
DAOrayaki: Web3 エコシステムにおける AI アプリケーションの展望
ChatGPT と GPT-4 の導入以来、AI が Web 3 を含むすべてのものにどのように革命をもたらすことができるかについて多くの記事が書かれてきました。複数の業界の開発者は、ChatGPT をコドライバーとして利用して、ボイラープレート コードの生成、単体テストの実施、ドキュメントの作成、デバッグ、バグの検出などのタスクを自動化することで、50% から 500% の範囲で生産性が大幅に向上したと報告しています (% はさまざまです)。この記事では、AI が新しくて興味深い Web 3 の使用例をどのように可能にするかを検討しますが、主な焦点は Web 3 と AI の相互利益関係にあります。人工知能の方向性に大きな影響を与えることができるテクノロジーはほとんどありません。Web 3 はその 1 つです。

Web3 はどのように人工知能を促進しますか?
その巨大な可能性にもかかわらず、現在の AI モデルは、データのプライバシー、独自のモデルの実行における公平性、信頼できる偽のコンテンツを作成して配布する能力など、いくつかの課題に直面しています。既存の Web 3 テクノロジーの中には、これらの課題に対処する独自の立場にあるものもあります。
01 機械学習 (ML) トレーニング用の独自のデータセットを作成する
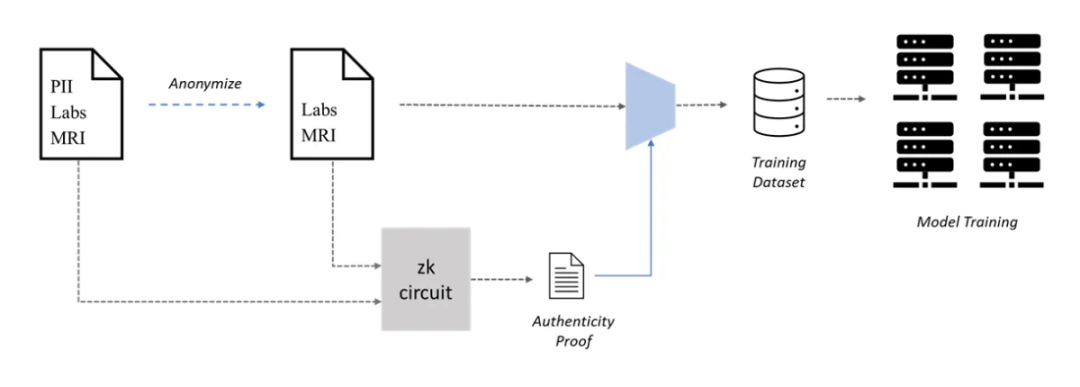
Web 3 が AI に役立つ分野の 1 つは、機械学習 (ML) トレーニング用の独自のデータセットの共同作成、つまりデータセットの作成に PoPW ネットワークを使用することです。大規模なデータセットは正確な ML モデルにとって重要ですが、ML を使用した医療診断など、プライベート データの使用が必要なユースケースでは、データセットの作成がボトルネックになる可能性があります。患者データのプライバシー上の懸念により、これらのモデルをトレーニングするには医療記録へのアクセスが必要ですが、患者はプライバシー上の懸念から医療記録の共有に消極的な場合があります。これに対処するために、患者は自分の医療記録を検証可能な方法で匿名化し、ML トレーニングに参加しながらプライバシーを保護できます。
ただし、偽のデータはモデルのパフォーマンスに重大な影響を与える可能性があるため、匿名化された医療記録の信頼性が問題になります。この問題に対処するために、ゼロ知識証明 (ZKP) を使用して、匿名化された医療記録の信頼性を検証できます。患者は、個人を特定できる情報 (PII) を削除した後でも、匿名記録が実際に元の記録のコピーであることを証明する ZKP を生成できます。このようにして、患者は、プライバシーを犠牲にすることなく、ZKP を使用して匿名の記録を利害関係者が利用できるようになり、貢献に対する報酬を受け取ることもできます。
02 プライベートデータ推論を実行する
現在の LLM の主な弱点は、プライベート データの処理です。たとえば、ユーザーが chatGPT と対話すると、OpenAI はユーザーのプライベート データを収集し、それをモデルのトレーニングに使用します。これは機密情報の漏洩につながります。これはサムスンの場合です。ゼロ知識 (zk) 技術は、ML モデルがプライベート データに対して推論を実行するときに発生する問題の一部を解決するのに役立ちます。ここでは、オープンソース モデルと独自モデルの 2 つのケースを検討します。
オープンソース モデルの場合、ユーザーはプライベート データにモデルをローカルにダウンロードして実行できます。たとえば、Worldcoin は World ID をアップグレードする予定です。このユースケースでは、Worldcoin はユーザーのプライベートな生体認証データ、つまりユーザーの虹彩スキャンを処理して、IrisCode と呼ばれる各ユーザーの一意の識別子を作成する必要があります。この場合、ユーザーは自分のデバイス上で生体認証データを非公開にし、IrisCode の生成に使用される ML モデルをダウンロードし、ローカルで推論を実行し、IrisCode が正常に作成されたという証拠を作成できます。生成された証明は、データのプライバシーを維持しながら推論の信頼性を保証します。 Modulus Labs によって開発されたもののような、ML モデルの効率的な zk 証明メカニズムは、このユースケースにとって非常に重要です。
