
Coinbaseによる仮想通貨×AIの蜃気楼かどうかの徹底分析
原題:Cryptos AI Mirage
原著者: David Han、Coinbase Institutional Research Analyst
オリジナル編集: DAOSquare

簡単な概要
分散型暗号人工知能 (Crypto-AI) アプリケーションは、短期から中期的には、その導入を妨げる可能性のある多くの逆風に直面しています。しかし、暗号通貨と人工知能をめぐる建設的な物語は、しばらくの間、取引の物語を維持する可能性があります。
重要なポイント
人工知能 (AI) と暗号通貨の接点は非常に幅広いですが、それを深く理解している人はほとんどいません。私たちは、交差点にあるさまざまなサブフィールドには、それぞれ異なる機会と開発サイクルがあると信じています。
私たちは一般に、人工知能製品については、分散化自体の競争上の優位性だけでは十分ではなく、他の重要な分野で集中化された競合他社との機能的同等性を維持する必要があると考えています。
私たちの逆張りの見方は、市場が AI 業界に広く注目しているため、多くの AI トークンの潜在的な価値が誇張されている可能性があり、多くの AI トークンには短期から中期的に持続可能な需要要因が欠けている可能性があるというものです。
近年、人工知能(特に生成人工知能)の継続的な進歩により、人工知能業界に大きな注目が集まり、その間に暗号プロジェクトの機会が提供されています。私たちは以前、2023年6月のレポートで業界のいくつかの可能性について取り上げ、クリプトの全体的な資本配分から判断すると、人工知能分野が過小評価されているように見えると指摘しました。それ以来、暗号人工知能の分野は急速に発展し始めました。現時点で、私たちは、その広範な普及を妨げる可能性のある実際的な課題のいくつかを強調することが重要であると感じています。
AI の急速な変化により、一部の暗号プラットフォームの大胆な主張に対して、その独自のポジショニングが業界全体を混乱させ、ほとんどの AI トークンの長期的かつ持続可能な価値の蓄積が不確実になるという大胆な主張に注意が払われています。特に、これは固定トークンを使用するプロジェクトに当てはまります。モデル。むしろ、広範な市場競争や規制要因を考慮すると、AI の新たなトレンドによって、仮想通貨ベースのイノベーションの採用が実際には困難になる可能性があると私たちは考えています。
そうは言っても、AI と暗号通貨の接点は幅広く、多様な機会が秘められていると私たちは考えています。特定のサブセクターでは導入が早くなる可能性がありますが、これらの分野の多くには取引可能なトークンがありません。しかし、これが投資家の意欲を弱めているわけではないようだ。 AI関連の暗号トークンのパフォーマンスはAI市場の熱狂によって動かされており、ビットコインが安く取引される日であっても、そのポジティブな価格行動をサポートできることがわかりました。したがって、多くの AI 関連トークンは、AI の進歩を表すものとして今後も取引される可能性が高いと考えられます。
人工知能の主な動向
私たちの意見では、AI 分野 (暗号 AI 製品に関連する) における最も重要なトレンドの 1 つは、オープンソース モデルを中心とした文化の継続です。 AI コミュニティのコラボレーション プラットフォームである Hugging Face では、研究者やユーザーが実行して微調整できる 530,000 を超えるモデルが公開されています。 AI コラボレーションにおける Hugging Face の役割は、コードのホスティングに Github に依存したり、コミュニティ管理に Discord に依存したりすることと何ら変わりません (どちらも暗号通貨で広く使用されています)。重大な不始末がない限り、この状況が近い将来変わる可能性は低いと考えています。
