒前にあなたと何を話したか全く覚えていません。それは完全に閉ざされた黒い箱の中に住んでいて、唯一の入力は文字、唯一の出力も文字です。

だからこそ、OpenClawの価値があるのです:それは大規模言語モデルそのものではなく、大規模言語モデルの外側に被さっている「殻」です。それは、文字しりとりしかできない予測器を、あなたを覚えていて、実際に手を動かして働き、さらには自発的に仕事を見つける「デジタル従業員」に変える責任を負っています。OpenClawの創設者であるPeter Steinberger自身も言っています、OpenClawはただの殻であり、実際に働いているのはあなたが接続した大規模言語モデルだと。しかし、まさにこの殻が、あなたのAI体験が「チャットボットと気まずい会話をする」のか、それとも「本当のパーソナルアシスタントを持つ」のかを決定するのです。
Q1:モデル自体は「重度の健忘症」で、毎回リクエストを処理するのはゼロからです。では、どうやって「前回何を話したか覚えている」、「自分がどんな役割を演じるべきか知っている」のでしょうか?
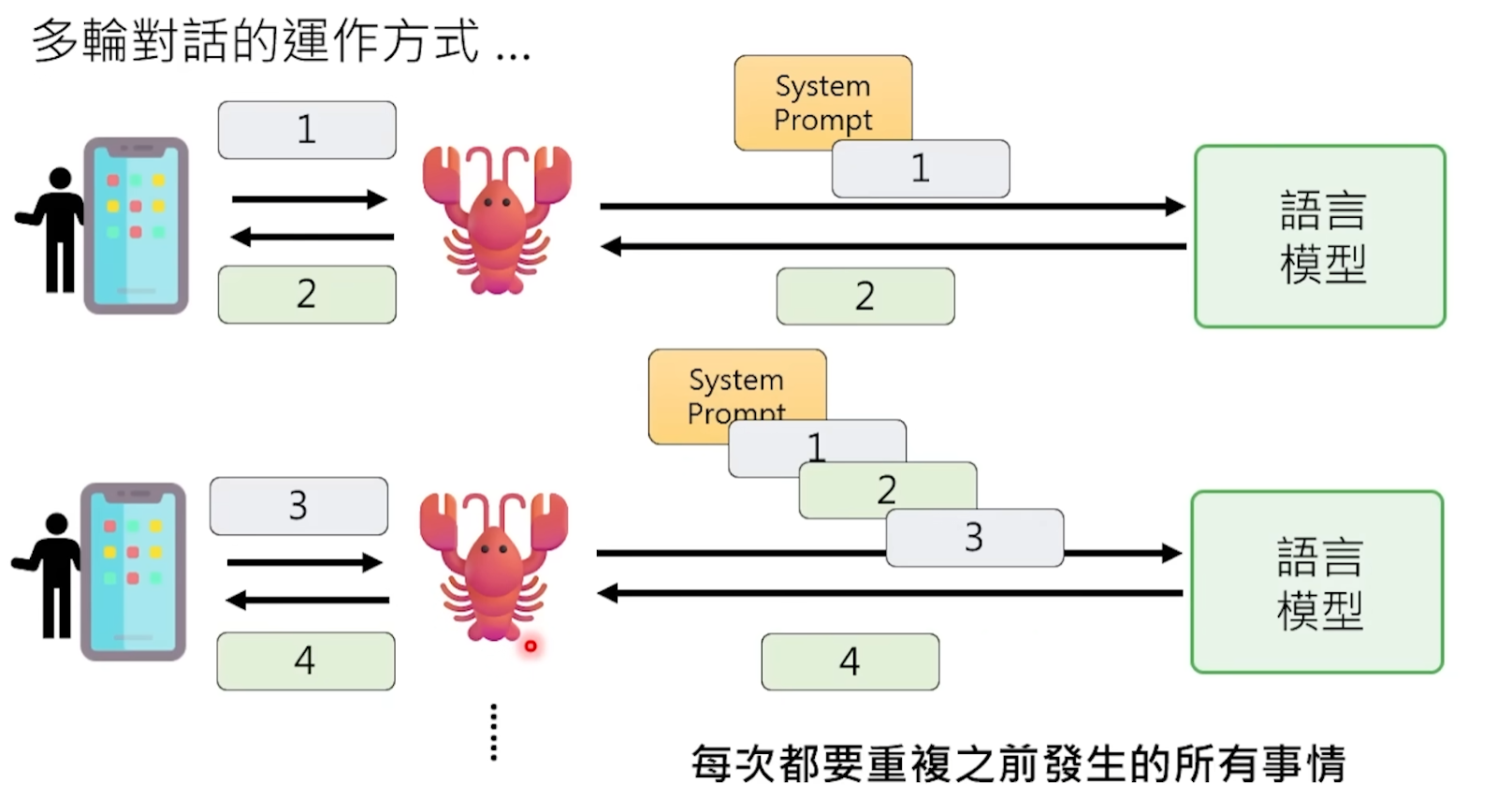
OpenClawは裏で大量の「メモ渡し」作業を行っています。
毎回あなたのメッセージをモデルに送る前に、OpenClawはバックグラウンドで黙々と一つの大規模なプロジェクトを完了します——モデルが「知る必要がある」すべての情報を一つの巨大なプロンプトに結合し、まとめてモデルに詰め込むのです。
このプロンプトには何が含まれているのでしょうか?まずはOpenClawワークスペース内の「魂の三種の神器」——AGENTS.md、SOUL.md、USER.mdの3つのファイルで、このOpenClawが誰なのか、その性格は何か、その主人は誰なのか、主人にはどんな好みや仕事の習慣があるかが書かれています。そしてあなたとそれまでのすべての会話記録が、一字一句そのまま後ろに付け加えられます。さらに、以前呼び出したツールが返した結果、現在の日付や時間などの環境情報も加わります。
モデルはこの数万字に及ぶ可能性のあるテキストの山を読み終えた後、初めて「自分が誰なのか、以前あなたと何を話したのか」を「思い出します」。そして、これらすべてのコンテキストに基づいて、次の返答を予測します。
言い換えれば、モデルの「記憶」は実は一種のトリックです——それは毎回最初からすべてのチャット履歴を読み直すことで「記憶効果を偽装している」のです。まるで健忘症の患者が毎回会う前に日記帳を最初から最後まで読み直し、あなたと話すときには何でも覚えているように見えるが、実際には毎回あなたを再認識しているようなものです。
OpenClawはさらに一歩進んでいます:永続化された「長期記憶」システムを持っており、重要な情報をワークスペースのファイルに書き込みます。これにより、たとえ会話履歴がクリアされても、それらの重要な情報は失われません。あなたが杭州に住んでいることを言ったら、次回はあなたに地元のAIイベントを自発的にプッシュするかもしれません——それは「覚えている」からではなく、この情報がファイルに書き込まれ、次回プロンプトを組み立てるときに含まれるからです。