もう 1 つのケースは、推論に使用される ML モデルが独自のものである場合です。ローカル推論はオプションではないため、このタスクは多少困難です。ただし、ZKP が支援できる方法は 2 つあります。最初のアプローチは、前のデータセット作成例で説明したように、ZKP を使用してユーザー データを匿名化し、匿名化されたデータを ML モデルに送信することです。別のアプローチは、前処理された出力を ML モデルに送信する前に、プライベート データに対してローカル前処理ステップを使用することです。この場合、前処理ステップではユーザーの個人データが再構築できないように隠蔽されます。ユーザーは、前処理ステップが正しく実行されたことを示す ZKP を生成すると、独自モデルの残りの部分をモデル所有者のサーバーでリモート実行できます。ここでのユースケースの例には、潜在的な診断のために患者の医療記録を分析できる AI 医師や、クライアントの個人的な財務情報を評価する財務リスク評価アルゴリズムが含まれる可能性があります。
03 コンテンツの信頼性とディープフェイク技術との闘い
chatGPT は、画像、音声、ビデオの生成に焦点を当てた生成 AI モデルから脚光を奪った可能性があります。ただし、これらのモデルは現在、現実的なディープフェイクを生成できます。 Drake が最近 AI で生成した曲は、これらのモデルが達成できることの一例です。人間は見聞きしたものを信じるようにプログラムされているため、こうしたディープフェイクは大きな脅威となっています。 Web 2 テクノロジーを使用してこの問題を解決しようとしているスタートアップ企業が数多くあります。ただし、この問題の解決には、デジタル署名などの Web 3 テクノロジの方が適しています。
Web 3 では、ユーザーの対話、つまりトランザクションは、その正当性を証明するためにユーザーの秘密キーによって署名されます。同様に、テキスト、画像、オーディオ、ビデオのいずれであっても、コンテンツの信頼性を証明するために作成者の秘密キーで署名することもできます。誰でも、作成者の Web サイトまたはソーシャル メディア アカウントで提供される作成者のパブリック アドレスに対して署名を検証できます。 Web 3 ネットワークは、この使用例を実現するために必要なインフラストラクチャをすべて構築しました。フレッド・ウィルソンは、コンテンツを公開暗号化キーにリンクすることで、誤った情報とどのように効果的に対抗できるかについて説明します。多くの評判の良いベンチャー キャピタル企業は、Twitter などの既存のソーシャル メディア プロファイル、またはレンズ プロトコルやミラーなどの分散型ソーシャル メディア プラットフォームを、コンテンツとしてデジタル署名を提供する暗号化されたパブリック アドレスにリンクしています。認証方法の信頼性がサポートを提供します。 。
概念は単純ですが、この認証プロセスのユーザー エクスペリエンスを向上させるには、まだ多くの作業が必要です。たとえば、クリエイターが利用できるシームレスなプロセスを提供するには、コンテンツ作成のデジタル署名を自動化する必要があります。もう 1 つの課題は、再署名せずにオーディオ クリップやビデオ クリップなどの署名済みデータのサブセットを生成する方法です。既存の Web 3 テクノロジーの多くは、これらの問題に対処するために独自の立場にあります。
04 独自モデルへの信頼を最小限に抑える
Web 3 が AI に役立つもう 1 つの領域は、独自の機械学習モデルがサービスとして提供される場合に、サービス プロバイダーに対する信頼を最小限に抑えることです。ユーザーは、支払ったサービスが実際に提供されたことを検証したり、機械学習モデルが公正に実行されること、つまりすべてのユーザーが同じモデルを使用することの保証を得る必要がある場合があります。ゼロ知識証明は、そのような保証を提供するために使用できます。このアーキテクチャでは、機械学習モデルの作成者は、モデルを表すゼロ知識回路を生成します。必要に応じて、この回路はユーザー推論のためのゼロ知識証明を生成するために使用されます。ゼロ知識証明は、検証のためにユーザーに送信することも、ユーザー検証タスクを処理するパブリック チェーン上で公開することもできます。機械学習モデルが非公開の場合、独立した第三者は、使用されている zk 回路がモデルを表していることを検証できます。機械学習モデルの信頼最小化の側面は、モデルのパフォーマンス結果のリスクが高い場合に特に役立ちます。例えば:
医療診断用の機械学習モデル