Hugging Face で利用できるモデルは、大規模言語モデル (LLM) から生成画像およびビデオ モデルまで多岐にわたり、OpenAI、Meta、Google などの主要な業界プレーヤーや独立系開発者から提供されています。一部のオープン ソース言語モデルは、(同等の出力品質を維持しながら) スループットの点で最先端のクローズド ソース モデルよりも優れたパフォーマンス上の利点を備えているため、オープン ソース モデルと商用モデルの間である程度の競争が保証されます (図 1 を参照) )。重要なのは、この活気に満ちたオープンソースのエコシステムが、競争の激しい商業部門と組み合わされて、パフォーマンスの低いモデルが競争から追い出される業界を促進していると私たちが信じていることです。
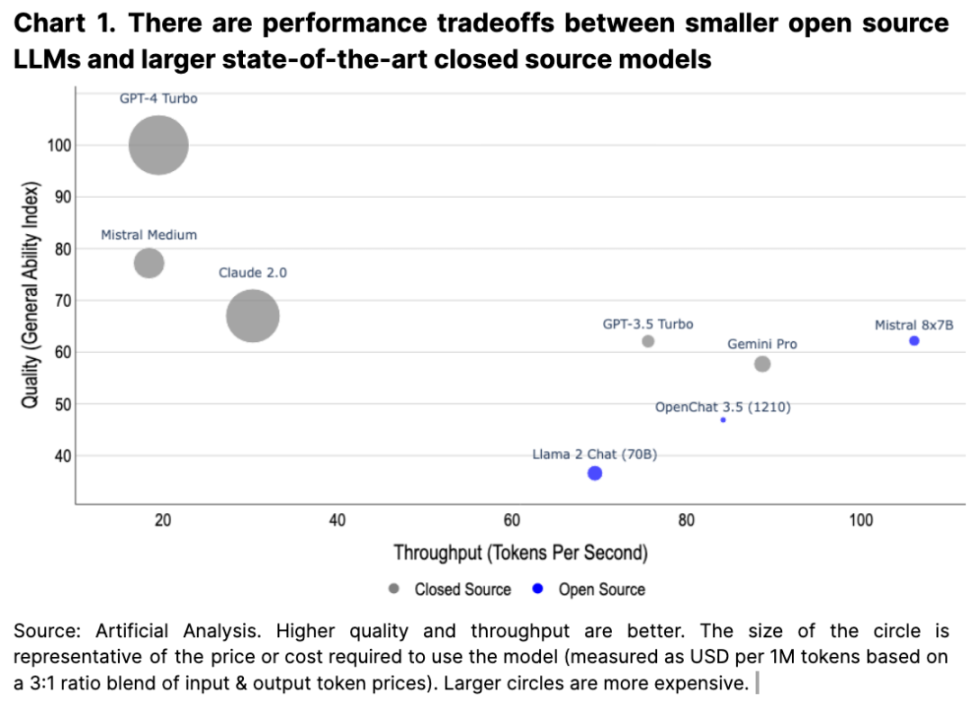
2 番目の傾向は、小規模モデルの品質と費用対効果の向上であり (これは 2020 年の LLM 研究で強調され、最近では MIcrosoft の論文でも強調されました)、これはオープンソース文化とも一致しています。ローカルで実行される高性能 AI モデルの未来。特定のベンチマークでは、一部の微調整されたオープンソース モデルは、主要なクローズド ソース モデルを上回るパフォーマンスを発揮する場合もあります。そのような世界では、一部の AI モデルをローカルで実行して、分散化を最大限に高めることができます。もちろん、既存のテクノロジー企業は今後もクラウド上で大規模なモデルのトレーニングと実行を続けるでしょうが、両者の間には設計空間におけるトレードオフが存在します。
さらに、AI モデルのベンチマーク作業がますます複雑化していること (データの汚染やテスト範囲の変化など) を考慮すると、生成されたモデルの出力は、最終的には自由市場のエンドユーザーによって最もよく評価される可能性があると考えています。実際、エンド ユーザーがモデルの出力を並べて比較できるツールはすでに存在しており、同様のサービスを提供するベンチマーク会社もあります。人工知能ベンチマークを生成することの難しさは、MMLU、HellaSwag、TriviaQA、BoolQ など、オープン LLM ベンチマークの種類が増えていることからもわかります。各ベンチマークは、常識的推論、学術トピック、さまざまな質問など、さまざまなユースケースをテストします。フォーマットなど
AI 分野で観察される 3 番目の傾向は、強力なユーザー ロックインや特定のビジネス上の問題を抱える既存のプラットフォームが AI 統合から不釣り合いな恩恵を受ける可能性があるということです。たとえば、Github Copilot とコード エディターの統合により、すでに強力な開発環境が強化されます。電子メール クライアント、スプレッドシート、顧客関係管理ソフトウェアなどの他のツールに AI インターフェイスを組み込むことも、AI の自然な使用例です (たとえば、Klarna の AI アシスタントは 700 人のフルタイム エージェントの仕事を行うことができます)。
ただし、これらのシナリオの多くでは、AI モデルは新しいプラットフォームを作成するのではなく、既存のプラットフォームを強化するだけであることに注意することが重要です。従来のビジネス プロセスを改善する他の AI モデル (たとえば、Apple が App Tracking Transparency を導入した後、Meta の Lattice は広告パフォーマンスを回復しました) も、多くの場合、独自のデータやクローズド システムに依存しています。この種の AI モデルはコア製品に垂直統合されており、独自のデータを使用するため、クローズド ソースのままになる可能性があります。
AI ハードウェアとコンピューティングの世界では、他にも 2 つの関連トレンドが見られます。 1 つ目は、計算の使用がトレーニングから推論に移行することです。つまり、人工知能モデルが最初に開発されるとき、大規模なデータセットを供給することによってモデルを「トレーニング」するために、膨大な量のコンピューティングリソースが使用されます。ここで、モデルのデプロイメントとモデルのクエリに進みます。