Q2:なぜOpenClawを飼うのはこんなにお金がかかるのか?
上記のプロンプトメカニズムを理解すれば、多くのユーザーを悩ませるこの問題を理解できるでしょう。
毎回のインタラクションで、モデルが処理するのはあなたが今送った一言だけではありません。それは魂の設定、すべての履歴会話、すべてのツール出力を含むプロンプト全体を処理する必要があります。これらの内容はトークン単位で課金され、1トークンは約1漢字または0.5英単語に相当します。
たとえあなたが「こんにちは」と一言送っただけでも、OpenClawは裏で5000トークンのプロンプトを組み立てているかもしれません。なぜなら、すべての背景設定ファイルを持っていかなければならないからです。この「こんにちは」に対して実際に支払うお金は、2トークンの処理料ではなく、5000トークンの処理料です。
そして忘れてはいけません、OpenClawにはハートビート(心拍)メカニズムがあり、数十分ごとに自動的にモデルをポークします。たとえあなたが何も言わなくても、トークンは継続的に消費されています。統計によると、OpenClawは過去30日間でOpenRouter上の呼び出し量が世界一で、合計8.69兆トークンを消費しました。ヘビーユーザーは1ヶ月で約1億トークンが必要で、費用は約7000元です。OpenClawが制御不能になった場合、一気に数億トークンを消費し、数万元の請求書を発生させた人さえいます。
毎回のインタラクションは、モデルに「小説全体を再び読ませる」ことに相当します。これがOpenClawを飼うとお金がかかる根本的な理由です。
二、身体とツール:「話すだけ」のモデルにどうやって「手を動かす」ことをさせるか?
普通のチャットボット、例えばウェブ版のChatGPTは、本質的には「口だけ」です。あなたが「このPDFを私のメールに送って」と頼んでも、それは操作手順を教えるだけで、自分ではできません。デスクトップ上のファイルを整理してほしいと頼んでも、それはチュートリアルをくれるだけです。口だけで、手を動かしません。
OpenClawとそれらの本質的な違いはここにあります。コミュニティで最も広く流布されている言葉で言えば:ChatGPTは軍師で、計画を出すだけ。OpenClawは工兵で、直接実行する。「MITのPythonコースをダウンロードして」と言えば、普通のAIはリンクをくれますが、OpenClawは自動的にブラウザを開き、リソースを見つけ、ダウンロードし、あなたのデスクトップに置きます。
しかし、ここで修正すべき重要な認識があります:モデル自体はコンピュータを操作する能力を本当に獲得したわけではありません。それは依然として文字を出力するだけです。本当の魔法は、OpenClawという「殻」の上で起こります。
Q3:大規模言語モデルは明らかに文字を出力するだけなのに、「ツール呼び出し」は実際にはどう実現されているのか?