このユースケースでは、患者は潜在的な診断を行うために機械学習モデルに医療データを送信します。患者は、ターゲットの機械学習モデルが自分のデータに正しく適用されていることを確認する必要があります。推論プロセスでは、機械学習モデルが正しく実行されたことを証明するゼロ知識証明が生成されます。
ローンの信用価値評価
ゼロ知識証明により、銀行や金融機関は信用度を評価する際に、申請者が提出したすべての財務情報を確実に考慮することができます。さらに、ゼロ知識証明は公平性、つまりすべてのユーザーが同じモデルを使用していることを証明できます。
保険請求処理
現在の保険請求処理は手動であり、主観的です。機械学習モデルは、保険契約と保険金請求の詳細に関する保険金請求をより公平に評価できます。ゼロ知識証明と組み合わせることで、これらの保険金請求処理機械学習モデルは、すべての保険契約と保険金請求の詳細を考慮し、同じ保険契約に基づくすべての保険金請求が同じモデルを使用して処理されたことを証明できます。
05 モデル作成の一元化問題を解決する
LLM の作成とトレーニングは、特定のドメインの専門知識、専用のコンピューティング インフラストラクチャ、および数百万ドルの計算コストを必要とする、時間と費用がかかるプロセスです。これらの特性により、モデルへのアクセスを制限することでユーザーに大きな影響力を及ぼす強力な中央エンティティ (OpenAI など) が発生する可能性があります。
こうした集中化のリスクを考慮して、Web 3 が LLM のさまざまな側面の分散化をどのように促進できるかについて重要な議論が行われています。 Web 3 の支持者の中には、集中型のプレーヤーと競争する方法として分散型コンピューティングを提案している人もいます。基本的な考え方は、分散型コンピューティングがより安価な代替手段になり得るということです。ただし、これは集中型のプレーヤーと競争するには最適な角度ではない可能性があると考えています。分散コンピューティングの欠点は、異なる異種コンピューティング デバイス間の通信オーバーヘッドにより、ML トレーニングが 10 ~ 100 倍遅くなる可能性があることです。
代わりに、Web 3 プロジェクトは、PoPW 方式でユニークで競争力のある ML モデルの作成に集中できます。これらの PoPW ネットワークは、データを収集して、これらのモデルをトレーニングするための独自のデータセットを構築することもできます。この方向に進んでいるプロジェクトには、Togetter や Bittensor などがあります。
06 AI エージェントの支払いおよび実行チャネル
ここ数週間、LLM を使用して目標を達成するために必要なタスクを推論し、それらのタスクを実行して目標を達成する AI エージェントが増加しています。 AI エージェントの波は BabyAGI のアイデアから始まり、すぐに AutoGPT を含む高度なバージョンに広がりました。ここでの重要な予測は、AI エージェントが特定のタスクで優れた能力を発揮するためにより専門化するということです。専用の AI エージェントの市場が存在する場合、AI エージェントは特定のタスクを実行するために他の AI エージェントを検索、雇用、支払いを行うことができ、主要プロジェクトの完了につながります。その過程で、Web 3 ネットワークは AI エージェントに理想的な環境を提供します。支払いの場合、AI エージェントには、支払いの受け取りや他の AI エージェントへの支払いのための暗号通貨ウォレットを装備できます。さらに、AI エージェントは暗号化されたネットワークに接続して、許可なくリソースを委任することができます。たとえば、AI エージェントがデータを保存する必要がある場合、AI エージェントは Filecoin ウォレットを作成し、IPFS 上の分散ストレージの料金を支払うことができます。 AI エージェントは、Akash などの分散型コンピューティング ネットワークからコンピューティング リソースを委任して、特定のタスクを実行したり、自身の実行を拡張したりすることもできます。
07 AIプライバシー侵害からの保護
優れたパフォーマンスの ML モデルをトレーニングするには大量のデータが必要であることを考えると、個人の行動を予測するために ML モデルで公開データが使用されると想定しても問題ありません。さらに、銀行や金融機関は、ユーザーの財務情報に基づいてトレーニングされ、ユーザーの将来の金融行動を予測できる独自の ML モデルを構築できます。これは重大なプライバシーの侵害となる可能性があります。この脅威に対する唯一の緩和策は、デフォルトで金融取引のプライバシーを確保することです。このプライバシーは、zCash や Aztec Payments などのプライベート決済ブロックチェーンや、Penumbra や Aleo などのプライベート DeFi プロトコルを使用することで実現できます。