Nvidia は 2024 年 2 月の決算会見で、自社のビジネスの約 40% が推論であることを明らかにしました。サタヤ ナデラ氏も Microsoft の 1 月の決算会見で同様の発言をし、Azure AI の使用量の「ほとんど」が推論のためであると指摘しました。この傾向が続くにつれ、モデルの収益化を目指す企業は、安全かつ本番環境に対応した方法でモデルを確実に実行できるプラットフォームを優先すると考えられます。
2 番目の大きな傾向は、ハードウェア アーキテクチャを取り巻く競争環境です。 Nvidia の H 200 プロセッサは 2024 年の第 2 四半期に発売される予定で、次世代 B 100 のパフォーマンスはさらに 2 倍になると予想されています。さらに、Google は自社のテンソル プロセッシング ユニット (TPU) と Groq の新しい言語プロセッシング ユニット (LPU) を継続的にサポートしているため、今後数年間でこの分野での市場シェアが強化される可能性があります (図 2 を参照)。これらの開発は、AI 業界のコスト力学を変える可能性が高く、迅速に適応し、大規模なハードウェアを調達し、関連する物理ネットワークと開発ツールをセットアップできるクラウド サービス プロバイダーに利益をもたらす可能性があります。
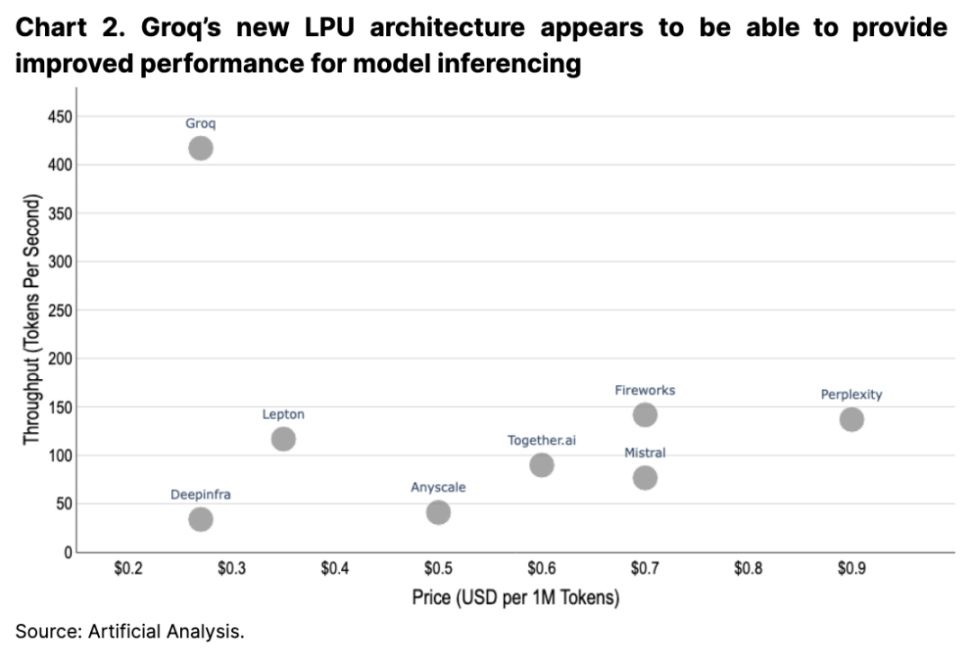
全体として、人工知能の分野は新興分野であり、急速に発展しています。 ChatGPT が 2022 年 11 月に初めて市場に登場してから 1 年半も経っていません (ただし、その基礎となる GPT-3 モデルは 2020 年 6 月から存在しています)。それ以来、この分野の急速な発展は驚くべきものでした。生成 AI モデルの背後にはある程度のバイアスがありますが、市場の適者生存効果 (より優れた代替モデルを優先してパフォーマンスの低いモデルを無視する) がすでに見え始めています。業界の急速な成長と今後の規制は、新しいソリューションが市場に投入され続けるにつれて、業界の問題領域も変化することを意味します。
「地方分権化が[問題の挿入]を解決する」というよく宣伝される一連の対策パッケージはコンセンサスのようですが、私たちの見解では、これほど急速に革新する分野にとっては時期尚早です。また、必ずしも存在するとは限らない集中化の問題も事前に解決します。現実には、AI 業界では、多くの異なる企業とオープンソース プロジェクト間の競争を通じて、テクノロジーとビジネスの分野ですでに多くの分散化が進んでいます。さらに、技術レベルと社会レベルの両方で、真の分散型プロトコルは、集中型プロトコルに比べて意思決定と合意のプロセスがはるかに遅くなります。これは、AI 開発の現段階で分散化と競争力のバランスをとる製品を探すのに障害となる可能性があります。そうは言っても、暗号通貨と人工知能の間にはいくつかの意味のある相乗効果があると私たちは考えていますが、それはより長い時間軸での話です。
チャンスの範囲を広げる
大まかに言うと、私たちは AI と暗号通貨の交差点を 2 つの大きなカテゴリに分類します。 1 つ目は、暗号通貨業界を改善するための AI 製品のユースケースです。これには、人間が判読できるトランザクションの作成、ブロックチェーン データ分析の改善、パーミッションレス プロトコルでのモデル出力の使用のシナリオが含まれます。 2 番目のカテゴリは、Crypto の計算、検証、ID などの分散手法を通じて従来の AI プロセスを打破することを目的としたユースケースです。
私たちの見解では、前者のカテゴリーでは、ビジネスと一致するシナリオでのユースケースは明確であり、重大な技術的課題は残っているものの、長期的にはより複雑なオンチェーン推論モデルの恩恵を受けると考えています。 . シーンにはまだ見通しがあります。一元化された AI モデルは、開発者ツール、コード監査、人間の言語をオンチェーンのアクションに翻訳するなど、他のテクノロジー中心の業界と同様に暗号通貨を改善できます。しかし、この分野への現在の投資は通常、ベンチャーキャピタルを通じて民間企業が所有しているため、公開市場では無視されることが多い。