大規模言語モデルには、ツールを直接呼び出す能力は一切ありません。ファイルを読めない、リクエストを送れない、ブラウザを操作できない——それができるのはたった一つのこと:一連の文字を出力すること。いわゆる「ツール呼び出し」は、本質的にモデルとフレームワークが協力して演じる二人芝居です。
具体的には、OpenClawはプロンプトの中で事前にモデルに伝えます:「あなたが何かアクションを実行する必要があるときは、以下のフォーマットで特殊なテキストを出力してください。」このフォーマットは通常、構造化された文字列で、例えばTool Callマーカーを含むJSONで、どのツールを呼び出したいのか、どんなパラメータを渡すのかが明記されています。
モデルはそれに従います——「今ファイルを読む必要がある」と判断したとき、それは実際に読みに行くのではなく、出力の中に次のような文を書きます:
[Tool Call] Read("/Users/あなた/Desktop/report.txt")
これが一行の純粋なテキストで、何の魔法もありません。

そしてOpenClawは外でモデルのすべての出力を監視しています。出力の中にこの特定のフォーマットの文字列が含まれているのを検出すると、OpenClawは「ああ、モデルはReadツールを使いたがっている」と知ります。そこでOpenClawは自分でこの操作を実行します——オペレーティングシステムのインターフェースを呼び出し、ファイルの内容を読み取ります——そしてその結果を新しいテキストとしてプロンプトに戻し、モデルに続きを処理させます。
この過程全体で、モデル自身はツールが実際に実行されたかどうか、実行結果が何かを全く知りません。それはただ「フォーマットに合った言葉を言った」だけで、次の会話ラウンドで結果を見るのを待っているだけです。すべての面倒な仕事は、あなたのコンピュータ上で動いているOpenClawというプログラムが裏でやっています。
だからこそ、OpenClawは「殻」だと言われるのです——モデルは脳、OpenClawは手足。脳が「あのコップを取れ」と言い、手が伸びて取り、触感を脳にフィードバックする。脳自体は一度もコップに触れたことがない。

Q4:具体的にOpenClawにおいて、一回の完全なツール呼び出しプロセスはどのようなものか?
実際のシナリオを使って全プロセスを追ってみましょう。あなたが飛書(Feishu)であなたのOpenClawに言ったとします:「デスクトップ上のreport.txtファイルを読み取って要約して。」
第一歩、OpenClawはあなたのメッセージをモデルに送る前に、すでにプロンプトの中に「ツール使用説明書」を詰め込んでいます。この説明書は構造化されたフォーマットでモデルに伝えます:あなたは以下のツールを使うことができ、各ツールにはどんなパラメータが必要で、どんな結果が返ってくるか。例えばReadツールはファイルを読み取ることができ、Shellツールはコマンドライン指令を実行でき、Browserツールはブラウザを操作できます。
第二歩、モデルはあなたのリクエストを見て、ツール説明書からReadツールを使う必要があると判断し、出力の中で約束されたフォーマットに従ってTool Call文字列を書き出し、ツール名とファイルパスを含めます。
第三歩、OpenClawはこの特殊なフォーマットの文字列を認識し、あなたのコンピュータ上で実際にファイル読み取り操作を実行し、report.txtの実際の内容を取得します。ここで強調しておきます:OpenClawはあなたのローカルコンピュータ上で動いています。これがChatGPTとの最大の違いの一つです。あなたのコンピュータ上のファイルシステムに直接アクセスできます。
第四歩、OpenClawは読み取ったファイルの内容を新しいメッセージとしてプロンプトに戻し、更新された完全なプロンプトを再びモデルに送ります。モデルはファイルの内容を読み、ようやくあなたに要約をまとめることができます。OpenClawは飛書に接続されているので、この要約は直接飛書メッセージとしてあなたの携帯電話にプッシュされます——あなたはちょうど地下鉄に乗っていて、携帯電話を取り出すと、仕事はもう終わっているかもしれません。
Peter Steinbergerは、多くの人が見落としている巨大な利点について言及しています:OpenClawはあなたのコンピュータ上で動いているので、認証問題が直接回避されます。それはあなたのブラウザ、あなたがすでにログインしているアカウント、あなたが持っているすべての権限を使用します。OAuthを申請する必要も、どのプラットフォームとも協力する必要もありません。あるユーザーは、自分のOpenClawがあるタスクにAPI Keyが必要だと気づき、自動的にブラウザを開き、Google Cloud Consoleに入り、自分でOAuthを設定し、新しいトークンを取得したと共有しています。これがローカル実行