AI を活用した Web3 アプリケーションの事例
01 オンチェーン ゲーム
プログラマ以外のプレイヤー向けのボットを生成する
Dark Forest のようなオンチェーン ゲームは、プレイヤーが必要なゲーム タスクを実行するボットを開発および展開することで優位性を得るという独自のパラダイムを生み出します。このパラダイムシフトにより、コーディングができないプレイヤーが排除される可能性があります。ただし、LLM はこれを変更できます。 LLM は、オンチェーンのゲーム ロジックを理解するために微調整でき、プレイヤーがコードを記述することなくプレイヤーの戦略を反映するボットを作成できるようになります。 Primodium や AI Arena などのプロジェクトは、AI と人間のプレイヤーをゲームに参加させることに取り組んでいます。
ロボット格闘、ギャンブル、賭博
オンチェーン ゲームのもう 1 つの可能性は、完全自律型 AI プレーヤーです。この場合、プレーヤーは AutoGPT などの AI エージェントであり、LLM をバックエンドとして使用し、インターネット アクセスや初期の暗号通貨資金などの外部リソースにアクセスできます。これらの AI プレイヤーはロボット戦争のようにギャンブルをすることができます。これにより、投機とその結果に対する賭けの市場が開かれる可能性があります。
オンチェーン ゲーム用にリアルな NPC 環境を作成する
現在のゲームでは、ノンプレイヤー キャラクター (NPC) にはほとんど注意が払われません。 NPCの行動は限られており、ゲームの進行にほとんど影響を与えません。 AI と Web3 の相乗効果を考慮すると、予測可能性を打ち破り、ゲームをより面白くする、より魅力的な AI 制御の NPC を作成することが可能です。ここでの根本的な課題は、これらのアクティビティに関連するスループット (TPS) を最小限に抑えながら、有意義な NPC ダイナミクスを導入する方法です。過剰な NPC アクティビティに必要な TPS 要件はネットワークの混雑を引き起こし、実際のプレイヤーにとって悪いユーザー エクスペリエンスを生み出す可能性があります。
02 分散型ソーシャルメディア
分散型ソーシャル (DeSo) プラットフォームが現在直面している課題の 1 つは、既存の集中型プラットフォームと比較して独自のユーザー エクスペリエンスを提供していないことです。 AI とのシームレスな統合を採用することで、Web2 の代替手段にはない独自のエクスペリエンスを提供できます。たとえば、AI が管理するアカウントは、関連コンテンツを共有したり、投稿にコメントしたり、ディスカッションに参加したりすることで、新しいユーザーをネットワークに引き付けるのに役立ちます。 AIアカウントは、ユーザーの興味に合わせた最新トレンドをまとめたニュースアグリゲーションにも活用できます。 [ 18 ]
03 分散型プロトコルのセキュリティと経済設計のテスト
目標を定義し、コードを作成し、コードを実行できる LLM ベースの AI エージェントへの傾向は、分散型ネットワークのセキュリティと経済的健全性をテストする機会を生み出します。この場合、AI エージェントはプロトコルのセキュリティまたは経済的バランスを活用するように指示されます。 AI エージェントはまずプロトコル文書とスマート コントラクトをレビューし、弱点を特定します。 AI エージェントは、自らの利益を最大化するために、プロトコルを攻撃するための強制メカニズムを個別に競うことができます。このアプローチは、プロトコルが起動後に経験する実際の環境をシミュレートします。これらのテスト結果に基づいて、プロトコル設計者はプロトコル設計をレビューし、弱点を修正できます。現在までのところ、分散型プロトコルにそのようなサービスを提供するために必要な技術スキルを備えているのは、Gauntlet などの専門企業のみです。ただし、Solidity、DeFiメカニズム、および以前に開発されたメカニズムでトレーニングされたLLMが同様の機能を提供できると予想しています。
04 データのインデックス作成と指標抽出のための LLM