ただし、私たちにとってあまり確信が持てないのは、2 番目のカテゴリーの価値提案 (つまり、暗号通貨が既存の AI 環境を破壊するということ) です。後者のカテゴリーの課題は、技術的な性質の課題に取って代わるものであり(長期的には一般に解決可能であると当社は信じています)、より広範な市場および規制勢力との困難な戦いです。しかし、それにもかかわらず、現実には、AI + 暗号に関する最近の注目の多くは、このカテゴリーに集中しています。これらのユースケースは、リキッドトークンの作成により適しているからです。これは次のセクションで焦点を当てますが、仮想通貨では、集中型 AI ツールに関連する流動性トークンは (今のところ) 比較的少数です。
AIにおける暗号の役割
簡略化するために、AI プロセスの 4 つの主要な段階を通じて、Crypto が AI に与える潜在的な影響を分析します。
(1) データの収集、保存、処理、(2) モデルのトレーニングと推論、(3) モデル出力の検証、(4) AI モデル出力の追跡。これらの分野では多数の新しい暗号 AI プロジェクトが登場していますが、短期から中期的には多くのプロジェクトがデマンドサイドでの生成における重大な課題や、中央集権的な企業やオープンソース ソリューションとの熾烈な競争に直面すると考えられます。
独自のデータ
データはすべての AI モデルの基盤であり、おそらくプロフェッショナル AI モデルのパフォーマンスにおける重要な差別化要因となります。過去のブロックチェーン データ自体は、モデル用の新しくて豊富なデータ ソースであり、一部のプロジェクト (Grass など) は、オープン インターネットから新しいデータ セットを取得するために暗号化インセンティブを活用することも目的としています。この点で、Crypto には業界固有のデータセットを提供し、新しい価値のあるデータセットの作成を奨励する機会があります。 (Reddit と Google との最近の年間 6,000 万ドルのデータ ライセンス契約は、データ セットの収益化における将来の成長を予感させます。)
初期のモデル (GPT-3 など) の多くは、CommonCrawl、WebText 2、Books、Wikipedia などのオープン データセットを組み合わせて使用していました。同様のデータセットは、Hugging Face (現在 110,000 を超えるオプションをホストしています) で自由に入手できます。ただし、おそらく商業的利益を保護するため、最近リリースされたクローズドソース モデルの多くは、最終的なトレーニング データセットの組み合わせを公開していません。特にビジネス モデル内で独自のデータセットへの傾向は今後も続き、データ ライセンスの重要性が高まると当社は考えています。
既存の集中型データ マーケットプレイスは、すでにデータ プロバイダーと消費者との間のギャップを埋めるのに役立っており、これにより、オープン ソース データ カタログと企業の競合他社の間に新たな分散型データ マーケットプレイス ソリューションの機会が生まれると私たちは考えています。法的構造のサポートがなければ、純粋に分散型のデータ マーケットプレイスは、標準化されたデータ インターフェイスとチャネルを構築し、データの整合性と構成を検証し、製品のコールド スタート問題を解決する必要もあります。市場参加者間でトークンのインセンティブのバランスを取る必要もあります。
さらに、分散型ストレージ ソリューションは最終的に AI 業界でニッチな市場を見つける可能性がありますが、この点ではまだかなりの課題があると考えられます。一方で、オープンソース データセットを配布するチャネルはすでに存在しており、広く使用されています。一方で、独自のデータセットの所有者の多くは、厳格なセキュリティとコンプライアンスの要件を持っています。現在、Filecoin や Arweave などの分散ストレージ プラットフォームで機密データをホストするための規制経路はありません。実際、多くの企業は依然としてオンプレミス サーバーから集中型クラウド ストレージ プロバイダーへの移行を進めています。技術レベルでは、これらのネットワークの分散型の性質は、現在、特定の地域の問題や機密データ ストレージの物理データ サイロ要件と互換性がありません。
分散型ストレージ ソリューションと既存のクラウド プロバイダーの価格比較では、単一ストレージ ユニットの観点からは分散型オプションの方が安価である可能性があることも示されていますが、これではより大きな問題が見落とされていると考えられます。まず、継続的な運用費用に加えて、ベンダー間でシステムを移行するための初期費用も考慮する必要があります。第二に、暗号ベースの分散ストレージ プラットフォームは、過去 20 年間に開発された成熟したクラウド システムによって提供される、より優れたツールと統合に適合する必要があります。ビジネス運営の観点から見ると、クラウド ソリューションはコストがより予測可能であり、契約上の義務があり、専任のサポート チームと大規模な開発者の人材プールが伴います。
「ビッグ 3」クラウド プロバイダー (AWS、Google Cloud Platform、Microsoft Azure) との大まかな比較は不完全であることにも注意してください。低コストのクラウド会社も数十社あり、より安価な基本的なサーバーやその他のサービスを提供して市場シェアを争っています。私たちの見解では、短期的には、コストを重視する消費者にとって、彼らが真の主な競争相手となるでしょう。とはいえ、Filecoin のデータ コンピューティングや Arweave の ao コンピューティング環境などの最近のイノベーションは、機密性の低いデータ セットを使用することが多い、またはコストに最も敏感な今後の革新的なプロジェクトの一部で役割を果たす可能性があります。サプライヤーをダウンさせます。
したがって、データ空間には新しい暗号製品の余地が確かにありますが、独自の価値提案を生み出すことができる短期的なブレークスルーが起こると私たちは信じています。私たちの見解では、分散型製品が従来の競合他社やオープンソースの競合他社と真っ向から競合する分野は、大幅な進歩を遂げるまでにさらに長い時間がかかると考えられます。
トレーニングと推論モデル
Crypto の分散コンピューティング (DeComp) 分野も、既存の GPU の供給不足が原因で、集中型クラウド コンピューティングの代替となることを目指しています。この不足に対して提案されている解決策の 1 つは、Akash や Render などのプロトコルで採用されており、アイドル状態のコンピューティング リソースを集中ネットワークに再統合し、それによって集中クラウド プロバイダーのコストを削減することです。暫定的な指標によると、このようなプロジェクトはユーザーとベンダーの両方で採用が増加しているようです。たとえば、Akash は、主にストレージとコンピューティング リソースの使用量の増加により、アクティブなテナント (ユーザー数) が年初から 3 倍に増加しました (図 3 を参照)。
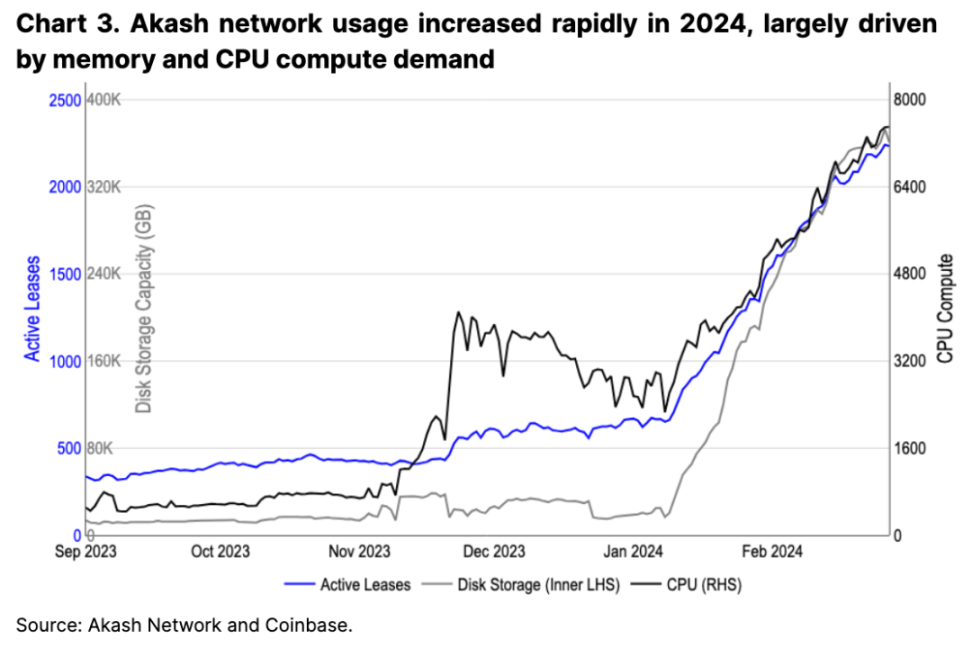
ただし、利用可能な GPU の供給がこれらのリソースの需要の増加を上回っているため、2023 年 12 月のピーク以来、ネットワークに支払われる料金は実際には減少しています。とはいえ、より多くのプロバイダーがネットワークに参加するにつれて、リースされる GPU の数 (比例して最大の収益原動力となるようです) は減少しています (図 4 を参照)。需要と供給の変化に基づいて計算価格が変化する可能性があるネットワークでは、供給側の成長が需要側の成長を上回った場合、ネイティブ トークンに対する使用量に応じた持続的な需要が最終的にどこから来るのかは不明です。市場の変化を最適化するために、将来このトークンモデルを再検討する必要があるかもしれないと私たちは考えていますが、そのような変化の長期的な影響は現時点では不明です。
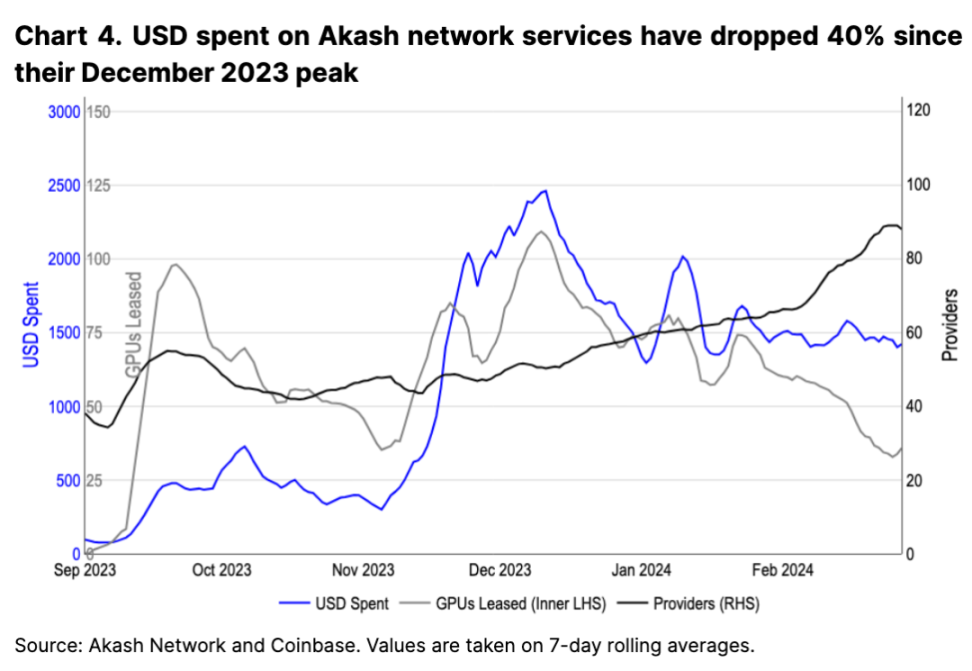
技術レベルでは、分散型コンピューティング ソリューションはネットワーク帯域幅の制限という課題にも直面しています。マルチノードのトレーニングを必要とする大規模なモデルの場合、物理ネットワーク インフラストラクチャ層が重要な役割を果たします。データ転送速度、同期オーバーヘッド、および特定の分散トレーニング アルゴリズムのサポートにより、それらを効率的に実行するには、特定のネットワーク構成とカスタム ネットワーク通信 (InfiniBand など) が必要になります。そのため、クラスターサイズが一定の範囲を超えると、分散型での実装が困難になります。