ブロックチェーン データは公開されていますが、そのデータのインデックスを作成し、有用な洞察を抽出することは継続的な課題です。この分野の一部のプレーヤー (CoinMetrics など) は、データのインデックス作成と販売用の複雑なメトリクスの構築を専門としていますが、他のプレーヤー (Dune など) は、生のトランザクションの主要コンポーネントのインデックス作成と、コミュニティの貢献を通じてメトリクス抽出部分をクラウドソーシングすることに重点を置いています。最近の LLM の進歩により、データのインデックス作成とメトリクスの抽出が危険にさらされる可能性があることが明らかになりました。 Dune はこの脅威を認識し、SQL クエリの解釈と NLP ベースのクエリの可能性を含む LLM ロードマップを発表しました。しかし、LLM の影響はこれよりもさらに深くなると予測しています。ここでの可能性の 1 つは、LLM ベースのインデックス作成です。LLM モデルは、ブロックチェーン ノードと直接対話して、特定のメトリクスのデータにインデックスを付けます。 Dune Ninja のような新興企業は、データのインデックス作成のための革新的な LLM アプリケーションをすでに検討しています。
05 新しいエコシステム開発者の紹介
このエコシステムでアプリケーションを構築する開発者を引きつけるために、さまざまなブロックチェーンが競合しています。 Web 3 開発者のアクティビティは、エコシステムの成功を示す重要な指標です。開発者が直面する主な困難は、新しいエコシステムの学習と構築を開始するときにサポートを得ることです。このエコシステムは、専任の開発者関係チームという形で、エコシステムを探索する開発者をサポートするために数百万ドルを投資してきました。この点で、新興の LLM は、複雑なコードを説明し、エラーを捕捉し、さらにはドキュメントを作成するなど、目覚ましい成果を上げています。適応した LLM は人間のエクスペリエンスを補完し、開発者関係チームの生産性を大幅に向上させることができます。たとえば、LLM を使用すると、ドキュメントやチュートリアルを作成したり、よくある質問に回答したり、テンプレート コードを使用してハッカソン開発者をサポートしたり、単体テストを作成したりすることもできます。
06 DeFiプロトコルの改善
人工知能を DeFi プロトコルのロジックに統合することで、多くの DeFi プロトコルのパフォーマンスを大幅に向上させることができます。これまでのところ、AI を DeFi に統合する際の主なボトルネックは、オンチェーン AI の実装にかかる法外なコストでした。 AI モデルはオフチェーンで実装できますが、以前はモデルの実行を検証する方法がありませんでした。ただし、オフチェーンで実行される検証は、Modulus や ChainML などのプロジェクトを通じて可能になりつつあります。これらのプロジェクトでは、オンチェーンのコストを制限しながら、オフチェーンで ML モデルを実行できます。 Modulus の場合、オンチェーン料金はモデルの ZKP の検証に限定されます。 ChainML の場合、オンチェーンコストは分散型 AI 実行ネットワークに支払われるオラクル料金です。
AI 統合から恩恵を受ける可能性がある DeFi のユースケースの一部。
AMM 流動性供給、つまり Uniswap V3 流動性の範囲を更新します。
オンチェーンおよびオフチェーンのデータ保護を使用した債務ポジションの清算保護。
金庫メカニズムが固定戦略ではなく金融 AI モデルによって定義される、複雑な DeFi 構造の製品。これらの戦略には、AI 管理の取引、融資、オプションが含まれる場合があります。
結論は
結論は
私たちは、Web3 と AI は文化的にも技術的にも互換性があると信じています。ボットを撃退する傾向にあった Web2 とは異なり、Web3 はそのパーミッションレス プログラマビリティにより AI の繁栄を可能にします。もっと広く言えば、ブロックチェーンをネットワークとして考えると、AI がネットワークのエッジを支配すると予想されます。これは、ソーシャル メディアからゲームまで、さまざまな消費者向けアプリケーションに当てはまります。これまでのところ、Web 3 ネットワークのエッジは主に人間によって担われてきました。人間が取引を開始して署名したり、固定戦略を備えたボットを実装したりします。時間の経過とともに、ネットワークのエッジにはますます多くの AI エージェントが登場するでしょう。 AI エージェントは、スマート コントラクトを通じて人間や相互に対話します。こうしたインタラクションにより、新たな消費者体験が可能になります。