全体として、分散型コンピューティング (およびストレージ) の長期的な成功は、集中型クラウド プロバイダーとの厳しい競争に直面すると考えています。私たちの見解では、少なくともクラウド サービスの導入サイクルに関して言えば、いかなる導入も長期的なプロセスになると考えられます。分散型 Web 開発の技術的複雑さの増大と、同様にスケーラブルな開発および販売チームの不足を考慮すると、分散型コンピューティングのビジョンを完全に実行することは困難な道のりになると考えています。
認証と信頼モデル
私たちの生活において AI モデルの重要性が高まるにつれ、その出力の品質と偏りに対する懸念が高まっています。一部の暗号プロジェクトは、一連のアルゴリズムを活用してさまざまなカテゴリの出力を評価することで、この問題に対する分散型の市場ベースの解決策を見つけることを目指しています。ただし、モデルのベンチマークを取り巻く上記の課題、および明らかなコスト、スループット、品質のトレードオフにより、競合は正面から挑戦的になります。このカテゴリで最大の AI に焦点を当てた暗号通貨の 1 つである BitTensor は、この問題の解決を目指していますが、広範な普及を妨げる可能性のある技術的な課題がまだいくつかあります (付録 1 を参照)。
さらに、トラストレス モデル推論 (つまり、モデル出力が実際に主張されたモデルによって生成されたことの証明) は、Crypto x AI で活発に研究されているもう 1 つの分野です。ただし、オープンソース モデルの規模が縮小するにつれて、これらのソリューションは需要の面で課題に直面する可能性があると考えています。確立されたファイル ハッシュ/チェックサム方法によってコンテンツの整合性が検証され、モデルをローカルにダウンロードして実行できる世界では、トラストレス推論の役割はそれほど明確ではありません。確かに、多くの LLM は携帯電話などの軽量デバイスではまだトレーニングして実行できませんが、強力なデスクトップ コンピューター (ハイエンド ゲームに使用されるコンピューターなど) を使用して、多くの高性能モデルを実行することができます。
データソースとアイデンティティ
生成型 AI の出力が人間の出力と区別できなくなるにつれて、AI が生成したものを追跡することの重要性がクローズアップされています。 GPT-4 は GPT-3.5 より 3 倍の速さでチューリング テストに合格しており、そう遠くない日、オンラインの人格と機械や本物の人間を区別できなくなる日がほぼ確実に発生します。そのような世界では、オンライン ユーザーの人間性を判断し、AI によって生成されたコンテンツに透かしを入れることが重要な機能になります。
Worldcoin のような分散型識別子と本人証明メカニズムは、チェーン上で人間を識別することで前者の問題を解決することを目的としています。同様に、データ ハッシュをブロックチェーンに公開すると、コンテンツの年齢と出所を検証することでデータの出所を確認できます。ただし、前のセクションと同様に、暗号ベースのソリューションの実現可能性は、集中型の代替案と比較して検討する必要があると考えています。
中国などの一部の国では、オンラインの個人情報を政府が管理するデータベースにリンクしています。世界の多くはそれほど集中化されていませんが、KYC プロバイダーのコンソーシアムは、ブロックチェーン技術から独立した人格証明ソリューションを提供することもできます (おそらく、今日のインターネット セキュリティの基礎を形成する信頼できる認証局と同様の方法で)。また、コンテンツが AI によって生成されたかどうかをアルゴリズムが検出できるようにするために、テキストや画像出力に隠された信号を埋め込む AI 透かしの研究も進行中です。 Microsoft、Anthropic、Amazon を含む多くの大手 AI 企業は、生成するコンテンツにそのような透かしを追加することを公に約束しています。
さらに、既存のコンテンツ プロバイダーの多くは、コンプライアンス上の理由からコンテンツ メタデータの厳密な記録を保持しているとすでに信頼されています。その結果、ユーザーは多くの場合、ソーシャル メディアの投稿に関連付けられたメタデータ (ただし、スクリーンショットは除く) を、それらが中央に保存されているにもかかわらず信頼します。ここで重要なのは、暗号ベースのデータ来歴とアイデンティティのソリューションが広く効果を発揮するには、ユーザー プラットフォームと統合する必要があるということです。したがって、暗号ベースのソリューションは、身元とデータの出所を証明するという点では技術的には実現可能ですが、その採用は当然のことではなく、最終的にはビジネス、コンプライアンス、規制要件に依存すると考えています。
トレーディング AI ナラティブ
上記の問題にもかかわらず、多くの AI トークンは、2023 年第 4 四半期以降、ビットコインやイーサリアム、さらには Nvidia や Microsoft などの主要 AI 株を上回りました。これは、AI トークンが一般に、より広範な暗号市場とそれに関連する AI ブームの相対的なパフォーマンスから恩恵を受けるためであると私たちは考えています (付録 2 を参照)。したがって、たとえビットコインの価格が下落したとしても、AIに焦点を当てたトークンは価格の上昇に見舞われ、ビットコインの下落時に上向きのボラティリティが生じます。図 5 は、ビットコインが下落していた日の AI トークンのパフォーマンスを示しています。
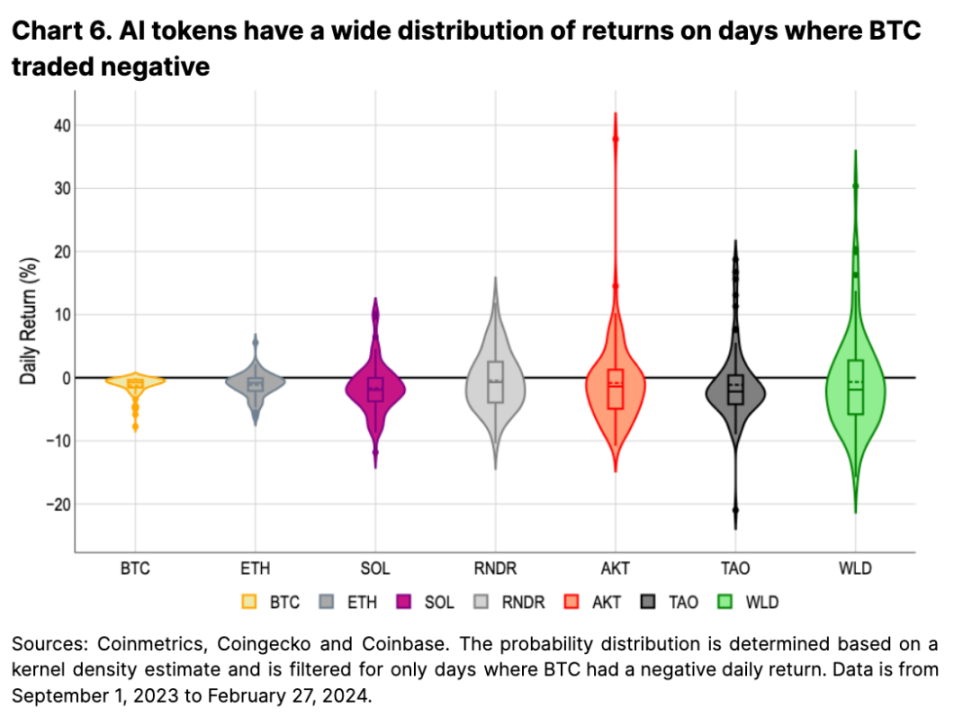
全体として、私たちは、AI ナラティブ取引には多くの短期的な持続可能な需要の推進力が欠けていると引き続き信じています。明確な導入予測や指標が欠如しているため、ミーム風の憶測が生まれており、私たちの意見では、長期的には持続可能ではない可能性があります。最終的に、価格と効用は収束するが、未解決の問題は、それにどれくらいの時間がかかるのか、そして効用が価格に見合うまで上昇するのか、それともその逆なのかということである。そうは言っても、持続可能で建設的な仮想通貨市場とAI業界を上回るパフォーマンスにより、仮想通貨AIの強力な物語はしばらく続く可能性が高いと私たちは考えています。
結論は
AI における暗号の役割は孤立して存在するわけではなく、分散型プラットフォームは既存の集中型プラットフォームと競合するため、より広範なビジネスおよび規制要件の文脈の中で分析する必要があります。したがって、「分散化」を目的として集中型プロバイダーを置き換えるだけでは、市場での有意義な採用を促進するには十分ではないと考えています。生成 AI モデルは数年前から存在しており、市場競争とオープンソース ソフトウェアによりある程度の分散化が維持されています。
このレポートで繰り返し取り上げられているテーマは、暗号ベースのソリューションは多くの場合技術的に実現可能であるものの、より集中化されたプラットフォームとの機能的同等性を達成するには依然として多大な作業が必要であるということであり、これはこれらのプラットフォームがこの期間中に停滞しないことが前提となっています。実際、集中型開発はコンセンサス メカニズムにより分散型開発よりも高速であることが多く、人工知能のような急速に発展している分野では課題が生じる可能性があります。
これを念頭に置くと、AI と暗号通貨の重複はまだ初期段階にあり、人工知能のより広範な分野が発展するにつれて、今後数年間で急速に変化する可能性が高いと考えられます。多くの仮想通貨関係者が思い描いている分散型 AI の未来は、現時点では実現する保証はなく、実際、AI 業界自体の将来はほとんど不透明なままです。したがって、そのような市場を慎重にナビゲートし、仮想通貨ベースのソリューションが実際にどのように有意義に優れた代替手段を提供するか、少なくとも根底にある取引の物語を理解する方法をより深く掘り下げることが賢明であると私たちは信じています。したがって、このような市場では慎重な姿勢を誤り、暗号ベースのソリューションがどのように真に意味のある優れた代替手段を提供できるか、少なくとも根底にある取引の物語を理解できるかをより深く掘り下げることが賢明であると考えます。
付録 1: BitTensor
BitTensor は、32 のサブネットにわたるさまざまなインテリジェンス市場を奨励します。これは、サブネット所有者がゲームのような制約を作成して情報プロバイダーからインテリジェンスを抽出できるようにすることで、ベンチマークに関するいくつかの問題に対処することを目的としています。たとえば、主力のサブネット 1 はテキスト プロンプトを中心としており、「そのサブネット内のサブネット バリデーターによって送信されたプロンプトに基づいて最適な応答を生成する」マイナーにインセンティブを与えます。つまり、そのサブネット内の他のバリデーターによって判断され、特定のプロンプトに対して最良のテキスト応答を生成できるマイナーに報酬が与えられます。これにより、ネットワーク参加者がさまざまな市場でモデルを作成しようとするスマート エコノミーが可能になります。
ただし、この検証と報酬のメカニズムはまだ初期段階にあり、特にバイアスを含む他のモデルを使用してモデルが評価される場合、敵対的な攻撃に対して脆弱です (ただし、この領域では、特定のサブネットの評価に新しい合成データを使用して進歩が見られます)。 。これは、言語や芸術などの「あいまいな」出力に特に当てはまります。評価指標が主観的になる可能性があるため、モデルのパフォーマンスに複数のベンチマークが必要になります。
たとえば、BitTensor のサブネット 1 の検証メカニズムでは、実際には次のことが必要です。
バリデーターは 1 つ以上の参照回答を生成し、すべてのマイナーの回答が比較されます。リファレンスに対して最も類似した回答をした人が最高の報酬を受け取り、最終的には最大のインセンティブを受け取ります。
現在の類似性アルゴリズムは、報酬の基礎として文字列リテラルとセマンティック一致の組み合わせを使用しますが、限られた参照回答セットでさまざまなスタイルの好みを把握することは困難です。
BitTensor インセンティブ構造から得られるモデルが最終的に集中型モデルよりも優れたパフォーマンスを発揮するかどうか (または、最もパフォーマンスの高いモデルが BitTensor に移行するかどうか)、あるいはモデル サイズや基礎となる計算コストなどの他のトレードオフにどのように対応できるかは不明です。ユーザーが自分の好みに合ったモデルを自由に選択できる市場では、「見えざる手」を通じて同様のリソースの割り当てを実現できるかもしれません。そうは言っても、BitTensor は、拡大し続ける問題空間において非常に困難な問題を解決しようとしています。
付録 2: ワールドコイン
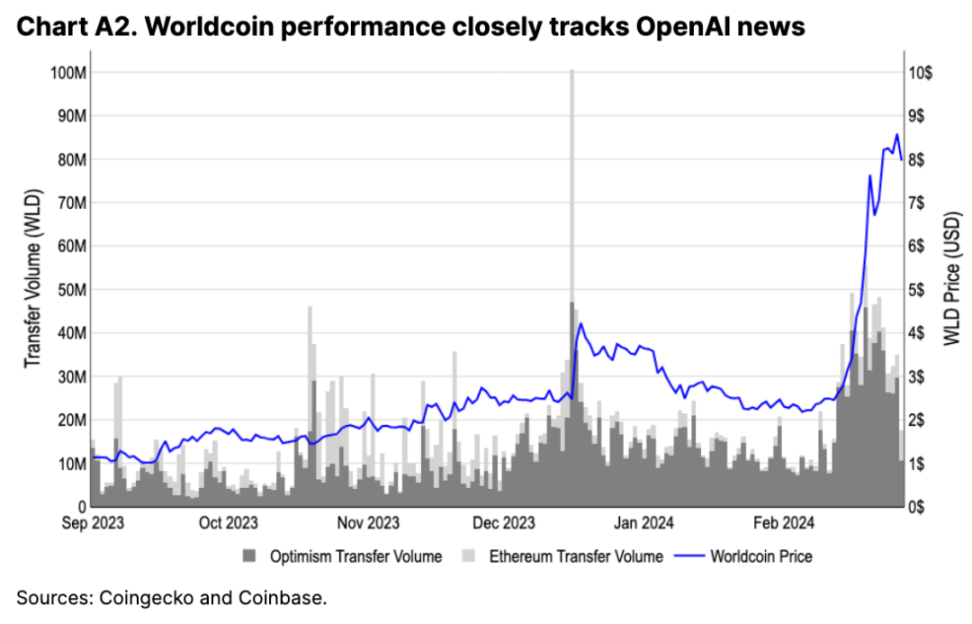
おそらく、人工知能市場の流行に続く AI トークンの最も明白な例はワールドコインでしょう。 2023年12月13日にワールドID 2.0アップグレードをリリースしたが、ほとんど注目を集めなかったが、サム・アルトマン氏が12月15日にワールドコインを宣伝した後、50%上昇した。 (ワールドコインの将来についての憶測は依然として悪者扱いされている。サム・アルトマン氏がワールドコインの開発者であるツール・フォー・ヒューマニティの共同創設者であることも一因である。同様に、2024年2月15日にOpenAIがリリースしたSoraの価格は3倍近く上昇したものの、 Worldcoin の Twitter やブログには関連する発表はありません (図 6 を参照)。この記事の執筆時点で、Worldcoin の評価額は 800 億米ドルであり、これは 2 月 16 日時点の OpenAI の評価額 860 億米ドルに非常に近いです (これは、年間収益のある企業です) 20億ドル)。
https://dao2.io にログインして、世界中の主要なメディアや機関からの最新情報、洞察、研究を入手してください。
DAOSquare コミュニティに参加して、DAOSquare インキュベーターの最新開発について学びましょう。


